Amazon Web Services ブログ
Amazon S3 Vectors と Amazon OpenSearch Service によるベクトル検索の最適化
本記事は、2025 年 7 月 21 日に公開された Optimizing vector search using Amazon S3 Vectors and Amazon OpenSearch Service を翻訳したものです。翻訳は Solutions Architect の 深見 が担当しました。
注: 2025 年 7 月 22 日現在、Amazon S3 Vectorsと Amazon OpenSearch Service の統合機能はプレビューリリースであり、今後変更される可能性があります。
ベクトル埋め込みと類似度検索機能の進歩に伴い、データの保存と検索方法が急速に進化しています。ベクトル検索は、生成 AI やエージェント AI などの最新のアプリケーションにとって不可欠なものとなっています。しかし、大規模なベクトルデータを管理することは大きな課題があります。組織は、数百万または数十億ものベクトル埋め込みを保存して検索する際、レイテンシー、コスト、精度のトレードオフに悩まされることが多くあります。従来のソリューションでは、大規模なインフラストラクチャの管理が必要になるか、データ量が増えるにつれて非常に高額なコストがかかります。
私たちは、Amazon Simple Storage Service (Amazon S3) Vectors と Amazon OpenSearch Service の 2 つの統合機能のパブリックプレビューを公開しました。これにより、ベクトル埋め込みをより柔軟に格納および検索することができるようになります。
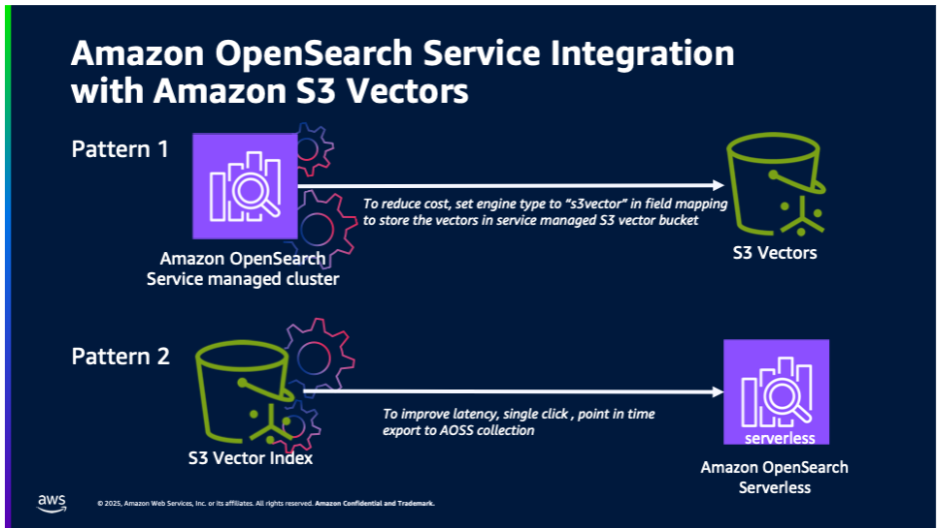
- コスト最適化されたベクトルストレージ: OpenSearch Service マネージドクラスターは、マネージドサービスの S3 Vectors を使用してコスト最適化されたベクトル格納を行います。この統合により、レイテンシーの増加を許容してでもコストを抑えつつ、高度な OpenSearch の機能 (ハイブリッド検索、高度なフィルタリング、地理フィルタリングなど) を利用したい OpenSearch のワークロードをサポートします。
- S3 Vectors からのワンクリックエクスポート: S3 ベクトルインデックスから OpenSearch Serverless コレクションへのワンクリックエクスポートにより、高パフォーマンスのベクトル検索が可能になります。S3 Vectors 上にベクトルストアを構築されたお客様は、より高速なクエリパフォーマンスを得るために OpenSearch を利用できるメリットがあります。
これらの統合を利用することで、頻繁にクエリされないベクトルを S3 Vectors に保持し、ハイブリッド検索や集計などの高度な検索機能を必要とするようなレイテンシの制約が最も高い操作には OpenSearch を使用することで、ベクトルワークロードを賢く分散させ、コスト、レイテンシー、精度を最適化できます。さらに、OpenSearch のパフォーマンスチューニング機能 (量子化、k 近傍 (knn) アルゴリズム、メソッド固有のパラメータ) は、コストや精度をほとんど妥協することなく、パフォーマンスを向上させるのに役立ちます。
この投稿では、ベクトル検索の実装に柔軟なオプションを提供しながら、このシームレスなインテグレーションについて説明します。コスト最適化されたベクトル格納のために、OpenSearch Service マネージドクラスターで新しい S3 Vectors エンジンタイプを使用する方法と、高パフォーマンスのシナリオで 10ms という低レイテンシーの持続的なクエリが必要な場合に、S3 Vectors から OpenSearch Serverless コレクションへのワンクリックエクスポートを使用する方法を学びます。この投稿の最後には、パフォーマンス、コスト、スケーラビリティの具体的な要件に基づいて、適切なインテグレーションパターンを選択して実装する方法がわかります。
サービスの概要
Amazon S3 Vectors は、およそ 1 秒以内のベクトル検索機能をネイティブでサポートする初めてのクラウドオブジェクトストアで、インフラストラクチャ管理は不要です。Amazon S3 の簡単さ、耐久性、可用性、コスト効率性に、ネイティブのベクトル検索機能を組み合わせたものです。ベクトル埋め込みを直接 S3 に保存して検索できます。Amazon OpenSearch Service は、ベクトルワークロードに対してマネージドクラスターと サーバーレスコレクションの 2 つの補完的なデプロイメントオプションを提供しています。どちらも Amazon OpenSearch の強力なベクトル検索と検索機能を活用しますが、それぞれが異なるシナリオに適しています。OpenSearch ユーザーにとって、S3 Vectors と Amazon OpenSearch Service の統合により、ベクトル検索アーキテクチャを最適化する前例のない柔軟性が得られます。リアルタイムアプリケーションに超高速のクエリパフォーマンスが必要な場合も、大規模なベクトルデータセットに低コストのストレージが必要な場合も、この統合により、特定のユースケースに最適なアプローチを選択できます。
ベクトル格納オプションの理解
OpenSearch Service は、さまざまなユースケースに最適化された、ベクトル埋め込みを格納および検索するための複数のオプションを提供しています。Lucene エンジン (OpenSearch のネイティブ検索ライブラリ) は、Hierarchical Navigable Small World (HNSW) 手法を実装しており、効率的なフィルタリング機能と OpenSearch のコア機能との強力な統合を提供します。さらなる最適化オプションが必要なワークロードの場合、Faiss エンジン (Facebook AI Similarity Search) は、HNSW と IVF (Inverted File Index) の両方の手法の実装に加えて、ベクトル圧縮の機能を提供します。HNSW はベクトル間の接続の階層的なグラフ構造を作成し、検索時の効率的なナビゲーションを可能にします。一方、IVF はベクトルをクラスター化し、クエリ時に関連するサブセットのみを検索します。S3 エンジンタイプの導入により、Amazon S3 の耐久性とスケーラビリティを活用しながら、およそ 1 秒以内のクエリパフォーマンスを維持できる、コスト効率の高いオプションが利用可能になりました。このように多様なオプションから、パフォーマンス、コスト、精度に関する特定の要件に基づいて最適なアプローチを選択できます。たとえば、アプリケーションが 50 ms 未満のクエリレスポンスと効率的なフィルタリングを必要とする場合、Faiss の HNSW 実装が最適な選択肢です。一方、ストレージコストを最適化しながら妥当なパフォーマンスを維持する必要がある場合は、新しい S3 エンジンタイプがより適切でしょう。
ソリューションの概要
この投稿では、2 つの主要な統合パターンについて説明します。
OpenSearch Service マネージドクラスターをマネージドサービスの S3 Vectors と使用して、ベクトルストレージのコストを最適化する
OpenSearch Service ドメインを既に使用しており、およそ 1 秒以内のクエリパフォーマンスを維持しながらコストを最適化したいお客様向けに、新しい Amazon S3 エンジンタイプが魅力的なソリューションを提供します。OpenSearch Service は、Amazon S3 でのベクトル格納、データ取得、キャッシュ最適化を自動的に管理するため、運用オーバーヘッドがなくなります。
S3 ベクトルインデックスから OpenSearch Serverless コレクションへのワンクリックエクスポートにより、高性能なベクトル検索が可能に
より高速なクエリパフォーマンスが必要なユースケースでは、S3 ベクトルインデックスからベクトルデータを OpenSearch Serverless コレクションに移行できます。この方法は、リアルタイムのレスポンスタイムが必要なアプリケーションに最適で、Amazon OpenSearch Serverless の利点を得られます。これには、高度なクエリ機能とフィルタ、自動スケーリングと高可用性、管理の手間がかからないことが含まれます。エクスポートプロセスでは、スキーママッピング、ベクトルデータ転送、インデックス最適化、接続設定が自動的に処理されます。
次の図は、Amazon OpenSearch Service と S3 Vectors の間の 2 つの統合パターンを示しています。
前提条件
始める前に、次の項目について確認してください。
- AWS アカウント
- Amazon S3 と Amazon OpenSearch Service へのアクセス権
- OpenSearch Service ドメイン (1 番目の統合パターンの場合)
- S3 ベクトルに格納されたベクトルデータ (2 番目の統合パターンの場合)
統合パターン 1 : S3 Vectors を使用した OpenSearch Service マネージドクラスター
このパターンを実装するには:
- OpenSearch バージョン 2.19 で OR1 インスタンス を使用してOpenSearch Service ドメインを作成します。
- OpenSearch Service ドメインを作成する際、Advanced features セクションで Enable S3 Vectors as an engine option を選択します。
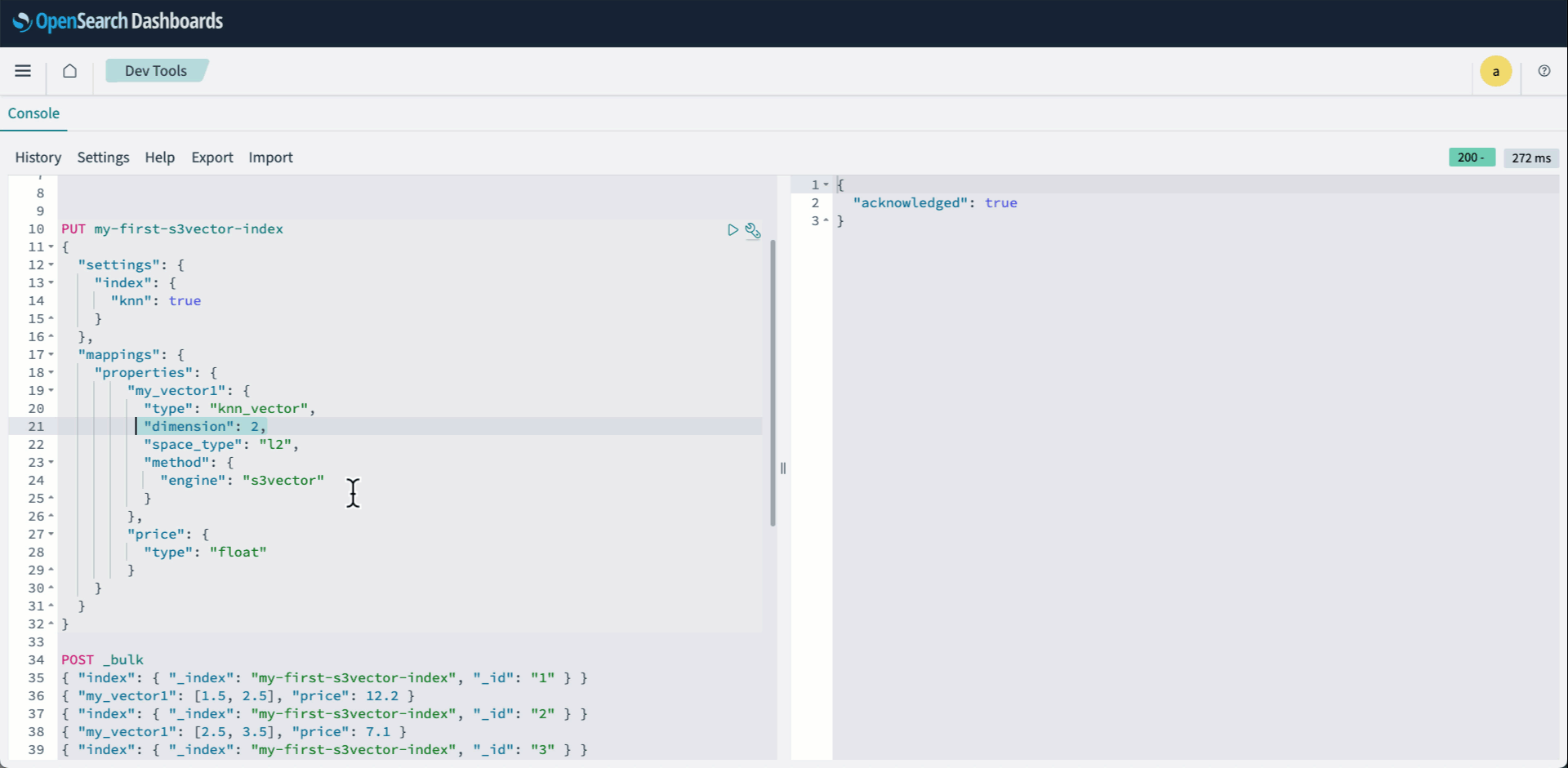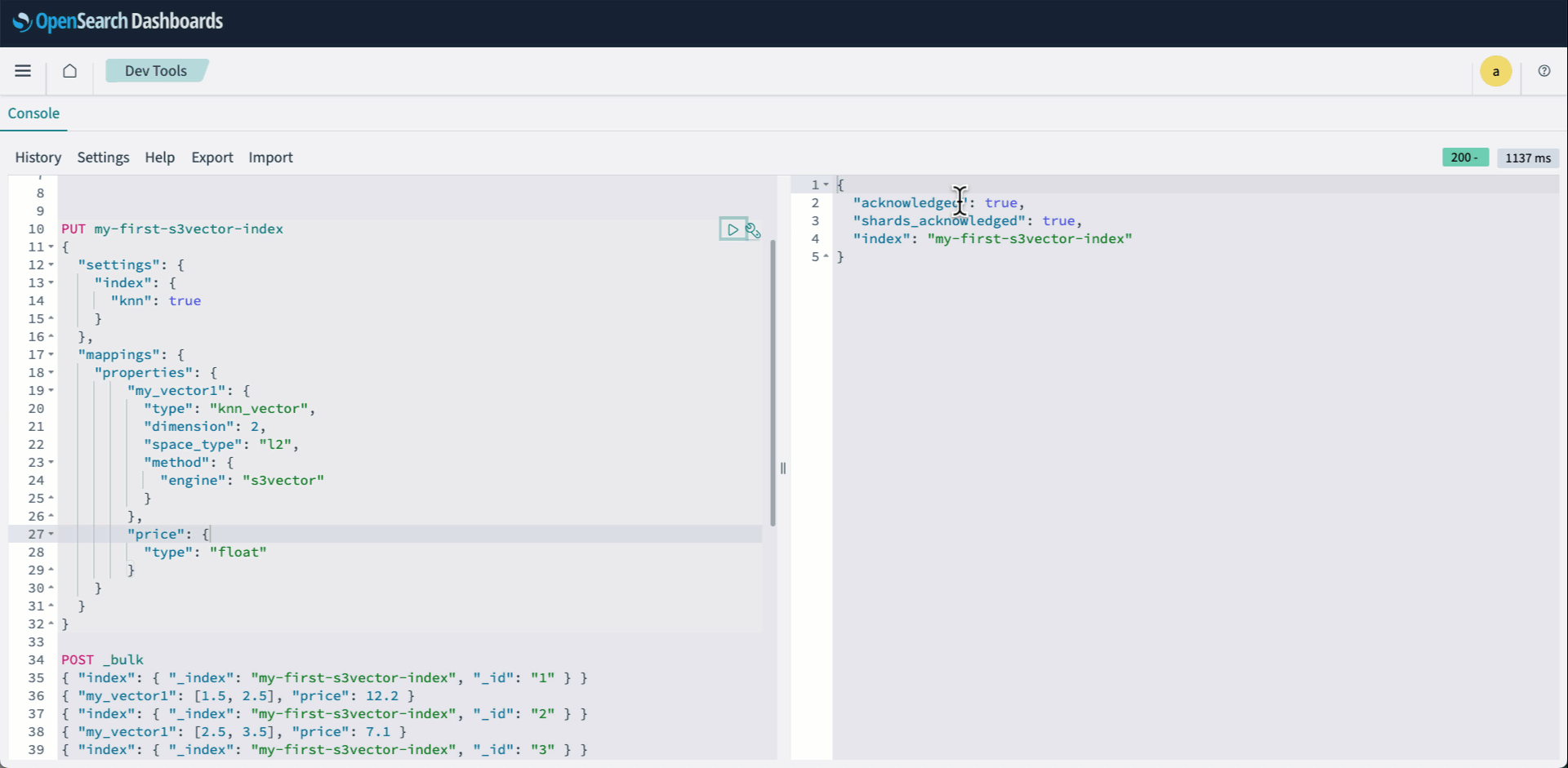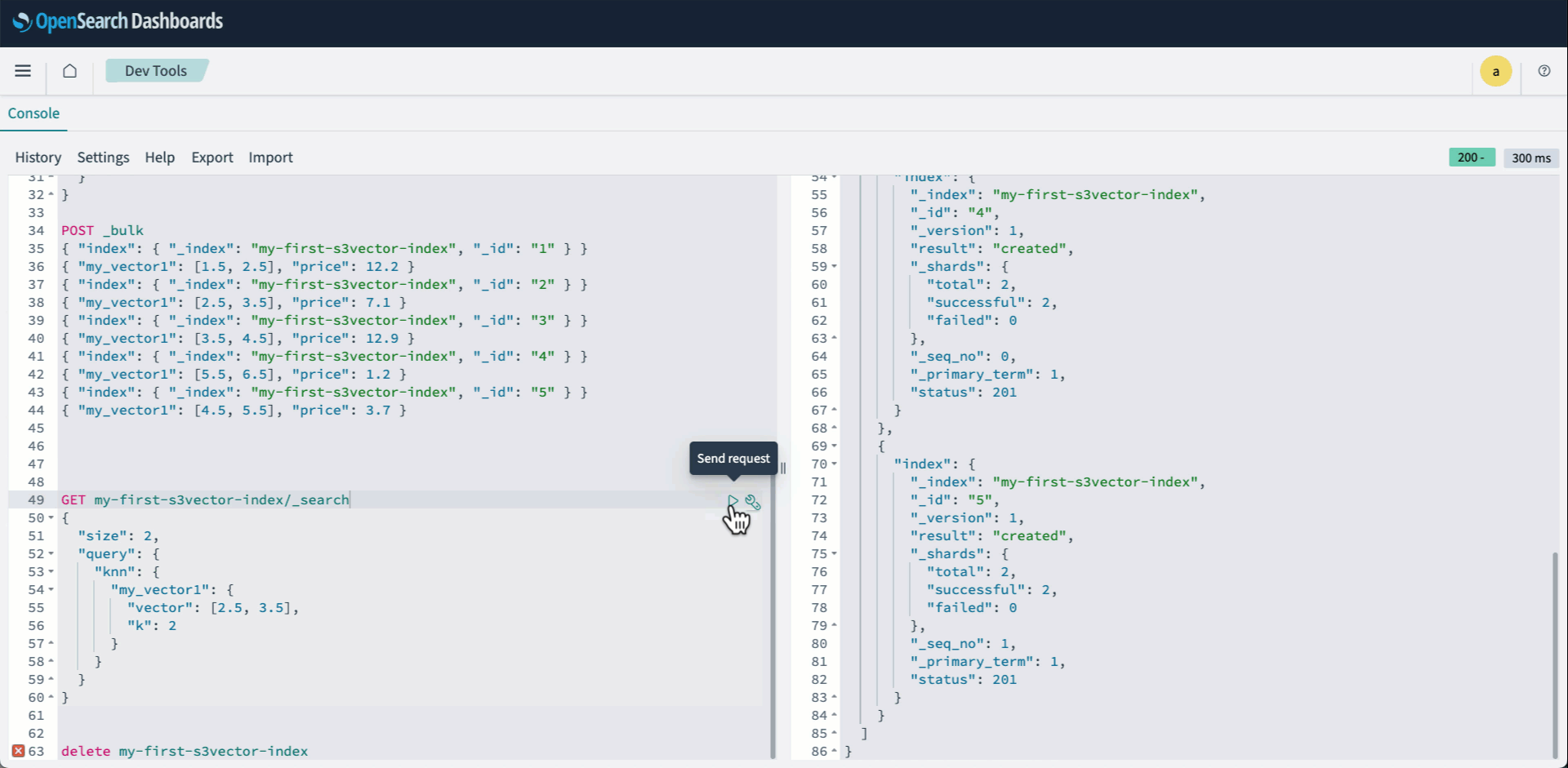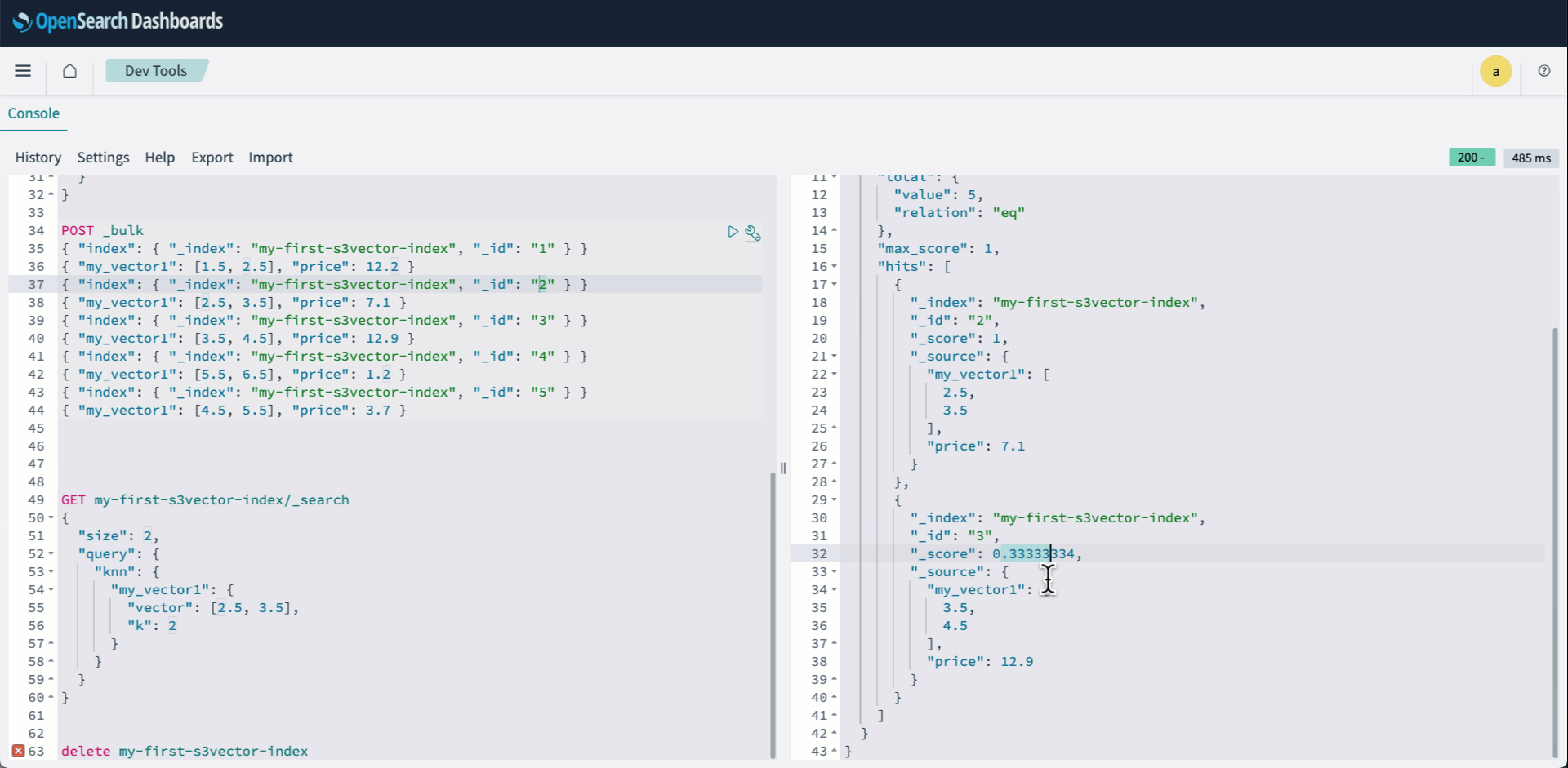
- OpenSearch Dashboards にサインインし、Dev tools を開きます。次に、knn インデックスを作成し、engine として s3vector を指定します。
- ベクトルを Bulk API を使ってインデクシングします:
- 通常どおり knn クエリを実行します:
次のアニメーションは、上記の手順 2 から 4 を示しています。
統合パターン 2 : S3 ベクトルインデックスを OpenSearch Serverless にエクスポート
このパターンを実装するには:
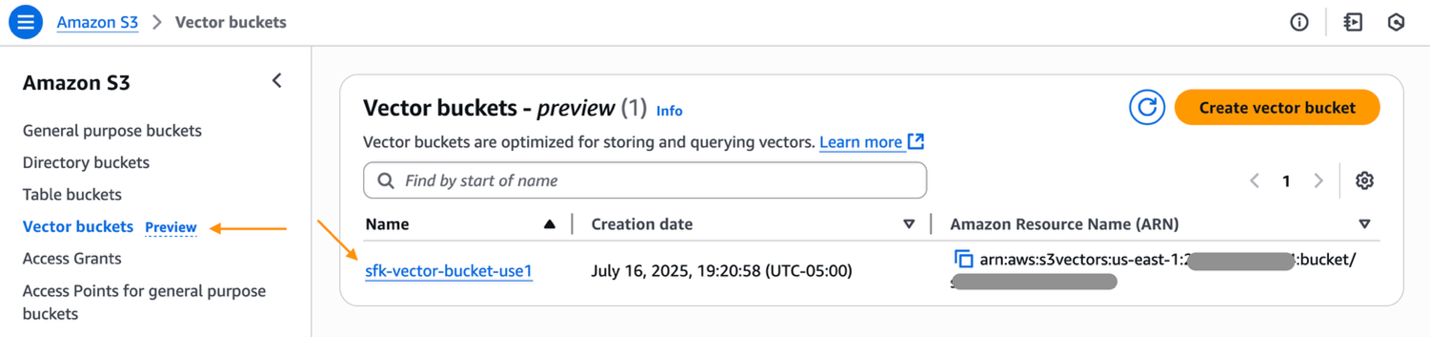
- Amazon S3 の AWS マネジメントコンソールに移動し、S3 Vector Bucket を選択します。
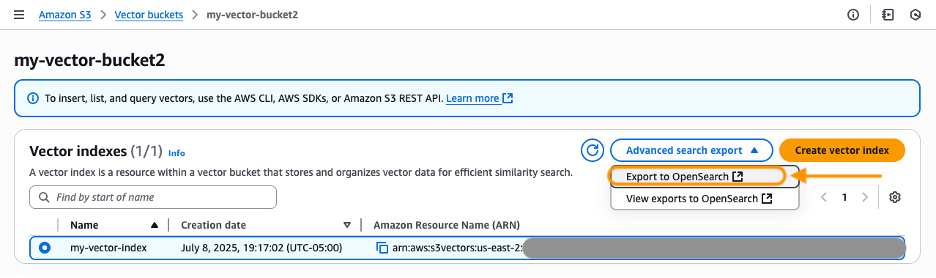
- エクスポートしたいベクトルインデックスを選択します。Advanced search export の下にある Export to OpenSearch を選択してください。
または、次のようにすることもできます。
- OpenSearch Service コンソールに移動します。
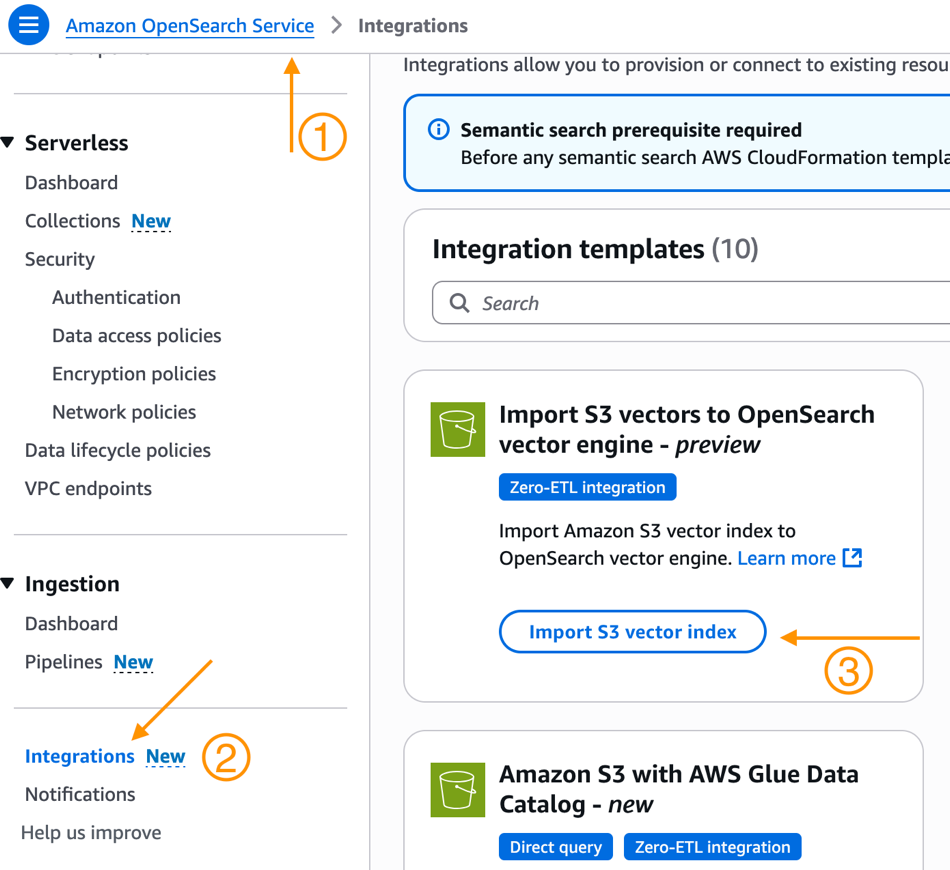
- ナビゲーションペインから Integrations を選択します。
- ここに Import S3 vectors to OpenSearch vector engine – preview という新しい統合テンプレートが表示されます。Import S3 vector index を選択してください。
- 次に、Export S3 vector index to OpenSearch vector engine テンプレートが事前に選択され、S3 ベクトルインデックスの Amazon リソースネーム (ARN) が事前に入力された Amazon OpenSearch Service 統合コンソールに移動します。必要な権限を持つ既存のロールを選択するか、新しいサービスロールを作成してください。
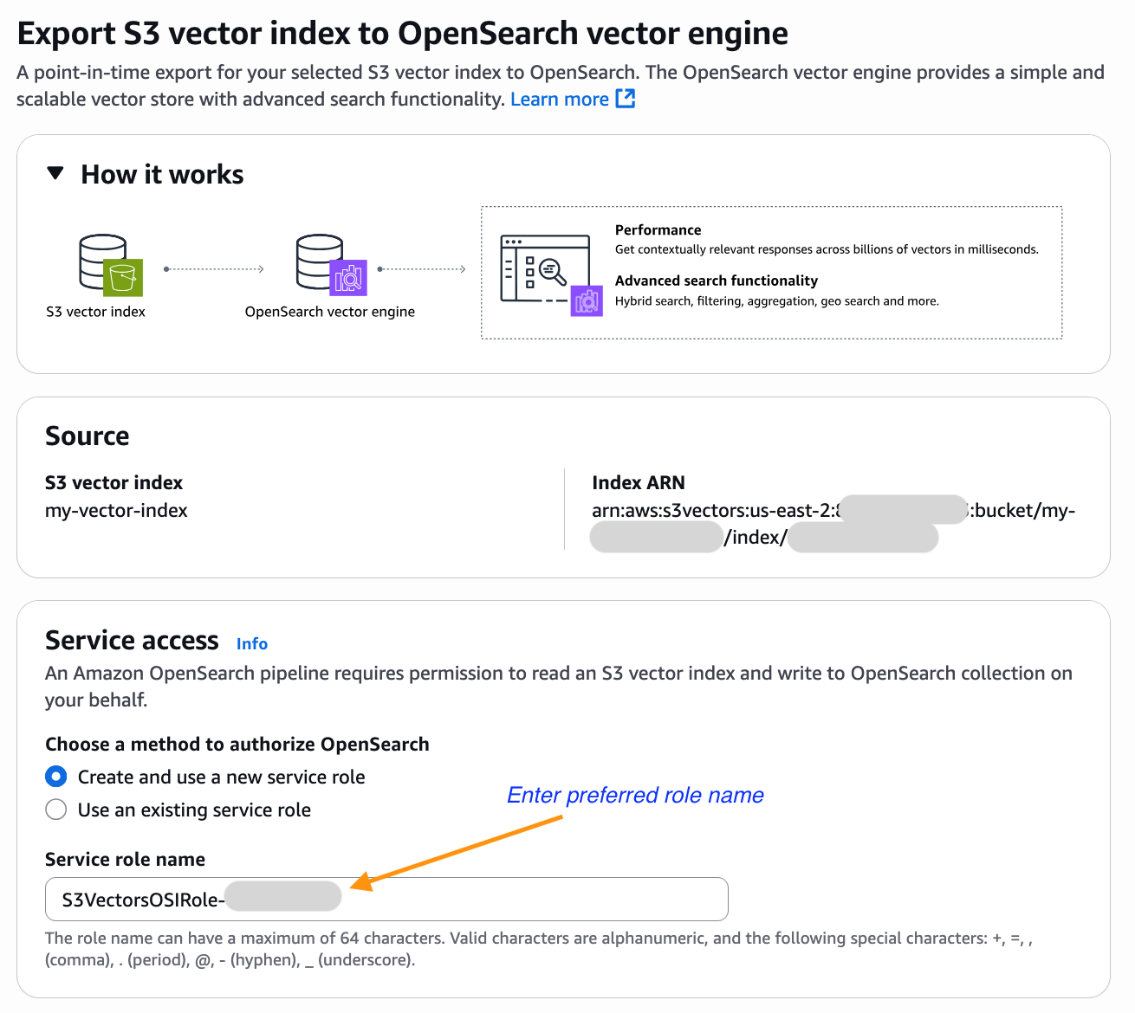
-
下にスクロールして Export を選択し、新しい OpenSearch Serverless コレクションを作成し、S3 ベクトルインデックスからデータを OpenSearch knn インデックスにコピーする手順を開始します。
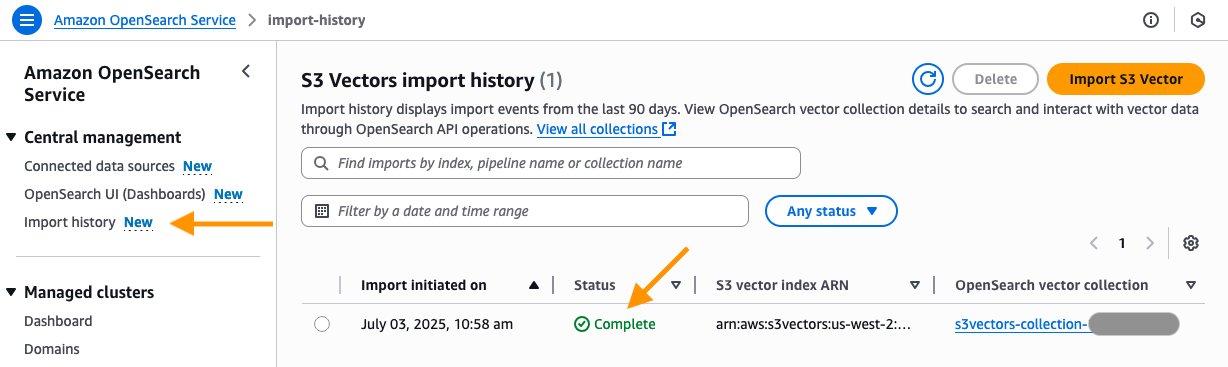
- OpenSearch Service コンソールの インポート履歴 ページに移動します。ここで、S3 ベクトルインデックスを OpenSearch サーバーレス knn インデックスに移行するために作成された新しいジョブが表示されます。ステータスが In Progress から Complete に変わったら、新しい OpenSearch サーバーレスコレクションに接続し、新しい OpenSearch knn インデックスをクエリできます。
次のアニメーションは、新しい OpenSearch サーバーレスコレクションに接続し、Dev ツールを使用して新しい OpenSearch knn インデックスをクエリする方法を示しています。
クリーンアップ
継続的な課金を避けるには:
- パターン 1 の場合:
- S3 Vectors を使用する OpenSearch インデックスを削除します。
- 不要になった場合は、OpenSearch Service マネージドクラスターを削除します。
- パターン 2 の場合:
- OpenSearch Service コンソールの Import history セクションからインポートタスクを削除します。このタスクを削除すると、インポートタスクによって自動的に作成された OpenSearch ベクトルコレクションと OpenSearch 取り込みパイプラインの両方が削除されます。
結論
Amazon S3 Vectors と Amazon OpenSearch Service の革新的な統合は、ベクトル検索技術の変革的な到達点を示し、企業に前例のない柔軟性とコスト効率を提供します。この強力な組み合わせは、それぞれのサービスの長所を兼ね備えています。Amazon S3 の高い耐久性とコスト効率が、OpenSearch の高度な AI 検索機能とシームレスに融合しています。企業は今や、ベクトル検索ソリューションを数十億ものベクトルまでスケールアップできるようになり、レイテンシー、コスト、精度を制御できるようになりました。OpenSearch Service を使って 10ms という極めて高速なクエリ性能を優先するか、S3 Vectors を使ってコスト最適化された秒未満の優れた性能を実現するか、OpenSearch で高度な検索機能を実装するかに応じて、この統合はお客様のニーズに合った完璧なソリューションを提供します。OpenSearch マネージドクラスターで S3 Vectors エンジンを試し、S3 ベクトルインデックスから OpenSearch Serverless への 1 クリックエクスポートをテストすることで、今すぐ始めることをお勧めします。
詳細については、以下をご覧ください。
- Amazon S3 Vectors のドキュメント
- Amazon OpenSearch Service のドキュメント
- OpenSearch Service と Amazon S3 Vectors の統合
- Amazon OpenSearch Service ベクトルデータベースのブログ
著者について
 Sohaib Katariwala は、シカゴに拠点を置く Amazon OpenSearch Service を専門とする AWS のシニアスペシャリストソリューションアーキテクトです。彼の関心は、データとアナリティクス全般にあります。特に、顧客が AI を活用してデータ戦略を立て、現代の課題を解決することを支援することに情熱を注いでいます。
Sohaib Katariwala は、シカゴに拠点を置く Amazon OpenSearch Service を専門とする AWS のシニアスペシャリストソリューションアーキテクトです。彼の関心は、データとアナリティクス全般にあります。特に、顧客が AI を活用してデータ戦略を立て、現代の課題を解決することを支援することに情熱を注いでいます。
 Mark Twomey は、ストレージとデータ管理に特化した AWS のシニアソリューションアーキテクトです。適切なタイミングで適切な場所に適切なコストでデータを配置できるよう、お客様と協力することを楽しんでいます。アイルランド在住の Mark は、田舎を散歩したり、映画を観たり、本を読むことが好きです。
Mark Twomey は、ストレージとデータ管理に特化した AWS のシニアソリューションアーキテクトです。適切なタイミングで適切な場所に適切なコストでデータを配置できるよう、お客様と協力することを楽しんでいます。アイルランド在住の Mark は、田舎を散歩したり、映画を観たり、本を読むことが好きです。
 Sorabh Hamirwasia は、OpenSearch プロジェクトで働く AWS のシニアソフトウェアエンジニアです。主な関心事は、コスト最適化された高性能な分散システムの構築です。
Sorabh Hamirwasia は、OpenSearch プロジェクトで働く AWS のシニアソフトウェアエンジニアです。主な関心事は、コスト最適化された高性能な分散システムの構築です。
 Pallavi Priyadarshini は、Amazon OpenSearch Service の Senior Engineering Manager で、検索、セキュリティ、リリース、ダッシュボードの高性能でスケーラブルなテクノロジーの開発を主導しています。
Pallavi Priyadarshini は、Amazon OpenSearch Service の Senior Engineering Manager で、検索、セキュリティ、リリース、ダッシュボードの高性能でスケーラブルなテクノロジーの開発を主導しています。
 Bobby Mohammed は、AWS の Principal Product Manager で、検索、GenAI、Agentic AI の製品イニシアチブを主導しています。以前は、SageMaker プラットフォームでのデータ、分析、ML 機能、Intel での深層学習トレーニングと推論製品など、機械学習のフルライフサイクルにわたる製品に携わっていました。
Bobby Mohammed は、AWS の Principal Product Manager で、検索、GenAI、Agentic AI の製品イニシアチブを主導しています。以前は、SageMaker プラットフォームでのデータ、分析、ML 機能、Intel での深層学習トレーニングと推論製品など、機械学習のフルライフサイクルにわたる製品に携わっていました。