AWS for Industries
Part 3: How BBVA built a global analytics and machine learning platform on AWS
This is the third post of a six-part series detailing how BBVA migrated its Analytics, Data, AI (ADA) platform to AWS. We’re sharing how BBVA partnered with AWS to onboard over 6,500 advanced users (including data scientists and data engineers) to a new machine learning platform based on Amazon SageMaker AI.
Read the entire series:
- Part 1: BBVA: Building a multi-region, multi-country global Data Platform at scale
- Part 2: How BBVA processes a global data lake using AWS Glue and Amazon EMR
- Part 3: How BBVA built a global analytics and machine learning platform on AWS
- Part 4: Building a Multi-Layer Security Strategy for BBVA’s Global Data Platform on AWS
- Part 5: BBVA’s unified console: Key to successful global platform deployment
- Part 6: Effective sunset of the legacy data platform in BBVA: the migration methodology
Introduction
BBVA Global Data Platform organizes BBVA’s analytics business units through dedicated sandbox accounts, with each business unit initiative assigned its own isolated environment. Within each sandbox account, sandbox owners define the initial configuration and resources available. Sandbox users (primarily data scientists and data engineers) leverage Amazon SageMaker AI to access data and create analytics workflows.
To handle these diverse analytical needs, each sandbox environment provides users with comprehensive tools for data lake access, data processing, interactive querying, machine learning model development, and business intelligence reporting. This standardized yet flexible approach allows ADA to maintain governance while empowering teams to innovate across its global operations.
ADA’s migration to AWS faced multiple challenges because of the scale and complexity of its analytics ecosystem. With thousands of analytics assets and users spread across global business units, the migration required careful planning. For instance, ADA needed to continue offering the existing on-premises capabilities while introducing new features, such as an expanded selection of ML tools and infrastructure options (for example, GPU instances).
Enabling self-service deployment of sandbox accounts for business units was critical for teams to gain agility while maintaining centralized governance. Scalability and cost optimization across sandbox environments were essential as the diverse analytical workloads risked escalating expenses without proper resource management.
By leveraging AWS services tailored to these needs, BBVA successfully built a secure, scalable, and cost-efficient platform that empowers BBVA analytics teams globally.
Solution overview
BBVA selected Amazon SageMaker AI as the primary tool for sandbox users to interact with data and build machine learning models. From Amazon SageMaker Studio, sandbox users have the flexibility to choose other tools for data processing and analysis, integrating with Amazon EMR and AWS Glue interactive sessions. Sandbox accounts also support interactive SQL with Amazon Athena and drive business intelligence (BI) workloads with Amazon Aurora and Amazon QuickSight.
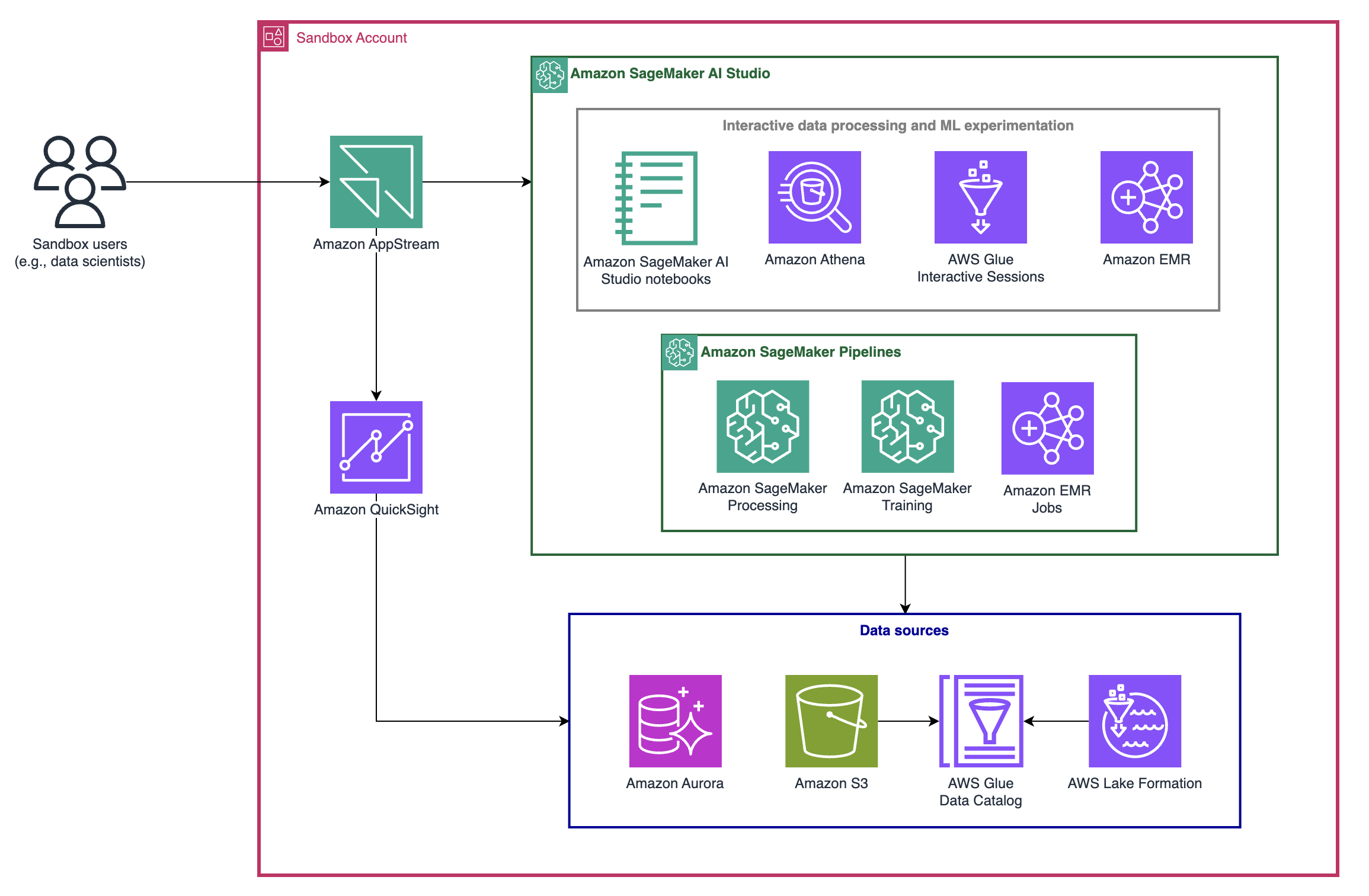
Figure 1 – Data science workflow from sandbox users through Amazon SageMaker Studio to data sources
The architecture diagram in Figure 1 illustrates how sandbox accounts enable ADA end users (data scientists, data engineers, etc.) to access multiple tools for managing and processing data, developing machine learning models, and building BI reports.
As part of the creation of a sandbox account, ADA offers sandbox owners the flexibility of enabling specific AWS services within the sandbox (QuickSight, Aurora database) and setting up infrastructure and usage configurations such as the maximum number of concurrent EMR clusters allowed (refer to the FinOps for data analytics and machine learning section for additional information). Part 5 of this series covers how ADA teams can deploy hundreds of sandbox accounts at scale with AWS CloudFormation.
Each sandbox account sits in a dedicated environment that brings together users from its respective business unit (BU). The number of user profiles scales based on the needs of the BU or project, and each BU onboards new users as needed during and after sandbox deployment. Each user gets a specific AWS Identity and Access Management (IAM) role that defines and enforces the resources they can access within the environment, such as GPU Amazon Elastic Compute Cloud (EC2) instances or SageMaker JupyterLab space instances.
In addition to a local AWS Glue Data Catalog for each sandbox, sandbox users can access the central data lake in the ADA Data account (refer to Part 1 of this series for additional information). AWS Lake Formation governs the access to the Data Catalog tables. And sandbox accounts can subscribe to specific tables from the ADA console (refer to Part 4 of this series for additional information on data subscription from the ADA console).
Amazon SageMaker AI monitors data access within the SageMaker Studio environment at an individual user level to ensure traceability and compliance (Monitor individual user resource access from SageMaker Studio with sourceIdentity). Users can only access SageMaker Studio through Amazon AppStream 2.0 to prevent data leakage (refer to Part 4 of this series for additional information on AppStream 2.0).
Administrators configure the SageMaker Studio domain in VPC-only access mode to ensure secure network isolation and prevent direct access from the public internet, requiring multiple VPC endpoints for services like EMR and Lake Formation. To manage costs, ADA centralizes these endpoints in a central account connected to sandbox accounts via AWS Transit Gateway. This setup simplifies network management and reduces costs by avoiding redundant endpoint configurations across multiple accounts. Refer to Centralized access to VPC private endpoints for additional information.
Advanced analytics and machine learning with Amazon SageMaker AI
The user journey for accessing sandbox environments typically begins from the ADA console (refer to Part 5 of this series for additional information on the ADA console), where users access SageMaker Studio through a secure AppStream 2.0 session. This setup ensures that sandbox users work within a controlled and isolated environment.
Interactive workloads
Once users enter SageMaker Studio, they initialize a SageMaker JupyterLab space tailored for their analytics and machine learning (ML) tasks. This environment supports the development of ML workloads using Jupyter notebooks, offering a flexible platform for experimentation and analysis.
From SageMaker Studio, users access a dedicated Data Catalog for their sandbox environment, as well as a global Data Catalog in the central Data account. Lake Formation governs this setup to enable fine-grained data access controls (refer to Apply fine-grained data access controls with AWS Lake Formation and Amazon EMR from Amazon SageMaker Studio for more details).
To access and process data from the Data Catalog, users run Athena queries and interactive Spark jobs on Amazon EMR or AWS Glue interactive sessions directly from their Jupyter notebooks. They access their local Aurora Serverless database through Jupyter notebooks to enhance their BI reports.
For ML experimentation, sandbox accounts provide access to Amazon SageMaker AI with MLflow, allowing data scientists to track metrics and experiments efficiently. This integration enables comprehensive experiment tracking across various environments, including SageMaker Studio notebooks and SageMaker Processing and Training jobs. It supports full MLflow capabilities, such as tracking runs and comparing model performance.
Users have the capability to automate data preparation processes by scheduling notebooks as SageMaker Notebook Jobs, streamlining workflows and enhancing productivity.
Streamlining EMR cluster creation with Service Catalog
To streamline the creation of Amazon EMR clusters with the required security cluster configuration, the ADA platform team provisioned AWS Service Catalog products across all sandbox accounts. For more information, see Configure Amazon EMR CloudFormation templates in the Service Catalog.
The platform team offers various predefined configurations for processing EMR clusters tailored to different workload sizes. User roles control access to these configurations. This lets sandbox users provision Amazon EMR clusters from SageMaker Studio with their specific customizations. Once available, users connect to these EMR clusters from their notebooks using secure authentication. For more information, see Launch an Amazon EMR cluster from Studio and Configure IAM runtime roles for Amazon EMR cluster access in Studio.
Key capabilities and advantages of this setup include:
- Self-service provisioning – Service Catalog simplifies the creation of Amazon EMR clusters by letting the ADA platform team register CloudFormation templates as products in a Service Catalog portfolio. This portfolio is accessible from SageMaker Studio, from which users can provision EMR clusters on their own through a user-friendly interface.
- Consistent governance – Service Catalog allows for central management of commonly deployed EMR cluster configurations, helping to achieve consistent governance and compliance.
- Customization – The CloudFormation templates used within Service Catalog allow the ADA platform team to specify configurable parameters for users to provide custom inputs to tailor their EMR clusters.
- Access control – Access to templates is managed through IAM roles, ensuring that users only have access to the appropriate EMR cluster configurations.
Managing workloads with Amazon SageMaker Pipelines
Once users transition from experimenting with notebooks to organizing their ML workflows into pipelines, SageMaker Pipelines provides a streamlined solution for creating machine learning workflows that can be executed and scheduled within a sandbox account. SageMaker Pipelines is a workflow service that allows users to create, manage and automate machine learning tasks. The ADA platform team provides two main blueprints to enable two main use cases in a governed way:
- Data processing pipelines – This comprises a SageMaker Pipeline with a SageMaker Processing or Amazon EMR step to process data.
- Machine learning model building pipelines – This comprises a SageMaker Pipeline with a SageMaker Training step to build a model and store it to Amazon Simple Storage Service (Amazon S3). ADA plans to adopt SageMaker Model Registry to connect the model training and registry steps as part of a larger model governance framework.
With the above patterns, BBVA migrated over 5,000 pipelines from their on-premises platform to AWS (ADA). Note that when the SageMaker Pipelines with an Amazon EMR step are promoted to production, they’re transformed into standalone Amazon EMR jobs. Refer to Part 2 for additional information on how ADA manages thousands of EMR jobs at scale.
FinOps for data analytics and machine learning
BBVA created a FinOps practice focused on data (FinDataOps) for cost control and visibility across ADA. This new practice works in different areas:
- Budgeting and billing model – Definition, implementation and communication of the budgeting and invoicing model to the different business units.
- Cost visibility – Enable cost observability tools that give users visibility of the economic impact of their actions on ADA and for tracking the cost incurred per area and user, to optimize resource utilization and costs across the organization.
- Governance model – Introduce new ways of working, best practices, roles and responsibilities within the organization.
- Cost protection – Design and implementation of guardrails to avoid errors in using resources that lead to an undesired cost increase (e.g. definition of alert thresholds).
FinDataOps guardrails for sandbox accounts
The FinDataOps team has implemented over 60 guardrails across all sandbox accounts. There are two types of guardrails:
- Preventive – These guardrails are enabled when an AWS service is first deployed or configured as part of the sandbox account creation. For instance, the size of Amazon EMR clusters and SageMaker notebook instances depends on the type of SageMaker Studio user. Also, sandbox accounts come with a set of Athena workgroups available to control query access and costs.
- Detective – These guardrails trigger when the AWS service is being used. For example, the maximum number of SageMaker Pipelines and EMR clusters in a sandbox along with the maximum run time for an EMR job.
As an example, Figure 2 illustrates the process behind one of the detective guardrails that limits the maximum execution time per Athena query for a given Athena workgroup.
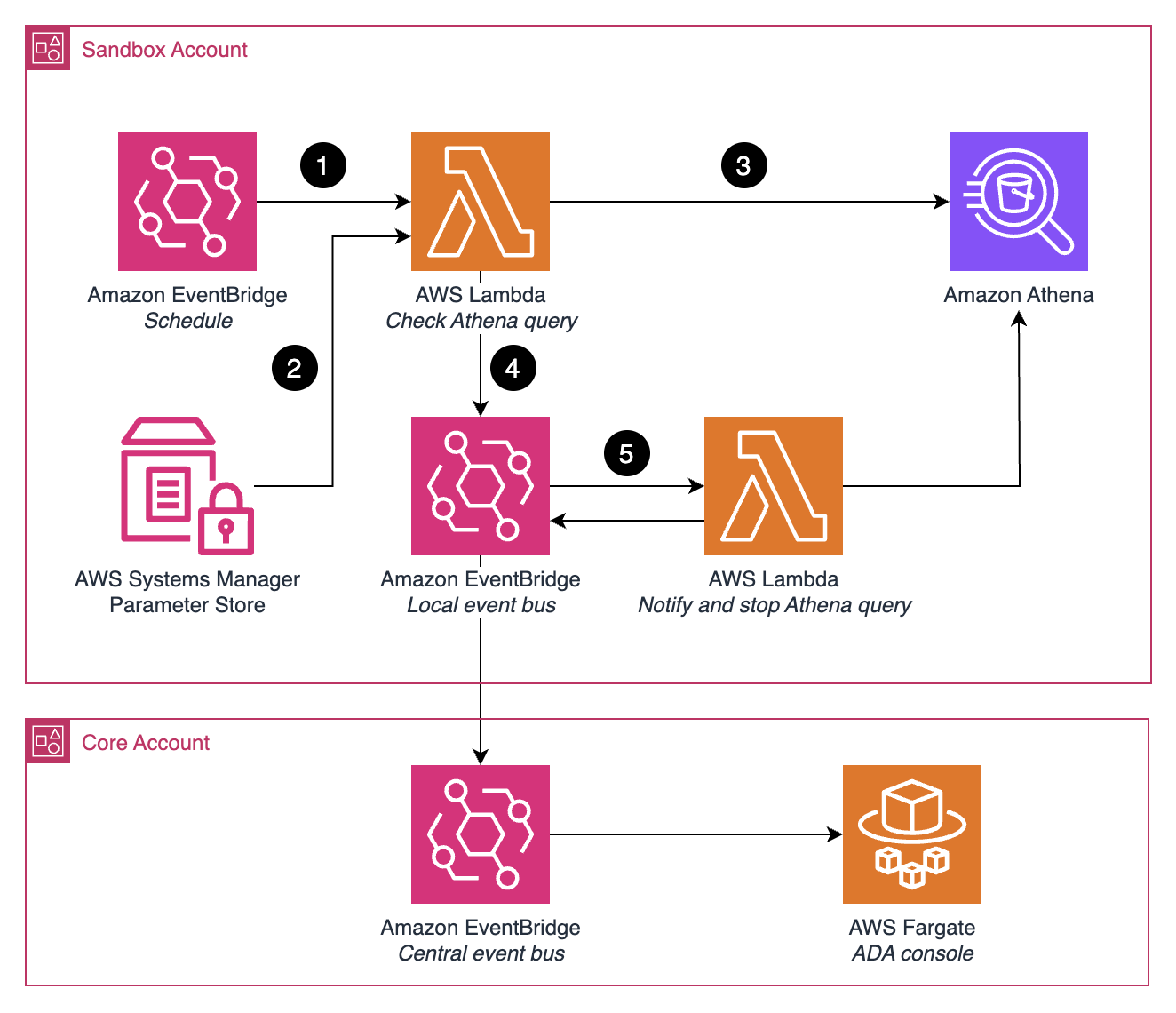
Figure 2 – Amazon EventBridge-based workflow to monitor Athena queries
- An Amazon EventBridge Scheduler schedule analyzes the running Athena queries for a given Athena workgroup.
- The schedule triggers an AWS Lambda function that will read a parameter from AWS Systems Manager Parameter Store that contains the maximum query execution time allowed for the given Athena workgroup.
- The Lambda function will check if there are Athena queries in RUNNING or QUEUED status whose execution time is at 75%, 95% or over the maximum time allowed.
- The identified queries will be part of an event sent to an EventBridge event bus in the sandbox account.
- This event bus has as target a Lambda function that will publish the identified queries to the ADA console. This function will also stop the queries whose execution time is over the maximum time allowed.
Sandbox accounts budget control
All sandbox accounts are created with a specific budget assigned to their corresponding business units using AWS Cost and Usage Reports (CUR). Once the sandbox is active and sandbox users start working, the consumed budget is visible from the ADA console. If this budget exceeds 200%, ADA shuts down the sandbox automatically to find and analyze the deviation root cause.
The following diagram illustrates how budget management works in sandbox accounts.

Managing the operational availability of sandbox accounts at scale
To align with business requirements and optimize resource utilization and costs, sandbox accounts are only available during a specific period. ADA defines the period by days in a week (e.g., 5 days) and hours in a day (e.g., 12 hours). This lets the business units establish a schedule for when sandbox users can work and control the availability of AWS services.
Most sandbox accounts are configured to be available Monday through Friday during regular business hours. To accomplish this, BBVA deployed an AWS Service Catalog product across all sandbox accounts. Service Catalog lets organizations create, organize and govern a curated catalog of AWS resources. In this case, the Service Catalog product starts and stops the key AWS services in sandbox accounts based on the configured schedule.
Figure 3 shows the workflows for managing the availability of sandbox accounts.
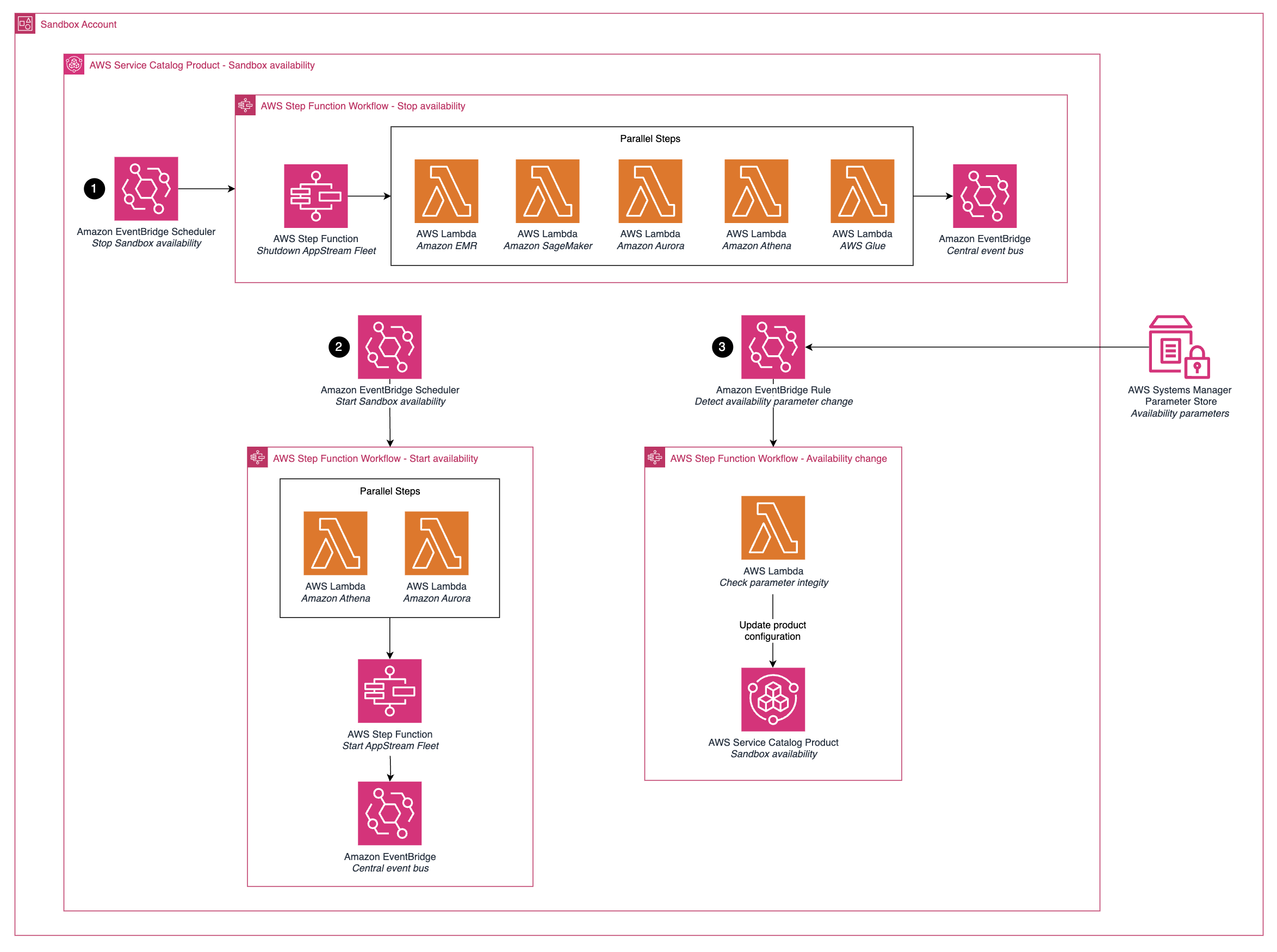
Figure 3 – Sandbox availability workflow with Step Functions and Lambda integrations
The deployed service manages sandbox availability through three main workflows:
- The first workflow handles stopping sandbox resources, initiating with the prevention of user access to the analytics environment. It then disables various core data and analytics services, finally updating the central console on the sandbox’s status.
- The second workflow manages starting sandbox availability. It first starts the necessary data and analytics services to ensure they are ready before restoring user access to the environment. Finally, it updates the central console about the sandbox’s active status.
- The third workflow permits dynamic adjustments to the sandbox’s availability parameters, such as schedule and time zone. These parameters can be updated from the central console, which triggers this workflow. It validates the integrity of the new parameters and updates the configuration as needed. This enables platform administrators to configure sandbox availability at scale with ease.
Conclusion
By providing a secure, governed, reliable, and cost-optimized environment with sandbox accounts, ADA empowers data scientists and data engineers to innovate and accelerate their analytics initiatives. From interactive exploration to automated pipelines, the platform offers a comprehensive set of tools and guardrails that enable users to leverage the full potential of AWS services while adhering to BBVA’s security and compliance standards.
ADA facilitates consistent data access and sharing, enhancing collaboration and decision-making. With a modern toolset based on a managed architecture running on demand, ADA minimizes compute requirements, reduces costs, and supports sustainable machine learning development and operations. Its flexible design ensures adaptability to new AWS products and services, enabling BBVA to meet evolving use case demands and compliance requirements while remaining at the forefront of technological innovation.
This migration has led to a 94% reduction in the time required for analytical work environments to be available for end users on ADA. The platform has successfully migrated to AWS over 250 sandbox accounts and 5,000 analytical assets across seven countries on two continents.
To learn more about ADA, look at the rest of this six-part series on the strategic collaboration between BBVA and AWS:
- Part 1: BBVA: Building a multi-region, multi-country global Data Platform at scale
- Part 2: How BBVA processes a global data lake using AWS Glue and Amazon EMR
- Part 3: How BBVA built a global analytics and machine learning platform on AWS
- Part 4: Building a Multi-Layer Security Strategy for BBVA’s Global Data Platform on AWS
- Part 5: BBVA’s unified console: Key to successful global platform deployment
- Part 6: Effective sunset of the legacy data platform in BBVA: the migration methodology