Artificial Intelligence
Category: AWS Trainium

Splash Music transforms music generation using AWS Trainium and Amazon SageMaker HyperPod
In this post, we show how Splash Music is setting a new standard for AI-powered music creation by using its advanced HummingLM model with AWS Trainium on Amazon SageMaker HyperPod. As a selected startup in the 2024 AWS Generative AI Accelerator, Splash Music collaborated closely with AWS Startups and the AWS Generative AI Innovation Center (GenAIIC) to fast-track innovation and accelerate their music generation FM development lifecycle.

How Amazon scaled Rufus by building multi-node inference using AWS Trainium chips and vLLM
In this post, Amazon shares how they developed a multi-node inference solution for Rufus, their generative AI shopping assistant, using Amazon Trainium chips and vLLM to serve large language models at scale. The solution combines a leader/follower orchestration model, hybrid parallelism strategies, and a multi-node inference unit abstraction layer built on Amazon ECS to deploy models across multiple nodes while maintaining high performance and reliability.
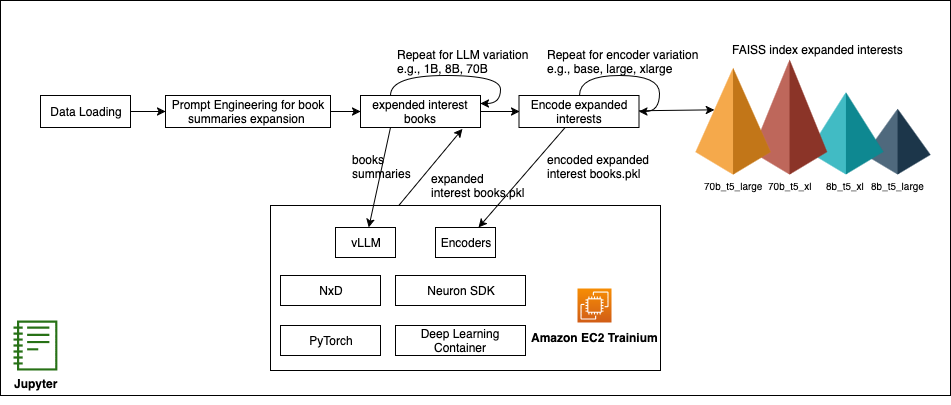
Boost cold-start recommendations with vLLM on AWS Trainium
In this post, we demonstrate how to use vLLM for scalable inference and use AWS Deep Learning Containers (DLC) to streamline model packaging and deployment. We’ll generate interest expansions through structured prompts, encode them into embeddings, retrieve candidates with FAISS, apply validation to keep results grounded, and frame the cold-start challenge as a scientific experiment—benchmarking LLM and encoder pairings, iterating rapidly on recommendation metrics, and showing clear ROI for each configuration

Enabling customers to deliver production-ready AI agents at scale
Today, I’m excited to share how we’re bringing this vision to life with new capabilities that address the fundamental aspects of building and deploying agents at scale. These innovations will help you move beyond experiments to production-ready agent systems that can be trusted with your most critical business processes.

How Rufus doubled their inference speed and handled Prime Day traffic with AWS AI chips and parallel decoding
Rufus, an AI-powered shopping assistant, relies on many components to deliver its customer experience including a foundation LLM (for response generation) and a query planner (QP) model for query classification and retrieval enhancement. This post focuses on how the QP model used draft centric speculative decoding (SD)—also called parallel decoding—with AWS AI chips to meet the demands of Prime Day. By combining parallel decoding with AWS Trainium and Inferentia chips, Rufus achieved two times faster response times, a 50% reduction in inference costs, and seamless scalability during peak traffic.

Cost-effective AI image generation with PixArt-Sigma inference on AWS Trainium and AWS Inferentia
This post is the first in a series where we will run multiple diffusion transformers on Trainium and Inferentia-powered instances. In this post, we show how you can deploy PixArt-Sigma to Trainium and Inferentia-powered instances.

How to run Qwen 2.5 on AWS AI chips using Hugging Face libraries
In this post, we outline how to get started with deploying the Qwen 2.5 family of models on an Inferentia instance using Amazon Elastic Compute Cloud (Amazon EC2) and Amazon SageMaker using the Hugging Face Text Generation Inference (TGI) container and the Hugging Face Optimum Neuron library. Qwen2.5 Coder and Math variants are also supported.

ByteDance processes billions of daily videos using their multimodal video understanding models on AWS Inferentia2
At ByteDance, we collaborated with Amazon Web Services (AWS) to deploy multimodal large language models (LLMs) for video understanding using AWS Inferentia2 across multiple AWS Regions around the world. By using sophisticated ML algorithms, the platform efficiently scans billions of videos each day. In this post, we discuss the use of multimodal LLMs for video understanding, the solution architecture, and techniques for performance optimization.

PEFT fine tuning of Llama 3 on SageMaker HyperPod with AWS Trainium
In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. We use HuggingFace’s Optimum-Neuron software development kit (SDK) to apply LoRA to fine-tuning jobs, and use SageMaker HyperPod as the primary compute cluster to perform distributed training on Trainium. Using LoRA supervised fine-tuning for Meta Llama 3 models, you can further reduce your cost to fine tune models by up to 50% and reduce the training time by 70%.

Serving LLMs using vLLM and Amazon EC2 instances with AWS AI chips
The use of large language models (LLMs) and generative AI has exploded over the last year. With the release of powerful publicly available foundation models, tools for training, fine tuning and hosting your own LLM have also become democratized. Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance […]