O blog da AWS
Apresentando o suporte nativo do AWS Lambda para eventos Apache Kafka formatados em Avro e Protobuf
Por Nihar Sheth, gerente senior de produtos na Amazon Web Services.
O AWS Lambda agora fornece suporte nativo para eventos formatados em Apache Avro e Protobuf (Protobuf) com mapeamento de origem de eventos (ESM) do Apache Kafka ao usar o Modo Provisionado. O suporte permite que você valide seu esquema com registros de esquemas populares. Isso permite que você use e filtre os formatos de eventos binários mais eficientes e compartilhe dados usando o esquema de forma centralizada e consistente. Esta postagem do blog mostra como você pode usar o Lambda para processar eventos formatados em Avro e Protobuf a partir de tópicos do Kafka usando a integração do registro de esquema.
Esse novo recurso funciona com Amazon Managed Streaming for Apache Kafka (Amazon MSK), Confluent Cloud e clusters Kafka autogerenciados. Para começar, atualize seu Kafka ESM existente para o Modo Provisionado e adicione a configuração do registro do esquema, ou crie um novo ESM no Modo Provisionado com a integração do registro do esquema ativada.
Avro e Protobuf
Muitas organizações usam os formatos Avro e Protobuf com o Apache Kafka porque esses formatos de serialização binária oferecem vantagens sobre o JSON. Eles fornecem tamanhos de mensagem de 50 a 80% menores, desempenho mais rápido de serialização e desserialização, recursos robustos de evolução de esquemas e digitação robusta em várias linguagens de programação. Anteriormente, trabalhar com esses formatos nas funções do Lambda exigia código personalizado. Os desenvolvedores precisavam implementar clientes de registro de esquema, lidar com autenticação e armazenamento em cache, escrever uma lógica de desserialização específica para o formato e gerenciar cenários de evolução do esquema.
O que há de novo
O Kafka Event Source Mapping (ESM) do Lambda agora fornece integração integrada com o AWS Glue Schema Registry, o Confluent Cloud Schema Registry e o Confluent Schema Registry autogerenciado. Quando você define as configurações de registro do esquema para seu Kafka ESM, o serviço valida automaticamente os registros recebidos do esquema JSON, Avro e Protobuf em relação ao esquema registrado. Isso move a lógica complexa de integração do registro do esquema da sua camada de aplicativo para o serviço Lambda gerenciado.
Você pode criar sua função com a interface ConsumerRecords de código aberto do Kafka usando Powertools for AWS Lambda para obter diretamente seus objetos de negócios gerados pelo Avro ou Protobuf. Opcionalmente, você pode especificar para obter seus registros no formato JSON, onde sua função recebe dados JSON limpos e validados, independentemente do formato de serialização original, eliminando a necessidade de código de desserialização personalizado em suas funções do Lambda. Isso também permite que você crie consumidores do Kafka em várias linguagens de programação.
O Powertools for AWS Lambda é um kit de ferramentas para desenvolvedores que fornece suporte específico para Java, .NET, Python e TypeScript, mantendo a consistência com os padrões de desenvolvimento existentes do Kafka. Você pode acessar diretamente objetos de negócios sem código de desserialização personalizado.
Você também pode configurar regras de filtragem para descartar eventos irrelevantes formatados em JSON, Avro ou Protobuf antes das invocações de funções, o que pode melhorar o desempenho do processamento e reduzir custos.
Como funciona a validação do esquema
Ao configurar a integração do registro do esquema para seu Kafka ESM, você especifica o endpoint do registro, os detalhes da autenticação e quais campos de eventos (chave, valor ou ambos) devem ser validados. O ESM pesquisa seus tópicos do Kafka em busca de registros, como de costume, mas agora executa um processamento adicional antes de invocar sua função do Lambda. Para cada evento recebido, o ESM extrai o ID do esquema incorporado nos dados serializados. Ele busca o esquema correspondente do seu registro configurado. Esse processo ocorre de forma transparente, com as definições de esquema armazenadas em cache por até 24 horas para otimizar o desempenho. O ESM identifica o formato dos seus eventos usando metadados do esquema e valida a estrutura do evento. Ele mantém os dados binários originais ou os desserializa para o formato JSON com base na configuração do cliente e os envia para sua função para processamento.

Figura 1: Diagrama de fluxo de processamento do Kafka.
O ESM lida com a evolução do esquema automaticamente. Quando os produtores começam a usar novas versões do esquema, o serviço detecta as IDs de esquema atualizadas e busca as definições mais recentes do seu registro. Isso garante que suas funções sempre recebam dados desserializados adequadamente sem exigir alterações no código.
Formato de registro de eventos
Como parte da configuração do registro do esquema ESM, você precisa especificar o Event Record Format, que o Lambda usa para entregar registros validados à sua função. A configuração do registro do esquema oferece suporte a SOURCE e JSON.
O SOURCE preserva o formato binário original dos dados como uma string codificada em base64 com o ID do esquema anexado ao produtor removido. Isso permite a conversão direta em objetos Avro ou Protobuf para que você possa usar a interface ConsumerRecords do Kafka para uma experiência semelhante à do Kafka. Use esse formato ao trabalhar com linguagens de tipagem forte ou quando precisar manter todos os recursos dos esquemas Avro ou Protobuf. Em seguida, você pode usar qualquer desserializador Avro ou Protobuf para converter bytes brutos em seu objeto de negócios. O Powertools fornece suporte nativo para essa desserialização.
Com o JSON, o ESM desserializa os dados prontos para uso direto em linguagens com suporte nativo ao JSON. Use isso quando não precisar preservar o formato binário original ou trabalhar com classes geradas. Você também pode usar o Powertools para converter a base64 em seu objeto de negócios. Consulte a documentação sobre formatos de carga útil e comportamento de desserialização.
Se você configurar as regras de filtragem, elas operarão nos eventos formatados em JSON após a desserialização. Essa filtragem upstream evita invocações Lambda desnecessárias para eventos que não correspondem aos seus critérios de processamento, reduzindo diretamente seus custos de computação.
Configuração e configuração
Para usar esse recurso, você deve ativar o Modo Provisionado para seu Kafka ESM, que fornece os recursos de computação dedicados necessários para a integração do registro do esquema.
Você pode configurar a integração por meio do AWS Management Console, da AWS Command Line Interface (AWS CLI), dos AWS Language SDKs ou de ferramentas de infraestrutura como código (IaC), como o AWS Serverless Application Model (AWS SAM) ou o AWS Cloud Development Kit (AWS CDK).
A configuração do registro do esquema inclui a URL do endpoint de registro, o método de autenticação (AWS Identity and Access Management (IAM) para o AWS Glue Schema Registry ou registros de autenticação básica, SASL/SCRAM ou mTLS para o Confluent) e configurações de validação. Você especifica quais atributos de evento validar e, opcionalmente, define regras de filtragem usando a sintaxe padrão de filtragem de eventos do Lambda.
Para tratamento de erros, configure destinos de falha do Lambda para os quais os eventos que falham na validação ou desserialização do esquema são enviados. Isso garante que eventos problemáticos não desapareçam silenciosamente, mas sejam roteados para outros serviços, como Amazon Simple Queue Service (Amazon SQS), Amazon Simple Notification Service (Amazon SNS) e Amazon S3 para depuração e análise.
Ver os novos recursos em ação
Há vários padrões Serverless que você pode usar para processar fluxos do Kafka usando o Lambda. Este exemplo usa o padrão Java.
Implante um exemplo de cluster Amazon MSK
Para configurar um cluster Amazon MSK, siga as instruções no repositório do GitHub e crie uma nova pilha do AWS CloudFormation usando o arquivo de exemplo MSKandkafkaClientec2.yaml. A pilha cria o cluster Amazon MSK, junto com uma instância cliente do Amazon EC2, para gerenciar o cluster Kafka. Há custos envolvidos na execução dessa infraestrutura.
-
- Conecte-se à instância do EC2 usando o EC2 Instance Connect.
- Verifique se o tópico do Kafka foi criado verificando o conteúdo do arquivo kafka_topic_creator_output.txt.
Implante o registro do esquema Glue e a função Lambda do consumidor
A instância EC2 contém o software necessário para implantar o registro do esquema e a função Lambda.
- Mude o diretório para o diretório do pattern.
cd serverless-patterns/msk-lambda-schema-avro-java-sam - Crie o aplicativo usando o AWS SAM.
sam build - Para implantar seu aplicativo pela primeira vez, execute o seguinte no shell da instância EC2:
4. Você pode aceitar todos os padrões pressionando Enter. Você pode navegar até o console de registro do esquema AWS Glue e ver a definição do ContactSchema:
A função Lambda do consumidor (ESM) está configurada para o Modo Provisionado.
5. Visualize a configuração do ESM no console do Lambda para o nome da função Lambda prefixado com msk-Lambda-schema-avro-ja-lambdamskConsumer.
6. Escolha o gatilho do MSK Lambda que abre o painel Acionadores em Configuração.
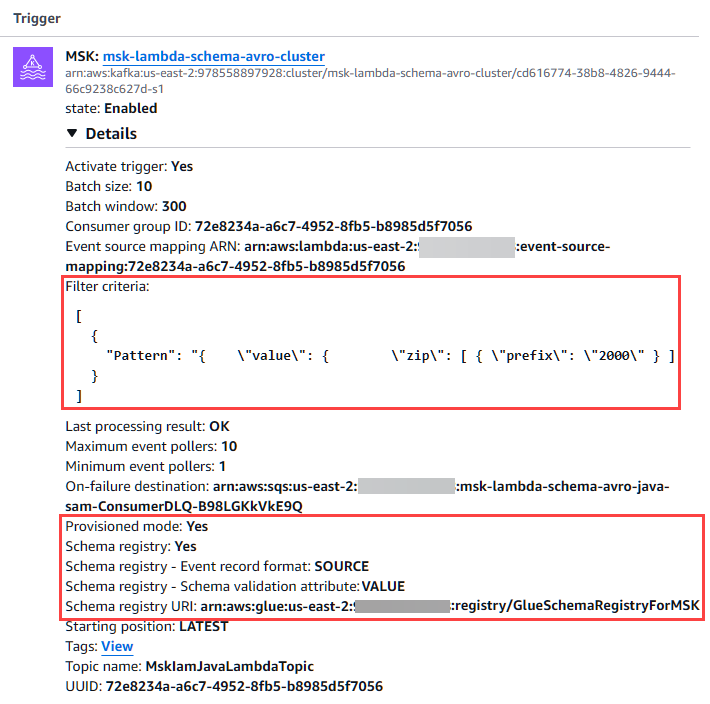
7. A configuração especifica o uso do formato de registro de eventos SOURCE para que sua função possa usar a interface ConsumerRecords de código aberto nativa do Kafka. O Powertools então desserializa a carga útil.
8. O atributo de validação do esquema é VALUE.
9. A configuração do filtro ESM processa somente os registros que correspondem aos códigos postais de 2000.
10. Em seu código de função, especifique a interface de código aberto Kafka ConsumersRecords incluindo o Powertools for Lambda como uma dependência. O ConsumerRecords fornece metadados sobre os registros do Kafka e permite que você tenha acesso direto aos objetos de negócios gerados pelo Avro/Protobuf sem exigir nenhum código de desserialização adicional.
Registros de produção e consumo
Para enviar mensagens para Kafka, há uma função Java do LambdaMSK Producer.
- Invoque a função do console Lambda ou da CLI na instância do EC2.
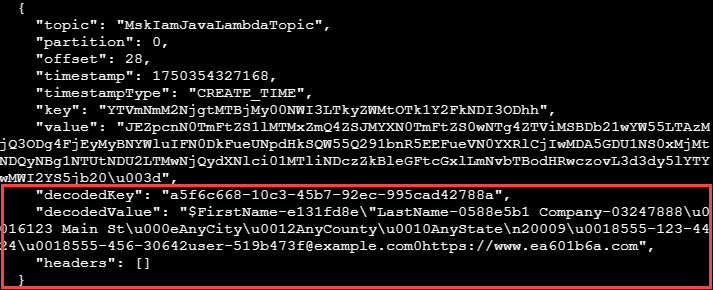
- Você pode visualizar os registros do produtor para ver os 10 registros produzidos. A função Lambda do consumidor processa os registros.
- Visualize os registros da função Lambda do consumidor usando o console de registros do Amazon CloudWatch ou a CLI na instância EC2.
Limpando
Você pode limpar o exemplo da função Lambda executando o comando sam delete.
Se você criou o cluster Amazon MSK e a instância do cliente EC2, navegue até o console do CloudFormation, escolha a pilha e escolha Excluir.
Considerações sobre desempenho e custo
A validação e a desserialização do esquema podem aumentar o tempo de processamento antes da invocação da função. No entanto, essa sobrecarga geralmente é mínima quando comparada aos benefícios. O armazenamento em cache do ESM minimiza as chamadas de API do registro do esquema. O uso da filtragem permite reduzir custos, dependendo da eficácia com que suas regras de filtragem eliminem eventos irrelevantes. Esse recurso simplifica a sobrecarga operacional do gerenciamento do código de integração do registro do esquema para que as equipes possam se concentrar na lógica de negócios e não nas preocupações com a infraestrutura.
Tratamento e monitoramento de erros
Se os registros de esquema ficarem temporariamente indisponíveis, os esquemas em cache permitirão que o processamento de eventos continue até que o registro esteja disponível novamente. Falhas de autenticação geram mensagens de erro com lógica de repetição automática. A evolução do esquema acontece perfeitamente, pois o Lambda detecta e busca automaticamente novas versões.
Se os eventos falharem na validação ou desserialização, eles serão roteados para seus destinos de falha configurados. Para destinos do Amazon SQS e do Amazon SNS, o serviço envia metadados sobre a falha. Para destinos do Amazon S3, tanto os metadados quanto a carga original serializada são incluídos para análise detalhada.
Você pode usar o monitoramento padrão do Lambda, com mais métricas do CloudWatch fornecendo visibilidade das taxas de sucesso da validação do esquema, do uso da API de registro e da eficácia da filtragem.
Conclusão
O AWS Lambda agora oferece suporte aos formatos Avro e Protobuf para processamento de eventos do Kafka no modo provisionado para o Kafka ESM. Isso permite a validação do esquema, a filtragem de eventos e a integração com os clusters Amazon MSK, Confluent e Kafka autogerenciados. Se você está criando novos aplicativos Kafka ou migrando consumidores existentes para o Lambda, essa integração nativa de registros de esquemas simplifica os pipelines de processamento.
Para obter mais informações sobre os recursos de integração do Lambda Kafka, acesse o guia de aprendizado, a documentação do Lambda ESM. Para saber mais sobre os preços do Lambda, como os custos do Modo Provisionado, visite a página de preços do Lambda.
Para obter mais recursos de aprendizado Serverless, visite Serverless Land.
Este conteúdo foi traduzido da postagem original do blog, que pode ser encontrada aqui.
Biografia do Autor
 |
Nihar Sheth, gerente senior de produtos na Amazon Web Services |
Biografia do tradutor
 |
Daniel Abib é Arquiteto de Soluções Sênior e Especialista em Amazon Bedrock na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e especialização em Machine Learning. Ele trabalha apoiando Startups, ajudando-os em sua jornada para a nuvem. https://www.linkedin.com/in/danielabib/ . |
Biografia do Revisor
 |
Rodrigo Peres é Arquiteto de Soluções na AWS, com mais de 20 anos de experiência trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados. |