Amazon Web Services ブログ
Amazon OpenSearch Service が AI 検索イノベーションを加速するフロービルダーをリリース
本記事は 2025 年 5 月 2 日 に公開された「Amazon OpenSearch Service launches flow builder to empower rapid AI search innovation」を翻訳したものです。
OpenSearch 2.19 以降のドメインで Amazon OpenSearch Service の AI 検索フロービルダーにアクセスし、AI 検索アプリケーションのイノベーションをより迅速に開始できるようになりました。ビジュアルデザイナーを通じて、カスタム AI 検索フロー (取り込みと検索時に実行される一連の AI 駆動データエンリッチメント) を設定できます。これらの AI 検索フローを OpenSearch 上で構築・実行することで、カスタムミドルウェアを構築・保守することなく、OpenSearch 上で AI 検索アプリケーションを動かすことができます。
アプリケーションは、ビジネス成果を向上させるために、AI と検索を活用してユーザーインタラクション、コンテンツ発見、自動化を再発明し改善しています。これらのイノベーションは、AI 検索フローを実行して、セマンティック検索、クロス言語検索、コンテンツ理解を通じて関連情報を発見し、個々の行動に合わせて情報ランキングを適応させ、回答を特定するためのガイド付き会話を可能にします。しかし、検索エンジンはネイティブの AI 強化検索サポートに限界があるため、開発者は機能的なギャップを埋めるために検索エンジンを補完するミドルウェアを開発しています。このミドルウェアは、ユースケース、データセット、要件に合わせてデータ変換、検索クエリ、AI エンリッチメントをさまざまな組み合わせでつなぎ合わせるデータフローを実行するカスタムコードで構成されています。
OpenSearch 用の新しい AI 検索フロービルダーにより、OpenSearch 上で AI 検索フローを設計・実行するための協調環境が提供されます。ビジュアルデザイナーは OpenSearch Dashboards の AI Search Flows にあり、セマンティック検索、マルチモーダル検索、ハイブリッド検索、検索拡張生成 (RAG) などの一般的なユースケース向けの事前設定されたフローテンプレートを起動することで、すぐに開始できます。設定を通じて、Amazon Bedrock、Amazon SageMaker、Amazon Comprehend、OpenAI、DeepSeek、Cohere などの AI プロバイダーを使用して検索とインデックスプロセスをエンリッチするカスタムフローを作成できます。フローは、OpenSearch の既存の取り込み、インデックス、ワークフロー、検索 API を通じて、任意の OpenSearch 2.19 以降のクラスターにプログラムでエクスポート、デプロイ、スケーリングできます。
この記事の残りの部分では、フロービルダーを実演するいくつかのシナリオを説明します。まず、クライアント側のコード変更なしで、既存のキーワードベースの OpenSearch アプリケーションでセマンティック検索を有効にします。次に、マルチモーダル RAG フローを作成し、アプリケーション内で画像発見を再定義する方法を紹介します。
AI 検索フロービルダーの主要概念
始める前に、いくつかの主要概念を説明します。フロービルダーは API またはビジュアルデザイナーを通じて使用できます。ビジュアルデザイナーは、ワークフロープロジェクトの管理に役立つため推奨されます。各プロジェクトには、少なくとも 1 つの取り込みフローまたは検索フローが含まれます。フローはプロセッサリソースのパイプラインです。各プロセッサは、テキストをベクトル埋め込みにエンコードしたり、チャットボット AI サービスで検索結果を要約したりするなど、特定のタイプのデータ変換を適用します。
取り込みフローは、データがインデックスに追加される際にデータをエンリッチするために作成されます。以下で構成されます。
- インデックスに登録するドキュメントのデータサンプル
- 取り込まれたドキュメントに変換を適用するプロセッサのパイプライン
- 処理されたドキュメントから構築されたインデックス
検索フローは、検索リクエストと結果を動的にエンリッチするために作成されます。以下で構成されます。
- 検索 API に基づくクエリインターフェース。フローのクエリ方法と実行方法を定義します
- リクエストコンテキストまたは検索結果を変換するプロセッサのパイプライン
一般的に、プロトタイプから本番環境への道のりは、AI コネクタをデプロイし、データサンプルからフローを設計し、開発クラスターからフローをエクスポートして本番前環境で大規模テストを行うことから始まります。
シナリオ 1: クライアント側のコード変更なしで OpenSearch アプリケーションでセマンティック検索を有効にする
このシナリオでは、10 年前に OpenSearch 上に構築された製品カタログがあります。検索品質を改善し、購入を増加させることを目指しています。カタログには検索品質の問題があり、例えば「NBA」で検索してもバスケットボール関連商品が表示されません。また、アプリケーションは 10 年間手つかずのため、リスクと実装工数を削減するためにクライアント側のコード変更を避けることを目指しています。
ソリューションには以下が必要です。
- 既存のインデックス内のテキストからテキスト埋め込み (ベクトル) を生成する取り込みフロー
- 検索語をテキスト埋め込みにエンコードし、キーワードタイプの match クエリを k-NN (ベクトル) クエリに動的に書き換えて、エンコードされた語句でセマンティック検索を実行する検索フロー。この書き換えにより、アプリケーションはキーワードタイプのクエリを通じて透過的にセマンティックタイプのクエリを実行できます
また、クロスエンコーダーを使用して結果を再ランク付けする第 2 段階の再ランキングフローも評価します。これにより検索品質が向上する可能性があります。
フロービルダーを使用してタスクを達成します。まず、OpenSearch Dashboard の AI Search Flows に移動し、テンプレートカタログから Semantic Search を選択します。
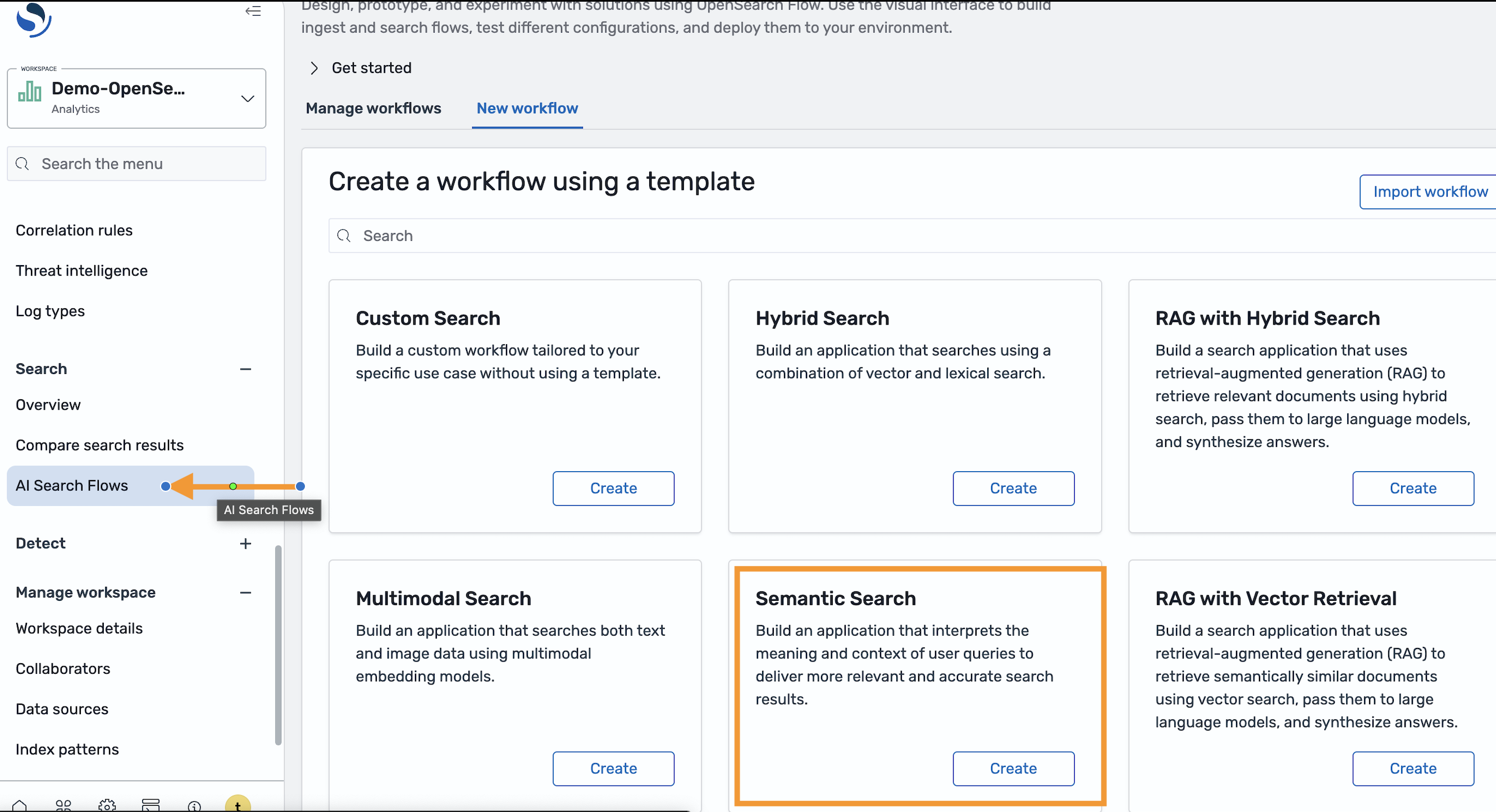
このテンプレートでは、テキスト埋め込みモデルを選択する必要があります。前提条件としてデプロイされた Amazon Bedrock Titan Text を使用します。テンプレートを設定すると、デザイナーのメインインターフェースに入ります。プレビューから、テンプレートが事前設定された取り込みフローと検索フローで構成されていることがわかります。
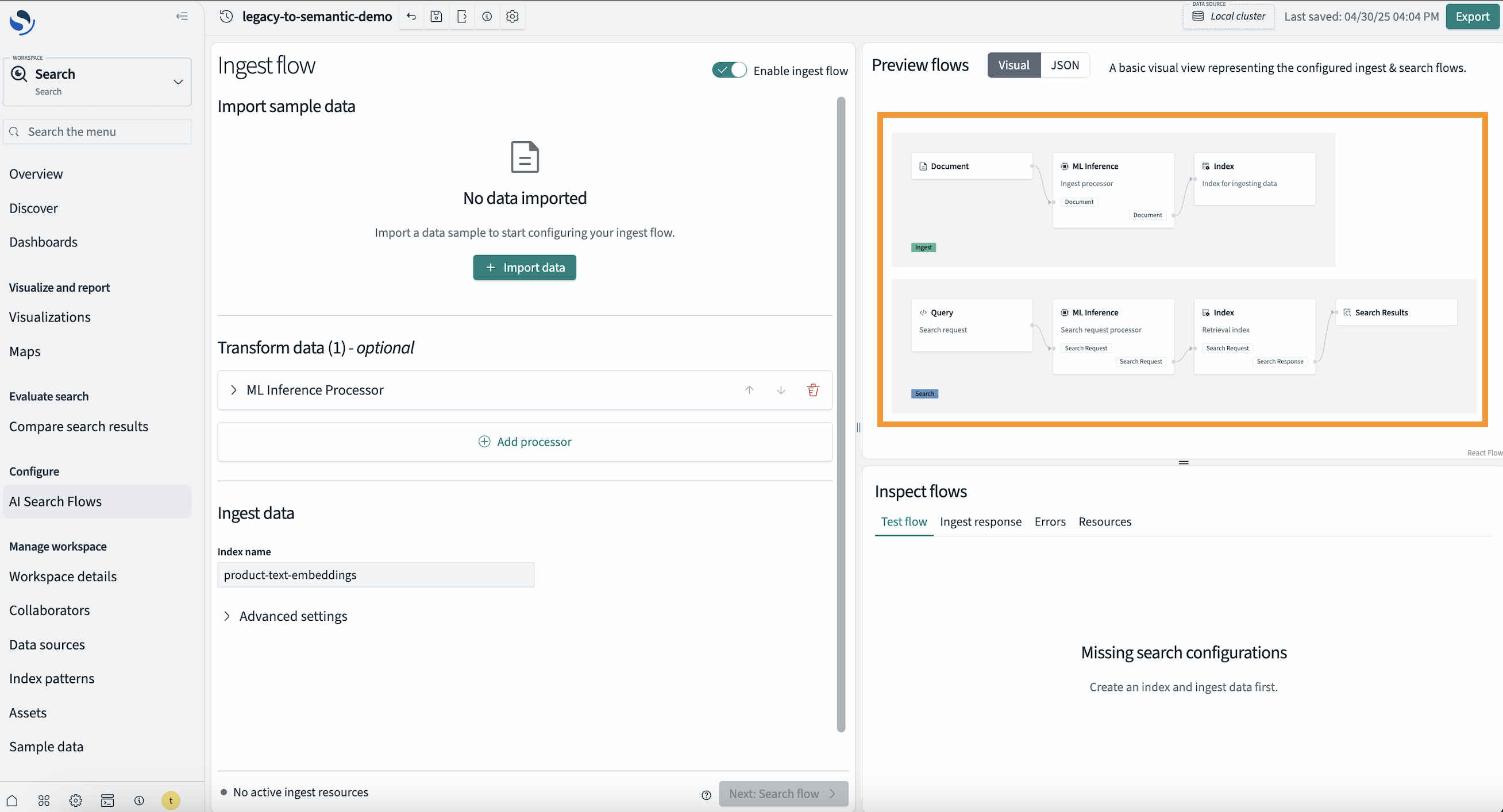
取り込みフローでは、データサンプルを提供する必要があります。製品カタログは現在、Amazon 製品データセットを含むインデックスによって提供されているため、このインデックスからデータサンプルをインポートします。

取り込みフローには ML Inference Ingest Processor が含まれており、データが OpenSearch に取り込まれる際に埋め込み (ベクトル) などの機械学習 (ML) モデル出力を生成します。前述の設定どおり、プロセッサは Amazon Titan Text を使用してテキスト埋め込みを生成するように設定されています。製品説明を保持するデータフィールドをモデルの inputText フィールドにマッピングして、埋め込み生成を有効にします。

これで取り込みフローを実行でき、データサンプルの埋め込みを含む新しいインデックスが構築されます。インデックスの内容を検査して、埋め込みが正常に生成されたことを確認できます。

インデックスができたら、検索フローを設定できます。まず、基本的な match クエリに事前設定されているクエリインターフェースを更新します。プレースホルダー my_text を製品説明に置き換える必要があります。この更新により、検索フローはレガシーアプリケーションからのクエリに応答できるようになります。
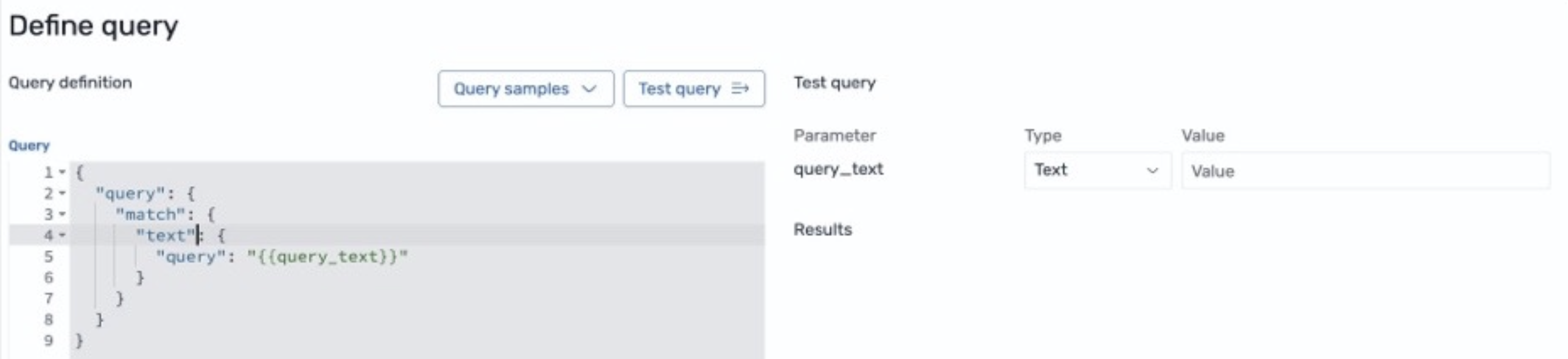
検索フローには ML Inference Search Processor が含まれています。前述の設定どおり、Amazon Titan Text を使用するように設定されています。Transform query の下に追加されているため、クエリリクエストに適用されます。この場合、検索語をテキスト埋め込み (クエリベクトル) に変換します。デザイナーはクエリインターフェースからの変数をリストし、検索語 (query.match.text.query) をモデルの inputText フィールドにマッピングできます。これにより、インデックスがクエリされるたびに検索語からテキスト埋め込みが生成されます。

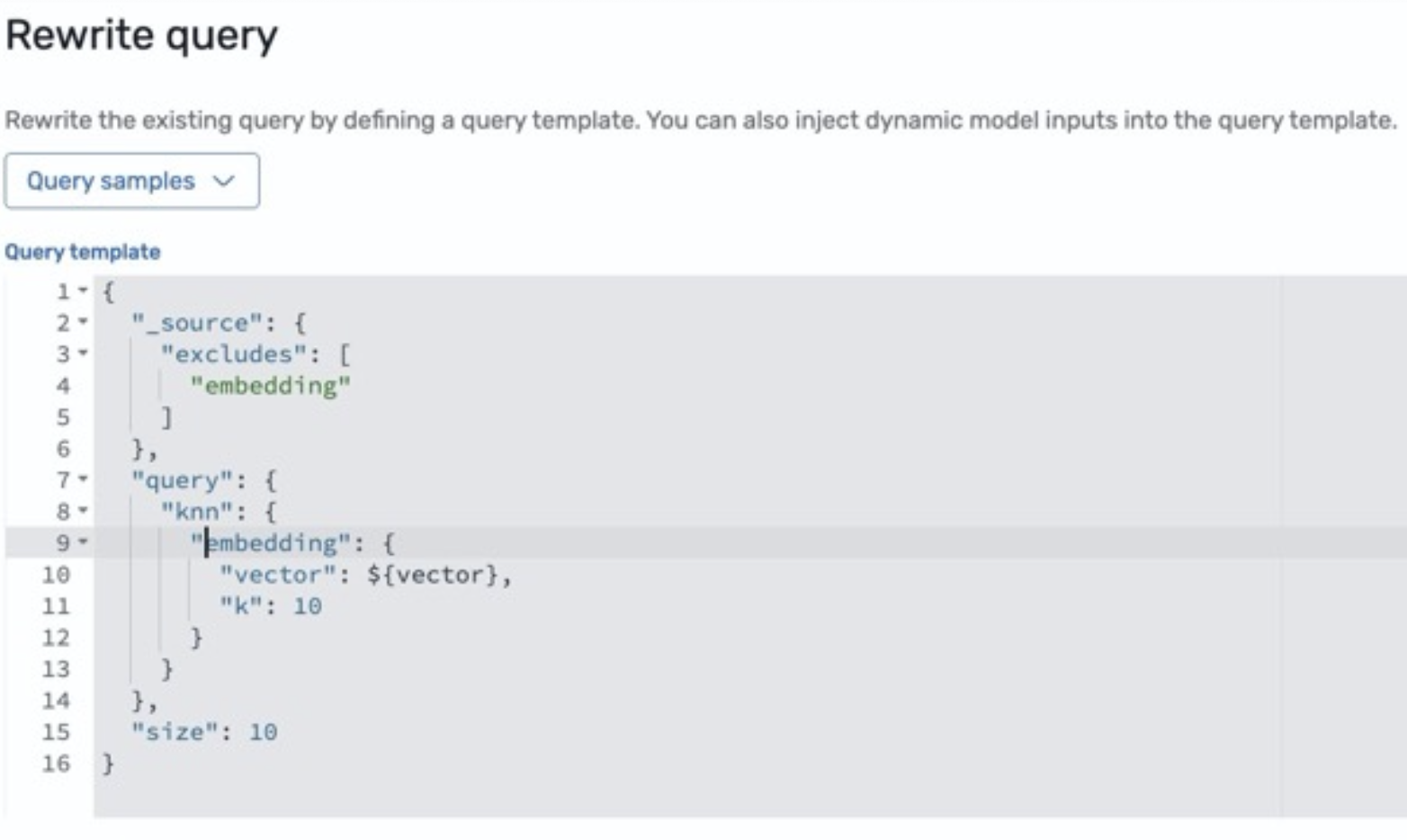
次に、match クエリを k-NN クエリに書き換えるように事前設定されているクエリ書き換え設定を更新します。プレースホルダー my_embedding を埋め込みに割り当てられたクエリフィールドに置き換えます。これをハイブリッドクエリなど別のクエリタイプに書き換えることもでき、検索品質が向上する可能性があります。
検索比較ツールからセマンティックソリューションとキーワードソリューションを比較してみましょう。「basketball」で検索すると、両方のソリューションでバスケットボール関連商品を見つけることができます。

しかし、「NBA」で検索するとどうなるでしょうか?セマンティック検索フローのみが結果を返します。これは「NBA」と「basketball」の間のセマンティックな類似性を検出するためです。

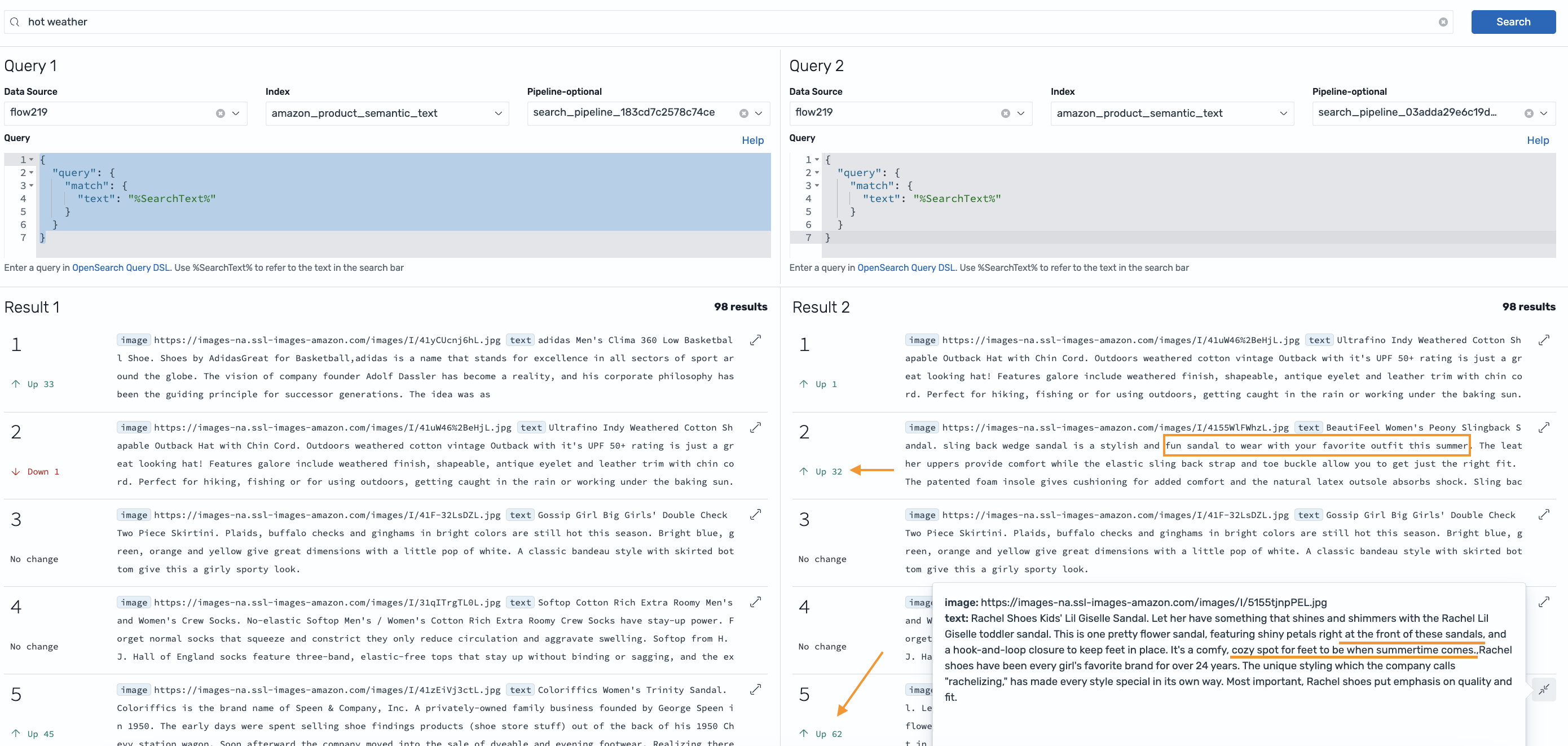
改善を達成しましたが、さらに良くできるかもしれません。クロスエンコーダーで検索結果を再ランク付けすることで改善できるか見てみましょう。Transform response の下に ML Inference Search Processor を追加して、プロセッサが検索結果に適用されるようにし、Cohere Rerank を選択します。デザイナーから、Cohere Rerank にはドキュメントのリストとクエリコンテキストが入力として必要であることがわかります。検索結果を Cohere Rerank で処理できる形式にパッケージ化するためにデータ変換が必要です。そこで、JSONPath 式を適用してクエリコンテキストを抽出し、データ構造をフラット化し、ドキュメントから製品説明をリストにパックします。
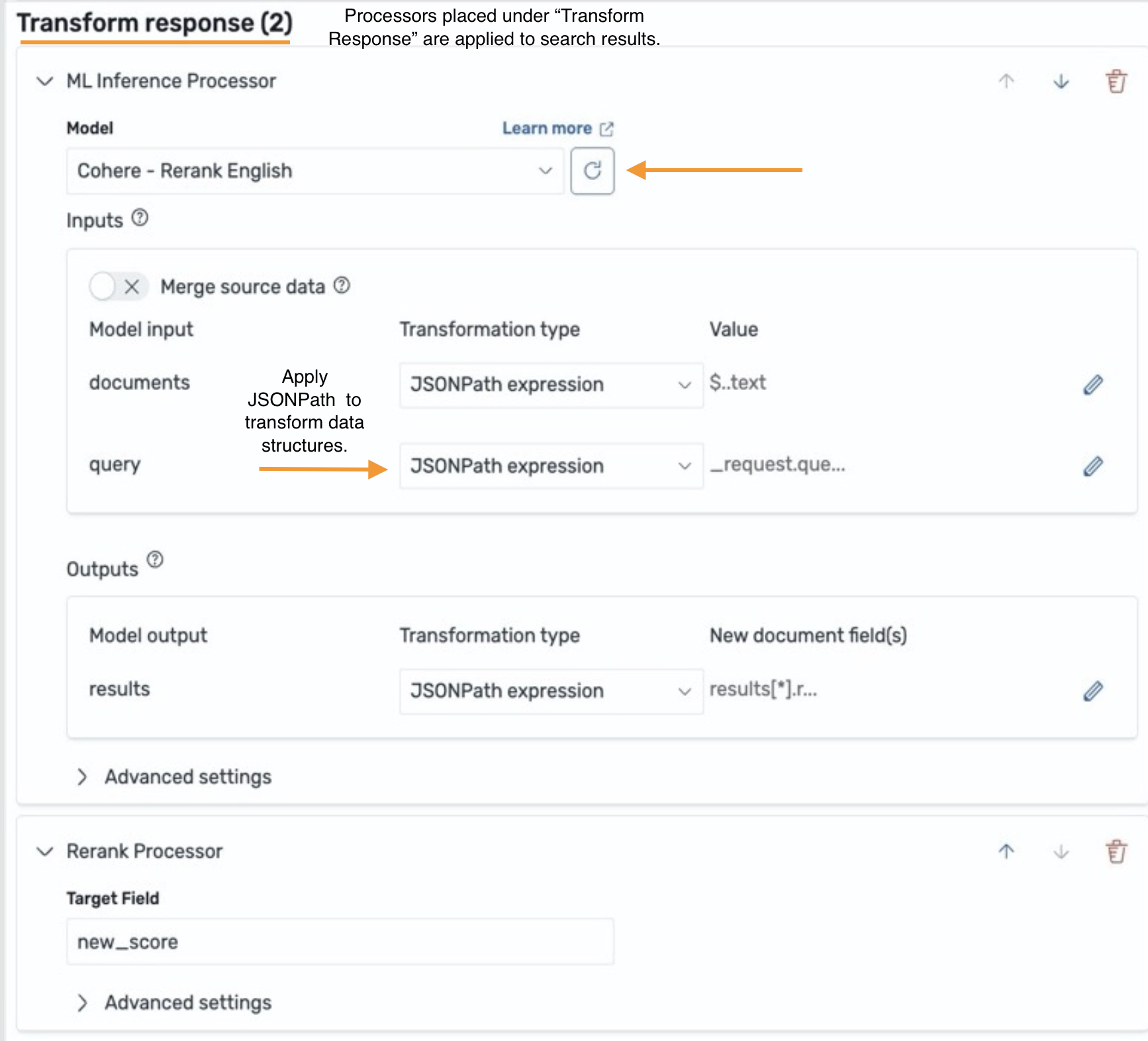
検索比較ツールに戻って、フローのバリエーションを比較してみましょう。以前の「basketball」と「NBA」の検索では意味のある違いは観察されません。しかし、「hot weather」で検索すると改善が観察されます。右側では、2 番目と 5 番目の検索ヒットがそれぞれ 32 位と 62 位上昇し、「hot weather」に適した「sandals」が返されています。
本番環境に進む準備ができたので、開発クラスターから本番前環境にフローをエクスポートし、ワークフロー API を使用してフローを自動化に統合し、バルク、取り込み、検索 API を通じてテストプロセスをスケーリングします。
シナリオ 2: 生成 AI を使用して画像検索を再定義し向上させる
このシナリオでは、数百万のファッションデザインの写真があります。メンテナンスの少ない画像検索ソリューションを探しています。生成マルチモーダル AI を使用して画像検索を近代化し、画像タグやその他のメタデータを維持するための労力を排除します。
ソリューションには以下が必要です。
- Amazon Titan Multimodal Embeddings G1 などのマルチモーダルモデルを使用して画像埋め込みを生成する取り込みフロー
- マルチモーダルモデルでテキスト埋め込みを生成し、テキストから画像へのマッチングのために k-NN クエリを実行し、マッチした画像をテキストと画像を処理できる Anthropic の Claude Sonnet 3.7 などの生成モデルに送信する検索フロー
RAG with Vector Retrieval テンプレートから始めます。このテンプレートを使用すると、基本的な RAG フローをすばやく設定できます。テンプレートには、テキストと画像コンテンツを処理できる埋め込みモデルと大規模言語モデル (LLM) が必要です。それぞれ Amazon Bedrock Titan Multimodal G1 と Anthropic の Claude Sonnet 3.7 を使用します。
デザイナーのプレビューパネルから、このテンプレートとセマンティック検索テンプレートの類似点がわかります。同様に、取り込みフローにデータサンプルをシードします。前の例と同様に Amazon 製品データセットを使用しますが、モデルが base64 画像を必要とし、このソリューションではテキストが不要なため、製品説明を base64 エンコードされた画像に置き換えます。base64 画像データを対応する Amazon Titan G1 入力にマッピングして埋め込みを生成します。次に、取り込みフローを実行し、インデックスに base64 画像と対応する埋め込みが含まれていることを確認します。

この検索フローを設定する最初のステップは前のシナリオと似ています。クエリインターフェースを更新し、ML Inference Search Processor のモデル入力にクエリテキストフィールドをマッピングし、クエリ書き換え設定を修正します。このフローの主な違いは、画像を処理するために Anthropic の Claude Sonnet 3.7 を使用するように設定された追加のレスポンスプロセッサです。
クエリコンテキストと、LLM がファッションアドバイザーの役割を果たし、画像ペイロードについてコメントを提供するための指示を含む LLM プロンプトを設定する必要があります。
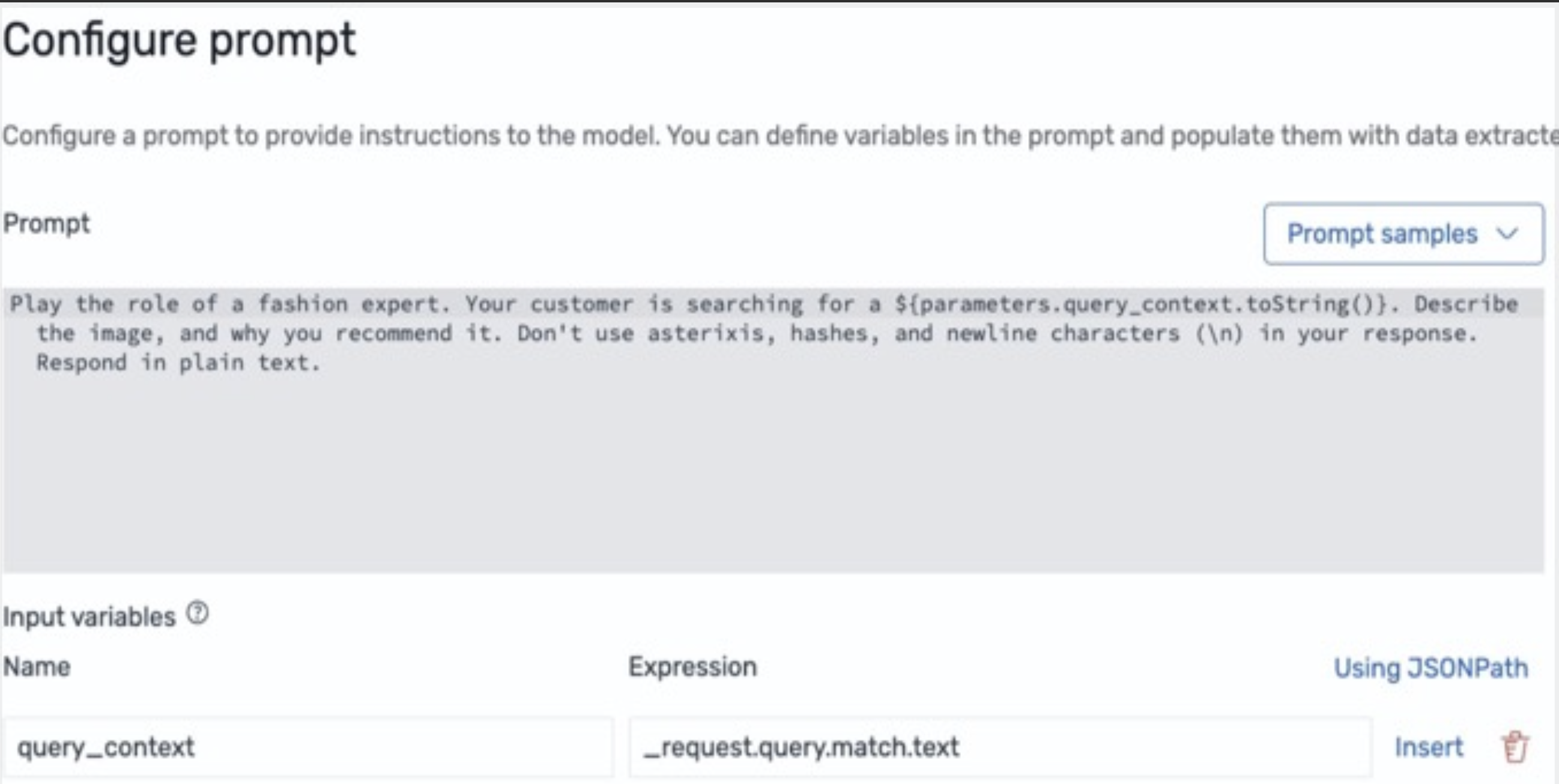
次に、プロンプトと base64 画像データフィールドをモデルの入力に適切にマッピングします。

「sunset colored dresses」で検索してマルチモーダル RAG フローをテストしてみましょう。以下の結果が観察されます。
 |
この美しいドレスは、ゴージャスなオンブレカラーグラデーションで夕焼けの本質を完璧に捉えています。トップの柔らかいピーチピンクから始まり、中央で鮮やかなオレンジに移行し、裾で明るい黄色で終わります。まさに太陽が地平線の下に沈むときの空の色のようです。このドレスは、短いキャップスリーブを備えたシンプルでカジュアルなシルエットが特徴で、多くの体型に似合う快適でリラックスしたフィット感があるようです。タイダイ効果は、夏のお出かけ、ビーチバケーション、カジュアルな夜のイベントに最適なボヘミアンで気楽な雰囲気を与えます。この夕焼け色のドレスは、目を引き、汎用性があり、あらゆる機会を明るくする魔法のような夕焼けの輝きを体現しているため、お勧めします。この色は特に暖かい肌のトーンによく合い、ゴールドのアクセサリーで簡単にドレスアップしたり、シンプルなサンダルでカジュアルに保つことができます。 |
 |
この鮮やかなタイダイドレスは、美しい色のグラデーションで夕焼けの本質を完璧に捉えています。ドレスには、ゴールデンイエロー、ファイアリーオレンジ、リッチピンクのバンドがシームレスにブレンドされており、夕暮れ時の空を思わせます。ストラップレスのデザインは肩をエレガントに見せ、ギャザーウエストは快適な膝丈スカートに流れる魅力的なシルエットを作り出します。このドレスは、夏のイベント、ビーチバケーション、カジュアルなお出かけに最適な選択です。夕焼けのカラーパレットはトレンドであるだけでなく、ニュートラルなアクセサリーと合わせるのに十分な汎用性があります。目を引く色、快適なフィット感、美しい夕焼けを眺めるような暖かくリラックスした感覚を体現しているため、このアイテムをお勧めします。 |
画像メタデータなしで、OpenSearch は夕焼け色のドレスの画像を見つけ、正確でカラフルなコメントで応答します。
まとめ
AI 検索フロービルダーは、OpenSearch Service で OpenSearch 2.19 以降をサポートするすべての AWS リージョンで利用できます。詳細については、Building AI search workflows in OpenSearch Dashboards と、Amazon Bedrock、SageMaker、その他の AWS およびサードパーティ AI サービスからさまざまな AI モデルを統合する方法を示す GitHub のチュートリアルを参照してください。
著者について
 Dylan Tong は、Amazon Web Services のシニアプロダクトマネージャーです。OpenSearch のベクトルデータベース機能を含む、OpenSearch の AI および機械学習 (ML) の製品イニシアチブをリードしています。Dylan は、データベース、アナリティクス、AI/ML 分野で顧客と直接協力し、製品やソリューションを作成してきた数十年の経験があります。Dylan はコーネル大学でコンピュータサイエンスの学士号と修士号を取得しています。
Dylan Tong は、Amazon Web Services のシニアプロダクトマネージャーです。OpenSearch のベクトルデータベース機能を含む、OpenSearch の AI および機械学習 (ML) の製品イニシアチブをリードしています。Dylan は、データベース、アナリティクス、AI/ML 分野で顧客と直接協力し、製品やソリューションを作成してきた数十年の経験があります。Dylan はコーネル大学でコンピュータサイエンスの学士号と修士号を取得しています。
 Tyler Ohlsen は、Amazon Web Services のソフトウェアエンジニアで、主に OpenSearch の Anomaly Detection と Flow Framework プラグインに注力しています。
Tyler Ohlsen は、Amazon Web Services のソフトウェアエンジニアで、主に OpenSearch の Anomaly Detection と Flow Framework プラグインに注力しています。
 Mingshi Liu は、OpenSearch の機械学習エンジニアで、主に OpenSearch、ML Commons、Search Processors リポジトリに貢献しています。検索技術やその他のオープンソースプロジェクト向けの機械学習機能の開発と統合に注力しています。
Mingshi Liu は、OpenSearch の機械学習エンジニアで、主に OpenSearch、ML Commons、Search Processors リポジトリに貢献しています。検索技術やその他のオープンソースプロジェクト向けの機械学習機能の開発と統合に注力しています。
 Ka Ming Leung (Ming) は、OpenSearch のシニア UX デザイナーで、ML を活用した検索開発者エクスペリエンス、およびオブザーバビリティとクラスター管理機能の設計に注力しています。
Ka Ming Leung (Ming) は、OpenSearch のシニア UX デザイナーで、ML を活用した検索開発者エクスペリエンス、およびオブザーバビリティとクラスター管理機能の設計に注力しています。
この記事は Kiro が翻訳を担当し、Solutions Architect の 榎本 貴之 がレビューしました。