AWS Compute Blog
Under the hood: how AWS Lambda SnapStart optimizes function startup latency
When building applications using AWS Lambda, optimizing function startup is an important step to improve performance for latency sensitive applications. The largest contributor to startup latency (often referred to as cold start time) is the time that Lambda spends initializing your function code. Lambda SnapStart is a feature available for Java, Python, and .NET runtimes that helps reduce variable cold start latency from several seconds (or higher) to as low as sub-second. SnapStart typically needs zero or minimal changes to your application code and makes it easier to build highly responsive and scalable applications without implementing complex performance optimizations. This post explains how SnapStart works under the hood and provides recommendations to improve application performance when using SnapStart.
If your function already initializes within hundreds of milliseconds, then AWS recommends using Lambda Provisioned Concurrency to achieve double-digit millisecond startup latency.
What is a cold-start?
Lambda runs your function code in an isolated, secure execution environment that uses Firecracker microVM technology. When you first invoke a Lambda function, Lambda creates a new execution environment for the function to run in. Lambda downloads your function code, starts the language runtime, and runs your function initialization code, which is code outside the handler. This initialization process (INIT) is called a cold start. Then, Lambda runs your function handler code to invoke the function. A Lambda execution environment only handles a single invoke request at a time. The following figure shows the lifecycle of a typical invocation request.

Figure 1. Function invocation lifecycle without SnapStart
After the function finishes running, Lambda doesn’t stop the execution environment right away. When your function receives another invocation request, Lambda attempts to route the request to the idle but already running execution environment. As the INIT process has already run for this execution environment, this invoke is called a warm start. When more traffic arrives than Lambda has available idle execution environments, Lambda initializes new execution environments to serve the additional requests, performing the cold start initialization process again.
The last step of the cold start, initializing function code, typically takes the longest. This depends on the startup tasks that you execute in your code and the programming language runtime or framework you use. For languages such as Java and .NET, startup latency is impacted by just-in-time compilation of static code in loaded classes. For Python, it can be impacted if your executed code contains numerous or large modules. Other startup tasks, such as downloading machine learning (ML) models, can also take several seconds to complete, which adds to your function’s initialization latency. SnapStart is designed to optimize this last step of the cold start process and achieves this in three stages.
Stage 1: Snapshotting your Lambda function
When using SnapStart, the Lambda execution environment lifecycle changes. When you enable SnapStart for a particular function, publishing a new function version triggers the snapshotting process. The process runs the function initialization phase and takes an immutable, encrypted Firecracker microVM snapshot of the memory and disk state of the initialized execution environment, caching and chunking the snapshot for reuse. Code paths that are not executed during initialization, such as classes loaded on-demand through dependency injection, are not included in your function’s snapshot. To improve snapshot efficiency, proactively execute code paths during the initialization phase, or use runtime hooks to run code before Lambda creates a snapshot.
Snapshot creation can take a few minutes, during which your function version remains in the PENDING state, becoming ACTIVE when the snapshot is ready.
When you subsequently invoke your function, Lambda restores new execution environments from this snapshot. This optimization makes the invocation time faster and more predictable, because creating new a execution environment no longer requires an initialization.
The following figure shows the lifecycle of a SnapStart configured function.
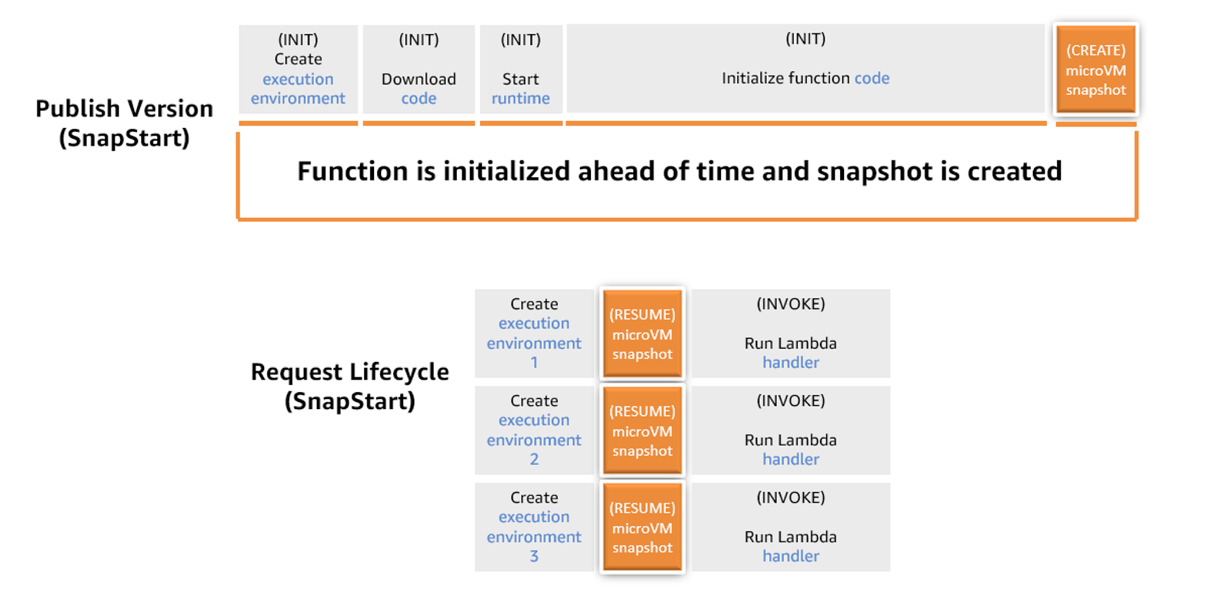
Figure 2. Function invocation lifecycle with SnapStart
After Lambda creates a snapshot, it periodically regenerates it to apply security patches, runtime updates, and software upgrades. Your invocation requests continue to work throughout the regeneration process.
Stage 2: Storing snapshots for low-latency retrieval at Lambda scale
Lambda operates at a high scale, processing tens of trillions of invocation requests every month. To efficiently manage and retrieve snapshots at this volume of traffic, Lambda uses storage and caching components. These consist of three layers: Amazon S3 for durable storage, a dedicated distributed cache, and a local cache on Lambda worker nodes.
Lambda stores function snapshots in Amazon S3, dividing them into 512 KB chunks to optimize retrieval latency. Retrieval latency from Amazon S3 can take up to hundreds of milliseconds for each 512 KB chunk. Therefore, Lambda uses a two-layer cache to speed-up snapshot retrieval.
When you enable SnapStart, during the optimization process, Lambda stores snapshot chunks in a layer two (L2) cache. This layer is a dedicated distributed cache instance fleet purpose-built by Lambda. Lambda stores a separate copy of each snapshot per AWS Availability Zone (AZ). To balance performance with costs, Lambda may not proactively cache unused snapshot chunks, instead caching them after they are first accessed. Chunks remain cached in the L2 fleet as long as your function version is active. The snapshot restore performance from the L2 layer is typically single digit milliseconds for a 512 KB chunk.
Lambda also maintains a layer one (L1) cache located on Lambda worker nodes, the Amazon Elastic Compute Cloud (Amazon EC2) instances handling function invocations. This layer is available locally, thus it provides the fastest performance, typically 1 millisecond for a 512 KB chunk. Functions with more frequent invocations are more likely to have their snapshot chunks cached in this layer. Functions with fewer invocations are automatically evicted from this cache, because it is bound by the worker instance disk capacity. When a snapshot chunk is not available in the L1 cache, Lambda retrieves the chunk from the L2 cache layer.
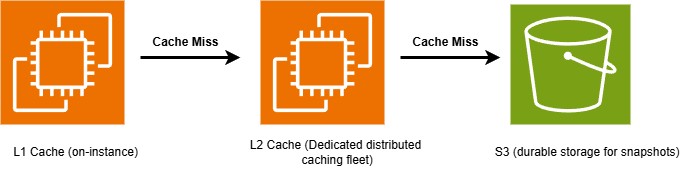
Figure 3. SnapStart tiered cache
Stage 3: Resuming execution from restored snapshots
Resuming execution from snapshots with low latency is the final SnapStart stage. This involves loading the retrieved snapshot chunks into your function execution environment. Typically, only a subset of the retrieved snapshot is needed to serve an invocation. Storing snapshots as chunks lets Lambda optimize the resume process by proactively loading only the necessary subset of chunks. To achieve this, Lambda tracks and records the snapshot chunks that the function accesses during each function invocation, as shown in the following figure.
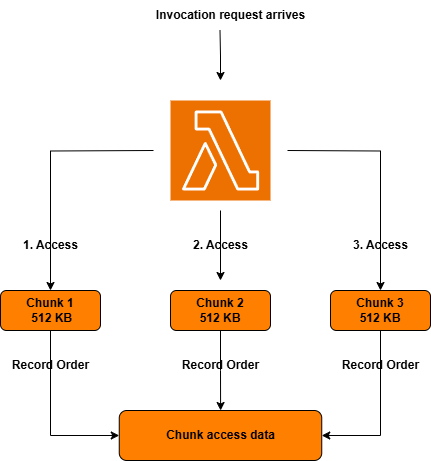
Figure 4. Initial invocation, record chunk access pattern
After the first function invocation, Lambda refers to this recorded chunk access data for subsequent invokes, as shown in the following figure. Lambda proactively retrieves and loads this “working set” of chunks before they are needed for execution. This significantly speeds up cold-start latency. If every invoke executes the same code path, then all necessary chunks are tracked after the first invoke. If your Lambda function includes a method that is conditionally invoked once every five cold starts, then Lambda adds the corresponding chunks representing this method to the chunk access metadata after five cold starts.
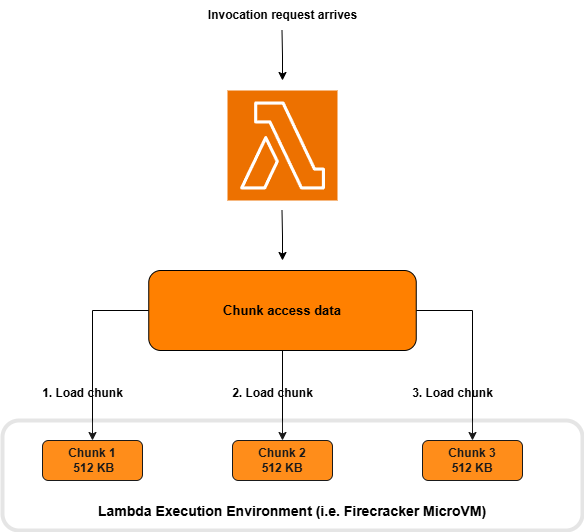
Figure 5. Subsequent invocation, load chunks in order of access
Understanding SnapStart function performance
The speed of restoring a snapshot depends on its contents, size, and the caching tier used. As a result, SnapStart performance can vary across individual functions.
Function performance improves with more invocations
Frequently invoked functions are more likely to have their snapshots cached in the L1 layer, which provides the fastest retrieval latency. Infrequently accessed portions of snapshots for functions with sporadic invokes are less likely to be present in the L1 layer, resulting in slower retrieval latency from the L2 and S3 cache layers. Chunk access data for functions with more invocations is also more likely to be “complete”, which speeds up snapshot restore latency.
Pre-load code paths to optimize snapshot restore latency
To maximize the benefits of SnapStart, preload dependencies, initialize resources, and perform heavy computation tasks that contribute to startup latency in your initialization code instead of in the function handler. Code paths not executed during your function’s INIT phase, such as application classes loaded on-demand through dependency injection, are not included in your function’s snapshot. You can further improve SnapStart effectiveness by proactively executing these code paths during function initialization. You can also run code using runtime hooks and invoking your handler during the initialization phase before creating the snapshot. To achieve this, refer to the documentation and posts for Spring Boot and .NET applications to implement the performance tuning.
Performance differs depending on function size
SnapStart performance depends on how quickly Lambda can retrieve and load cached snapshots into your function execution environment. Larger function sizes increase the size of snapshots, and thus the number of chunks, which causes performance to differ for functions of varying sizes.
Not all functions benefit from SnapStart
SnapStart is designed to improve startup latency when function initialization takes several seconds, due to language-specific factors or because of initializing and loading software dependencies and frameworks. If your functions initialize within hundreds of milliseconds, you are unlikely to experience a significant performance improvement with SnapStart. For these scenarios, we recommend Provisioned Concurrency, which pre-initializes execution environments, delivering double-digit millisecond latency.
Conclusion
AWS Lambda SnapStart can deliver as low as sub-second startup performance for Java, .NET, and Python functions with long initialization times. This post explores how the Lambda lifecycle changes with SnapStart and how Lambda efficiently stores and loads snapshots to improve start up performance. SnapStart helps developers build highly responsive and scalable applications without provisioning resources or implementing complex performance optimizations.
To learn more about SnapStart, refer to the documentation and launch posts for Java, and Python and .NET. For performance tuning, refer to the SnapStart best practices section for your preferred language runtime. This post outlines approaches to pre-load code paths to further optimize startup latency. Find more information and sample applications built using SnapStart on Serverlessland.com.