AWS Database Blog
AWS DMS validation: A custom serverless architecture
AWS Database Migration Service (AWS DMS) is a managed service that helps support database migrations to AWS with minimal downtime. It supports both homogeneous migrations (like Oracle to Oracle) and heterogeneous migrations (like Oracle to PostgreSQL) while keeping the source database fully operational during the migration process. In this post, we walk you through how to build a custom AWS DMS data validation solution with AWS serverless services.
Challenges with data validation
AWS DMS customers might choose not to use the data validation feature provided by the AWS DMS service due to the time it takes to complete validation after a load, a large dataset transfer or a data reload, where business requires rapid availability of data in the target environment. As a result, you might opt to perform validation manually or use a single pass full load only validation, which requires additional effort and time.
We identified this issue with an enterprise customer’s doing monthly manual validation. By the time customer discovered and reported data mismatches, the associated DMS logs had expired. This created two problems: the customer missed the window for accurate data validation impacting business and faced significant challenges in troubleshooting the root cause.
To address this challenge, we built a customized solution architecture. This architecture aims to automate the data validation process after the AWS DMS task has completed or encountered an error (in the case of full load migrations) or when that there are no active writes/changes on the source, such as during change data capture (CDC).
In this post, we show you how to implement event-driven data validation for AWS DMS. This post provides architectural guidance only. While some code snippets are included, they are for reference purposes and may need to be adapted for your specific implementation needs.
With our custom architecture approach, you can benefit from automated data validation without compromising the migration performance. It offers flexibility in data validation, ranging from simple record count comparisons between source and target databases to complex, multi-table queries for business-specific data points. The architecture automatically delivers validation results through email or other chosen communication channels, alleviating the need to log in to the AWS DMS console. This can help monitor data quality through notifications.
This custom validation approach works alongside DMS’s native validation features, not as a replacement. It provides the flexibility to automate validation checks based on your specific data quality requirements.
Solution overview
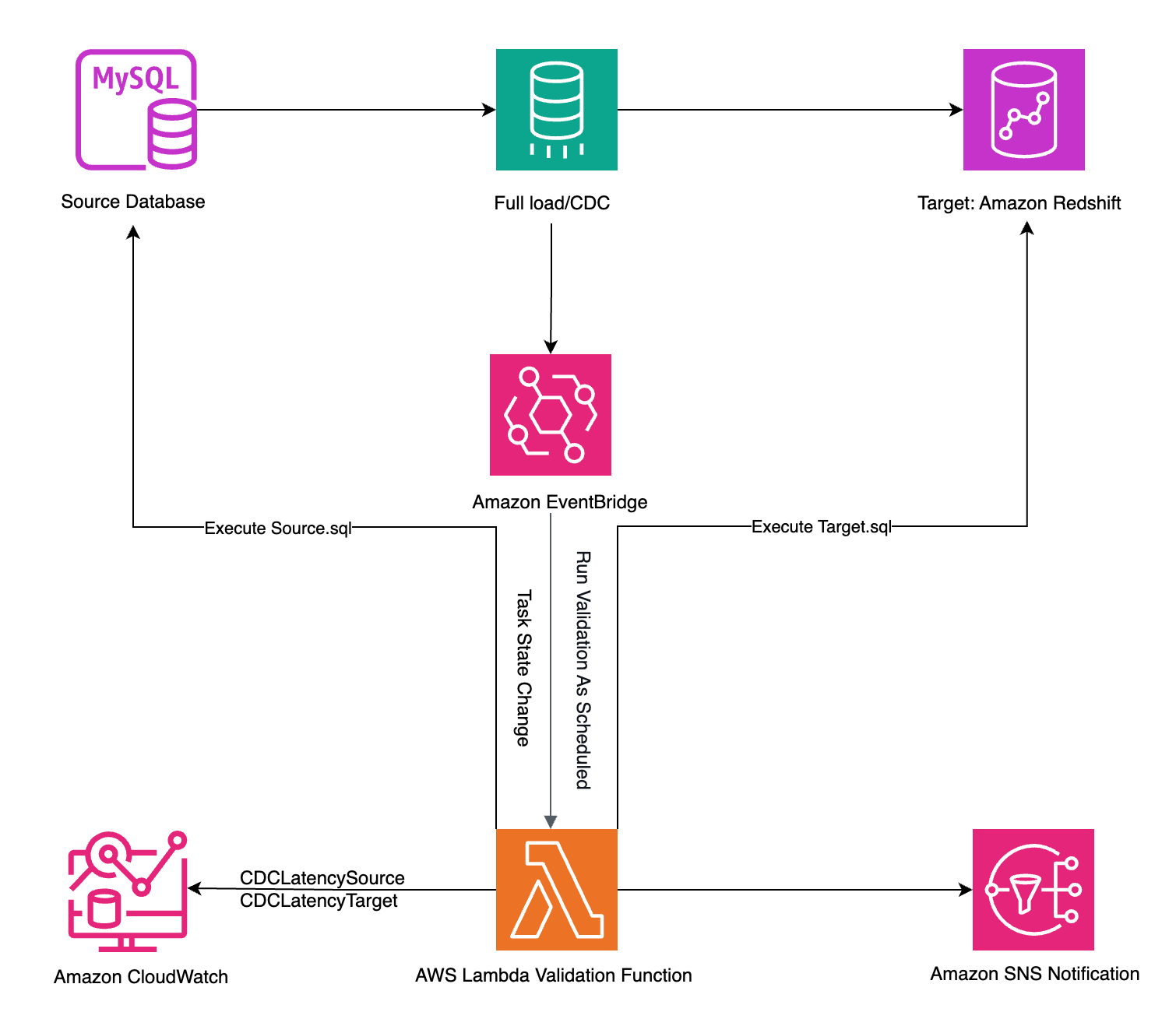
The architecture uses AWS serverless computing and an event-driven mechanism to validate data in two ways:
- Automatically, when an AWS DMS task status changes (for example, when
REPLICATION_TASK_STOPPEDis triggered) - On a scheduled basis, as defined in Amazon EventBridge
In both cases, AWS Lambda functions perform the data validation, and the results are automatically sent using email notifications with Amazon Simple Notification Service (Amazon SNS).
The following diagram illustrates the solution architecture.
Prerequisites
Before you get started, you must complete the following prerequisites:
- Create an AWS DMS replication instance.
- Create AWS DMS source and target endpoints connecting to the source and target database, respectively.
- Create an AWS DMS task, associate endpoints with the task, and enable Amazon CloudWatch logs.
- Make sure you have the necessary permissions using an AWS Identity and Access Management (IAM) role to access required AWS services.
- To implement this solution, you should have knowledge of Python programming language to write and customize AWS Lambda functions.
Create a Lambda function
To implement custom data validation, start with creating a Lambda function and add files to do specific jobs. This is to keep the solution modular. The following screenshot shows the various custom modules.

The architecture should have the following structure, which can be extended based on your needs:
- dms_task_details – Manages AWS DMS task information and gets the AWS DMS task source and target endpoint.
- dms_task_event – Retrieves AWS DMS task details from the event emitted from the AWS DMS full load task.
- dms_task_latency – Processes AWS DMS task latency metrics:
- Retrieves AWS DMS latency metrics from Amazon CloudWatch
- Monitors both CDC source and target latencies
- lambda_function – Serves as an automated validation system for AWS DMS replication tasks. It performs the following functions:
- AWS DMS event monitoring:
- Captures and processes AWS DMS task events, specifically monitoring for
REPLICATION_TASK_STOPPEDevents. - When a task stops, it triggers detailed event processing through the
dms_task_event_detailsmethod of dms_task_event module.
- Captures and processes AWS DMS task events, specifically monitoring for
- Replication data validation:
- Monitors AWS DMS replication latency metrics for both source and target.
- Implements parallel processing to efficiently compare source and target data counts.
- Includes latency threshold checks (under 5 seconds) before performing validations.
- Parallel data validation:
- Uses ThreadPoolExecutor for concurrent execution. This helps simultaneously run the query on the source and target databases.
- Optimizes performance by running source and target queries in parallel.
- AWS DMS event monitoring:
- notification – Handles alert notifications using Amazon SNS:
- Implements automated notifications for validation results.
- Reports discrepancies between source and target data counts.
- Provides detailed error messaging for troubleshooting.
- requirements.txt – Lists all dependencies the application needs. In this case, it specifies PyMySQL version 1.0.2, which is the library that allows the Lambda function to communicate with MySQL databases. To connect a Lambda function to MySQL, you must add a layer containing the PyMySQL package to the function.
- source_db – Manages source database operations. Implement code that connects to the AWS DMS source database using credentials stored in AWS Secrets Manager, then executes the queries defined in source.sql.
- source.sql – Contains SQL queries that retrieve data from the source database that will be compared against the target database to verify successful replication.
- target_details – Handles target database operations. Implement code that connects to the AWS DMS target database using credentials stored in AWS Secrets Manager, then executes the queries defined in
target.sqlfile. - target.sql – Contains SQL queries that retrieve data from the target database that will be compared against the source database to verify successful replication.
In the case of full load
An AWS DMS status change event for REPLICATION_TASK_STOPPED is received by the Lambda validation function in the lambda_handler function event parameter.
- Get the eventtype from the event parameter for the REPLICATION_TASK_STOPPED event to get the task from the event resources. refer the following code:
- Use the Boto3 library to create an AWS DMS client, then get source and target details from the
describe_replication_tasksmethod response:
Automation to run a query and send results
The next step is to write source and target specific queries that the Lambda validation function will execute on respective databases and compare the results. You can use Amazon SNS to send the results to the user in an email.You can refer to the following code snippet to get the data from source and target and compare the results. Following code used simple count queries in source.sql and target.sql to compare source and target data, but you can extend the queries to multiple tables and customize the logic to define success or failure.
In the case of CDC
The Lambda validation function will be triggered on schedule as defined in EventBridge. You need to capture the CDCLatencySource and CDCLatencyTarget AWS DMS task latency metrics.
- Create a CloudWatch client using Boto3:
- Use the following code to retrieve metrics from CloudWatch:
- To get the source and target latency metrics, refer the following code with the CloudWatch client:
- Compare the latency to 5 seconds (you can change it based on your requirement) and Lambda validation function run the parallel query on both the source and target databases. The following code uses simple count queries in source.sql and target.sql to compare source and target data, but you can extend the queries to multiple tables and customize the logic to define success or failure.
When the Lambda validation function receives both query results, it compares them and sends a notification using Amazon SNS. The following is a sample notification received in an email:
Create an EventBridge rule
You also need to configure an EventBridge rule to capture the AWS DMS events and then run the scheduler to invoke the Lambda validation function.
- On the EventBridge console, create a rule with the configurations shown in the following JSON. This rule will be used for a full load scenario.
- Set the target of the rule to the Lambda function, as shown in the following screenshot.
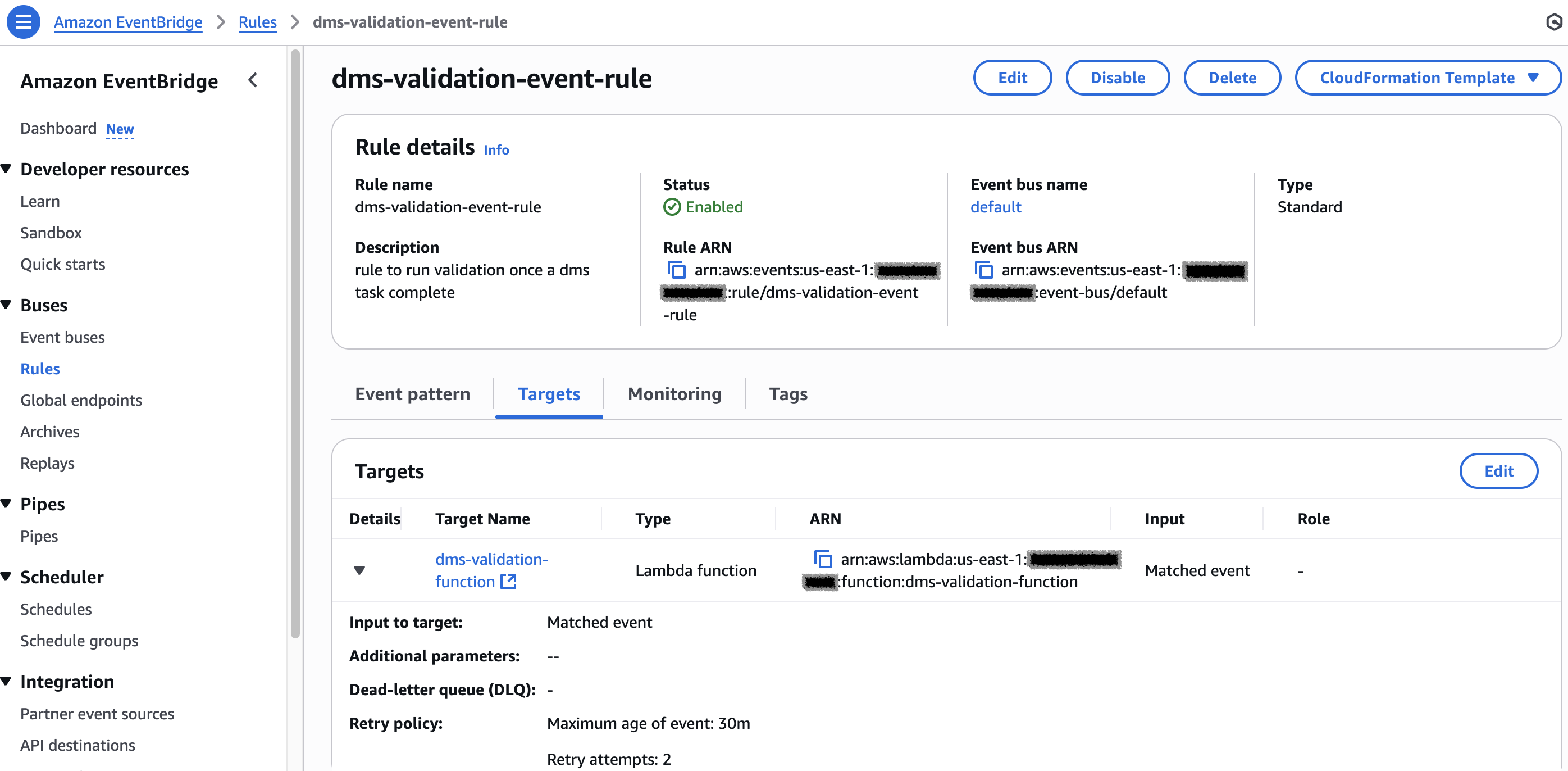
- For CDC, create a scheduler to run on your specific schedule and set the target to the Lambda validation function.
Technical Scope and Limitations
Before implementing this solution, it’s important to understand its technical boundaries and constraints. This section outlines what the architecture can accomplish and its limitations, helping you determine if it meets your specific use case requirements.
- Database Support: Our solution demonstrates MySQL-to-Redshift migration scenarios, but you can extend it to work with other databases. Just be sure to validate collation differences, check character set compatibility, and test thoroughly in your environment.
- LOB Handling: The solution doesn’t support Large Object (LOB) validation – consider excluding these columns from your validation scope
- Queries: If query executions take more than 15 min, replace Lambda with Amazon Elastic Container Service (Amazon ECS) or AWS Fargate.
Cost Consideration
While this solution offers automated validation capabilities, costs can be managed effectively by adjusting the frequency of validation checks, setting appropriate log retention periods in CloudWatch, and optimizing Lambda function execution time. Remember to delete all resources after implementing this architecture to prevent incurring unnecessary costs.
Summary
In this post, we showed you how this architecture automates the AWS DMS data validation process, reducing manual effort. The architecture uses serverless computing and event-driven architectures to dynamically trigger data validation routines, addressing concerns regarding latency and minimizing the impact on data migration performance.Try out the approach for your own use case, and share your feedback and questions in the comments.