AWS for Industries
Generative AI Adoption in Automotive and Manufacturing: Key Technology Considerations
The automotive and manufacturing industries are undergoing another digital transformation, this time powered by artificial intelligence. From engineering workbenches to smart factories, Generative AI (Gen AI) is transforming how vehicles are designed, manufactured, and maintained. However, implementing production-grade AI applications requires more than just selecting the right models – it demands robust architecture, enterprise-grade security, and operational excellence to succeed at scale.
This blog post will examine five essential technology dimensions for building Gen AI applications on AWS: Architecture, Security, Performance, Operations, and Cost. These considerations are essential to lay the right foundation for deploying Gen AI in critical environments such as design studios, smart factories, and digital supply chains.
1. Architecture: Building the Right Foundation for Gen AI
AWS offers a broad set of services and components that can be composed into common architectural patterns for Generative AI which can be tailored to meet the needs of use cases in the automotive and manufacturing industry.
- Prompt Engineering
Prompt engineering is the crafting of precise inputs to guide foundation models (large pre-trained models trained on vast datasets) such as LLMs (large language models). It is a common starting point for automotive teams using Gen AI to generate assembly steps, summarize manuals, or support diagnostics. This approach suits early-stage, low-risk experiments within labs or engineering workbenches. It requires minimal setup, relying on pre-trained models through services like Amazon Bedrock or Amazon SageMaker JumpStart. Applications using prompt engineering typically expose simple REST endpoints for integration into internal tools, enabling fast iteration without the complexity of training or fine-tuning. - Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) combines language models with external knowledge sources to generate more accurate responses to user queries. It works by retrieving relevant domain-specific data, like engineering specs, CAD files, or service manuals and including them in the model’s context at the time of query. This helps reduce hallucinations and helps ensure the output is grounded in real documents. Document embeddings are typically stored in services like Amazon OpenSearch and fetched dynamically during inference. RAG is especially effective for critical use cases such as design checks, compliance reviews, or diagnostic support, where precision and traceability are key. - Model Fine-Tuning
Fine-tuning is the process of using labeled data to further train a foundation model to improve its performance on specific tasks. In the automotive context, these tasks can include detecting manufacturing defects, interpreting sensor data, analyzing chassis stress, or forecasting supply chain issues. Fine-tuning requires domain-specific datasets and typically uses Amazon SageMaker training jobs and techniques such as Low-Rank Adaptation (LoRA) for parameter-efficient tuning. Fine-tuned models can be deployed using SageMaker endpoints for low-latency inference. While more resource-heavy (compute intensive and requires large volume of high-quality, labeled data specific to target task) than prompt engineering or RAG, fine-tuning delivers higher accuracy and better results for targeted use cases. - Agentic Systems
Agentic systems use an advanced architectural pattern to enable Gen AI applications to act as domain-aware assistants capable of reasoning and making decisions. In the automotive context, this could take the form of engineering agents that understand homologation requirements, recommend design changes based on regulations, or assist manufacturing teams in resolving complex issues on the production floor. These systems often involve orchestration frameworks like LangChain, memory management with Amazon DynamoDB, and multi-step workflows managed through AWS Step Functions and Amazon EventBridge. The focus here is not just generating output but managing tasks autonomously with defined goals, tool access, and feedback loops. Safety, explainability, and guardrails become essential in this setup, especially when agentic systems influence decisions in critical environments. - Model Re-Training/Custom Industry models
Model retraining means building or extensively modifying a model using proprietary data to achieve even greater customization. For OEMs or tier-1 suppliers with strong Gen AI capabilities, this offers the most control to develop industry-specific models using data like telemetry, test outputs, or sensor streams. Models re-trained on an OEM / vendor dataset can remain proprietary to the OEM and be licensed within the OEM’s ecosystem. Retraining supports complex use cases such as detecting anomaly patterns, resolving EV charging issues, predicting part failures, optimizing energy efficiency, or automating quality assurance workflows. Training is typically performed on GPU-optimized infrastructure using Amazon SageMaker or on AI accelerators such as AWS Trainium, to handle the high compute demands efficiently. While resource-intensive, this approach can create deeply integrated and highly specialized AI systems that are not achievable through fine-tuning alone.
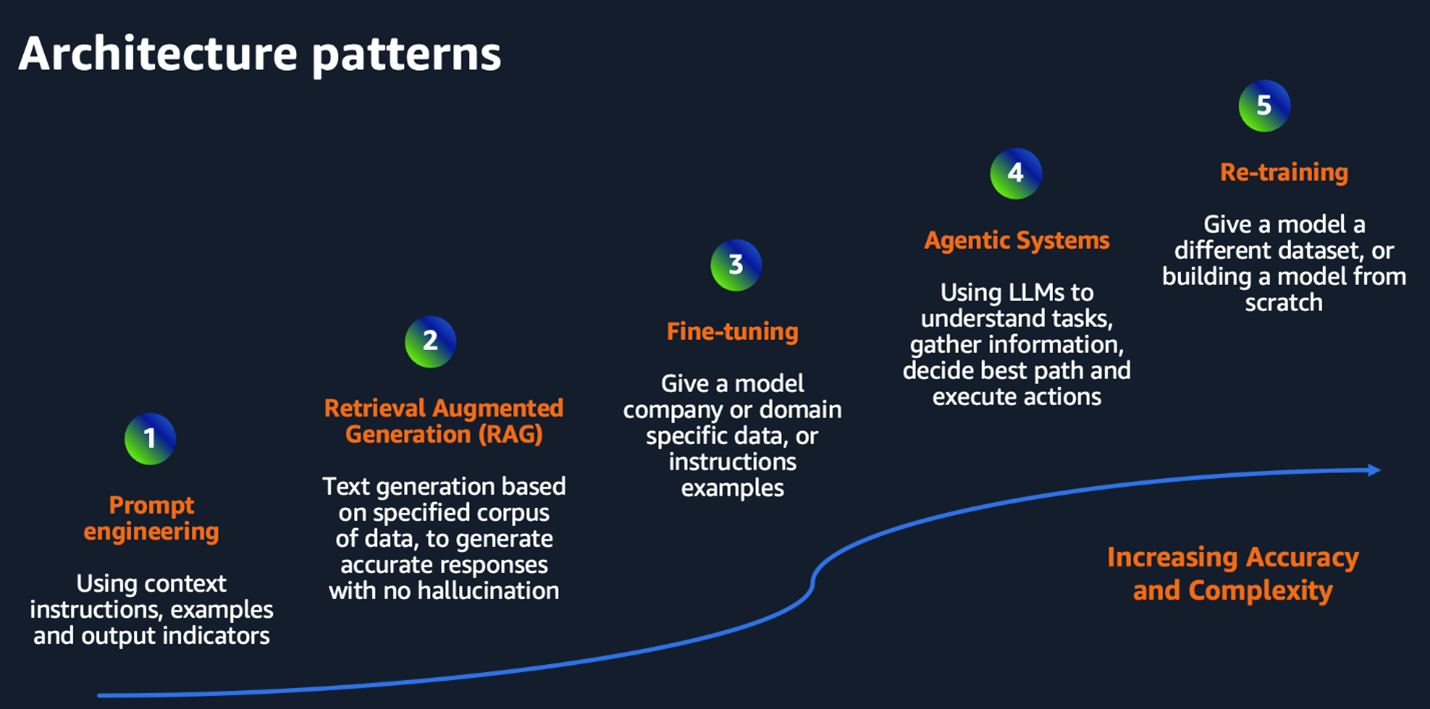
Figure 2: Architecture patterns to build right foundation for Gen AI
Here is a summarized view of use cases and architecture pattern:
| Use Case | Architecture Pattern |
| Simple conversation | LLM + Prompt engineering |
| Chatbots | LLM + Retrieval system (RAG) |
| Domain specific learning | LLM + Domain knowledge (Fine Tuning) |
| Complex workflows | LLM + Agents (Agentic) |
| Custom foundation models | Build LLM from scratch (Re-Training) |
Engineer’s Tip: Most use cases begin with RAG to link Gen AI with product data, then evolve toward fine-tuning and agent-based approaches as organizational confidence and data maturity grow.
2. Security: Ensuring Data Privacy and Trust by Design
Automotive applications often process confidential vehicle designs, telematics data, regulatory documentation, and customers’ personal identifying information (PII), requiring strict controls around data access, handling, and model behavior. AWS provides a comprehensive set of capabilities to help customers secure every layer of the Gen AI stack, from infrastructure to prompt-level output.
Security Principles for Gen AI on AWS
- Data Isolation: Gen AI workloads on Amazon Bedrock and Amazon SageMaker can be deployed entirely within a Amazon Virtual Private Cloud (VPC), helping ensure full network isolation. When using Amazon Bedrock, the easiest way to build and scale generative AI applications with foundation models, your prompts and responses never leave your VPC. By default, AWS will not use your data to train or fine-tune foundation models.
- Encryption: All data, including prompts, embeddings, responses, and underlying training inputs, is encrypted by default using AWS Key Management Service (KMS). You can choose between AWS-managed keys or bring your own keys (BYOK) for additional control.
- Role-Based Access & Security Controls: Use AWS Identity and Access Management (IAM) roles, VPC boundaries, and fine-grained access controls to ensure only authorized users and services can interact with Gen AI components and data. These controls may be implemented, for example, when dealing with sensitive data such as CAD files, vehicle engineering data, or supplier contracts.
- Compliance and Certifications: AWS maintains numerous industry certifications, including ISO 27001, SOC 1/2/3, GDPR, HIPAA, and FedRAMP, making it suitable for Gen AI applications that operate in security-critical domains or manage PII-regulated customer data. For automotive use cases, this helps support customer compliance with data protection regulations like GDPR in the EU or CCPA in the U.S.
- Data Residency and Region Control: Data used for model inference or fine-tuning can be constrained to a specific AWS region, ensuring compliance with residency policies. This is critical when working with vehicle data from geographically segmented fleets or local homologation requirements.
Advanced Responsible AI Controls
Beyond infrastructure-level protections, AWS helps enable responsible deployment of Gen AI applications through built-in safety mechanisms, content filters, and customizable safeguards:
- Prompt & Response Filtering: Amazon Bedrock supports content moderation filters with Amazon Bedrock Guardrails to block unsafe, toxic, or brand-sensitive outputs. This is particularly valuable in customer-facing Gen AI apps (e.g., dealer chatbots or diagnostic assistants) where tone, accuracy, and appropriateness must be tightly controlled.
- Factual Grounding & Hallucination Filtering: RAG with enterprise data stores can be used to mitigate hallucinated responses. Amazon Bedrock also supports output filtering and confidence scoring, ensuring responses are aligned with trusted sources—such as approved service manuals or validated engineering datasets.
- PII Detection and Redaction: When processing sensitive inputs like warranty claims, customer feedback, or diagnostic logs, AWS helps support PII redaction through integrated tools such as Amazon Comprehend or custom filters in AWS Lambda. These can strip names, VINs, or addresses before sending content to a foundation model, as described in this blog.
- Custom Guardrails and Policy Enforcement: You can define application guardrails with Amazon Bedrock Guardrails, such as prohibited terms (e.g., “recall,” “cyber breach”) or contextual limitations (e.g., avoiding speculative answers about safety features). AWS Verified Permissions, AWS CloudTrail, and Amazon GuardDuty can be used to help enforce access control, audit actions, and detect anomalous usage patterns across your Gen AI pipelines.
Best Practice: Start by enabling security defaults in Bedrock or SageMaker and extend with fine-grained IAM, logging, and custom filters using AWS Verified Permissions or Amazon GuardDuty.
3. Performance: Matching Intelligence with Throughput
Performance in Gen AI isn’t just about low latency, it’s about maintaining responsiveness, consistency, and cost-efficiency across varying workloads. In the automotive context, this can mean anything from real-time virtual assistant responses on the factory floor to concurrent prompt evaluations across 3D simulations. AWS helps customers meet their required level of performance through optimized infrastructure, intelligent model selection, and advanced inference techniques:
- Model Distillation: Through model distillation, large foundation models are distilled into smaller, task-specific models. These “student” models inherit the intelligence of their larger counterparts but operate with lower latency and cost because they are smaller, require fewer computations, and can be optimized for lightweight deployment. For example, a distilled model could be fine-tuned to detect welding defects from sensor streams or translate technical documents in supplier interactions, without needing the full compute footprint of a general-purpose model.
- Throughput Optimization: Provisioned throughput in Amazon Bedrock allows you to reserve tokens per minute (TPM) and requests per minute (RPM) for high-volume environments ensuring reliable performance for high-volume tasks like batch inference on historical vehicle data or factory logs.
Engineering Insight: Match your model’s complexity to the use case. For example, use advanced models for reasoning-based decisions in design validation and distilled models for repetitive tasks like parts classification or logistics ETA predictions.
4. Operations: Industrial-Grade MLOps for Gen AI
Operationalizing Gen AI in the automotive industry requires more than model deployment. It calls for robust Foundation Model Operations (FMOps) integrated with traditional MLOps practices. FMOps is the discipline of managing, monitoring, and governing foundation models across their lifecycle in production environments. From managing prompt workflows in the design studio to supporting digital twin updates on the production line, the lifecycle of Gen AI models must be governed.
- Experimentation: Tools like Amazon SageMaker Studio and Amazon Bedrock playgrounds are designed to allow engineers, data scientists, and product teams to test and refine prompts or workflows collaboratively. These tools support prompt versioning, sandboxed evaluation, and visualization of model outputs, all within the context of enterprise policy boundaries.
- Model & Data Governance: Tag, version, and audit all model artifacts. If Gen AI is used to summarize homologation documentation or generate maintenance plans, those outputs must be traceable and meet internal customer SOPs. AWS provides services like SageMaker Model Registry, Amazon DataZone, and AWS Glue Data Catalog to manage model metadata and data lineage.
- Human-in-the-Loop (HITL): For quality assurance, involve engineers and operators to review and validate Gen AI recommendations before deployment, especially when outputs impact production tuning, compliance documentation, or safety-critical decisions.
Factory Insight: Govern, version, monitor, and always keep a human in the loop, where safety and accuracy matter most.
5. Cost: Tuning for Value Without Throttling
Gen AI workloads can consume considerable compute resources, especially those supporting high-volume or real-time use cases in the automotive industry. Managing this cost without sacrificing capability is important, particularly in a margin-sensitive industry where operational efficiency is paramount.
- On-Demand Inference: For low-volume or prototyping scenarios, such as service part recommendation bots or internal knowledge tools, on-demand inference is the most cost-effective. It allows usage-based billing with minimal overhead, ideal for experimentation or departmental pilots.
- Provisioned Throughput: For steady-state production workloads, such as real-time assistance in product lifecycle management (PLM) or generating work instructions for digital twins, provisioned throughput (reserving a fixed amount of model processing capacity in advance) in Bedrock ensures consistent performance with predictable pricing. This model is suitable when prompt volumes and concurrency levels are known in advance.
- Trainium and Inferentia: AWS Trainium and AWS Inferentia provide cost-effective, high-performance computing for Gen AI workloads. Use AWS Trainium for training large models on simulation data, design records, and vehicle telemetry. Deploy AWS Inferentia for low-latency, low-cost inference in production environments, such as factory-floor assistants or service automation bots.
- Batch Inference: Batch inference runs many inputs through a model at once on a set schedule, cutting costs and enabling large-scale tasks like warranty analysis, sensor data labeling, or service log insights.
- Multi-model Cost Strategy: Mix and match model types. Use high-performing models (e.g., Claude or Mistral) where needed, and lower-cost distilled or fine-tuned versions elsewhere.
CFO Insight: Cost control in Gen AI starts with intelligent workload planning, treat token budgets like fuel budgets for test fleets: optimize routes, avoid idling, and batch when possible.
Data: The Key Enabler to Deriving Value from Gen AI
While Gen AI draws attention with its outputs, the true value driver lies in your enterprise data, which governs the structure, availability, quality, and governance of Gen AI applications. Automotive Gen AI applications remain applications at their core; they rely on real-time inputs, contextual datasets, and transactional systems just like any digital product. A modern data strategy starts with building and managing data lakes and operational data stores. Services like AWS Glue, Amazon Kinesis, Amazon Redshift, and Amazon S3 support batch and real-time data ingestion, while services like Amazon SageMaker Data Wrangler or Amazon EMR support transformation and preparation for model readiness.
To support this, several layers of data integration are needed, including:
- Data sourcing, whether through batch ingestion or real-time streaming;
- Pipelines that adapt to changing data inputs; and
- Transformations and preprocessing steps that make data suitable for GenAI models.
Conclusion
In automotive and manufacturing, Gen AI isn’t just a trend, it’s a productivity accelerator, design enabler, and digital transformation force multiplier. But without attention to architecture, security, performance, operations, and cost, even the most advanced models can stall in real-world environments.
With AWS, you can move from pilot to production more confidently, designing more secure, performant, and scalable Gen AI applications that span from vehicle R&D to assembly lines and global supply chains. Engineers and leaders do not just pick a model—they must orchestrate people, process, and AI. AWS can help you make that orchestration more efficient, responsible, and ready for scale. For further guidance, visit the AWS for automotive and Manufacturing pages, or contact your AWS team today.