AWS Public Sector Blog
Building Trusted Research Environments on AWS

Trusted Research Environments (TREs) provide secure access to sensitive data, enabling research while controlling data movement to meet governance requirements. In this post, we review core TRE concepts, examine TRE history and related initiatives, and explore key considerations for successfully deploying a TRE on Amazon Web Services (AWS). Building your TRE on AWS allows use of cloud services with advanced security features and architectural patterns to meet compliance and governance needs, providing secure, elastic, and scalable services to accelerate research.
Defining the TRE
AWS innovative security services help customers protect data and workloads, but what makes a TRE distinct? The technical components of a TRE provide a controlled environment to access, store, analyze, and—where appropriate—share sensitive data, analyses, machine learning (ML) models, and other artifacts. Publications, including the Goldacre review and Data Saves Lives paper, emphasize the crucial enabling role TREs play.
TREs are also known as data safe havens by Research Data Scotland and secure data environments according to the National Health Service England. Although organizations and domains have different priorities, and datatypes vary, they share common functional requirements. The common thread is that data consumers, analysts, or researchers need to interact with data, whereas data controllers must restrict data movement, primarily preventing sensitive data from leaving the environment. Here, we use the term TRE to encompass three aspects: the application, information governance, and business operations.
The UK Office for National Statistics (ONS) Five Safes framework provides guiding principles for TRE. It describes Safe people, Safe projects, Safe data, Safe settings, and Safe outputs that underpin the ONS Secure Research Service. It’s referenced by the SAIL Databank population dataset for Wales, operated by University of Swansea and Research Data Scotland’s network. UK Biobank and Genomics England employ similar approaches for their platforms built on AWS.
UK Research and Innovation (UKRI) has invested in platforms for handling sensitive data through its creation of Data and Analytics Research Environments UK (DARE). The first phase of DARE funded a series of projects addressing different aspects of TRE and provided network funding for the UK TRE community. Standardised Architectures for Trusted Research Environments (SATRE), led by the Health Informatics Centre at University of Dundee, developed practical guidance for TRE that helps organizations design or evaluate environments. SATRE bridges the gap between the Five Safes framework and regulatory requirements such as the NHS Data Security and Protection Toolkit, General Data Protection Regulation (GDPR), and the Digital Economies Act. The second phase of DARE funding aims to develop approaches for a network of TREs in the UK, and funds projects such as TREvolution, which builds on existing projects, including SATRE. EOSC-ENTRUST has similar ambitions in Europe.
Trusted Secure Enclaves (TSEs) or Secure Research Environments (SREs) sound like TRE but are distinct. These create cloud foundations meeting specific compliance requirements in domains including national security, defense, and law enforcement. On AWS, this foundational infrastructure is called a landing zone.
TRE roles and responsibilities
At Amazon, we work backwards from our customers’ challenges, beginning with the intended personas. SATRE details TRE roles including top management, who are ultimately responsible for an organization’s governance and compliance. In this post, we focus on the operational roles but it’s important to understand that TREs extend beyond technology. They encompass the people and processes, including data management, project lifecycle, and compliance reporting.
In the following table, we map SATRE roles to the terminology we’ve developed in our customer engagements. In practice, individuals might have responsibilities of multiple roles according to each organization’s scale and implementation. Typically, the lead researcher acts as project manager, with responsibility for orchestrating research activities while potentially exercising varying degrees of administrative control. Data managers are often responsible for comprehensive data stewardship within the data environment, including data transfer operations and access management.
Information governance is responsible for determining controls for ingress and egress of data and for monitoring and reviewing processes. The virtual research environment (VRE) operator, although aligned with the TRE operator, focuses on the VRE, but in practice might have overall operational responsibility. We recommend that a TRE is deployed within your organizations’ landing zone to meet specific compliance requirements for each workload, and the VRE operator should work closely with IT and information governance to determine appropriate controls.
| Persona | SATRE group | SATRE role(s) |
| Lead researcher | Project | Project manager |
| Researchers | Project | Data analyst |
| Data manager | Data management | Data steward |
| Information governance | Governance | Information governance manager |
| VRE operator | Infrastructure management | TRE operator |
Table 1: Personas aligned to SATRE groups and roles
TRE architecture
A TRE requires integrated technical components with each playing its part in creating a robust framework for securing research with sensitive data. There are three core components of a TRE:
- Virtual research environment – Users can self-service right-sized compute with approved software and project data. Access is limited within the bounds and scope of a project. Data transfer is controlled, including limiting file upload and download, and copy and paste.
- Data environment – Data storage and governance tooling, managing access and life cycling. Can provide tooling for extract, transform, load (ETL) operations, metadata curation, and data processing to ready incoming datasets for research use. Can also serve as a repository for historical project data, enabling data reuse and supporting reproducible research.
- Data review and transfer – Facilitates controlled movement of data and software, encompassing:
- Data staging – During transfers, data is stored temporarily. Incoming data can be from trusted and untrusted sources. Approved outbound data is also stored in this location until collection.
- Airlock – A bridge between staging and data environments, governing the flow of data through automated and manual processes. Enforces authorized review processes and proper governance for ingress and egress.
Detailed requirements of each component vary with use case. The same is true for supplementary components, for example, some organizations may prioritize searchable catalogs of organizational data, others might not need them. Additional considerations include governance controls and workflow integrations:
- Identity provider – Handles user management and authentication for the TRE components. This would facilitate identity federation if required.
- Management component – Centralizes monitoring tasks, logging, backup, budget, and cost control, helping the TRE run efficiently and securely.
- Environment controls – Facilitates the automation of TRE deployments and integration with external data sources when acting within a network of TREs and data libraries.
- Workflow controls – Process automation, including project setup, data approvals, and requesting data transfer. Typically self-service, to enabling scaling.
- Metadata catalogue – A searchable repository containing information about the data available within the TRE, aiding discovery. Data lineage, quality, and use might also be recorded.
- Code pipeline – Components to manage code. Through approval workflows, researchers can access packaged code, containerized applications, and Git repositories. These also support the development of code within the TRE.
The following graphic illustrates common elements typically found within a TRE.
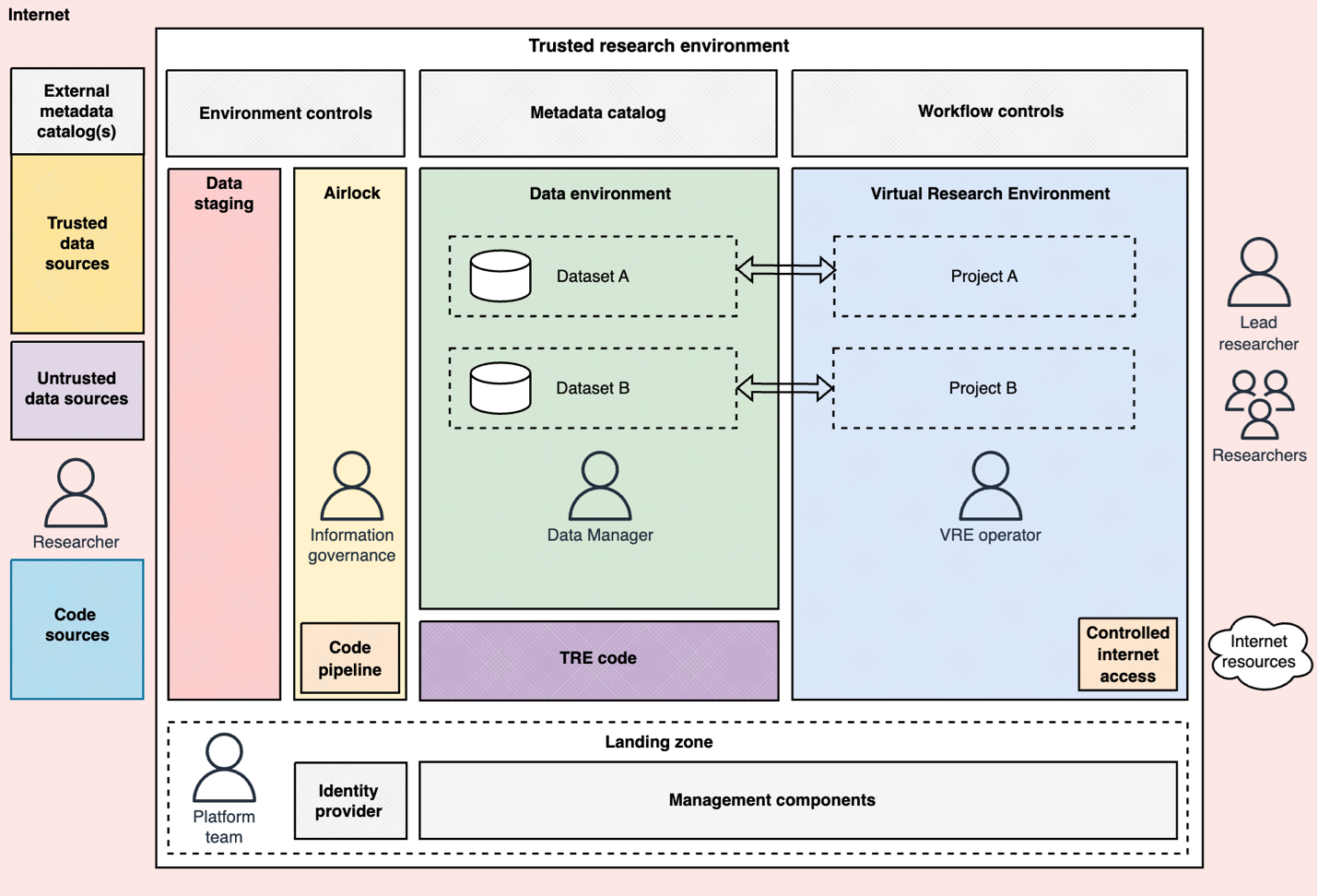
Figure 1: Functional architecture of a TRE
AWS services in the TRE architecture
In the following figure, we map AWS services and products to the TRE functional architecture. It’s important to align design decisions with your requirements, the needs of your stakeholders, and their knowledge and skills. Your organization’s specific requirements might be better met by alternative services or AWS Partner Network solutions. We provide links to case studies exploring different options later.
A landing zone is designed to meet compliance needs across your organization’s AWS operations. Landing Zone Accelerator on AWS accelerates customer journeys by integrating AWS services, including AWS Control Tower, which manages AWS Organizations; AWS CloudTrail, logging AWS API calls; Amazon CloudWatch, monitoring resources; and AWS Config for standard controls for accounts and resources. Utilization and cost recovery can be managed using AWS Budgets with associated billing services. AWS Backup enables standard back-up policies and life cycling. You can connect to your identity provider using AWS IAM Identity Center and use AWS Directory Service and application identity integrations with Amazon Cognito.
You can use Research and Engineering Studio on AWS (RES) to deliver a VRE providing self-service workspaces. Its project construct separates resources and manages access to specific data sources. RES includes features to restrict upload and download and copy and paste. Security groups and AWS Identity and Access Management (IAM) policies enable projects to use scale compute resources, including AWS ParallelCluster or AWS Parallel Computing Service, workflow services such as AWS HealthOmics, and Amazon SageMaker for AI training jobs.
Data environments typically use Amazon Simple Storage Service (Amazon S3) but Amazon Elastic File System (Amazon EFS) or databases can be used. For more complex needs, such as sharing datasets to multiple projects, AWS Lake Formation can be used to provision a data lake, and Amazon DataZone can enforce governance and provide a searchable catalog. You could also introduce Amazon SageMaker Unified Studio to provide an integrated experience for data managers and engineers to perform ETL with services including AWS Glue, query data with Amazon Athena, and use generative AI tooling.
AWS Transfer Family provides tooling for transfer from internal and external data sources and code repositories. The Data Review and Transfer Component provides an interface to AWS DataSync for managing ingress and egress requests. Amazon Macie can help identify personal data, supporting semiautomated review processes, and after necessary checks, data is transferred into the data environment. AWS Code family can enable automated checks before ingress. Software can be installed on custom Amazon Machine Images (AMIs) or accessed through AWS CodeArtifact. Customers have also used AWS Network Firewall to provide fine-grained access to external resources.
Audit and governance can be streamlined by automating deployment and management of resources. Infrastructure and environments should use infrastructure as code where possible. AWS Lambda can facilitate integrations between existing systems and your TRE such as automating project operations with existing ticketing or project management tooling.
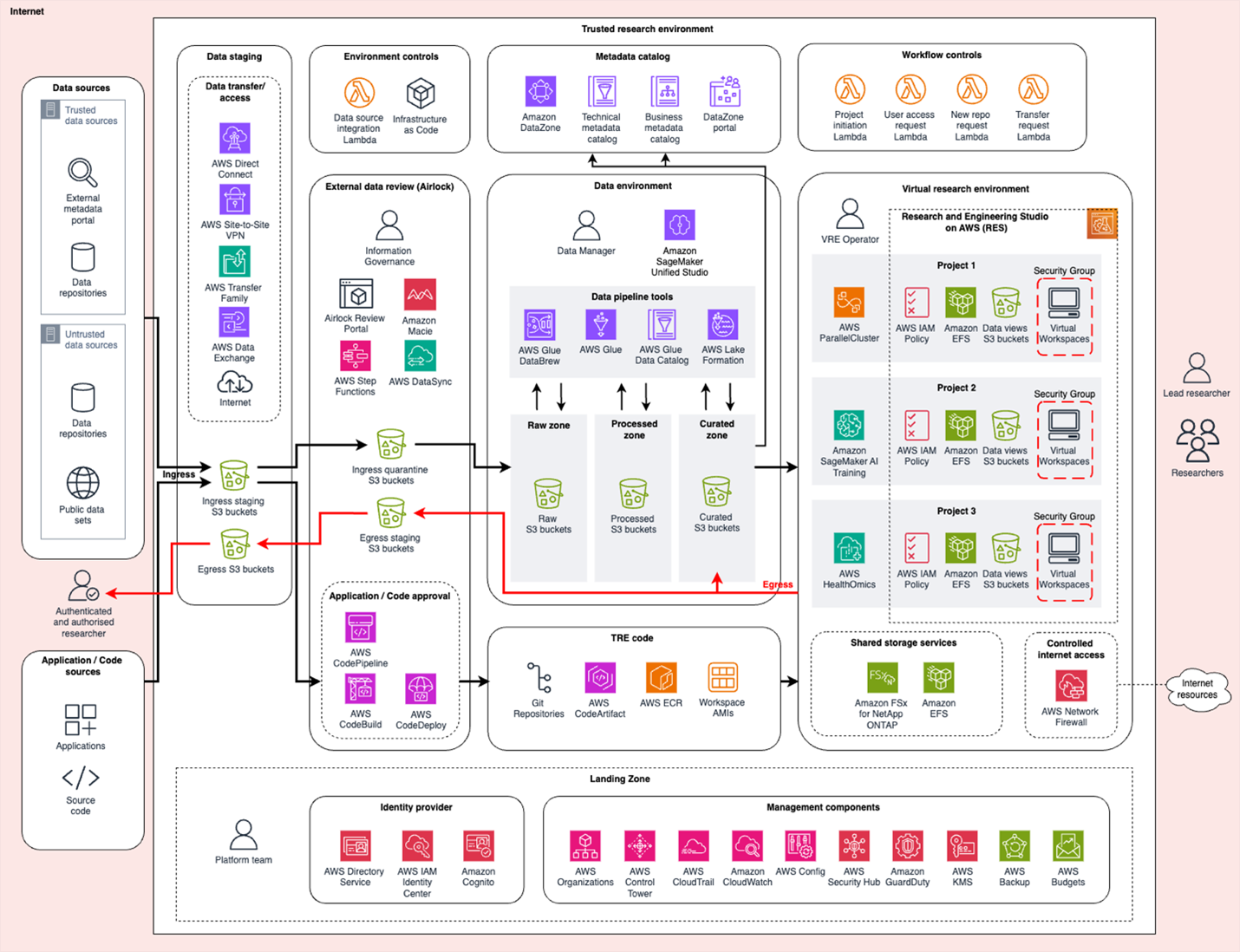
Figure 2: Example architecture overlaying AWS services on TRE functionality
A holistic approach to TRE implementation
When planning a TRE project, SATRE emphasizes information governance and business process are as important to consider as the technical solution. The following figure outlines a holistic TRE implementation approach, encompassing key stages and cross-cutting functions.
Throughout the project lifecycle, from initial development to ongoing service delivery, it’s crucial to assess your organization’s internal resources, including knowledge, skills, and availability. This evaluation will help determine whether you have the necessary in-house expertise to independently develop, maintain, and operate the solution. For organizations facing resource constraints or those aiming to focus their efforts more closely on data and research activities, the AWS Partner Network offers valuable support tailored to specific project needs.

Figure 3: Lifecycle pillars for building a TRE
Under the shared responsibility model, AWS operates, manages, and controls the cloud infrastructure, while customers are responsible for securing their applications, data, and access management. During the initial design phase, AWS field teams provide valuable insights during discovery, showcasing potential solutions. AWS Professional Services can work with your teams to design and develop solutions to the deployment stage, and although they can’t work in production, ongoing guidance remains available through account teams and AWS Support.
AWS Partners can provide additional layers of maintenance and operational support. Selecting an independent software vendor (ISV) partner’s software as a service (SaaS) solution reduces the customer’s operational overhead. Other partners provide consultancy and development services, along with managed service options that can be implemented permanently or as a transitional measure while internal teams build operational confidence. Being aware of options helps establish clear operational expectations at the project’s outset, and early decisions will help guide your choice of solution and support structure, aligning with capabilities, priorities, and long-term objectives.
TRE project stages
TRE projects should begin with specific research use cases in mind, a comprehensive understanding of stakeholder needs, and a clear plan for resource allocation. Early and frequent engagement helps validate proposed components and mitigates the delivery of a system that fails to meet real-world requirements.
Proof of concept (PoC) components don’t need full integration and can benefit from a quick, experimental approach to review different tooling. Cloud technologies offer the flexibility to explore options and gather feedback before committing to final decisions, and open data enables prototyping before governance and operational frameworks are established. As you progress to minimum viable product, you can incorporate user feedback and explore integration with existing systems. Even as automation and processes continue to evolve to align with the new operating model, select research groups should begin conducting research using real data. By the pilot phase, the TRE should satisfy technical and governance requirements and be ready for broader adoption by the research community. On moving to production, focus shifts to continuous improvement—adapting to researchers’ changing needs and compliance with evolving TRE guidelines.
The following graphic illustrates the flow of project stages.
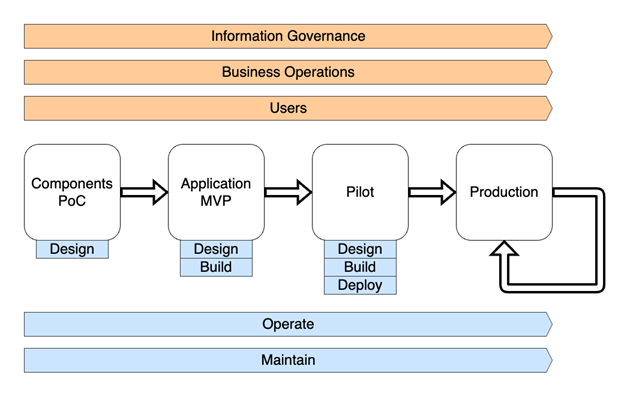
Figure 4: TRE project stages from proof of concept to production
TRE case studies: AWS customer implementations
AWS customers and partners have implemented numerous TREs. The architectural and technological choices vary based on specific use cases, priorities, and expertise, including preferences for managed services, SaaS solutions, or self-managed infrastructure. Here are several notable approaches:
- Dundee was an early adopter of cloud-based TREs, building their TRE on AWS and open source TREEHOOSE. Although the core VRE component is no longer supported, this demonstrated how TREs could be operated in the cloud.
- Kainos collaborated with the East of England Subnational SDE, using AWS services and products. Integrating Research and Engineering Studio in Trusted Research Environments built on AWS in the AWS HPC Blog explains how to deliver requirements for VREs. Data ingress and egress through Trusted Research Environments and other secure enclaves in the AWS Public Sector Blog shows integrating data movement workflows and introducing automated checks.
- Genomics England host 100,000 genomes and research environments on AWS with Lifebit.
- UK BioBank host research and medical data from 500,000 patients including whole genomes on AWS with DNAnexus.
- The Francis Crick Institute worked with Snowflake and Infinite Lambda to establish the TRELLIS data fabric.
- The University of Sheffield implemented their TRE using RONIN Isolate.
- Relevance Labs has created Research Gateway, for research use cases including specialized functionality for handling sensitive data.
Getting started with a TRE on AWS
In this post, we’ve reviewed the history of TREs and best practices for building and operating a TRE on AWS. Although TREs address diverse requirements across multiple domains, they share common functional elements that can be tailored to specific use cases. AWS, working with our customers and partners, has extensive experience across numerous projects that can help guide your implementation journey.
If you operate a TRE or work with sensitive data and would like to know more, contact your AWS account team or connect with the AWS Public Sector Sales Team.