O blog da AWS
Processamento inteligente de documentos em grande escala com IA generativa e Amazon Bedrock Data Automation
Por Nikita Kozodoi, PhD, Senior Applied Scientist; Zainab Afolabi, Senior Data Scientist; Aiham Taleb, PhD, Senior Applied Scientist; Liza (Elizaveta) Zinovyeva, Applied Scientist; Nuno Castro, Sr. Applied Science Manager at AWS; Ozioma Uzoegwu, Principal Solutions Architect; Eren Tuncer, Solutions Architect and Francesco Cerizzi, Solutions Architect at Amazon Web Services.
Extrair informações de documentos não estruturados em grande escala é uma tarefa comercial recorrente. Casos de uso comuns incluem criar tabelas de características de produtos a partir de descrições, extrair metadados de documentos e analisar contratos legais, avaliações de clientes, artigos de notícias e muito mais. Uma abordagem clássica para extrair informações do texto é chamada de reconhecimento de entidades nomeadas (NER – Named Entity Recognition). O NER identifica entidades de categorias predefinidas, como pessoas e organizações. Embora vários serviços e soluções de IA ofereçam suporte ao NER, essa abordagem é limitada a documentos de texto e oferece suporte apenas a um conjunto fixo de entidades. Além disso, os modelos clássicos do NER não conseguem lidar com outros tipos de dados, como pontuações numéricas (como sentimento) ou texto de formato livre (como resumo). A IA generativa libera essas possibilidades sem anotações de dados caras ou treinamento de modelos, permitindo um processamento inteligente de documentos (IDP) mais abrangente.
Recentemente, a AWS anunciou a disponibilidade geral do Amazon Bedrock Data Automation, um recurso do Amazon Bedrock que automatiza a geração de informações valiosas a partir de conteúdo multimodal não estruturado, como documentos, imagens, vídeo e áudio. Esse serviço oferece recursos pré-construídos para IDP e extração de informações por meio de uma API unificada, eliminando a necessidade de engenharia de prompts complexa ou ajuste fino e tornando-o uma excelente opção para workflows de processamento de documentos em grande escala. Para saber mais sobre o Amazon Bedrock Data Automation, consulte Simplifique a IA generativa multimodal com o Amazon Bedrock Data Automation.
O Amazon Bedrock Data Automation é a abordagem recomendada para casos de uso de IDP devido à sua simplicidade, precisão líder do setor e recursos de serviços gerenciados. Ele lida com a complexidade da análise de documentos, gerenciamento de contexto e seleção de modelos automaticamente, para que os desenvolvedores possam se concentrar em sua lógica de negócios em vez de nos detalhes da implementação do IDP.
Embora o Amazon Bedrock Data Automation atenda à maioria das necessidades de IDP, algumas organizações exigem personalização adicional em seus pipelines de IDP. Por exemplo, as empresas podem precisar usar modelos de fundação (FMs) auto-hospedados para IDP devido aos requisitos regulatórios. Alguns clientes têm equipes de desenvolvedores que talvez prefiram manter o controle total sobre o pipeline do IDP em vez de usar um serviço gerenciado. Por fim, as organizações podem operar em regiões da AWS onde o Amazon Bedrock Data Automation não está disponível (disponível em us-west-2 e us-east-1 a partir de junho de 2025). Nesses casos, os desenvolvedores podem usar os Amazon Bedrock FMs diretamente ou realizar reconhecimento óptico de caracteres (OCR) com o Amazon Textract.
Esta postagem apresenta um aplicativo de IDP de ponta a ponta desenvolvido pelo Amazon Bedrock Data Automation e outros serviços da AWS. Ele fornece uma infraestrutura reutilizável da AWS como código (IaC) que implanta um pipeline de IDP e fornece uma interface de usuário intuitiva para transformar documentos em tabelas estruturadas em grande escala. O aplicativo exige apenas que o usuário forneça os documentos de entrada (como contratos ou e-mails) e uma lista de atributos a serem extraídos. Em seguida, ele executa o IDP com IA generativa.
O código de exemplo e as instruções de implantação estão disponíveis no GitHub sob a licença MIT.
Visão geral da solução
A solução de IDP apresentada neste post é implantada como IaC usando o AWS Cloud Development Kit (AWS CDK). O Amazon Bedrock Data Automation serve como o principal mecanismo para extração de informações. Para casos que exigem mais personalização, a solução também fornece caminhos alternativos de processamento usando a integração do Amazon Bedrock FMs e do Amazon Textract.
Usamos o AWS Step Functions para orquestrar o fluxo de trabalho do IDP e paralelizar o processamento de vários documentos. Como parte do fluxo de trabalho, usamos as funções do AWS Lambda para chamar o Amazon Bedrock Data Automation ou o Amazon Textract e o Amazon Bedrock (dependendo do modo de análise selecionado). Os documentos processados e os atributos extraídos são armazenados no Amazon Simple Storage Service (Amazon S3).
Um fluxo de trabalho do Step Functions com a lógica de negócios é invocado por meio de uma chamada de API realizada usando um SDK da AWS. Também criamos um aplicativo web em contêineres executado no Amazon Elastic Container Service (Amazon ECS) que está disponível para usuários finais por meio do Amazon CloudFront para simplificar sua interação com a solução. Usamos o Amazon Cognito para autenticação e acesso seguro às APIs.
O diagrama a seguir ilustra a arquitetura e o fluxo de trabalho da solução IDP.
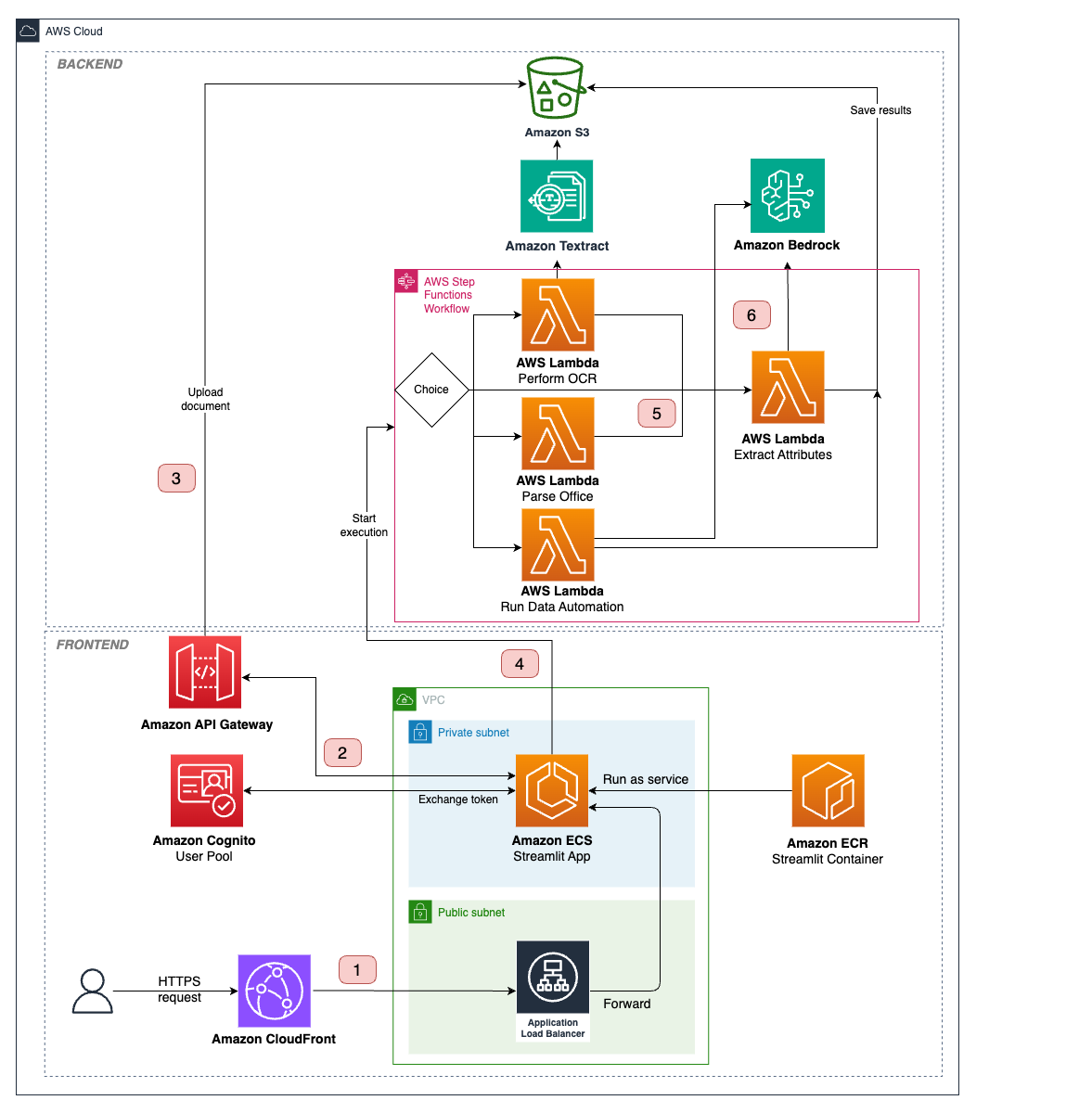
O fluxo de trabalho do IDP inclui as seguintes etapas:
- Um usuário faz login no aplicativo web usando credenciais gerenciadas pelo Amazon Cognito, seleciona documentos de entrada e define os campos a serem extraídos deles na interface do usuário. Opcionalmente, o usuário pode especificar o modo de análise, o LLM a ser usado e outras configurações.
- O usuário inicia o pipeline do IDP.
- O aplicativo cria uma URL S3 pré-assinada para os documentos e os carrega no Amazon S3.
- O aplicativo aciona o Step Functions para iniciar a máquina de estados com as configurações de URIs e IDP do S3 como entradas. O estado do Mapa começa a processar os documentos simultaneamente.
- Dependendo do tipo de documento e do modo de análise, ele se ramifica para diferentes funções do Lambda que executam o IDP, salvam os resultados no Amazon S3 e os enviam de volta para a interface do usuário:
- Amazon Bedrock Data Automation — Os documentos são direcionados para a função Lambda “Executar automação de dados”. A função Lambda cria um esquema com o esquema de campos definido pelo usuário e inicia uma tarefa assíncrona do Amazon Bedrock Data Automation. O Amazon Bedrock Data Automation lida com a complexidade do processamento de documentos e da extração de atributos usando prompts e modelos otimizados. Quando os resultados do trabalho estiverem prontos, eles serão salvos no Amazon S3 e enviados de volta para a interface do usuário. Essa abordagem fornece o melhor equilíbrio entre precisão, facilidade de uso e escalabilidade para a maioria dos casos de uso do IDP.
- Amazon Textract — Se o usuário especificar o Amazon Textract como um modo de análise, o pipeline do IDP se dividirá em duas etapas. Primeiro, a função Lambda “Perform OCR” é invocada para executar um trabalho assíncrono de análise de documentos. As saídas do OCR são processadas usando a biblioteca amazon-textract-textractor e formatadas como Markdown. Em segundo lugar, o texto é passado para a função Lambda “Extrair atributos” (Etapa 6), que invoca um Amazon Bedrock FM de acordo com o texto e o esquema de atributos. As saídas são salvas no Amazon S3 e enviadas para a interface do usuário.
- Manipulação de documentos de escritório — Documentos com sufixos como.doc, .ppt e .xls são processados pela função Lambda “Parse office”, que usa carregadores de documentos LangChain para extrair o conteúdo do texto. As saídas são passadas para a função Lambda “Extrair atributos” (Etapa 6) para continuar com o pipeline do IDP.
- Se o usuário escolher um Amazon Bedrock FM para IDP, o documento será enviado para a função Lambda “Extrair atributos”. Ele converte um documento em um conjunto de imagens, que são enviadas para um FM multimodal com o esquema de atributos como parte de um prompt personalizado. Ele analisa a resposta do LLM para extrair as saídas JSON, as salva no Amazon S3 e as envia de volta para a interface do usuário. Esse fluxo é compatível com documentos.pdf, .png e .jpg.
- O aplicativo web verifica os resultados da execução da máquina de estados periodicamente e retorna os atributos extraídos ao usuário quando eles estão disponíveis.
Pré-requisitos
Você pode implantar a solução de IDP a partir do seu computador local ou de uma instância do notebook Amazon SageMaker. As etapas de implantação estão detalhadas no arquivo README da solução.
Se você optar por implantar usando um notebook do SageMaker, o que é recomendado, você precisará acessar uma conta da AWS com permissões para criar e iniciar uma instância do notebook do SageMaker.
Implemente a solução
Para implantar a solução em sua conta da AWS, conclua as seguintes etapas:
- Abra o Console de Gerenciamento da AWS e escolha a região na qual você deseja implantar a solução de IDP.
- Inicie uma instância do notebook SageMaker. Forneça o nome da instância do notebook e o tipo da instância do notebook, que você pode definir como ml.m5.large. Deixe outras opções como padrão.
- Navegue até a instância do Notebook e abra a função do IAM anexada ao notebook. Abra a função no console do AWS Identity and Access Management (IAM).
- Anexe uma política embutida à função e insira o seguinte JSON de política:
- Quando o status da instância do notebook estiver marcado como InService, escolha Abrir JupyterLab.
- No ambiente do JupyterLab, escolha Arquivo, Novo e Terminal.
- Clone o repositório da solução executando os seguintes comandos:
- Navegue até a pasta do repositório e execute o script para instalar os requisitos:
- Execute o script para criar um ambiente virtual e instalar dependências:
- Na pasta do repositório, copie o config-example.yml em um config.yml para especificar o nome da pilha. Opcionalmente, configure os serviços e indique os módulos que você deseja implantar (por exemplo, para desativar a implantação de uma interface de usuário, altere deploy_streamlit para False). Certifique-se de adicionar seu e-mail de usuário à lista de usuários do Amazon Cognito.
- Configure o acesso ao modelo Amazon Bedrock abrindo o console do Amazon Bedrock na região especificada no arquivo config.yml. No painel de navegação, escolha Model Access e certifique-se de habilitar o acesso para os IDs de modelo especificados em config.yml.
- Inicialize e implante o AWS CDK em sua conta:
Observe que essa etapa pode levar algum tempo, especialmente na primeira implantação. Quando a implantação for concluída, você deverá ver a mensagem conforme mostrado na captura de tela a seguir. Você pode acessar o frontend do Streamlit usando a URL de distribuição do CloudFront fornecida nas saídas do AWS CloudFormation. As credenciais de login temporárias serão enviadas para o e-mail especificado em config.yml durante a implantação.

Usando a solução
Esta seção mostra dois exemplos para mostrar os recursos do IDP.
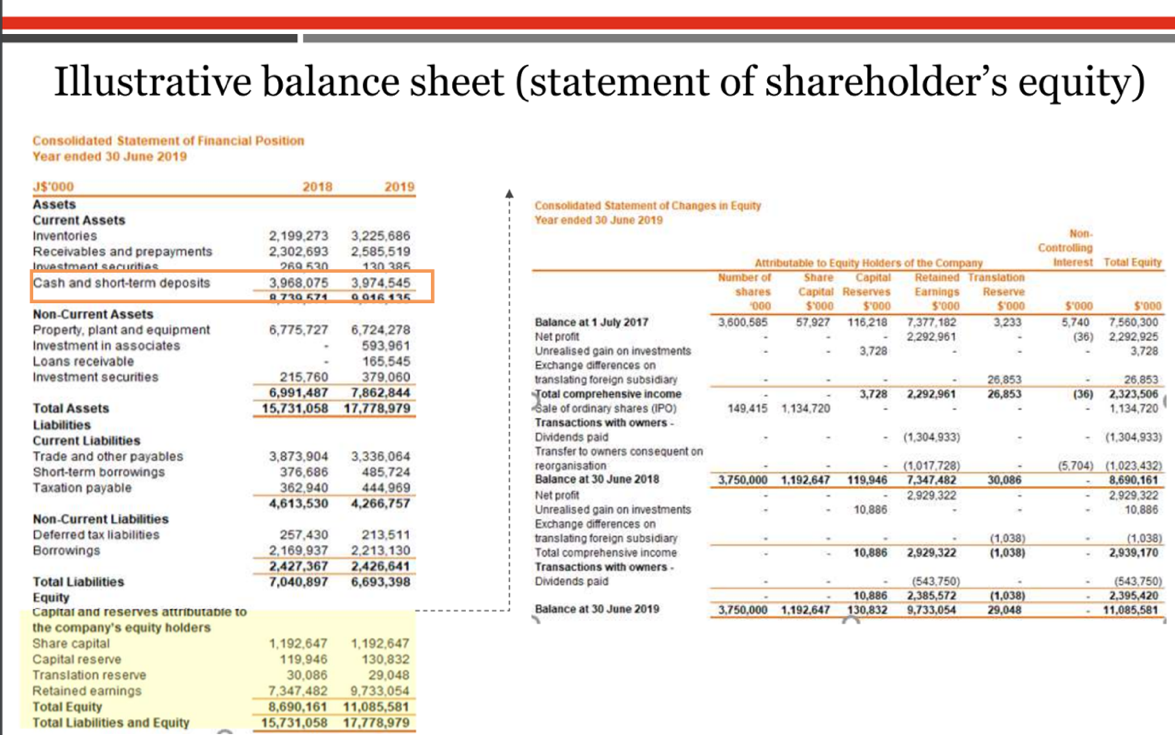
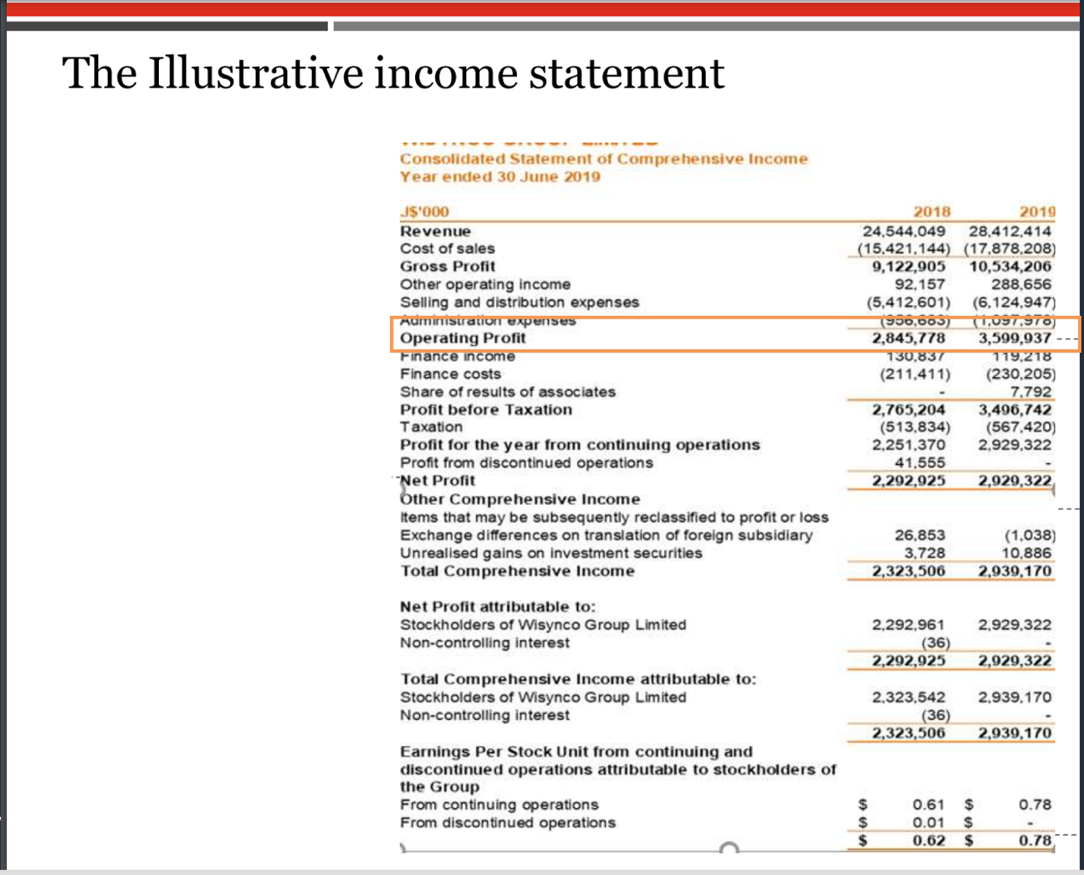
Exemplo 1: Análise de documentos financeiros
Nesse cenário, extraímos os principais recursos de um demonstrativo financeiro de várias páginas usando o Amazon Bedrock Data Automation. Usamos um documento de amostra em formato PDF com uma mistura de tabelas, imagens e texto e extraímos várias métricas financeiras. Conclua as seguintes etapas:
-
- Faça upload de um documento anexando um arquivo por meio da interface de usuário da solução.
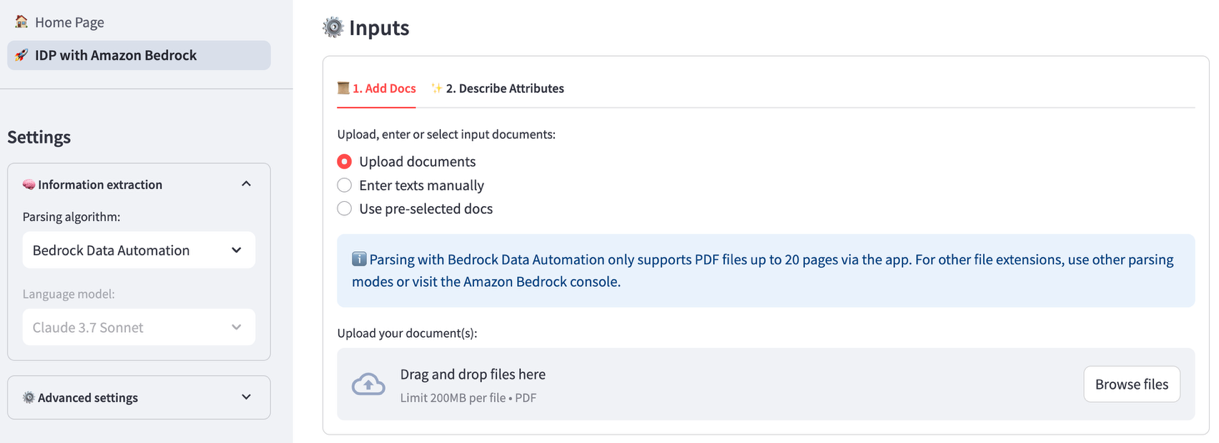
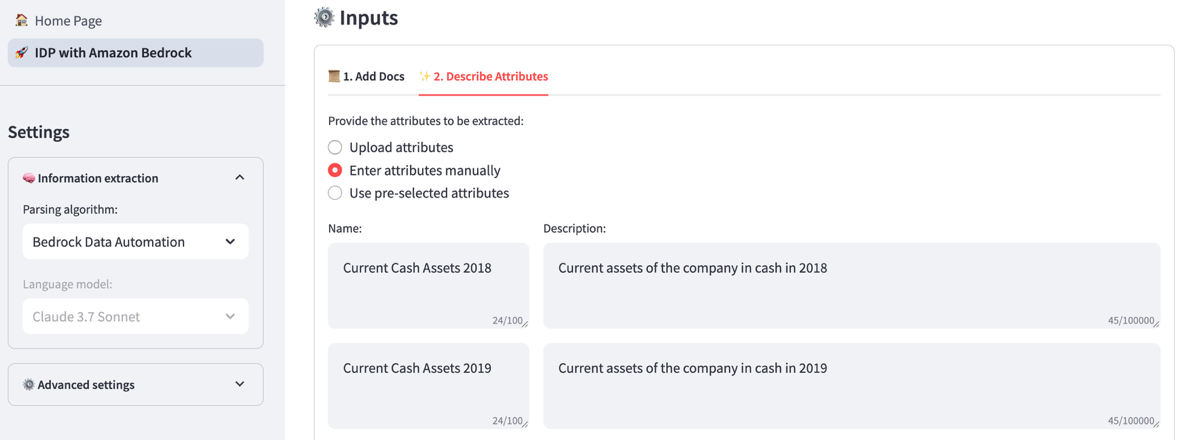
- Na guia Descrever atributos, liste manualmente os nomes e as descrições dos atributos ou carregue esses campos no formato JSON. Queremos encontrar as seguintes métricas:
-
- Caixa atual em ativos em 2018
- Caixa atual em ativos em 2019
- Lucro operacional em 2018
- Lucro operacional em 2019
-
- Escolha Extrair atributos para iniciar o pipeline do IDP.
Os atributos fornecidos são integrados a um esquema personalizado com a lista de atributos inferidos, que é então usada para invocar um job do Amazon Bedrock Data Automation para os documentos carregados.
Depois que o pipeline do IDP for concluído, você verá uma tabela de resultados na interface do usuário. Ele inclui um índice para cada documento na coluna _doc, uma coluna para cada um dos atributos que você definiu e uma coluna file_name que contém o nome do documento.
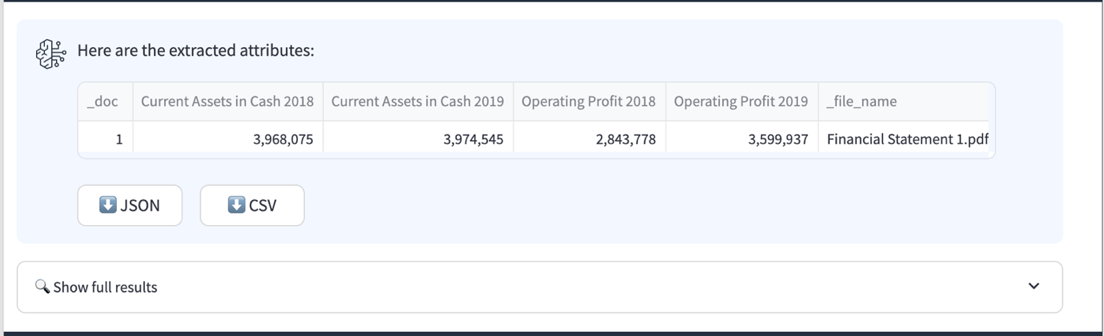
A partir dos trechos da declaração a seguir, podemos ver que o Amazon Bedrock Data Automation conseguiu extrair corretamente os valores dos ativos atuais e do lucro operacional.
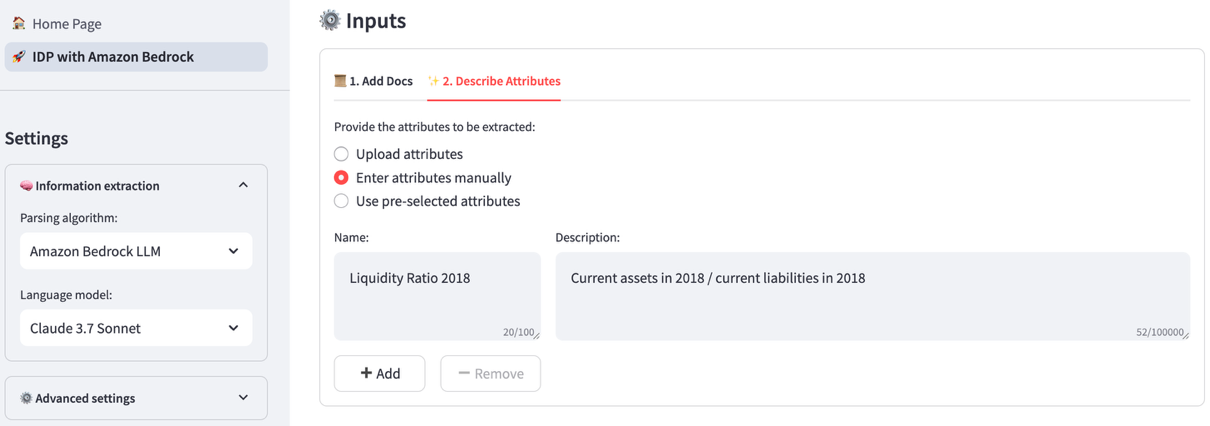
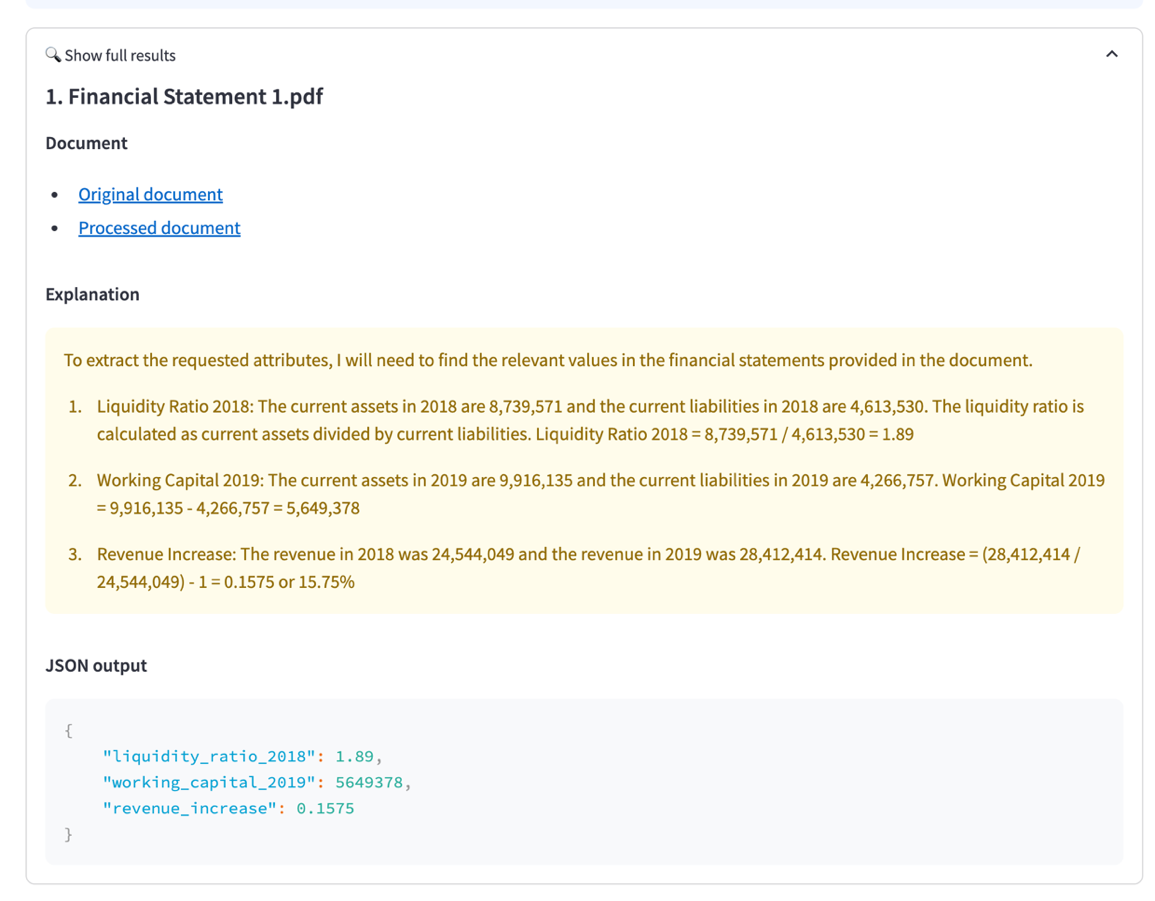
A solução de IDP também é capaz de fazer cálculos complexos além de entidades bem definidas. Digamos que queremos calcular as seguintes métricas contábeis:
- Índices de liquidez (ativo circulante/passivo circulante)
- Capital de giro (Ativo circulante — Passivo circulante)
- Aumento de receita ((Ano de receita 2/Ano de receita 1) — 1)
Definimos os atributos e suas fórmulas como partes do esquema dos atributos. Desta vez, escolhemos um Amazon Bedrock LLM como modo de análise para demonstrar como o aplicativo pode usar um FM multimodal para o IDP. Ao usar um Amazon Bedrock LLM, iniciar o pipeline do IDP agora combinará os atributos e sua descrição em um template de prompt personalizado, que é enviado ao LLM com os documentos convertidos em imagens. Como usuário, você pode especificar o LLM que alimenta a extração e seus parâmetros de inferência, como temperatura.
A saída, incluindo os resultados completos, é mostrada na captura de tela a seguir.
Exemplo 2: Processamento de e-mails de clientes
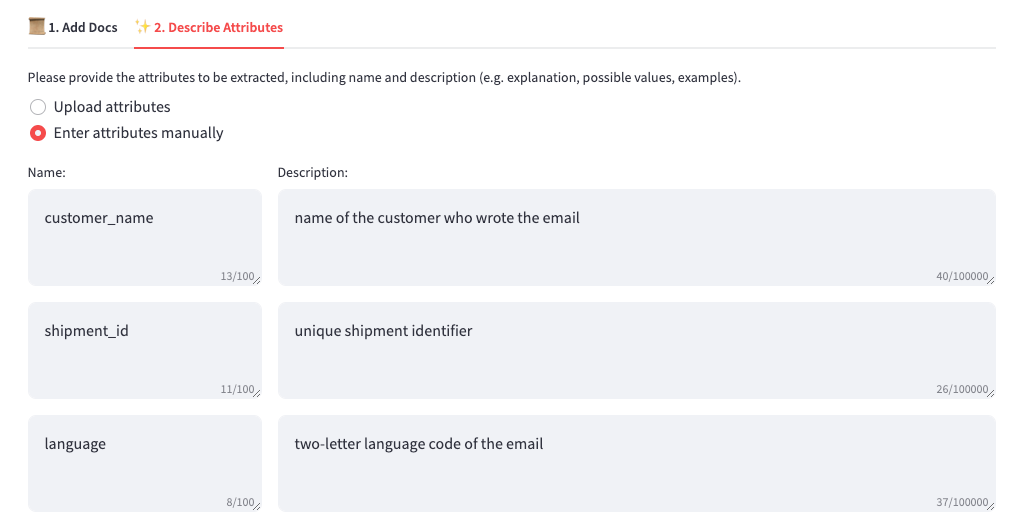
Nesse cenário, queremos extrair vários recursos de uma lista de e-mails com reclamações de clientes devido a atrasos nas remessas de produtos usando o Amazon Bedrock Data Automation. Para cada e-mail, queremos encontrar o seguinte:
- Nome do cliente
- ID da remessa
- Idioma do e-mail
- Sentimento por e-mail
- Atraso na remessa (em dias)
- Resumo do problema
- Resposta sugerida
Conclua as seguintes etapas:
-
- Faça upload de e-mails de entrada como arquivos.txt. Você pode baixar exemplos de e-mails do GitHub.
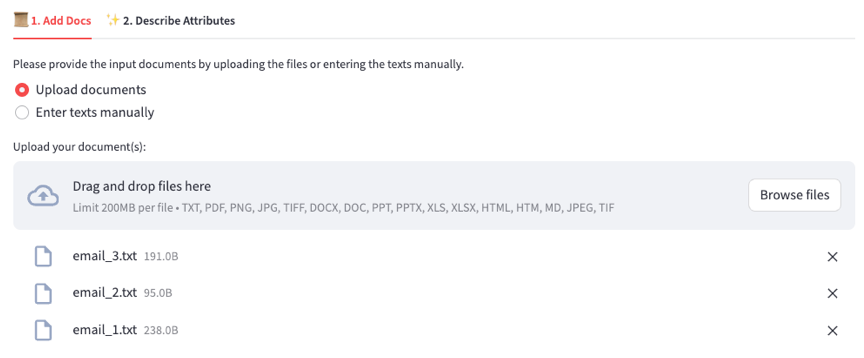
- Na guia Descrever atributos, liste os nomes e as descrições dos atributos.
-
Você pode adicionar alguns exemplos de alguns campos (como atraso) para explicar ao LLM como os valores desses campos devem ser extraídos. Você pode fazer isso adicionando um exemplo de entrada e a saída esperada para o atributo à descrição.
-
- Escolha Extrair atributos para iniciar o pipeline do IDP.
Você pode adicionar alguns exemplos de alguns campos (como atraso) para explicar ao LLM como os valores desses campos devem ser extraídos. Você pode fazer isso adicionando um exemplo de entrada e a saída esperada para o atributo à descrição.

O aplicativo permite baixar os resultados da extração como um arquivo CSV ou JSON. Isso facilita o uso dos resultados para tarefas posteriores, como agregar scores de sentimento do cliente.
Preços
Nesta seção, calculamos estimativas de custo para realizar o IDP na AWS com nossa solução.
O Amazon Bedrock Data Automation fornece um esquema de preços transparente, dependendo do tamanho do documento de entrada (número de páginas, imagens ou minutos). Ao usar o Amazon Bedrock FMs, o preço depende do número de tokens de entrada e saída usados como parte da chamada de extração de informações. Por fim, ao usar o Amazon Textract, o OCR é executado e precificado separadamente com base no número de páginas nos documentos.
Usando os cenários anteriores como exemplos, podemos aproximar os custos dependendo do modo de análise selecionado. Na tabela a seguir, mostramos os custos usando dois conjuntos de dados: 100 documentos financeiros de 20 páginas e 100 e-mails de clientes de 1 página. Ignoramos os custos do Amazon ECS e do Lambda.
| Serviço AWS |
Caso de uso 1 (100 documentos financeiros de 20 páginas) |
Caso de uso 2 (100 e-mails de clientes de 1 página) |
| Opção IDP 1: Automação de Dados Amazon Bedrock | ||
| Automação de Dados Amazon Bedrock (saída personalizada) | $20,00 | $1,00 |
| Opção IDP 2: Amazon Bedrock FM | ||
| Amazon Bedrock (invocação FM, Claude 4 Sonnet da Anthropic) | $1,79 | $0,09 |
| Opção IDP 3: Amazon Textract e Amazon Bedrock FM | ||
| Amazon Textract (trabalho de análise de documento com layout) | $30,00 | $1,50 |
| Amazon Bedrock (invocação FM, Claude 3.7 Sonnet da Anthropic) | $1,25 | $0,06 |
| Orquestração e armazenamento (custos compartilhados) | ||
| Amazon S3 | $0,02 | $0,02 |
| AWS CloudFront | $0,09 | $0,09 |
| Amazon ECS | – | – |
| AWS Lambda | – | – |
| Custo total: Automação de Dados Amazon Bedrock | $20,11 | $1,11 |
| Custo total: Amazon Bedrock FM | $1,90 | $0,20 |
| Custo total: Amazon Textract e Amazon Bedrock FM | $31,36 | $1,67 |
A análise de custo sugere que usar o Amazon Bedrock FMs com um template de prompt personalizado é um método econômico para o IDP. No entanto, essa abordagem requer uma sobrecarga operacional maior, porque o pipeline precisa ser otimizado dependendo do LLM e requer gerenciamento manual de segurança e privacidade. O Amazon Bedrock Data Automation oferece um serviço gerenciado que usa uma variedade de FMs de alto desempenho por meio de uma única API.
Limpe
Para remover os recursos implantados, conclua as seguintes etapas:
1. No console do AWS CloudFormation, exclua a pilha criada. Como alternativa, execute o seguinte comando:
2. No console do Amazon Cognito, exclua o grupo de usuários.
Conclusão
Extrair informações de documentos não estruturados em grande escala é uma tarefa comercial recorrente. Esta postagem discutiu um aplicativo de IDP de ponta a ponta que executa a extração de informações usando vários serviços da AWS. A solução é baseada no Amazon Bedrock Data Automation, que fornece um serviço totalmente gerenciado para gerar insights a partir de documentos, imagens, áudio e vídeo. O Amazon Bedrock Data Automation lida com a complexidade do processamento de documentos e da extração de informações, otimizando o desempenho e a precisão sem exigir experiência em engenharia de prompts. Para maior flexibilidade e personalização em cenários específicos, nossa solução também oferece suporte ao IDP usando chamadas LLM personalizadas do Amazon Bedrock e Amazon Textract para OCR.
A solução oferece suporte a vários tipos de documentos, incluindo texto, imagens, PDF e documentos do Microsoft Office. No momento em que este artigo foi escrito, a compreensão precisa das informações em documentos ricos em imagens, tabelas e outros elementos visuais só está disponível para PDF e imagens. Recomendamos converter documentos complexos do Office em PDFs ou imagens para obter o melhor desempenho. Outra limitação da solução é o tamanho do documento. A partir de junho de 2025, o Amazon Bedrock Data Automation oferece suporte a documentos de até 20 páginas para extração de atributos personalizados. Ao usar LLMs personalizados do Amazon Bedrock para IDP, a janela de contexto de 300.000 tokens do Amazon Nova LLMs permite processar documentos com até aproximadamente 225.000 palavras. Para extrair informações de documentos maiores, atualmente você precisaria dividir o arquivo em vários documentos.
Nas próximas versões da solução IDP, planejamos continuar adicionando suporte para modelos de linguagem de última geração disponíveis por meio do Amazon Bedrock e iterar a engenharia de prompts para melhorar ainda mais a precisão da extração. Também planejamos implementar técnicas para ampliar o tamanho dos documentos suportados e fornecer aos usuários uma indicação precisa de onde exatamente as informações extraídas estão vindo do documento.
Para começar a usar o IDP com a solução descrita, consulte o repositório do GitHub. Para saber mais sobre o Amazon Bedrock, consulte a documentação.
Este conteúdo é uma tradução da postagem original do blog, que pode ser encontrada aqui.
Autores
 |
Nikita Kozodoi, PhD, is a Senior Applied Scientist at the AWS Generative AI Innovation Center, where he works on the frontier of AI research and business. With rich experience in Generative AI and diverse areas of ML, Nikita is enthusiastic about using AI to solve challenging real-world business problems across industries. |
 |
Zainab Afolabi is a Senior Data Scientist at the Generative AI Innovation Centre in London, where she leverages her extensive expertise to develop transformative AI solutions across diverse industries. She has over eight years of specialised experience in artificial intelligence and machine learning, as well as a passion for translating complex technical concepts into practical business applications. |
 |
Aiham Taleb, PhD, is a Senior Applied Scientist at the Generative AI Innovation Center, working directly with AWS enterprise customers to leverage Gen AI across several high-impact use cases. Aiham has a PhD in unsupervised representation learning, and has industry experience that spans across various machine learning applications, including computer vision, natural language processing, and medical imaging.
|
 |
Liza (Elizaveta) Zinovyeva is an Applied Scientist at AWS Generative AI Innovation Center and is based in Berlin. She helps customers across different industries to integrate Generative AI into their existing applications and workflows. She is passionate about AI/ML, finance and software security topics. In her spare time, she enjoys spending time with her family, sports, learning new technologies, and table quizzes. |
 |
Nuno Castro is a Sr. Applied Science Manager at AWS Generative AI Innovation Center. He leads Generative AI customer engagements, helping hundreds of AWS customers find the most impactful use case from ideation, prototype through to production. He has 19 years experience in AI in industries such as finance, manufacturing, and travel, leading AI/ML teams for 12 years. |
 |
Ozioma Uzoegwu is a Principal Solutions Architect at Amazon Web Services. In his role, he helps financial services customers across EMEA to transform and modernize on the AWS Cloud, providing architectural guidance and industry best practices. Ozioma has many years of experience with web development, architecture, cloud and IT management. Prior to joining AWS, Ozioma worked with an AWS Advanced Consulting Partner as the Lead Architect for the AWS Practice. He is passionate about using latest technologies to build a modern financial services IT estate across banking, payment, insurance and capital markets. |
 |
Eren Tuncer is a Solutions Architect at Amazon Web Services focused on Serverless and building Generative AI applications. With more than fifteen years experience in software development and architecture, he helps customers across various industries achieve their business goals using cloud technologies with best practices. As a builder, he’s passionate about creating solutions with state-of-the-art technologies, sharing knowledge, and helping organizations navigate cloud adoption.
|
 |
Francesco Cerizzi is a Solutions Architect at Amazon Web Services exploring tech frontiers while spreading generative AI knowledge and building applications. With a background as a full stack developer, he helps customers across different industries in their journey to the cloud, sharing insights on AI’s transformative potential along the way. He’s passionate about Serverless, event-driven architectures, and microservices in general. When not diving into technology, he’s a huge F1 fan and loves Tennis. |
Tradutoes
 |
Daniel Abib é Arquiteto de Soluções Sênior e Especialista em Amazon Bedrock na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e especialização em Machine Learning. Ele trabalha apoiando Startups, ajudando-os em sua jornada para a nuvem. |
 |
Guilherme Souza Gomes é Especialista Sênior em AI/ML na AWS, com mais de 20 anos de experiência em desenvolvimento de software, arquitetura de soluções e gerenciamento de projetos. Possui Mestrado em Ciência da Computação e especializações em Inteligência Artificial Generativa, Machine Learning e Design de Sistemas. Ele trabalha apoiando empresas em sua jornada de transformação digital com IA, desenvolvendo soluções escaláveis utilizando Amazon Bedrock e Amazon SageMaker, e liderando a implementação de arquiteturas cloud-native com foco em serverless, containers e microsserviços. |