AWS for M&E Blog
Introducing: Guidance for a media lake on AWS
Many companies struggle to manage their vast collections of digital media files stored across multiple Amazon Simple Storage Service (Amazon S3) buckets. This scattered storage approach can create significant challenges for organizations. Searching for specific content can be difficult and time-consuming (with organizing files effectively becoming a complex task) making extracting the full value from existing content challenging.
Media teams often resort to manually searching through various storage locations, relying solely on file names to identify assets. This inefficient process slows down production workflows and hinders the ability to reuse valuable content effectively.
Our Guidance for a media lake on Amazon Web Services (AWS) shows you how to create a centralized system for searching and managing media assets stored on AWS. It offers a user-friendly interface and API for searching and managing your media files, while allowing you to create a unified catalog of all your media assets—even stored across multiple S3 buckets. More importantly, you can achieve this organization without changing your existing storage setup. Our guidance uses automated workflows (also called pipelines) to catalog and process your media files, making them quicker to find and use.
We will show you how a media lake can help you get more value from your digital content by creating a searchable, expandable media storage system that works seamlessly with AWS services and partner solutions. We’ll explain the system’s design, show you different ways to set it up, and demonstrate how to turn your scattered media files into an organized, searchable collection.
Overview
Our Guidance for a media lake on AWS provides a reference architecture and sample code you can deploy to create a media management system. The solution demonstrates how to:
- Create a unified search interface that lets you find media files across all your Amazon S3 storage locations at once.
- Build event-driven automated media workflows by utilizing default and customizable pipelines in a drag-and-drop interface.
- Enable natural language search capabilities through AI-powered integrations.
- Organize your media files by finding them quickly, previewing their content, and viewing their technical details and descriptions.
Deployment
The media lake uses AWS Cloud Development Kit (AWS CDK) for Infrastructure as Code (IaC). You can set up the sample code using either of these three methods:
- AWS CloudFormation template: Use the provided AWS CloudFormation template to automatically create an AWS CodePipeline. This pipeline will use AWS CodeBuild to deploy the AWS CDK application in your chosen AWS account and Region.
- Local environment deployment: Deploy a media lake directly from your computer using standard AWS CDK deployment methods. This option gives you more flexibility—allowing you to change the media lake deployment configuration, and the AWS profile used to deploy before deploying to various AWS Regions as needed.
- Continuous integration and deployment (CI/CD) pipelines: If you have an existing CI/CD pipeline that deploys AWS CDK code you can integrate media lake into that pipeline, allowing you to deploy with your existing CI/CD pipeline.
Regardless of which method you choose, all three approaches will set up the same AWS resources. This flexibility allows you to select the deployment method that works best with your organization’s existing processes and preferences.
Architecture overview
The guidance provides a user interface and RESTful API that leverages serverless architecture for scalability and security. Amazon CloudFront serves the static user interface content from Amazon S3, while AWS WAF provides protection against common web exploits. Amazon API Gateway handles requests, while Amazon Cognito implements user authentication against the API and generates secure web tokens for accessing the API resources.
The media lake stores backend data in Amazon DynamoDB and Amazon OpenSearch Service. Media assets, logs, and IaC are stored on Amazon S3. It manages its workflows using AWS Step Functions, which coordinates the process, while AWS Lambda functions handle the actual work of accessing and managing data in the storage systems.
For media workflow orchestration, used to interact with the backend data stores and storage, review the reference architecture for a media lake.
Getting started
When you deploy our guidance, the system will automatically create an administrator account. An invitation email will be sent to the address you provided during setup. Upon your first login, you’ll need to make an important decision about how you want to search for your media assets.
You have two main options:
- Traditional metadata search: This method relies on keywords generated by AI, technical metadata, or file information to find media assets. It’s more similar to traditional file search systems.
- Semantic search: This advanced feature allows you to use natural language queries to find media. For example, you could type “find images of red cars racing” or “show me video of coastlines at sunset”. This method goes beyond simple keyword matching—understanding the meaning behind your search.
It’s crucial to decide on your search method and configure your settings before you start importing media into your media lake. This confirms that all your assets are properly indexed from the beginning, making them quicker to find later.
If you enable semantic search, metadata search will still be available, and you can switch between traditional and semantic search. Figure 1 is an example of semantic search showing a search for “mountains with snow on them that have a purple background”.
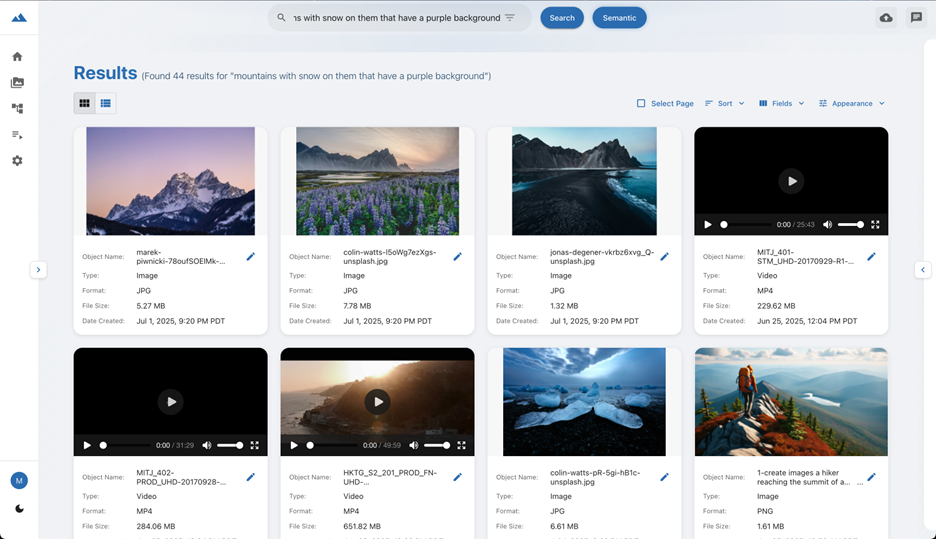
Figure 1: Semantic search example.
Currently, to enable semantic search, our guidance uses TwelveLabs’ Marengo embeddings model for AI-powered video understanding with OpenSearch Service as your vector database. Select the TwelveLabs API as your embedding provider and OpenSearch Service as your embedding store in the system settings. Configure your TwelveLabs integration and import the pre-configured TwelveLabs audio, image, and video pipelines. Once configured, your pipelines will automatically generate embeddings for all incoming supported media, enabling semantic search.
Storage connectors
Our guidance uses storage connectors to link your existing S3 buckets to the system. These connectors serve two important purposes. First, they automatically process any new media files added to your S3 buckets and second, they sync any existing media files already in your S3 buckets with your media lake. This creates a single, unified view of all your media files across different storage locations.
When you add a storage connector, our guidance begins a series of steps to integrate your content:
- It enables Amazon EventBridge notifications on the target S3 bucket, if not already enabled.
- It creates an EventBridge rule that routes Amazon S3 events to an Amazon Simple Queue Service (Amazon SQS) queue for reliable event processing.
- When deployed, it saves the Amazon S3 ingest Lambda function to the IaC S3 bucket. This Lambda function processes queued events to index new assets automatically.
- Once the Lambda function processes the media asset, an event is sent to the media lake analysis event bus for additional analysis and transformation of the media asset.
Our guidance currently requires that storage connectors reside in the same AWS Region and account as the media lake itself. When you put new supported media into the S3 bucket after creating a storage connector, the guidance automatically discovers, indexes, and makes the media searchable.
Media lake integrations
Media lake integrations provide secure credential management used by pipelines to access external services in your media workflows. By decoupling credentials from the pipeline configurations, you can rotate API keys and manage access independently without modifying your workflows. This provides you the ability to update a credential in one place, and the change will automatically apply to all pipelines using that credential. Use the media lake interface to create, edit, and update integrations for external services.
Our guidance uses AWS Secrets Manager to securely store all credentials. When you create a pipeline, it stores necessary credentials as environment variables using Secrets Manager ARNs (Amazon resource names). During pipeline execution, each step that needs to access an external service retrieves its specific credential from Secrets Manager using the stored ARN. This approach offers two key benefits: it follows AWS security best practices for managing third-party API keys and provides centralized control over credentials across all your media workflows. This method verifies secure and efficient credential management throughout your media processing operations.
Media lake pipelines
Our guidance streamlines the creation of media workflows on AWS through its pipeline feature. During deployment, the guidance reads configuration files from its repository to determine which nodes to create and set up. These nodes then appear in a drag-and-drop interface, providing a visual design of your workflow.
Once you’ve arranged your workflow and save the pipeline, the guidance translates your design into an AWS Step Functions state machine. This state machine orchestrates your media workflow according to your specific configuration.
To manage the workflow’s execution, the guidance sets up three additional components: an Amazon EventBridge rule, an Amazon SQS queue, and an AWS Lambda function. The EventBridge rule sends events to the Amazon SQS queue. The Lambda function then processes these events from the queue and initiates the appropriate Step Function, starting your media workflow.
This system provides a user-friendly way to create complex media processing workflows while leveraging powerful AWS services behind the scenes.
The guidance deploys three default pipelines when it’s deployed: Default Video Pipeline, Default Audio Pipeline, and Default Image Pipeline. These pipelines are responsible for creating proxies, thumbnails, and extracting technical metadata from media assets that the storage connectors process. When new supported media files arrive in your connected S3 buckets, the default pipelines automatically start processing them. This confirms that all your media assets are handled consistently. Following is an image of the default video code in the drag-and-drop interface.
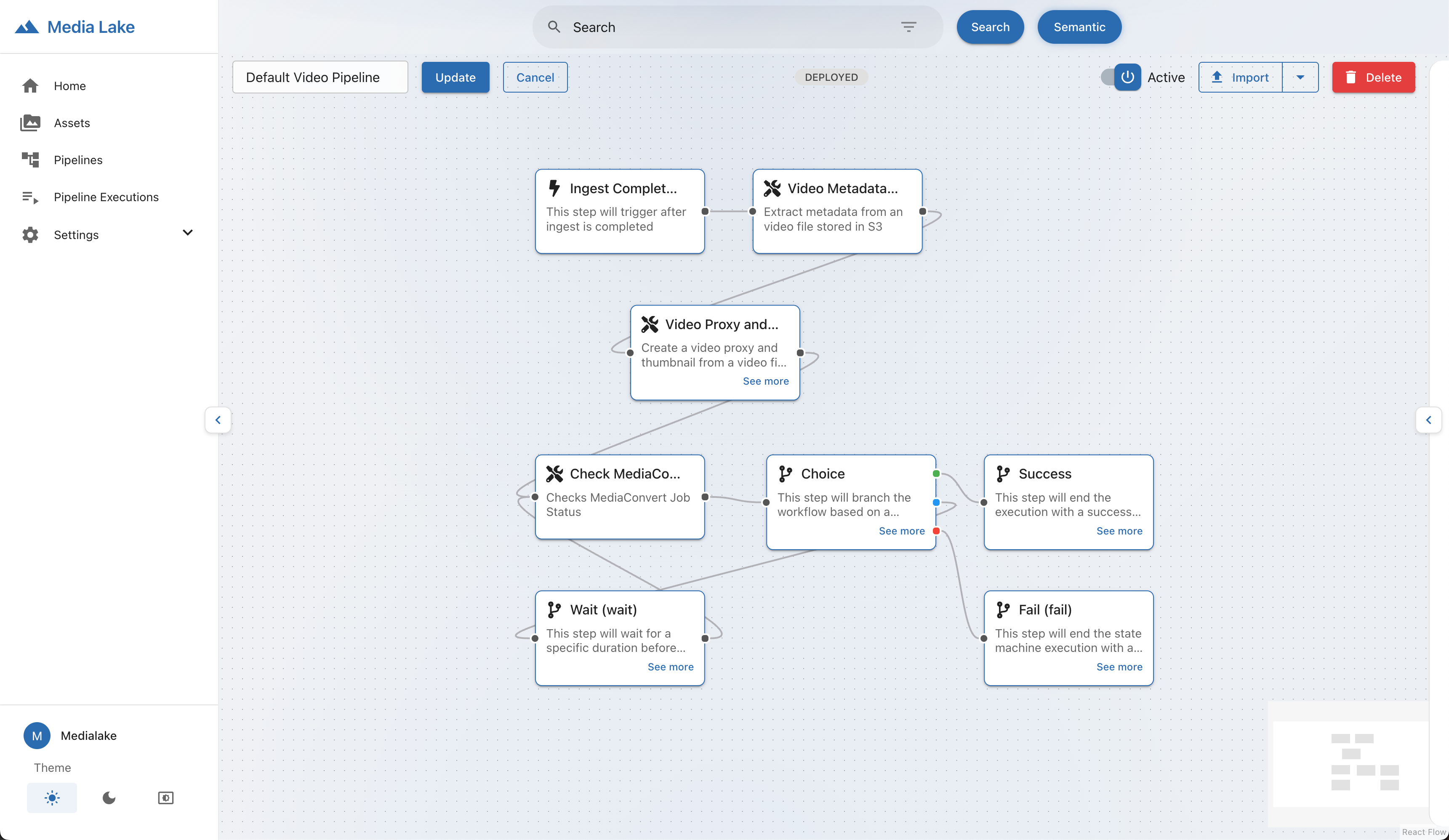
Figure 2: Media lake default pipeline.
The media lake supports importing pre-configured pipeline templates; the code repository includes sample templates that demonstrate common media processing patterns. When importing pipeline templates, it prompts you to map any required integrations, maintaining secure credential management across your workflows.
The guidance captures media asset metadata during pipeline executions to help you better understand and work with your media assets. It stores this metadata across two complementary AWS services: Amazon DynamoDB serves as the primary metadata store, while Amazon OpenSearch Service enables full-text search capabilities. As your pipelines process media assets, technical metadata is extracted—including resolution, bit depth, sample rates, codec information, bitrates, and duration. The media lake automatically stores this data in DynamoDB and indexes it in OpenSearch Service.
For audio and video content, AI-powered transcription services provide time-aligned text segments, making spoken content searchable and accessible. You can also configure and populate additional metadata fields for your organization to track, view, and use. This dual-storage approach enables lightning-fast search, understands asset quality and technical specifications, accesses AI-generated insights, and retrieves files in the appropriate format for your downstream workflows.
After a user searches for assets, users can navigate to the asset detail screen to view their media assets. For audio and video assets, the architecture uses Omakase Player, an open-source, web-based player designed for media supply chain use cases. Omakase Player delivers a frame-accurate viewing experience and allows time-based metadata to be accurately viewed in relation to a proxy.
When a user selects an asset, the guidance generates a secure, time-limited pre-signed Amazon S3 URL that grants access to a proxy stored in Amazon S3. The pre-signed URLs allow content to be streamed directly from Amazon S3 and expire after a specified time period, enabling access while maintaining security.
The asset detail page provides a detailed view of your media assets, combining media preview, download options, and detailed metadata. You can review proxy representations of your media for quick playback and viewing while maintaining access to both original master files and proxy versions for different workflow requirements.
Conclusion
Our Guidance for a media lake on AWS demonstrates how to build a media management solution on AWS that consolidates assets from multiple S3 buckets into a searchable catalog while creating media workflows. The guidance utilizes serverless services such as Amazon CloudFront, Amazon API Gateway, AWS Lambda, and Amazon DynamoDB to build a scalable media repository.
Key capabilities include the creation of visual media workflows (referred to as pipelines), the use AWS Step Functions for automated media processing. It also utilizes AWS Secrets Manager for secure credential management in third-party integrations. Users can find content in two ways: through traditional keyword searches using metadata, or through AI-powered semantic search that understands the meaning behind search phrases. Our guidance helps you to keep your current Amazon S3 storage, while incorporating centralized discovery, automated workflows, and professional media playback through frame-accurate proxy streaming.
By implementing the Guidance for a media lake on AWS patterns, you can transform fragmented media storage into an intelligent system that processes, indexes, and surfaces your content through a single interface. Your teams will be able to find, and use, media assets efficiently across your organization, regardless of storage location.
Contact an AWS Representative to know how we can help accelerate your business.