Amazon Web Services ブログ
JWT を使用した Amazon Bedrock と Amazon OpenSearch Service による SaaS 向けマルチテナント RAG 実装
By Kazuki Nagasawa, Cloud Support Engineer – AWS Support Engineering
By Kensuke Fukumoto, Solutions Architect – AWS ISV/SaaS
近年、大規模言語モデル(LLM)の台頭により、様々な産業分野で AI の導入が加速しています。しかし、LLM の能力をさらに拡張し、最新の情報やドメイン固有の知識を効果的に活用するには、外部データソースとの統合が不可欠です。この課題に対する効果的なアプローチとして、Retrieval Augmented Generation(RAG)が注目を集めています。
RAG は、ユーザーの入力に基づいて既存の知識ベースや文書から関連情報を検索し、この情報を LLM の入力に組み込むことで、より正確で文脈に適した応答を生成する手法です。この技術は、製品開発における技術文書の活用から、カスタマーサポートでの FAQ 応答、さらには最新データに基づく意思決定支援システムまで、幅広いアプリケーションで実装されています。
RAG の実装は、Software as a Service(SaaS)プロバイダーとその利用者(テナント)の両方に大きな価値をもたらします。
SaaS プロバイダーは、単一のコードベースから複数のテナントにサービスを提供するためにマルチテナントアーキテクチャーを使用できます。テナントがサービスを利用するにつれて、適切なアクセス制御とデータ分離によって保護されながら、データが蓄積されていきます。このような環境で LLM を使用した AI 機能を実装する際、RAG により各テナントの固有データを使用してパーソナライズされた AI サービスを提供することが可能になります。
カスタマーサービスコールセンター SaaS を例に考えてみましょう。各テナントの過去の問い合わせ記録、FAQ、製品マニュアルは、テナント固有の知識ベースとして蓄積されます。RAG システムを実装することで、LLM はこれらのテナント固有のデータソースを参照して、各テナントのコンテキストに関連する適切な応答を生成できます。これにより、汎用的な AI アシスタントでは不可能な、テナント固有のビジネス知識を組み込んだ高精度なインタラクションが可能になります。RAG は、SaaS におけるパーソナライズされた AI 体験を提供する重要なコンポーネントとして、サービスの差別化と価値向上に貢献します。
しかし、RAG を通じてテナント固有のデータを使用する場合、セキュリティとプライバシーの観点で技術的な課題があります。主な懸念は、テナント間のデータ分離を維持し、意図しないデータ漏洩やクロステナントアクセスを防ぐセキュアなアーキテクチャの実装です。マルチテナント環境では、データセキュリティの実装が SaaS プロバイダーの信頼性と競争優位性に重大な影響を与えます。
Amazon Bedrock Knowledge Bases により、より簡単に RAG を実装できます。ベクトルデータベースとして OpenSearch を使用する場合、Amazon OpenSearch Service または Amazon OpenSearch Serverless の 2 つの選択肢があります。マルチテナント環境を構築する際、各選択肢には異なる特徴と権限モデルがあります:
- Amazon OpenSearch Serverless:
- メタデータフィルタリングにより、ベクトルデータベースからの検索結果をテナント別にフィルタリングできます(詳細はMulti-tenant RAG with Amazon Bedrock Knowledge Basesを参照)
- この権限モデルでは、データの作成や更新などの書き込み操作に対する権限を分離できません
- Amazon OpenSearch Service:
- Fine-grained access control(FGAC)が利用可能です
- ナレッジベースにアタッチされた単一の AWS Identity and Access Management(IAM)ロールを通じたアクセスとなるため、権限分離に FGAC を使用することが困難です
この記事では、JSON Web Token(JWT)と FGAC の組み合わせ、およびテナントリソースルーティングを使用したテナント分離パターンを紹介します。前述の権限モデルの制限により FGAC の目標を達成できない場合は、この記事のソリューションを使用できます。このソリューションは、ベクトルデータベースとして OpenSearch Service、オーケストレーションレイヤーとして AWS Lambda を使用して実装されています。
次のセクションでは、OpenSearch Service における JWT と FGAC を使用したテナント分離の具体的な実装と、これによってセキュアなマルチテナント RAG 環境がどのように実現されるかを探ります。
OpenSearch Service におけるマルチテナントデータ分離での JWT の有効性
Amazon OpenSearch Service にマルチテナント SaaS のデータを格納する で紹介されているように、OpenSearch Service では、マルチテナントデータを管理する分離レベルとして、ドメインレベルの分離、インデックスレベルの分離、ドキュメントレベルの分離と複数の方法があります。
インデックスレベルとドキュメントレベルでのアクセス権限分離を実装するには、OpenSearch Security プラグインでサポートされている FGAC を使用できます。
OpenSearch Service では、IAM アイデンティティを OpenSearch ロールにマッピングすることで、きめ細かなアクセス制御を実現できます。これにより、各 IAM アイデンティティに対して OpenSearch での詳細な権限設定が可能になります。しかし、このアプローチには重大なスケーラビリティの課題があります。テナント数の増加に伴い、必要な IAM ユーザーやロールの数も増加し、AWS サービスクォータの制限に達する可能性があります。また、多数の IAM エンティティの管理は運用の複雑さを招きます。動的に生成される IAM ポリシーでこの課題自体は克服できる可能性がありますが、動的に生成された各ポリシーは単一の IAM ロールにアタッチされます。単一の IAM ロールは単一の OpenSearch ロールにマッピングできますが、適切な分離のためにはテナントごとに IAM ロールと動的ポリシーが必要となり、多数のエンティティを管理する同様の運用上の複雑さが生じます。
この記事では代替アプローチを提供し、マルチテナント環境でのデータ分離とアクセス制御を実装するための自己完結型トークンである JWT の有効性に焦点を当てます。JWT を使用することで、以下の利点が得られます:
- 動的なテナント識別 – JWT ペイロードには、テナントを識別するための属性情報(テナントコンテキスト)を含めることができます。これにより、システムはリクエストごとにテナントを動的に識別し、このコンテキストを後続のリソースやサービスに渡すことができます。
- OpenSearch における FGAC との統合 – FGAC は、JWT 内の属性情報を直接使用してロールマッピングを行うことができます。これにより、JWT 内のテナント ID などの情報に基づいて、特定のインデックスやドキュメントへのアクセス権限をマッピングできます。
JWT と FGAC を組み合わせることで、OpenSearch Service を使用したマルチテナント RAG 環境において、セキュアで柔軟かつスケーラブルなデータ分離とアクセス制御が実現されます。次のセクションでは、この概念を実際のシステムに適用するための具体的な実装詳細と技術的考慮事項を探ります。
ソリューション概要
RAG では、LLM の出力を拡張するために使用される関連文書などのデータは、埋め込み言語モデルによってベクトル化され、ベクトルデータベースにインデックスされます。自然言語でのユーザーの質問は、埋め込みモデルを使用してベクトルに変換され、ベクトルデータベースで検索されます。ベクトル検索によって取得されたデータは、出力を拡張するためのコンテキストとして LLM に渡されます。以下の図は、ソリューションアーキテクチャを示しています。
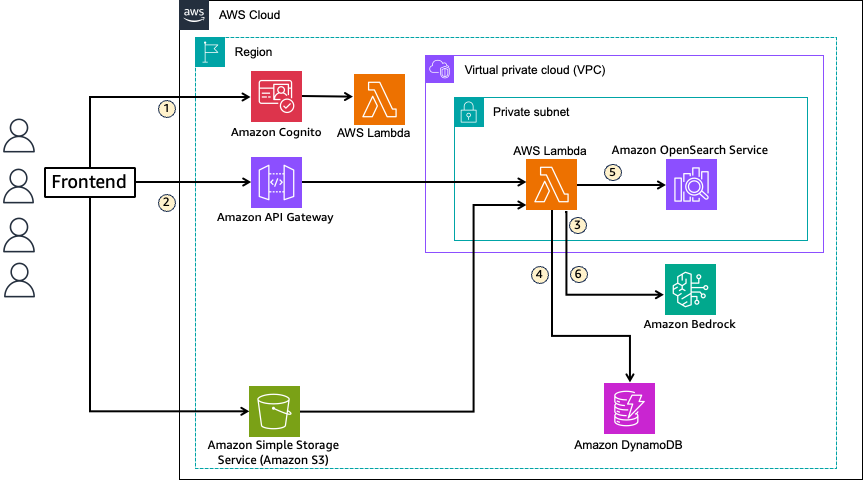
このソリューションでは、RAG におけるナレッジソースを格納するベクトルデータストアとして OpenSearch Service を使用します。フローは以下の通りです:
- 各テナントの RAG アプリケーションユーザーは、Amazon Cognito ユーザープールのユーザーとして作成され、フロントエンドへのログイン時にテナント ID 情報でエンリッチされた JWT を受け取ります。各ユーザーのテナント情報は Amazon DynamoDB に格納されており、ユーザー認証時にトークン生成前 Lambda トリガーによって JWT に追加されます。
- ユーザーがフロントエンドでチャットを開始すると、ユーザークエリは JWT とともに Amazon API Gateway を通じて Lambda 関数に渡されます。
- ユーザークエリは、Amazon Bedrock で利用可能なテキスト埋め込みモデルと連携してベクトル化されます。
- 検索用のドメインとインデックス情報を DynamoDB から取得します。
- OpenSearch Service でベクトル検索を実行し、インデックスからクエリに関連する情報を取得します。
- 取得された情報をコンテキストとしてプロンプトに追加し、Amazon Bedrock で利用可能な LLM に渡して応答を生成します。
このソリューションで注目すべき点は、OpenSearch Service でのテナントデータ分離と各テナントのデータへのルーティングに JWT を使用することです。OpenSearch Service で利用可能な FGAC を使用して各データセットへのアクセス権限を分離し、JWT に追加されたテナント ID 情報を使用してアプリケーションユーザーと分離された権限セットをマッピングします。このソリューションでは、お客様の要件に合わせて、データ分離の粒度に対して 3 つの異なるパターンを提供しています。また、JWT からのテナント ID 情報とデータの場所(ドメイン、インデックス)のマッピングを DynamoDB で定義することで、ルーティングも可能になります。
ユーザーがドキュメントを追加する際は、ファイルを Amazon Simple Storage Service(Amazon S3)にアップロードし、メタデータを DynamoDB 上の管理テーブルに書き込みます。OpenSearch Service にデータを格納する際は、ベクトル化のために Ingest pipelines でテキスト埋め込みモデル(Amazon Bedrock)が呼び出されます。ドキュメントの作成、更新、削除では、リクエストに JWT が付与されているため、テナントの識別が可能です。
このソリューションは、AWS Cloud Development Kit(AWS CDK)を使用して実装されています。詳細については、GitHub リポジトリを参照してください。ソリューションのデプロイ手順は、リポジトリの README ファイルに含まれています。
前提条件
このソリューションを試すには、以下の前提条件が必要です:
- AWS アカウント
- AWS CDK の実行に必要な IAM アクセス権限
- フロントエンド実行環境:node.js と npm のインストールが必要
- AWS CDK が設定済みである必要があります。詳細については、チュートリアル: 最初の AWS CDK アプリを作成する を参照してください
- Amazon Bedrock で使用するモデルへのアクセスが設定されている必要があります。このソリューションでは、Anthropic の Claude 3.5 Sonnet v2 と Amazon Titan Text Embedding V2 を使用します。詳細については、Add or remove access to Amazon Bedrock foundation models を参照してください
アーキテクチャ図に示されているリソースに加えて、AWS CDK デプロイにより以下のリソースと設定が AWS CloudFormation カスタムリソースとして作成されます:
- Amazon Cognito ユーザープール:
- tenant-a、tenant-b、tenant-c、tenant-d のユーザー
- DynamoDB テーブル:
- ユーザーとテナントのマッピング
- テナントと OpenSearch 接続先およびインデックスのマッピング
- OpenSearch Service ドメイン:
- JWT 認証設定
- ベクトル埋め込み用 Ingest pipelines
- 各テナント用 FGAC ロールとロールマッピング
- k-NN インデックス
Amazon Cognito によるユーザー認証と JWT 生成
このソリューションでは、RAG アプリケーションのユーザー認証に Amazon Cognito ユーザープールを使用します。Amazon Cognito ユーザープールは認証時に JWT を発行します。OpenSearch Service の FGAC では JWT 認証がサポートされているため、ユーザープールから発行されるパブリックキーを OpenSearch Service ドメインに登録することで、Amazon Cognito ユーザープールで認証されたユーザーからのアクセスを許可できます。また、FGAC によるテナントデータアクセス権限分離では、JWT ペイロードに追加できる属性を使用した認可が実行されます。これを実現するため、Amazon Cognito ユーザープールにトークン生成前 Lambda トリガーを設定し、DynamoDB に格納された各ユーザーのテナント ID 情報を取得してトークンに追加します。取得された JWT はフロントエンドで保持され、バックエンドへのリクエストに使用されます。DynamoDB には、ユーザー ID(sub)とテナント ID のマッピングが以下のように格納されています:
Amazon Cognito でマルチテナント認証を実装するパターンは複数存在しますが、この実装では DynamoDB でのユーザー-テナントマッピングを持つ単一ユーザープールを使用しています。本番環境では追加の考慮事項が必要です。詳細については、マルチテナントアプリケーションのベストプラクティス を参照してください。
JWT を使用したテナントデータへのリクエストルーティング
テナントごとにリソースが分離されるマルチテナントアーキテクチャでは、テナントからのリクエストを適切なリソースにルーティングすることが不可欠です。テナントルーティング戦略の詳細については、AWS における SaaS アプリケーションのテナントルーティング戦略 を参照してください。このソリューションでは、OpenSearch Service へのルーティングに、この記事で説明されているデータドリブンルーティングに類似したアプローチを使用します。
DynamoDB テーブルには、テナント ID、対象 OpenSearch Service ドメイン、インデックスのマッピング情報が以下のように格納されています:
フロントエンドから API Gateway を通じて Lambda 関数に送信される HTTP リクエストの Authorization ヘッダーから JWT を取得します。JWT を解析して取得されるテナント ID を使用してルーティング情報を取得し、ルーティング先を決定します。また、JWT は次のセクションで説明するように、OpenSearch へのリクエストの認証情報としても使用されます。
OpenSearch Service におけるマルチテナントデータ位置とアクセス権限の分離
OpenSearch Service におけるマルチテナントデータ分離戦略には、ドメインレベル、インデックスレベル、ドキュメントレベルの分離という 3 種類の分離パターンと、これらを組み合わせたハイブリッドモデルがあります。このソリューションでは、テナントデータへのアクセス権限制御に FGAC を使用し、テナントごとに専用のロールを作成します。
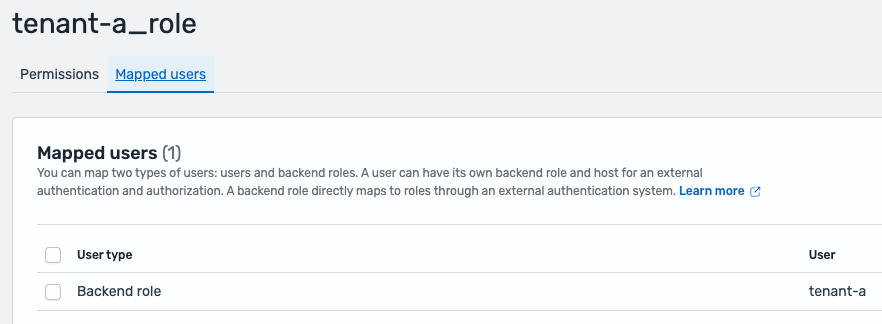
テナントユーザーと FGAC テナントロールのマッピングは、バックエンドロールを通じて実装されます。OpenSearch Service で利用可能な JWT 認証では、JWT ペイロード内でバックエンドロールとリンクする属性を Roles key として指定できます。以下のスクリーンショットは、このドメイン設定を示しています。

JWT ペイロードには、以下のように tenant_id 属性が含まれています:
"tenant_id": "tenant-a"
この属性を OpenSearch JWT 認証の Roles key として設定し、以下のようにロールをマッピングすることで、テナントユーザーと FGAC ロールがリンクされます:
以下のスクリーンショットは、OpenSearch Dashboards での FGAC におけるテナントロールマッピングの例を示しています。
このソリューションのサンプルでは、tenant-a、tenant-b、tenant-c、tenant-d の 4 つのテナントを提供し、3 つの分離方法すべてを試すことができます。以下の図は、このアーキテクチャを示しています。
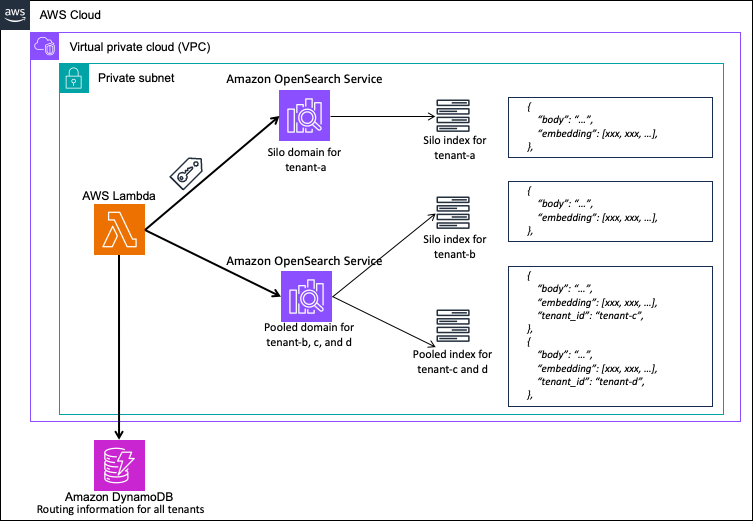
各ロールには、対応するテナントデータのみにアクセスできる権限が割り当てられます。このセクションでは、JWT と FGAC を使用して 3 つの分離方法それぞれを実装する方法を紹介します:
- ドメインレベルの分離 – 各テナントに個別の OpenSearch Service ドメインを割り当てます。この分離パターンではドメインが各テナント専用であるため、ドメイン内でのデータ分離は必要ありません。そのため、FGAC ロールはインデックス全体へのアクセス権限を付与します。以下のコードは、インデックスへのアクセス権限を付与する FGAC ロール定義の index_permissions の一部です:
- インデックスレベルの分離 – 複数のテナントが OpenSearch Service ドメインを共有し、各テナントに個別のインデックスを割り当てます。各テナントは自分のインデックスのみにアクセスできる必要があるため、FGAC ロールの index_permissions は以下のように設定されます(tenant-b の例):
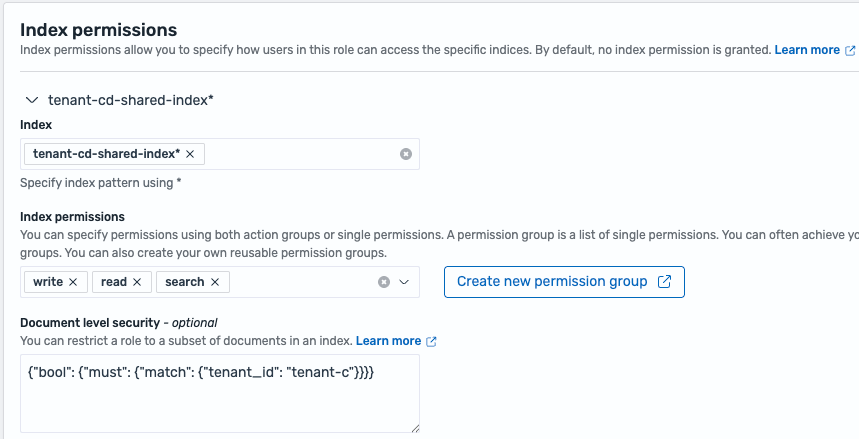
- ドキュメントレベルの分離 – 複数のテナントが OpenSearch Service ドメインとインデックスを共有し、インデックス内のテナントデータのアクセス権限分離に FGAC のドキュメントレベルセキュリティを使用します。各インデックスにはテナント ID 情報を格納するフィールドが含まれ、そのフィールドに対してドキュメントレベルセキュリティクエリが設定されます。以下のコードは、tenant-c と tenant-d がインデックスを共有する構成で、tenant-c が自分のデータのみにアクセスできる FGAC ロールの index_permissions の一部です:
以下のスクリーンショットは、FGAC ロールにおけるドキュメントレベル分離のためのインデックス権限の例を示しています。
考慮事項
この記事の実装では、DynamoDB テーブルと S3 バケットをテナント間で共有するモデルを使用しています。本番環境での使用では、Partitioning Pooled Multi-Tenant SaaS Data with Amazon DynamoDB と Partitioning and Isolating Multi-Tenant SaaS Data with Amazon S3 で紹介されているパーティショニングモデルを検討し、要件に基づいて最適なモデルを決定してください。
また、各リソースへのアクセス権限を制限する追加のレイヤーとして、IAM ポリシーの動的生成を使用できます。
クリーンアップ
予期しない料金を避けるため、リソースが不要になった場合は削除することをお勧めします。リソースは AWS CDK で作成されているため、cdk destroy コマンドを実行して削除します。この操作により、Amazon S3 にアップロードされたドキュメントも削除されます。
結論
この記事では、マルチテナント RAG において OpenSearch Service をベクトルデータストアとして使用し、JWT と FGAC を使用してデータ分離とルーティングを実現するソリューションを紹介しました。
このソリューションでは、JWT と FGAC の組み合わせを使用して厳密なテナントデータアクセス分離とルーティングを実装するため、OpenSearch Service の使用が必要です。執筆時点では、Amazon Bedrock Knowledge Bases は OpenSearch Service への JWT ベースのアクセスを使用できないため、RAG アプリケーションは独立して実装されています。
マルチテナント RAG の使用は SaaS 企業にとって重要であり、データ分離の厳密さ、管理の容易さ、コストなどの要件によって戦略は異なります。このソリューションでは複数の分離モデルを実装しているため、要件に基づいて選択できます。
マルチテナント RAG 実装に関するその他のソリューションや情報については、以下のリソースを参照してください:
- Multi-tenant RAG with Amazon Bedrock Knowledge Bases
- Build a multi-tenant generative AI environment for your enterprise on AWS
- Self-managed multi-tenant vector search with Amazon Aurora PostgreSQL
- Multi-tenant vector search with Amazon Aurora PostgreSQL and Amazon Bedrock Knowledge Bases
翻訳はソリューションアーキテクトの福本が担当しました。原文はこちらです。
著者について
 |
Kazuki Nagasawa は、Amazon Web Services のクラウドサポートエンジニアです。Amazon OpenSearch Service を専門とし、お客様の技術的な課題解決に注力しています。プライベートでは、様々な種類のウイスキーを探求したり、新しいラーメン店を発見したりすることを楽しんでいます。 |
 |
Kensuke Fukumoto は、Amazon Web Services のシニアソリューションアーキテクトです。ISV や SaaS プロバイダーのアプリケーションモダナイゼーションと SaaS モデルへの移行支援に情熱を注いでいます。プライベートでは、バイクに乗ることやサウナに行くことを楽しんでいます。 |