AWS Architecture Blog
Category: Compute
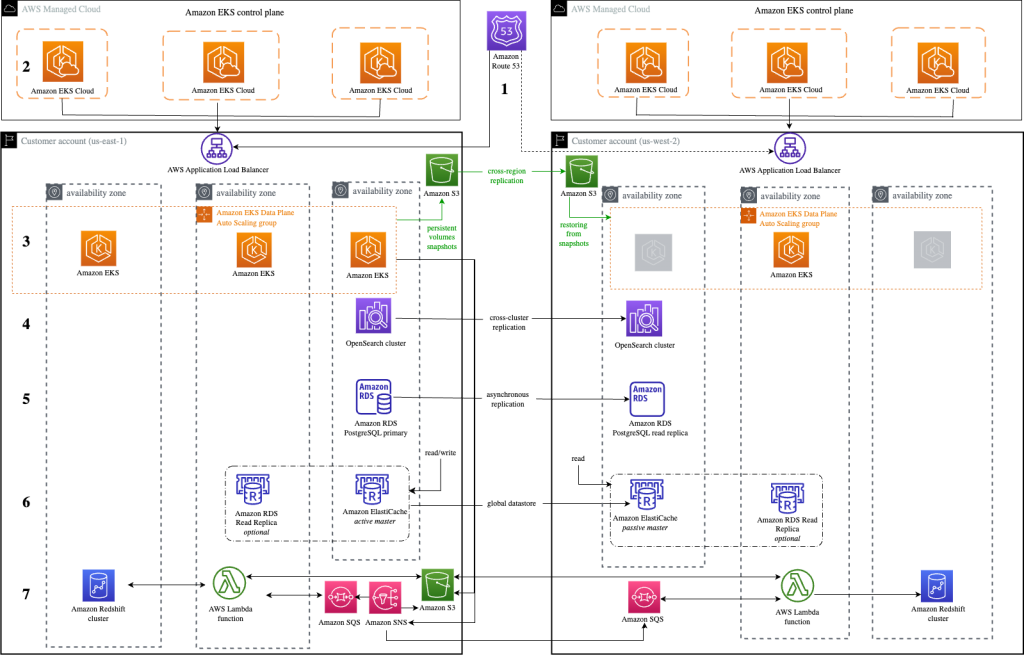
Disaster Recovery Solutions with AWS managed services, Part 3: Multi-Site Active/Passive
Welcome to the third post of a multi-part series that addresses disaster recovery (DR) strategies with the use of AWS-managed services to align with customer requirements of performance, cost, and compliance. In part two of this series, we introduced a DR concept that utilizes managed services through a backup and restore strategy with multiple Regions. […]

Boosting Resiliency with an ML-based Telemetry Analytics Architecture
Data proliferation has become a norm and as organizations become more data driven, automating data pipelines that enable data ingestion, curation, and processing is vital. Since many organizations have thousands of time-bound, automated, complex pipelines, monitoring their telemetry information is critical. Keeping track of telemetry data helps businesses monitor and recover their pipelines faster which results […]

Introducing Client-side Evaluation for Amazon CloudWatch Evidently
Amazon CloudWatch Evidently enables developers to test new features on a small percentage of traffic and gauge the outcome before rolling it out to the rest of their users. Evidently feature flags are defined ahead of your release and, at runtime, your application code queries a remote service to determine whether to show the new […]

Building an event-driven solution for AvalonBay property leasing and search
In this blog post, we show you how to build an event-driven and serverless solution for property leasing and search that is scalable and resilient. This solution was created for AvalonBay Communities, Inc.—a leading residential Real Estate Investment Trusts (REITs). It enables: More than 150,000 multi-parameter searches per day The processing of more than 3,500 […]

Let’s Architect! Architecting for sustainability
Sustainability is an important topic in the tech industry, as well as society as a whole, and defined as the ability to continue to perform a process or function over an extended period of time without depletion of natural resources or the environment. One of the key elements to designing a sustainable workload is software […]

Decreasing incident response time for OutSystems with AWS serverless technology
Leading modern application platform space OutSystems is a low-code platform that provides tools for companies to develop, deploy, and manage omnichannel enterprise applications. Security is a top priority at OutSystems. Their Security Operations Center (SOC) deals with thousands of incidents a year, each with a set of response actions that need to be executed as […]

Text analytics on AWS: implementing a data lake architecture with OpenSearch
Text data is a common type of unstructured data found in analytics. It is often stored without a predefined format and can be hard to obtain and process. For example, web pages contain text data that data analysts collect through web scraping and pre-process using lowercasing, stemming, and lemmatization. After pre-processing, the cleaned text is […]

Streaming the AWS Wickr desktop client with Amazon AppStream 2.0
Amazon Web Services (AWS) customers using AWS Wickr who want to find a way to access their AWS Wickr Windows desktop client though a web browser, can use Amazon AppStream 2.0 to stream the application through to their users. Using this architecture, you can provide lightweight access to the AWS Wickr desktop client for users […]

Genomics workflows, Part 4: processing archival data
Genomics workflows analyze data at petabyte scale. After processing is complete, data is often archived in cold storage classes. In some cases, like studies on the association of DNA variants against larger datasets, archived data is needed for further processing. This means manually initiating the restoration of each archived object and monitoring the progress. Scientists […]

Deploying Oracle RAC in AWS Outposts via FlashGrid Cluster
Amazon Web Services (AWS) customers are deploying AWS Outposts as a fully managed solution that delivers AWS infrastructure and services to on-premises or edge locations for a truly consistent hybrid experience. Those hybrid cloud workloads can require highly available Oracle databases running on- or close-to premises. One way to meet this requirement is Oracle Real […]