AWS Architecture Blog
Category: Analytics
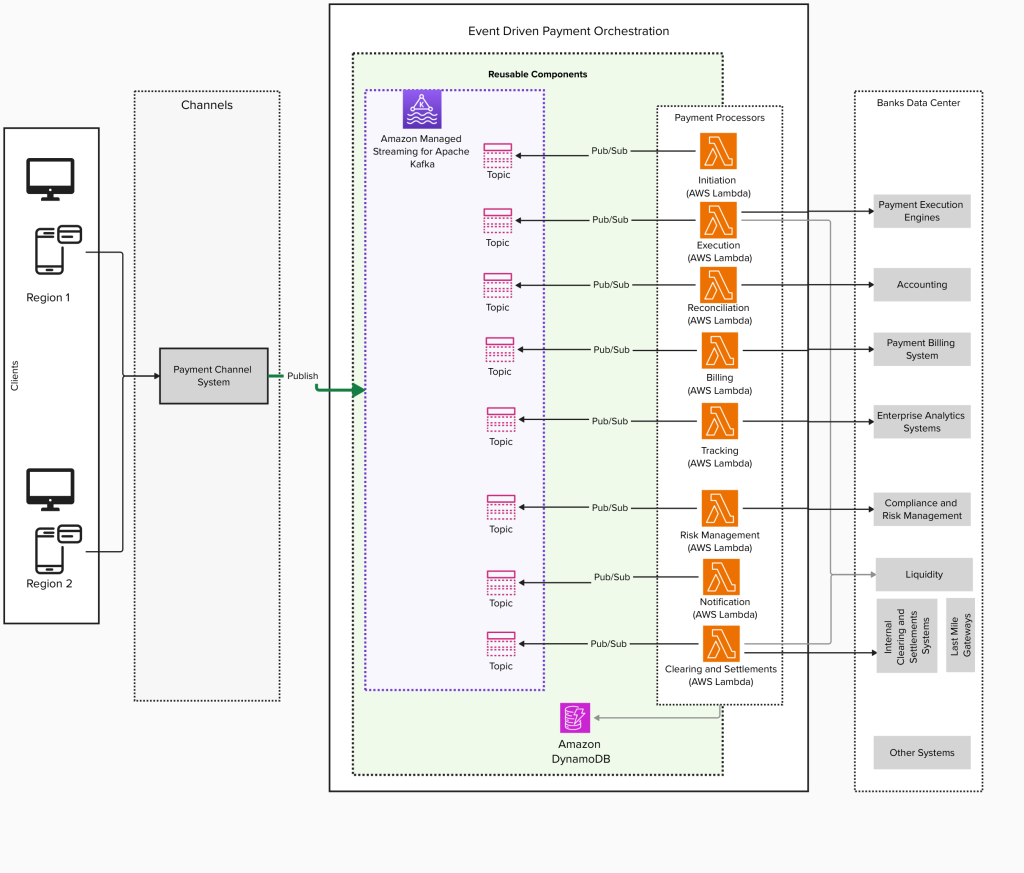
Modernization of real-time payment orchestration on AWS
The global real-time payments market is experiencing significant growth. According to Fortune Business Insights, the market was valued at USD 24.91 billion in 2024 and is projected to grow to USD 284.49 billion by 2032, with a CAGR of 35.4%. Similarly, Grand View Research reports that the global mobile payment market, valued at USD 88.50 […]
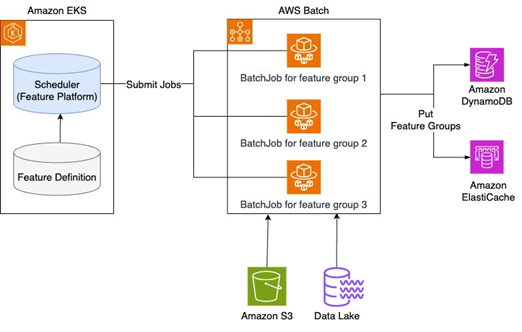
How Karrot built a feature platform on AWS, Part 2: Feature ingestion
This two-part series shows how Karrot developed a new feature platform, which consists of three main components: feature serving, a stream ingestion pipeline, and a batch ingestion pipeline. This post covers the process of collecting features in real-time and batch ingestion into an online store, and the technical approaches for stable operation.

Analyze media content using AWS AI services
Organizations managing large audio and video archives face significant challenges in extracting value from their media content. Consider a radio network with thousands of broadcast hours across multiple stations and the challenges they face to efficiently verify ad placements, identify interview segments, and analyze programming patterns. In this post, we demonstrate how you can automatically transform unstructured media files into searchable, analyzable content.

How Nielsen uses serverless concepts on Amazon EKS for big data processing with Spark workloads
In this post, we follow Nielsen’s journey to build a robust and scalable architecture while enjoying linear scaling. We start by examining the initial challenges Nielsen faced and the root causes behind these issues. Then, we explore Nielsen’s solution: running Spark on Amazon Elastic Kubernetes Service (Amazon EKS) while adopting serverless concepts.

Simplify and automate bill processing with Amazon Bedrock
This post was co-written with Shyam Narayan, a leader in the Accenture AWS Business Group, and Hui Yee Leong, a DevOps and platform engineer, both based in Australia. Hui and Shyam specialize in designing and implementing complex AWS transformation programs across a wide range of industries. Enterprises that operate out of multiple locations such as […]

Top Architecture Blog Posts of 2023
2023 was a rollercoaster year in tech, and we at the AWS Architecture Blog feel so fortunate to have shared in the excitement. As we move into 2024 and all of the new technologies we could see, we want to take a moment to highlight the brightest stars from 2023. As always, thanks to our […]

Let’s Architect! Designing systems for stream data processing
Harnessing the potential of streaming data processing offers the opportunity to stay at the forefront of industries, make data-informed decisions with agility, and gain invaluable insights into customer behavior and operational efficiency.

Use a reusable ETL framework in your AWS lake house architecture
Data lakes and lake house architectures have become an integral part of a data platform for any organization. However, you may face multiple challenges while developing a lake house platform and integrating with various source systems. In this blog, we will address these challenges and show how our framework can help mitigate these issues. Lake […]
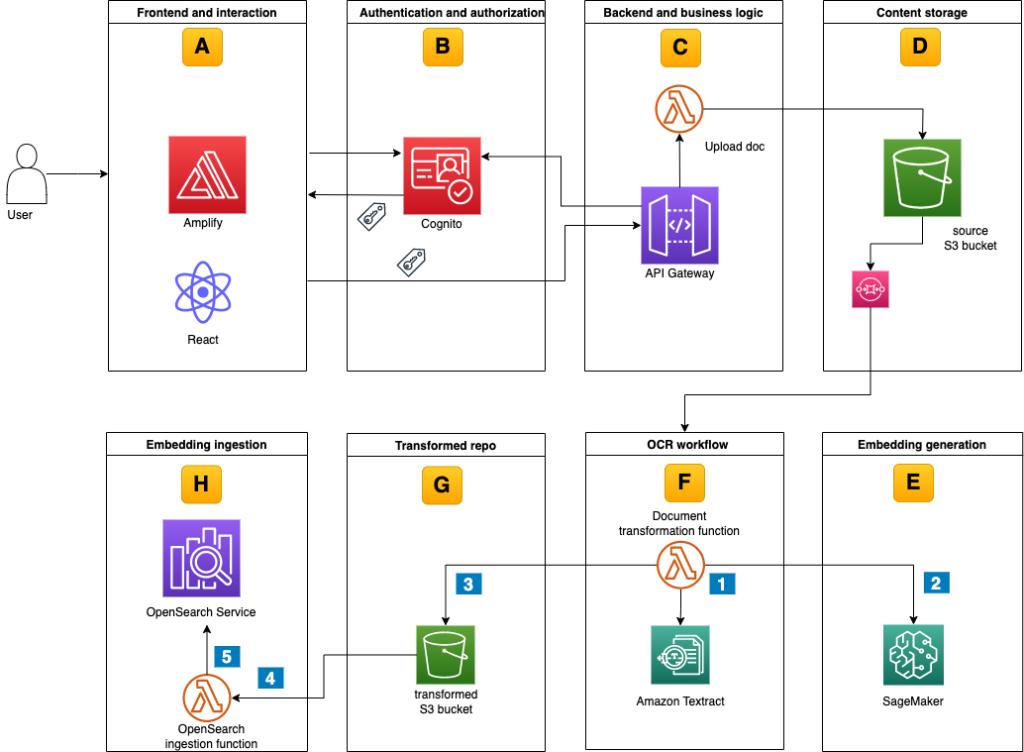
Content Repository for Unstructured Data with Multilingual Semantic Search: Part 2
Leveraging vast unstructured data poses challenges, particularly for global businesses needing cross-language data search. In Part 1 of this blog series, we built the architectural foundation for the content repository. The key component of Part 1 was the dynamic access control-based logic with a web UI to upload documents. In Part 2, we extend the […]

Best practices for implementing event-driven architectures in your organization
Event-driven architectures (EDA) are made up of components that detect business actions and changes in state, and encode this information in event notifications. Event-driven patterns are becoming more widespread in modern architectures because: they are the main invocation mechanism in serverless patterns. they are the preferred pattern for decoupling microservices, where asynchronous communications and event […]