Amazon Web Services ブログ
NTTドコモのモバイルネットワークにおけるサービス障害検知の迅速化(第一弾)
1. はじめに
昨今のモバイルネットワーク は、人同士のコミュニケーションツールから、いまでは決済、物流など様々なサービス・生活を支える重要な社会基盤へと進化しており、これまで以上に安定したサービスの提供が求められています。一方で、モバイルネットワークの拡張と複雑化が進み、通信事業者にとってより早く異常を検知し、被疑箇所を特定し、迅速に復旧を行うことは大きな課題となっています。
これまで、NTT ドコモは、装置からの警報を契機とした設備監視を行い、異常時にサービス影響のある障害であるかを切り分けていました。トラフィックの変動から異常を検知するための可視化システムを構築することで、オペレーターが早期にサービス障害に気付き迅速に周知広報や措置回復させることでより安定したモバイルサービスを提供することを可能としました。
参考:2023 年 5 月 「電気通信サービスにおける 障害発生時の周知・広報に関する ガイドライン」が策定され、 障害発生時刻から原則 30 分以内の初報の公表が必要とされました。
2. 可視化システムの要件
ドコモでは障害を早期に検知する方法として、現在のトラフィックの状態と平時のトラフィックの状態それぞれの推移を時系列で可視化することを目指しました。トラフィックの状態を表すメトリクスとしては、モバイルネットワーク装置から監視装置を経由して収集している PM: Performance Management データ (トラフィックデータ)を使います。
新規の可視化システムを開発するにあたり、以下の要件がありました。
- トラフィックデータの前処理要件:
- 収集したトラフィックデータを解凍し、データを整形し、装置情報のマッピングを行うETL機能
- ダッシュボードの表示要件:
- 最短 1 分間隔での自動更新機能
- リアルタイム性能要件:
- データ受信から表示までの全処理を数分以内に完了
- ダッシュボード上のクエリ応答(ダッシュボード画面の表示時間)は 10 秒以内
- コスト最適化要件:
- 大容量データに対応した効率的なシステム設計の実現
- システム運用における維持費用の最小化
上記のうち、特に最も重要な要件は、リアルタイム性要件です。より迅速に障害を検知するためには、トラフィックデータを受信してから可視化しオペレーターが異常を検知するまでの時間をできる限り短縮する必要があります。また、そのような状況下でダッシュボードの表示時間ができる限り短い時間であることも利用者であるオペレータにとって非常に重要な要件になります。一方で、トラフィックデータは、最短 1 分周期で装置群単位で大量のメトリクスを扱っており、多くの同時読み書きトランザクションが発生することが想定されます。したがって、大量の同時読み書きトランザクションが常時発生するシステムにおいてリアルタイム性を実現することが重要なポイントになります。
3. ソリューション
上記要件を満たすソリューションとして新規に構築したシステムのアーキテクチャ図は以下になります。
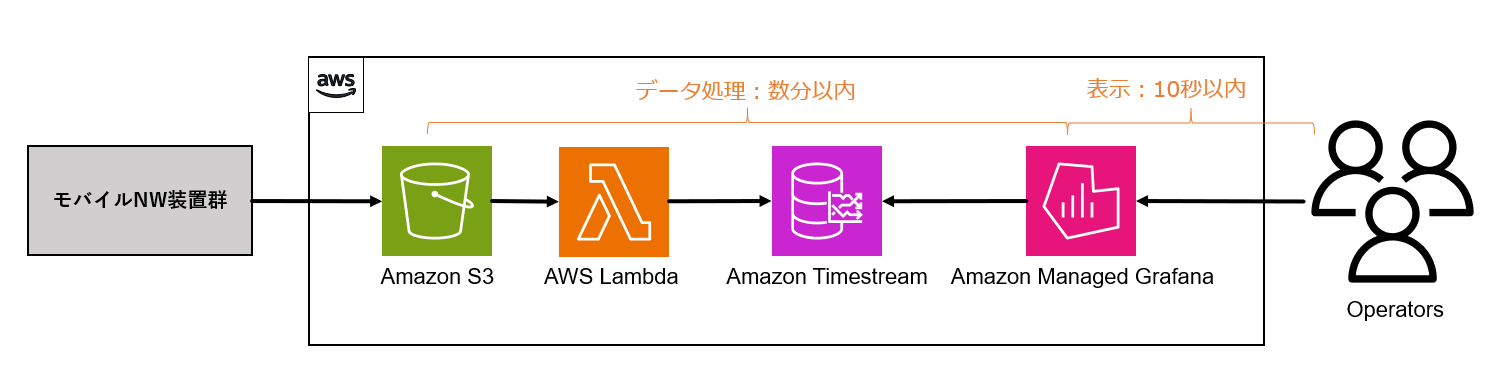
図1. アーキテクチャ概要
- データが Amazon S3 にアップロードされたことをトリガーとして AWS Lambda が起動します。
- AWS Lambda によりファイルの解凍、データの抽出、集計など必要な ETL 処理が行われ、Amazon Timestream に可視化に必要なデータを格納します。
- Amazon Managed Grafana のダッシュボード から Amazon Timestream に対して最短 1 分間隔のクエリが発行され、取得したデータのメトリクスの可視化がされます。
- Amazon Managed Grafana のダッシュボードは、最短 1 分ごとに自動更新されほぼリアルタイムでトラフィックの変動が確認できます。
本アーキテクチャのポイントとしては、以下 4 つあります。
- サーバーレスアーキテクチャの採用
- ドコモのオペレーション現場では、サービス影響可視化システムはオペレーションに使用するツールの 1 つであり、モバイルネットワークに対する保守運用が集中すべき業務であり、ネットワークビジネスの運用コスト削減のためにもシステム基盤の運用はなるべく軽減する必要があります。そこで、AWS のサーバーレスアーキテクチャを採用することでインフラ部分の運用が不要になり運用コストをできる限り抑えています。
- Amazon Timestream と Amazon Managed Grafana による統合サービスの活用
- Amazon Timestream は、1 分あたり数十 GB を超える時系列データを取り込み、TB 規模の時系列データに対して SQL クエリを数秒で実行できる時系列データベースサービスです。ドコモでは、リアルタイム性の要件が強く、また、今後拡大するデータ量を考慮して Amazon Timestream を採択しました。
- Amazon Managed Grafana は、 オープンソースの Grafana をベースにしたフルマネージドサービスで運用データを簡単に可視化します。ダッシュボードの自動更新機能がある点と Amazon Timestream とシームレスに連携でき、親和性に優れている点からリアルタイム性監視用途に向いているため採択しました。
- 採用にあたっては、机上検討だけではなく、PoC の実施により実際のデータに近いサンプルデータを使って機能評価および性能評価を行い、要件を満たせることを確認しました。
- 複雑な集計処理はクエリ側ではなく AWS Lambda 側で実装
- トラフィックの変動から異常を検知するために過去のトラフィックデータと現在のトラフィックデータの比較を行い、その乖離が大きい場合に検知を行う目的があったため、その乖離率の算出を行う必要がありました。Amazon Managed Grafana から Amazon Timestream に対しての SELECT 文で集計を行う方法と、AWS Lambda 側で集計を行ってから Amazon Timestream に投入する方法があります。前週比較のみのような簡易な集計の場合は前者を、数週間分の比較や複雑な統計関数を使用する場合には後者、と使い分けることでリアルタイム性を保つような工夫を行っています。結果として、10 秒以内でのクエリ結果の可視化(ダッシュボード画面の表示)を行うことを実現できました。
- コスト効率が良いデータの扱い
- トラフィックデータは TB を超えるほどのデータ量があります。オペレータが扱いたいデータを予め定義し可視化に必要な分だけ AWS Lambda で抽出を行うことで Amazon Timestream や Amazon Managed Grafana で扱うデータ量を最小限に絞りコスト最適化を図っています。
オペレータ向けに提供された可視化画面は以下になります。モバイルネットワークを構成するコンポーネントの 1 つであるコアネットワークのコントロールプレーンを制御する装置である MME のトラフィックデータを時系列で地域別に表示しています。以下の例では、Attach の試行数/成功数/成功率について平時の値と重ねて表示しており、オペレータが異常に気付けるようになっています。
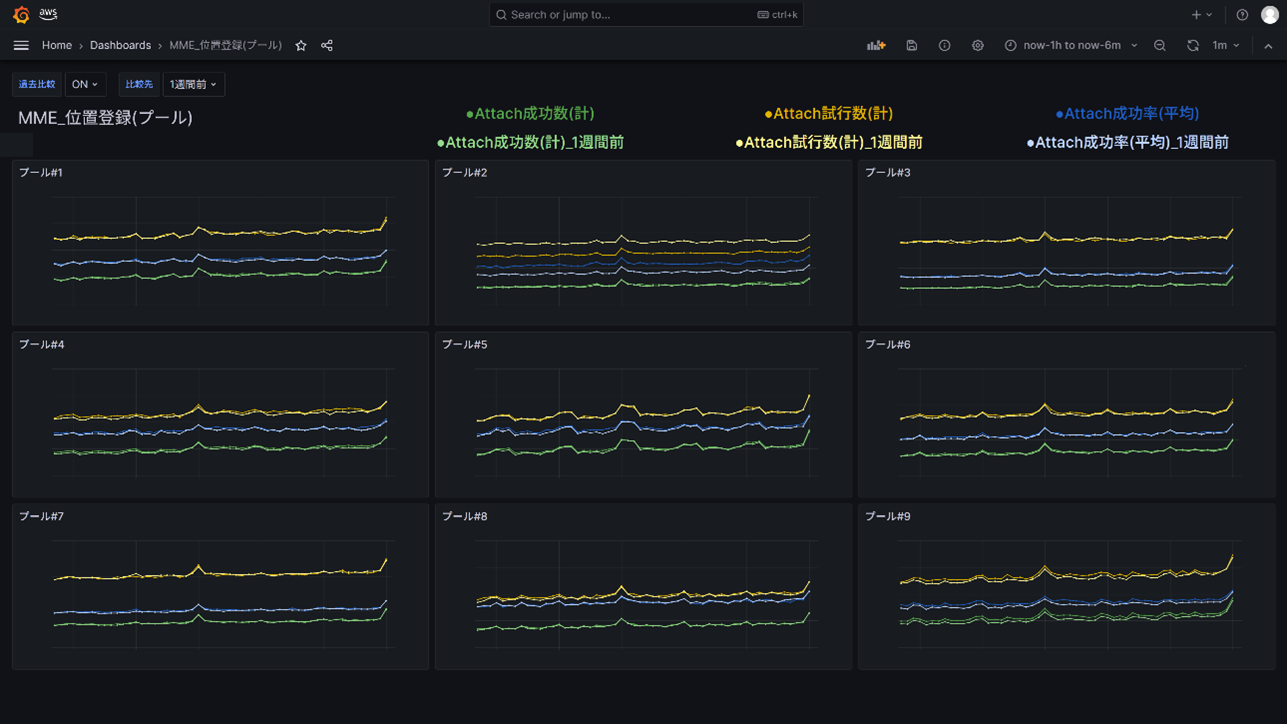
図2. Amazon Managed Grafana による可視化画面
4. まとめ
結果として、NTT ドコモにおけるモバイルネットワークのオペレーション現場に、既存の監視では迅速に気づくことが難しいサービス障害を迅速に検知できる仕組みを導入しました。また、トラフィックデータの状態を可視化したことで、故障発生時の障害箇所の切り分けにも使用でき、より迅速な復旧措置にもつながっています。
本稿では、取り組みの背景とアーキテクチャ概要についてご紹介しました。第二弾では、より技術的な実装方法をご紹介します。
著者

株式会社 NTTドコモ
ネットワーク本部 サービスマネジメント部 オペレーションシステム DX 担当
今井 識
株式会社 NTTドコモにて、モバイルネットワークの遠隔監視・措置業務向け可視化システムの企画・開発・運用を一貫して行うチームのマネジメントと技術課題解決のリードを担当しています。

アマゾン ウェブ サービス ジャパン合同会社
宮崎 友貴
ソリューションアーキテクトとして通信業界のお客様の AWS 活用 を支援しています。

アマゾン ウェブ サービス ジャパン合同会社
高野 翔史
ソリューションアーキテクトとして製造業界のお客様の AWS 活用 を支援しています。