Amazon Web Services ブログ
OpenSearch のコスト削減: Intel AVX-512 によるバイナリベクトルパフォーマンスの向上
本記事は 2025 年 5 月 8 日 に公開された「Save big on OpenSearch: Unleashing Intel AVX-512 for binary vector performance」を翻訳したものです。
OpenSearch バージョン 2.19 で、Amazon OpenSearch Service はバイナリベクトルのレイテンシーとスループットを向上させるハードウェアアクセラレーションに対応しました。データノードに最新世代の Intel Xeon インスタンスを選択すると、OpenSearch は AVX-512 アクセラレーションを使用し、前世代の R5 インスタンスと比較して最大 48% のスループット向上、OpenSearch 2.17 以前と比較して 10% のスループット向上を実現します。設定を変更する必要はありません。OpenSearch 2.19 にアップグレードし、c7i、m7i、R7i インスタンスを使用するだけで改善効果が得られます。
本記事では、Intel Xeon プロセッサが OpenSearch ワークロードにもたらす改善と、総所有コスト (TCO) の削減にどのように役立つかを説明します。
フル精度ベクトルとバイナリベクトルの違い
OpenSearch Service でセマンティック検索を使用する場合、ベクトル埋め込みを作成して OpenSearch に保存します。OpenSearch の k 近傍法 (k-NN) プラグインは、Facebook AI Similarity Search (FAISS)、Non-Metric Space Library (NMSLib)、Apache Lucene などのエンジンと、Hierarchical Navigable Small World (HNSW) や Inverted File (IVF) などのアルゴリズムを提供し、埋め込みの保存と最近傍マッチングの計算を行います。
ベクトル埋め込みは、32 ビット浮動小数点数 (FP32) の高次元配列です。大規模言語モデル (LLM)、基盤モデル (FM)、その他の機械学習 (ML) モデルは、入力からベクトル埋め込みを生成します。一般的な 384 次元の埋め込みは 384 * 4 = 1,536 バイトを必要とします。ベクトル数が数百万 (または数十億) に増加すると、そのデータの保存と処理にコストがかかります。
OpenSearch Service はバイナリベクトルに対応しています。バイナリベクトルは各次元を 1 ビットで保存します。384 次元のバイナリ埋め込みは 384 / 8 ビット = 48 バイトで保存できます。もちろん、ビット数を減らすと情報も失われます。バイナリベクトルはフル精度ベクトルほど正確な再現率を提供しません。その代わり、バイナリベクトルはコストが大幅に低く、レイテンシーも大幅に改善されます。
ハードウェアアクセラレーション: AVX-512 と popcount 命令
バイナリベクトルは類似度の測定にハミング距離を使用します。2 つのバイナリベクトル間のハミング距離は、2 つの数値間で異なるビット数として定義されます。ハミング距離は popcount (ポピュレーションカウント) と呼ばれる手法に依存しており、次のセクションで簡単に説明します。
例えば、5 と 3 のハミング距離を求める場合:
- 5 = 101
- 3 = 011
- 2 つの位置で異なる (ビット単位 XOR): 101 ⊕ 011 = 110 (1 が 2 つ)
したがって、ハミング距離 (5, 3) = 2 となります。
popcount は、バイナリ入力内の 1 ビットの数をカウントする演算です。2 つのバイナリ入力間のハミング距離は、ビット単位 XOR 結果の popcount を計算することと同等です。AVX-512 アクセラレータにはネイティブの popcount 演算があり、popcount とハミング距離の計算を高速化します。
OpenSearch 2.19 は、FAISS エンジンに Intel AVX-512 命令を統合しています。OpenSearch Service で OpenSearch 2.19 エンジンとバイナリベクトルを使用すると、OpenSearch は最新の Intel Xeon プロセッサでパフォーマンスを最大化できます。OpenSearch k-NN プラグインと FAISS は、avx512_spr という特殊なビルドモードを使用し、__mm512_popcnt_epi64 ベクトル命令でハミング距離計算を高速化します。__mm512_popcnt_epi64 は、8 つの 64 ビット整数の論理 1 ビット数を一度にカウントします。その結果、CPU が実行する命令数であるインストラクションパス長が 8 分の 1 に削減されます。次のセクションのベンチマークでは、この最適化による OpenSearch バイナリベクトルの改善を示します。
この最適化はデフォルトで有効になっているため、特別な設定は必要ありません。最適化を使用するための要件は以下のとおりです:
- OpenSearch バージョン 2.19 以上
- データノードに Intel 第 4 世代 Xeon 以降のインスタンス (C7i、M7i、または R7i)
バイナリベクトルワークロードの処理時間の内訳
システムを徹底的にテストするため、1,000 万件のバイナリベクトルのテストデータセットを作成しました。バイナリデータに適したハミング空間をベクトル間の距離測定に選択しました。この大規模なデータセットにより、パフォーマンスのボトルネックがどこで発生するかを正確に特定するのに十分な負荷をシステムにかけることができました。詳細に興味がある方は、本記事末尾の Appendix 2 に完全なクラスター構成とインデックス設定を記載しています。
フレームグラフを使用したバイナリベクトルベースのワークロードのプロファイル分析では、処理時間の大部分が FAISS ライブラリでのハミング距離計算に費やされていることがわかります。FAISS ライブラリの BinaryIndices に最大 66% の時間が費やされています。

ベンチマークと結果
次のセクションでは、このロジックの最適化結果と、OpenSearch ワークロードへのメリットを 2 つの観点から見ていきます:
- 価格性能比: CPU 消費量の削減により、ドメイン内のインスタンス数を削減できる可能性があります
- Intel popcount 命令によるパフォーマンス向上
OpenSearch ユーザーの価格性能比と TCO 向上
パフォーマンス向上を活用するには、データノードにメモリ対コア比が高い R7i インスタンスをお勧めします。以下の表は、1,000 万ベクトルと 1 億ベクトルのデータセットでのベンチマーク結果と、R5 インスタンスと比較した R7i インスタンスでの改善を示しています。R5 インスタンスは avx512 命令に対応していますが、avx512_spr の高度な命令には対応していません。これは R7i 以降の Intel インスタンスでのみ利用可能です。
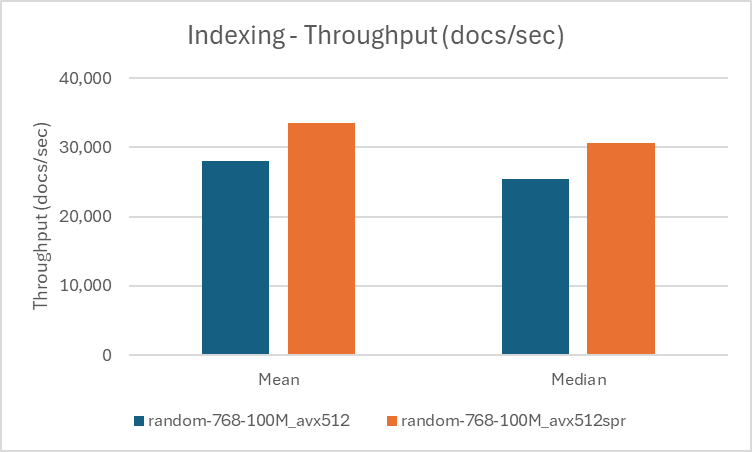
平均して、R5 と R7i インスタンスを比較すると、インデックス作成スループットで 20% の向上、検索スループットで最大 48% の向上が見られました。R7i インスタンスは R5 インスタンスより約 13% 高価ですが、価格性能比では R7i が優れています。1 億ベクトルのデータセットでは、検索スループットが 40% 以上向上し、さらに良い結果が得られました。Appendix 1 にテスト構成を、Appendix 3 に表形式の結果を記載しています。
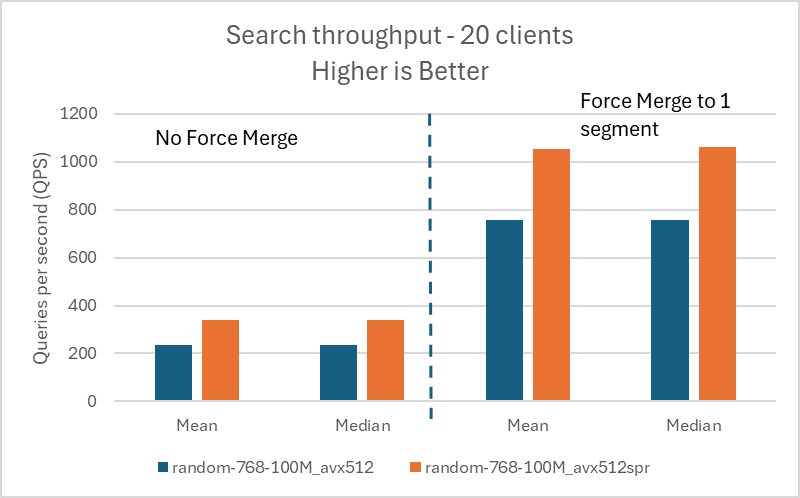
以下の図は、1,000 万ベクトルのデータセットでの結果を視覚化したものです。
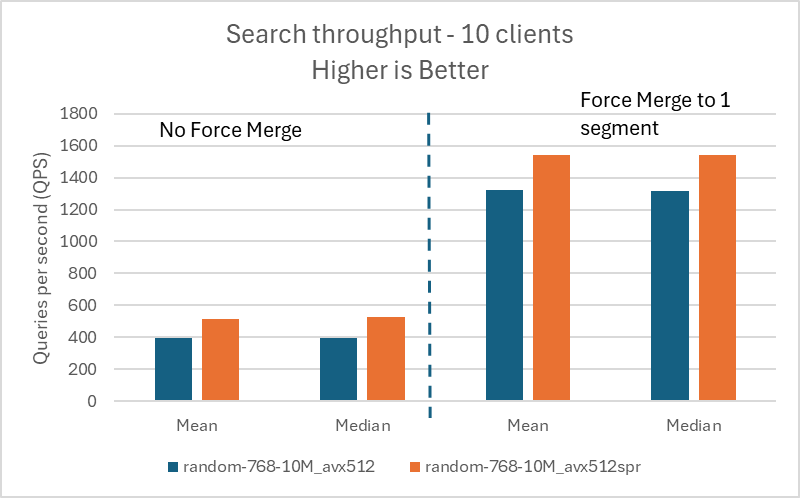
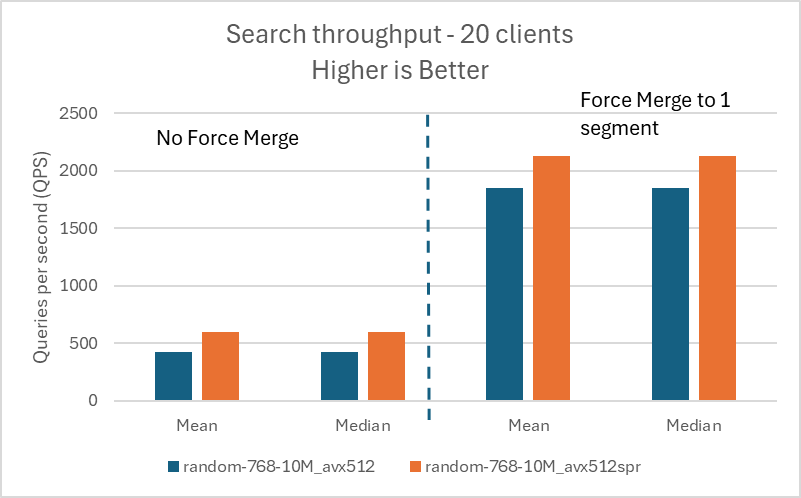
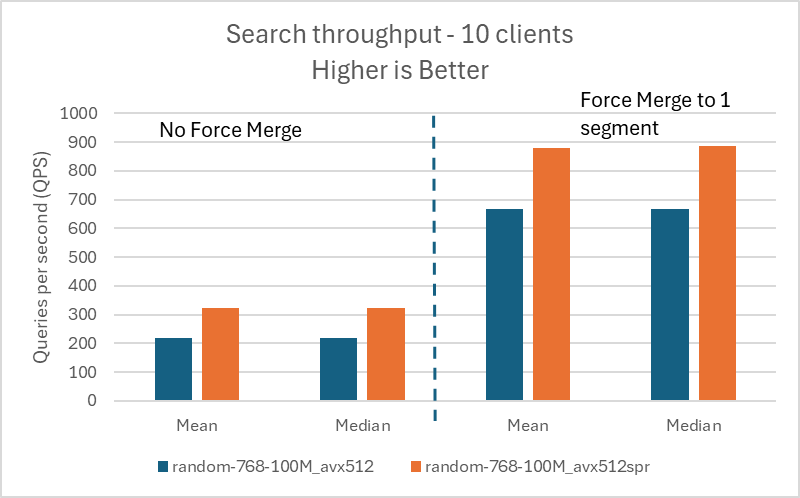
以下の図は、1 億ベクトルのデータセットでの結果を視覚化したものです。
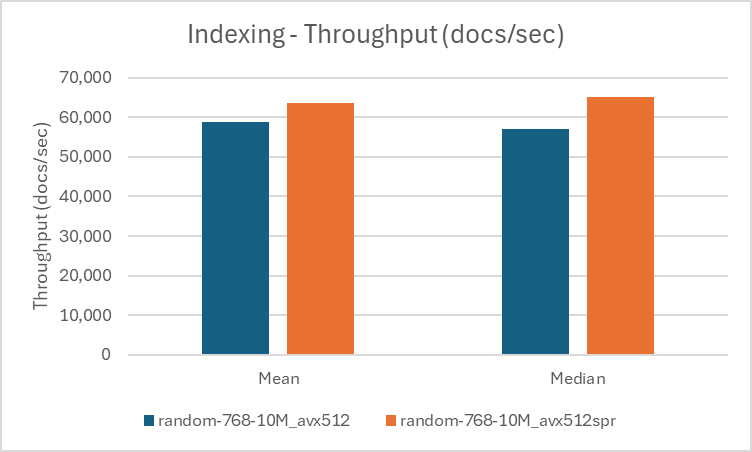
AVX-512 の popcount 命令によるパフォーマンス向上
このセクションは、新しい avx512_spr がもたらす改善の程度と、パフォーマンス向上の詳細に興味がある上級ユーザー向けです。この実験で使用した OpenSearch 構成は Appendix 2 に記載しています。
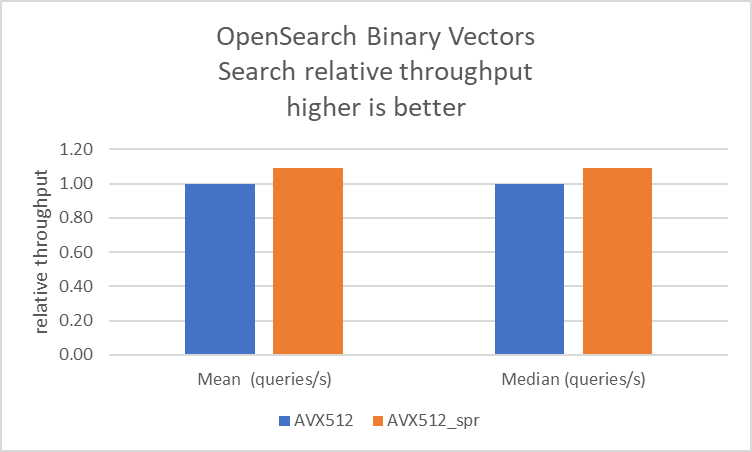
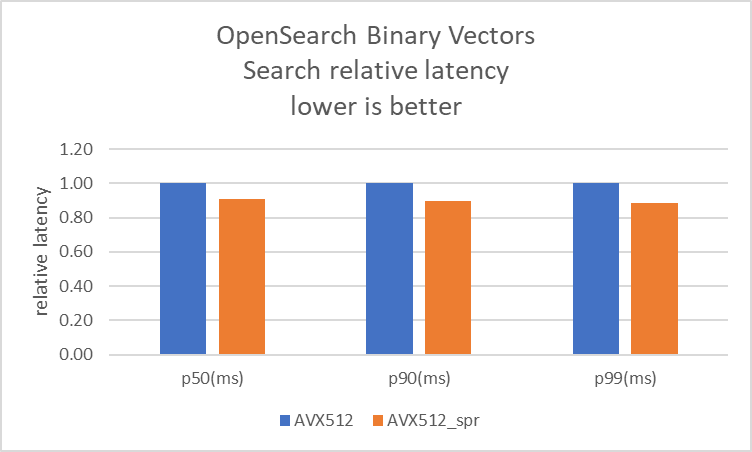
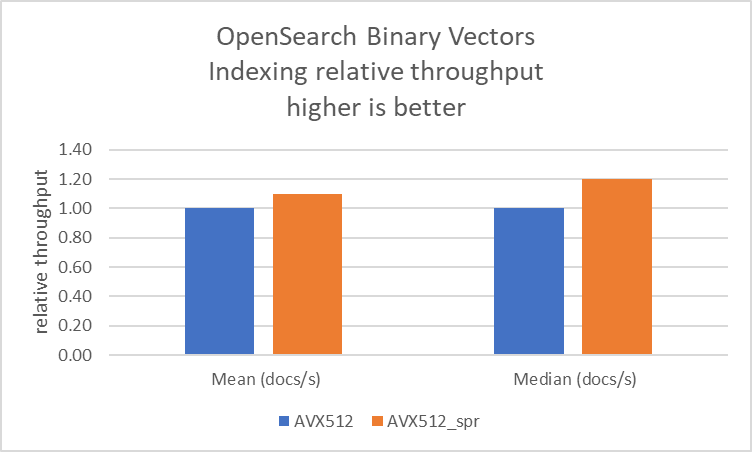
R7i インスタンスで、ハミング距離最適化の有無による OpenSearch ベンチマークを実行しました。SIMD 最適化に記載されているように、opensearch.yaml ファイルで knn.faiss.avx512_spr.disabled を設定することで avx512_spr を無効にできます。データによると、この機能はインデックス作成と検索で 10% のスループット向上と、クライアント負荷が一定の場合に 10% のレイテンシー削減を提供します。
この向上は、Intel プロセッサに搭載されている __mm512_popcnt_epi64 ハードウェア命令の使用によるもので、ワークロードのパス長が削減されます。前のセクションで特定したホットスポットは、ハードウェア命令を使用するコードで最適化されています。その結果、同じワークロードを実行するための CPU サイクルが削減され、OpenSearch でのバイナリベクトルインデックス作成が 10% 高速化し、検索ワークロードのレイテンシーが削減されます。
以下の図はベンチマーク結果を視覚化したものです。
まとめ
ストレージ、メモリ、コンピューティングの改善は、ベクトル検索の最適化に不可欠です。バイナリベクトルは FP32/FP16 と比較してストレージとメモリのメリットをすでに提供しています。本記事では、ハミング距離計算の改善により、AWS の R5 と R7i インスタンスを比較した場合に最大 48% のコンピューティングパフォーマンス向上を実現する方法を詳しく説明しました。バイナリベクトルは FP32 と同等の再現率では劣りますが、オーバーサンプリングやリスコアリングなどの手法で再現率を向上できます。大規模なデータセットを扱う場合、コンピューティングコストは大きな支出になります。AWS の Intel R7i 以降のインスタンスに移行することで、インフラストラクチャコストを大幅に削減でき、ユーザーにとって効率的なソリューションとなります。
新しい AVX-512 命令によるハミング距離サポートは、OpenSearch 2.19 以降で利用可能です。お好みのクラウド環境で最新の Intel インスタンスをぜひお試しください。
新しい命令は、FP16 や BF16 などの量子化手法など、ベクトル検索の他の領域でもハードウェアアクセラレーションを活用する機会を提供します。AMX や AVX-10 など、他のハードウェアアクセラレータのベクトル検索への活用も検討しています。
著者について
Akash Shankaran は Intel の Xeon ソフトウェアチームのソフトウェアアーキテクトおよびテックリードです。OpenSearch の最適化機会の発掘と実装に取り組んでいます。
Mulugeta Mammo は Intel の OpenSearch 最適化チームをリードするシニアソフトウェアエンジニアです。
Noah Staveley は Intel の OpenSearch 最適化チームで働くクラウド開発エンジニアです。
Assane Diop は Intel の OpenSearch 最適化チームで働くクラウド開発エンジニアです。
Naveen Tatikonda は AWS のソフトウェアエンジニアで、OpenSearch プロジェクトと Amazon OpenSearch Service に携わっています。分散システムとベクトル検索に関心があります。
Vamshi Vijay Nakkirtha は OpenSearch プロジェクトと Amazon OpenSearch Service に携わるソフトウェアエンジニアリングマネージャーです。主な関心分野は分散システムです。
Dylan Tong は Amazon Web Services のシニアプロダクトマネージャーです。OpenSearch のベクトルデータベース機能を含む、OpenSearch の AI および機械学習 (ML) に関するプロダクトイニシアチブをリードしています。Dylan はデータベース、アナリティクス、AI/ML 分野で顧客と直接協力し、製品やソリューションを作成してきた数十年の経験があります。Dylan は Cornell University でコンピュータサイエンスの学士号と修士号を取得しています。
注意事項と免責事項
Intel と OpenSearch チームは、ハミング距離機能の追加で協力しました。Intel は機能の設計と実装を担当し、Amazon はコンパイラ、リリース管理、ドキュメントを含むツールチェーンの更新を担当しました。両チームが本記事で紹介したデータポイントを収集しました。
パフォーマンスは使用状況、構成、その他の要因によって異なります。詳細は Performance Index ウェブサイトをご覧ください。
コストと結果は異なる場合があります。
Intel テクノロジーには、有効化されたハードウェア、ソフトウェア、またはサービスのアクティベーションが必要な場合があります。
Appendix 1
以下の表は、Appendix 3 の結果に対するテスト構成をまとめたものです。
avx512 |
avx512_spr |
|
| vector dimension | 768 | |
| ef_construction | 100 | |
| ef_search | 100 | |
| primary shards | 8 | |
| replica | 1 | |
| data nodes | 2 | |
| data node instance type | R5.4xl | R7i.4xl |
| vCPU | 16 | |
| Cluster manager nodes | 3 | |
| Cluster manager node instance type | c5.xl | |
| data type | binary | |
| space type | Hamming | |
Appendix 2
以下の表は、このベンチマークで使用した OpenSearch 構成をまとめたものです。
avx512 |
avx512_spr |
|
| OpenSearch version | 2.19 | |
| engine | faiss | |
| dataset | random-768-10M | |
| vector dimension | 768 | |
| ef_construction | 256 | |
| ef_search | 256 | |
| primary shards | 4 | |
| replica | 1 | |
| data nodes | 2 | |
| cluster manager nodes | 1 | |
| data node instance type | R7i.2xl | |
| client instance | m6id.16xlarge | |
| data type | binary | |
| space type | Hamming | |
| Indexing clients | 20 | |
| query clients | 20 | |
| force merge segments | 1 | |
Appendix 3
この Appendix には、1,000 万ベクトルと 1 億ベクトルのデータセット実行結果が含まれています。
以下の表は、クエリ毎秒 (QPS) でのクエリ結果をまとめたものです。
| Query Throughput Without Forcemerge | Query Throughput with Forcemerge to 1 Segment | ||||||
| Dataset | Dimension | avx512 / avx512_spr |
Query Clients | Mean Throughput | Median Throughput | Mean Throughput | Median Throughput |
| random-768-10M | 768 | avx512 |
10 | 397.00 | 398.00 | 1321.00 | 1319.00 |
| random-768-10M | 768 | avx512_spr |
10 | 516.00 | 525.00 | 1542.00 | 1544.00 |
| %gain | – | – | – | 29.97 | 31.91 | 16.73 | 17.06 |
| random-768-10M | 768 | avx512 |
20 | 424.00 | 426.00 | 1849.00 | 1853.00 |
| random-768-10M | 768 | avx512_spr |
20 | 597.00 | 600.00 | 2127.00 | 2127.00 |
| %gain | – | – | – | 40.81 | 40.85 | 15.04 | 14.79 |
| random-768-100M | 768 | avx512 |
10 | 219 | 220 | 668 | 668 |
| random-768-100M | 768 | avx512_spr |
10 | 324 | 324 | 879 | 887 |
| %gain | – | – | – | 47.95 | 47.27 | 31.59 | 32.78 |
| random-768-100M | 768 | avx512 |
20 | 234 | 235 | 756 | 757 |
| random-768-100M | 768 | avx512_spr |
20 | 338 | 339 | 1054 | 1062 |
| %gain | – | – | – | 44.44 | 44.26 | 39.42 | 40.29 |
以下の表は、インデックス作成結果をまとめたものです。
| Indexing Throughput (documents/second) | ||||||
| Dataset | Dimension | avx512 / avx512_spr |
Indexing Clients | Mean Throughput | Median Throughput | Forcemerge (minutes) |
| random-768-10M | 768 | avx512 |
20 | 58729 | 57135 | 61 |
| random-768-10M | 768 | avx512_spr |
20 | 63595 | 65240 | 57 |
| %gain | – | – | 8.29 | 14.19 | 7.02 | |
| random-768-100M | 768 | avx512 |
16 | 28006 | 25381 | 682 |
| random-768-100M | 768 | avx512_spr |
16 | 33477 | 30581 | 634 |
| %gain | – | – | 19.54 | 20.49 | 7.04 | |
この記事は Kiro が翻訳を担当し、Solutions Architect の 榎本 貴之 がレビューしました。