AWS Compute Blog
Processing Amazon S3 objects at scale with AWS Step Functions Distributed Map S3 prefix
If you’re building large scale enterprise applications, you’ve likely faced the complexities of processing large volumes of data files. Whether you’re analyzing your application logs, processing customer data files, or transforming machine learning datasets, you know the complexity involved in orchestrating workflows. You’ve probably written nested workflows and additional custom code to process objects from Amazon Simple Storage Service (Amazon S3) buckets.
With AWS Step Functions Distributed Map, you can process large scale datasets by running concurrent iterations of workflow steps across data entries in parallel, achieving massive scale with simplified management.
With the new prefix-based iteration feature and LOAD_AND_FLATTEN transformation parameter for Distributed Map, your workflows can now iterate over S3 objects under a specified prefix using S3ListObjectsV2 to process their contents in a single Map state, avoiding nested workflows and reducing operational complexity.
This post is part of a series of post about AWS Step Functions Distributed Map:
|
In this post, you’ll learn how to process Amazon S3 objects at scale with the new AWS Step Functions Distributed Map S3 prefix and transformation capabilities.
Use case: Application log processing and summarization
You’ll build a sample Step Functions state machine that demonstrates processing of all the log files from the given S3 prefix using a Distributed Map. You’ll analyze all the log files to build a summary INFO, WARNING and ERROR messages in the log file on hourly basis. The following diagram presents the AWS Step Functions state machine:
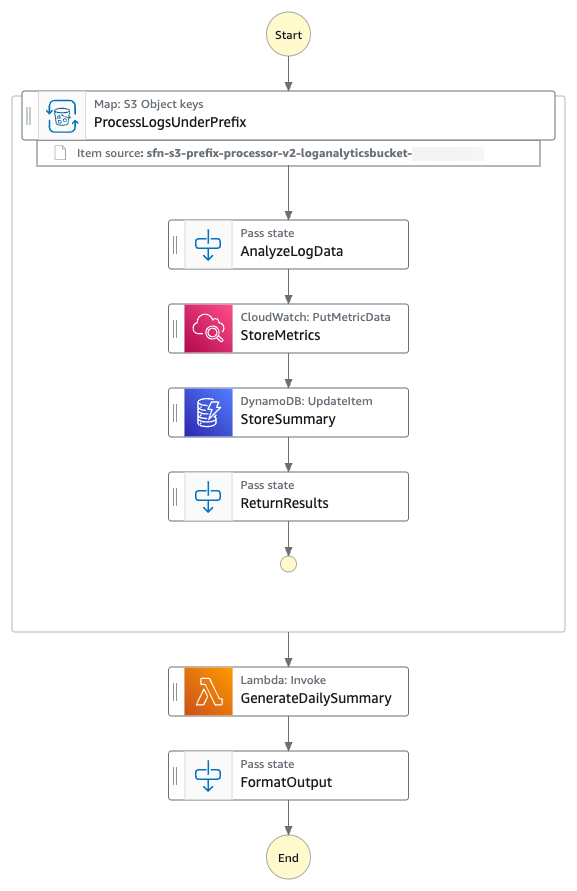
Log files processing workflow
- The state machine iterates over all the log files from the specified S3 prefix using S3
ListObjectsV2and process them using AWS Step Functions Distributed Map. - For each log file entry, the state machine puts hourly
ErrorCountmetric into Amazon CloudWatch. - The state machine then stores hourly metrics count in a Amazon DynamoDB table.
- The state machine then invokes an AWS Lambda function to perform metrics aggregation.
The following is an example of the parameters in an ItemReader configured to iterate over the content of S3 objects using S3 ListObjectsV2.
With the LOAD_AND_FLATTEN option, your state machine will do the following:
- Read the actual content of each object listed by the Amazon S3
ListObjectsV2call. - Parse the content based on
InputType(CSV, JSON, JSONL, Parquet). - Create items from the file contents (rows/records) rather than metadata.
We recommend including a trailing slash on your prefix. For example, if you select data with a prefix of folder1, your state machine will process both folder1/myData.csv and folder10/myData.csv. Using folder1/ will strictly process only one folder. All of the objects listed by prefix need to be in the same data format. For example, if you are selecting InputType as JSONL, your S3 prefix should contain only JSONL files and not a mix of other types.
The context object is an internal JSON structure that is available during an execution. The context object contains information about your state machine and execution. Your workflows can reference the context object in a JSONata expression with $states.context.
Within a Map state, the context object includes the following data:
For each Map iteration, the Index contains the index number for the array item that is being currently processed.
A Key is only available when iterating over JSON objects. Value contains the array item being processed. For example, for the following input JSON object, Names will be assigned to Key and {"Bob", "Cat"} will be assigned to Value.
Source contains one of the following:
- For state input:
STATE_DATA - For Amazon S3
LIST_OBJECTS_V2withTransformation=NONE, the value will show the S3 URI for the bucket. For example:S3://amzn-s3-demo-bucket1 - For all the other input types, the value will be the Amazon S3 URI. For example:
S3://amzn-s3-demo-bucket1/object-key
Using LOAD_AND_FLATTEN and the Source field, you can connect child executions to their sources.
Prerequisites
- Access to an AWS account through the AWS Management Console and the AWS Command Line Interface (AWS CLI). The AWS Identity and Access Management (IAM) user that you use must have permissions to make the necessary AWS service calls and manage AWS resources mentioned in this post. While providing permissions to the IAM user, follow the principle of least-privilege.
- AWS CLI installed and configured. If you are using long-term credentials like access keys, follow manage access keys for IAM users and secure access keys for best practices.
- Git Installed.
- AWS Serverless Application Model (AWS SAM) installed.
- Python 3.13 or later installed.
Set up and run the workflow
Run the following steps to deploy and test the Step Functions state machine.
- Clone the GitHub repository in a new folder and navigate to the project folder.
- Run the following commands to deploy the application.
- Enter the following details:
Stack name: Stack name for CloudFormation (for example, stepfunctions-s3-prefix-processor)AWS Region: A supported AWS Region (for example, us-east-1)- Accept all other default values.
The outputs from the AWS SAM deploy will be used in the subsequent steps.
- Run the following command to generate sample log files.
- Run the following to upload the log files to the S3 bucket with the
/logs/dailyprefix. Replaceamzn-s3-demo-bucket1with the value from thesam deployoutput. - Run the following command to execute the Step Functions workflow. Replace the
StateMachineArnwith the value from thesam deployoutput.The Step Function state machine iterates over all the log files with the S3 prefix
/logs/dailyand processes them in parallel. The workflow updates the metrics in CloudWatch, stores hourly metrics count in DynamoDB, then invokes an AWS Lambda function to aggregate the metrics.
Monitor and verify results
Run the following steps to monitor and verify the test results.
- Run the following command to get the details of the execution. Replace
executionArnwith your state machine ARN. - When the status shows
SUCCEEDED, run the following commands to check the processed output from theLogAnalyticsSummaryTableNameDynamoDB table. Replace the valueLogAnalyticsSummaryTableNamewith the value from thesam deployoutput. - Check that hourly
ERROR,WARN, andINFOlogs statistics are saved in the DynamoDB table. The following is a sample output: - Run the following command to check the output of the Step Functions state machine execution output.
The following is a sample output:
The output of the Step Functions state machine shows the daily summary insights of the log files created by the Lambda function.
Clean up
To avoid costs, remove all resources created for this post once you’re done. Run the following command after replacing amzn-s3-demo-bucket1 with your own bucket name to delete the resources you deployed for this post’s solution:
Conclusion
In this post, you learned how AWS Step Functions Distributed Map can use prefix-based iteration with LOAD_AND_FLATTEN transformation to read and process multiple data objects from Amazon S3 buckets directly. You no longer need one step to process object metadata and another to load the data objects. Loading and flatting in one step is particularly valuable for data processing pipelines, batch operations, and event-driven architectures where objects are continually added to S3 locations. By eliminating the need to maintain object manifests, you can build more resilient, dynamic data processing workflows with less code and fewer moving parts.
New input sources for Distributed Map are available in all commercial AWS Regions where AWS Step Functions is available. For a complete list of AWS Regions where Step Functions is available, see the AWS Region Table. To get started, you can use the Distributed Map mode today in the AWS Step Functions console. To learn more, visit the Step Functions developer guide.
For more serverless learning resources, visit Serverless Land.