AWS Public Sector Blog
UC Merced automates document data extraction to support research using Amazon Bedrock LLMs

In the rapidly evolving landscape of academic research, cloud computing and advanced digital services have revolutionized the way scientists collaborate, analyze data, and disseminate findings. Amazon Web Services (AWS) is partnering with higher education institutions to revolutionize how research is conducted.
Today’s researchers have access to unprecedented computational power, vast data storage capabilities, and sophisticated tools for real-time collaboration across global networks. This digital transformation has not only accelerated the pace of scientific discovery, but also democratized access to cutting-edge resources—enabling institutions of all sizes to participate in groundbreaking research. As we continue to push the boundaries of knowledge, understanding the historical foundations and impact of early digital networks becomes crucial for contextualizing our current technological capabilities and envisioning the future of scientific inquiry. It is within this framework that we examine the innovative research being conducted at the University of California Merced, where scholars are exploring the intricate relationships between technological infrastructure, scientific productivity, and societal progress.
Research into ARPANET and its potential impacts on today’s society
Dr. Christian Fons-Rosen is an Associate Professor of Economics at University of California Merced, where his research centers on the intersection of science, innovation, and economic development. His department focuses on understanding the institutional, technological, and social drivers of knowledge production and diffusion. His team is especially interested in how public policy and infrastructure shape scientific collaboration, innovation outcomes, and the inclusiveness of the research process.
Dr. Fons-Rosen’s current project, funded by the National Science Foundation, explores how early digital connectivity affected the trajectory of U.S. science. Specifically, it studies the impact of the ARPANET (Advanced Research Projects Agency Network)—the precursor to the modern internet—on academic and corporate research between the 1960s and 1980s. ARPANET, which predates the modern internet, was a computer network developed by the U.S. Department of Defense during the late 1960s. It was based on this framework that modern day internet technologies and protocols such as TCP/IP (Transmission Control Protocol/Internet Protocol) were developed. ARPANET was a transformative technology, offering real-time computer connectivity for the first time across geographically dispersed universities and government institutions. Dr. Fons-Rosen’s research uses this unique historical event to address two key policy questions: (1) Did ARPANET help reduce gender disparities in scientific productivity? and (2) Did it facilitate greater integration between academic research and corporate innovation?
The idea for this project arose from persistent questions in science policy: Why are women still underrepresented in STEM (Science, Technology, Engineering, and Mathematics)? How can we better connect academic discoveries to practical applications in the private sector? The project uses extensive archival work—drawing on never-before-digitized records from the Computer History Museum and the National Archives—to create new datasets that track researchers, their collaborations, and their outputs over time.
The goal of Dr. Fons-Rosen’s research is to rigorously quantify how connectivity shapes who gets to participate in science and how ideas move across institutional boundaries. In doing so, the research aims to contribute not only to academic debates, but also to policy discussions about equity in science and the public value of research.
Identifying the right use case for generative AI
Dr. Christian Fons-Rosen, recognizing the potential of cutting-edge AI technologies to revolutionize his research process, approached AWS with a novel challenge. His project, which involves analyzing vast amounts of historical documents, needed an efficient method to extract and process data at scale.
The professor obtained a collection of over 10,000 declassified ARPA documents, some very large in size. Many documents reached sizes of over 500 pages. The documents contained information regarding ARPA projects, which are research projects that allocated funding to research institutions with the goal of conducting research on behalf of the US government. There was no single format to the documents, with some being organized in charts/tables, while others were in free form text. For this research project, the professor needed to extract certain characteristics about ARPA orders from the documents. Each document could contain information about multiple ARPA orders, or no relevant information at all.
There were four main data aspects that need to be extracted:
- The first parameter was the ARPA order number. ARPA orders range from 1-7,000 and can be referred to as just the order number, such as “ARPA order 500”, or they can have the year the ARPA order was contracted attached in the following format “500-66” (66 representing the year 1966).
- The second parameter was the names of any professors, researchers, contractors, or scientists that worked on the execution of the ARPA order. These could be a single name or multiple names.
- The third parameter was the name of the institution/company/university or any other organization that worked on the ARPA order.
- The last parameter was any contract numbers that may be associated with the ARPA order. Contract numbers can come in many different formats because different organizations follow different syntax for naming/numbering their contracts.
The professor approached AWS, requesting a solution that would automate the processing and information/parameter extraction from these documents. Due to the variation of the types of documents and sheer size of the documents, the professor did not have the bandwidth/manpower to analyze these documents manually. It was estimated that it would take thousands of man hours to process these documents manually. The large variation of document types also made it hard to write automation scripts to extract the information.
Cost was a significant factor in deciding on the solution, because—as is the case with many research projects—there was not a large budget associated with this project. This meant a cost-effective solution was needed that would steer away from custom model training.
Accuracy was discussed as a potential trade off when using standard large language model (LLM) prompting (without custom tuning). However, due to the nature of the project, 100 percent accuracy was not necessary, and 80-100 percent detection of data was acceptable.
Although the PDF files used in this project contain publicly available information, the solution implements standard AWS security practices throughout the architecture. This includes default encryption in transit between services and encryption at rest for data stored in Amazon Simple Storage Service (Amazon S3) buckets and Amazon DynamoDB.
Finally, the professor and his team had limited development knowledge. Therefore, they preferred a low code solution. Generative AI was chosen as the solution for this intelligent document processing task.
Building an automated, low code, scalable solution for Intelligent Document Processing
As requested by the professor, the solution had to be low code, and not exceed a certain cost cap. This excluded the training of specialized models or customization of existing foundation models (FMs). Furthermore, it would be hard to train a model on the documents because they were all in many different formats and not well structured.
Although solutions such as Amazon Q for Business and Amazon Bedrock Data Automation were explored, the solution chosen due to its flexibility and agility was a processing pipeline that would prompt Amazon Bedrock Agents for the necessary information. Both Amazon Nova and Anthropic Claude models were considered, with Claude Sonnet 3.7 ultimately chosen. The prompts were augmented by attaching the documents to the request and instructing the agent to extract the needed parameters.
The following AWS services were used in this solution:
- Amazon Bedrock to access foundation models for extracting relevant fields
- AWS Lambda for document chunking and interacting with Amazon Bedrock
- Amazon S3 for storing original documents, as well as chunked documents for processing
- Amazon Simple Queue Service (Amazon SQS) to queue documents for processing, handing fault tolerance, and throttle against Amazon Bedrock
- DynamoDB to store final outputs
Solution overview
The following figure outlines the visualized flow of documents as they are processed by the pipeline.
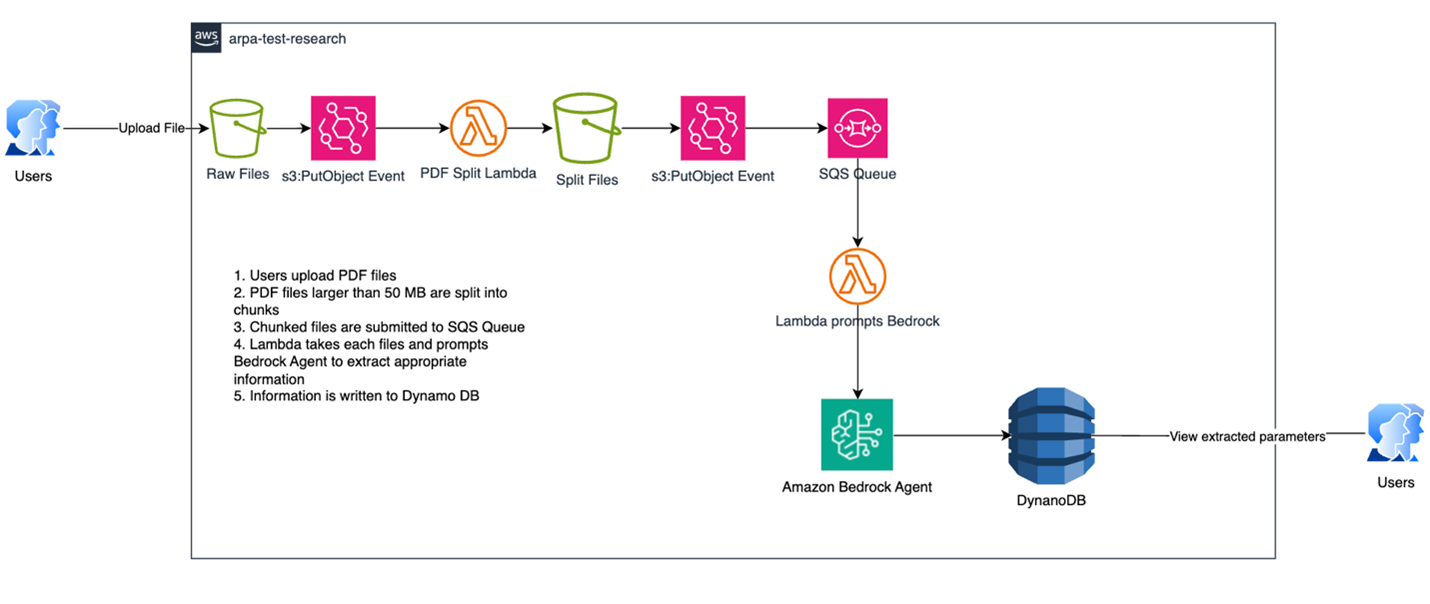
Figure 1: Visualized flow of documents as they are processed by the pipeline, starting with ingestion into Amazon S3 and processing through Amazon Bedrock.
The general flow of the pipeline is as follows:
- User uploads a document to a “preprocessed” directory in an S3 bucket.
- An S3 PutObject event triggers a Lambda that checks if the uploaded file is more than 3 MB.
- If it is, then the Lambda chunks the original files to 3 MB files and uploads them to a “processed” directory.
- If the file is 3 MB or less, then the Lambda copies the file to the “processed” directory.
- In the processed directory, another S3 PutObject event is triggered, writing the event to an SQS queue.
- The SQS queue triggers another Lambda function that prompts the Amazon Bedrock Agent to extract the information needed and provides the Amazon S3 file that was uploaded.
- The SQS queue was chosen so that the trigger settings of Lambda concurrency could be limited as to not exceed Amazon Bedrock API calls.
- Concurrency was set to two concurrent Lambdas, with each processing up to five events (files) from Amazon SQS.
- The prompt specifically requests back a JSON (JavaScript Object Notation file) only response from the FM.
- When the JSON response is returned from the LLM, the Amazon Bedrock Agent (through a Custom Action) writes the response to DynamoDB, creating a record for each ARPA order number extracted, and subsequent “columns” for each of the needed parameters (institution name, researcher name, and contract numbers).
- The importance of having a strict JSON object format (as requested in the prompt) is crucial, so that the Lambda code can process each response the same and write data to appropriate columns in DynamoDB.
- The Lambda writes each record with a generated random “sort key”. This is so that it does not override data because multiple documents could contain data on same ARPA order number.
- Data from DynamoDB can be extracted to CSV by the professor for further processing as needed to meet research goals.
Prompt engineering was an important factor in this solution. The key was to specifically prompt the LLM to extract only the relevant information needed from documents and return it in a specifically formatted JSON that could be processed by the Amazon Bedrock Agent and written to DynamoDB.
The following is a sample prompt that was used:
prompt = """
From the attached document, extract all “ARPA order numbers”. For each of those ARPA
order numbers, please list 1) contract numbers associated with it 2) institution name
where work was done for that ARPA order and 3) names of people/scientists/researchers
that worked on that ARPA order. Return the results in the following JSON format.
Do NOT return anything else in the response. Return JSON only:
{
“arpaorder1”: {
“ARPAOrderNo”: “”,
“ContractNumbers”: “”,
“InstitutionNames”: “”,
“ResearcherNames”: “”
}
}
If the document contains multiple ARPA orders, add additional objects to the JSON as such:
{
“arpaorder1”: {
“ARPAOrderNo”: “”,
“ContractNumbers”: “”,
“InstitutionNames”: “”,
“ResearcherNames”: “”
},
“arpaorder2”: {
“ARPAOrderNo”: “”,
“ContractNumbers”: “”,
“InstitutionNames”: “”,
“ResearcherNames”: “”
}
}
For ARPAOrderNo field, do not put any commas. The Format should be only the order number,
such as “26” or “26-60”. Do not include anything in the response other than JSON.
"""And the following is a sample output that was returned by the LLM:
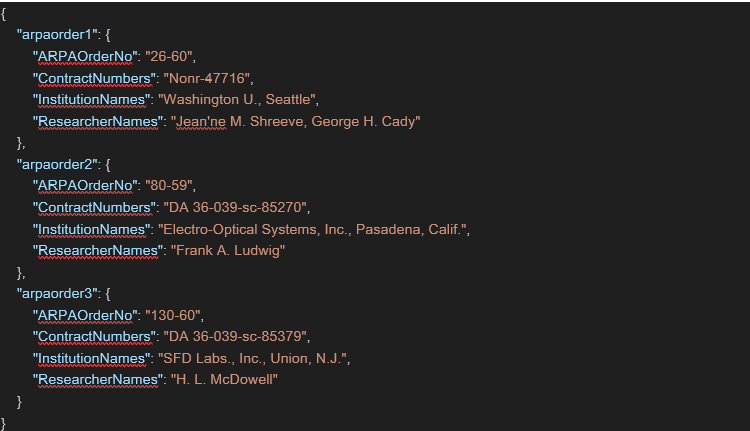
Initial results of the automated document processing solution
The professor and his graduate student assistants have been using this solution since April 2025. The team has had great success in extracting the needed information from their documents, spending significantly less time than would be needed to perform this manually. To optimize the results, prompt engineering and tweaking is taking place to adjust for changing data formats in the different documents. This enables efficient and correct data extraction depending on the type of document being processed. Professor Dr. Fons-Rosen hopes to finish roughly around 1,000 (100,000 pages total) documents by September 2025. This solution is estimated to have reduced costs and saved hundreds of man hours, allowing the research team to focus on the analysis and insights from the data, rather than the extraction process.
Future collaborations at UC Merced and beyond
Dr. Fons-Rosen hopes this research can have a lasting global impact: “Several countries are currently exploring to launch their own ARPA equivalent programs. And in the U.S. while the initial ARPA had military goals, now we also have ARPA-h with health goals. One of the distinctive features of ARPA compared to other federal institutions is the lack of red tape, small scale, and fast reaction times. The more we can learn about the impact of the original ARPA, the more informed the policy decisions on the potential launches of new ARPA.”
The success of this project can serve as a framework to build upon and assist other research initiatives not only within UC Merced, but also within the broader higher education system. The lessons learned from this large-scale data extraction will be applied to future collaborations—so that research institutions can automate data processes during their research and focus on true analytical- and discovery-type tasks.
To discover how other AWS customers are using generative AI to achieve their business goals, visit this webpage or contact your AWS Account Team.