AWS for M&E Blog
Using Amazon S3 Vectors (preview) to semantically search using a media lake on AWS
Many media organizations face challenges in managing and discovering content across their digital libraries. Relying on manual searches of file names, or folder structures, can result in duplicated work and underutilized assets—impacting productivity and content monetization opportunities for re-using and creating content.
The emergence of AI-powered semantic search introduces complexity and cost considerations for media workflows. Traditional vector databases can struggle to scale efficiently when processing high volumes of media. A single hour of video content can generate over 5,400 vector embeddings when analyzed at two-second intervals, resulting in datasets that quickly reach millions of vectors for media libraries.
Current vector storage solutions often require organizations to choose between cost and performance. Many are unable to scale from proof-of-concept implementations (handling thousands of vectors) to production systems (managing hundreds of millions). This limitation becomes particularly problematic when organizations need to find key moments in video within seconds of them occurring. Implementing custom face indexing or enabling multimodal understanding to traditional systems could cause the cost of vector storage, and similarity search, to exceed the value that enhanced discovery capabilities can deliver.
We will demonstrate how to build a natural language search solution for media assets using an Amazon Simple Storage Service (Amazon S3) Vectors bucket, the TwelveLabs Marengo embedding model on Amazon Bedrock, and the Guidance for a media lake on Amazon Web Services (AWS). We will walk through the architecture and implementation steps that enable natural language search across images, video, and audio content on a serverless infrastructure. We will show how to configure pipelines in a media lake, generate multimodal embeddings, store them in an S3 Vectors (preview) bucket, and perform similarity searches returning all relevant media assets.
Amazon S3 Vectors (preview)
Amazon S3 Vectors (preview) is a feature of Amazon S3 that provides cost effective vector storage and is the first cloud object store with built-in support to store and query vectors at massive scale. S3 Vectors (preview) is designed for highly elastic and durable storage of large vector datasets with sub-second query performance and is ideal for infrequent query workloads.
With S3 Vectors (preview) you can make any piece of video data quarriable, without having to worry about the long-term vector storage cost. This is particularly valuable for extensive, evolving content libraries where users want to preserve their treasured footage forever. S3 Vectors (preview) delivers the perfect balance between price and performance, helping you reduce costs for uploading, storing, and querying vector embeddings by up to 90 percent, without compromising on the customer experience.
S3 Vectors (preview) introduces vector buckets, a new bucket type with a dedicated set of APIs to store, access, and query vector data without provisioning any infrastructure. Within a vector bucket, you can create a vector index without having to provision any infrastructure. It can elastically scale from zero to tens of millions of vector embeddings in a single vector index. Also, when adding vector data to a vector index, you can attach metadata to limit future queries based on a set of conditions (such as dates, categories, or user preferences).
TwelveLabs on Amazon Bedrock
TwelveLabs is revolutionizing how we interact with video data through cutting-edge multimodal foundation models that bring human-like understanding to visual content. Now available on Amazon Bedrock, the technology of TwelveLabs maps natural language to what’s happening inside videos—from actions and objects to background sounds. This assists developers in creating sophisticated applications that can search, classify, summarize, and extract insights with unprecedented accuracy.
At the heart of this innovation is the TwelveLabs foundation model Marengo, a video-native multimodal embedding model that unifies all modalities (videos, texts, images, and audio) into a single vector space. This breakthrough delivers state-of-the-art performance for any-to-any multimodal tasks (including semantic search, anomaly detection, and intelligent recommendations). Customers can now find exactly what they’re looking for in vast content libraries, moving far beyond basic tagging into a new dimension of contextual, multimodal understanding.
Guidance for a media lake on AWS
The Guidance for a media lake on AWS demonstrates how to build a unified media management solution using a serverless architecture that consolidates assets from multiple S3 buckets into a single, searchable catalog. The solution leverages Amazon CloudFront for content delivery, Amazon API Gateway for RESTful API management, and Amazon Cognito for user authentication.
At its core, a media lake can use Amazon DynamoDB and Amazon S3 Vectors (preview) as the primary metadata and embedding store for semantic search and filtering capabilities, while AWS Step Functions orchestrate media workflows through visual pipelines. Storage connectors enable integration with existing S3 buckets by utilizing Amazon EventBridge notifications and Amazon Simple Queue Service (Amazon SQS) for reliable event processing.
When new media arrives in connected buckets automated pipelines extract technical metadata, including resolution, codecs, bitrates, and duration. The automated pipelines can leverage AI-powered services for transcription and semantic search capabilities through vector embeddings.
Our media lake guidance can utilize semantic search capabilities, leveraging S3 Vectors (preview) native vector storage and similarity search functionality, to enable natural language queries across media assets. The architecture integrates Amazon Bedrock for embedding generation using the TwelveLabs Marengo model. This creates multimodal embeddings that capture visual, audio, and textual elements from media content.
When users search for assets, API Gateway routes requests through AWS Lambda functions that perform cosine similarity searches against the S3 Vector bucket. It returns the most relevant media assets based on semantic understanding, rather than keyword matching. This serverless approach eliminates the need for managing separate vector databases while providing scalable, cost-effective semantic search that grows seamlessly from thousands to millions of media assets.
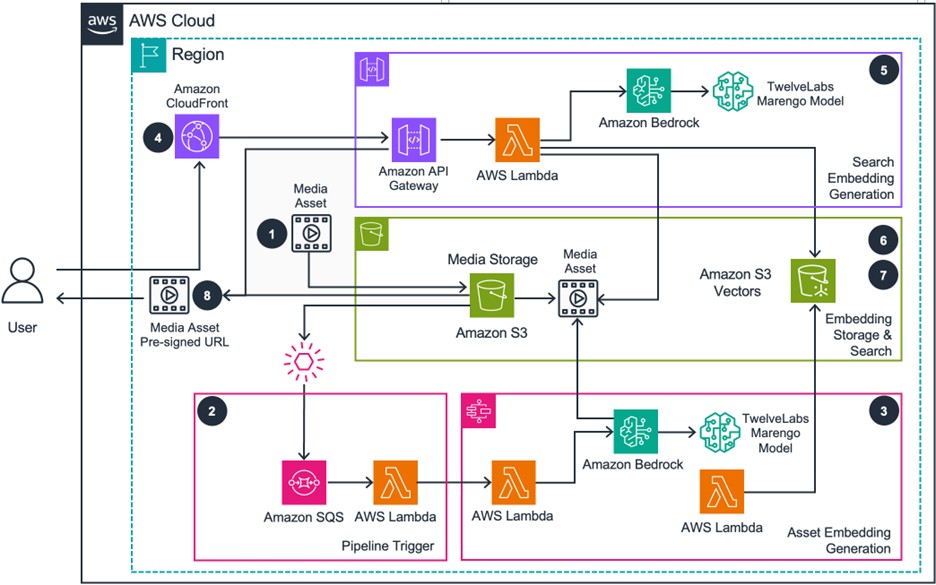
Figure 1: Guidance for a media lake on AWS utilizing S3 Vectors (preview) architecture.
Architecture walkthrough
The Guidance for a media lake on AWS enables semantic search by configuring S3 Vectors (preview) as the backend vector embedding store. The solution includes three pre-built pipelines that you can import and customize for your media workflows:
- TwelveLabs Marengo on Amazon Bedrock to S3 Vectors (preview) video pipeline: Generates embeddings for every 2-10 seconds in a video asset, users can set this through the media lakes user interface.
- TwelveLabs Marengo on Amazon Bedrock to S3 Vectors (preview) audio pipeline: Segments audio files into 10 second segments, submitting each segment to generate a new embedding for each 10 second segment.
- TwelveLabs Marengo on Amazon Bedrock to S3 Vectors (preview) image pipeline: Generates an embedding for each image.
Begin by enabling the TwelveLabs Marengo model on Amazon Bedrock through the AWS Management console. Import the S3 Vectors (preview) pipelines and enable TwelveLabs on Amazon Bedrock as your semantic search provider for your media lake. Your media assets will process through the following workflow:
- Media asset ingestion: When new media assets arrive in Amazon S3, Amazon S3 generates event notifications that trigger an ingest Lambda function. The media lake categorizes each asset by media type—image, audio, or video—and sends corresponding events to the analysis EventBridge event bus.
- Event routing and queue management: EventBridge rules route incoming events to dedicated Amazon SQS queues based on media type, with one queue for every pipeline. This architecture enables parallel processing across different media types, while Lambda functions provide concurrency control and throttle management to handle varying workload volumes.
- Embedding generation and storage: Lambda functions process events from their respective queues, sending each media asset to Amazon Bedrock for analysis. Amazon Bedrock generates embeddings using the TwelveLabs Marengo multimodal model, which captures visual, audio, and textual elements from the content. After processing completes, Lambda stores these vector embeddings in an S3 Vector bucket along with metadata—including the original S3 path and time codes for the audio/video content.
- User search interface: Users access the search interface through CloudFront, where they enter natural language queries, such as “aerial footage of city skylines at night” or “upbeat background music”. The interface provides advanced filtering options through metadata facets. Users can specify media types and other attributes to refine their searches.
- Search request processing: API Gateway receives search requests from CloudFront and triggers a Lambda function to process the query. This function sends the search string to Amazon Bedrock, which generates a text embedding using the same TwelveLabs Marengo model used during media ingestion, providing consistency between indexed content and search queries.
- Vector similarity search: Lambda performs a cosine similarity search using the text embedding against the stored embeddings in S3 Vectors (preview). The search leverages S3 Vectors (preview) native capabilities to find semantically similar content, returning the nearest neighbors vector embeddings along with metadata (including S3 object paths, relevance scores, and time codes for video and audio segments).
- Search results delivery: Lambda compiles the search results and generates pre-signed URLs for each matching asset. The API Gateway response includes relevance scores and time codes that help users jump directly to specific moments within video or audio files, providing secure, time-limited access to discovered assets through the media lake’s interface.
- Asset details timecode: When clicking on video and audio assets, users can see the time codes that are most relevant. Figure 2 shows the results for “A person walking down a runway in a silver dress”—selecting the first asset returned and showing the time codes.
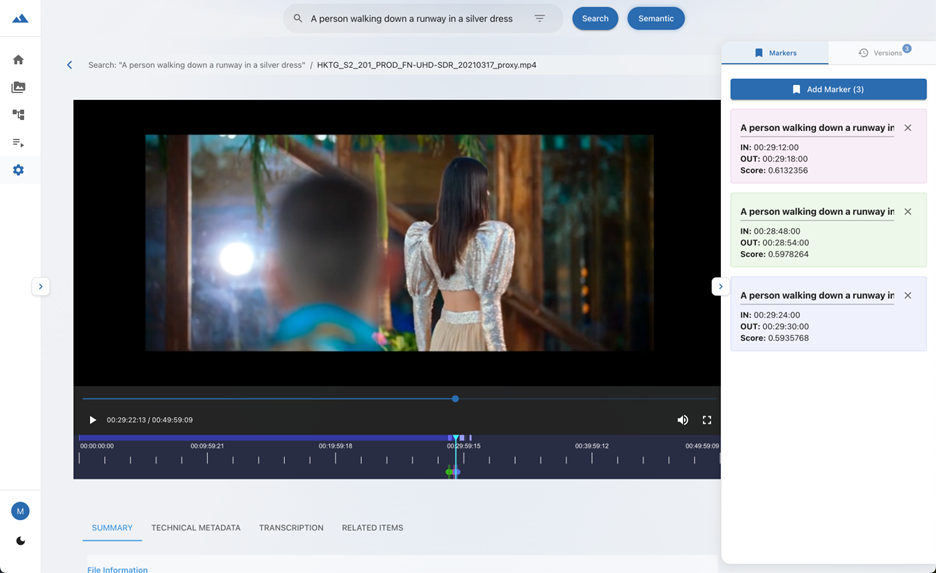
Figure 2: Asset detail screen after a semantic search.
Conclusion
Guidance for a media lake on AWS combines AWS managed services with AI models from TwelveLabs on Amazon Bedrock to enable natural language search across diverse media types. The serverless approach eliminates the operational overhead of managing separate vector databases while providing cost-effective scaling from thousands to millions of media assets.
By leveraging Amazon S3 Vectors (preview) native storage, and search capabilities with the TwelveLabs multimodal embedding model Marengo, organizations can implement semantic search without manual tagging or complex infrastructure management. Users will be able to discover relevant content and key moments in video and audio within seconds, reducing search time from hours to minutes while maintaining consistent performance as media libraries grow.
Contact an AWS Representative to know how we can help accelerate your business.