AWS Database Blog
Building resilient applications: design patterns for handling database outages
Database outages, whether planned or unexpected, pose significant challenges to applications. Planned outages for maintenance can be scheduled but still impact users. Unplanned outages are more disruptive and can happen at critical times. Even the most robust and resilient databases will inevitably experience outages, making application resiliency a critical consideration in modern system design. In this post, we explore design patterns for building resilient applications that gracefully handle database outages. These strategies protect against outages and ensure smooth degradation during database issues, helping maintain user experience and business continuity. By implementing these patterns, you can create more reliable applications that function even when database problems occur. To demonstrate each design pattern’s effectiveness, we analyze a sample e-commerce application with intensive database operations. We show how these patterns improve application resilience, particularly during high-traffic periods. These patterns can be implemented independently or combined to create robust, fault-tolerant applications.
Queue-based load leveling
The queue-based load leveling pattern introduces a message queue between your application and database to handle failures and high-load situations gracefully. Instead of writing directly to the database, the application sends operations to a queue where they wait to be processed at a controlled rate. This acts like a buffer zone. When the database is healthy, a consumer service processes these queued messages and performs the database operations. During database outages or performance issues, the queue safely holds the pending operations until recovery. This approach prevents data loss and maintains application responsiveness, because requests are quickly acknowledged after being added to the queue, rather than waiting for database operations to complete. The following architecture diagram shows how this design pattern is implemented.

Figure 1: Queue based load leveling
In the sample e-commerce platform, you can implement Queue-based load leveling using Amazon Simple Queue Service (Amazon SQS). Amazon SQS is a fully managed message queuing service that enables decoupling and scaling of microservices, distributed systems, and serverless applications. Amazon SQS can significantly improve order processing during high-traffic periods. Instead of writing orders directly to the database, the system sends them to an Amazon SQS queue. This approach offers several benefits:
- Surge Protection: During flash sales when order volume spikes, the queue acts as a buffer, preventing database overload.
- Consistent Performance: By processing orders from the queue at a steady rate, the database workload remains consistent, avoiding performance degradation during peak hours.
- Improved Reliability: If the database experiences issues, orders are safely stored in the queue until the system recovers, ensuring no orders are lost.
- Enhanced User Experience: Customers receive immediate order confirmations as requests are quickly added to the queue, even if backend processing is delayed.
- Scalability: The platform can easily scale queue processing capacity to handle varying loads without directly impacting the database.
Some of the key considerations when implementing Queue-based load leveling are:
- Queue-based load leveling trades real-time processing for system stability. Consider the impact of asynchronous processing on data consistency when designing the system.
- Queue configuration focuses on message size limits, queue length monitoring, and storage capacity planning. Key settings include retention periods and visibility timeouts to ensure message durability.
- Error handling requires Dead Letter Queues (DLQ) implementation with defined retry policies and monitoring for failed message recovery.
- Message processing must choose between First-In-First-Out (FIFO) or standard queue selection based on ordering requirements, using message group IDs for sequential processing needs.
- Data integrity relies on effective deduplication through either content-based or ID-based strategies, with proper interval configuration.
- Performance tuning involves optimizing batch sizes, consumer scaling, and choosing between long or short polling methods based on latency needs.
For a reference solution, see Guidance for Designing Resilient Applications with Amazon Aurora and Amazon RDS Proxy . You can also refer to the blog Modernized Database Queuing using Amazon SQS and AWS Services; which shows how a message queuing architecture improves database availability.
Cache-aside pattern
The cache-aside pattern, also known as lazy loading, uses a cache to improve database resilience and application performance. When requesting data, the application first checks the cache. If the data exists (cache hit), it’s returned immediately. If not (cache miss), the application retrieves it from the database, stores it in the cache for future use, and then returns it. The image below shows how the design pattern works.
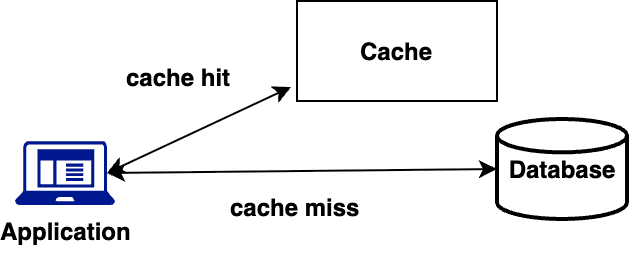
Figure 2: Cache-aside pattern
The Cache-aside pattern in the sample e-commerce platform example can be implemented using Amazon ElastiCache. Amazon ElastiCache is a fully managed, in-memory caching service that supports Valkey, Memcached and Redis OSS engines. The following are a few benefits of implementing this design pattern:
- Improved Performance: By caching frequently accessed product data in Amazon ElastiCache, the platform can deliver microsecond response times for catalog browsing, even during high-traffic periods.
- Reduced Database Load: Caching minimizes direct database queries for popular items, alleviating pressure on the database during flash sales.
- Enhanced Scalability: The ElastiCache cluster can handle a large portion of read requests, allowing the platform to manage higher traffic without overwhelming the database.
- Increased Availability: If the database experiences issues, the cache can continue serving product information, maintaining a functional catalog browsing experience.
Here are key considerations when implementing the Cache-aside pattern:
- Data Consistency Strategy – When implementing the Cache-aside pattern, carefully consider how to maintain synchronization between your cache and database. This includes determining acceptable data staleness thresholds, implementing robust cache invalidation mechanisms, and setting appropriate time to live (TTL) values that balance data freshness with system performance. Your strategy should align with your application’s specific requirements for data accuracy and real-time updates.
- Performance Requirements – System performance goals should guide your cache implementation decisions. Consider strategies for handling cold starts when the cache is empty, possibly implementing proactive cache warming to minimize impact on users.
Need more information, check out these resources:
Command Query Responsibility Segregation
Command Query Responsibility Segregation (CQRS) tackles database resilience by treating read and write operations as separate concerns, each with its own optimization strategy. In our e-commerce platform example, the product catalog needs frequent reads but occasional updates, while order processing requires immediate, consistent writes. Instead of using a single database model for all operations, CQRS uses specialized models for each type. This separation becomes particularly valuable during database failures. The write path typically uses a primary database for commands. The read path uses read replicas to serve queries, allowing the system to continue serving read requests even when the write path is impaired. The logical architecture diagram below shows how the read and write operations are treated as separate concerns.
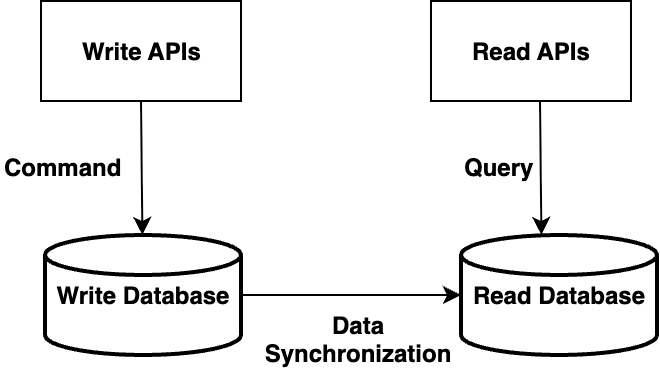
Figure 3: Command Query responsibility Segregation
In the sample e-commerce example, one of the AWS database services you can use is Amazon Aurora. Amazon Aurora is a fully managed relational database engine that’s compatible with MySQL and PostgreSQL. The write path can utilize Amazon Aurora for critical order processing and financial transactions due to high performance, high availability, and automatic scaling capabilities. For the read path, Aurora Read Replicas can efficiently handle high volumes of order history queries. Amazon Aurora manages replication through its unique storage-based architecture. Aurora’s storage architecture maintains multiple physical copies of data in the DB cluster volume. All Aurora Replicas access this shared cluster volume as a single logical volume, providing high availability with minimal replica lag. Additionally, Amazon RDS also supports read replicas for other database engines including MySQL, PostgreSQL, MariaDB, Oracle, and SQL Server, offering similar benefits of distributing read workloads and improving application performance through read scaling. You can implement the CQRS pattern by using various combinations of databases. You can refer to the guidance on the CQRS pattern showing how Amazon DynamoDB and Amazon Aurora can be used to implement the CQRS pattern.
Here are key considerations when implementing the CQRS pattern:
- Eventual consistency challenges- CQRS’s inherent eventual consistency model means the read database may temporarily lag behind the write database. Users might encounter stale data while the system synchronizes, requiring careful handling of user expectations and business requirements
- Schema coordination across read and write models – For homogeneous database replication like Aurora Replicas and DynamoDB Global tables, read and write models maintain identical schemas, simplifying synchronization. However, in heterogeneous database scenarios (for example, using Amazon Aurora PostgreSQL for write operations and Amazon OpenSearch Service for read operations), CQRS implementations require careful schema coordination between read and write models, as different database types may have varying data structures. Teams must ensure command model updates properly translate across different database schemas while maintaining data consistency.
Need more information, check out these links:
- CQRS pattern
- Decompose monoliths into microservices by using CQRS and event sourcing
- Modernize legacy database using event sourcing and CQRS with AWS DMS
Circuit breaker pattern
The Circuit breaker pattern helps protect your application during database failures by automatically detecting and preventing cascading failures. Think of it as a safety switch for your database connections. When your application detects a certain number of database errors, for example connection time out errors, too many connections errors within a specified time window (for example, 5 failures in 10 seconds), it opens the circuit and stops attempting database operations temporarily. Instead of waiting for database timeouts, the application immediately returns a predefined fallback response or serves cached data.
After a specified time period, the circuit breaker enters a ‘half-open’ state, allowing a limited number of test requests to pass through. If these requests succeed, the circuit closes and normal operations resume. If failures continue, the circuit returns to the open state. This gradual recovery mechanism prevents overwhelming a recovering database with sudden traffic and helps verify system health before fully restoring operations. The below diagram shows how the circuit state changes depending on failure threshold.
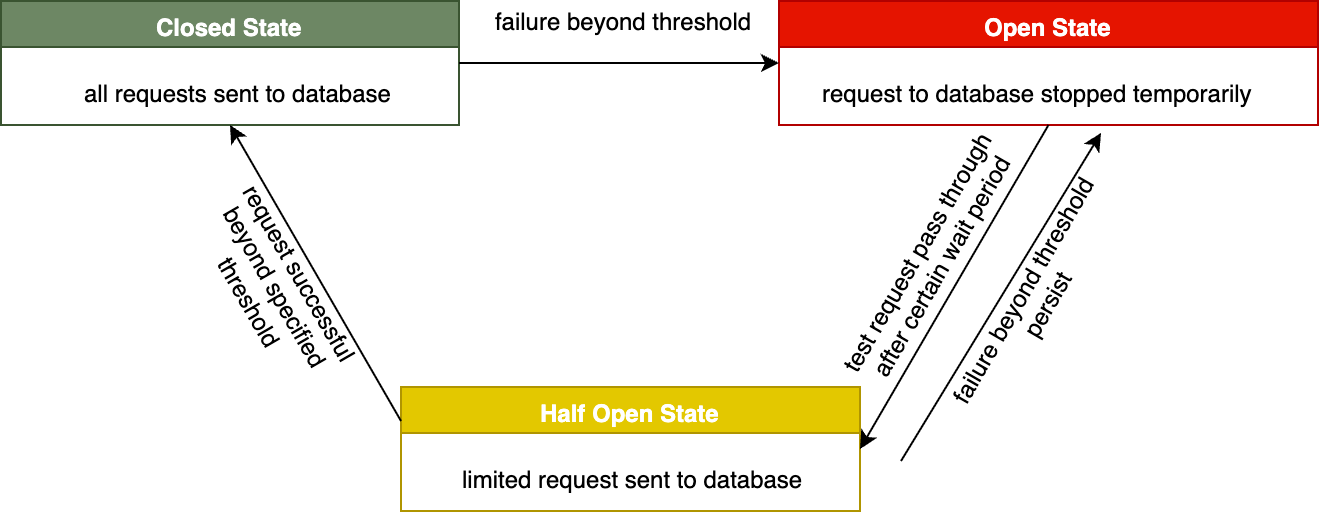
Figure 4: Circuit Breaker pattern
You can implement the Circuit breaker pattern using multiple AWS services.For reference, here are some implementation examples
- Implementing the circuit breaker pattern using AWS Step Functions and Amazon DynamoDB
- Implementing the circuit-breaker pattern with Lambda extensions and DynamoDB
The circuit breaker pattern can significantly improve resiliency of the sample e-commerce application in the following ways:
- During flash sales when traffic surges to higher-than-normal levels, if database errors occur beyond a set threshold, the circuit breaker prevents cascading failures by quickly stopping further requests.
- For the catalog of products, it can serve cached data or fallback responses, ensuring customers can still browse even if the database is not responding.
- In processing daily orders, if a database issue arises, the pattern can redirect write operations to a queue, preventing order loss.
- The half-open state allows gradual recovery, testing the connection before fully reopening database connections to all requests after an incident.
- By preventing repeated failed attempts, it reduces strain on the database, potentially allowing faster recovery during peak times.
Here are key considerations when implementing the circuit breaker pattern:
- The Failure Threshold is a critical parameter that determines when the circuit breaker should trip. It’s important to set appropriate thresholds based on the nature of the service and its expected behavior.
- The Reset Timer is a key component that determines how long the circuit breaker remains in the Open state before allowing a retry. Implementing a configurable reset timer allows for adjustment based on the specific needs of different services
Retry with backoff pattern
When your application encounters database errors, immediate retries can worsen the situation. The retry with backoff pattern introduces smart retry logic for handling transient issues like network problems or resource constraints.Instead of immediate retries, the pattern implements exponential backoff – increasingly longer delays between attempts (such as 1second, 2 second, 4second). Additionally, it adds ‘jitter’ – a random delay to each retry interval – preventing multiple failed requests from retrying simultaneously and causing another surge.
The AWS SDK automatically implements these retry mechanisms with configurable backoff strategies and timeout values, making it easier for developers to handle retries reliably.
For an e-commerce platform example, the retry with backoff pattern helps manage database operations during traffic spikes. When processing an unexpected surge in daily orders, any failed database operations are retried using gradually increasing time delays. This prevents multiple failed operations from retrying at the same time, which could overwhelm the system. The diagram below shows how the patters work between two services.
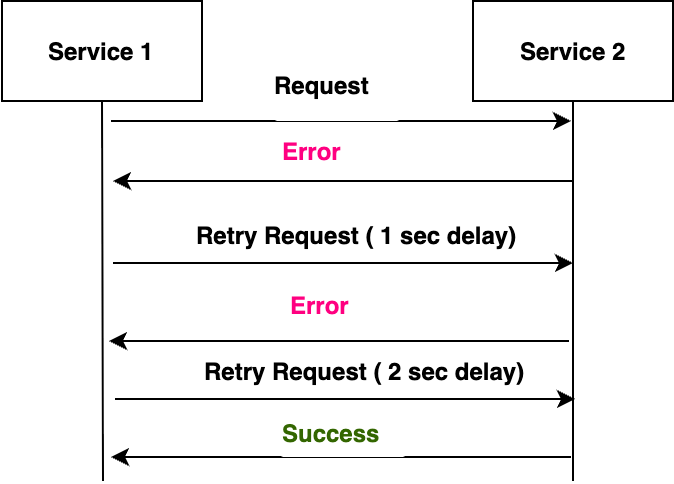
Figure 5: Retry and backoff pattern
Here are key considerations when implementing the retry and backoff pattern:
- Error Classification is important when implementing Retry with Backoff. It requires identifying truly transient errors suitable for retries, such as network timeouts and temporary service outages. Errors like authentication failures should not be retried and fail immediately to avoid wasting resources and masking underlying issues
- AWS SDK provides multiple retry modes to handle retry behavior that includes settings regarding how the SDKs attempt to recover from failures resulting from requests made to AWS services
Need more information, check out these links:
Bulkhead pattern
Similar to how ships have watertight compartments (bulkheads) that prevent a single hull breach from sinking the entire vessel, this pattern divides application resources into isolated pools, helping to ensure that a failure in one area doesn’t bring down your entire application.
AWS offers multiple approaches to implement the bulkhead pattern for improved system resilience. In the relational database domain , at the connection level, Amazon RDS Proxy can create separate connection pools for different workloads, allowing critical and non-critical operations to use isolated resources. For read/write separation, Amazon Aurora custom endpoints can route different types of workloads to specific database instances. Physical isolation can be achieved through multiple availability zones deployments, where workloads are distributed across different availability zones using Amazon Route 53 routing policies. Database sharding provides horizontal partitioning, where data can be split across multiple database instances based on specific criteria (like customer ID, geography, or time periods), ensuring that issues in one shard don’t impact others. Amazon Aurora PostgreSQL Limitless takes this concept further by automatically managing sharding operations and providing seamless horizontal scaling across multiple database instances, eliminating the need for manual shard management while maintaining consistent performance. In the NoSQL domain, AWS provides several options for implementing bulkhead pattern: Amazon DynamoDB offers workload isolation through separate tables, Global Tables for multi-region deployment, Amazon DocumentDB (with MongoDB compatibility) enables isolation through read replicas; Amazon Neptune supports read replicas across multiple Availability Zones; and Amazon ElastiCache for Redis OSS/Valkey allows read replicas through replication groups.
For complete isolation, separate database instances can be dedicated to critical services while other instances handle non-critical operations.For instance, in the sample ecommerce application, order processing might use a dedicated connection pool, while product browsing uses a separate pool, ensuring that checkout functionality remains available even if product catalog queries become slow or fail. This pattern effectively prevents resource exhaustion in one part of the system from affecting others, improving overall application resilience. The below diagram shows how the connection pools for each service is isolated to avoid cascading failures using this pattern.
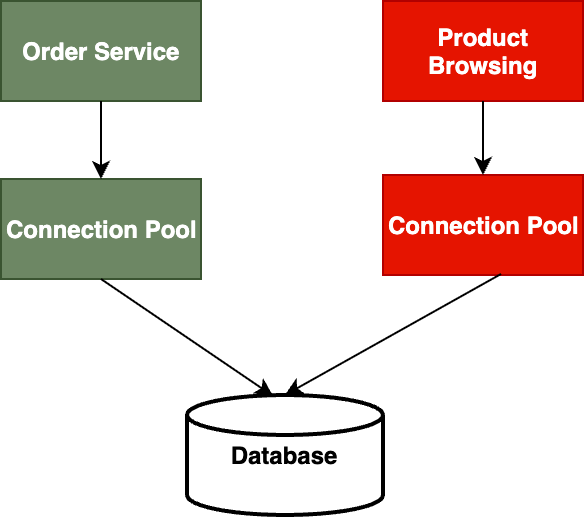
Figure 6: Bulkhead Pattern
Design Pattern in action
Let’s wrap up by looking at the ecommerce application as an example to see how some of these design patterns complement each other to improve application resilience. We will be using four design patterns in this example:
- Command Query Responsibility Segregation
- Queue-based load leveling pattern
- Cache Aside Pattern
- Retry with backoff pattern
The following diagram shows a sample e-commerce application implemented using AWS services.
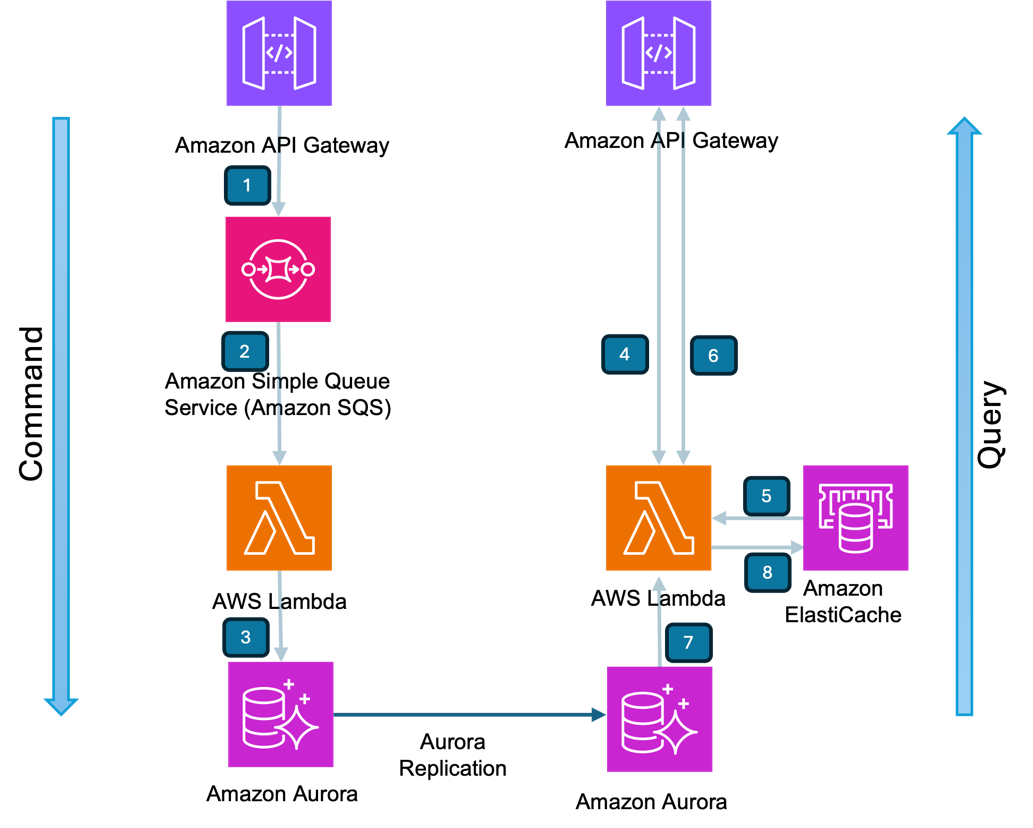
Figure 7: Sample e-commerce application
Consider a modern e-commerce platform where CQRS (Command Query Responsibility Segregation) separates the order processing and inventory management (commands) from product browsing and search operations (queries). Let’s walk through the request flow.
Command Side:
The command side receives the request and writes the order details to the database by implementing Queue-based load leveling pattern.
- When a customer places an order, Amazon API Gateway receives the request and sends the order details to Amazon SQS, implementing the Queue-based load leveling pattern. For more information on integrating Amazon API Gateway with Amazon SQS, refer to the guidance Integrate Amazon API Gateway with Amazon SQS to handle asynchronous REST APIs
- AWS Lambda functions as processing layer reads the order details from Amazon SQS and writes them to the Amazon Aurora. Retry and backoff pattern is implemented in the lambda code using AWS SDK
- Order details are committed to Amazon Aurora Database by the AWS Lambda function
Query Side:
The query side, serving product listings, search results implement a Cache-aside pattern using Amazon ElastiCache.
- Customer’s request for product detail is received by Amazon API Gateway
- AWS Lambda function checks Amazon ElastiCache for the product information. If the product information exists (Cache hit), the data is served back to the Amazon API Gateway directly from cache
- Customer makes another request for searching the product catalog which is received by Amazon API gateway
- AWS Lambda function checks Amazon ElastiCache for the product catalog information. If the information does not exist (Cache miss), the product catalog is fetched from Amazon Aurora Database and the response is sent back to Amazon API gateway
- AWS Lambda also adds the product catalog to Amazon ElastiCache cluster asynchronously for serving future request directly from cache
Retry Pattern
The system implements retry patterns in lambda function through AWS SDK for both command and query operations when interacting with the Aurora database. For command operations, if AWS Lambda cannot connect to the Aurora database, it first attempts retries using exponential backoff with jitter to prevent simultaneous database connection attempts. During the retrial attempts, the message is maintained in AWS SQS queue for data persistence. For query operations, when Lambda cannot establish a database connection, it follows a similar retry pattern with exponential backoff and jitter. However, in scenarios where there’s a cache miss and the Aurora database connection fails despite set number of retries, the Lambda function returns an error response to the client, requiring the client to implement their error handling mechanism.
Conclusion
Building truly resilient applications requires combining multiple design patterns. These patterns work best when used together to create robust systems. Remember, there’s no one-size-fits-all solution for resilience. Choose patterns based on your specific needs, balancing reliability, performance, and complexity.
To deepen your understanding of building resilient architectures, we encourage you to review the AWS Well-Architected Framework, particularly the Reliability Pillar. This comprehensive guide provides detailed best practices and design principles for building reliable systems in the cloud.