AWS for Industries
Part 6: Effective sunset of the legacy data platform in BBVA: the migration methodology
This is the sixth and final post of a six-part series detailing how BBVA migrated its Analytics, Data, AI (ADA) platform to AWS. We’re sharing how BBVA successfully orchestrated the sunset of their legacy data platform while ensuring a smooth transition of approximately 500TB of data and over 250 analytical environments to AWS.
Read the entire series:
- Part 1: BBVA: Building a multi-region, multi-country global Data and ML Platform at scale
- Part 2: How BBVA processes a global data lake using AWS Glue and Amazon EMR
- Part 3: How BBVA built a global analytics and machine learning platform on AWS
- Part 4: Building a Multi-Layer Security Strategy for BBVA’s Global Data Platform on AWS
- Part 5: BBVA’s unified console: Key to successful global platform deployment
- Part 6: Effective sunset of the legacy data platform in BBVA: the migration methodology
Challenges
BBVA accomplished a comprehensive migration from on-premises to AWS, with the data lake transition serving as a cornerstone of the project namely Analytics, Data, AI (ADA). The team effectively orchestrated the movement of approximately 500TB of data while seamlessly managing the synchronization of both the pseudo-catalog and data used across various ingestion and analysis stages. A major achievement was the catalog synchronization, which involved transferring and optimizing 30,000 tables, some containing up to 2,500 columns and over 100,000 partitions. The team implemented innovative strategies for both the initial migration and incremental iterations, ensuring data consistency and operational efficiency throughout the transition period.
The project’s success extended to the migration of over 250 analytical environments (sandboxes) across Europe and America, demonstrating BBVA’s ability to execute large-scale transformations. The team orchestrated the movement of critical components, including analytical datasets, workspace code, shared notebooks, BI data, ML models, and software products (Python and PySpark). Through sophisticated automation and careful planning, they adapted existing configurations and executable artifacts from Artifactory to AWS services, while maintaining parallel environments for thorough validation. This comprehensive approach ensured a smooth transition that maintained business continuity while positioning BBVA for enhanced operational capabilities in the cloud environment.
Catalog synchronization
In Part 2, we dive into how BBVA configured AWS Glue Data Catalog for efficient data cataloging and access, using AWS Lake Formation for managing the permissions. However, before using the catalog, it was necessary to migrate the metadata stored in the repositories to AWS. BBVA didn’t have a proper catalog on-premises but had schemas for all tables as a reference, without requiring jobs to use them. This led to issues with discordant schemas of stored data and challenges in schema evolution.
BBVA planned the metadata migration on two fronts:
- Migrating the catalog itself
- Migrating table partitions where needed
For catalog migration, they developed a series of components based on AWS Lambda and Amazon Simple Queue Service (Amazon SQS) for orchestrated and parallelized mass loading. The data team provided a CSV file with a list of all available tables, storing it in Amazon Simple Storage Service (Amazon S3). When this file was made available, the workflow was started. Through process parallelization using multiple concurrencies in Lambda functions, they achieved complete catalog migration, containing 30,000 tables (some with up to 2,500 columns and over 100,000 partitions) in approximately 15 minutes.
A peculiarity of the ADA environment is that the responsibilities of each platform’s role are well-defined. Regarding catalog loading with Lake Formation enabled, when a table is created, it assigns full permissions to the principal that created it. This behavior was undesirable in ADA, so the process had to be changed to remove the permissions in Lake Formation from the principal that created the tables immediately after creation. This way, the execution role of the Lambda function managing the catalog only has access to the catalog, not the data in the data lake.
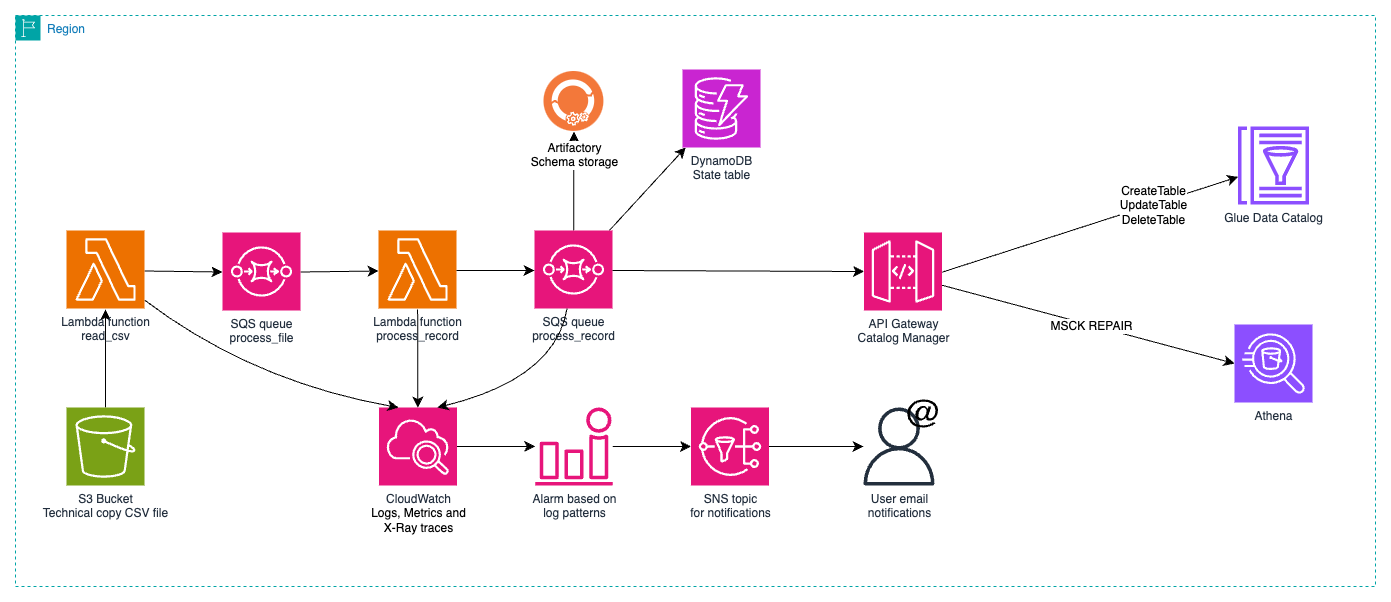 Figure 1: Catalog load process
Figure 1: Catalog load process
Data synchronization
BBVA used Amazon EMR for both batch processing and data copying from Hadoop Distributed File System (HDFS) to S3. After evaluating several AWS services, they chose a changed version of DistCp that enabled HDFS path mapping to S3 structures and integrated with Amazon Data Firehose for real-time monitoring of copy events.
The data copy process handled both complete and incremental transfers using a CSV inventory file. A single, adaptable process managed initial full transfers and incremental copies that identified new or deleted files. BBVA orchestrated this through AWS Step Functions with a state machine that:
- Parsed CSV files for paths
- Categorized files by country
- Created and terminated EMR clusters dynamically
The initial migration transferred 500TB of data at 10TB/h using a 40Gbps network line, with 700 parallel Spark maps optimized for 128MB file sizes. The incremental phase proved even more efficient, processing 100TB in just 3 hours using a smart differential copy strategy that only transferred changed files. This showed the architecture’s capability for efficient large-scale data transfers.
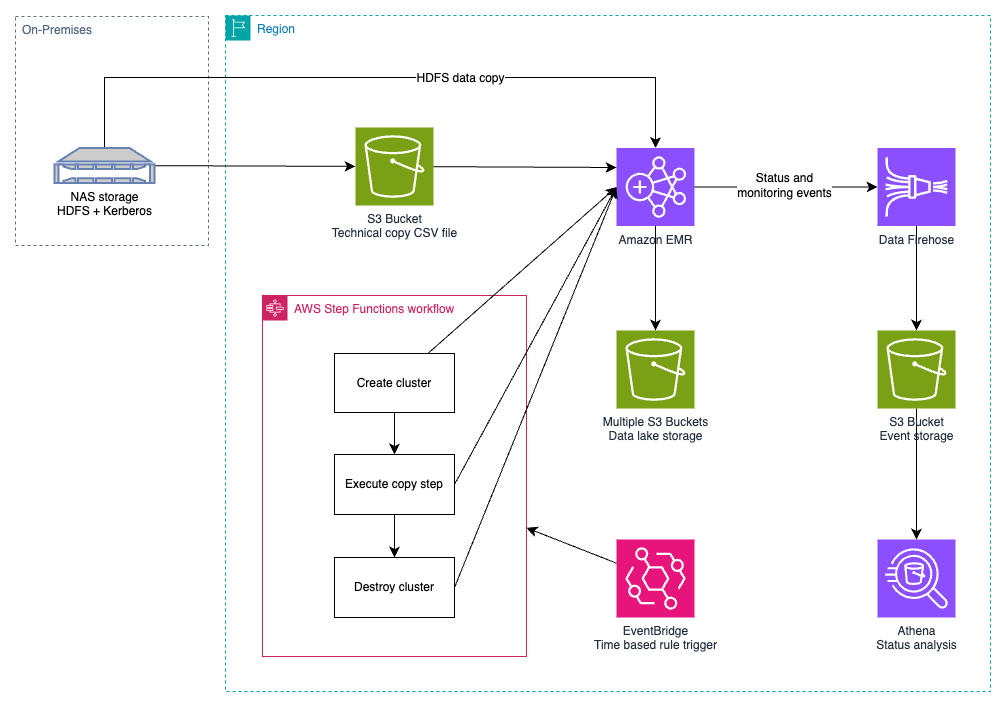 Figure 2: Data copy process
Figure 2: Data copy process
Partition synchronization
After copying data, updating the catalog with new or deleted partition directories played a crucial role. BBVA’s tables were mostly partitioned, primarily using date fields for structuring.
Partition synchronization was essential as unregistered partitions wouldn’t be analyzed. BBVA evaluated several methods:
- Amazon Athena’s MSCK REPAIR: Rejected because of scale and quota limitations
- Spark/EMR discovery: Not feasible because of access requirements
- Partition Projection: Limited to Athena compatibility
The chosen solution used the existing data copy CSV file, analyzing partitions for creation or deletion through direct AWS Glue API interaction. BBVA implemented this using AWS Step Functions with four major tasks:
- Reading the source CSV file
- Detecting directory changes
- Grouping by table
- Synchronizing via Lambda using Batch Partition APIs
This efficient approach ensured accurate catalog reflection and seamless access to migrated data while allowing parallel execution with data copying.
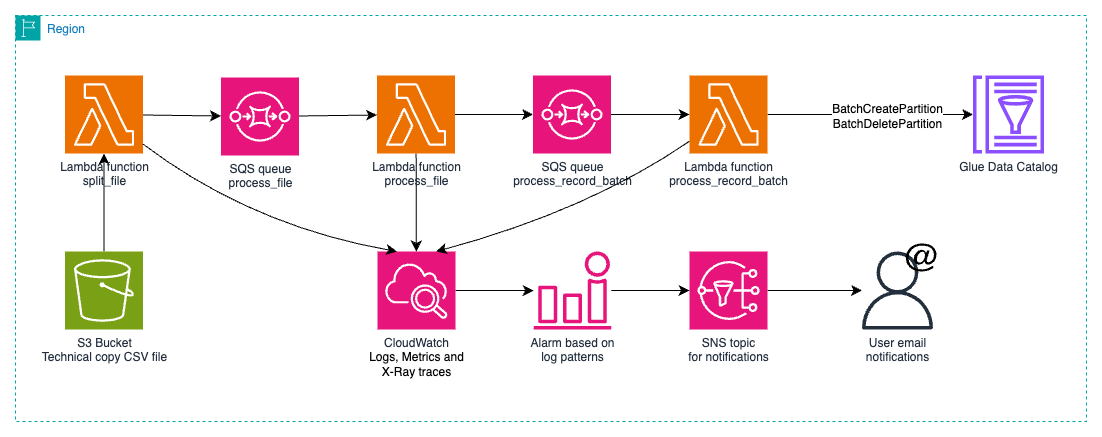 Figure 3: Partition load process
Figure 3: Partition load process
Jobs migration
The migration of Spark jobs from on-premises to AWS required a structured approach to maintain business continuity while modernizing BBVA’s data processing capabilities. The key challenges included:
- Managing different input/output paths from data lake migration to S3 buckets
- Migrating job configurations from Artifactory to ADA
- Replicating executable artifacts to S3 buckets
- Adapting internal libraries for AWS compatibility
- Running parallel validations between environments
BBVA developed an orchestrated mass loading system using AWS Lambda functions and Amazon SQS queues that:
- Extracted artifacts and configurations from on-premises
- Transferred files to an S3 bucket and the new configuration service
- Created updated job definitions
- Synchronized with the on-premises versions
For the remaining challenges, BBVA maintained identical paths, using internal libraries for translation and installed libraries at the cluster level to separate infrastructure dependencies from business logic.
Validations
BBVA maintained parallel environments for several months to ensure identical results between on-premises and AWS jobs. It made periodic incremental copies to separate S3 locations to avoid impacting production systems. Verification jobs compared data between environments, with validations running for both main and raw zones.
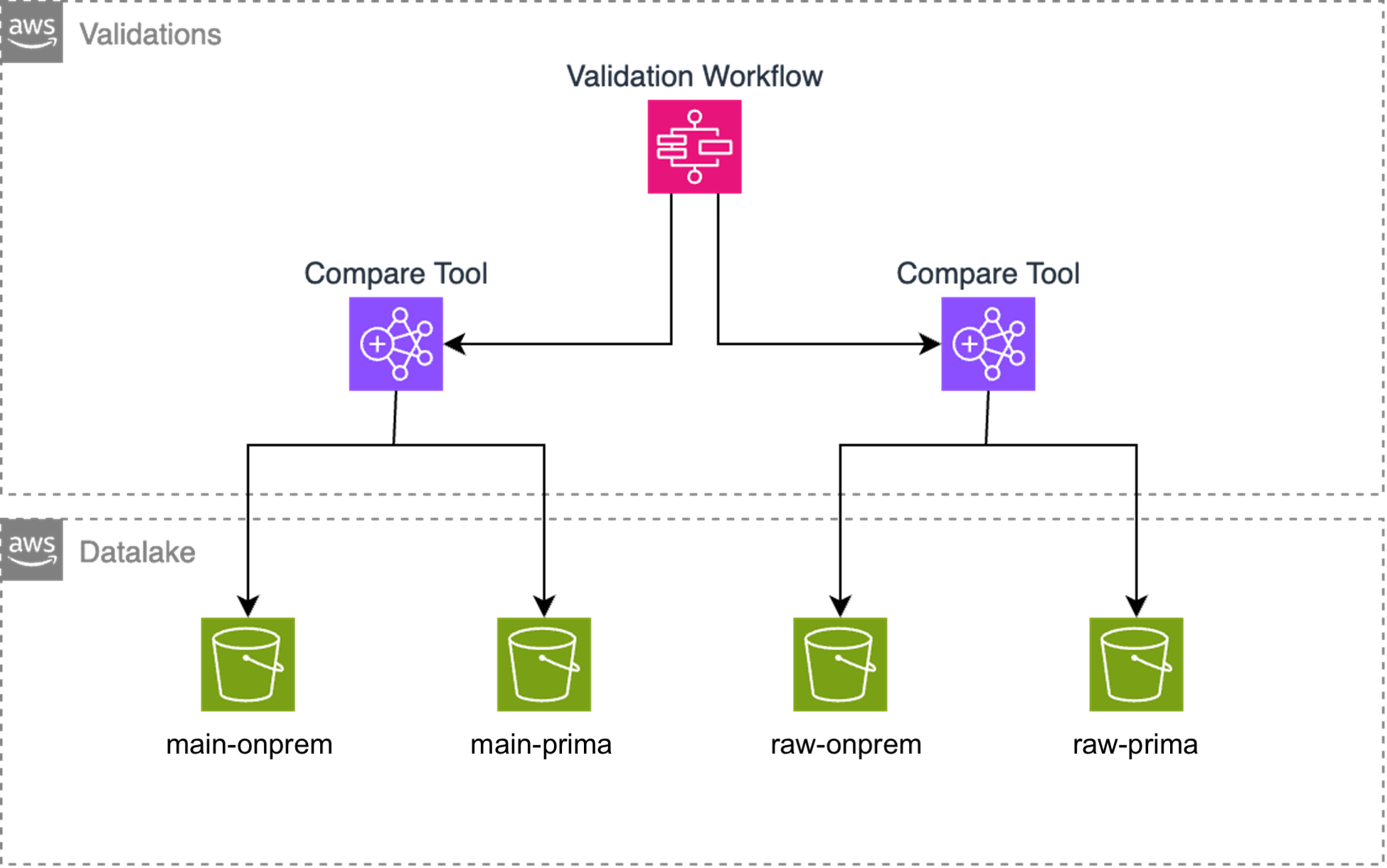
Figure 4: Validation architecture
A specialized team managed verification with Amazon EMR Serverless, selected for its scalability and cost-effectiveness. Key aspects included:
- EMR Serverless for automatically scaling verification jobs
- Direct data access without Lake Formation to simplify configuration
- Comprehensive data comparison (schema, record count, hashing, and field validation)
- Discrepancy identification and iterative improvement
The validation process runs unattended on weekends, generating:
- Partition summary entries
- Invalid record details
- Execution information
The architecture uses multiple AWS services: Compare tool (Scala) on EMR Serverless, Step Functions for orchestration, SQS and Lambda for data generation, and S3/Glue/Athena for storage and querying. This comprehensive approach ensured data accuracy and consistency throughout the migration, serving as a safety net for identifying and addressing inconsistencies before they could impact operations.
Sandbox migration
BBVA migrated over 250 isolated analytical environments from on-premises to AWS across Europe and the Americas. Each sandbox was an independent AWS account requiring the transfer of analytical datasets, workspace code, notebooks, Business Intelligence data, Machine Learning models, and user software.
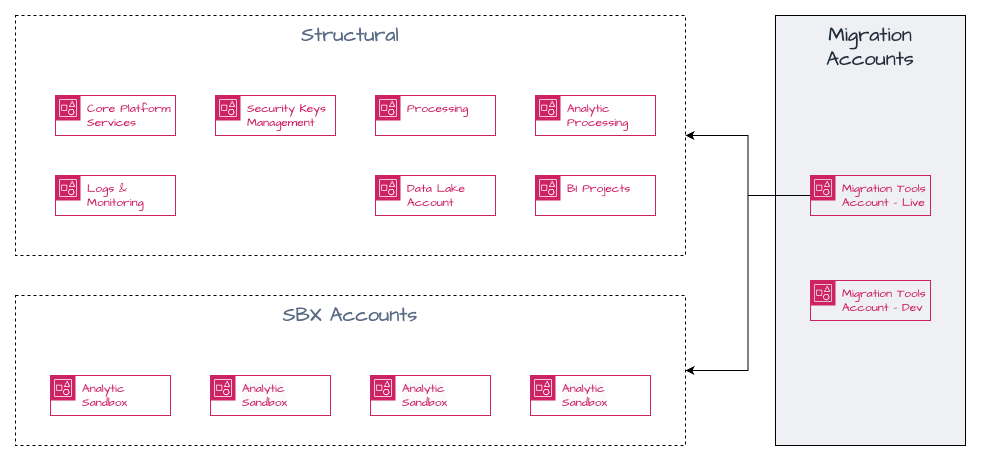 Figure 5: Migration accounts
Figure 5: Migration accounts
Key Challenges:
- Network Isolation: Sandboxes lacked internet and internal connectivity
- Scale: Automation needed across 250+ independent environments
- Component Diversity: Wide range of assets (data, code, notebooks, databases, ML models)
- Governance: Migration from HDFS ACLs to AWS Lake Formation
The migration architecture included a dedicated AWS migration utility account that orchestrated operations, storing only required metadata. It implemented:
- Multi-zone S3 structure (Raw, Silver, Gold) for different migration stages
- Serverless-first approach using AWS services (S3, Lambda, Step Functions, Glue, Amazon DynamoDB, AWS Secrets Manager, Athena) for processing, orchestration, and monitoring
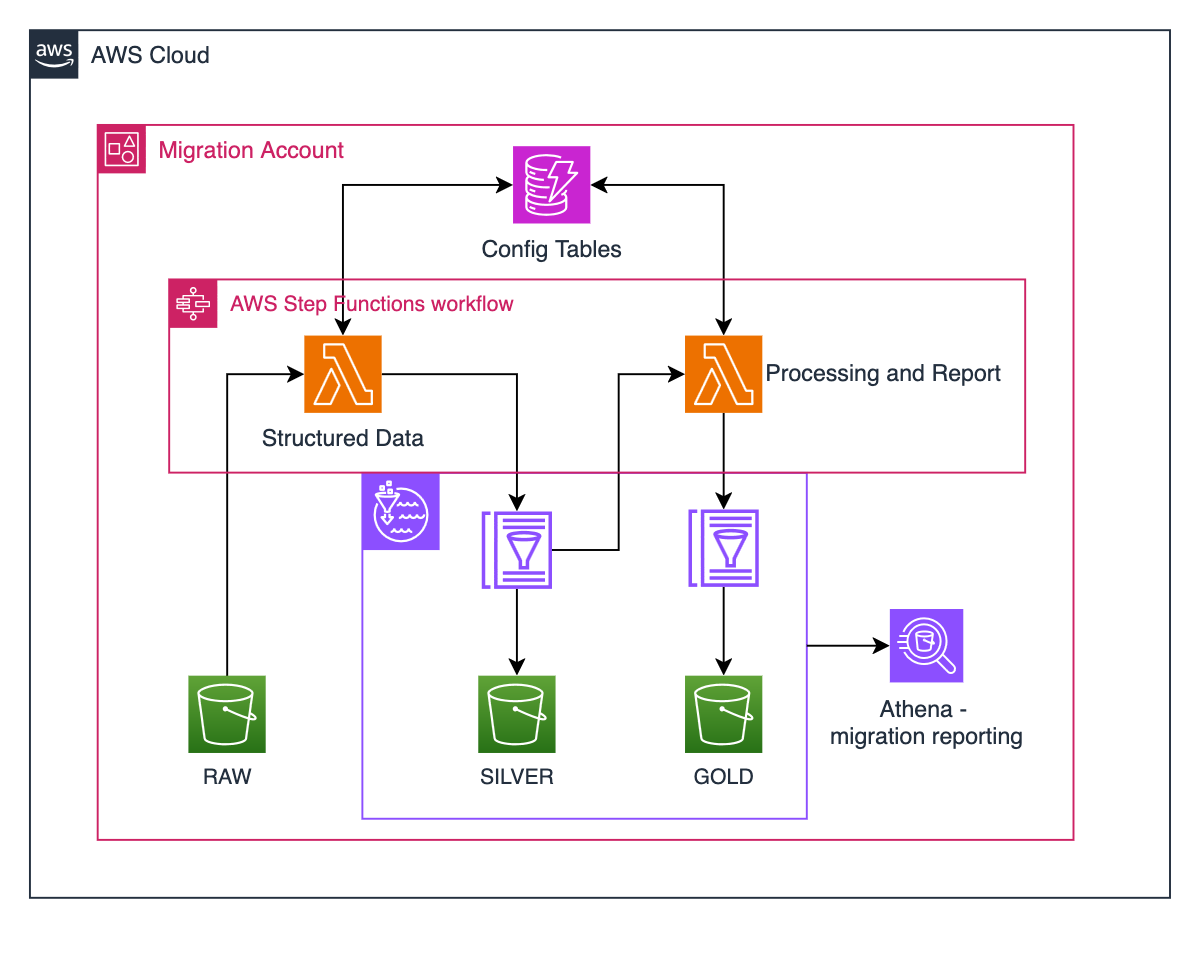 Figure 6: Data migration process
Figure 6: Data migration process
This streamlined architecture enabled secure and efficient migration while maintaining operational control and governance.
Data Migration
The data migration phase encompassed over 200 AWS sandbox accounts, each operating under complete internet isolation. The scope included four distinct data categories: sandbox bucket data, shared notebooks, user workspace data, and model artifacts. This structured approach ensured comprehensive coverage of all analytical assets while maintaining security constraints.
BBVA orchestrated the migration through AWS Step Functions in the migration account, which iteratively processed each sandbox based on geographical location. The process leveraged a secondary Step Function in the processing account to execute technical data copying from on-premises HDFS to destination S3 buckets. Using Amazon EMR clusters with DistCp for optimized distributed copying, the process generated detailed migration statistics that were stored in S3 and registered in the AWS Glue Data Catalog, enabling structured querying and comprehensive migration monitoring.
Reporting Database Migration
For the migration of over 30 PostgreSQL reporting databases, BBVA implemented an automated process that began with Jenkins jobs in the on-premises environment. These jobs generated database dumps in HDFS, triggering a Step Function in the migration utilities account that coordinated the transfer to either sandbox or production accounts. The process continued through a chain of Step Functions, with AWS CloudFormation StackSets deploying the necessary EC2 instance roles and permissions in destination accounts.
The final deployment stage used Amazon Elastic Compute Cloud (EC2) instances configured to access a migration bucket, automatically executing dump loading scripts through User Data without manual intervention. The entire process generated comprehensive logs in both Amazon S3 and Amazon CloudWatch, enabling monitoring without direct account access. Upon completion, an automated validation process compared source and target record counts, storing results in the AWS Glue Data Catalog for structured querying of migration success metrics.
HDFS ACLs Migration
The migration of HDFS ACLs permissions for main zone tables required adapting the security model to the AWS ecosystem. BBVA leveraged AWS Lake Formation to manage access to data cataloged in AWS Glue, enabling controlled access for over 200 sandboxes to main tables according to new permission schemes. The process began with ACL file generation in Datum, the bank’s data governance tool, which mapped HDFS permissions to sandbox groups requiring read and write access to main data paths.
The migration used AWS Step Functions parameterized by country and sandbox account, which iteratively generated specific permission files for each sandbox and triggered data subscription Step Functions in the ADA core account. Through the profiling API, it automatically assigned permissions to sandbox AWS account roles, with Lake Formation applying these permissions to Glue catalog tables. This approach ensured sandboxes could access main tables through a secure, centralized control scheme.
Data Catalog Migration
The migration of sandbox data catalogs was complex, involving over 200 AWS accounts and over 5,000 tables. Unlike main data, these catalogs lacked governance structures and required syntax modifications from Crossdata to AWS Glue. The European region alone processed 4,000 tables across 100 accounts in about one hour.
The migration process involved three phases, starting with table definition extraction through Jenkins jobs. 98% of the tables contained Parquet-formatted data, with 2% in CSV format. Technical copy tools transferred definitions to AWS, where Step Functions orchestrated the migration process by sandbox and country.
The core automation focused on DDL reconstruction and data mapping, handling tasks like column name escaping and special character conversion. The system mapped HDFS to S3 locations and managed views and external tables. Key steps included initial database creation through Athena and external table processing with AWS SDK for Pandas.
The process required special handling for main table views, including partitioned table references and data type conversions. Monitoring and validation were crucial, with reports stored in the AWS Glue Data Catalog. The migration achieved 99% successful table creation, though only 30% contained data. This systematic approach ensured a successful transition while maintaining data integrity.
Asset Migration (Models and Engines)
The migration of data and machine learning assets from on-premises to cloud environments involved over 5,000 Python and PySpark developments within sandbox environments. BBVA standardized structures through a minimal scaffolding version, creating two scaffolds: one for new cloud developments and another for existing code migration. They used Cruft and Cookiecutter tools to manage incremental updates while maintaining code integrity.
The migration architecture comprised three main phases:
- Metadata extraction and cataloging using AWS S3, Glue, Lambda, and DynamoDB
- Automated asset registration with Step Functions and Amazon EventBridge
- Version adaptation and deployment through CI/CD pipelines for Amazon SageMaker
The orchestration process, powered by AWS services, enabled efficient migration of over 5,000 user assets while establishing a foundation for future cloud-native development and enhanced user experience.
Conclusions: Migration at scale
The successful migration of BBVA’s data platform components to AWS shows the effectiveness of a well-structured, automated approach to cloud transformation. The initial data synchronization phase transferred approximately 500TB through a series of partial copies, achieving a throughput of 10TB/h using a dedicated 40Gbps network line. This performance was made possible by leveraging 700 Spark maps running in parallel, while the incremental copy phase further improved efficiency by processing 100TB of data in just 3 hours.
The catalog synchronization presented unique challenges, managing 30,000 tables, some containing up to 2,500 columns and over 100,000 partitions. Through process parallelization using Lambda functions, the team completed this complex migration in approximately 15 minutes, demonstrating the power of AWS serverless architectures for large-scale operations.
Key achievements in the sandbox migration include:
- Migration of over 250 analytical environments across Europe and America
- Processing of 4,000 tables in approximately one hour for the European region
- Successful migration of 30+ PostgreSQL reporting databases
- Implementation of secure access controls for over 200 sandboxes to main tables
- Migration of over 5,000 Python and PySpark developments to cloud-native implementations
The lessons learned from this migration emphasize the importance of comprehensive validation strategies and automated processes. By maintaining parallel environments and implementing rigorous validation procedures for both main and raw zones, BBVA ensured data integrity throughout the migration process. The success of this approach, combined with the effective use of AWS serverless services, provides a robust framework for future cloud migrations while maintaining operational excellence and security standards.
Strategic Collaboration and Future Innovation: “One team” BBVA and AWS
The success of BBVA’s global data platform transformation was rooted in a “one team” approach established from inception to delivery. This strategic collaboration and transformation journey united BBVA data engineering, BBVA architecture teams and strategic AWS Resources (Key Service teams within Analytics and ML/AI, AWS Professional Services, AWS Regions teams, AWS Presales Organizations, AWS Enterprise Support, etc.) in fulfilling BBVA’s roadmap to deliver ADA as a Group-wide initiative. BBVA’s decision to establish a specialized team focused solely on data platform design and architecture build, distinct from operational teams, was key to providing a clear separation of “build” versus “run” responsibilities ensuring both innovation in design and excellence in execution throughout the project lifecycle.
With the migration now well-consolidated, BBVA is positioned to incorporate progressively AWS technological innovations into ADA, particularly in areas such as real-time data processing and unstructured data management. These enhanced capabilities will enable BBVA to unlock the full potential of artificial intelligence across their solutions underscoring the bank’s commitment to technological innovation and its vision moving forward, as a leader in democratizing the use of data globally, while positioning itself right at the forefront of digital transformation in global banking.