Artificial Intelligence
Category: Amazon SageMaker

Amazon SageMaker HyperPod launches model deployments to accelerate the generative AI model development lifecycle
In this post, we announce Amazon SageMaker HyperPod support for deploying foundation models from SageMaker JumpStart, as well as custom or fine-tuned models from Amazon S3 or Amazon FSx. This new capability allows customers to train, fine-tune, and deploy models on the same HyperPod compute resources, maximizing resource utilization across the entire model lifecycle.

Supercharge your AI workflows by connecting to SageMaker Studio from Visual Studio Code
AI developers and machine learning (ML) engineers can now use the capabilities of Amazon SageMaker Studio directly from their local Visual Studio Code (VS Code). With this capability, you can use your customized local VS Code setup, including AI-assisted development tools, custom extensions, and debugging tools while accessing compute resources and your data in SageMaker Studio. In this post, we show you how to remotely connect your local VS Code to SageMaker Studio development environments to use your customized development environment while accessing Amazon SageMaker AI compute resources.

Use K8sGPT and Amazon Bedrock for simplified Kubernetes cluster maintenance
This post demonstrates the best practices to run K8sGPT in AWS with Amazon Bedrock in two modes: K8sGPT CLI and K8sGPT Operator. It showcases how the solution can help SREs simplify Kubernetes cluster management through continuous monitoring and operational intelligence.

Accelerating data science innovation: How Bayer Crop Science used AWS AI/ML services to build their next-generation MLOps service
In this post, we show how Bayer Crop Science manages large-scale data science operations by training models for their data analytics needs and maintaining high-quality code documentation to support developers. Through these solutions, Bayer Crop Science projects up to a 70% reduction in developer onboarding time and up to a 30% improvement in developer productivity.
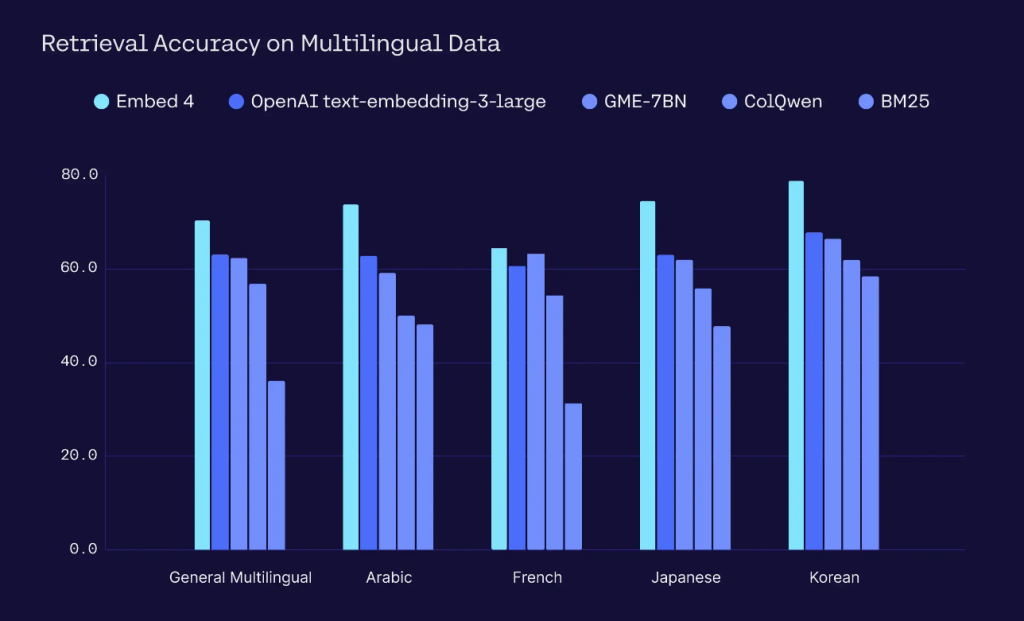
Cohere Embed 4 multimodal embeddings model is now available on Amazon SageMaker JumpStart
The Cohere Embed 4 multimodal embeddings model is now generally available on Amazon SageMaker JumpStart. The Embed 4 model is built for multimodal business documents, has leading multilingual capabilities, and offers notable improvement over Embed 3 across key benchmarks. In this post, we discuss the benefits and capabilities of this new model. We also walk you through how to deploy and use the Embed 4 model using SageMaker JumpStart.

Qwen3 family of reasoning models now available in Amazon Bedrock Marketplace and Amazon SageMaker JumpStart
Today, we are excited to announce that Qwen3, the latest generation of large language models (LLMs) in the Qwen family, is available through Amazon Bedrock Marketplace and Amazon SageMaker JumpStart. With this launch, you can deploy the Qwen3 models—available in 0.6B, 4B, 8B, and 32B parameter sizes—to build, experiment, and responsibly scale your generative AI applications on AWS. In this post, we demonstrate how to get started with Qwen3 on Amazon Bedrock Marketplace and SageMaker JumpStart.

End-to-End model training and deployment with Amazon SageMaker Unified Studio
In this post, we guide you through the stages of customizing large language models (LLMs) with SageMaker Unified Studio and SageMaker AI, covering the end-to-end process starting from data discovery to fine-tuning FMs with SageMaker AI distributed training, tracking metrics using MLflow, and then deploying models using SageMaker AI inference for real-time inference. We also discuss best practices to choose the right instance size and share some debugging best practices while working with JupyterLab notebooks in SageMaker Unified Studio.
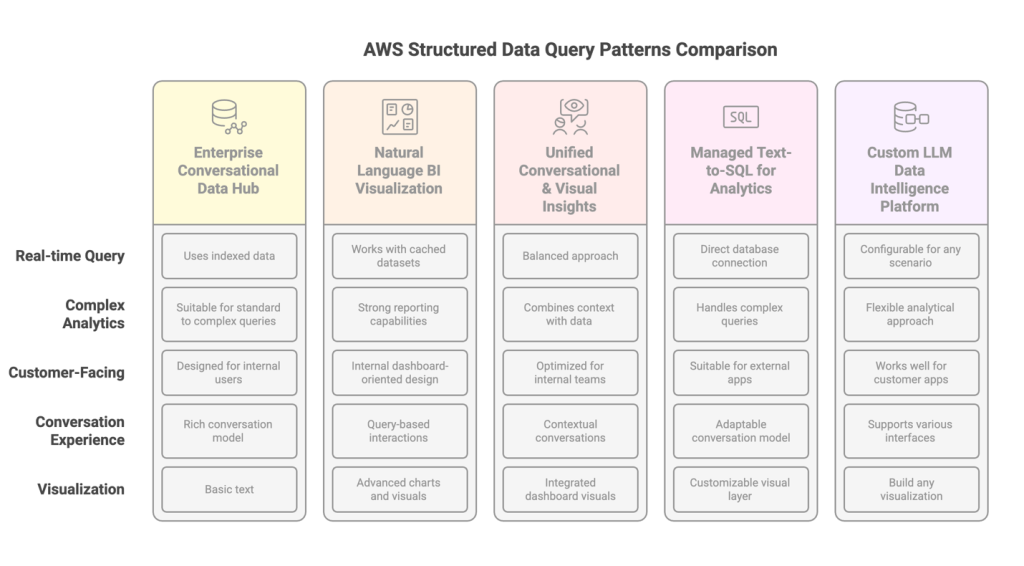
Choosing the right approach for generative AI-powered structured data retrieval
In this post, we explore five different patterns for implementing LLM-powered structured data query capabilities in AWS, including direct conversational interfaces, BI tool enhancements, and custom text-to-SQL solutions.

Build and deploy AI inference workflows with new enhancements to the Amazon SageMaker Python SDK
In this post, we provide an overview of the user experience, detailing how to set up and deploy these workflows with multiple models using the SageMaker Python SDK. We walk through examples of building complex inference workflows, deploying them to SageMaker endpoints, and invoking them for real-time inference.

Using Amazon SageMaker AI Random Cut Forest for NASA’s Blue Origin spacecraft sensor data
In this post, we demonstrate how to use SageMaker AI to apply the Random Cut Forest (RCF) algorithm to detect anomalies in spacecraft position, velocity, and quaternion orientation data from NASA and Blue Origin’s demonstration of lunar Deorbit, Descent, and Landing Sensors (BODDL-TP).