O blog da AWS
Revolucionando a análise de dados de medicamentos com recursos de RAG multimodais do Amazon Bedrock
Por Vivek Mittal, arquiteto de soluções na AWS; Shamika Ariyawansa, arquiteto sênior de soluções de IA/ML na divisão global de saúde e ciências biológicas da Amazon Web Services (AWS), e Shaik Abdulla, arquiteto sênior de soluções.
No setor farmacêutico, empresas de biotecnologia e saúde enfrentam um desafio sem precedentes: gerenciar e analisar eficientemente grandes volumes de dados relacionados a medicamentos provenientes de diversas fontes. Os métodos tradicionais de análise mostram-se inadequados para processar documentação médica complexa, que inclui combinações de textos, imagens, gráficos e tabelas. O Amazon Bedrock oferece recursos como retorno multimodal, funcionalidades avançadas de agrupamento e citações para auxiliar as organizações a obterem respostas de alta precisão.
As organizações farmacêuticas e de saúde processam um grande volume de documentos complexos e dados não estruturados que apresentam desafios analíticos. Documentos de estudos clínicos e trabalhos de pesquisa correlatos geralmente contêm uma combinação complexa de texto técnico, tabelas detalhadas e gráficos estatísticos sofisticados, o que torna a extração automatizada de dados particularmente desafiadora. Os documentos de estudos clínicos apresentam desafios adicionais devido à formatação não padronizada e aos diferentes estilos de apresentação de dados entre as instituições de pesquisa.
Esta publicação apresenta uma solução para extrair insights baseados em dados de documentos de pesquisa complexos, por meio de um aplicativo de amostra que fornece respostas de alta precisão. A ferramenta analisa dados de ensaios clínicos, resultados de pacientes, diagramas moleculares e relatórios de segurança dos documentos de pesquisa, podendo auxiliar as empresas farmacêuticas a acelerar seu processo de pesquisa. A solução oferece citações dos documentos de origem, reduzindo as alucinações e aumentando a precisão das respostas.
Visão geral da solução
O aplicativo de exemplo utiliza o Amazon Bedrock para criar um assistente inteligente de IA que analisa e resume documentos de pesquisa contendo texto, gráficos e dados não estruturados. O Amazon Bedrock é um serviço totalmente gerenciado que oferece diversos modelos fundamentais (FMs, Foundation Models) líderes do setor, além de um amplo conjunto de recursos para criar aplicativos de IA generativa, simplificando o desenvolvimento com foco em segurança, privacidade e IA responsável.
Para equipar os modelos fundamentais (FMs) com informações atualizadas e proprietárias, as organizações usam Retrieval Augmented Generation (RAG), uma técnica que busca dados e aprimora respostas, tornando-as mais relevantes e precisas.
O Amazon Bedrock Knowledge Bases é um recurso RAG totalmente gerenciado que oferece gerenciamento de contexto de sessão e atribuição de fonte. Ele auxilia na implementação completa do fluxo de trabalho do RAG, desde a ingestão até a recuperação e o enriquecimento imediato, eliminando a necessidade de criar integrações personalizadas com fontes de dados ou gerenciar fluxos de dados.
O Amazon Bedrock Knowledge Bases apresenta recursos avançados de análise de documentos, incluindo análise baseada no Amazon Bedrock Data Automation e análise FM, revolucionando a forma como lidamos com documentos complexos. O Amazon Bedrock Data Automation é um serviço totalmente gerenciado que processa dados multimodais eficientemente, sem necessidade de solicitações adicionais. A opção FM analisa dados multimodais utilizando um modelo fundamental, oferecendo a possibilidade de personalizar o prompt padrão usado para extração de dados.
Este recurso avançado transcende a extração básica de texto, segmentando inteligentemente os documentos em componentes distintos – texto, tabelas, imagens e metadados – preservando sua estrutura e contexto. Ao processar formatos compatíveis, como PDF, os modelos fundamentais especializados interpretam e extraem dados tabulares, gráficos e layouts de documentos complexos.
Adicionalmente, o serviço disponibiliza estratégias avançadas de agrupamento, como a fragmentação semântica, que divide o texto inteligentemente em segmentos significativos com base na similaridade semântica calculada pelo modelo de incorporação. Diferentemente dos métodos tradicionais de agrupamento sintático, essa abordagem preserva o contexto e o significado do conteúdo, aprimorando a qualidade e a relevância da recuperação de informações.
A arquitetura da solução implementa esses recursos por meio de um fluxo de trabalho contínuo, iniciando com os administradores fazendo o upload seguro de documentos da base de conhecimento em um bucket do Amazon Simple Storage Service (Amazon S3). Esses documentos são então ingeridos nas bases de conhecimento do Amazon Bedrock, onde um Large Language Model (LLM) processa e analisa os dados ingeridos.
A solução emprega fragmentação semântica para armazenar incorporações de documentos de forma eficiente no Amazon OpenSearch Service para recuperação otimizada. A solução apresenta uma interface amigável construída com o Streamlit, fornecendo uma experiência de bate-papo intuitiva para os usuários finais. Quando os usuários interagem com o aplicativo Streamlit, ele aciona funções do AWS Lambda que lidam com as solicitações, recuperando o contexto relevante da base de conhecimento e gerando respostas apropriadas.
A arquitetura é protegida por meio do AWS Identity and Access Management (IAM), mantendo o controle de acesso adequado em todo o fluxo de trabalho. O Amazon Bedrock usa o AWS Key Management Service (AWS KMS) para criptografar recursos relacionados às suas bases de conhecimento. Por padrão, o Amazon Bedrock criptografa esses dados usando uma chave gerenciada pela AWS. Opcionalmente, você pode criptografar os artefatos do modelo usando uma chave gerenciada pelo cliente.
Essa solução de ponta a ponta fornece processamento eficiente de documentos, recuperação de informações com reconhecimento de contexto e interações seguras com o usuário, fornecendo respostas precisas e abrangentes por meio de uma interface de bate-papo perfeita.
O diagrama a seguir ilustra a arquitetura da solução.
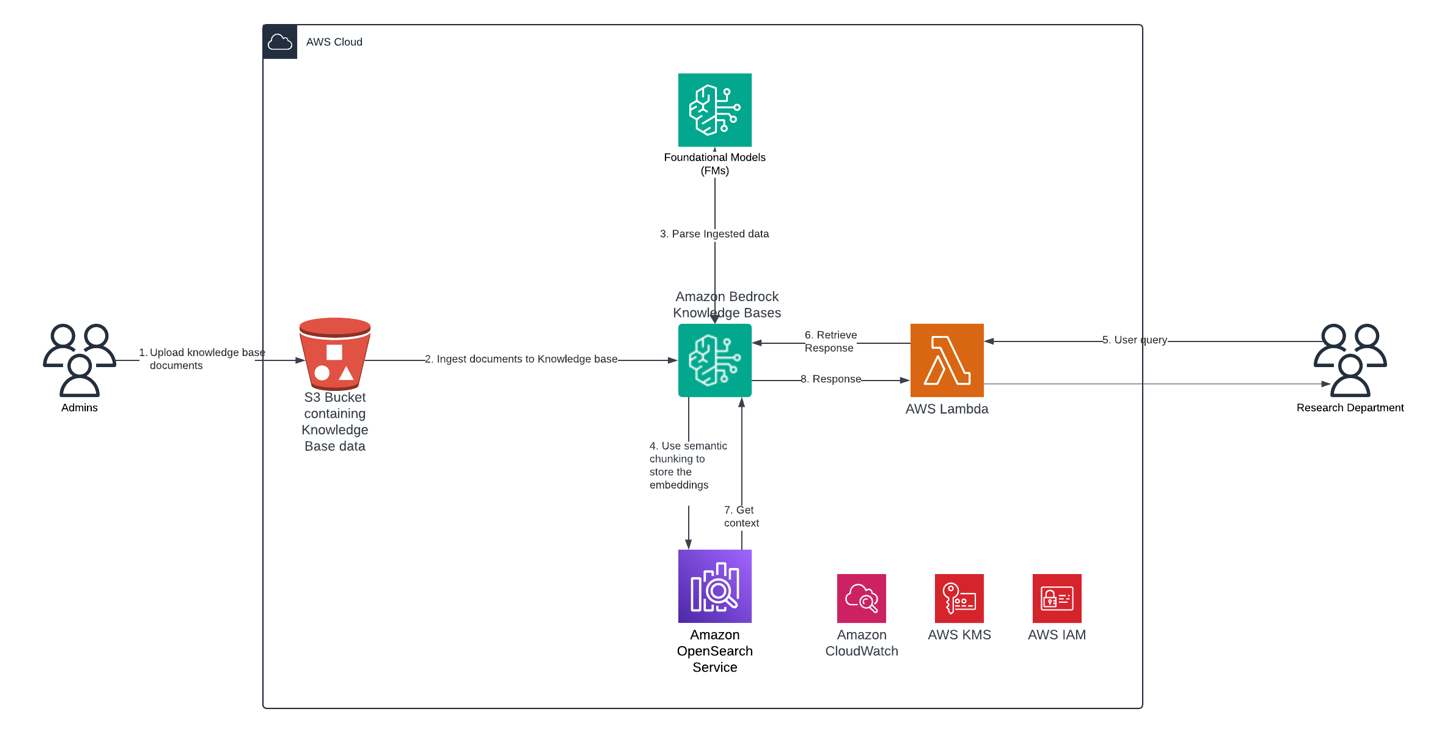
Essa solução usa os seguintes serviços e recursos adicionais:
- A família Anthropic Claude 3 oferece modelos Opus, Sonnet e Haiku que aceitam entradas de texto, imagem e vídeo e geram saída de texto. Eles fornecem uma ampla seleção de pontos de operação de capacidade, precisão, velocidade e custo. Esses modelos compreendem documentos de pesquisa complexos que incluem tabelas, gráficos, tabelas, diagramas e relatórios.
- O AWS Lambda é um serviço de computação sem servidor (serverless) que permite que você execute código sem provisionar ou gerenciar servidores de forma econômica.
- O Amazon S3 é um serviço de armazenamento de objetos altamente escalável, durável e seguro.
- O Amazon OpenSearch Service é um mecanismo de pesquisa e análise totalmente gerenciado para recuperação eficiente de documentos. Os recursos do banco de dados vetorial do OpenSearch Service permitem pesquisa semântica, RAG com LLMs, mecanismos de recomendação e mídia avançada de pesquisa.
- O Streamlit é uma maneira mais rápida de criar e compartilhar aplicativos de dados usando aplicativos de dados interativos baseados na Web em Python puro.
Pré-requisitos
Os pré-requisitos a seguir são necessários para continuar com essa solução. Para esta postagem, usamos a região us-east-1 da AWS. Para obter detalhes sobre as regiões disponíveis, consulte os endpoints e cotas do Amazon Bedrock.
- Uma conta da AWS com um usuário do IAM que tem permissões para Lambda, Amazon Bedrock, Amazon S3 e IAM.
- Acesso ao modelo Claude da Anthropic no Amazon Bedrock. Para obter instruções, consulte Acesse os modelos básicos do Amazon Bedrock.
Implemente a solução
Consulte o repositório do GitHub para ver as etapas de implementação listadas na seção do guia de implementação. Usamos um modelo do AWS CloudFormation para implementar recursos da solução, incluindo buckets S3 para armazenar os dados de origem e os dados da base de conhecimento.
Teste o aplicativo de exemplo
Imagine que você é membro de um departamento de P&D de uma empresa de biotecnologia, e seu trabalho exige a obtenção de insights sobre medicamentos e vacinas a partir de diversas fontes, como estudos de pesquisa, especificações de medicamentos e documentos do setor. Durante sua pesquisa sobre vacinas contra o câncer, você busca informações baseadas em publicações científicas sobre a doença.
Você pode realizar o upload dos documentos de referência para o bucket do S3 e sincronizar a base de conhecimento. Vamos explorar exemplos de interações que demonstram as funcionalidades do aplicativo. As respostas geradas pelo assistente de IA são baseadas nos documentos enviados ao bucket do S3 conectado à base de conhecimento. Vale ressaltar que, devido à natureza não determinística do aprendizado de máquina (ML), suas respostas podem diferir ligeiramente das apresentadas nesta publicação.
Entendendo o contexto histórico
Utilizamos a seguinte consulta: ‘Crie um cronograma dos principais desenvolvimentos na tecnologia de vacinas de mRNA para tratamento de câncer, com base nas informações fornecidas nas seções de histórico’. O assistente analisa diversos documentos e apresenta uma progressão cronológica do desenvolvimento das vacinas de mRNA, incluindo marcos importantes fundamentados nas informações recuperadas do banco de dados vetoriais do OpenSearch Service.
A captura de tela a seguir mostra a resposta do assistente de IA.

Análise de dados complexa
Usamos a seguinte consulta: “Sintetize as informações do texto, figuras e tabelas para fornecer uma visão geral abrangente do estado atual e das perspectivas futuras das vacinas terapêuticas contra o câncer”.
O assistente de IA é capaz de fornecer informações de tipos de dados complexos, o que é habilitado pela análise de FM, enquanto ingere os dados para o OpenSearch Service. Também é capaz de fornecer imagens na atribuição da fonte usando os recursos de dados multimodais das bases de conhecimento Amazon Bedrock.
A captura de tela a seguir mostra a resposta do assistente de IA.
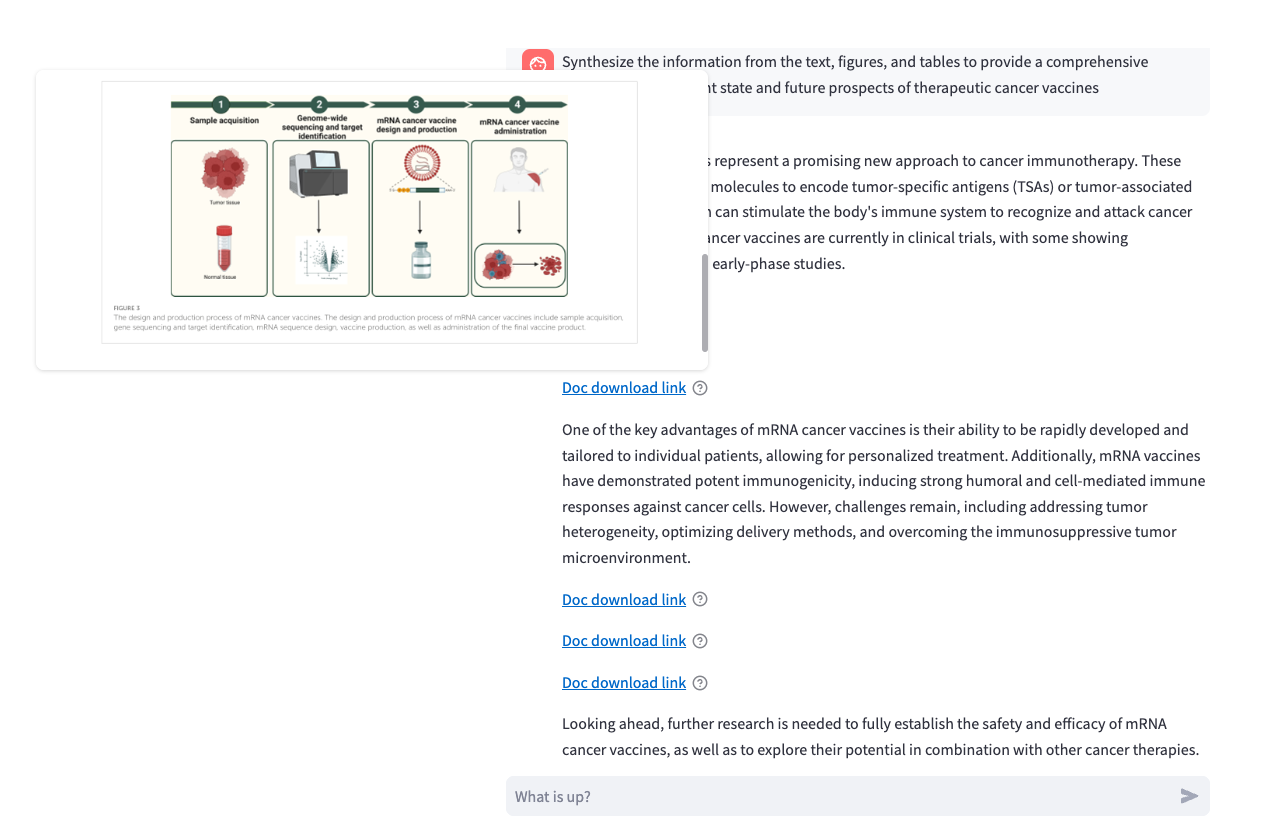
A captura de tela a seguir mostra as imagens fornecidas nas citações quando o cursor do mouse passa sobre o ícone do ponto de interrogação.
Análise comparativa
Usamos a seguinte consulta: “Compare os perfis de eficácia e segurança das vacinas baseadas em MAGE-A3 e NY-ESO-1 conforme descrito no texto e em quaisquer tabelas ou figuras relevantes”.
O assistente de IA usou os fragmentos semanticamente semelhantes retornados do banco de dados vetoriais do OpenSearch Service e adicionou esse contexto à pergunta do usuário, o que permitiu ao FM fornecer uma resposta relevante.
A captura de tela a seguir mostra a resposta do assistente de IA.
Aprofundamento técnico
Usamos a seguinte consulta: “Resuma as vantagens potenciais das vacinas de mRNA sobre as vacinas de DNA para direcionar a angiogênese tumoral, conforme descrito na revisão”.
Com o recurso de fragmentação semântica da base de conhecimento, o assistente de IA conseguiu obter o contexto relevante do banco de dados do OpenSearch Service com maior precisão.
A captura de tela a seguir mostra a resposta do assistente de IA.

A captura de tela a seguir mostra o diagrama que foi usado para a resposta como uma das citações.

A aplicação de exemplo demonstra o seguinte:
- Interpretação precisa de diagramas científicos complexos
- Extração precisa de dados de tabelas e gráficos
- Respostas contextuais que mantêm a precisão científica
- Atribuição da fonte para as informações fornecidas
- Capacidade de sintetizar informações em vários documentos
Esta aplicação permite analisar rapidamente grandes volumes de literatura científica complexa, extraindo insights significativos de diversos tipos de dados, mantendo a precisão e fornecendo atribuição adequada aos materiais de origem. Isso é viabilizado pelos recursos avançados das bases de conhecimento, que incluem:
- Análise FM: auxilia na interpretação de diagramas científicos complexos e na extração de dados de tabelas e gráficos;
- Fragmentação semântica: contribui para respostas contextualizadas de alta precisão;
- Recursos de dados multimodais: possibilitam a inclusão de imagens relevantes como atribuição de fonte.
Esses são alguns dos muitos novos recursos adicionados ao Amazon Bedrock, permitindo que você gere resultados de alta precisão, dependendo do seu caso de uso. Para saber mais, consulte Os novos recursos do Amazon Bedrock aprimoram o processamento e a recuperação de dados.
Preparado para produção
A solução proposta reduz o tempo de implementação e aumenta o valor do processo de desenvolvimento do projeto. As soluções desenvolvidas na nuvem AWS beneficiam-se da escalabilidade inerente à plataforma, mantendo controles robustos de segurança e privacidade.
A estrutura de segurança e privacidade inclui controles refinados de acesso de usuários através do IAM para os serviços OpenSearch Service e Amazon Bedrock. O Amazon Bedrock aprimora a segurança ao fornecer criptografia em repouso e em trânsito, além de opções de rede privada utilizando endpoints de Virtual Private Cloud (VPC).
A proteção de dados é garantida mediante o uso de chaves KMS, e as chamadas e utilização da API são monitoradas por meio de registros e métricas do Amazon CloudWatch. Para informações sobre validação de conformidade específica do Amazon Bedrock, consulte a documentação Validação de conformidade para o Amazon Bedrock.
Para obter detalhes adicionais sobre como mover aplicações RAG para produção, consulte Do conceito à realidade: navegando pela jornada do RAG da prova de conceito à produção.
Limpe
Conclua as etapas a seguir para limpar seus recursos.
- Esvazie os buckets Sources3Bucket e KnowledgeBases3BucketName.
- Exclua a pilha principal do CloudFormation.
Conclusão
Esta publicação demonstrou a eficiente análise multimodal de documentos (texto, gráficos e imagens) utilizando recursos avançados de análise e fragmentação das bases de conhecimento Amazon Bedrock. Ao combinar as capacidades dos modelos fundamentais do Amazon Bedrock, do OpenSearch Service e das estratégias inteligentes de fragmentação através das bases de conhecimento do Amazon Bedrock, as organizações podem transformar documentos de pesquisa complexos em insights pesquisáveis e acionáveis. A integração do agrupamento semântico assegura a preservação do contexto e dos relacionamentos documentais, enquanto a interface intuitiva do Streamlit torna o sistema acessível aos usuários finais através de uma experiência de chat natural. Esta solução não apenas simplifica o processo de análise documental, mas também demonstra a aplicação prática das tecnologias de IA/ML no aprimoramento da descoberta de conhecimento e recuperação de informações. À medida que as organizações continuam gerenciando volumes crescentes de documentos complexos, este sistema escalável e inteligente oferece uma estrutura robusta para maximizar o valor de seus repositórios de documentos.
Embora nossa demonstração tenha se concentrado no setor de saúde, a versatilidade dessa tecnologia vai além de um único setor. O RAG no Amazon Bedrock provou seu valor em diversos setores. Adotantes notáveis incluem marcas globais como Adidas no varejo, Empolis em gerenciamento de informações, Fractal Analytics em soluções de IA, Georgia Pacific em manufatura e Nasdaq em serviços financeiros. Esses exemplos ilustram a ampla aplicabilidade e o potencial transformador da tecnologia RAG em vários domínios de negócios, destacando sua capacidade de impulsionar inovação e eficiência em vários setores.
Consulte o repositório do GitHub para ver a aplicação de agente RAG, incluindo amostras e componentes para criar soluções de agentes RAG. Fique atento a recursos e amostras adicionais no repositório nos próximos meses.
Para saber mais sobre as bases de conhecimento do Amazon Bedrock, confira o workshop do RAG usando o Amazon Bedrock. Comece a usar as bases de conhecimento Amazon Bedrock e deixe sua opinião na seção de comentários.
Referências
- Terapias vacinais para o câncer: antes e agora
- Vacinas terapêuticas contra o câncer: avanços, desafios e perspectivas
- Vacinas contra o câncer: potência adjuvante, importância da idade, estilo de vida e tratamentos
- Avanços recentes nas vacinas de mRNA contra o câncer: enfrentando desafios e aproveitando oportunidades
- Vacinas contra o câncer de ácido nucléico direcionadas à angiogênese relacionada ao tumor. As vacinas de mRNA poderiam constituir uma virada de jogo?
- Descobertas recentes sobre vacinas terapêuticas contra o câncer: uma revisão atualizada
Vacinas contra o câncer: estratégia de seleção de antígenos
Este conteúdo foi traduzido da postagem original do blog, que pode ser encontrada aqui.
Biografia do Autores
 |
Vivek Mittal é arquiteto de soluções na Amazon Web Services, onde ajuda organizações a arquitetar e implementar soluções de nuvem de ponta. Com uma profunda paixão por IA generativa, aprendizado de máquina e tecnologias sem servidor, ele é especialista em ajudar os clientes a aproveitar essas inovações para impulsionar a transformação dos negócios. Ele encontra uma satisfação especial em colaborar com os clientes para transformar suas ambiciosas visões tecnológicas em realidade. |
 |
Shamika Ariyawansa, que atua como arquiteto sênior de soluções de IA/ML na divisão global de saúde e ciências biológicas da Amazon Web Services (AWS), tem um grande foco na IA generativa. Ele ajuda os clientes a integrar a IA generativa em seus projetos, enfatizando a importância da explicabilidade em suas iniciativas orientadas por IA. Além de seus compromissos profissionais, Shamika busca apaixonadamente aventuras de esqui e off-road. |
 |
Shaik Abdulla é arquiteto sênior de soluções, especializado em arquitetar soluções de nuvem em escala empresarial com foco em análise, IA generativa e tecnologias emergentes. Sua experiência técnica é validada pela conquista de todas as 12 certificações da AWS e pelo prestigioso reconhecimento da jaqueta dourada. Ele tem paixão por arquitetar e implementar soluções de nuvem inovadoras que impulsionam a transformação dos negócios. Ele fala em grandes eventos do setor, como o AWS re:Invent e as cúpulas regionais da AWS, onde compartilha ideias sobre arquitetura de nuvem e tecnologias emergentes.
|
Biografia do tradutoes
 |
Daniel Abib é Arquiteto de Soluções Sênior e Especialista em Amazon Bedrock na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e especialização em Machine Learning. Ele trabalha apoiando Startups, ajudando-os em sua jornada para a nuvem. https://www.linkedin.com/in/danielabib/
|
 |
Rodrigo Faria é Especialista de Go-to-Market para IA na AWS, com mais de 10 anos de experiência em ciência de dados, machine learning e inteligência artificial. Ele trabalha com startups focando em IA generativa, escalando conhecimento técnico e direcionando a evolução de produtos com base no feedback do mercado. |