AWS Big Data Blog
Build enterprise-scale log ingestion pipelines with Amazon OpenSearch Service
Organizations of all sizes generate massive volumes of logs across their applications, infrastructure, and security systems to gain operational insights, troubleshoot issues, and maintain regulatory compliance. However, implementing log analytic solutions presents significant challenges, including complex data ingestion pipelines and the need to balance cost and performance while scaling to handle petabytes of data.
Amazon OpenSearch Service addresses these challenges by providing high-performance search and analytics capabilities, making it straightforward to deploy and manage OpenSearch clusters in the AWS Cloud without the infrastructure management overhead. A well-designed log analytics solution can help support proactive management in a variety of use cases, including debugging production issues, monitoring application performance, or meeting compliance requirements.
In this post, we share field-tested patterns for log ingestion that have helped organizations successfully implement logging at scale, while maintaining optimal performance and managing costs effectively.
Solution overview
Organizations can choose from several data ingestion architectures, such as:
- Log shippers like FluentBit or Fluentd to send logs directly
- Amazon Data Firehose for serverless data delivery
- Custom solutions using AWS Lambda
- Amazon OpenSearch Ingestion for managed data ingestion
Irrespective of the chosen pattern, a scalable log ingestion architecture should comprise the following logical layers:
- Collect layer – This is the initial stage where logs are gathered from various sources, including application logs, system logs, and more.
- Buffer layer – This layer acts as a temporary storage layer to handle spikes in log volume and prevents data loss during downstream processing issues. This layer also maintains system stability during high load.
- Process layer – This layer transforms the unstructured logs into structured formats while adding relevant metadata and contextual information needed for effective analysis.
- Store layer – This layer is the final destination for processed logs (OpenSearch in this case), which supports various access patterns, including querying, historical analysis, and data visualization.
OpenSearch Ingestion offers a purpose-built, fully managed experience that simplifies the data ingestion process. In this post, we focus on using OpenSearch Ingestion to load logs from Amazon Simple Storage Service (Amazon S3) into an OpenSearch Service domain, a common and efficient pattern for log analytics.
OpenSearch Ingestion is a fully managed, serverless data ingestion service that streamlines the process of loading data into OpenSearch Service domains or Amazon OpenSearch Serverless collections. It’s powered by Data Prepper, an open source data collector that filters, enriches, transforms, normalizes, and aggregates data for downstream analysis and visualization.
OpenSearch Ingestion uses pipelines as a mechanism that consists of the following major components:
- Source – The input component of a pipeline. It defines the mechanism through which a pipeline consumes records.
- Buffer – A persistent, disk-based buffer that stores data across multiple Availability Zones to enhance durability. OpenSearch Ingestion dynamically allocates OCUs for buffering, which increases pricing as you may need additional OCUs to maintain ingestion throughput.
- Processors – The intermediate processing units that can filter, transform, and enrich records into a desired format before publishing them to the sink. The processor is an optional component of a pipeline.
- Sink – The output component of a pipeline. It defines one or more destinations to which a pipeline publishes records. A sink can also be another pipeline, so you can chain multiple pipelines together.
Because of its serverless nature, OpenSearch Ingestion automatically scales to accommodate varying workload demands, alleviating the need for manual infrastructure management while providing built-in monitoring capabilities. Users can focus on their data processing logic rather than spending time on operational complexities, making it an efficient solution for managing data pipelines in OpenSearch environments.
The following diagram illustrates the architecture of the log ingestion pipeline.
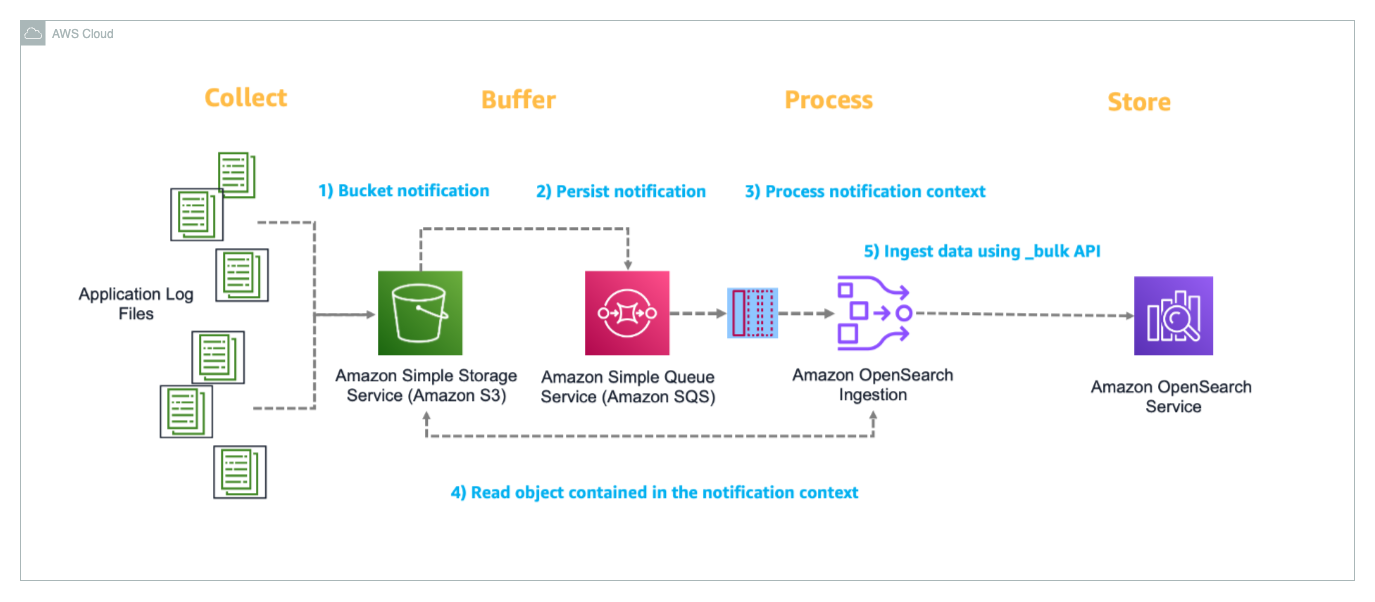
Let’s walk through how this solution processes Apache logs from ingestion to visualization:
- The source application generates Apache logs that need to be analyzed and stores them in an S3 bucket, which acts as the central storage location for incoming log data. When a new log file is uploaded to the S3 bucket (ObjectCreate event), Amazon S3 automatically triggers an event notification that is configured to send messages to a designated Amazon Simple Queue Service (Amazon SQS) queue.
- The SQS queue reliably manages and tracks the notifications of new files uploaded to Amazon S3, making sure the file event is delivered to the OpenSearch Ingestion pipeline. A dead-letter queue (DLQ) is configured to capture failed event processing.
- The OpenSearch Ingestion pipeline monitors the SQS queue, retrieving messages that contain information about newly uploaded log files. When a message is received, the pipeline reads the corresponding log file from Amazon S3 for processing.
- After the log file is retrieved, the OpenSearch Ingestion pipeline parses the content, and uses the OpenSearch Bulk API to efficiently ingest the processed log data into the OpenSearch Service domain, where it becomes available for search and analysis.
- The ingested data can be visualized and analyzed through OpenSearch Dashboards, which provides a user-friendly interface for creating custom visualizations, dashboards, and performing real-time analysis of the log data with features like search, filtering, and aggregations.
In the following sections, we guide you through the steps to ingest application log files from Amazon S3 into OpenSearch Service using OpenSearch Ingestion. Additionally, we demonstrate how to visualize the ingested data using OpenSearch Dashboards.
Prerequisites
This post assumes you have the following:
- An AWS account
- The AWS Command Line Interface (AWS CLI) installed
- The AWS CDK Toolkit installed
- Python 3 installed
Deploy the solution
The solution uses a Python AWS Cloud Development Kit (AWS CDK) project to deploy an OpenSearch Service domain and associated components. This project demonstrates event-based data ingestion into the OpenSearch Service domain in a no code approach using OpenSearch Ingestion pipelines.
The deployment is automated using the AWS CDK and comprises the following steps:
- Clone the GitHub repo.
- Create a virtual environment and install the Python dependencies:
- Update the following environment variables in
cdk.json:domain_name: The OpenSearch domain to be created in your AWS account.user_name: The user name for the internal primary user to be created within the OpenSearch domain.user_password: The password for the internal primary user.
This deployment creates a public-facing OpenSearch domain but is secured through fine-grained access control (FGAC). For production workloads, consider deploying within a virtual private cloud (VPC) with additional security measures. For more information, see Security in Amazon OpenSearch Service.
- Bootstrap the AWS CDK stack and initiate the deployment. Provide your AWS account number and the AWS Region where you want deploy the solution:
The process takes about 30–45 minutes to complete.
Verify the solution resources
When the previous steps are complete, you can check for the created resources.
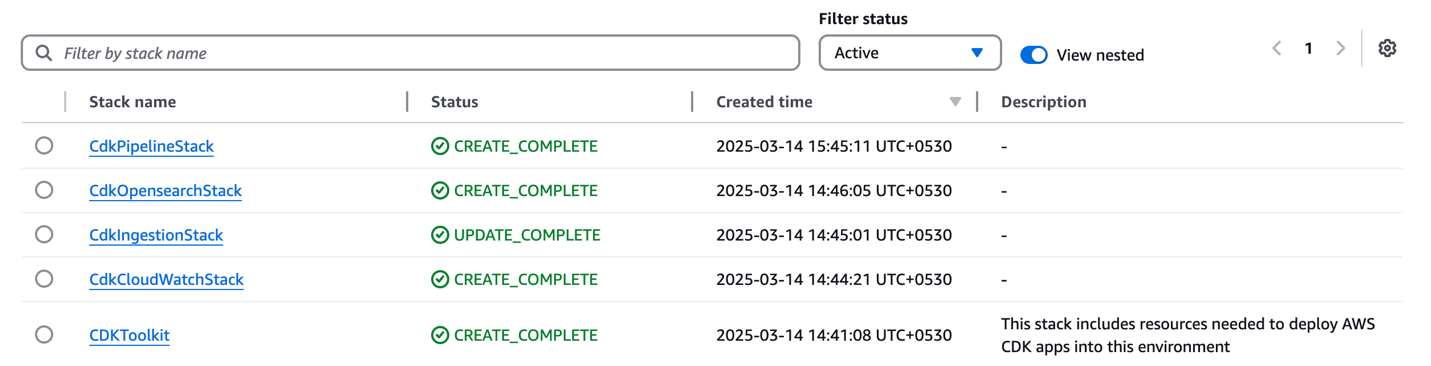
You can confirm the existence of the stacks on the AWS CloudFormation console. As shown in the following screenshot, the CloudFormation stacks have been created and deployed by cdk bootstrap and cdk deploy.
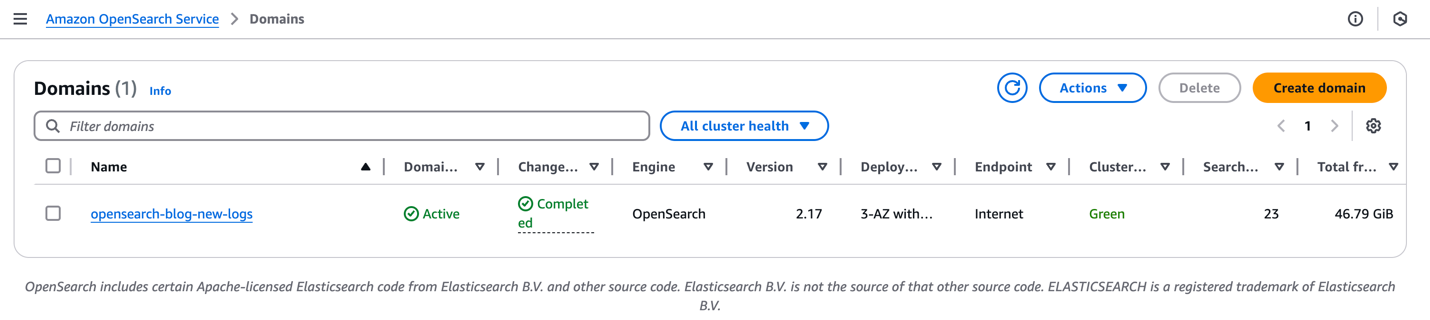
On the OpenSearch Service console, under Managed clusters in the navigation pane, choose Domains. You can confirm the domain created.
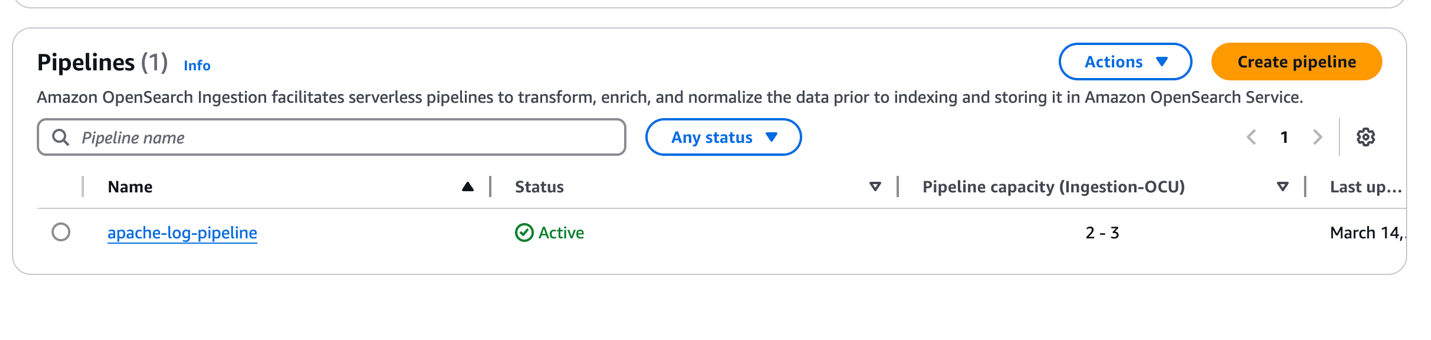
On the OpenSearch Service console, under Ingestion in the navigation pane, choose Pipelines. You can see the pipeline apache-log-pipeline created.
Configure security options
To configure your security roles, complete the following steps:
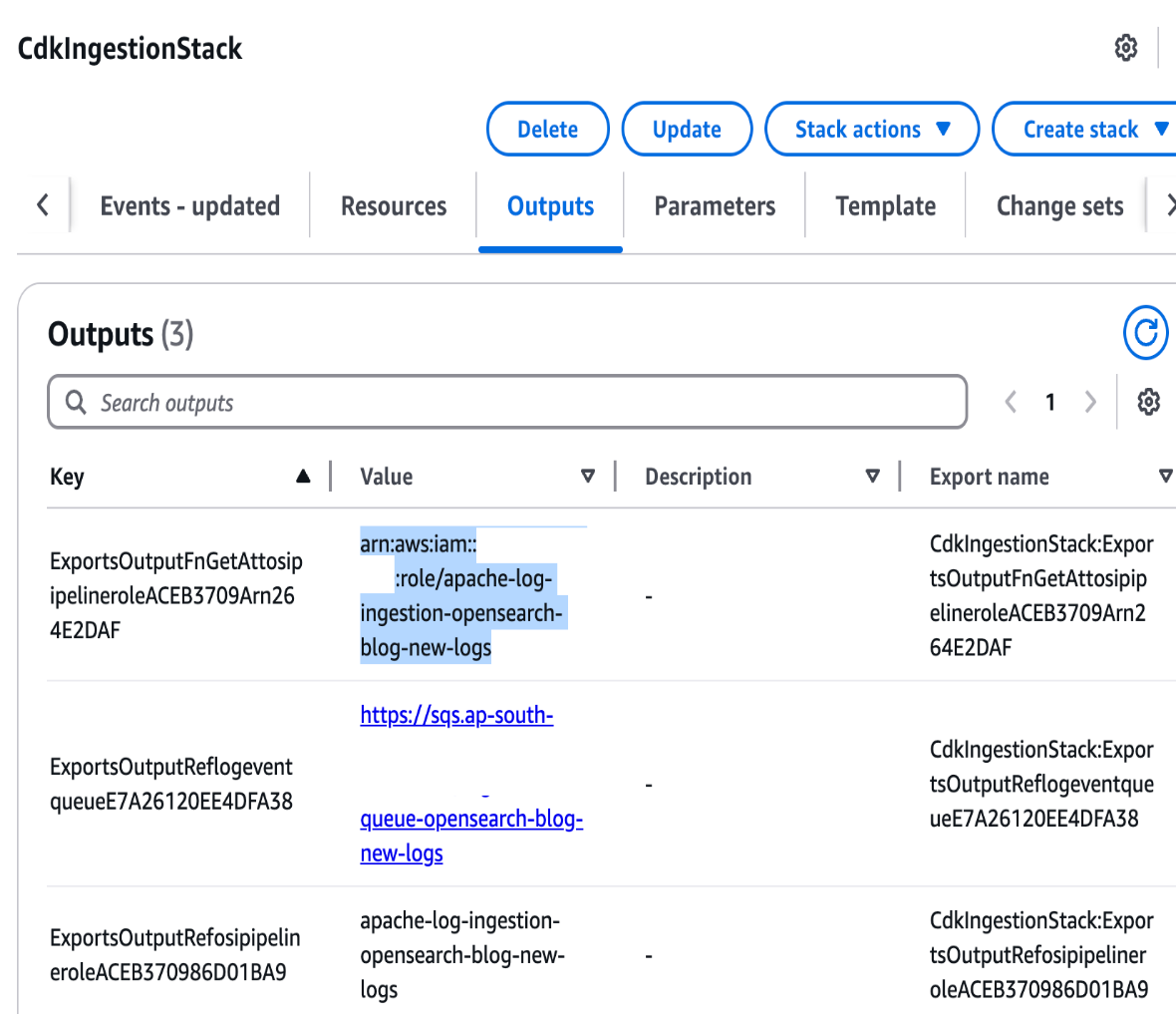
- On the AWS CloudFormation console, open the stack
CdkIngestionStack, and on the Outputs tab, copy the Amazon Resource Name (ARN) ofosi-pipeline-role.
- Open the OpenSearch Service console in the deployed Region within your AWS account and choose the domain you created.
- Choose the link for OpenSearch Dashboards URL.
- In the login prompt, enter the user credentials that were provided in
cdk.json.
After a successful login, the OpenSearch Dashboards console will be displayed.
- If you’re prompted to select a tenant, select the Global tenant.
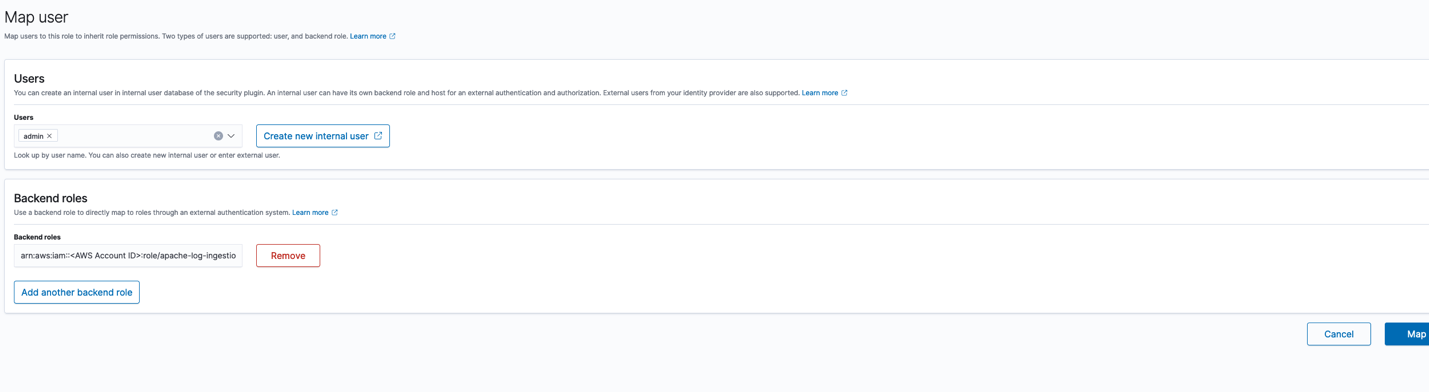
- In the Security options, navigate to the Roles section and choose the
all_accessrole. - On the
all_accessrole page, navigate tomapped_usersand choose Manage. - Choose Add another backend role under Backend roles and enter the IAM role ARN you copied.
- Confirm by choosing Map.
Create an index template
The next step is to create an index template. Complete the following steps:
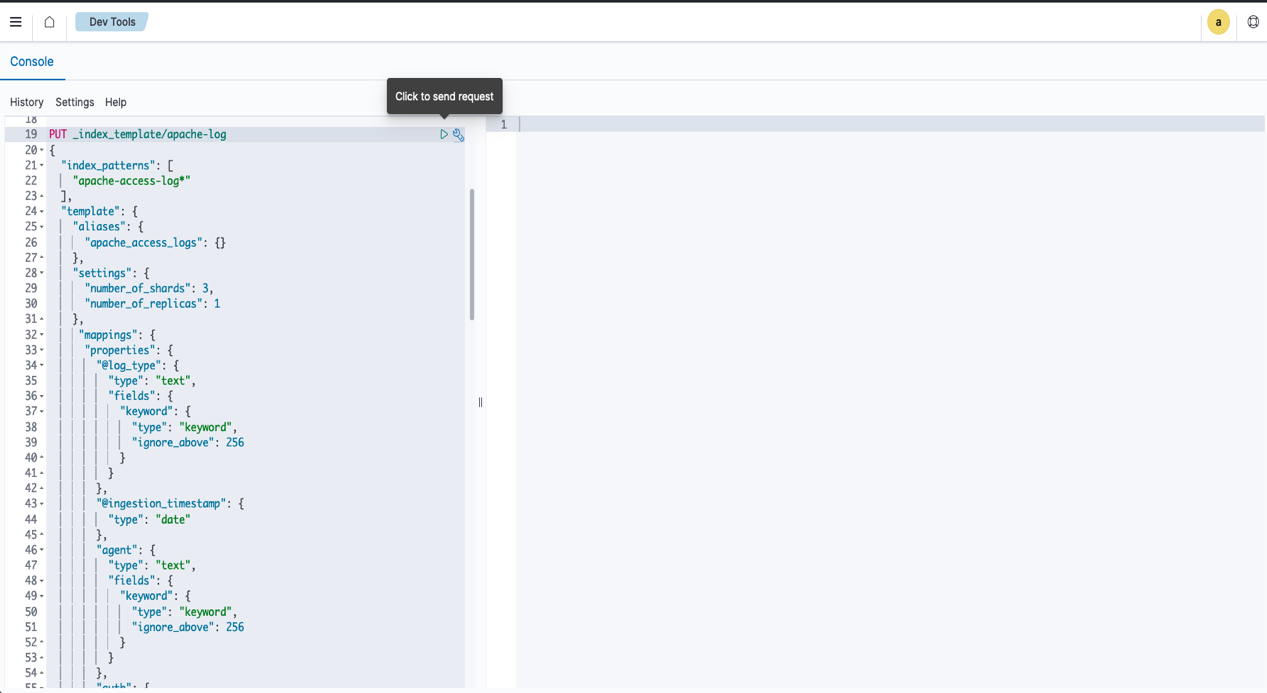
- On the Dev Tools console, copy the contents of the file
index_template.txtwithin theopensearch_objectdirectory. - Enter the code in the Dev Tools console.
This index template defines the mapping and settings for our OpenSearch index.
- Choose the play icon to submit the request and create a template.
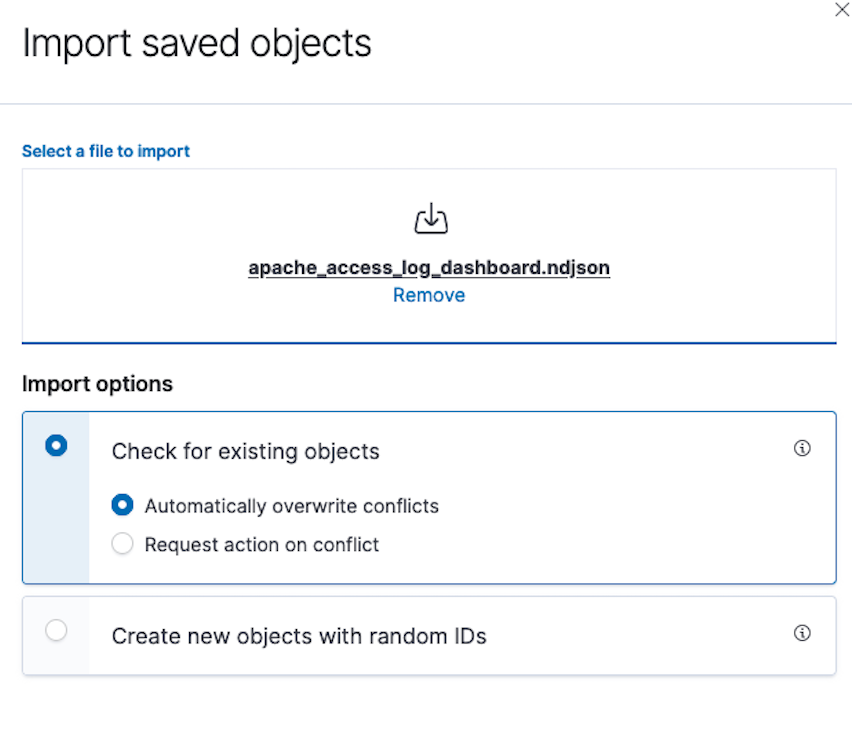
- In the Dashboard Management section, choose Saved Objects and choose Import.
- Choose Import and choose the
apache_access_log_dashboard.ndjsonfile within theopensearch_objectdirectory. - Choose Check for existing objects.
- Choose Automatically overwrite conflicts and choose Import.
Ingest data
Now you can proceed with the data ingestion.
- On the Amazon S3 console, open the S3 bucket
opensearch-logging-blog-<Account ID>. - Upload the data file
apache_access_log.gz(within theapache_log_datadirectory). The file can be uploaded in any prefix.
For this solution, we use Apache access logs as our example data source. Although this pipeline is configured for Apache log format, it can be modified to support other log types by adjusting the pipeline configuration. See Overview of Amazon OpenSearch Ingestion for details about configuring different log formats.
- After a few minutes, navigate to the Discover tab in OpenSearch Dashboards, where you can find that the data is ingested.
- Confirm that the
apache*index pattern is selected.
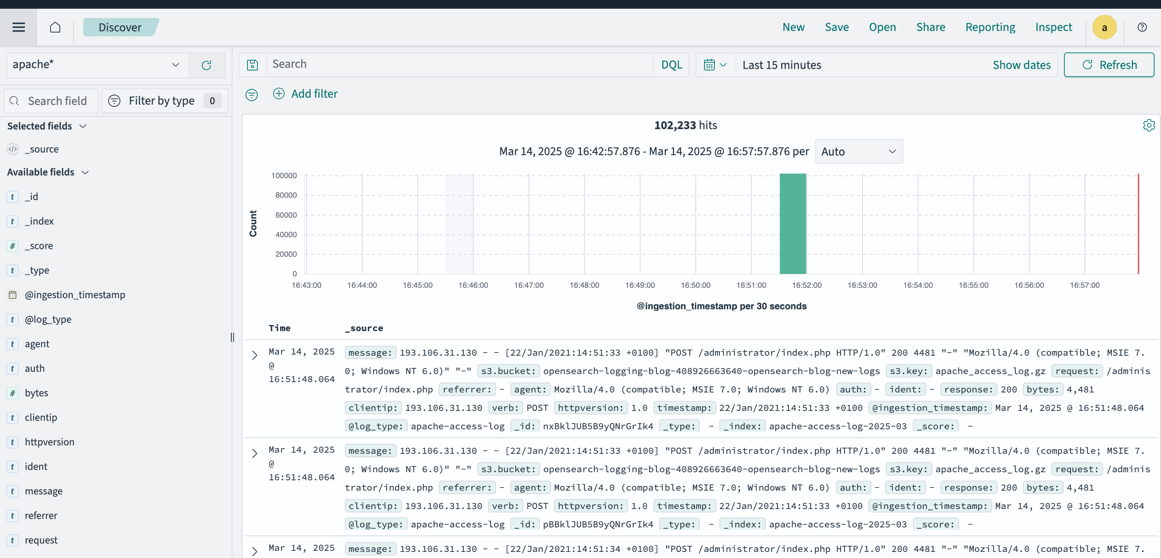
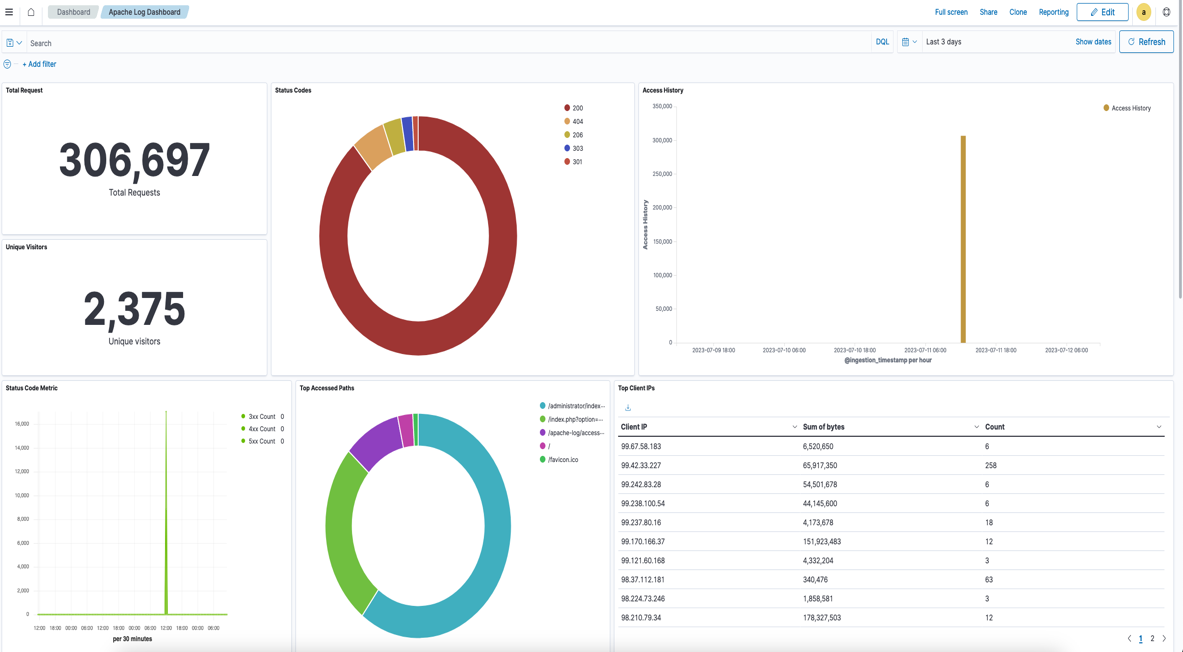
- 5. On the Dashboards tab, choose Apache Log Dashboard.
The dashboard will be populated by the data and visuals should be displayed.
Operational best practices
When designing your log analytics platform on OpenSearch Service, make sure you follow the recommended operational best practices for cluster configuration, data management, performance, monitoring, and cost optimization. For detailed guidance, refer to Operational best practices for Amazon OpenSearch Service.
Clean up
To avoid ongoing charges for the resources that you created, delete them by completing the following steps:
- On the Amazon S3 console, open the bucket
opensearch-logging-blog-<Account ID>and choose Empty. - Follow the prompts to delete the contents of the bucket.
- Delete the AWS CDK stacks using the following command:
Conclusion
As organizations continue to generate increasing volumes of log data, having a well-architected logging solution becomes crucial for maintaining operational visibility and meeting compliance requirements.
Implementing a robust logging infrastructure requires careful planning. In this post, we explored a field-tested approach in building a scalable, efficient, and cost-effective logging solution using OpenSearch Ingestion.
This solution serves as a starting point that can be customized based on specific organizational needs while maintaining the core principles of scalability, reliability, and cost-effectiveness.
Remember that logging infrastructure is not a “set-and-forget” system. Regular monitoring, periodic reviews of storage patterns, and adjustments to index management policies will help make sure your logging solution continues to serve your organization’s evolving needs effectively.
To dive deeper into OpenSearch Ingestion implementation, explore our comprehensive Amazon OpenSearch Service Workshops, which include hands-on labs and reference architectures. For additional insights, see Build a serverless log analytics pipeline using Amazon OpenSearch Ingestion with managed Amazon OpenSearch Service. You can also visit our Migration Hub if you’re ready to migrate legacy or self-managed workloads to OpenSearch Service.
About the authors
 Akhil B is a Data Analytics Consultant at AWS Professional Services, specializing in cloud-based data solutions. He partners with customers to design and implement scalable data analytics platforms, helping organizations transform their traditional data infrastructure into modern, cloud-based solutions on AWS. His expertise helps organizations optimize their data ecosystems and maximize business value through modern analytics capabilities.
Akhil B is a Data Analytics Consultant at AWS Professional Services, specializing in cloud-based data solutions. He partners with customers to design and implement scalable data analytics platforms, helping organizations transform their traditional data infrastructure into modern, cloud-based solutions on AWS. His expertise helps organizations optimize their data ecosystems and maximize business value through modern analytics capabilities.
 Ramya Bhat is a Data Analytics Consultant at AWS, specializing in the design and implementation of cloud-based data platforms. She builds enterprise-grade solutions across search, data warehousing, and ETL that enable organizations to modernize data ecosystems and derive insights through scalable analytics. She has delivered customer engagements across healthcare, insurance, fintech, and media sectors.
Ramya Bhat is a Data Analytics Consultant at AWS, specializing in the design and implementation of cloud-based data platforms. She builds enterprise-grade solutions across search, data warehousing, and ETL that enable organizations to modernize data ecosystems and derive insights through scalable analytics. She has delivered customer engagements across healthcare, insurance, fintech, and media sectors.
 Chanpreet Singh is a Senior Consultant at AWS, specializing in the Data and AI/ML space. He has over 18 years of industry experience and is passionate about helping customers design, prototype, and scale Big Data and Generative AI applications using AWS native and open-source tech stacks. In his spare time, Chanpreet loves to explore nature, read, and spend time with his family.
Chanpreet Singh is a Senior Consultant at AWS, specializing in the Data and AI/ML space. He has over 18 years of industry experience and is passionate about helping customers design, prototype, and scale Big Data and Generative AI applications using AWS native and open-source tech stacks. In his spare time, Chanpreet loves to explore nature, read, and spend time with his family.