AWS for Industries
Generative AI enabled Medical Coding on AWS
Medical coding is a vital, yet intricate, process in the healthcare industry—it ensures accurate reimbursement for services rendered and is necessary for compliance with regulatory guidelines. However, traditional manual coding methods can be time-consuming, error-prone, and resource-intensive, leading to inefficiencies, bad outcomes, and potential revenue losses. With healthcare organizations processing thousands of patient encounters daily, these challenges can significantly impact financial performance, patient experience, and operational efficiency.
Provider organizations typically lose approx. $210,000 annually due to under-billing, with a study showing only 9.3 percent of eligible Medicare patients being billed for Transitional Care Management, despite 43.3 percent of the patients being qualified. Common revenue leaks stem from underestimating evaluation and management (E/M) levels and missed preventive service billing. A systematic review in BMC Primary Care (2023) confirms a substantial gap between smoking cessation service delivery and reimbursement claims. Evidence shows that while most eligible patients receive cessation services, only about one-third of these services result in submitted claims for reimbursement. This represents a significant missed revenue opportunity for healthcare providers.
How generative AI can help
Foundation models, such as large language models (LLMs), are transforming this landscape by offering unprecedented capabilities to analyze clinical documentation, interpret medical terminology, and assign appropriate codes with greater speed and accuracy than conventional methods. Amazon Web Services (AWS) provides a comprehensive suite of services that enable healthcare organizations to implement AI-powered solutions (including medical coding solutions) that can adapt to the complexity of modern healthcare environments.
We’ll explore how AWS services like Amazon Bedrock, AWS HealthLake, and AWS HealthScribe can be leveraged to build a complete medical coding solution that improves coding accuracy. These services can also accelerate the revenue cycle, reduce administrative burden on clinicians, and help verify regulatory compliance. We’ll demonstrate a practical architecture that healthcare organizations, of any size, can implement to modernize their medical coding operations.
Challenges
The process of medical coding is inherently complex, requiring a deep understanding of clinical terminology, anatomy, and medical procedures. Each patient encounter, whether routine or specialized, must be meticulously translated into a precise set of codes that accurately reflect the services provided and the patient’s diagnosis and past clinical history. The AMA, and other governing bodies, have established intricate guidelines and rules for coding, which must be strictly adhered to for compliance and reimbursement purposes.
Consider a patient presenting with chest pain, a straightforward scenario. However, the nuances involved in accurately coding this encounter are vast. Is the chest pain acute or chronic? Is it related to an underlying condition, such as coronary artery disease or gastroesophageal reflux disease (GERD)? Were diagnostic tests performed, and what were the results? These details, along with the patient’s medical history, medications, and any procedures or treatments administered, must be carefully documented, and coded precisely.
The complexity compounds when patients present with multiple conditions. A diabetic patient with heart disease and depression—an increasingly common trilogy in modern medicine—requires a sophisticated understanding of how these conditions interact and influence billing hierarchies. The AMA coding guidelines recognize ~68,000 diagnosis codes and ~8,000 procedure codes, with countless permutations between them.
Moreover, the regulatory environment adds another layer of complexity. Medicare’s ever-evolving rules, commercial payers’ varying requirements, and the constant threat of audits create a perfect storm of administrative burden. A single miscoded claim can trigger a cascade of investigations, potentially leading to accusations of fraud—even when the error was entirely unintentional.
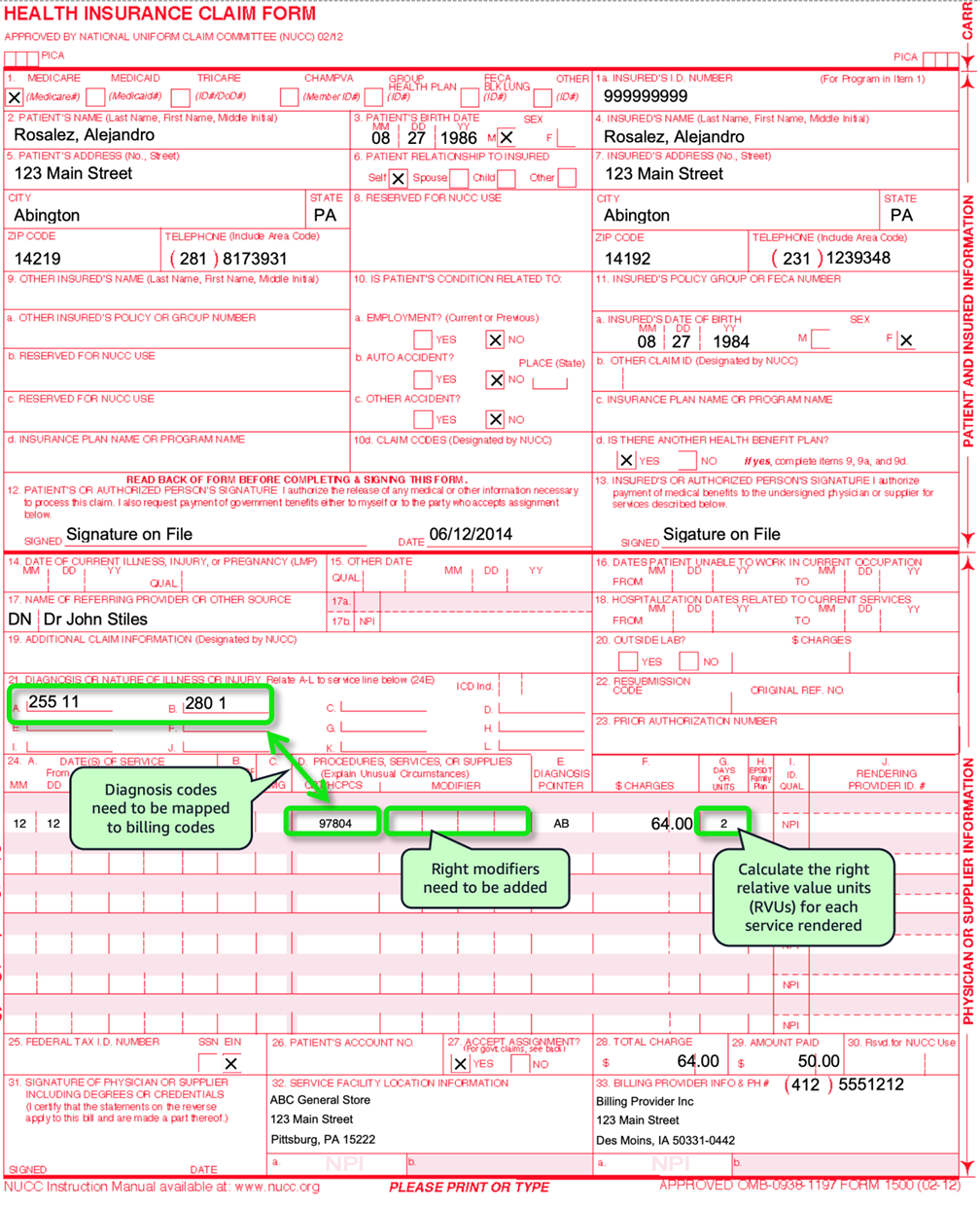 Figure 1 – an example CMS 1500 form, a paper claim form for billing healthcare services
Figure 1 – an example CMS 1500 form, a paper claim form for billing healthcare services
Capturing these nuances falls on the shoulders of healthcare providers, who must meticulously document their clinical observations, findings, and treatment plans in the patient’s subjective, objective, assessment, and plan (SOAP) notes and electronic health record (EHR). Obtaining a comprehensive patient history, including past medical conditions, surgeries, and family history, is crucial for accurate coding and ensuring continuity of care. However, this process can be time-consuming and prone to errors, especially in high-volume healthcare settings.
Once the clinical encounter is documented, the challenge of coding begins—deriving the correct diagnosis codes (ICD-10) codes from the unstructured progress note, then mapping the diagnosis codes to the appropriate billing (CPT/HCPCS) codes, and apply critical modifiers as necessary. This information must then be accurately transcribed onto a CMS-1500 claim form (in ANSI ASC X12N 837P format) as shown in Figure 1. This ensures that every detail, from the patient’s demographics to the specific procedure codes, is correctly represented. Any discrepancies or omissions in this process can lead to rejections, delayed reimbursements, or even compliance violations.
Solution overview
Automated medical coding with LLMs on AWS involves two main workflows: the inference workflow and an optional training workflow.
Inference workflow
The inference workflow comes into play when a clinical encounter is completed, and the need for medical coding arises. This workflow orchestrates the seamless integration of various AWS services, leveraging a trained LLM model to generate accurate and compliant medical codes based on the patient’s clinical data and encounter details.
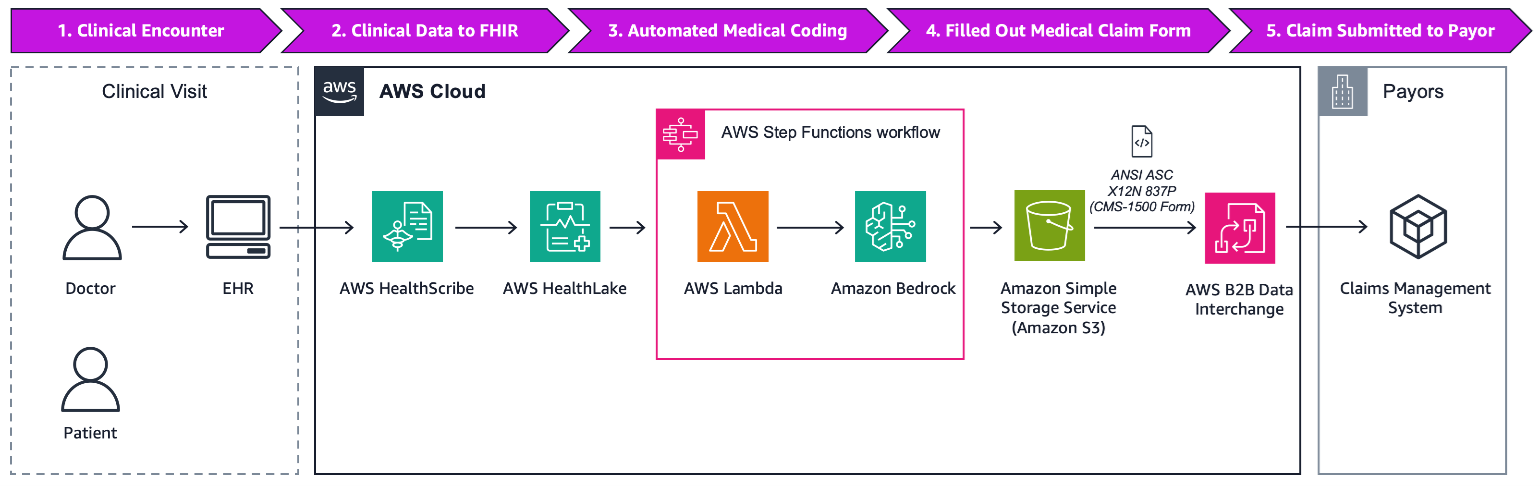 Figure 2 – Complete inference architecture for AI-enabled medical coding on AWS
Figure 2 – Complete inference architecture for AI-enabled medical coding on AWS
The inference workflow comes into play when a clinical encounter is completed, and medical coding is required. Here is how it unfolds:
- Clinical encounter completed: A patient’s clinical encounter is documented in the EHR system, capturing all relevant details using AWS HealthScribe. Details include SOAP notes and structured data fields.
- Clinical Data to fast healthcare interoperability resources (FHIR) data standard: The EHR backend sends the clinical data in the HL7 FHIR format to AWS HealthLake, where it is persisted for further processing.
- Automated medical coding: An AWS Step Functions workflow involving AWS Lambda and an Amazon Bedrock inference endpoint is triggered. The workflow first queries AWS HealthLake to retrieve the patient’s comprehensive clinical history and details about the EHR encounter. The information then passes to the Amazon Bedrock inference endpoint, where the desired LLM model is activated in a zero-shot prompt. Amazon Bedrock allows access to a wide range of multiple LLMs and other foundation models through simple API calls—enabling users to choose and change between the models that are best for each use case. The model produces a completed CMS-1500 form in ANSI ASC X12N 837P format, which is saved to Amazon Simple Storage Service (Amazon S3), and the S3 object URI is sent back to asynchronously.
- Human review (optional): Medical coding specialists can review and validate the AI-generated codes before final submission, ensuring accuracy and compliance with coding guidelines. This human-in-the-loop validation can be configured based on organizational requirements and confidence thresholds.
- Completed medical claims form submission: Retrieves the completed ANSI ASC X12N 837P form from Amazon S3. The claim is then submitted to the Payor using a clearing house or AWS B2B Data Interchange.
Training workflow (optional, recommended)
Although pre-trained LLMs today show good promise, Healthcare Provider organizations who need to optimize performance and accuracy can leverage a prompt engineering (few-shot) and fine-tuning workflow. By leveraging their organization’s data, users can improve performance and accuracy to meet their unique needs, Providers with data science/machine learning expertise can achieve significantly better results.
The training workflow focuses on further fine-tuning an LLM, tailoring it specifically for the task of medical coding. This process involves acquiring and curating your organizational datasets of real-world clinical data, coding guidelines, and historical claims data. This serves as the foundation for training the model to understand the nuances of medical coding accurately. This fine-tuned model can be married with prompt engineering techniques, such as few-shot prompting.
 Figure 3 – Training architecture for AI-enabled medical coding on AWS
Figure 3 – Training architecture for AI-enabled medical coding on AWS
The training workflow focuses on developing and fine-tuning the LLM model for accurate medical coding. The process involves several steps:
- Data acquisition: The first step is to gather and prepare the necessary data for training the model. This includes real-world training data sets consisting of structured clinical data (HL7 FHIR), unstructured clinical data (SOAP notes), past claims submissions (837), and remittance data (835). Additionally, referential data sets (such as the AMA Coding Guidelines) are required.
- Model development: With the data acquired, the next step is to develop and train the LLM model. This involves ingesting the real-world training data sets and the AMA Coding Guidelines into Amazon S3. Then, using Amazon Bedrock, an LLM (such as Amazon Nova) is selected due to its ability to be fine-tuned, and a fine-tuning job is set up with the training data from Amazon S3. Amazon Bedrock Knowledge Bases are also set up with the AMA Coding Guidelines to provide managed retrieval-augmented generation (RAG). After training the model, it undergoes rigorous evaluation, validation, and quality assurance leveraging Amazon Bedrock model evaluation capabilities. Based on the results, the model may be retrained for further improvement before being provisioned in Amazon Bedrock for inference, along with leveraging prompt engineering techniques to improve model performance.
- Inference endpoint setup: Once the model is trained and validated, an inference endpoint is set up and integrated into the workflow. The model is then fine-tuned based on real-world usage data, providing continuous improvement and adaptation to changing coding requirements.
Solution demonstration
The true power of AI-enabled medical coding is best demonstrated through a real-world scenario. We’ll walk through a primary care use case, starting from a progress note captured by the physician during an encounter.
82-year-old female with progressive memory problems over 5-10 years, frequently forgets conversations and asks same questions repeatedly. Mother had dementia with auditory/visual hallucinations. Patient denies head trauma, strokes, dizziness, numbness, or speech/visual/muscular issues. Unable to draw clock face. No recent labs or imaging. Referred to neurology for dementia evaluation. Ordered TSH, B12, and started Aricept 5 mg qhs.
As shown in Figure 4, the solution uses AWS HealthScribe to perform entity detection, mapping out relationships between various conditions, medications and tests discussed during the encounter.
Figure 4 – AI based entity mapping of progress note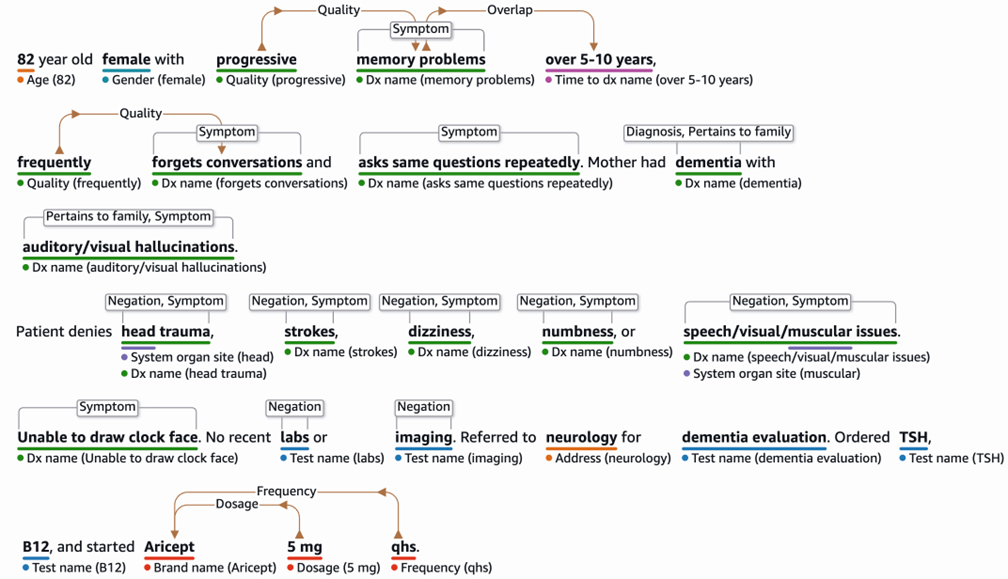 Figure 4 – AI based entity mapping of progress note
Figure 4 – AI based entity mapping of progress note
This analysis helps the solution craft a comprehensive SOAP note, which is then fed into the LLM with a request to generate a CMS-1500 form in ANSI ASC X12N 837P format.
Following is a demonstration video, showcasing a complete workflow, from patient encounter all the way to generating a CMS-1500 form in ANSI ASC X12N 837P format with proper ICD-10 to CPT/HCPCS code mappings.
Demonstration video 
Figure 5 – AWS generative AI Medical Bill Coding demonstration
Results
The implementation of AI-enabled medical coding demonstrates a successful generation of the CMS-1500 form in ANSI ASC X12N 837P format with appropriate CPT/HCPCS codes and mapped with the corresponding ICD-10 codes from the clinical encounter. Although the LLM model demonstrated good accuracy (Figure 6), we highly recommend using the afore mentioned techniques that can further improve outputs. Model fine-tuning using historical clinical data and CMS-1500 form in ANSI ASC X12N 837P format mappings has been shown to improve code selection precision. Additionally, expanding the collection of few-shot examples can strengthen the model’s pattern recognition capabilities across diverse clinical scenarios. The integration of Amazon Bedrock Knowledge Bases with referential data provides an additional layer of validation against established coding standards.
 Figure 6 – AI generated CMS-1500 form (zero-shot prompting used)
Figure 6 – AI generated CMS-1500 form (zero-shot prompting used)
To confirm optimal performance and continuous improvement, a human-in-the-loop verification process should be implemented. This oversight mechanism validates the recommended codes and also generates valuable feedback data. The collected feedback can be systematically incorporated into the RAG system, creating a self-improving cycle that progressively enhances the LLM’s ability to generate more accurate CPT codes. This combination of automated processing and human verification strikes an effective balance between efficiency and accuracy in medical coding operations.
Conclusion
The implementation of AI-enabled medical coding using LLMs on AWS has the potential to transform revenue cycle management operations in healthcare. By leveraging advanced natural language processing capabilities, healthcare providers can streamline the medical coding process, verifying accurate and compliant billing, while reducing the administrative burden on clinical staff.
This solution presents a significant opportunity for health systems to optimize their revenue cycle management operations, prevent under-billing and over-billing scenarios, maximize reimbursements, and maintain compliance with regulatory guidelines. Additionally, the cost efficiencies achieved through AI-enabled medical coding can be reinvested into enhancing patient experiences, upgrading facilities, or investing in innovative medical technologies, benefiting both organizations and patients.
Reach out to an AWS Representative to learn more about the underlying technology and start your revenue cycle management journey today.