Artificial Intelligence
Category: Compute

Optimizing Mobileye’s REM™ with AWS Graviton: A focus on ML inference and Triton integration
In this post, we focus on one portion of the REM™ system: the automatic identification of changes to the road structure which we will refer to as Change Detection. We will share our journey of architecting and deploying a solution for Change Detection, the core of which is a deep learning model called CDNet. We will share real-life decisions and tradeoffs when building and deploying a high-scale, highly parallelized algorithmic pipeline based on a Deep Learning (DL) model, with an emphasis on efficiency and throughput.

HyperPod enhances ML infrastructure with security and storage
This blog post introduces two major enhancements to Amazon SageMaker HyperPod that strengthen security and storage capabilities for large-scale machine learning infrastructure. The new features include customer managed key (CMK) support for encrypting EBS volumes with organization-controlled encryption keys, and Amazon EBS CSI driver integration that enables dynamic storage management for Kubernetes volumes in AI workloads.
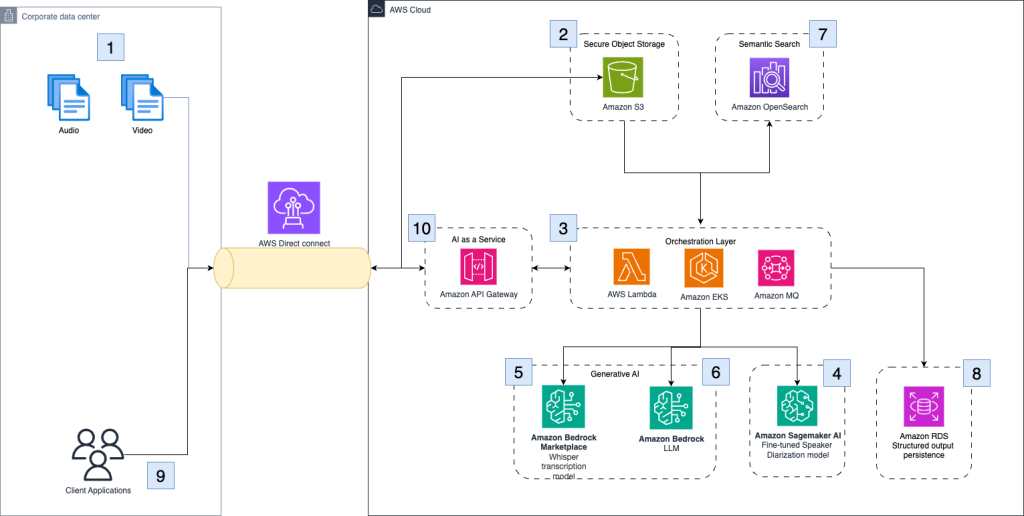
How Clario automates clinical research analysis using generative AI on AWS
In this post, we demonstrate how Clario has used Amazon Bedrock and other AWS services to build an AI-powered solution that automates and improves the analysis of COA interviews.
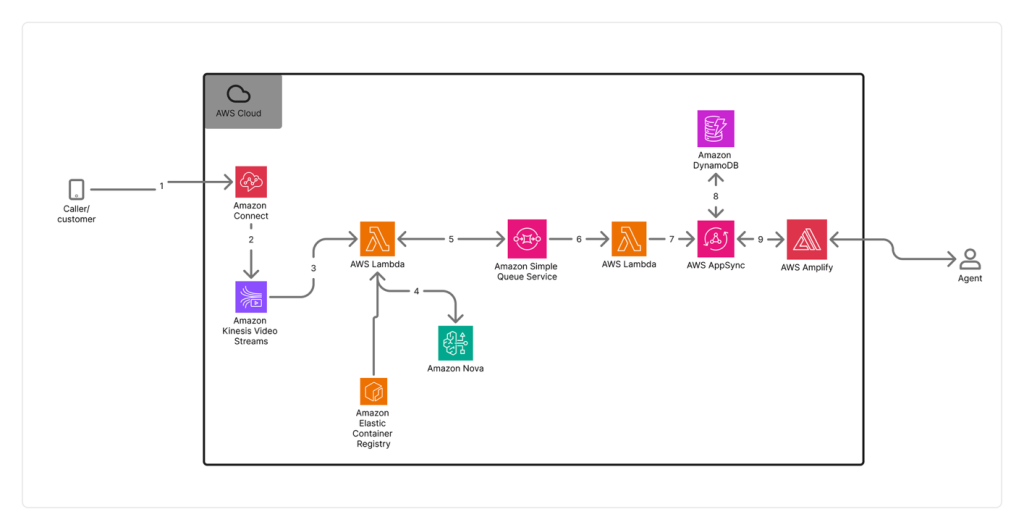
How Switchboard, MD automates real-time call transcription in clinical contact centers with Amazon Nova Sonic
In this post, we examine the specific challenges Switchboard, MD faced with scaling transcription accuracy and cost-effectiveness in clinical environments, their evaluation process for selecting the right transcription solution, and the technical architecture they implemented using Amazon Connect and Amazon Kinesis Video Streams. This post details the impressive results achieved and demonstrates how they were able to use this foundation to automate EMR matching and give healthcare staff more time to focus on patient care.
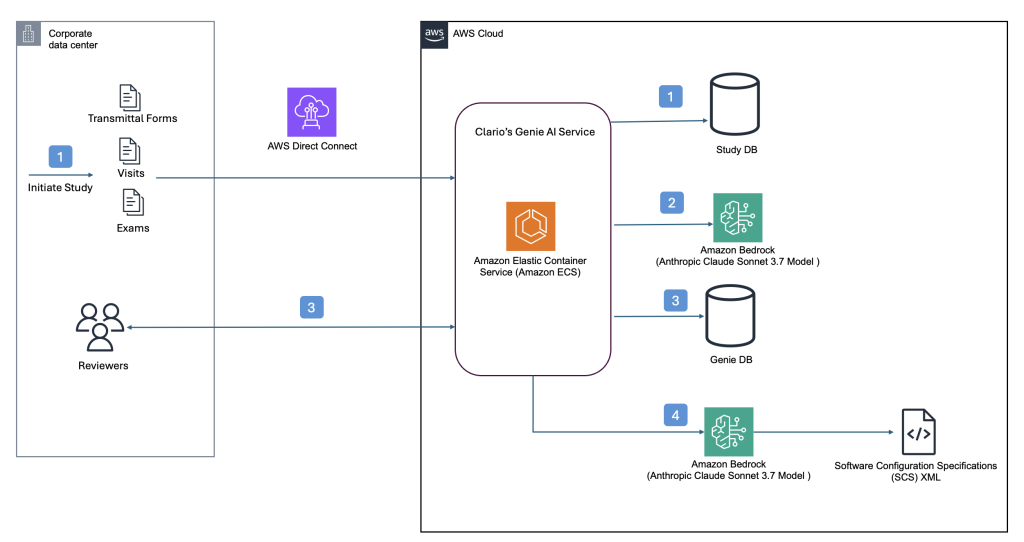
Clario streamlines clinical trial software configurations using Amazon Bedrock
This post builds upon our previous post discussing how Clario developed an AI solution powered by Amazon Bedrock to accelerate clinical trials. Since then, Clario has further enhanced their AI capabilities, focusing on innovative solutions that streamline the generation of software configurations and artifacts for clinical trials while delivering high-quality clinical evidence.

Accelerate large-scale AI training with Amazon SageMaker HyperPod training operator
In this post, we demonstrate how to deploy and manage machine learning training workloads using the Amazon SageMaker HyperPod training operator, which enhances training resilience for Kubernetes workloads through pinpoint recovery and customizable monitoring capabilities. The Amazon SageMaker HyperPod training operator helps accelerate generative AI model development by efficiently managing distributed training across large GPU clusters, offering benefits like centralized training process monitoring, granular process recovery, and hanging job detection that can reduce recovery times from tens of minutes to seconds.

Splash Music transforms music generation using AWS Trainium and Amazon SageMaker HyperPod
In this post, we show how Splash Music is setting a new standard for AI-powered music creation by using its advanced HummingLM model with AWS Trainium on Amazon SageMaker HyperPod. As a selected startup in the 2024 AWS Generative AI Accelerator, Splash Music collaborated closely with AWS Startups and the AWS Generative AI Innovation Center (GenAIIC) to fast-track innovation and accelerate their music generation FM development lifecycle.

Voice AI-powered drive-thru ordering with Amazon Nova Sonic and dynamic menu displays
In this post, we’ll demonstrate how to implement a Quick Service Restaurants (QSRs) drive-thru solution using Amazon Nova Sonic and AWS services. We’ll walk through building an intelligent system that combines voice AI with interactive menu displays, providing technical insights and implementation guidance to help restaurants modernize their drive-thru operations.
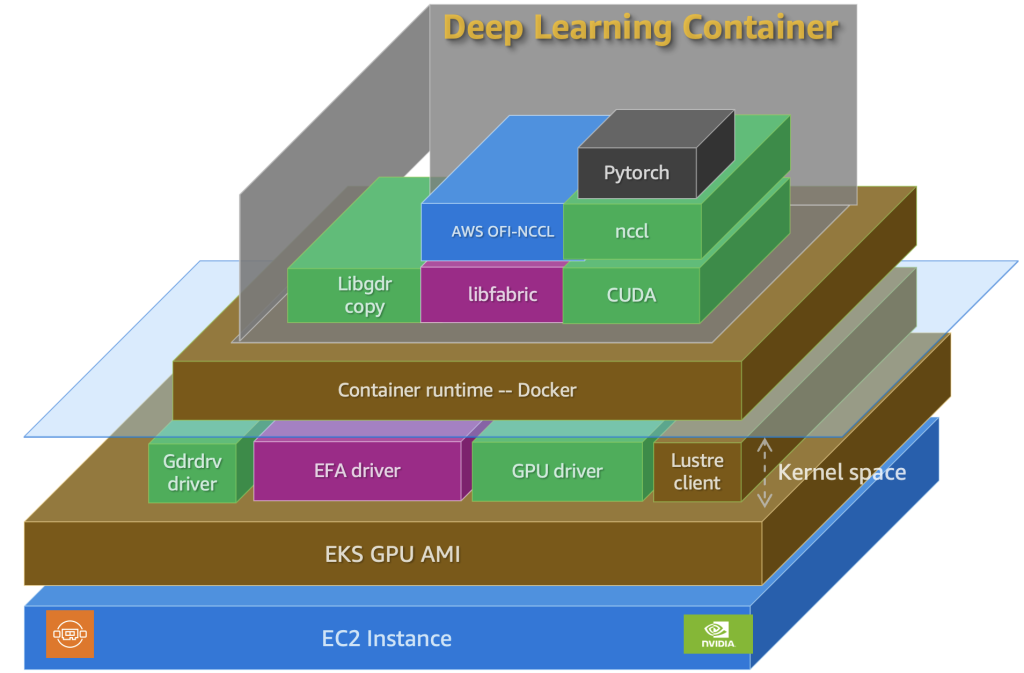
Configure and verify a distributed training cluster with AWS Deep Learning Containers on Amazon EKS
Misconfiguration issues in distributed training with Amazon EKS can be prevented following a systematic approach to launch required components and verify their proper configuration. This post walks through the steps to set up and verify an EKS cluster for training large models using DLCs.
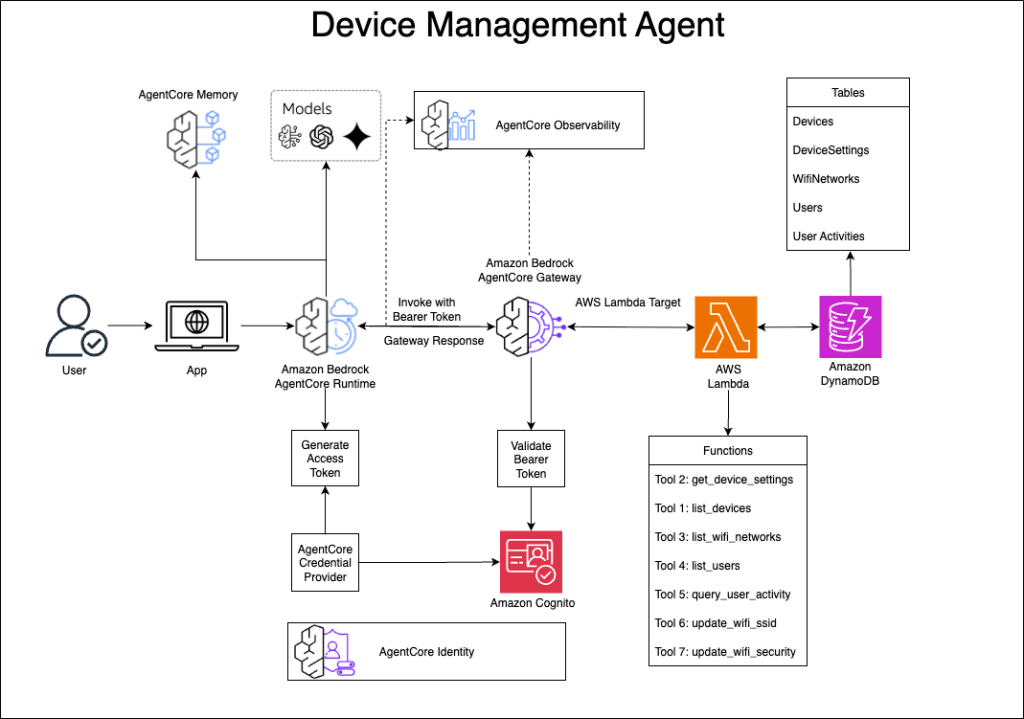
Build a device management agent with Amazon Bedrock AgentCore
In this post, we explore how to build a conversational device management system using Amazon Bedrock AgentCore. With this solution, users can manage their IoT devices through natural language, using a UI for tasks like checking device status, configuring WiFi networks, and monitoring user activity.