Amazon Web Services ブログ
Zero-ETL: AWS によるデータ統合の課題への取り組み
本記事は、2025 年 8 月 26 日に公開された Zero-ETL: How AWS is tackling data integration challenges を翻訳したものです。翻訳は Solutions Architect の下佐粉が担当しました。
このブログ投稿では、Amazon Web Services (AWS) がZero-ETL によってデータ統合をシンプルにしつつ、パフォーマンスの向上とコスト最適化を実現する方法をご紹介します。組織がアナリティクスと AI のためにデータを収集する中で、従来のデータ統合の中心である抽出、変換、ロード (ETL)のパイプラインは複雑化しています。これらのパイプラインの構築と維持は、イノベーションに費やすべき貴重なスタッフの時間とリソースを消費する、コスト要因にもなっています。AWS では Zero-ETL 統合を提供することによって、企業のデータ統合の取り扱いをシンプルなるよう支援します。Zero-ETL は、運用データベースとデータウェアハウス、データレイク、そしてこれらを組み合わせたレイクハウスなどの分析環境との間のシームレスなデータフローを維持しながら、データパイプライン維持の負担を軽減することができます。
数千もの AWS のお客様が、ペタバイト規模のデータを zero-ETL で処理しています。AWS のお客様は、Amazon Aurora、Amazon Relational Database Service (Amazon RDS)、Amazon Redshift、Amazon DynamoDB、Amazon SageMaker などのサービスとの Zero-ETL 統合、およびサードパーティー SaaS アプリケーションとの Zero-ETL を活用しています。これら Zero-ETL による統合によって、データ統合は技術的な負担ではなく戦略的な強みとなり、企業はデータから実用的なインサイトを導き出すことに注力できるようになります。
データ統合の進化と課題
従来、組織は運用データベースと分析システム間のデータ移動に ETL パイプラインを構築してきました。この手法は機能的ではありますが、組織がデータからタイムリーな洞察を得ることを妨げる、いくつかの重要な課題があります。
ETL パイプラインの構築と保守には多大なエンジニアリングリソースが必要で、多くの場合、人材がコアビジネスの施策から離れざるを得なくなります。これらのパイプラインは、継続的なモニタリング、更新、最適化が必要で、運用の負担が続きます。データ量が増加し、更新が頻繁になり、スキーマが進化するにつれて、これらのパイプラインの複雑さは指数関数的に増大します。
パイプラインの障害はデータの可用性に遅延を引き起こし、意思決定プロセスに影響を与える可能性があります。パイプラインが障害を起こした場合、問題の診断と修正に数時間から数日かかることがあり、その間、重要なビジネス上の意思決定が古い情報に基づいて行われる可能性があります。このデータ作成から分析可能になるまでのタイムラグは、変化の激しい業界において大きな競争上の不利となる可能性があります。
複雑なデータ変換は潜在的な障害ポイントを生み出し、データの不整合が発生するリスクを高めます。各変換ステップは、変換ロジックのバグやデータの予期せぬエッジケース(滅多に発生しない状態)により、エラーが発生する可能性があります。これらの変換全体でデータの品質と一貫性を確保するには、厳密なテストと検証プロセスが必要です。
さらに、組織が新しいデータソースを追加するにつれて、複数のパイプラインを管理する運用オーバーヘッドは急激に増加します。通常、新しいソースごとに、抽出、変換、ロードのためのカスタムロジックを備えた独自のパイプラインが必要になります。このようなパイプラインの増加は、すぐに管理が困難になり、組織全体で一貫したデータ戦略を維持することを難しくします。
Zero-ETL によるデータ分析の実現
AWS zero-ETL 統合は、AWS サービスとサードパーティアプリケーションの両方から、AWS のデータウェアハウス、データレイク、レイクハウスへのデータレプリケーションを、自動化された完全マネージド型で提供し、カスタムパイプラインの開発を不要にします。この新たなアプローチは、複数の重要な領域にわたって多くのメリットを提供し、組織のデータ統合へのアプローチを根本的に変革します。
データアーキテクチャの簡素化
Zero-ETL 統合は、ローコードまたはノーコードのセットアップを提供するため、組織は専門的な知識がなくても迅速にデータアクセスとフローを確立できます。このデータ統合の民主化により、組織全体のチームが独自のデータ統合を設定・管理できるようになり、インサイト獲得までの時間が短縮されます。
Zero-ETL 統合は、データ定義言語 (DDL)、スキーマの変更、データ型のマッピングを自動的に処理するため、分析ストア内のデータが正確かつ完全な状態に保たれます。このデータはビジネスでの利用にすぐに使用でき、ソースシステムとターゲットシステム間の一貫性を確保するのに役立ちます。この自動マッピングにより、手動マッピングプロセスで発生する可能性のあるエラーのリスクが大幅に軽減され、システム間でデータ型と構造が正しく変換されることが保証されます。
組み込みのモニタリングとエラー処理機能により、レプリケーションプロセスの状況を把握できるようになり、データの整合性維持に役立ちます。管理者は、レプリケーションの遅延や転送の失敗などの特定の条件に対してアラートを設定でき、データ統合プロセスの予防的な管理が可能になります。
Zero-ETL 統合は、フルロードと CDC (Change Data Capture) による継続的な変更を自動的に処理し、最新のデータへの迅速なアクセスを実現します。組織はこの二重の機能を活用して、既存のデータを移行しながら、新しいデータが継続的にレプリケートされることを確認でき、新しい統合モデルへのシームレスな移行を実現できます。
ニア・リアルタイム分析
Zero-ETL 統合では、通常、ソースシステムの更新から数秒または数分以内にターゲットシステムでデータを利用できるようになります。このほぼリアルタイムの機能は、大量のトランザクションワークロードにも対応し、急速に変化するビジネスにタイムリーなインサイトを提供します。例えば、E コマース企業は購買パターンをほぼ即座に分析でき、リアルタイムの在庫管理やパーソナライズされたレコメンデーションを実現できます。
このソリューションは、データ量が増加しても性能を低下させることなく、一貫したパフォーマンスを維持します。ビジネスが成長しデータ量が増加しても、Zero-ETL 統合は自動的にスケールすることで、システムへの要求が増加に対応します。
組み込みのフォールトトレランスと回復メカニズムにより、高可用性とデータの一貫性を確保します。レプリケーション中に問題が発生した場合、失敗した操作の手動または自動リトライにより、最後の正常地点から再開することで、データ損失を最小限に抑え、ソースシステムとターゲットシステム間の一貫性を確保できます。
運用負荷の削減
カスタムパイプラインのメンテナンスが不要になることで、Zero-ETL 統合は貴重なエンジニアリングリソースを解放します。データエンジニアは、定期的なパイプラインのメンテナンスに時間を費やすのではなく、データモデリング、高度な分析、機械学習などのより価値の高いタスクに集中できます。
追加のインフラストラクチャを管理する必要がないため、複雑さとコストが削減されます。Zero-ETL 統合は AWS が管理するインフラストラクチャ上で実行されるため、データ統合のためにサーバー、ストレージ、ネットワークコンポーネントをプロビジョニングおよび管理する必要がありません。
システムは、スキーマの変更を自動的に処理し、人の介入なしでデータ構造の変化に対応します。例えば、ソーステーブルに新しいカラムが追加された場合、Zero-ETL 統合は自動的にこの変更を検出し、それに応じてターゲットスキーマを更新し、データの同期を維持します。
AWS のセキュリティ機能との統合により、レプリケーションプロセス全体を通じてデータを保護することができます。これには、保管時および転送時の暗号化のサポート、さらに各種規制基準に準拠するための AWS Key Management Service (AWS KMS) との統合が含まれます。
Zero-ETL によるお客様の成功事例
ローンチ以来、Zero-ETL 統合は急速に採用が進んでいます。Zero-ETL 統合の汎用性とメリットは、様々な業界における顧客の導入事例を通じて実証されています。
大手グローバル決済ソリューションプロバイダーである MassPay のペイメントシステムアーキテクチャ部門ディレクターの Yossi Shlomo 氏は、次のように述べています。「Zero-ETL は MassPay のチームに変革をもたらしました。Amazon Aurora MySQL 互換エディションと Amazon Redshift の zero-ETL 統合を使用することで、コアペイメントシステムから不正検出、コンプライアンスケース管理、ビジネスインサイトに使用される分析環境へのデータフローを効率化しました。この移行によりレイテンシーが 90% 以上削減され、チームはプロセスと意思決定を最適化するための重要なデータにほぼ瞬時にアクセスできるようになりました」。このデータの鮮度と可用性の劇的な改善により、MassPay はより迅速で十分な情報に基づいた意思決定を行うことができ、顧客へのサービスと市場での競争力を向上させています。
Zero-ETL で統合可能な AWS サービス
AWS は現在、人気の AWS データベースサービスと、フルマネージド型データウェアハウスサービスの Amazon Redshift をシームレスに接続するためのZero-ETL 統合を提供しています。これには、Amazon Aurora MySQL 互換エディション、Amazon Aurora PostgreSQL 互換エディション、Amazon RDS for MySQL、Amazon RDS for Oracle 、Amazon DynamoDB が含まれます。つまり、組織は各サービスの強み( Aurora と Amazon RDS のトランザクション機能、DynamoDB の柔軟性、Amazon Redshift の分析能力)を活用しながら、これらのシステム間のデータ移動の複雑さを最小限に抑えることができます。
サードパーティ統合のサポート
Zero-ETL 統合は AWS サービスを超えて、幅広いサードパーティのデータもサポートするようになりました。AWS は、SAP OData、Salesforce、Salesforce Marketing Cloud Account Engagement、ServiceNow、Zendesk、Zoho CRM、さらに Facebook Ads や Instagram Ads などのソースと Zero-ETL 統合を提供しています。ターゲットには、Amazon Redshift や Amazon SageMaker を使用したレイクハウスが含まれます。
最近の更新内容は以下の通りです:
- AWS Glue が Amazon DynamoDB と 8 つの SaaS アプリケーションから Amazon S3 テーブルへのZero-ETL 統合をサポート開始
- Amazon Aurora MySQL と Amazon RDS for MySQL の Amazon SageMaker との統合が利用可能に
さまざまなベンダーの従来のリレーショナルデータベースも、Zero-ETL 統合を通じてレイクハウスに連携できます。この包括的なサポートにより、組織はカスタム統合パイプラインを構築することなく、多様なソースからのデータを AWS 分析環境に統合できます。Zero-ETL を使用して、複数のベンダーソリューション間のデータサイロを解消し、データ統合プロセスを簡素化することで、組織は複雑なデータパイプラインの管理ではなく、インサイトの導出に注力できます。
より多くの AWS サービスとデータソースをサポートするための追加の統合機能が開発中であり、エコシステムをさらに拡大する予定です。AWS は、お客様のニーズとデータ環境の進化に対応して、Zero-ETL 統合の範囲を継続的に拡大することにコミットしています。
Zero-ETL の高度な機能
AWS のZero-ETL 機能には、高度な機能が含まれています。例えば、更新間隔コントロールを使用することで、データの同期頻度をカスタマイズでき、各ユースケースに必要な最新のデータに基づいて分析を行うことができます。一方、履歴モードではデータの過去のバージョンを保持し、トレンド分析、インサイトに富んだダッシュボード作成、監査要件への対応を可能にします。また、Amazon Redshift で Slowly Changing Dimension (SCD) Type 2 テーブルを作成することもできます。
データフィルタリング機能を使用して、特定のオブジェクトやデータサブセットを選択的にレプリケートし、ストレージの使用を最適化し、関連性の高いデータに焦点を当てることができます。包括的なロギングとモニタリング機能により、データの移動状況とシステムの状態を可視化できるため、管理者は問題を迅速に特定して対処できます。
2 つの主要な統合アプローチを組み合わせることもできます。Zero-ETL は包括的な分析のために完全なデータレプリケーション (移動) を提供し、一方でフェデレーションも提供しており、これはソースデータへのリアルタイムアクセスが重要な場合にデータをその場で照会することを可能にします。この柔軟性を活用して、組織固有のニーズとユースケースに合わせてデータ統合戦略を決めることが可能になります。
Zero-ETL の使用開始
Zero-ETL 統合の利用を開始するには、まずソースデータベースとターゲットの分析サービスを特定する必要があります。これには、現在のデータアーキテクチャを評価し、Zero-ETL アプローチが最も効果的なデータフローを判断することが含まれます。
次に、必要な権限とネットワーク要件を設定する必要があります。これには通常、AWS Identity and Access Management (IAM) の設定、または AWS IAM Identity Center を使用したシングルサインオンの設定、そしてソースとターゲットのサービスが安全に通信できることを確認することが含まれます。
前提条件が整っていれば、次の画像に示すように、AWS 管理コンソール 内で簡単に Zero-ETL 統合を作成できます。直感的なインターフェイスがプロセスをガイドし、ソースとターゲットの詳細の指定、レプリケーション対象のテーブルの選択、追加オプションの設定を促します。
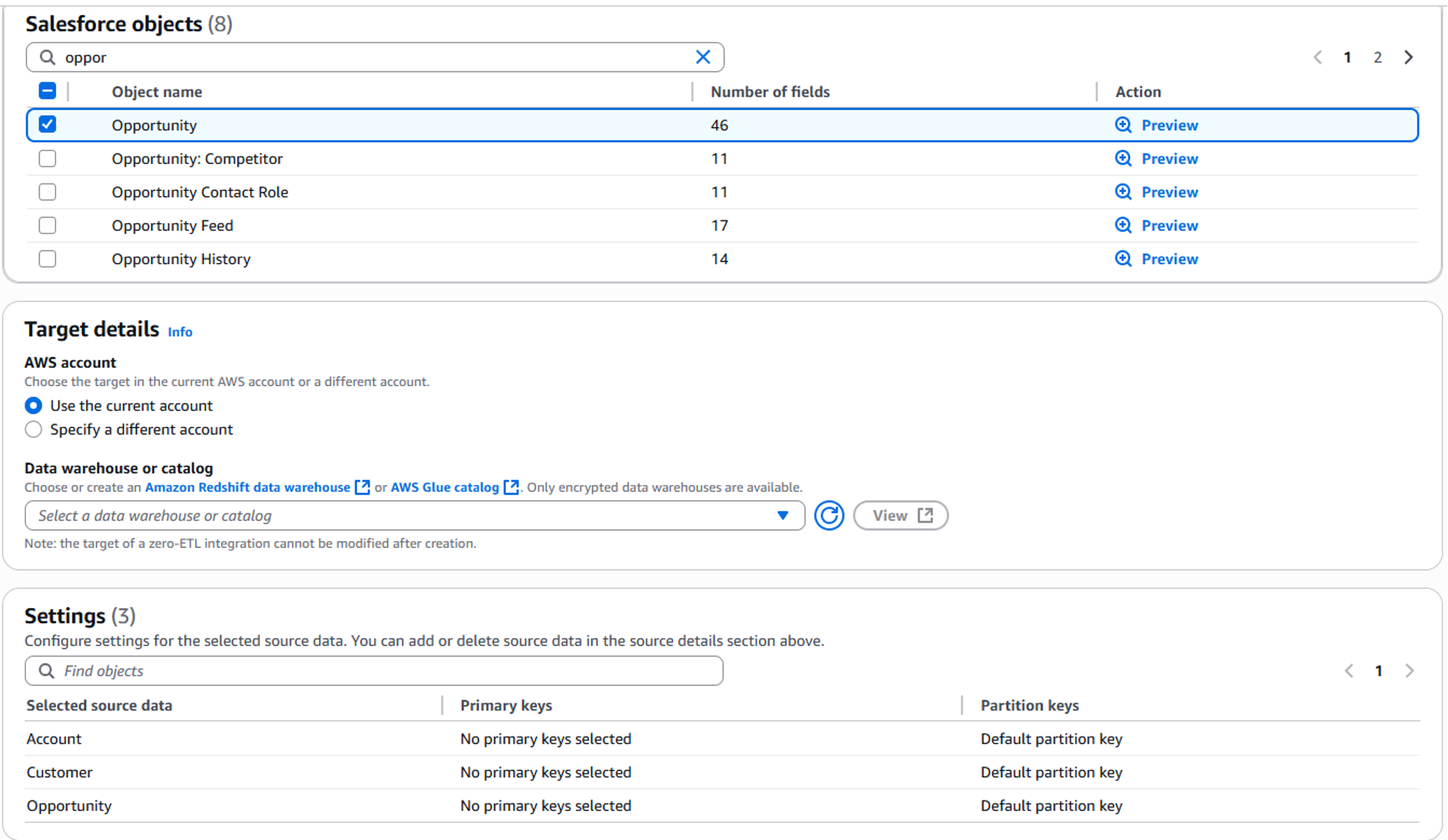
セットアップ後は、円滑な運用を確保するために、レプリケーションのステータスとパフォーマンスを監視できます。AWS は、Zero-ETL 統合の健全性とパフォーマンスを追跡するために、詳細なメトリクスとログを提供します。
詳細なセットアップ手順については、各サポートされている統合のステップバイストップガイドを提供している zero-ETL 統合の AWS ドキュメントをご覧ください。
Zero-ETL の今後の展望
AWS は、追加の AWS サービスとデータソースのサポートに向けたロードマップを積極的に取り組んでおり、Zero-ETL 統合の範囲を拡大することで、より多くのお客様がより広範なユースケースでシンプルなデータ統合のメリットを享受できるようにします。
Zero-ETL 統合は、組織がデータ統合にアプローチする方法の根本的な変化です。ETL パイプラインの複雑さがないため、お客様はインフラストラクチャの管理ではなく、データから価値を引き出すことに集中できます。このアプローチは、クラウド運用を簡素化し、お客様がより迅速なイノベーションを可能にするという AWS のコミットメントに沿っています。
Zero-ETL 統合の詳細と、そのメリットについては、以下のトピックをご覧ください。
- Aurora のZero-ETL 統合については、Zero-ETL 統合の利点、主要な概念、制限事項、クォータ、サポートされているリージョンをご覧ください
- Amazon RDS のZero-ETL 統合については、Zero-ETL の利点、主要な概念、制限事項、クォータ、サポートされているリージョンをご覧ください
- DynamoDB のZero-ETL 統合については、DynamoDB と Amazon Redshift のZero-ETL 統合をご覧ください
- アプリケーションとのZero-ETL 統合については、Zero-ETL 統合をご覧ください
AWS のZero-ETL 統合を使用して、データ運用を効率化し、データの可能性を最大限に引き出す方法を、今すぐ始めてみましょう。
 Nikki Rouda は AWS のプロダクトマーケティングに従事しています。IT インフラストラクチャ、ストレージ、ネットワーキング、セキュリティ、IoT、アナリティクス、モダンアプリケーションなど、幅広い分野で長年の経験を持っています。
Nikki Rouda は AWS のプロダクトマーケティングに従事しています。IT インフラストラクチャ、ストレージ、ネットワーキング、セキュリティ、IoT、アナリティクス、モダンアプリケーションなど、幅広い分野で長年の経験を持っています。