Organizations must often deal with a vast array of data formats and sources in their data analytics workloads. This range of data types, such as structured relational data, semi-structured formats like JSON and XML and even binary formats like Protobuf and Avro, has presented new challenges for companies looking to extract valuable insights.
Protocol Buffers (protobuf) has gained significant traction in industries that require efficient data serialization and transmission, particularly in streaming data scenarios. Protobuf’s compact binary representation, language-agnostic nature, and strong typing make it an attractive choice for companies in sectors such as finance, gaming, telecommunications, and ecommerce, where high-throughput and low-latency data processing is crucial.
Although protobuf offers advantages in efficient data serialization and transmission, its binary nature poses challenges when it comes to analytics use cases. Unlike formats like JSON or XML, which can be directly queried and analyzed, protobuf data requires an additional deserialization step to convert it from its compact binary format into a structure suitable for processing and analysis. This extra conversion step introduces complexity into data analytics pipelines and tools. It can potentially slow down data exploration and analysis, especially in scenarios where near real-time insights are crucial.
In this post, we explore an end-to-end analytics workload for streaming protobuf data, by showcasing how to handle these data streams with Amazon Redshift Streaming Ingestion, deserializing and processing them using AWS Lambda functions, so that the incoming streams are immediately available for querying and analytical processing on Amazon Redshift.
The solution provides a solid foundation for handling protobuf data in Amazon Redshift. You can further enhance the architecture to support schema evolution by incorporating AWS Glue Schema Registry. By integrating the AWS Glue Schema Registry, you can make sure your Lambda function uses the latest schema version for deserialization, even as your data structure changes over time. However, for the purpose of this post and to maintain simplicity, we focus on demonstrating how to invoke Lambda from Amazon Redshift to convert protobuf messages to JSON format, which serves as a solid foundation for handling binary data in near real-time analytics scenarios.
Solution overview
The following architecture diagram describes the AWS services and features needed to set up a fully functional protobuf streaming ingestion pipeline for near real-time analytics.
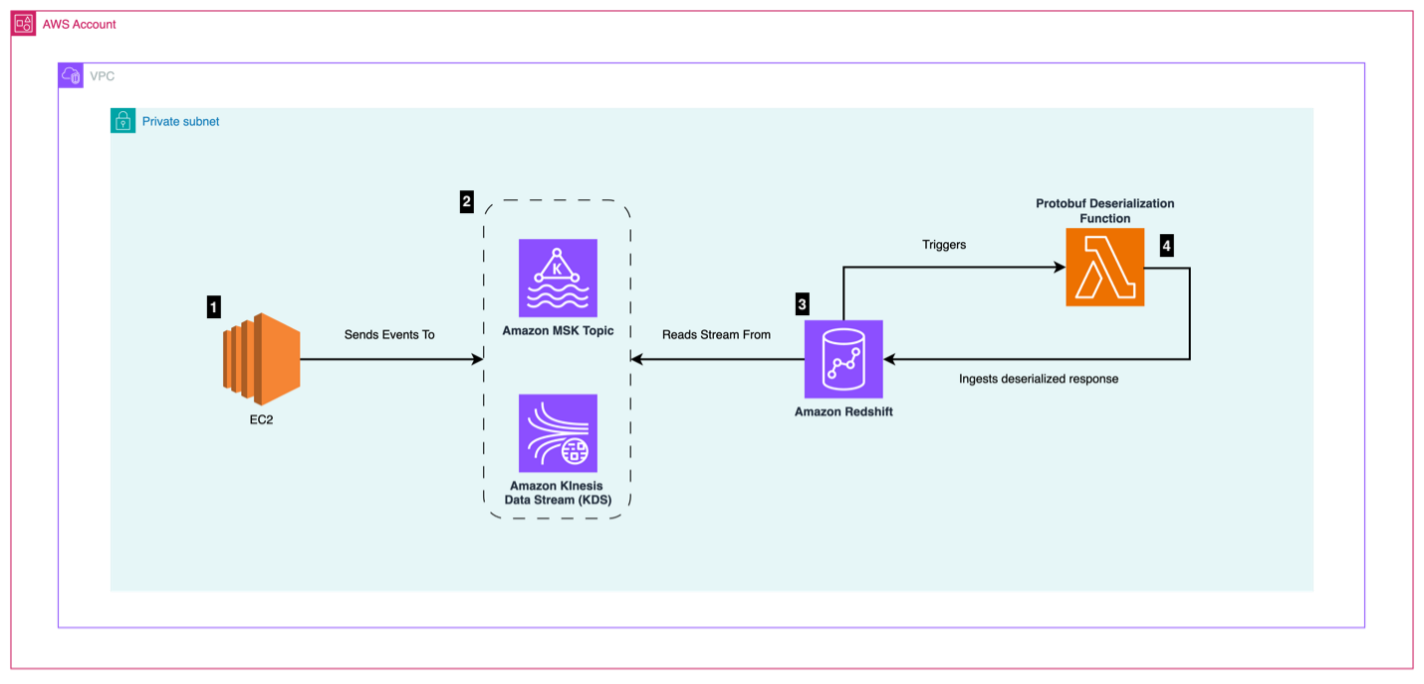
The workflow consists of the following steps:
- An Amazon Elastic Compute Cloud (Amazon EC2) event producer generates events and forwards them to a message queue. The events are created and serialized using protobuf.
- A message queue using Amazon Managed Streaming for Apache Kafka (Amazon MSK) or Amazon Kinesis accepts the protobuf messages sent by the event producer. For this post, we use Amazon MSK Serverless.
- A Redshift cluster (provisioned or serverless), in which a materialized view with an external schema is configured, points to the message queue. For this post, we use Amazon Redshift Serverless.
- A Lambda protobuf deserialization function is triggered by Amazon Redshift during ingestion and deserializes protobuf data into JSON data.
Schema
To showcase protobuf’s deserialization functionality, we use a sample protobuf schema that represents a financial trade transaction. This schema will be used across the AWS services mentioned in this post.
// trade.proto
syntax = "proto3";
message Trade{
int32 userId = 1;
string userName = 2;
int32 volume = 3;
int32 pair = 4;
int32 action = 5;
string TimeStamp = 6;
}
Amazon Redshift materialized view
In order for Amazon Redshift to ingest streaming data from Amazon MSK or Kinesis, an appropriate role needs to be assigned to Amazon Redshift and a materialized view needs to be properly defined. For detailed instructions on how to accomplish this, refer to Streaming ingestion to a materialized view or Simplify data streaming ingestion for analytics using Amazon MSK and Amazon Redshift.
In this section, we focus on the materialized view definition that makes it possible to deserialize protobuf data. Our example focuses on streaming ingestion from Amazon MSK. Typically, the materialized view ingests the Kafka metadata fields and the actual data (kafka_value) like in the following example:
CREATE MATERIALIZED VIEW trade_events AUTO REFRESH YES AS
SELECT
kafka_partition,
kafka_offset,
kafka_timestamp_type,
kafka_timestamp,
kafka_key,
JSON_PARSE(kafka_value) as Data,
kafka_headers
FROM
"dev"."msk_external_schema"."entity"
WHERE
CAN_JSON_PARSE(kafka_value)
When the incoming kafka_value is of type JSON, you can apply the built-in JSON_PARSE function and create a column of type SUPER so you can directly query the data.
Amazon Redshift Lambda user-defined function
In our case, accepting protobuf encoded data requires some additional steps. The first step is to create an Amazon Redshift Lambda user-defined function (UDF). This Amazon Redshift function is the link to a Lambda function that executes the actual deserialization. This way, when data is ingested, Amazon Redshift calls the Lambda function for deserialization.
Creating or updating our Amazon Redshift Lambda UDF is straightforward, as illustrated in the following code. Additional examples are available in the GitHub repo.
CREATE OR REPLACE EXTERNAL FUNCTION f_deserialize_protobuf(VARCHAR(MAX))
RETURNS VARCHAR(MAX) IMMUTABLE
LAMBDA 'f-redshift-deserialize-protobuf' IAM_ROLE ':RedshiftRole';
Because Lambda functions don’t (at the time of writing) accept binary data as input, you must first convert incoming binary data to its hex representation, prior to calling the function. You can do this by using the TO_HEX Amazon Redshift function.
Considering the hex conversation and with the Lambda UDF available, you can now use it in your materialized view definition:
CREATE MATERIALIZED VIEW trade_events AUTO REFRESH YES AS
SELECT
kafka_partition,
kafka_offset,
kafka_timestamp_type,
kafka_timestamp,
kafka_key,
kafka_value,
kafka_headers,
JSON_PARSE(f_deserialize_protobuf(to_hex(kafka_value)))::super as json_data
FROM
"dev"."msk_external_schema"."entity";
Lambda layer
Lambda functions require access to appropriate protobuf libraries, so that deserialization can take place. You can implement this through a Lambda layer. The layer is provided as a zip file, respecting the following folder structure, and contains the protobuf library, its dependencies, and user-provided code inside the custom folder, which includes the protobuf generated classes:
python
custom
google
Protobuf-4.25.2.dist-info
Because we implemented the Lambda functions in Python, the root folder of the zip file is the python folder. For additional languages, refer to the documentation on how to properly structure your folder structure.
Lambda function
A Lambda function converts incoming protobuf records to JSON records. As a first step, you must import your custom classes from the lambda Layer custom folder:
# Import generated protobuf classes
from custom import trade_pb2
You can now deserialize incoming hex encoded binary data to objects. This is implemented in a two-step process. The first step is to decode the hex encoded binary data:
# convert incoming hex data to binary
binary_data = bytes.fromhex(record)
Next, you instantiate the protobuf defined classes and execute the actual deserialization process using the protobuf library method ParseFromString:
# Instantiate class
trade_event = trade_pb2.Trade()
# Deserialize into class
trade_event.ParseFromString(binary_data)
After you run deserialization and instantiate your objects, you can convert to other formats. In our case, we serialize into JSON format, so that Amazon Redshift ingests the JSON content in a single field of type SUPER:
# Serialize into json
elems = trade_event.ListFields()
fields = {}
for elem in elems:
fields[elem[0].name] = elem[1]
json_elem = json.dumps(fields)
Combining these steps together, the Lambda function should look as follows:
import json
# Import the generated protobuf classes
from custom import trade_pb2
def lambda_handler(event, context):
results = []
recordSets = event['arguments']
for recordSet in recordSets:
for record in recordSet:
# convert incoming hex data to binary data
binary_data = bytes.fromhex(record)
# Instantiate class
trade_event = trade_pb2.Trade()
# Deserialize into class
trade_event.ParseFromString(binary_data)
# Serialize into json
elems = trade_event.ListFields()
fields = {}
for elem in elems:
fields[elem[0].name] = elem[1]
json_elem = json.dumps(fields)
# Append to results
results.append(json_elem)
print('OK')
return json.dumps({"success": True,"num_records": len(results),"results": results})
Batch mode
In the preceding code sample, Amazon Redshift is calling our function in batch mode, meaning that a number of records are sent during a single Lambda function call. More specifically, Amazon Redshift is batching records into the arguments property of the request. Therefore, you must loop through the incoming array of data and apply your deserialization logic per record. At the time of writing, this behavior is internal to Amazon Redshift and can’t be configured or controlled through a configuration option. An Amazon Redshift streaming consumer client will read new records on the message queue since the last time it read. The following is a sample of the payload the Lambda handler function receives:
"user": "IAMR:Admin",
"cluster": "arn:aws:redshift:*********************************",
"database": "dev",
"external_function": "fn_lambda_protobuf_to_json",
"query_id": 5583858,
"request_id": "17955ee8-4637-42e6-897c-5f4881db1df5",
"arguments": [
[
"088a1112087374723a3231383618c806200128093217323032342d30332d32302031303a34363a33382e363932" ], [ "08a74312087374723a3836313518f83c200728093217323032342d30332d32302031303a34363a33382e393031" ], [ "08b01e12087374723a3338383818f73d20f8ffffffffffffffff0128053217323032342d30332d32302031303a34363a33392e303134"
]
],
"num_records":3
}
Insights from ingested data
With your data stored in Amazon Redshift after the deserialization process, you can now execute queries against your streaming data and directly gain insights. In this section, we present some sample queries to illustrate functionality and behavior.
Examine lag query
To examine the difference between the most recent timestamp value of our streaming source vs. the current date/time (wall clock), we calculate the most recent point in time at which we ingested data. Because streaming data is expected to flow into the system continuously, this metric also reveals the ingestion lag between our streaming source and Amazon Redshift.
select top 1
(GETDATE() - kafka_timestamp) as ingestion_lag
from
trade_events
order by
kafka_timestamp desc
Examine content query: Fraud detection on an incoming stream
By applying the query functionality available in Amazon Redshift, we can discover behavior hidden in our data in real time. With the following query, we try to match opposite trade volumes played by different users during the last 5 minutes that result in a zero sum game and could support a potential fraud detection concept:
select
json_data.volume,
LISTAGG(json_data.userid::int, ', ') as users,
LISTAGG(json_data.pair::int, ', ') as pairs
from
trade_events
where
trade_events.kafka_timestamp >= DATEADD(minute, -5, GETDATE())
group by
json_data.volume
having
sum(json_data.pair) = 0
and min(abs(json_data.pair)) = max(abs(json_data.pair))
and count(json_data.pair) > 1
This query is a rudimentary example of how we can use live data to protect systems from fraudsters.
For a more comprehensive example, see Near-real-time fraud detection using Amazon Redshift Streaming Ingestion with Amazon Kinesis Data Streams and Amazon Redshift ML. In this use case, an Amazon Redshift ML model for anomaly detection is trained using the incoming Amazon Kinesis Data Streams data that is streamed into Amazon Redshift. After sufficient training (for example, 90% accuracy for the model is achieved), the trained model is put into inference mode for inferencing decisions on the same incoming credit card data.
Examine content query: Join with non-streaming data
Having our protobuf records streaming in Amazon Redshift makes it possible to join streaming with non-streaming data. A typical example is combining incoming trades with user information data already recorded in the system. In the following query, we join the incoming stream of trades with user information, like email, to get a list of possible alerts targets:
select
user_info.email
from
trade_events
inner join
user_info
on user_info.userId = trade_events.json_data.userid
where
trade_events.json_data.volume > 1000
and trade_events.kafka_timestamp >= DATEADD(minute, -5, GETDATE())
Conclusion
The ability to effectively analyze and derive insights from data streams, regardless of their format, is crucial for data analytics. Although protobuf offers compelling advantages for efficient data serialization and transmission, its binary nature can pose challenges and perhaps impact performance when it comes to analytics workloads. The solution outlined in this post provides a robust and scalable framework for organizations seeking to gain valuable insights, detect anomalies, and make data-driven decisions with agility, even in scenarios where high-throughput and low-latency processing is crucial. By using Amazon Redshift Streaming Ingestion in conjunction with Lambda functions, organizations can seamlessly ingest, deserialize, and query protobuf data streams, enabling near real-time analysis and insights.
For more information about Amazon Redshift Streaming Ingestion, refer to Streaming ingestion to a materialized view.
About the authors
 Konstantinos Tzouvanas is a Senior Enterprise Architect on AWS, specializing in data science and AI/ML. He has extensive experience in optimizing real-time decision-making in High-Frequency Trading (HFT) and applying machine learning to genomics research. Known for leveraging generative AI and advanced analytics, he delivers practical, impactful solutions across industries.
Konstantinos Tzouvanas is a Senior Enterprise Architect on AWS, specializing in data science and AI/ML. He has extensive experience in optimizing real-time decision-making in High-Frequency Trading (HFT) and applying machine learning to genomics research. Known for leveraging generative AI and advanced analytics, he delivers practical, impactful solutions across industries.
 Marios Parthenios is a Senior Solutions Architect working with Small and Medium Businesses across Central and Eastern Europe. He empowers organizations to build and scale their cloud solutions with a particular focus on Data Analytics and Generative AI workloads. He enables businesses to harness the power of data and artificial intelligence to drive innovation and digital transformation.
Marios Parthenios is a Senior Solutions Architect working with Small and Medium Businesses across Central and Eastern Europe. He empowers organizations to build and scale their cloud solutions with a particular focus on Data Analytics and Generative AI workloads. He enables businesses to harness the power of data and artificial intelligence to drive innovation and digital transformation.
 Pavlos Kaimakis is a Senior Solutions Architect at AWS who helps customers design and implement business-critical solutions. With extensive experience in product development and customer support, he focuses on delivering scalable architectures that drive business value. Outside of work, Pavlos is an avid traveler who enjoys exploring new destinations and cultures.
Pavlos Kaimakis is a Senior Solutions Architect at AWS who helps customers design and implement business-critical solutions. With extensive experience in product development and customer support, he focuses on delivering scalable architectures that drive business value. Outside of work, Pavlos is an avid traveler who enjoys exploring new destinations and cultures.
 John Mousa is a Senior Solutions Architect at AWS. He helps power and utilities and healthcare and life sciences customers as part of the regulated industries team in Germany. John has interest in the areas of service integration, microservices architectures, as well as analytics and data lakes. Outside of work, he loves to spend time with his family and play video games.
John Mousa is a Senior Solutions Architect at AWS. He helps power and utilities and healthcare and life sciences customers as part of the regulated industries team in Germany. John has interest in the areas of service integration, microservices architectures, as well as analytics and data lakes. Outside of work, he loves to spend time with his family and play video games.