Amazon Web Services ブログ
クロスリージョンのスタンバイレプリカによるAmazon RDS for Db2の高可用性と高速な災対切り替えの実現
本投稿は AWSの Javeed Mohammed、 Rajib S Sarkar と Sumit Kumar による寄稿を翻訳したものです。
Amazon Relational Database Service (Amazon RDS) for Db2 は、マルチ AZ デプロイメントを通じて高可用性 (HA) を提供します。マルチ AZ が有効な場合、Amazon RDS は同じ AWS リージョン内にデータの冗長な同期レプリケーションされたスタンバイコピーを維持します。プライマリインスタンスに書き込まれたデータは、ブロックレベルのストレージレプリケーションを介してスタンバイインスタンスに同期的にレプリケーションされます。プライマリインスタンスに問題が発生した場合、Amazon RDS は自動的にスタンバイに切り替わり (通常 60 秒以内)、データの可用性を継続的に確保します。自動フェイルオーバーが発生した場合でも、アプリケーションは裏側で何が起きているかを知る必要はありません。DB インスタンスの CNAME レコードは、新しく昇格したスタンバイを指すように変更されます。エンドポイントは同じままですが、DB インスタンスへの既存の接続を再確立する必要があります。プライマリインスタンスとスタンバイインスタンスは、同一リージョン内の異なるアベイラビリティーゾーンに配置されており、そのためマルチ AZ と呼ばれています。この分離により、両方のインスタンスが同じ障害の影響を受ける可能性が大幅に低減されます。マルチ AZ デプロイメントは RDS DB インスタンスの可用性と耐久性を向上させ、本番環境のワークロードに理想的な選択肢となります。
多くのエンタープライズのお客様にとって、ビジネス継続性を確保するために本番環境を予期せぬ障害から保護することは重要な要件となっています。Amazon RDS は耐障害性の高いマルチ AZ 構成を提供していますが、自然災害、悪意のあるイベント、データベースの破損、ワークロードが劣化状態で動作する原因となるイベントなど、全ての潜在的なリスクを防ぐことができるわけではありません。別のリージョンで実行することが、有効な対策の 1 つとなります。業務を継続的に運用するためには、包括的な災害対策 (DR) 計画を策定し、検証することが不可欠です。このような要件においてはは、別のリージョンへのデータ保存とダウンタイムの削減が必要になるため、RDS for Db2 のスタンバイレプリカ機能が重要になります。この機能により、別の AWS リージョンにデータベースのスタンバイレプリカを維持することができ、リージョン内のマルチ AZ 構成を超えた冗長性の追加レイヤーを提供します。
あるリージョンのデータベースが利用できなくなった場合、データベースのバックアップの復元を待つことなく、別のリージョンのスタンバイレプリカをすぐに昇格させて運用を再開できます。
マルチ AZ 配置とクロスリージョンのスタンバイレプリカを組み合わせることで、高可用性と災害対策のための包括的な対策を提供し、Db2 ワークロードの回復性と応答性を維持し、ミッションクリティカルな要件に対応できます。
詳細については、Working with replicas for Amazon RDS for Db2 をご参照ください。
この投稿では、RDS for Db2 インスタンスのスタンバイレプリカを構成する方法をご紹介します。
また、スタンバイレプリカのセットアップ、モニタリング、管理に関するベストプラクティスについても説明します。
この機能を使用することで、RDS for Db2 インスタンスを設定して、別のリージョンにスタンバイレプリカを保持することができます。
Amazon RDS は、プライマリからスタンバイレプリカへの変更を自動的に非同期でレプリケートします。
プライマリインスタンスが利用できなくなった場合、1 回の API 呼び出しでスタンバイをスタンドアロンインスタンス (新しいプライマリとして機能) に昇格させることができ、読み取りと書き込みの操作を即座に再開できます。
これにより、災害復旧時のダウンタイムが大幅に削減され、ミッションクリティカルなワークロードに対する追加の耐障害性レイヤーが提供されます。
このクロスリージョンのスタンバイレプリカ機能により、以下が可能になります:
- 別のリージョンまたはアベイラビリティーゾーンへの非同期データレプリケーション
- 災害復旧時のスタンバイからプライマリへのシームレスな昇格
- 目標復旧ポイント (RPO) は通常数秒以内
- 目標復旧時間 (RTO) は通常数分以内
- 従来のバックアップおよび復元方式と比較して、より迅速な災害復旧
スタンバイレプリカは、プライマリデータベースの物理コピーであり、IBM Db2 の High Availability Disaster Recovery (HADR) 機能を使用して、SUPERASYNC モードでプライマリとスタンバイレプリカ間のレプリケーションを行います。
RDS for Db2 のスタンバイレプリカデータベースは、プライマリで生成されスタンバイ DB インスタンスに送信されるログデータを通じて、プライマリデータベースと同期されます。スタンバイデータベースは、常にログを適用して更新を行います。
スタンバイ という用語は、明示的にスタンドアロンのプライマリインスタンスに昇格されない限り、読み取りや書き込み操作に使用できないことを示しています。
DB インスタンスに対して、プライマリと同じリージョン内または異なるリージョンに、最大 3 つのスタンバイレプリカを作成できます。
スタンバイレプリカは昇格されるまで操作できないため、インスタンスサイズに関係なく、レプリカごとに 2 vCPU 分の商用データベースライセンスのみが必要です。(訳注:BYOSLに関するIBMのサイトはこちらです)
Db2 Advanced Edition (AE) と Standard Edition (SE) の両方で、Bring Your Own License (BYOL) モデルと AWS Marketplace を通じた Db2 ライセンスモデルの両方において、スタンバイ用のレプリカを作成できます。
Db2 11.5 バージョンはレプリカ DB インスタンスをサポートしています。
次の表は、Amazon RDS for Db2 の各種 HA および DR 機能で達成可能な RPO および RTO メトリクスを示しています。
| 機能 | RPO (概算) | RTO (概算) |
| Amazon RDS マルチ AZ | 0 | 1 ~ 2 分 |
| Amazon RDS for Db2 スタンバイレプリカ (リージョン内/リージョン間) | 秒単位 | 分単位 |
| リージョン内の自動バックアップを使用した PITR | 5 分 | 数時間程度 |
| リージョン間の自動バックアップを使用した PITR | 25 分 | 数時間程度 |
ソリューションの概要
以下の図は、RDS for Db2 のスタンバイレプリカを使用するアーキテクチャを示しています。
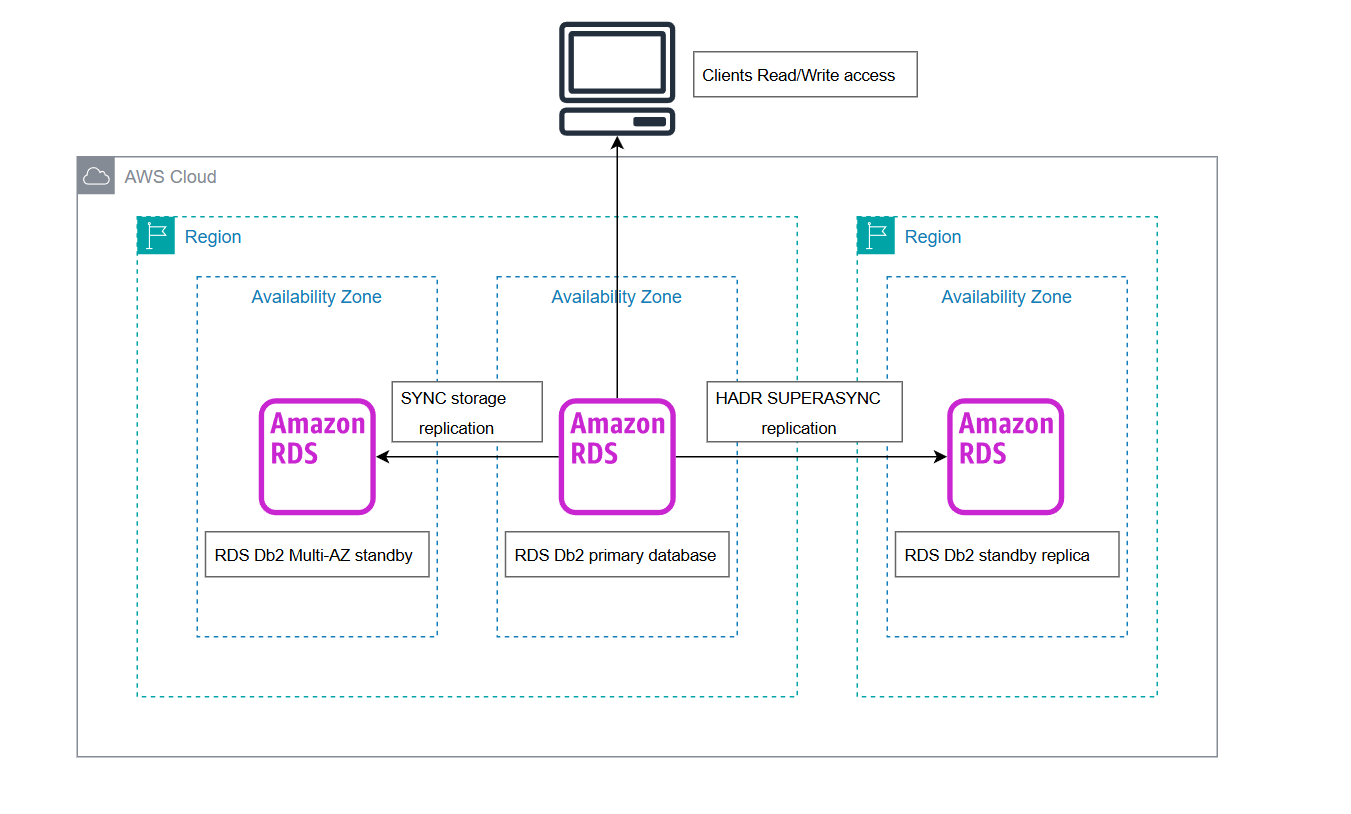
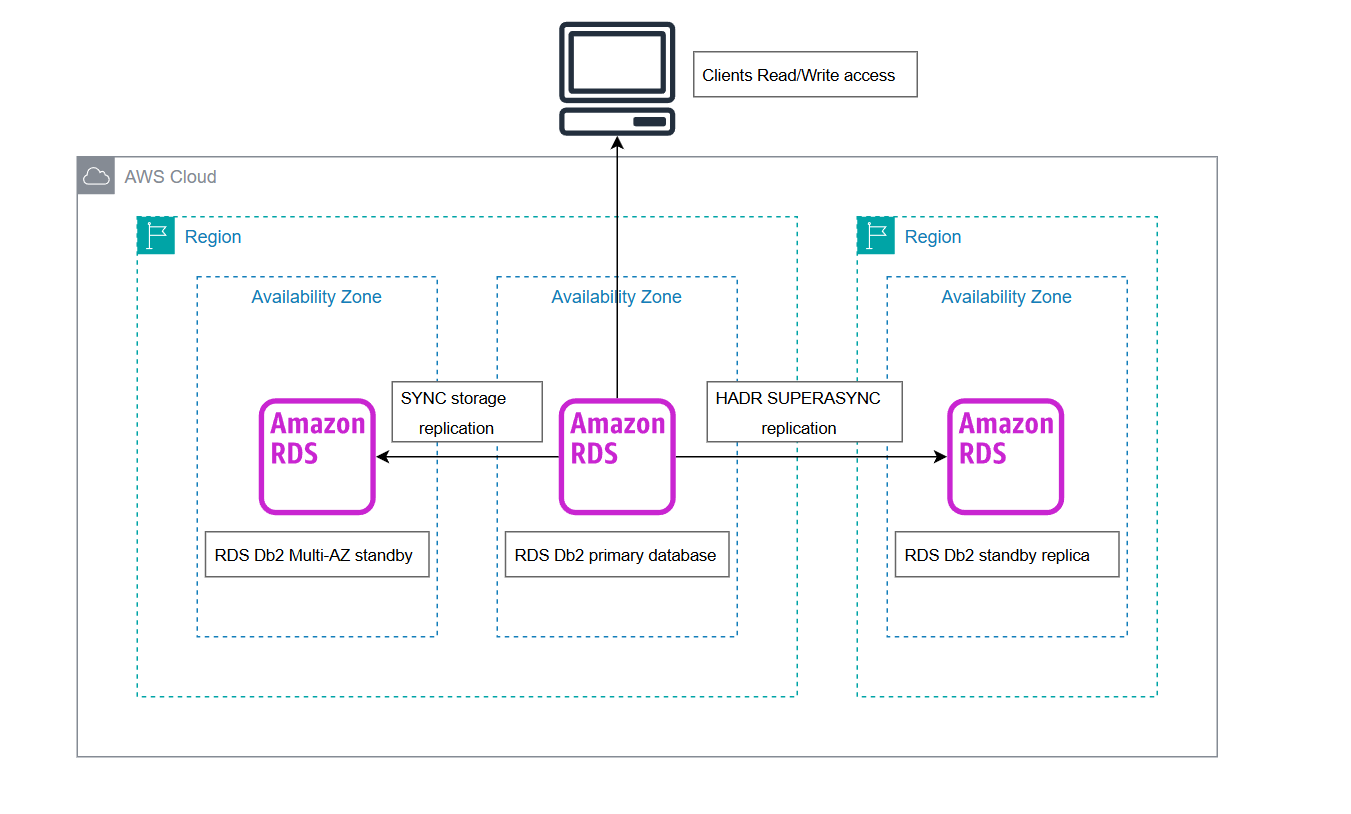
DR 状況において障害復旧の実装が必要な場合、RDS for Db2 のスタンバイレプリカインスタンスをスタンドアロン (新しいプライマリとして機能) インスタンスに昇格させることができます。
次の図は、レプリカ昇格後の構成を示しています。
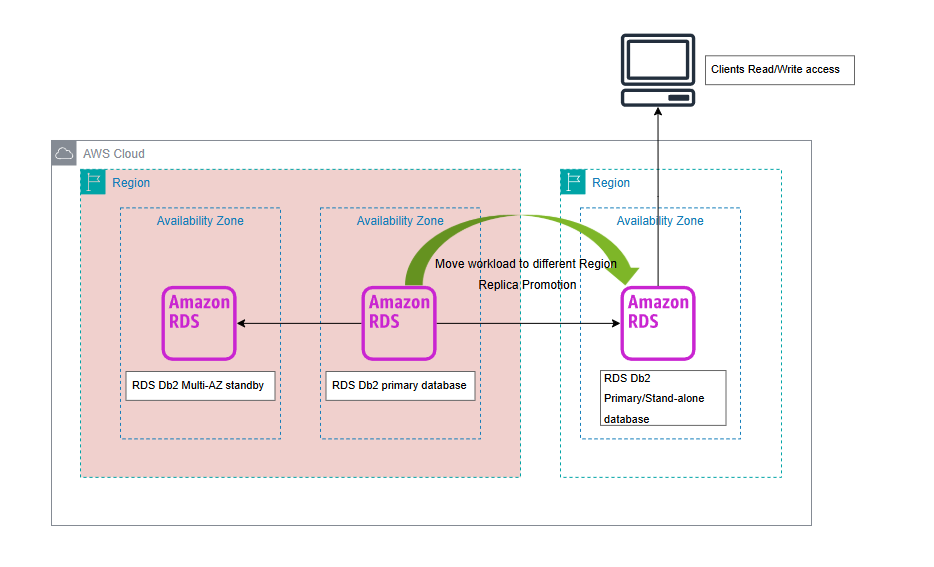
この投稿では、US East (N. Virginia) リージョン (us-east-1) にデプロイされたプライマリの RDS for Db2 インスタンスを使用します。
US East (Ohio) リージョン (us-east-2) にスタンバイレプリカを構成する手順について説明します。
前提条件
このブログの手順に従うには、以下の前提条件が必要です。
- プライマリ RDS for Db2 インスタンスが必要です (この投稿では、インスタンスは
rds-db2-primaryという名前で、us-east-1にデプロイされています)。 - ターゲット (セカンダリ) リージョン (この場合は
us-east-2) で設定されたカスタム RDS パラメータグループを使用する必要があります。詳細については、Amazon RDS のパラメータグループを参照してください。クロスリージョンのスタンバイレプリカのパラメータグループは、プライマリ RDS for Db2 インスタンスとは異なる値を持つことができます。ただし、BYOL ライセンスモデルでは、customer_idとsite_idは引き続き必要であり、セカンダリリージョンのパラメータグループで更新する必要があります。 - ソースデータベースが AWS Key Management Service (AWS KMS) のマルチリージョンキーを使用して暗号化されている場合、同じキーを使用してスタンバイレプリカを作成できます。そうでない場合は、セカンダリリージョンで新しい KMS キーを作成する必要があります。
- レプリカを作成する前に、データベースの作成、削除、復元、ロールフォワードのための組み込みの
rdsadminストアドプロシージャを、プライマリ RDS for Db2 DB インスタンスで完了しておく必要があります。 - プライマリインスタンスで複数のデータベースを設定している場合、スタンバイレプリカ作成後は、プライマリ RDS for Db2 インスタンスに追加のデータベースを追加できないことに注意してください。データベースを追加するには、まずスタンバイレプリカを削除し、必要に応じてプライマリインスタンスに追加のデータベースを作成してから、スタンバイレプリカを再作成する必要があります。作業を進める前に、プライマリ RDS for Db2 インスタンスに必要なデータベースを作成しておいてください。プライマリインスタンス上のすべてのデータベースはアクティブな状態である必要があります。
- ソース DB インスタンスで自動バックアップを有効にする必要があります。
前提条件の詳細については、RDS for Db2 レプリカの要件と考慮事項を参照してください。
RDS for Db2 レプリカに関する重要な考慮事項
- RDS for Db2 はローカルユーザーをレプリカに複製しますが、マスターユーザーは複製しません。レプリカ上でマスターユーザーを変更することができます。詳細については、Amazon RDS DB インスタンスの変更をご参照ください。
- RDS for Db2 はデータベース設定をレプリカに複製します。
- RDS for Db2 は以下の項目を複製しません:
- ストレージアクセス。外部テーブルなど、ストレージアクセスに依存するデータに注意してください。
- 非インライン LOB。
- 外部ストアドプロシージャ( C 言語または Java )のバイナリ。
- レプリケーションは LOAD コマンドをサポートしていません。ソース DB インスタンスで LOAD コマンドを実行すると、データはリカバリ不可能モードでロードされます。つまり、データはスタンバイレプリカに複製されません。
- Amazon RDS for Db2 でレプリカが作成されると、データベースレベルのパラメータ BLOCKNONLOGGED と LOGINDEXBUILD がプライマリインスタンスで自動的に YES に設定されます。これにより、すべての操作とインデックスの構築がレプリケーションのために完全にログに記録されます。スタンバイレプリカがスタンドアロンインスタンス(レプリカの昇格)になると、Amazon RDS はプライマリインスタンスの値を NO に戻します。
- レプリケーションは、RDS for Db2 プライマリ DB インスタンス上のすべてのデータベースに対して Db2 HADR を使用します。
RDS for Db2 のスタンバイレプリカの作成
ソースの RDS for Db2 DB インスタンスからスタンバイレプリカを作成するには、以下の手順を実行します:
- Amazon RDS コンソールのナビゲーションペインで、Databases を選択します。
- スタンバイレプリカのソースとして使用する RDS for Db2 DB インスタンスを選択します。

- Actions ドロップダウンメニューから、Create replica を選択します。
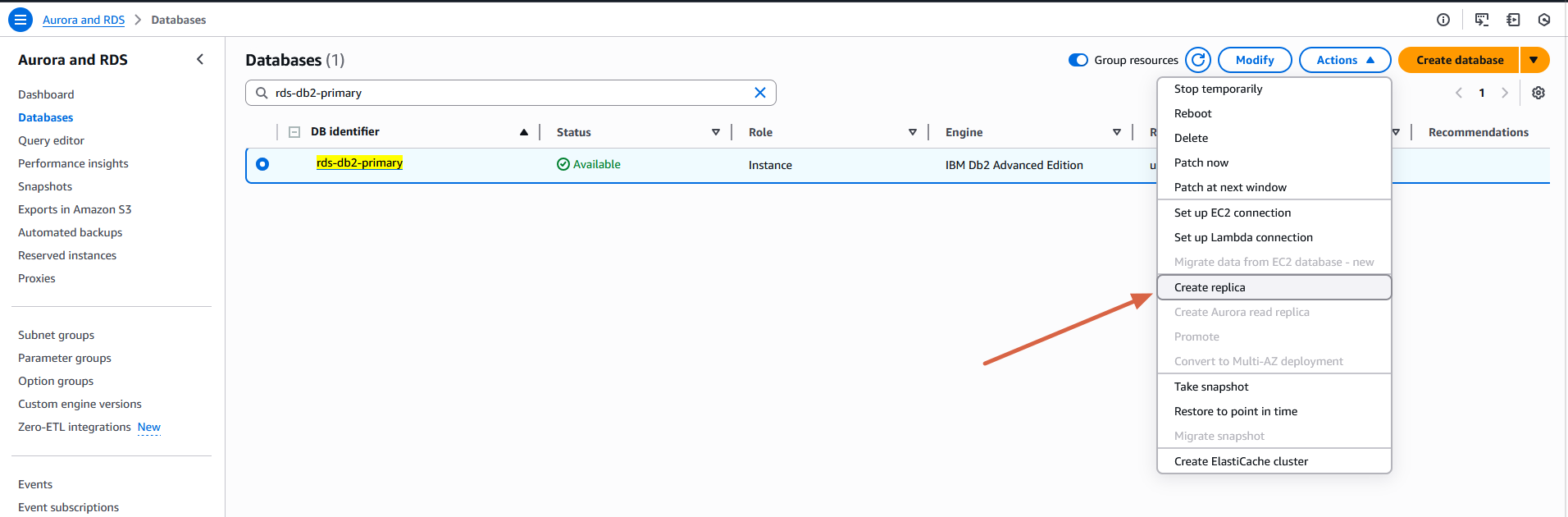
- Replica mode で、Standby を選択します。

- DB instance identifier に、リードレプリカの名前を入力します。

- Regions で、スタンバイレプリカを起動するリージョンを選択します。

- インスタンスサイズとストレージタイプを選択します。
- Multi-AZ deployment で、レプリカのスタンバイインスタンスを作成する場合は、Create a standby instance を選択します。これにより、別のアベイラビリティーゾーンにスタンバイレプリカのフェイルオーバー用インスタンスが作成されます(オプション)。
- その他の設定を必要に応じて選択します。
- Create replica を選択します。
ターゲットリージョンの**Databases**ページで、スタンバイレプリカのロールは**Replica**となっています。
プライマリの RDS for Db2 インスタンスの Connectivity & Security タブにある Replication セクションで、レプリカの設定詳細を確認することもできます。


または、以下の AWS Command Line Interface (AWS CLI) コマンドを使用して、RDS for Db2 のスタンバイレプリカを作成することもできます。
RDS for Db2 スタンバイレプリカの昇格
プライマリ DB インスタンスが利用できなくなった場合、スタンバイレプリカをスタンドアロンインスタンスに昇格させ、読み取りと書き込みの操作を再開することができます。
スタンバイレプリカの昇格が開始されると、RDS はアーカイブログから保留中のトランザクションを適用し、スタンバイレプリカをアクティブな状態に移行し、昇格したインスタンスで読み取り/書き込み機能を有効にします。このプロセスでは、プライマリデータベースからスタンバイレプリカへの非同期データレプリケーションが行われることを理解することが重要です。そのため、プライマリデータベースとスタンバイレプリカ間のレプリケーションの遅延に応じてデータ損失が発生する可能性があります。
潜在的なデータの不一致を最小限に抑えるため、レプリカの昇格を開始する前に、このブログ投稿のベストプラクティスセクションで説明されているように、レプリケーションの遅延を確認することを強く推奨します。この遅延を慎重に監視し、その影響を理解することで、災害復旧シナリオにおいて適切な判断を下し、昇格したスタンバイインスタンスで最適なデータ整合性を確保することができます。
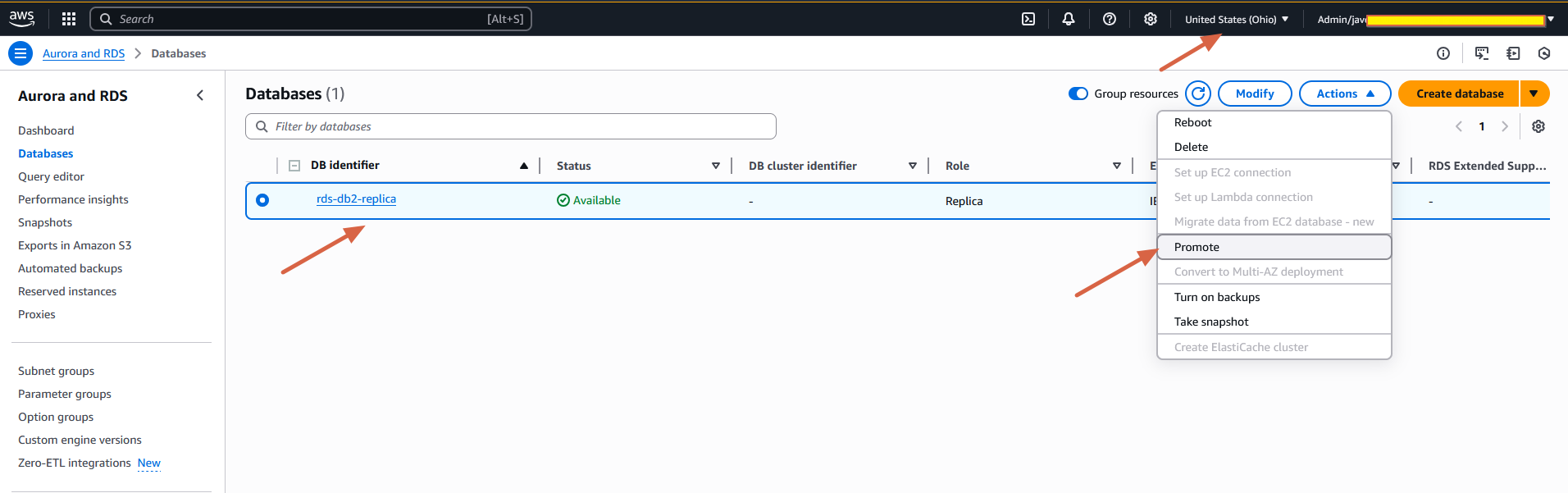
RDS for Db2 のスタンバイレプリカを昇格させるには
- Amazon RDS コンソールのナビゲーションペインで、Databases を選択します。
- ソースとなる RDS for Db2 DB インスタンスを選択します。
- スタンバイレプリカを選択します。
- Actions ドロップダウンメニューから、Promote を選択します。
または、以下の AWS CLI コマンドを使用することもできます:
昇格後の RDS for Db2 スタンバイレプリカに接続します:
ベストプラクティス
このソリューションを実装する際は、以下のベストプラクティスを考慮してください。
- パフォーマンスの問題やレプリケーションの遅延を避けるため、一般的に RDS for Db2 のスタンバイレプリカは、プライマリインスタンスと同じインスタンスタイプとサイズで構成することをお勧めします。ただし、インフラストラクチャのコストを最適化するために、スタンバイレプリカに異なるインスタンスタイプとサイズを選択することも可能です。
- RDS for Db2 のスタンバイレプリカのバージョンは、プライマリインスタンスのバージョンと同じか、それ以上である必要があります。マイナーバージョンの手動アップグレードを実行する場合は、プライマリインスタンスをアップグレードする前にレプリカインスタンスをアップグレードする必要があります。
- Amazon RDS の
ReplicaLagメトリクスを Amazon CloudWatch で確認し、レプリケーションの遅延を監視することをお勧めします。レプリケーションの遅延時間の詳細については、リードレプリケーションのモニタリングおよびAmazon RDS の Amazon CloudWatch メトリクスをご参照ください。ReplicaLagメトリクスは、遅延が発生しているデータベースの最大遅延を秒単位で示します。レプリケーションの問題のモニタリングとトラブルシューティングの詳細については、RDS for Db2 レプリケーションの問題のトラブルシューティングをご参照ください。
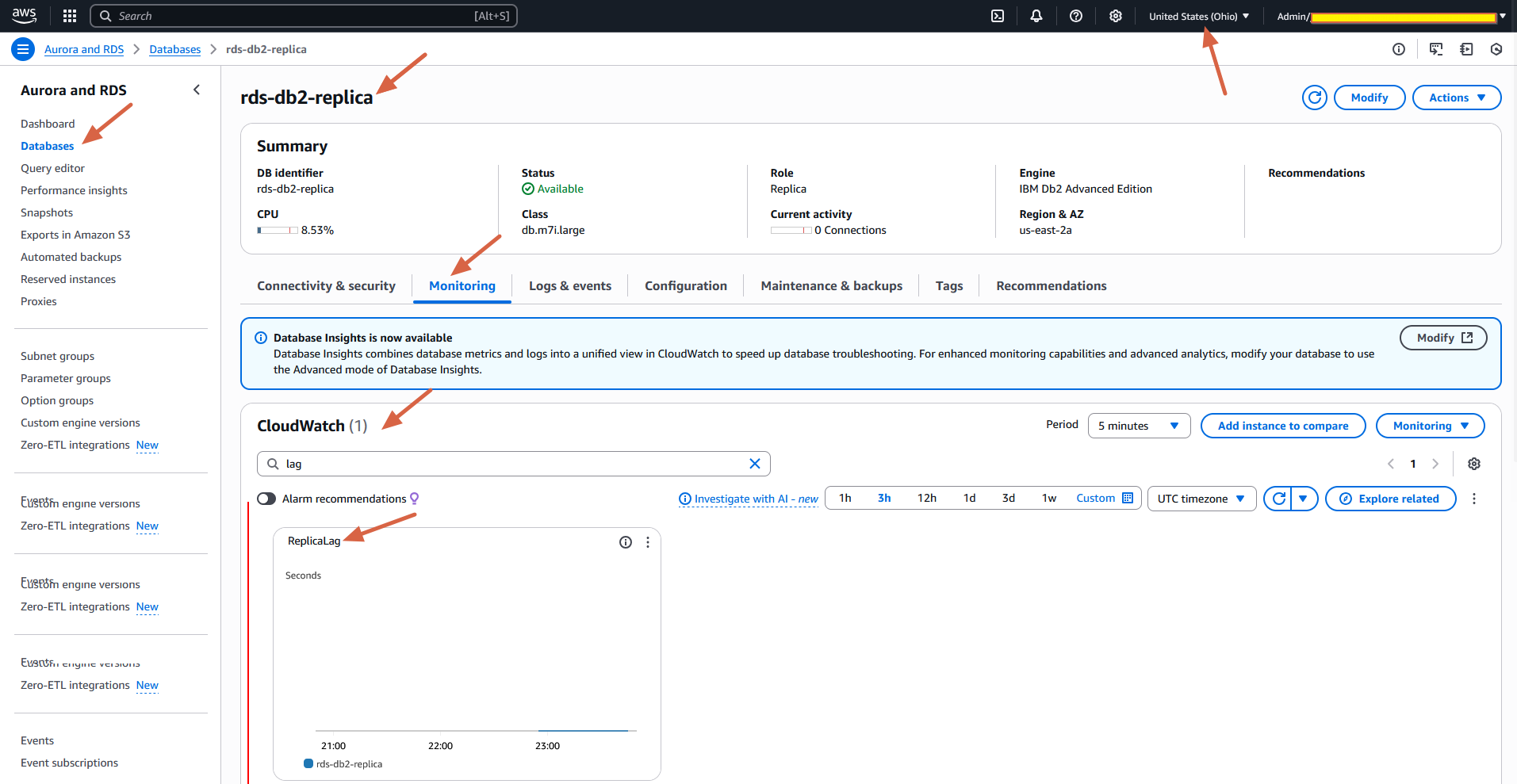
ビジネス要件に基づいて、ReplicaLag が定義されたしきい値を超えた場合に通知を受け取るように CloudWatch アラームを設定できます。
- プライマリの RDS for Db2 インスタンスがマルチ AZ で構成され、自動バックアップが有効になっている場合、これらの設定をスタンバイレプリカでも有効にできます。これにより、スタンバイはプライマリインスタンスと同じ構成を維持し、DR シナリオ発生時にスムーズで迅速な移行が可能になります。昇格後は、これらの設定を個別に構成する必要なく、昇格されたインスタンスに接続できます。
- 昇格時に予期しない動作を避けるため、プライマリインスタンスとスタンバイインスタンスの両方で、同じまたは互換性のある DB パラメータグループとオプショングループを使用してください。
- RDS for Db2 レプリカインスタンスのバックアップを作成および復元できます。RDS for Db2 スタンバイレプリカは、自動バックアップと手動スナップショットの両方をサポートしています。RDS for Db2 レプリカは、デフォルトでは自動バックアップが有効になっていません。バックアップ保持期間を 0 より大きい値に設定することで、自動バックアップを有効にできます。RDS for Db2 スタンバイレプリカで自動バックアップを有効にすることで、ポイントインタイムリストアを含む完全な復旧機能を備えた状態で昇格できます。これは、災害復旧、コンプライアンス、必要に応じたスタンドアロンインスタンスへのスムーズな移行に重要です。詳細については、Working with RDS for Db2 replica backups を参照してください。
- アプリケーションエンドポイントを変更せずにトラフィックルーティングの自動化を実装する方法については、Orchestrate disaster recovery automation using Amazon Route 53 ARC and AWS Step Functions を参照してください。
リソースの削除
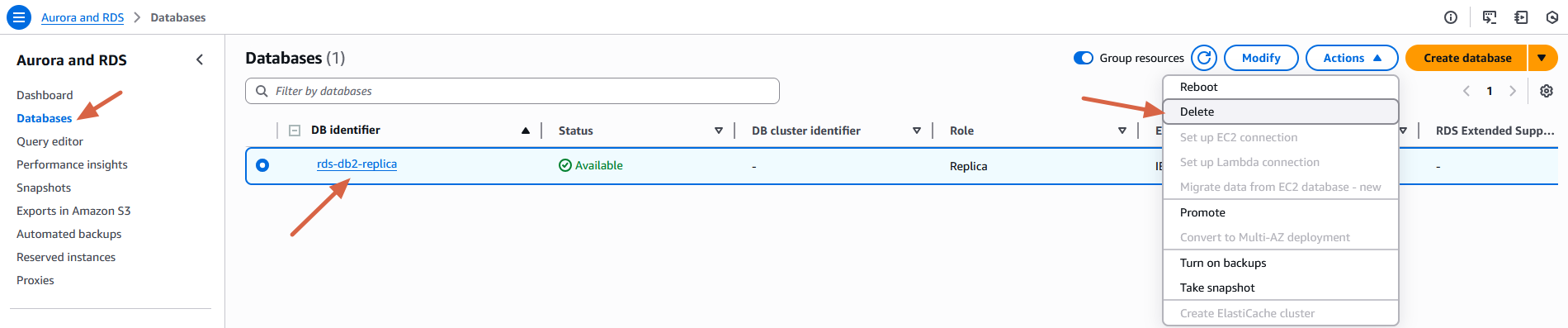
RDS for Db2 のスタンバイレプリカを削除するには。
- Amazon RDS コンソールのナビゲーションペインで、Databases を選択します。
- ソースとなる RDS for Db2 DB インスタンスを選択します。
- スタンバイレプリカを選択します。
- アクション ドロップダウンメニューから、 削除 を選択します。
RDS for Db2 のスタンバイレプリカを削除するには、以下の AWS CLI コマンドを使用します:
まとめ
RDS for Db2 のクロスリージョンスタンバイレプリカを構成することで、可用性と災害対策の両方を強化できます。
セットアップと暗号化に関するベストプラクティスに従うことで、スムーズなフェイルオーバーを実現できます。
このセットアップにより、予期せぬ事態が発生した場合でも、最小限の中断で業務の継続性を維持できます。
この解決策をご自身のユースケースで試していただき、コメントでフィードバックをお寄せください。
翻訳はソリューションアーキテクトの山根 英彦が担当しました。原文はこちらです。