AWS Public Sector Blog
Building an AI-powered scientific meeting transcription platform with AWS

Modern scientific research relies heavily on collaborative discussions and meetings, yet capturing and analyzing these vital conversations has always been challenging. In this post, we explore how to build a sophisticated meeting transcription and analysis platform using AWS services, designed specifically for the scientific community. Our solution combines the power of Amazon Transcribe, Amazon Bedrock, and other Amazon Web Services (AWS) services to create an intelligent tool that transforms how researchers document and analyze their discussions.
The complexity of scientific discussions, combined with the need for accurate documentation, poses unique challenges in academic and research environments. Traditional note-taking methods often fall short in capturing the depth and nuance of scientific conversations. This solution addresses these gaps by providing an automated, intelligent system that not only transcribes meetings with high accuracy, but also derives meaningful insights from these conversations.
Architecture overview
The solution architecture consists of the frontend built using Vue.js, chosen for its reactive data-handling capabilities and component-based architecture. This interfaces with a .NET Core backend API, selected for its enterprise-grade reliability and cross-platform capabilities. The AWS services integration layer forms the backbone of our solution, providing scalable, secure, and intelligent processing capabilities.
The system uses Amazon Transcribe for accurate speech-to-text conversion. Amazon Transcribe excels in scientific terminology through custom vocabulary support. Amazon Bedrock provides the artificial intelligence and machine learning (AI/ML) capabilities needed for sophisticated analysis, and Amazon Cognito handles secure user authentication. This example solution uses AWS Lambda functions for serverless processing of various tasks, with Amazon Relational Database Service (Amazon RDS) managing the relational data storage needs. AWS Step Functions orchestrates complex workflows, providing reliable execution of multi-step processes. The following diagram illustrates this solution architecture.
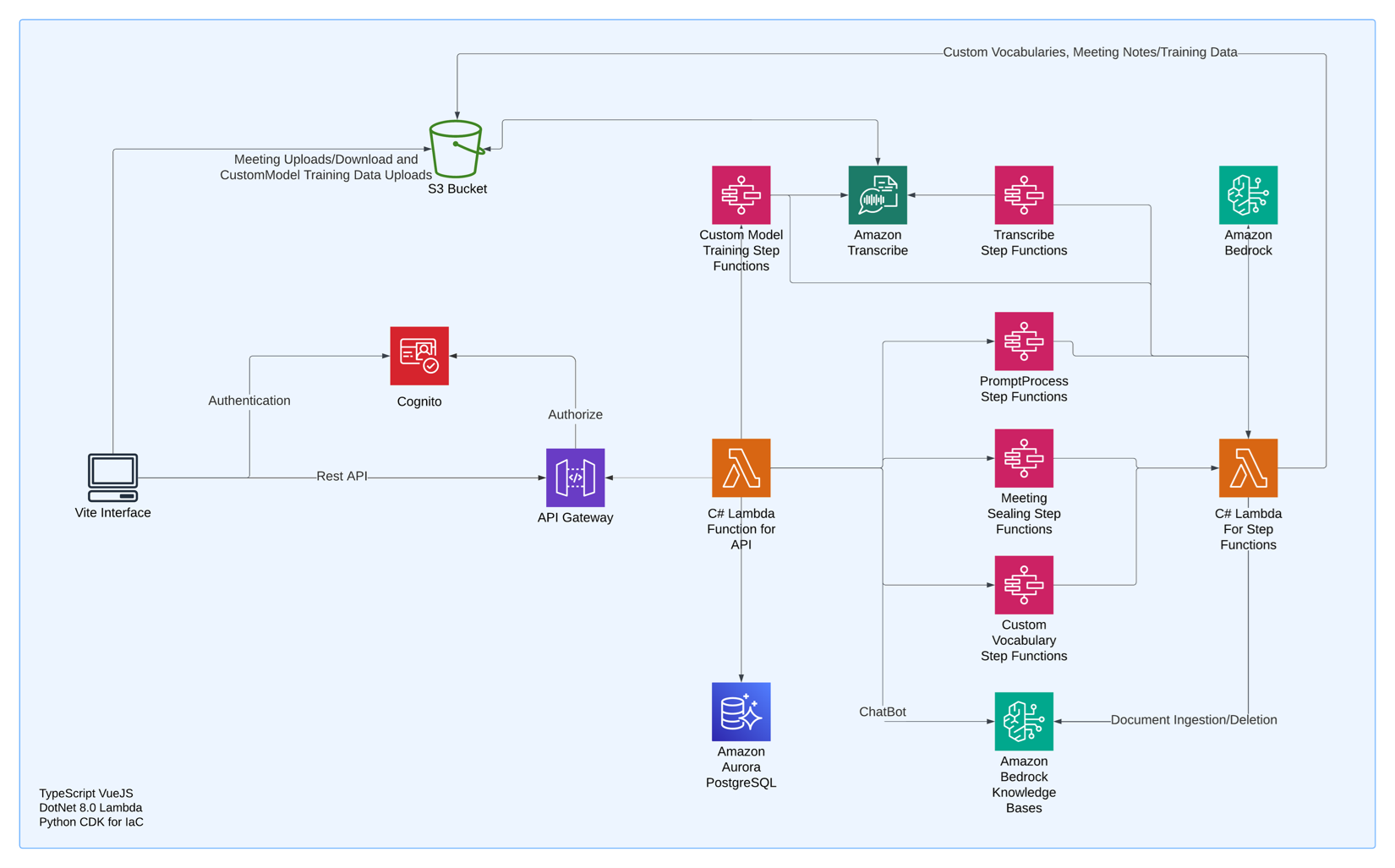
Figure 1: Solution architecture
Core features and functionality
Organizations can securely host multiple teams by utilizing this example solution using data segregation patterns. Each team’s data is stored, processed, and configured in dedicated data structures, providing isolation and security. This multi-tenant architecture enables teams to work independently while maintaining data privacy. By using a single solution across the organization, research and scientific teams can collaborate confidently while optimizing costs through shared infrastructure. Teams can focus on their research objectives knowing their data remains secure and separated from other teams’ workloads.
The Amazon Transcribe custom vocabulary support system revolutionizes how scientific terminology is handled in transcriptions. The platform learns from existing research papers and publications, continually improving its understanding of domain-specific terminology. Users can collaboratively build and maintain vocabulary sets, which are automatically updated based on usage patterns and feedback. This flow is shown in the following diagram.
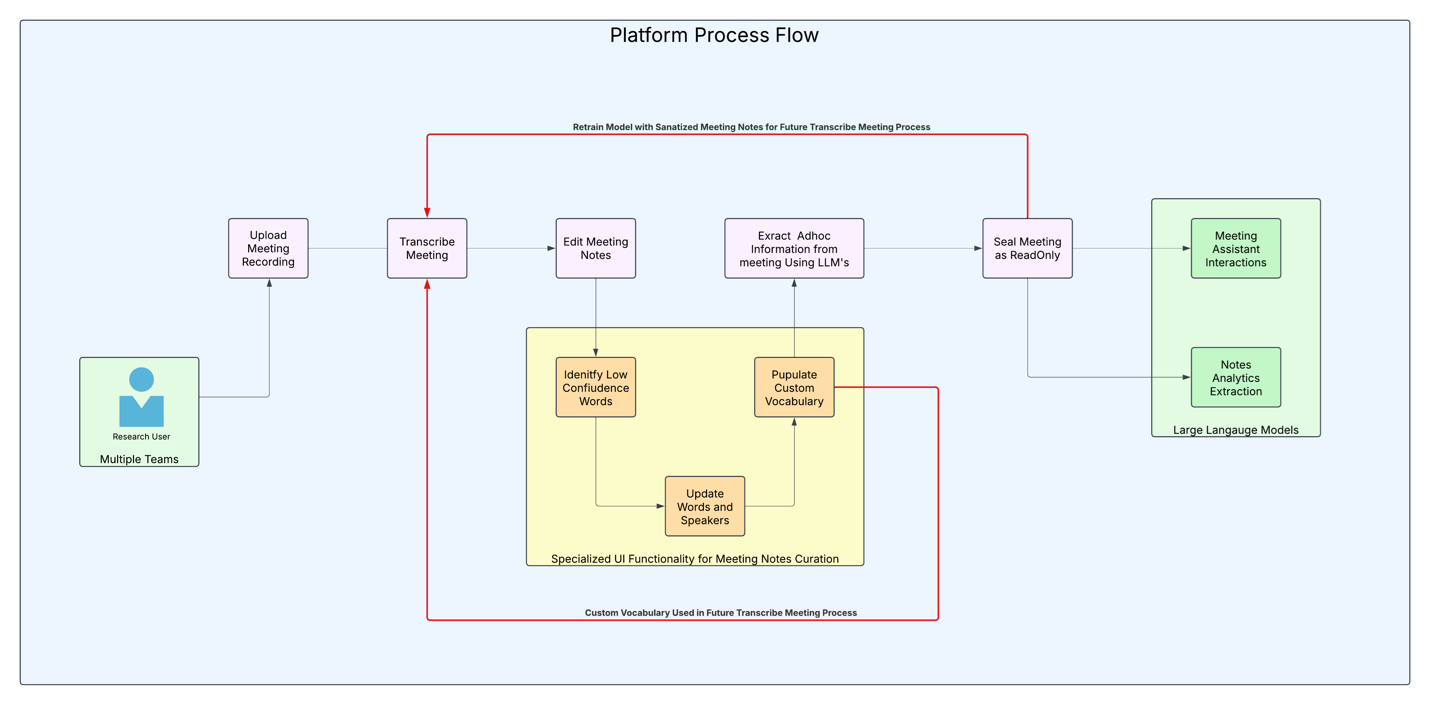
Figure 2: Platform process flow
This solution continually improves transcription accuracy for domain-specific terminology. As teams review and sanitize meeting transcripts, the solution automatically captures vocabulary corrections and builds a growing knowledge base of specialized terms. These learned vocabularies serve two purposes: they enhance custom model training and automatically populate custom vocabulary lists for future transcriptions. This creates a positive feedback loop where each transcription review makes future meetings more accurate. For example, when a research team corrects technical terms like protein names or experimental procedures, these corrections are automatically added to their domain-specific vocabulary. In subsequent meetings, Amazon Transcribe uses this enhanced vocabulary to deliver higher accuracy transcriptions, significantly reducing the time teams spend on review and corrections.
The generative AI–powered analysis capabilities, powered by Amazon Bedrock, represent a significant advancement in meeting intelligence. The system not only transcribes conversations but understands complex scientific concepts, identifies research methodologies, and can even suggest relevant published papers based on meeting content. Different language models within Amazon Bedrock are used for specific tasks like complex reasoning, text generation, and specialized models for scientific content analysis. By using these foundation models (FMs), the platform automatically extracts key meeting analytics including action items, decisions made, risks identified, and project milestones. This structured data is then stored in Amazon Aurora PostgreSQL-Compatible Edition, enabling organizations to gain data-driven insights across all their meetings. For example, teams can track research progress over time, identify common bottlenecks, and analyze collaboration patterns, transforming meeting transcripts from static documents into a rich source of organizational intelligence that drives better decision-making and research outcomes.
Meeting notes editor
The meeting notes editor feature of this solution provides an advanced interface for managing transcription accuracy and speaker attribution, utilizing the Amazon Transcribe confidence scoring system to enhance the user experience. The editor displays word-level confidence through intuitive visual indicators, where lower confidence words are highlighted with varying intensities of underlining. This visual feedback system, shown in the following screenshot, helps users quickly identify potential transcription errors while maintaining a clean, distraction-free interface. When users hover over any word, a tooltip displays the exact confidence percentage along with alternative suggestions generated by the Amazon Transcribe language models.
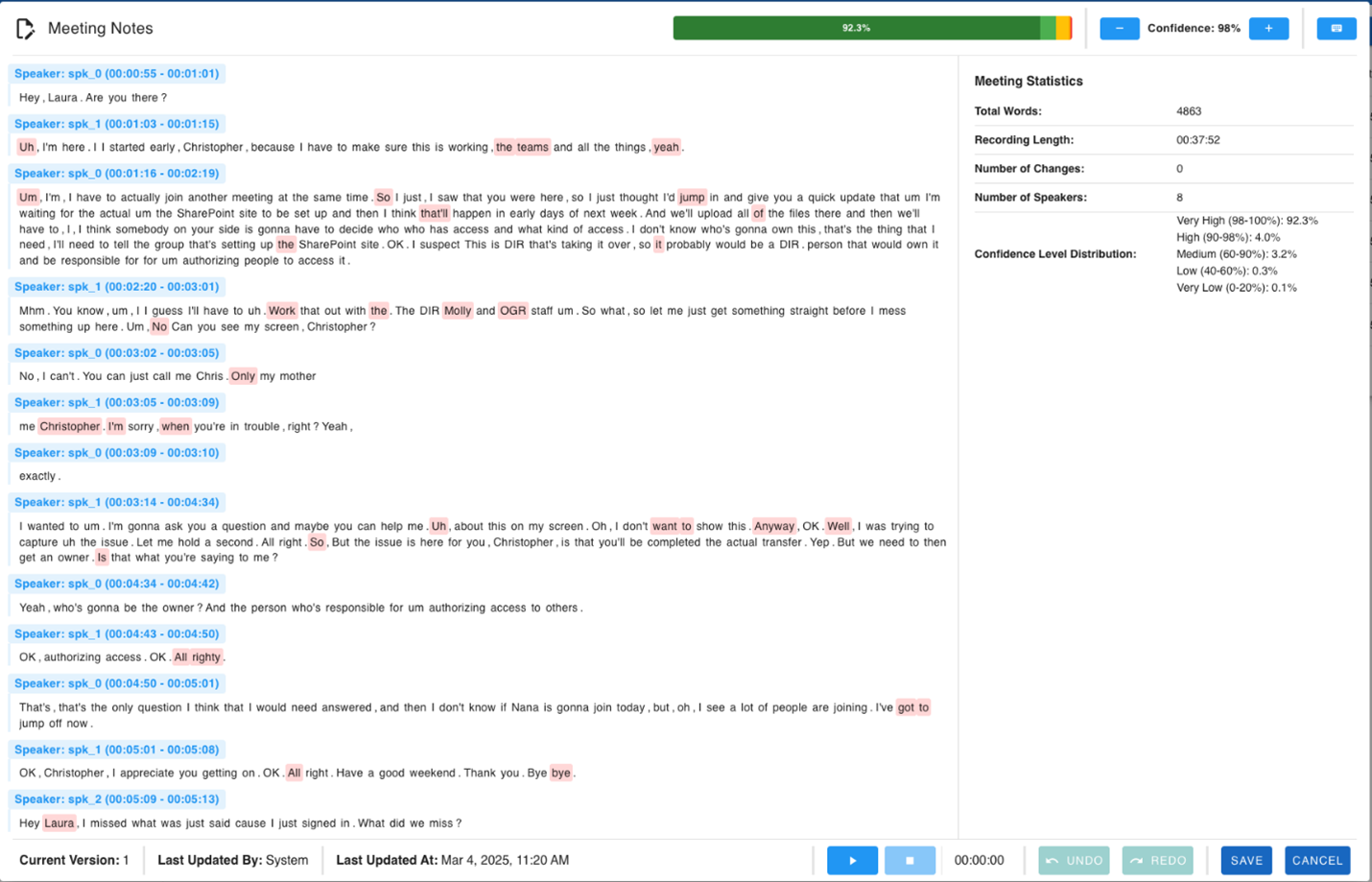
Figure 3: Meeting notes editor
Speaker identification and management are seamlessly integrated into the editing experience. Users can modify speaker assignments through an inline dropdown menu that appears when clicking on speaker labels. The system maintains speaker consistency throughout the transcript, automatically updating all instances of a speaker when corrections are made.
The interface supports batch speaker updates for efficient editing of longer transcripts. Additionally, users can use the integrated audio playback feature within the interface, which means they can listen to the recording while simultaneously highlighting words as they are spoken in real time. This synchronized playback and text highlighting capability means that users can precisely identify and correct any transcription errors by comparing the audio with the written text.
The custom vocabulary management system is deeply integrated into the editing workflow. When users correct transcription errors, they can instantly add words or phrases to their organization’s custom vocabulary through a contextual menu, as shown in the following screenshot. These additions are categorized by research domain and automatically synchronized with the Amazon Transcribe custom vocabulary API.
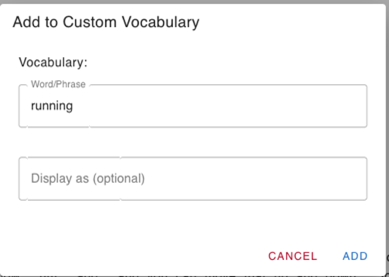
Figure 4: Custom vocabulary contextual menu
The system maintains usage statistics for each term, helping organizations build comprehensive, domain-specific vocabularies that continually improve transcription accuracy. Additionally, the editor suggests potential vocabulary additions by analyzing patterns in manual corrections across multiple meetings, making it easier for organizations to maintain and expand their specialized terminology databases.
Technical implementation
The frontend provides a seamless user experience with offline capabilities through progressive web app (PWA) implementation. Real-time collaboration features are enabled through a VueJS interface hosted on Amazon Amplify. When meeting transcripts are finalized and approved, they’re automatically processed through an Amazon Step Functions workflow that prepares and formats the content for Amazon Bedrock Knowledge Bases ingestion. This process includes metadata enrichment, topic extraction, and relationship mapping, making the content optimally structured for AI-powered retrieval and analysis.
The integration with Amazon Bedrock Knowledge Bases transforms how users can interact with historical meeting data. As soon as a meeting transcript is sealed and processed, it becomes part of the organization’s knowledge graph, enabling the meeting assistant to provide contextually relevant information from both recent and historical meetings. This real-time knowledge integration allows researchers to ask questions about current discussions while immediately leveraging insights from meetings that may have just concluded, creating a truly dynamic and up-to-date research knowledge base. Amazon CloudFront enables this rich interactive experience to be delivered with low latency to users globally, crucial for international research collaborations.
The backend architecture implements a microservice-based architecture for faster feature development and source code maintainability. The system uses event sourcing to maintain a complete audit trail of all changes, crucial for scientific record-keeping. The implementation includes automatic scaling capabilities, with API Gateway for API management, AWS Lambda used for services, and Amazon Step Functions handling service orchestration and management. Aurora PostgreSQL-Compatible provides seamless performance scaling for storage, while Amazon Bedrock Knowledge Bases automatically ingests and indexes finalized meeting transcripts in real-time, making them immediately available for AI-powered analysis and retrieval through the meeting assistant.
Security and compliance
Security is paramount in scientific research. This solution implements comprehensive security measures including multi-factor authentication (MFA) through Amazon Cognito, IP-based access controls, and end-to-end encryption using AWS Key Management Services (AWS KMS). Additionally, the solution implements automated security scanning and continual monitoring through Amazon GuardDuty and AWS Security Hub.
Benefits for scientific research
In the following screenshot, we demonstrate the transformative potential of generative AI in meeting analytics, showcasing a forward-looking vision of how organizations might capture and analyze meeting content. The dashboard presents an intriguing glimpse into what’s possible, featuring automated extraction of key meeting elements such as speaking time distribution, engagement metrics, and agenda coverage. This illustrates how generative AI could transform raw meeting content into structured, actionable insights—from automatically identifying key problems and solutions to tracking participation rates and speaking patterns among attendees.
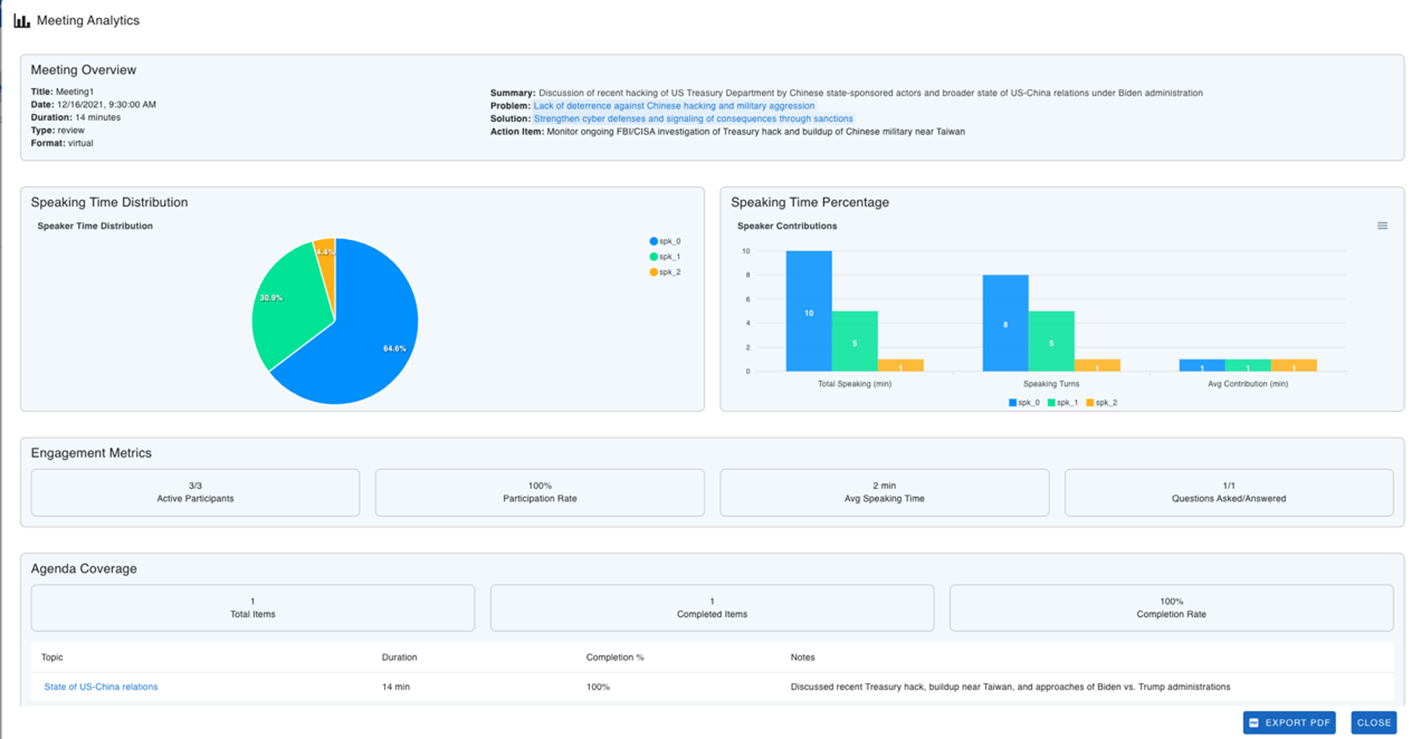
Figure 5: Meeting analytics graph
This dashboard powerfully illustrates the art of the possible in the realm of AI-enhanced collaboration tools. It demonstrates how to automatically parse meeting discussions to generate comprehensive analytics, extract action items, and provide visual representations of meeting dynamics. As organizations continue to explore the possibilities of generative AI, this prototype serves as an inspiring example of how we might reimagine meeting productivity and knowledge management in the enterprise space.
Meeting assistant
During scientific meetings, researchers can interact with an intelligent natural language based interface powered by Amazon Bedrock FMs, which provides real-time assistance and insights. The chat assistant can answer questions about specific discussion points, clarify technical terminology, or surface relevant information from previous meetings. For example, when a researcher asks, “What were the key findings from our protein analysis discussion last week?”, the chat assistant seamlessly retrieves and summarizes the relevant information while also identifying any related discussions from other meetings that might be pertinent to the current research focus. The meeting assistant interface is shown in the following screenshot.
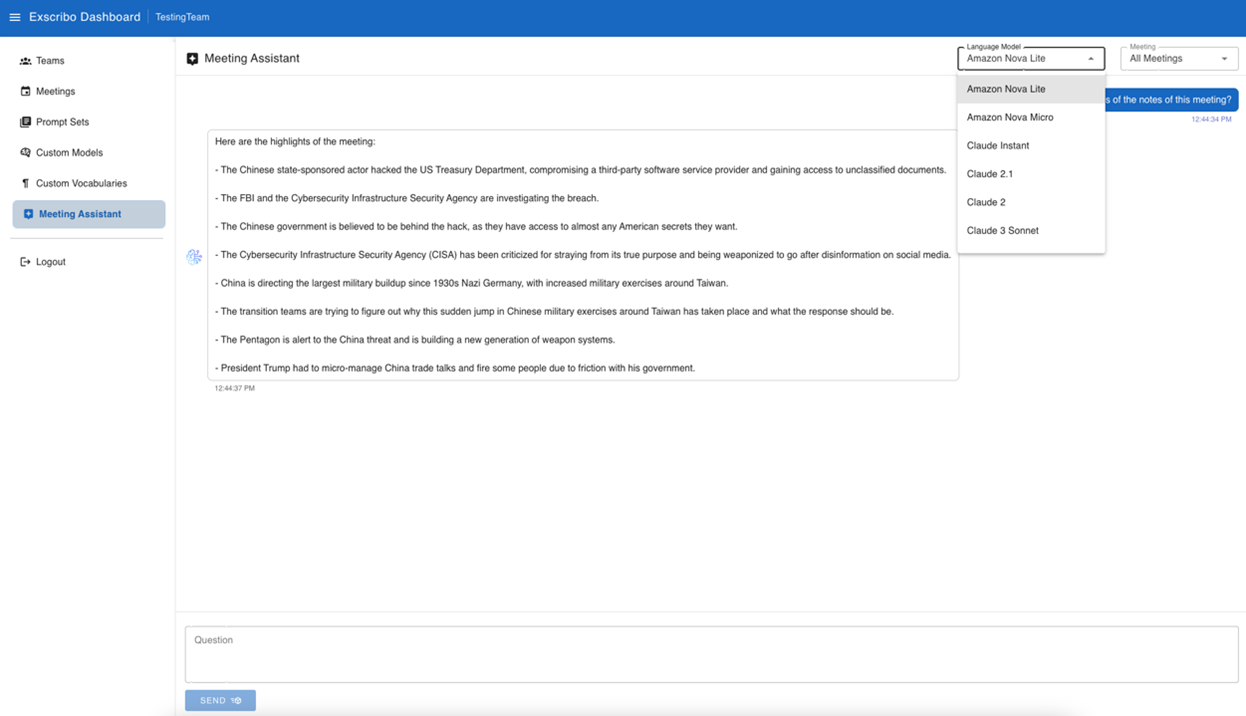
Figure 6: Meeting assistant interface
The cross-meeting intelligence feature extends the chat assistant’s capabilities beyond single-meeting contexts. By using Amazon OpenSearch Service and Amazon Bedrock models, the system maintains a comprehensive understanding of the organization’s entire meeting history and research context. Researchers can explore complex queries like, “Show me all discussions about CRISPR techniques across our lab meetings this quarter” or “What different approaches have we considered for solving our current methodology challenge?” The chat assistant then synthesizes information across multiple meetings, identifying patterns, contradictions or evolving discussions, while providing citations to specific meeting timestamps and participants. This feature transforms the meeting archive from a passive repository into an active knowledge base that researchers can engage with naturally through conversation.
The power of AWS generative AI services for fast development
Through the groundbreaking capabilities of Amazon Q Developer, we accomplished what typically would have been a months-long development cycle in just 15 days. The project architecture—combining VueJS for the frontend, .NET Lambda functions for backend services, and AWS Cloud Development Kit (AWS CDK) with Python for infrastructure as code (IaC)—was streamlined significantly through AI-assisted development. Amazon Q Developer proved invaluable by generating boilerplate code, suggesting optimizations for our Vue components, and even helping debug complex Lambda function implementations. The tool’s deep understanding of AWS best practices was particularly evident in crafting the CDK infrastructure code, where it provided context-aware suggestions for security configurations and resource optimization.
Perhaps most impressively, Amazon Q Developer helped maintain consistency across our full-stack implementation by understanding the interrelations between frontend state management, API integrations, and backend services. This project attests to how Amazon generative AI services are revolutionizing development workflows, enabling small teams to deliver enterprise-grade solutions in record time while maintaining high code quality and AWS best practices.
Conclusion
This solution—which is powered by AWS services—demonstrates how modern cloud technologies can revolutionize scientific research documentation and analysis. The combination of accurate transcription, intelligent analysis, and secure collaboration features creates a powerful platform that enhances research productivity and knowledge sharing. As research becomes increasingly collaborative and data-driven, tools like this will become essential for modern scientific work.
Getting the code
All the code referenced in this blog post is available in our AWS Samples GitHub repository. You can find the complete source code on this webpage.
Feel free to clone or download the repository to explore the implementation details and try it out yourself.