Amazon Web Services ブログ
Amazon FSx for Lustre のスケーラブルなメタデータパフォーマンスでファイルシステムワークロードのより高いパフォーマンスを実現
映画スタジオのように、膨大な量のビデオファイル、スクリプト、アニメーションアセットを扱う会社を想像してみてください。これらのファイルは Amazon FSx for Lustre などの高性能ファイルシステムに格納されます。Amazon FSx for Lustre は、世界で最も普及している高性能ファイルシステム上に構築された完全マネージド型の共有ストレージです。各ファイルには POSIX 情報などのメタデータがあります。スタジオのプロジェクトが増えるにつれて、ファイルやディレクトリの数も増えます。ファイルの検索や、ファイルへのアクセス、ディレクトリ内の一覧表示を実施する必要がある場合、システムはこのメタデータをすばやく取得して管理する必要があります。しかしながら、従来のファイルシステムでは、ファイル数が特に数百万または数十億に増加すると、メタデータ操作が大幅に遅くなる可能性があります。この速度低下がボトルネックとなり、ファイルの取得が遅れ、チームの生産性が低下する可能性があります。これは、厳しい締め切りの中で作業する場合に非常に重要です。
FSx for Lustre は、CPU と GPU を最大容量で使用し続け、TB/秒のスループットと数百万 IOPS に達する高速ストレージを必要とするアプリケーション向けに設計されています。何千ものコンピューティングインスタンスから同じファイルやディレクトリへ同時アクセスをサポートしながら、ファイル操作において一貫性のあるミリ秒未満のレイテンシーを提供することは、多くのワークロードを実現に結びつきます。FSx for Lustre は、図 1 に示すようにオブジェクトストレージサーバ (OSS) を使用して複数のノードにファイルを分散します。そのため、ストレージ容量とスループットのバランスをとるために、各読み取りまたは書き込み操作はクラスター全体で並列化されます。FSx for Lustre は専用のメタデータサーバ (MDS) を使用してメタデータ操作をサポートします。

図 1. スケーラブルなメタデータ機能以前の FSx for Lustre 構成図
ファイルシステムのメタデータパフォーマンスは、ファイルシステムが 1 秒あたりに作成、一覧表示、読み取り、削除できるファイルやディレクトリの数を決定します。メタデータを集中的に使用するワークロードでは、多数の小さなファイルの作成、処理、操作が必要となることが多くあります。FSx for Lustre は、プロビジョニングされたストレージ容量に基づいて、デフォルトのメタデータパフォーマンスレベルを自動的に提供します。スケーラブルなメタデータ機能がリリースされる以前は、デフォルトよりも多くのメタデータ操作を必要とするユーザーは、より大きなファイルシステムを作成するか、データを複数のファイルシステムに分割する必要がありました。スケール可能なメタデータのリリースにより、ユーザーはプロビジョニングされたストレージとは独立して、利用可能なメタデータ IOPS を最大 15 倍まで増やすことができるようになりました。これにより、最もメタデータを集中的に使用するワークロードでも利用が可能になります。さらに、この機能は図 2 に示すように、ファイルシステムの作成時に有効にすることも、ファイルシステムの作成後に有効にすることも可能で、特定のファイルシステムに対してメタデータ操作専用の IOPS の量を増やすことができます。

図 2. スケーラブルなメタデータ機能を備えた FSx for Lustre 構成図
ワークロードやユースケース
この新機能により、データ管理が合理化され、機械学習(ML)、電子設計自動化(EDA)、財務分析リスクシミュレーションなど、メタデータを多用するワークロードを必要とするユースケースの効率が向上します。EDA における基礎設計や、研究者がプロジェクト作成中にデータセットの名前を変更するといった作業負荷は、メタデータを多用する性質上、ファイルシステムに大きな負荷をかけます。MDTest を使用してこれらの操作の上限をテストできます。
メタデータパフォーマンス
特定のワークロードに FSx for Lustre ファイルシステムを導入するには、パフォーマンスを最適化する上でメタデータ IOPS がどのように重要な役割を果たすかを理解する必要があります。図 3a に示すように、自動モードの FSx for Lustre はファイルシステムのストレージ容量に基づいてメタデータ IOPS を自動的に割り当てるため、プロセスが簡素化されます。このアプローチでは、IOPS の数とストレージのサイズが相関関係にあるため、手動で調整しなくても大半のワークロードで適切なレベルのパフォーマンスが得られます。たとえば、1,200 GiB のストレージを備えたファイルシステムは自動的に 1,500 のメタデータ IOPS を受け取りますが、大規模なシステムでは 12,000 GiB を超える容量の場合、最大 12,000 メタデータ IOPS にスケールアップします。
一方、ユーザープロビジョニングモードでは、よりきめ細かい制御が可能です。ストレージ容量に関係なく、必要なメタデータ IOPS の正確な値を手動で指定できます。このモードは、自動モードでは対応しきれないメタデータ IOPS を要するワークロードに適しています。

図 3a. ファイルシステムのメタデータパフォーマンス
FSx for Lustre は、図 3b に示すように、ファイルの作成、削除、ディレクトリ操作などにメタデータ操作を分類し、それぞれ 1 秒あたりの処理レートが異なります。これは、数百万にも及ぶファイルシステムの IOPS とは異なります。たとえば、ファイル削除の操作はプロビジョニングされた IOPS ごとの 1 秒あたりの処理レートが 1 であるのに対し、ファイル作成やファイルを開く操作は 1 秒あたりの処理レートが 2 となります。プロビジョニングされた IOPS の値を、ワークロードが必要とする特定の種類の操作に合わせれば、FSx for Lustre はメタデータを効率的に処理できるようになります。この最適化は、ファイルシステム全体のパフォーマンスを向上させるだけでなく、ストレージや運用上のニーズの拡大に応じたスケーラビリティもサポートします。

図 3b. ファイルシステムのメタデータパフォーマンス
前提条件
この操作手順では、次の前提条件を満たす必要があります。
- AWS アカウント
- FSx for Lustre ファイルシステムの作成および変更
- Slurm を利用した既存の AWS ParallelCluster の使用
- AWS ParallelCluster での Amazon Elastic Compute Cloud (Amazon EC2) インスタンスの作成
- Lustre クライアントのチューニングに関する理解
- Linux コマンドラインの実践的な知識
- Amazon CloudWatch ダッシュボードの作成
メタデータパフォーマンスの設定方法
新しい FSx for Lustre ファイルシステムを作成する場合、図 4a に示すように、メタデータパフォーマンスを自動モードとして定義する新しいオプションがあります。この場合、IOPS はファイルシステムの容量 (24 TiB のストレージあたり 12,000 メタデータ IOPS) に基づいて自動的に定義されます。または、図 4b に示すように、ユーザープロビジョニングモードとして定義することもできます。この場合、ユーザーはメタデータ IOPS の値に 1,500、3,000、6,000、あるいは 192,000 メタデータ IOPS までの 12,000 の倍数を指定できます。ユーザーは、AWS マネジメントコンソール、AWS Command Line Interface (AWS CLI),、または AWS Software Development Kits (SDKs) を使用して、メタデータパフォーマンスを向上させる機能を持った FSx for Lustre ファイルシステムを作成できます。

図 4a. メタデータ設定の自動モード
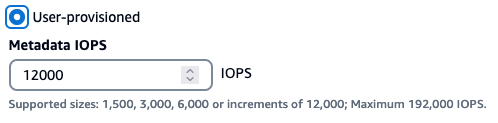
図 4b. メタデータ設定のユーザープロビジョニングモード
テストの実行
このセクションの目標は、さまざまなワークロードシナリオにおける標準のメタデータ設定とスケールされたメタデータ設定のメタデータパフォーマンスを比較することです。また、これらのテストをお客様の AWS アカウントで再現する手順についても説明します。
図 5 は、コンソールで作成されたファイルシステムの例を示しています。この特定のファイルシステムは 12 TiB のストレージで構成されており、1,500 MB/秒のスループット (125 MB/秒) と 192,000 のメタデータ IOPS を実現しています。この構成は、スループット要件は低くメタデータ操作が集中するアプリケーション向けに調整されています。

図 5. 192,000 メタデータ IOPS で作成されたファイルシステム
このテストシナリオでは、2 組の大規模ファイルシステムを作成しました。いずれも P250 と P1000 のスループット構成で、一方はスケールされたメタデータを持たないサイズが 12 TiB のファイルシステム、もう一方は 192,000 IOPS のスケールされたメタデータを持つサイズが 12 TiB のファイルシステムです。
AWS ParallelCluster を使用して、この HPC ベンチマークを実行するためのクラスターを構築しました。以下の設定の c5.9xlarge インスタンスタイプのクライアント EC2 インスタンスが 200 個あります。
Instance type: c5.9xlarge
Operating Systems: Amazon Linux 2
Linux Kernel: 5.10.219-208.866.amzn2.x86_64
mpi version: Open MPI 4.1.6
lustre version: 2.12.8_198_gde6dd89_dirty
ENA driver: 2.12.0g
Ranks for job: 800
ParallelCluster: 3.10.1
Lustre クライアント側のパラメータ
sudo lctl set_param osc.*OST*.max_rpcs_in_flight=32
sudo lctl set_param mdc.*.max_rpcs_in_flight=64
sudo lctl set_param mdc.*.max_mod_rpcs_in_flight=50
sudo lctl set_param osc.*.max_dirty_mb=64
Lustre パフォーマンス設定の詳細については、FSx for Lustre パフォーマンスガイドとオンラインの Lustre ドキュメントを詳しく調べてください。
テストツールとして、このシナリオではオープンソースの MDTest を使用してメタデータの I/O シミュレーションを行います。
MDTest のインストールと実行
次のコマンドは、OpenMPI ライブラリとコンパイラを使用してユーザーの PATH と LD_LIBRARY_PATH で実行しました。
$ git clone https://github.com/hpc/ior.git
$ cd ior
$ ./bootstrap
$ ./configure --prefix=/opt/parallelcluster/shared
$ make all
$ make install
この時点で、トラブルシューティングを行ったり、テストを積極的に監視したりしたい場合に備えて、MDTest を起動するためのインタラクティブジョブを実行しています。
$ srun --nodes=200 --ntasks-per-node=32 --time=12:00:00 --pty bash -i
EC2 インスタンスが利用可能になった時点で、そのテストを実施するために、自分の UID がフルアクセス権限を持つサブディレクトリを作成しました。
(例)
$ sudo mkdir -p /fsx/mdTestFiles
$ chown 1000:1000 /fsx/mdTestFiles
次に、ジョブを実行します。このジョブは 3 回繰り返され、ワークロードの平均を確認できます。
$ mpirun --mca plm_rsh_num_concurrent 800 --mca routed_radix 800 --mca routed direct --map-by node --mca btl_tcp_if_include eth0 -np 800 /opt/parallelcluster/shared/bin/mdtest -F -v -n 4000 -i 3 -u -d /fsx/mdtestFilesMDTest オプションの説明 :
-F: ファイルのみでテストを実行 (ディレクトリを含まない)
-v: 詳細出力
-n 4000: ランクごとに create/stat/read/remove を行うディレクトリやファイルの数
-i 3: テストを実行する反復回数
-u: 各ランクに固有の作業ディレクトリ
-d: ジョブのルートディレクトリ
図 6 は単一メタデータターゲット (MDT) を持つ 12 TiB のファイルシステムで実行された最初のジョブの出力例を示しています。
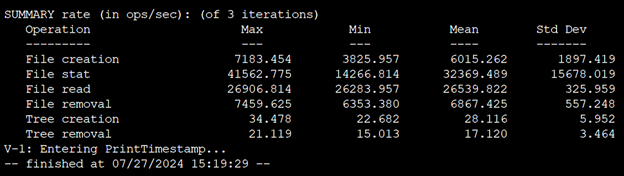
図 6. MDTest 実行時の出力例
このセクションでは、先の図における単一メタデータターゲット (MDT) 12 TiB の FSx for Lustre ファイルシステムの最初のテストで確認されたことを詳しく説明します。ファイル作成 (create) は、1 つのプロセスイベントで 1 ファイルずつ作成されます。これは小さな書き込みワークロードと解釈できます。統計 (stat) の観点から見ると、これは Lustre にとってコストのかかる操作になる可能性があり、ツリーウォークや大規模な “ls -l” がどのように動作するかを表しています。ファイルの読み取り (read) は読み取りワークロードであり、ファイルの削除 (remove) はファイルシステムからファイルを完全に消去することです。メタデータサーバへの負荷は、イベントごとに異なります。
図 7 はクライアントの数とキャパシティを同じ条件に保ちながら、異なるファイルシステムタイプで実施した複数回の実行結果を包括的にまとめた表になります。

図 7. MDTest の結果
上の表は、それぞれメタデータ IOPS が 12,000 と 192,000 のファイルシステムのパフォーマンスの違いを示しています。パフォーマンスの違いは操作タイプに関連しており、メタデータ IOPS が高いほどすべてのテストで改善が見られます。ワークロードの要件によって FSx for Lustre のメタデータ IOPS を高める明確な方法があります。
ファイルシステムのメタデータメトリクスの監視
ファイルシステムの稼働時には、CloudWatch メトリクスを使用してメタデータのパフォーマンスを監視し、増加するワークロード要件に対応するため、必要に応じてパフォーマンスをスケールアップすることができます。FSx for Lustre の監視は、システムの安定性を維持し、発生する可能性のある問題に迅速に対処するために不可欠です。CloudWatch は監視の中心的なツールとして機能し、FSx for Lustre からリアルタイムのメトリクスを継続的に収集して処理します。CloudWatch アラームを設定すると、異常時やパフォーマンスのしきい値に超えたときに、管理者は Amazon Simple Notification Service (Amazon SNS) を通じて即座に通知を受け取ることができ、潜在的な問題を軽減するための対応が可能になります。
FSx for Lustre は、デフォルトで 1 分間隔でメトリクスデータを CloudWatch に自動的に送信し、これらのメトリクスは raw バイトで報告されます。CloudWatch とその機能の詳細については、CloudWatch ユーザーガイドを参照してください。
FSx for Lustre は、そのメトリクスを CloudWatch の FSx 名前空間に発行します。新しいスケーラブルメタデータ機能により、図 8a、8b、8c に示すような新しいメトリクスを利用して、メタデータ操作の詳細を確認できるようになりました。新しいメトリクスには DiskReadOperations や DiskWriteOperations、FileCreateOperations、FileOpenOperations、FileDeleteOperations、StatOperations、RenameOperations があります。これらのメトリクスからより詳細なデータが利用可能になるため、FileSystemID (特定のファイルシステム用) と StorageTargetID (特定の MDT – メタデータターゲット用) を使用してデータを絞り込むことができます。

図 8a. CloudWatch ダッシュボードにおける新しいメタデータメトリクス

図 8b. CloudWatch ダッシュボードにおける新しいメタデータメトリクス

図 8c. CloudWatch ダッシュボードにおける新しいメタデータメトリクス
FSx for Lustre のスケーラブルなメタデータ用の AWS CloudFormation テンプレートをダウンロードするにはこちらを利用してください :
![]()
料金
このソリューションを試す場合、費用が発生します。このソリューションでは EC2 インスタンス、FSx for Lustre ファイルシステム、および CloudWatch ダッシュボードを実行しています。
料金の詳細は、FSx for Lustre、 EC2 インスタンス、および CloudWatch の料金ページで確認できます。
クリーンアップ
今後の確認に備えて、必要なすべてのパフォーマンスの実行をバックアップします。
FSx for Lustre ファイルシステムと関連するコンピューターリソースを削除して、そのプロジェクトの課金を終了してください。CloudFormation ページよりダッシュボードを削除して、アカウントから削除してください。
必要に応じて ParallelCluster を管理してください。コストを節約するために、不要になったら削除してください。
まとめ
この新機能の影響は広範囲に及び、特に要求の厳しい AI/ML や HPC ワークロードを実行している組織にとって重要です。これらのワークロードでは、多くの場合、膨大な数の小さなファイルの作成、処理、操作が行われ、メタデータパフォーマンスに大きな負荷がかかります。Amazon FSx for Lustre ではメタデータパフォーマンスをスケールすることで、ユーザーはワークロードを 1 つのファイルシステムに統合できます。これは、ワークロードを分割せずにワークロードをより大規模に実行すること、メタデータパフォーマンスを容易に向上させ変化するパフォーマンス要件に適応すること、メタデータパフォーマンスをストレージ容量から切り離してリソースの使用を最適化することで実現されます。
このブログは 2025 年 2 月 21 日に Tom McDonald (Senior Workload Storage Specialist) によって執筆された内容を日本語化したものです。原文はこちらを参照してください。
この記事を読んでいただきありがとうございました。
翻訳はクラウドサポートエンジニアの奥野が担当しました。