O blog da AWS
Orquestrando o processamento de documentos com o AWS AppSync Events e o Amazon Bedrock
Por Mehdi Amrane, Sr. Solutions Architect.
Muitas organizações implementam pipelines inteligentes de processamento de documentos para extrair insights significativos de um volume cada vez maior de conteúdo não estruturado (como reivindicações de seguros, solicitações de empréstimos e muito mais). Tradicionalmente, esses pipelines exigem esforços significativos de engenharia, pois a implementação geralmente envolve o uso de vários modelos de aprendizado de máquina (ML) e a orquestração de fluxos de trabalho complexos.
À medida que as organizações integram esses pipelines aos aplicativos voltados para o cliente (como aplicativos da web para que os clientes façam upload de documentos como reivindicações de seguros, documentos de aprovação de empréstimos e muito mais), elas estabelecem metas para fornecer informações em tempo real para aumentar a experiência do cliente final. Essas organizações também pretendem executar e escalar essas cargas de trabalho com o mínimo de sobrecarga operacional e otimizando os custos. Além disso, essas organizações exigem a implementação de práticas comuns de segurança, como gerenciamento de identidade e acesso, para garantir que somente usuários autorizados e autenticados tenham permissão para realizar ações específicas ou acessar recursos específicos.
Nesta postagem, mostramos uma solução para simplificar a criação de um pipeline inteligente de processamento de documentos, com um aplicativo web para que os clientes façam upload de seus arquivos (documentos e imagens) e obtenham insights deles (resumo, extração e classificação de campos). A solução usa principalmente tecnologias serverless, inclui um websocket da web para receber informações em tempo real e oferece vários benefícios, como escalabilidade automática, alta disponibilidade integrada e um modelo de cobrança de acordo com o uso para otimizar os custos. A solução também inclui uma camada de autenticação e uma camada de autorização para gerenciar identidades e permissões.
Visão geral da solução
Nesta publicação, fornecemos uma visão geral operacional da solução e, em seguida, descrevemos como configurá-la com os seguintes serviços:
- Amazon Bedrock e Amazon Bedrock Data Automation para resumir o conteúdo dos arquivos enviados (documentos ou imagens) e gerar insights a partir deles
- AWS Step Functions e AWS Lambda para orquestrar as operações de resumo e extração, usando o Amazon Bedrock e o Amazon Bedrock Data Automation
- Eventos do AWS AppSync para criar um websocket serverless para que o aplicativo web receba os insights de resumo e extração em tempo real
- AWS Amplify para criar e implantar o aplicativo web
- Amazon EventBridge acionará o fluxo de trabalho de orquestração (usando o AWS Step Functions e o AWS Lambda) após o upload de um novo arquivo
- Amazon Cognito implementará uma plataforma de identidade (diretório de usuários e gerenciamento de autorizações) para o aplicativo web.
- Amazon Simple Storage Service (Amazon S3) para armazenar arquivos carregados (para serem processados pelo pipeline de processamento) e ativos relacionados a aplicativos web.
A arquitetura da solução é ilustrada no diagrama a seguir:
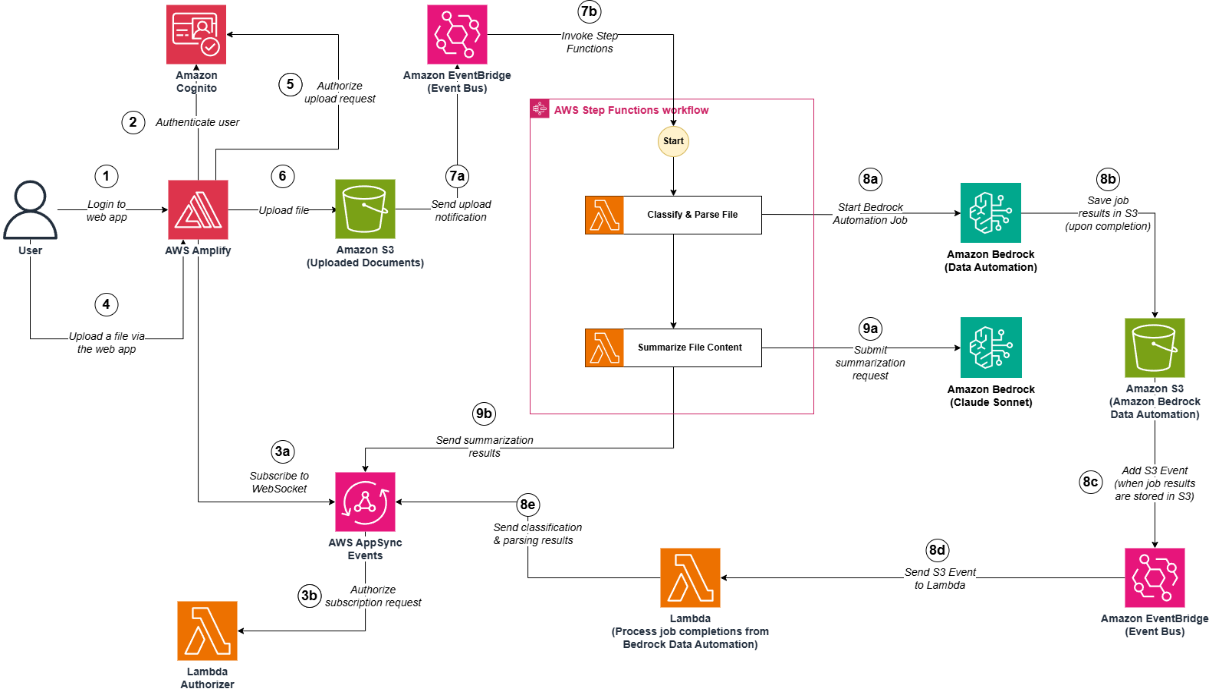
Etapa 1: O usuário se autentica no aplicativo web (hospedado no AWS Amplify).
Etapa 2: O Amazon Cognito valida os detalhes da autenticação. Depois disso, o usuário agora está logado no aplicativo web.
Etapas 3a e 3b:
- Etapa 3a: O aplicativo web (AWS Amplify) assina um soquete web do AWS AppSync Events.
- Etapa 3b: O soquete da web do AWS AppSync Events chama um autorizador do AWS Lambda para confirmar que o usuário está autorizado a assinar o soquete da web.
Etapa 4: O usuário carrega um arquivo (documento ou imagem) usando o aplicativo web.
Etapa 5: O aplicativo web (hospedado no AWS Amplify) chama o Amazon Cognito (pool de identidade) para confirmar que o usuário está autorizado a fazer upload de um arquivo.
Etapa 6: O arquivo é carregado em um bucket do Amazon S3.
Etapas 7a e 7b: Ao receber um evento de upload do Amazon S3 (que notifica que o arquivo foi carregado no bucket do Amazon S3) no barramento padrão do Amazon Event Bridge, uma regra de barramento do Amazon Event Bridge aciona a execução de uma máquina de estado do AWS Step Functions para iniciar o fluxo de trabalho de orquestração.
Etapa 8 (Etapa para extrair campos de um arquivo e classificá-lo):
- Etapa 8a: A primeira função do AWS Lambda inicia um novo trabalho do Amazon Bedrock Automation (esse trabalho extrai campos específicos do arquivo carregado e o classifica)
- Etapa 8b: Depois que o trabalho é concluído, os resultados são armazenados em um bucket do Amazon S3.
- Etapa 8c e 8d: Ao receber um evento do Amazon S3 (que notifica que os resultados foram armazenados no bucket do Amazon S3) no Amazon Event Bridge padrão, uma regra de barramento do Amazon Event Bridge aciona a execução de uma função do AWS Lambda
- Etapa 8e: Uma função do AWS Lambda publica os resultados no soquete da web.
Etapas 9a e 9b: A segunda função do AWS Lambda envia uma solicitação para um modelo da Amazon Bedrock Foundation (Sonnet 3), para solicitar um resumo em streaming do arquivo carregado. A função AWS Lambda publica os dados de streaming no soquete da web.
Após a Etapa 8e e a Etapa 9b, o usuário agora pode consultar o resultado do resumo e os insights de extração do arquivo carregado no aplicativo web.
Pré-requisitos
Para acompanhar e configurar essa solução, você deve ter o seguinte:
- Uma conta da AWS
- Um dispositivo com acesso à sua conta da AWS com o seguinte:
- Python 3.12 instalado (incluindo pip)
- Node.js 20.12.0 instalado
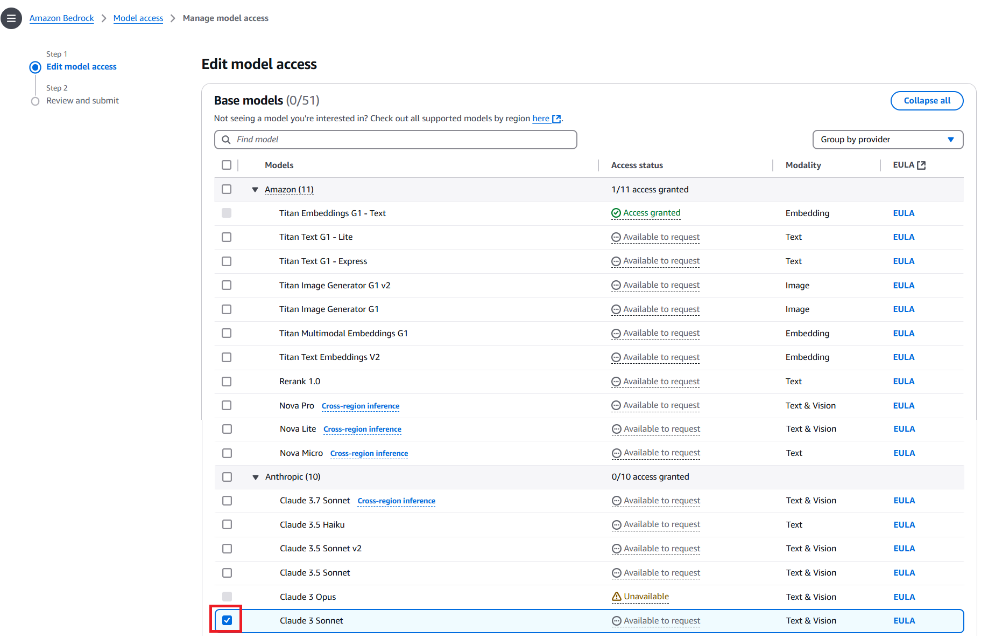
- Habilite o acesso ao modelo Claude 3 Sonnet no Amazon Bedrock
Note: Deploying this solution will incur costs. Review the pricing page of each AWS service used in this post for details on costs. The cost of running this solution will primarily depend on:
- O número de documentos (e o tamanho de cada documento)
- O número de usuários ativos
Configurar a automação de dados Amazon Bedrock
Nesta seção, configuramos um projeto de automação de dados do Amazon Bedrock e um blueprint do Amazon Bedrock.
Um projeto contém uma lista de plantas, e cada planta define os campos a serem extraídos de diferentes tipos de arquivos (como documentos ou imagens). Neste post, definimos um plano para uma carteira de habilitação.
Conclua as etapas a seguir para criar um projeto Amazon Bedrock Data Automation e um plano de carteira de habilitação:
- Clone o repositório do GitHub
- Acesse a pasta
sample-create-idp-with-appsyncevents-and-amazonbedrock - Inicialize o ambiente (deixe os arquivos de script de shell, do repositório do GitHub, prontos para serem usados)
- Execute o script
setup-bda-project.shpara criar um projeto Amazon Bedrock Data Automation e um modelo de modelo de carteira de habilitação de exemplo:
Crie o websocket e o backend de orquestração
Nesta seção, criamos os seguintes recursos:
- Um diretório de usuários para autenticação e autorização na web, criado com um grupo de usuários do Amazon Cognito. Um pool de identidade do Amazon Cognito também é criado para validar se os usuários estão autorizados a fazer upload de arquivos por meio do aplicativo web.
- Um websocket usando o AWS AppSync Events. Isso permite que nosso aplicativo web receba atualizações em tempo real para resultados de resumo e extração. Uma camada de autorização também é criada para proteger o websocket contra usuários não autorizados. Isso é implementado com uma função autorizadora do Lambda para validar se as solicitações recebidas incluem detalhes de autorização válidos.
- Uma máquina de estado usando o AWS Step Functions e o AWS Lambda para orquestrar as operações de resumo e extração do conteúdo não estruturado
- Buckets do Amazon S3 para armazenar arquivos para processamento de documentos e arquivos de código para funções do AWS Lambda
Conclua as etapas a seguir para criar o soquete da web e o beckend de orquestração da solução, usando os modelos do AWS CloudFormation:
- Crie buckets do Amazon S3 usados pela solução executando o script a seguir. Esses buckets armazenarão os arquivos enviados pelos usuários e os arquivos de código das funções do AWS Lambda usadas nesta solução.
- Crie o grupo de usuários e o grupo de identidades do Amazon Cognito executando o script
create-cognito-userpool.sh: - Crie o websocket do AWS AppSync Events executando o seguinte script:
- Crie a máquina de estado do AWS Step Functions (incluindo funções do AWS Lambda) executando os seguintes scripts:
Configurar o grupo de usuários do Amazon Cognito
Nesta seção, criamos um usuário em nosso grupo de usuários do Amazon Cognito. Esse usuário fará login em nosso aplicativo da web.
Execute o script create-cognito-testuser.sh para criar o usuário (certifique-se de fornecer seu endereço de e-mail):
Depois de criar o usuário, você deverá receber um e-mail com uma senha temporária neste formato: “Seu nome de usuário é #your -email-address# e a senha temporária é #temporary -password#”.
Anote esses detalhes de login (endereço de e-mail e senha temporária) para usar posteriormente ao testar o aplicativo web.
Crie o aplicativo web
Nesta seção, criamos um aplicativo web usando o AWS Amplify e o publicamos para torná-lo acessível por meio de uma URL de endpoint.
Conclua as etapas a seguir para criar o aplicativo web:
- Execute o script
create-webapp.shpara criar o aplicativo web com o AWS Amplify: - Execute o script
deploy.shpara implantar o aplicativo web
O aplicativo web agora está disponível para teste e uma URL deve ser exibida, conforme mostrado na captura de tela a seguir. Anote o URL a ser usado na seção a seguir.
Teste o aplicativo web
Nesta seção, testamos o aplicativo web e carregamos um arquivo para ser processado:
- Abra a URL do aplicativo AWS Amplify em seu navegador da web.
- Insira suas informações de login (seu e-mail e a senha temporária que você recebeu anteriormente ao configurar o grupo de usuários no Amazon Cognito) e escolha Entrar.
- Quando solicitado, digite uma nova senha e escolha Alterar senha.
- Agora você deve conseguir ver uma interface da web.
- Baixe a amostra da carteira de habilitação neste local e faça o upload por meio do aplicativo da web usando sua câmera ou um arquivo em seu dispositivo local, conforme ilustrado

{kind=link}
Depois que o arquivo for carregado, você deverá começar a receber respostas no aplicativo web. Quando todas as operações forem concluídas, você verá um resultado equivalente ao mostrado na captura de tela a seguir:

Observação: Se você planeja usar outras imagens de amostra de carteira de habilitação com outros formatos, talvez seja necessário atualizar o esquema existente do Bedrock Data Automation que criamos anteriormente ou definir um novo modelo em seu projeto do Bedrock Data Automation que criamos anteriormente para que essas novas imagens funcionem. Para obter mais informações, consulte a documentação do Bedrock Data Automation.
Limpe
Para garantir que nenhum custo adicional seja incorrido, remova os recursos provisionados em sua conta. Verifique se você está na conta correta da AWS antes de excluir os seguintes recursos.
Observação importante: você deve ter cuidado ao executar as etapas anteriores. Verifique se você está excluindo os recursos na conta correta da AWS.
Você pode navegar até o console do AWS CloudFormation para excluir as pilhas do CloudFormation associadas aos recursos provisionados ou usar o script auxiliar de limpeza cleanup.sh disponível na raiz da pasta sample-create-idp-with-appsyncevents-and-amazonbedrock:
Conclusão
Neste post, analisamos uma solução para criar um pipeline de processamento de documentos, com um aplicativo web usando serviços serverless. Por meio do aplicativo web, pudemos fazer o upload de um arquivo e receber respostas em tempo real para diferentes tipos de operações (resumo, extração de campos específicos e classificação). Primeiro, criamos um projeto de automação de dados Amazon Bedrock (com um plano de carteira de motorista). Em seguida, criamos um websocket junto com uma solução de orquestração usando uma máquina de estado (funções AWS Step Functions e AWS Lambda). Também configuramos um grupo de usuários para conceder acesso ao aplicativo web. Por fim, criamos o front-end do aplicativo web no AWS Amplify.
Para se aprofundar nessa solução, um workshop individualizado está disponível no AWS Workshop Studio.
Este conteúdo foi traduzido da postagem original do blog, que pode ser encontrada aqui.
Biografia dos Autores
 |
Mehdi Amrane, Sr. Solutions Architect |
Biografia do Tradutor
 |
Rodrigo Peres é Arquiteto de Soluções na AWS, com mais de 20 anos de experiência trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados. |
Biografia do Revisor
 |
Daniel Abib é arquiteto de soluções sênior na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e segurança. Ele trabalha apoiando clientes corporativos, ajudando-os em sua jornada para a nuvem. |