O blog da AWS
Nos bastidores: como o AWS Lambda SnapStart otimiza a latência de inicialização da função
Por Ayush Kulkarni, Sr. Product Mgr Tech e Eric Heinz, Sr. Software Dev Engineer.
Ao criar aplicativos usando o AWS Lambda, otimizar a inicialização da função é uma etapa importante para melhorar o desempenho de aplicativos sensíveis à latência. O maior fator que contribui para a latência de inicialização (geralmente chamada de tempo de inicialização a frio ou cold start) é o tempo que o Lambda gasta inicializando seu código. O Lambda SnapStart é um recurso disponível para runtimes Java, Python e .NET que ajuda a reduzir a latência variável de inicialização a frio de vários segundos (ou mais) para menos de um segundo. Normalmente, o SnapStart precisa de nenhuma ou mínima alteração no código do aplicativo e facilita a criação de aplicativos altamente responsivos e escaláveis sem implementar otimizações complexas de desempenho. Esta postagem explica como o SnapStart funciona nos bastidores e fornece recomendações para melhorar o desempenho do aplicativo ao usar o SnapStart.
Se sua função já for inicializada em centenas de milissegundos, a AWS recomenda usar o Lambda Provisioned Concurrency para obter uma latência de inicialização de dois dígitos em milissegundos.
O que é inicialização a frio (cold start)?
O Lambda executa seu código de função em um ambiente de execução isolado e seguro que usa a tecnologia Firecracker microVM. Quando você invoca uma função do Lambda pela primeira vez, o Lambda cria um novo ambiente de execução para a função ser executada. O Lambda baixa o código da função, inicia o runtime da linguagem e executa o código de inicialização da função, que é um código fora do handler. Esse processo de inicialização (INIT) é chamado de inicialização a frio. Em seguida, o Lambda executa o código do handler de funções para invocar a função. Um ambiente de execução do Lambda processa apenas uma única solicitação de invocação por vez. A figura a seguir mostra o ciclo de vida de uma solicitação de invocação típica.

Figura 1. Ciclo de vida de invocação de funções sem o SnapStart
Depois que a função termina de ser executada, o Lambda não interrompe o ambiente de execução imediatamente. Quando sua função recebe outra solicitação de invocação, o Lambda tenta rotear a solicitação para o ambiente de execução ocioso, mas já em execução. Como o processo INIT já foi executado nesse ambiente de execução, essa invocação é chamada de inicialização a quente. Quando chega mais tráfego do que o Lambda tem em ambientes de execução ociosos disponíveis, o Lambda inicializa novos ambientes de execução para atender às solicitações adicionais, executando novamente o processo de inicialização a frio.
A última etapa da inicialização a frio, inicializar o código da função, normalmente leva mais tempo. Isso depende das tarefas de inicialização que você executa em seu código e do runtime ou estrutura da linguagem de programação que você usa. Para linguagens como Java e .NET, a latência de inicialização é afetada pela compilação just-in-time de código estático em classes carregadas. Para Python, ele pode ser afetado se o código executado contiver vários ou grandes módulos. Outras tarefas de inicialização, como baixar modelos de aprendizado de máquina (ML), também podem levar alguns segundos para serem concluídas, o que aumenta a latência de inicialização da função. O SnapStart foi projetado para otimizar essa última etapa do processo de inicialização a frio e consegue isso em três estágios.
Etapa 1: Capturando sua função Lambda
Ao usar o SnapStart, o ciclo de vida do ambiente de execução do Lambda muda. Quando você ativa o SnapStart para uma função específica, a publicação de uma nova versão da função aciona o processo de captura instantânea. O processo executa a fase de inicialização da função e captura um snapshot imutável e criptografado do microVM Firecracker, contendo o estado da memória e do disco do ambiente de execução inicializado, armazenando em cache e fragmentando o instantâneo para reutilização. Caminhos de código (code path) que não são executados durante a inicialização, como classes carregadas sob demanda por meio de injeção de dependência, não estão incluídos no snapshot da sua função. Para melhorar a eficiência do snapshot , execute proativamente os caminhos do código durante a fase de inicialização ou use runtime hooks para executar o código antes que o Lambda crie um snapshot .
A criação do instantâneo pode levar alguns minutos, durante os quais sua versão da função permanece no estado PENDENTE, tornando-se ATIVA quando o instantâneo estiver pronto.
Quando você invoca sua função posteriormente, o Lambda restaura novos ambientes de execução a partir desse snapshot . Essa otimização torna o tempo de invocação mais rápido e previsível, porque a criação de um novo ambiente de execução não requer mais uma inicialização.
A figura a seguir mostra o ciclo de vida de uma função configurada do SnapStart.
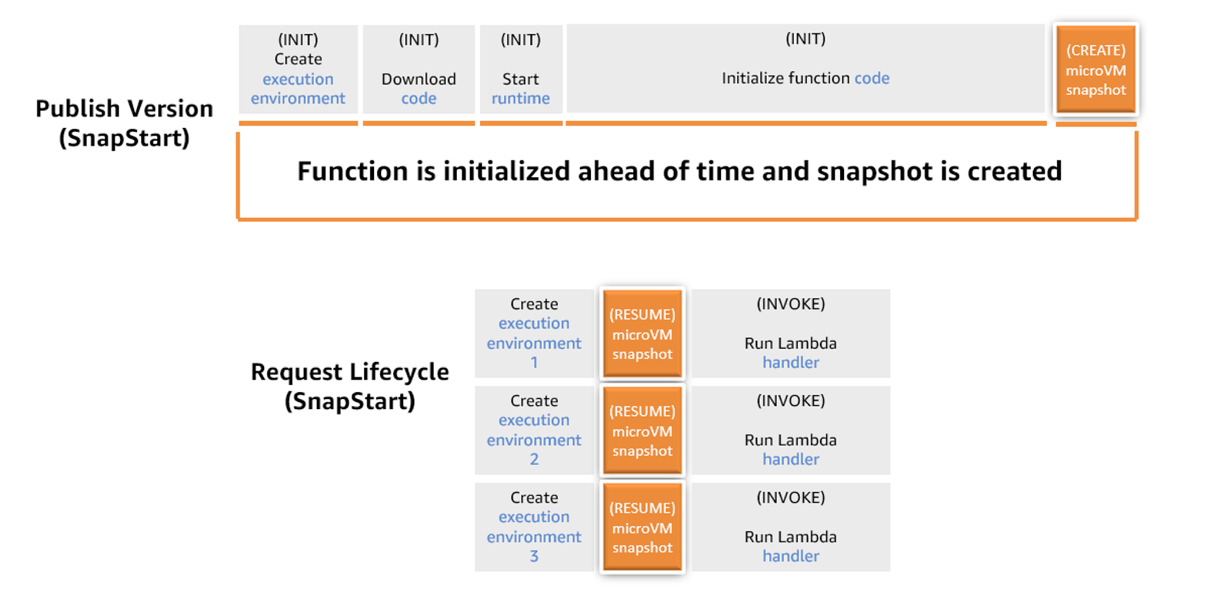
Figura 2. Ciclo de vida de invocação de funções com o SnapStart
Depois que o Lambda cria um snapshot , ele o regenera periodicamente para aplicar patches de segurança, atualizações de runtime e atualizações de software. Suas solicitações de invocação continuam funcionando durante todo o processo de regeneração.
Etapa 2: Armazenamento de snapshots para recuperação de baixa latência em escala Lambda
O Lambda opera em alta escala, processando dezenas de trilhões de solicitações de invocação todos os meses. Para gerenciar e recuperar snapshots com eficiência nesse volume de tráfego, o Lambda usa componentes de armazenamento e cache. Eles consistem em três camadas: Amazon S3 para armazenamento durável, um cache distribuído dedicado e um cache local nos nós de trabalho do Lambda.
O Lambda armazena snapshots de funções no Amazon S3, dividindo-os em blocos de 512 KB para otimizar a latência de recuperação. A latência de recuperação do Amazon S3 pode levar até centenas de milissegundos para cada bloco de 512 KB. Portanto, o Lambda usa um cache de duas camadas para acelerar a recuperação de snapshots.
Quando você ativa o SnapStart, durante o processo de otimização, o Lambda armazena partes do snapshot em um cache de camada dois (L2). Essa camada é uma frota dedicada de instâncias de cache distribuídas, criada especificamente pela Lambda. O Lambda armazena uma cópia separada de cada snapshot por zona de disponibilidade (AZ) da AWS. Para equilibrar desempenho e custos, o Lambda não pode armazenar proativamente fragmentos de snapshots não utilizados, mas sim armazená-los em cache depois de serem acessados pela primeira vez. Os fragmentos permanecem em cache na frota L2 enquanto sua versão de função estiver ativa. O desempenho da restauração de snapshots da camada L2 geralmente é de milissegundos de um dígito para um fragmento de 512 KB.
O Lambda também mantém um cache de camada um (L1) localizado nos nós de trabalho do Lambda, as instâncias do Amazon Elastic Compute Cloud (Amazon EC2) que lidam com invocações de funções. Essa camada está disponível localmente, portanto, fornece o desempenho mais rápido, normalmente 1 milissegundo para um bloco de 512 KB. Funções com invocações mais frequentes têm maior probabilidade de ter seus fragmentos de snapshots armazenados em cache nessa camada. Funções com menos invocações são automaticamente removidas desse cache, porque ele está limitado pela capacidade de disco da instância de trabalho. Quando um fragmento de snapshot não está disponível no cache L1, o Lambda recupera o fragmento da camada de cache L2.
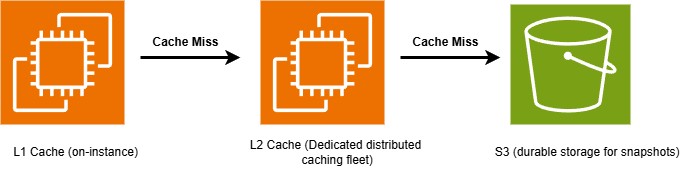
Figura 3. Cache hierárquico do SnapStart
Etapa 3: retomar a execução a partir de snapshots restaurados
A retomada da execução a partir de snapshots com baixa latência é o estágio final do SnapStart. Isso envolve carregar os fragmentos de snapshots recuperados em seu ambiente de execução de funções. Normalmente, somente um subconjunto do snapshot recuperado é necessário para atender a uma invocação. Armazenar snapshots como partes permite que o Lambda otimize o processo de retomada carregando proativamente somente o subconjunto necessário de partes. Para conseguir isso, o Lambda rastreia e registra os fragmentos de snapshot que a função acessa durante cada invocação da função, conforme mostrado na figura a seguir.
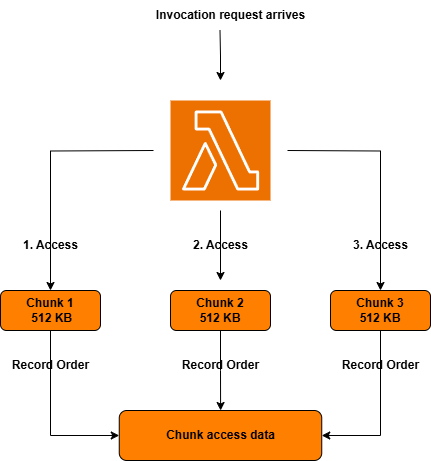
Figura 4. Invocação inicial, padrão de acesso ao fragmento de registro
Após a primeira invocação da função, o Lambda se refere a esses dados de acesso em blocos registrados para invocações subsequentes, conforme mostrado na figura a seguir. O Lambda recupera e carrega proativamente esse “conjunto de trabalho” de partes antes que elas sejam necessárias para execução. Isso acelera significativamente a latência de inicialização a frio. Se cada invocação executar o mesmo caminho de código, todos os fragmentos necessários serão rastreados após a primeira invocação. Se sua função do Lambda incluir um método que é invocado condicionalmente uma vez a cada cinco inícios a frio, o Lambda adiciona os fragmentos correspondentes que representam esse método aos metadados de acesso do fragmento após cinco inícios a frio.
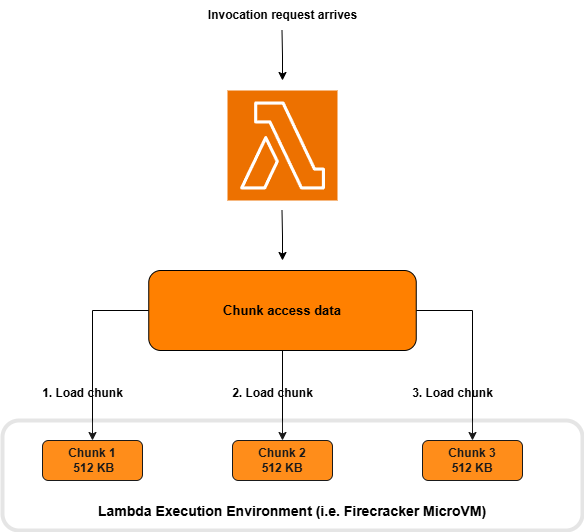
Figura 5. Invocação subsequente, fragmentos de carga em ordem de acesso
Compreendendo o desempenho da função SnapStart
A velocidade de restauração de um snapshot depende do conteúdo, do tamanho e do nível de cache usado. Como resultado, o desempenho do SnapStart pode variar de acordo com as funções individuais.
O desempenho da função melhora com mais invocações
As funções invocadas com frequência têm maior probabilidade de ter seus snapshots armazenados em cache na camada L1, que fornece a latência de recuperação mais rápida. Partes de snapshots acessadas com pouca frequência para funções com invocações esporádicas têm menos probabilidade de estar presentes na camada L1, resultando em uma latência de recuperação mais lenta das camadas de cache L2 e S3. Os dados de acesso em partes para funções com mais invocações também têm maior probabilidade de serem “completos”, o que acelera a latência da restauração de snapshots.
Pré-carregue caminhos de código (dependências) para otimizar a latência de restauração de snapshots
Para maximizar os benefícios do SnapStart, pré-carregue dependências, inicialize recursos e execute tarefas computacionais pesadas que contribuem para a latência de inicialização em seu código de inicialização em vez de no handler de funções. Caminhos de código não executados durante a fase de inicialização da função, como classes de aplicativos carregadas sob demanda por meio de injeção de dependência, não são incluídos no snapshot da função. Você pode melhorar ainda mais a eficácia do SnapStart executando proativamente esses caminhos de código durante a inicialização da função. Você também pode executar o código usando hooks de runtime e invocando seu handler durante a fase de inicialização antes de criar o instantâneo. Para conseguir isso, consulte a documentação e as postagens do Spring Boot e. Aplicativos .NET para implementar o ajuste de desempenho.
O desempenho varia dependendo do tamanho da função
O desempenho do SnapStart depende da rapidez com que o Lambda pode recuperar e carregar snapshots em cache em seu ambiente de execução de funções. Tamanhos de função maiores aumentam o tamanho dos snapshots e, portanto, o número de blocos, o que faz com que o desempenho seja diferente para funções de tamanhos variados.
Nem todas as funções se beneficiam do SnapStart
O SnapStart foi projetado para melhorar a latência de inicialização quando a inicialização da função demora vários segundos, devido a fatores específicos da linguagem ou devido à inicialização e ao carregamento de estruturas e dependências de software. Se suas funções forem inicializadas em centenas de milissegundos, é improvável que você tenha uma melhora significativa no desempenho com o SnapStart. Para esses cenários, recomendamos a Concorrência Provisionada, que pré-inicializa os ambientes de execução, oferecendo latência de dois dígitos em milissegundos.
Conclusão
O AWS Lambda SnapStart pode oferecer desempenho de inicialização de até menos de um segundo para funções Java, .NET e Python com longos tempos de inicialização. Esta postagem explora como o ciclo de vida do Lambda muda com o SnapStart e como o Lambda armazena e carrega snapshots com eficiência para melhorar o desempenho da inicialização. O SnapStart ajuda os desenvolvedores a criar aplicativos altamente responsivos e escaláveis sem provisionar recursos ou implementar otimizações complexas de desempenho.
Para saber mais sobre o SnapStart, consulte a documentação e as postagens de lançamento para Java, Python e .NET. Para ajustar o desempenho, consulte a seção de melhores práticas do SnapStart para saber o runtime de sua linguagem preferida. Esta postagem descreve abordagens para pré-carregar caminhos de código para otimizar ainda mais a latência de inicialização. Encontre mais informações e exemplos de aplicativos criados usando o SnapStart em Serverlessland.com.
Este conteúdo foi traduzido da postagem original do blog, que pode ser encontrada aqui.
Biografia dos Autores
 |
Ayush Kulkarni, Sr. Product Mgr Tech |
 |
Eric Heinz, Sr. Software Dev Engineer |
Biografia do Tradutor
 |
Rodrigo Peres é Arquiteto de Soluções na AWS, com mais de 20 anos de experiência trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados. |
Biografia do Revisor
 |
Daniel Abib é arquiteto de soluções sênior na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e segurança. Ele trabalha apoiando clientes corporativos, ajudando-os em sua jornada para a nuvem. |