Amazon Web Services ブログ
Amazon S3 Vectors の紹介:ネイティブベクトルを大規模にサポートする最初のクラウドストレージ (プレビュー)
このブログは 2025 年 7 月 15 日に Channy Yun によって執筆された内容を日本語化したものです。原文はこちらを参照してください。
本日、Amazon S3 Vectors のプレビュー版を発表します。これは、ベクトルのアップロード、保存、クエリの総コストを最大 90 % 削減できる、耐久性に優れたベクトルストレージソリューションです。Amazon S3 Vectors は、大規模なベクトルデータセットの保存をネイティブにサポートし、1 秒未満のクエリパフォーマンスを実現する初めてのクラウドオブジェクトストアです。これにより、企業が AI 対応データを大規模に低コストで保存できるようになります。
ベクトル検索は、生成 AI アプリケーションで使用されている新しい手法で、距離または類似度メトリックを使用してベクトル表現を比較することにより、特定のデータに類似したデータポイントを検索します。ベクトルは埋め込みモデルから作成された非構造化データを数値で表現したものです。ドキュメント内のフィールドの埋め込みモデルを使用してベクトルを生成し、ベクトルを S3 Vectors に保存してセマンティック検索を行います。
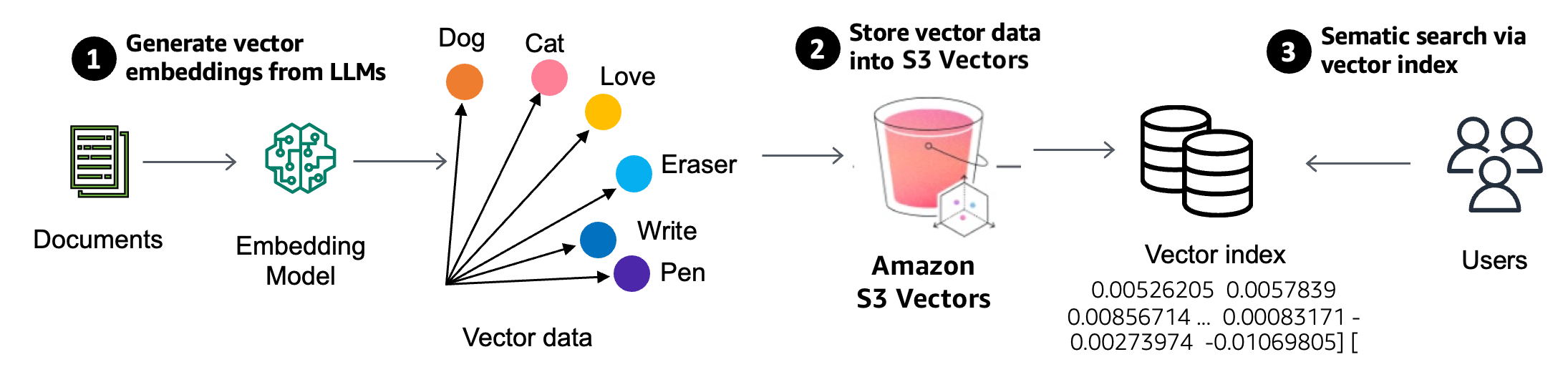
S3 Vectors では、ベクトルバケットが導入されました。ベクトルバケットは、インフラストラクチャをプロビジョニングせずにベクトルデータを保存、アクセス、クエリするための専用の API セットを備えた新しいバケットタイプです。S3 ベクトルバケットを作成すると、ベクトルデータをベクトルインデックス内に整理し、データセットに対して類似検索クエリを簡単に実行できるようにします。各ベクトルバケットには最大 10,000 個のベクトルインデックスを含めることができ、各ベクトルインデックスには数千万個のベクトルを格納できます。
ベクトルインデックスを作成した後、ベクトルデータをインデックスに追加するときに、メタデータをキーと値のペアとして各ベクトルに添付して、日付、カテゴリ、ユーザー設定などの一連の条件に基づいて今後のクエリをフィルタリングすることもできます。時間の経過とともにベクトルの書き込み、更新、削除を行うと、S3 Vectors は、データセットが拡大したり進化したりしても、ベクトルストレージのコストパフォーマンスが可能な限りベストになるように、ベクトルデータを自動的に最適化します。
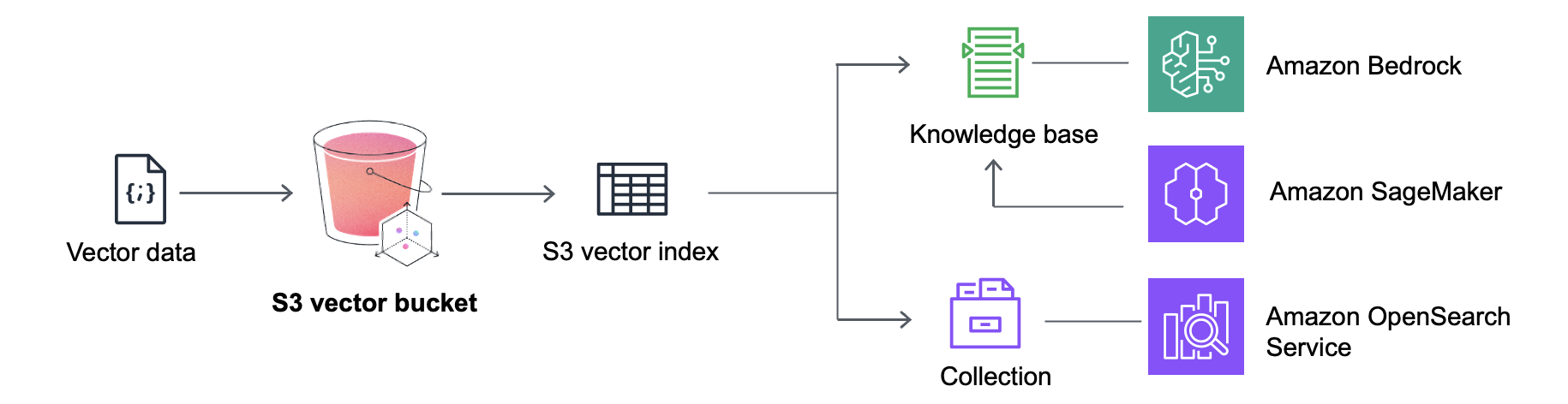
S3 Vectorsは、Amazon SageMaker Unified Studio を含む Amazon Bedrock Knowledge Bases ともネイティブに統合されており、費用対効果の高い Retrieval-Augmented Generation (RAG) アプリケーションを構築できます。Amazon OpenSearch Service との統合により、クエリ頻度の低いベクトルを S3 Vectors に保存することでストレージコストを削減でき、需要が高まったときにそれらを OpenSearch にすばやく移動したり、リアルタイムで低レイテンシーの検索操作をサポートすることができます。
S3 Vectors を使用すると、画像、動画、ドキュメント、音声ファイルなどの大量の非構造化データを表すベクトル埋め込みを経済的に保存できるようになり、セマンティック検索、類似検索、RAG、ビルドエージェントメモリなどのスケーラブルな生成 AI アプリケーションが可能になります。また、ベクトルデータベースの管理に伴う複雑さやコストをかけずに、パーソナライズされた推奨事項、自動コンテンツ分析、インテリジェントな文書処理など、さまざまな業界のユースケースをサポートするアプリケーションを構築できます。
S3 Vectors の動作
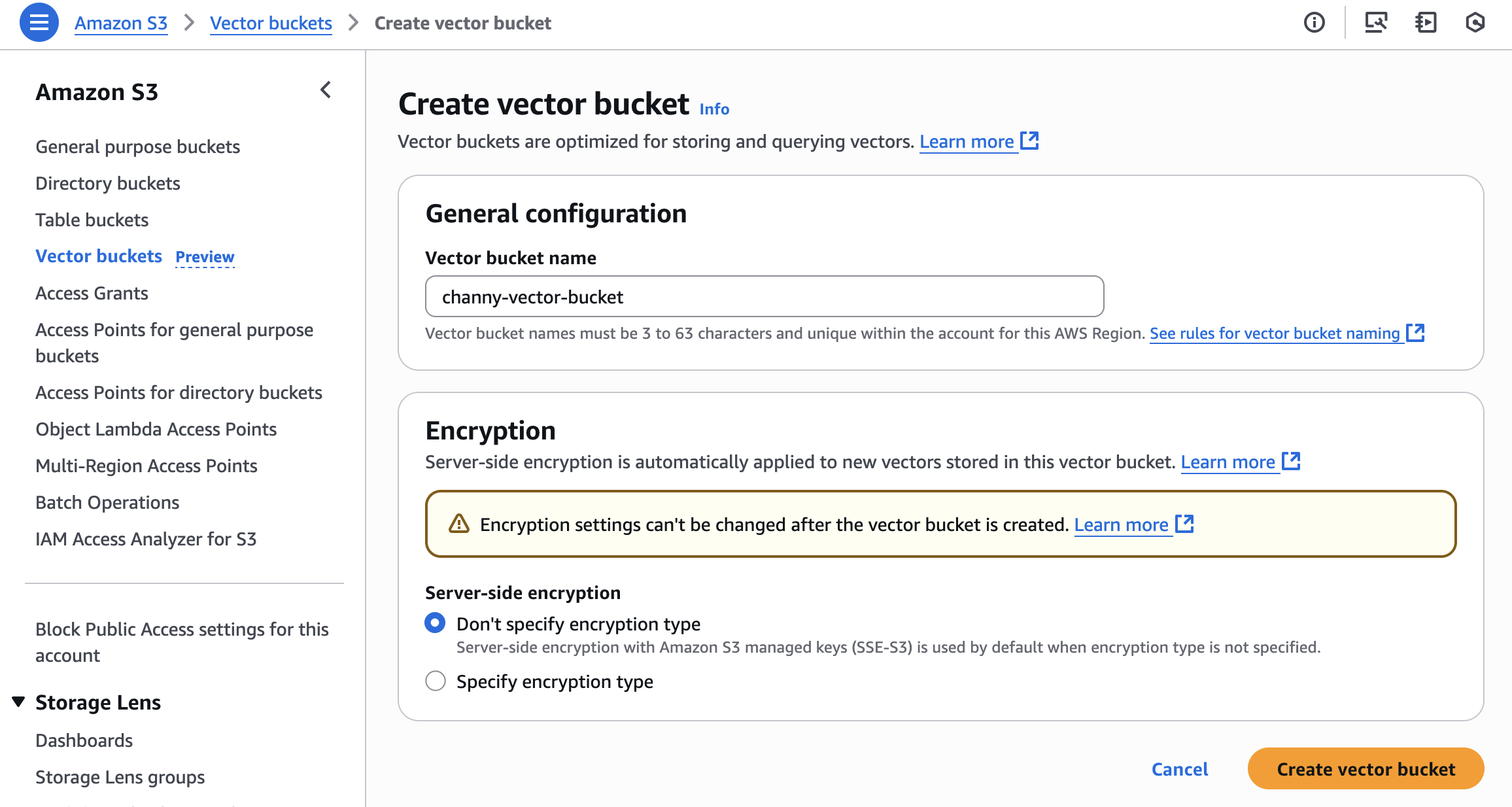
ベクトルバケットを作成するには、Amazon S3 コンソールの左側のナビゲーションペインで Vector buckets を選択し、Create vector bucket を選択します。
ベクトルバケット名を入力し、暗号化タイプを選択します。暗号化タイプを指定しない場合、Amazon S3 は新しいベクトルの暗号化の基本レベルとして Amazon S3 管理キー (SSE-S3) を使用してサーバー側の暗号化を適用します。AWS Key Management Service (AWS KMS) キー (SSE-KMS) を使用してサーバー側の暗号化を選択することもできます。ベクトルバケットの管理の詳細については、Amazon S3 ユーザーガイドの S3 ベクトルバケットをご覧ください。
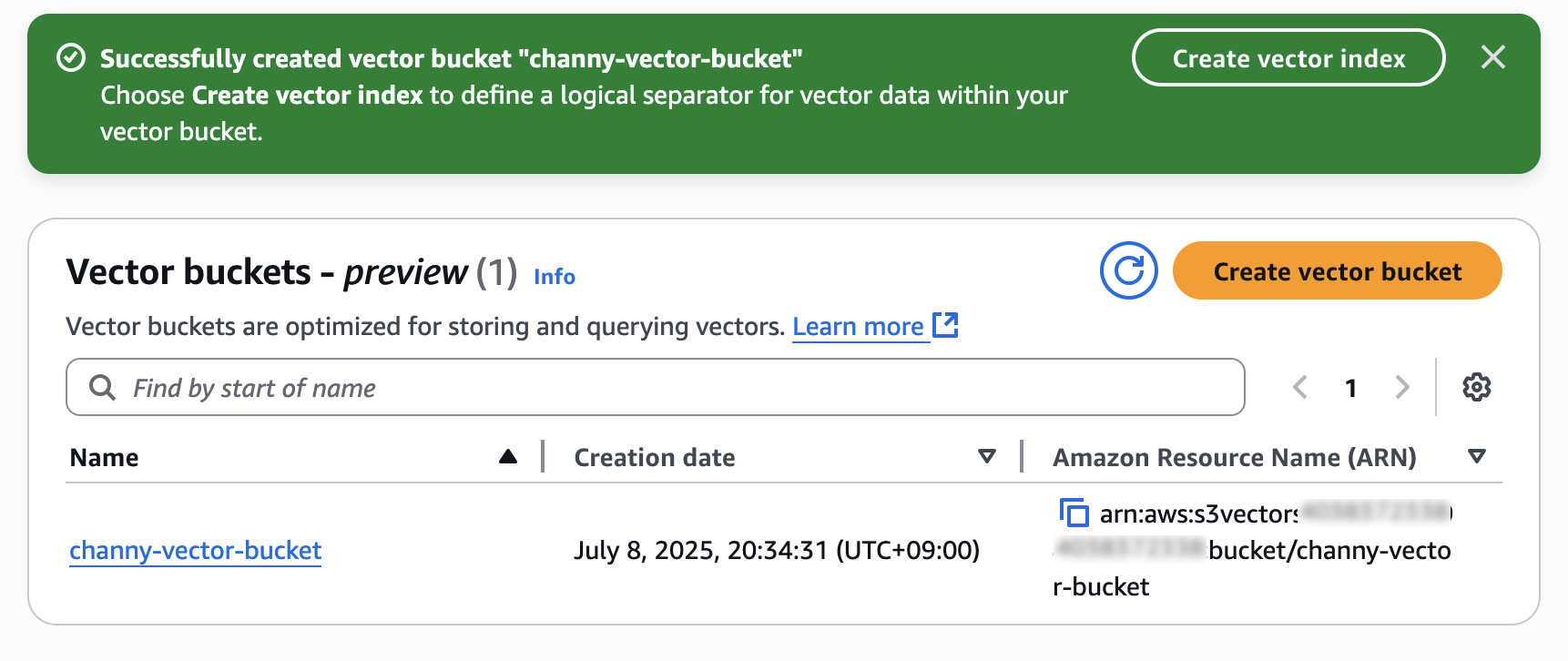
これで、ベクトルインデックスを作成して、作成したベクトルバケット内でベクトルデータを保存およびクエリできます。
ベクトルインデックス名と、インデックスに挿入するベクトルの次元を入力します。このインデックスに追加されるすべてのベクトルは、完全に同じ数の値を持つ必要があります。
Distance metric では、Cosine または Euclidean を選択できます。ベクトル埋め込みを作成する場合、より正確な結果を得るには、埋め込みモデルの推奨された距離メトリックを選択してください。
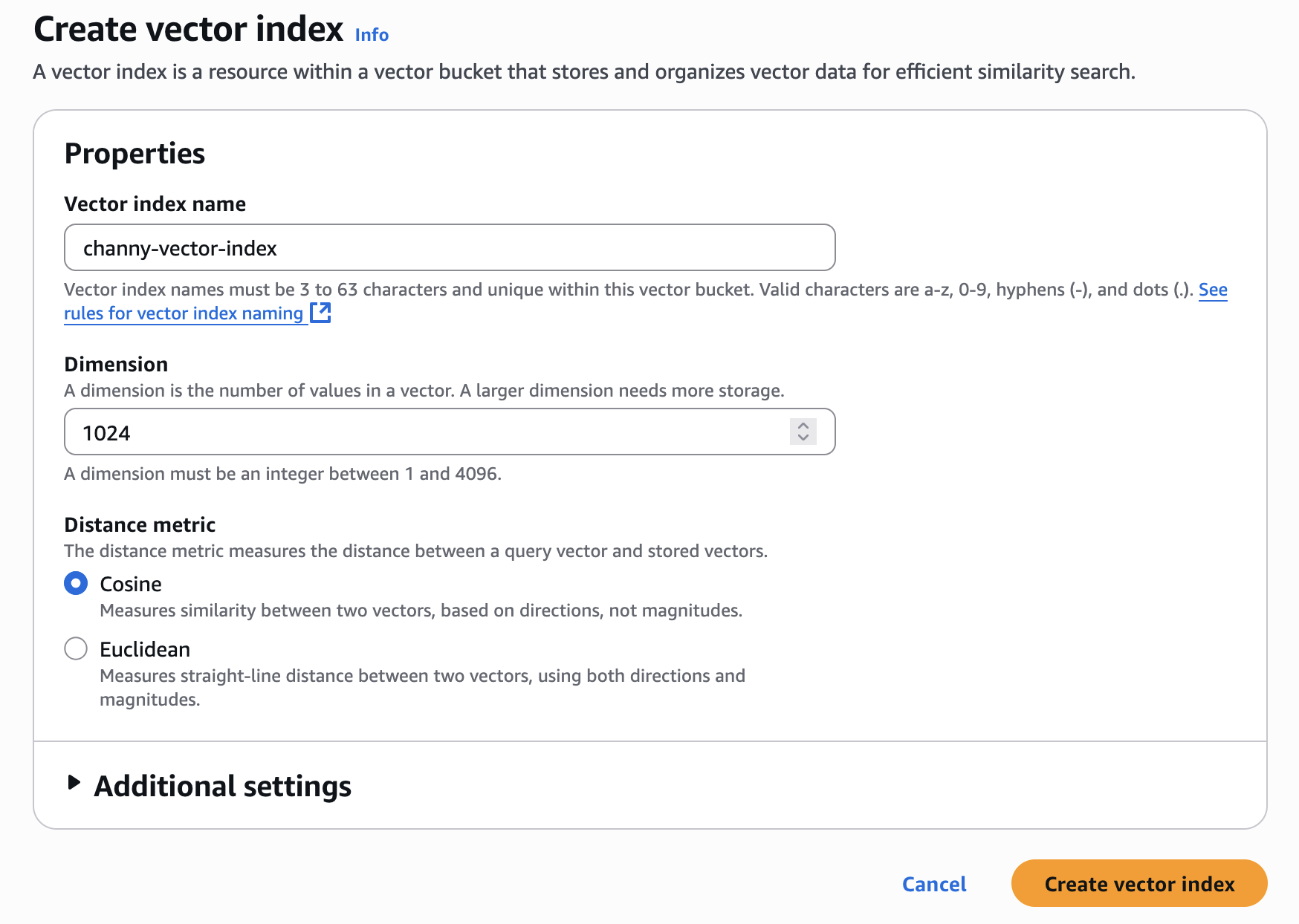
Create vector index を選択すると、ベクトルの挿入、一覧表示、クエリを行うことができます。
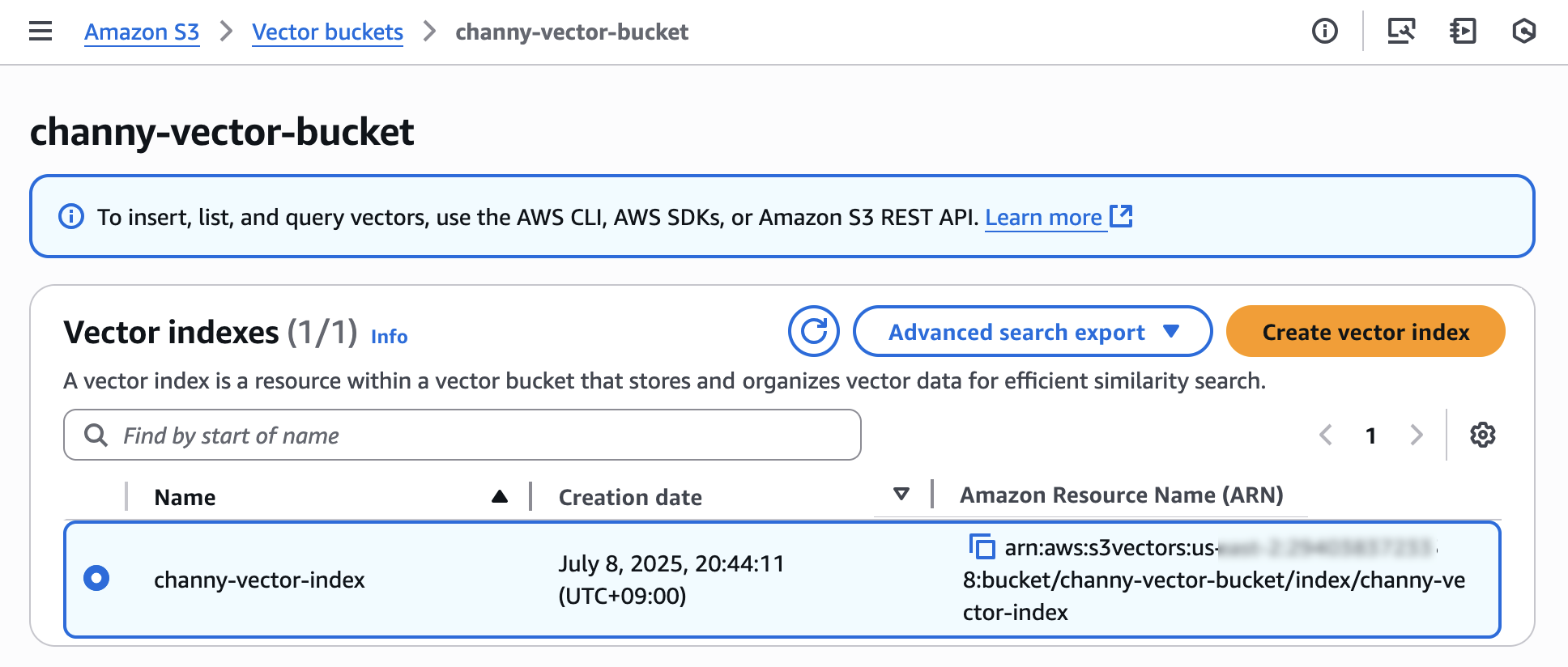
ベクトル埋め込みをベクトルインデックスに挿入するには、AWS コマンドラインインターフェイス (AWS CLI)、AWS SDKs、または Amazon S3 REST API を使用できます。非構造化データ用のベクトル埋め込みを生成するには、Amazon Bedrock が提供する埋め込みモデルを使用できます。
最新の AWS Python SDK を使用している場合は、次のコード例を使用して Amazon Bedrock を使用してテキストのベクトル埋め込みを生成できます。
これで、ベクトル埋め込みをベクトルインデックスに挿入し、クエリー埋め込みを使用してベクトルインデックスのベクトルをクエリできるようになりました。
ベクトルインデックスへのベクトルの挿入、ベクトルの一覧表示、クエリ、削除の詳細については、Amazon S3 ユーザーガイドの S3 ベクトルバケットと S3 ベクトルインデックスをご覧ください。さらに、S3 Vectors embed コマンドラインインターフェイス (CLI) を使用すると、Amazon Bedrock を使用してデータのベクトル埋め込みを作成し、1 つのコマンドで S3 ベクトルインデックスに保存してクエリすることができます。詳細については、S3 Vectors Embed CLI GitHub リポジトリを参照してください。
S3 Vectors を他の AWS サービスと統合
S3 Vectors は、Amazon Bedrock、Amazon SageMaker、Amazon OpenSearch Service などの他の AWS サービスと統合することで、ベクトル処理機能を強化し、AI ワークロード向けの包括的なソリューションを提供します。
S3 Vectors を使用して Amazon Bedrock ナレッジベースを作成
Amazon Bedrock ナレッジベースで S3 Vectors を使用すると、RAG アプリケーションのベクトルストレージのコストを簡素化および削減できます。Amazon Bedrock コンソールでナレッジベースを作成する場合、ベクトルストアのオプションとして S3 ベクトルバケットを選択できます。
Step 3 では、Vector store creation method を選択して S3 ベクトルバケットとベクトルインデックスを作成するか、以前に作成した既存の S3 ベクトルバケットとベクトルインデックスを選択できます。
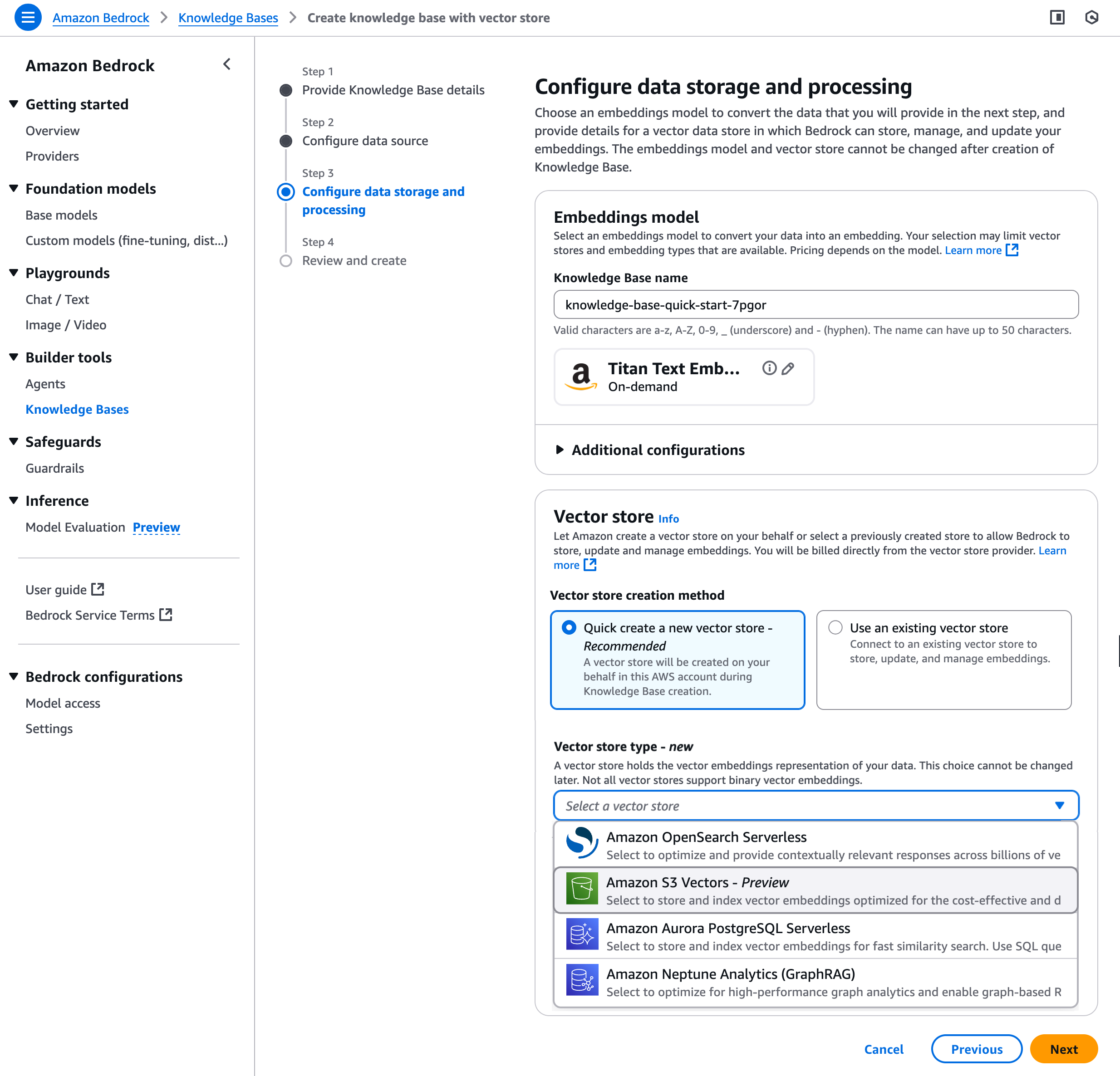
詳細な手順については、Amazon Bedrock ユーザーガイドの Create a knowledge base by connecting to a data source in Amazon Bedrock Knowledge Bases を参照してください。
Amazon SageMaker Unified Studio を使用する
Amazon Bedrock を使用して生成 AI アプリケーションを構築すると、Amazon SageMaker Unified Studio で S3 Vectors を使用してナレッジベースを作成および管理できます。SageMaker Unified Studio は次世代の Amazon SageMaker で利用でき、Amazon Bedrock ナレッジベースを使用する生成 AI アプリケーションの構築やテキスト送信など、データと AI の統合開発環境を提供します。

生成 AI アプリケーションを構築する時に、Amazon Bedrock で作成された S3 Vectors を使用してナレッジベースを選択できます。詳細については、Amazon SageMaker Unified Studio ユーザーガイドの Add a data source to your Amazon Bedrock app をご覧ください。
S3 ベクトルデータを Amazon OpenSearch サービスにエクスポートする
長期的に利用するベクトルデータを Amazon S3 にコスト効率よく保存する一方で、優先度高く利用したいベクトルを OpenSearch にエクスポートしてリアルタイムのクエリパフォーマンスを実現する階層型戦略を採用することで、コストとパフォーマンスのバランスを取ることができます。
この柔軟性により、組織は OpenSearch の高パフォーマンス (高 QPS、低遅延) を利用して、製品の推奨や不正検出などの重要なリアルタイムアプリケーションにアクセスでき、時間的制約の少ないデータを S3 Vectors に保存できます。
ベクトルインデックスをエクスポートするには、Advanced search export を選択し、次に Amazon S3 コンソールで Export to OpenSearch を選択します。
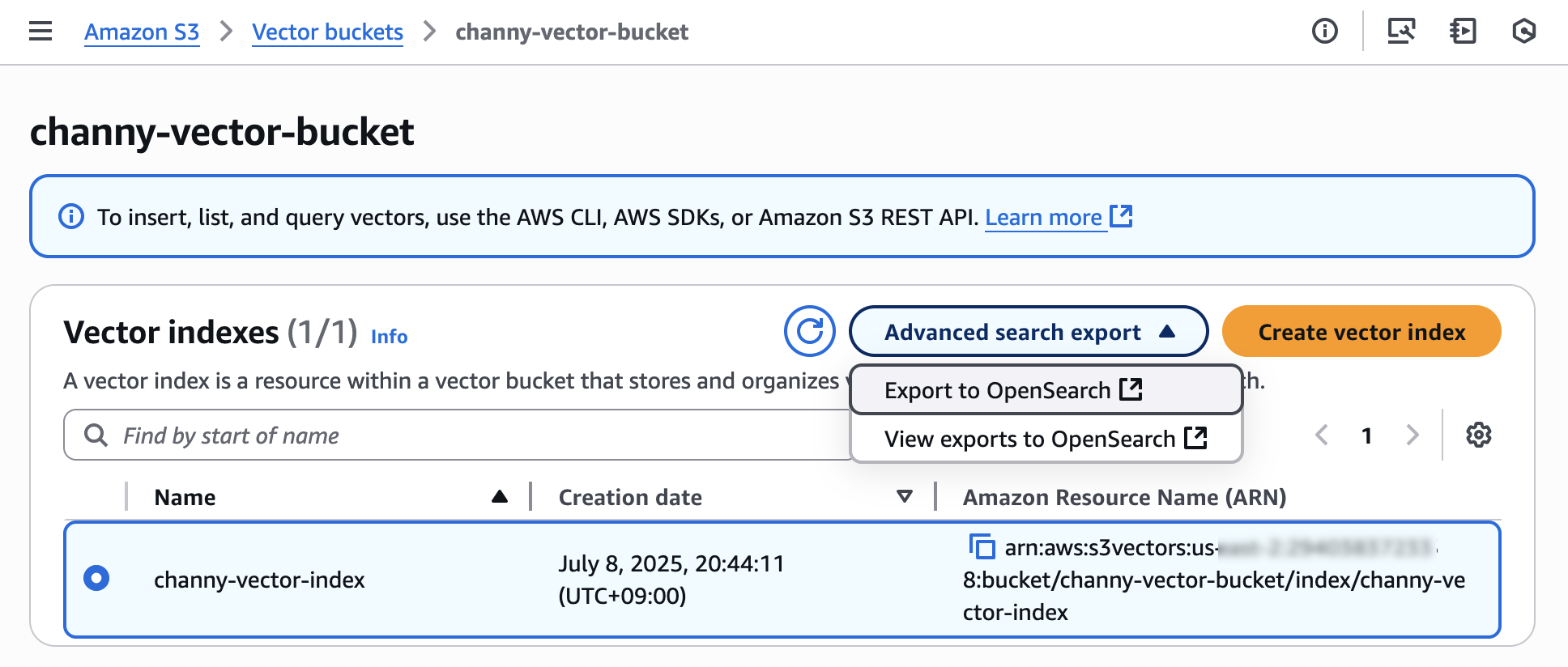
次に、OpenSearch ベクトルエンジンに S3 ベクトルインデックスをエクスポートするためのテンプレートを含む Amazon OpenSearch サービス統合コンソールが表示されます。事前に選択した S3 ベクトルソースとサービスアクセスロールを使用してエクスポートを選択します。
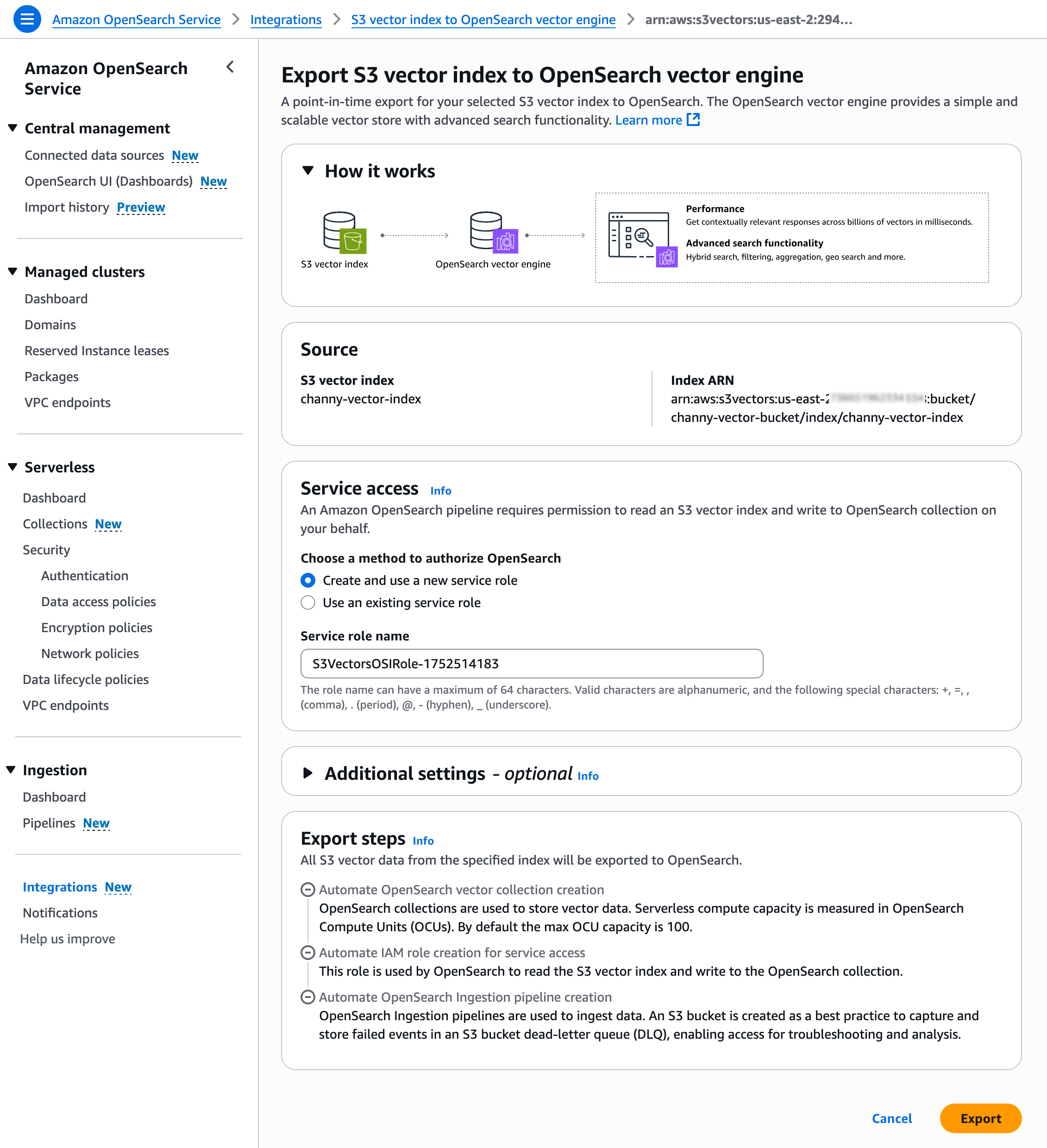
これで、新しい OpenSearch Serverless コレクションを作成し、S3 ベクトルインデックスから OpenSearch k-NN インデックスにデータを移行する手順が開始されます。
左側のナビゲーションペインで Import history を選択します。S3 ベクトルインデックスのベクトルデータを OpenSearch Serverless コレクションにコピーするために作成された新しいインポートジョブが表示されます。
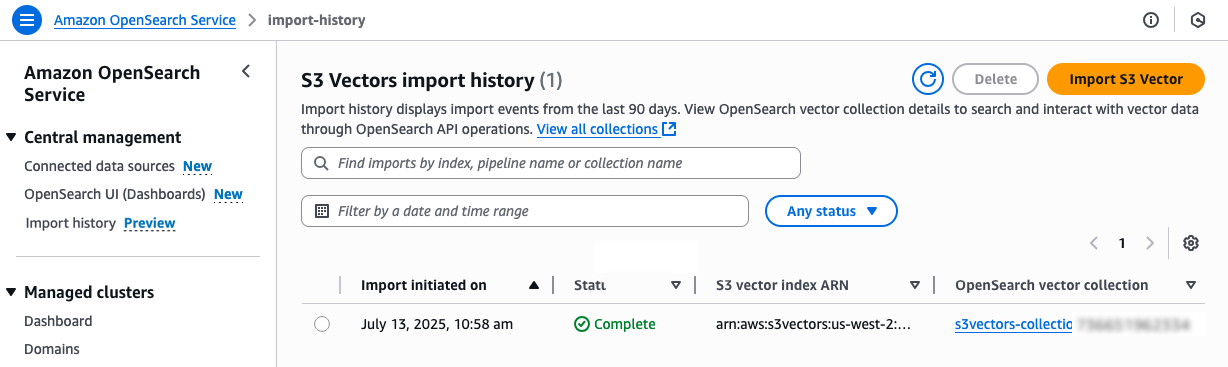
ステータスが Complete に変わったら、新しい OpenSearch Serverless コレクションに接続して、新しい OpenSearch knn インデックスをクエリできます。
詳細については、Amazon OpenSearch サービス開発者ガイドの Creating and managing Amazon OpenSearch Serverless collections をご覧ください。
今すぐご利用いただけます
Amazon S3 Vectors、および Amazon Bedrock、Amazon OpenSearch Service、Amazon SageMaker との統合は、現在、米国東部 (バージニア北部)、米国東部 (オハイオ)、米国西部 (オレゴン)、ヨーロッパ (フランクフルト)、およびアジアパシフィック (シドニー) の各リージョンでプレビュー段階にあります。
今すぐ Amazon S3 コンソールで S3 Vectors を試してみて、AWS re:Post for Amazon S3 か通常の AWS サポートの連絡先を通じてフィードバックを送ってください。
この記事を読んでいただきありがとうございました。
翻訳はクラウドサポートエンジニアの黒川が担当しました。