AWS 기술 블로그
SAP OData connection과 AWS Glue로 S3 Tables에서 SAP Data 활용하기
AWS Tech Blog ‘SAP 데이터와 AWS Glue를 활용하여 RISE 워크로드 확장하기’에서 AWS Glue OData 커넥터를 활용하여, SAP Data를 S3에 저장하고 Glue Data Catalog를 통해 Data를 활용하는 방법에 대해서 말씀드렸습니다. 이 블로그는 ‘SAP 데이터와 AWS Glue를 활용하여 RISE 워크로드 확장하기’의 내용을 기반으로 하고 있기 때문에, 이 블로그와 함께 꼭 읽어보시기를 추천드립니다.
Amazon S3 Tables는 분석 워크로드에 최적화된 새로운 스토리지 서비스로, Apache Iceberg 형식을 기본 지원하는 완전 관리형 스토리지 서비스입니다. Iceberg는 대규모 데이터셋의 관리, 스키마 진화, 파티션 관리, 트랜잭션 지원 등 현대적인 데이터 레이크 요구사항을 충족하는 오픈소스 테이블 포맷입니다. S3 Tables는 Apache Iceberg 테이블을 일반 S3 버킷에 저장했을 때와 비교하면 최대 3배 빠른 쿼리 성능과 10배 더 많은 트랜잭션 처리량을 제공하기 때문에, 대규모 데이터 레이크 환경에서도 페타바이트~엑사바이트 규모의 데이터를 효율적으로 처리할 수 있습니다. 또, S3 Tables에 적재된 데이터는 AWS 분석 서비스들과 손쉽게 통합하여 활용할 수 있습니다.
이러한 특징을 가진, S3 Tables에서 SAP 데이터를 활용하면 다음과 같은 이점을 누릴 수가 있습니다.
- SAP 시스템의 대규모 데이터를 S3 Tables의 테이블 버킷에 Iceberg 포맷으로 저장하면, 데이터의 구조화와 관리가 용이해집니다. 이는 데이터 레이크 환경에서 SAP 데이터를 장기 보관하거나 다양한 분석 워크로드에 활용할 때 매우 유리합니다.
- S3 Tables의 높은 데이터 처리 능력은 SAP 데이터처럼 대량의 데이터 분석이 필요한 경우에 적합하며, Amazon Athena, Amazon Redshift, Amazon EMR, Apache Spark 등 다양한 AWS 분석 서비스와 손쉽게 연동할 수 있습니다. SAP 데이터를 S3 Tables에 저장하면, 표준 SQL을 활용해 손쉽게 분석·가공할 수 있으며, SageMaker Lakehouse 등 AI/ML 플랫폼과도 연계가 가능합니다.
- S3 Tables는 데이터 압축, 스냅샷 관리, 불필요한 파일 자동 삭제 등 유지 관리 작업을 자동화하여 운영 부담을 줄이고, 스토리지 비용을 절감할 수 있기 때문에, SAP 데이터의 주기적 적재 및 관리에도 효율적입니다.
- S3 Tables는 엑사바이트급까지 확장 가능하며, 네임스페이스 및 리소스 기반 정책을 통해 SAP 데이터에 대한 세분화된 접근 제어와 데이터 거버넌스를 실현할 수 있습니다.
- Iceberg 포맷의 특성을 활용해 SAP 데이터의 스키마 변경, 파티셔닝, 과거 데이터 버전 조회(시간여행) 등 데이터 진화 관리가 용이합니다. 이는 SAP 시스템에서 점진적으로 변경되는 데이터 모델을 유연하게 지원할 수 있습니다.
Amazon SageMaker Unified Studio는 조직의 모든 데이터를 찾아 액세스하고 모든 사용 사례에서 통합된 도구를 사용하여 작업할 수 있는 단일 데이터 및 AI 개발 환경입니다. SageMaker Unified Studio는 Amazon EMR, AWS Glue, Amazon Athena, Amazon Redshift, Amazon Bedrock 및 Amazon SageMaker AI를 비롯한 기존 AWS 애널리틱스 및 AI/ML 서비스의 기능과 도구를 통합합니다. SageMaker Unified Studio는 S3 Tables도 억세스 할 수 있습니다. 이를 통해서, 고객은 SAP 데이터를 다른 서비스들과 손쉽게 연계하고 통합하여 활용하고 확장할 수 있습니다.
솔루션 개요
SAP에서 제공하는 Demo table인 SFLIGHT 테이블의 데이터를 AWS Glue를 통해서 Amazon S3에 적재합니다. 적재된 데이터를 다시 Glue를 활용해서 S3 Tables의 테이블로 데이터를 로드합니다. 이렇게 만들어진 S3 Tables의 테이블을 SageMaker Unified Studio에서 접근해서 활용합니다.
사전 요구사항
이 게시물에 제시된 솔루션을 완료하기 위해, 다음과 같은 사전 요구사항 단계를 완료해야 합니다:
1. SAP 시스템의 SAP Gateway에서 추출을 위한 ODP(Operational Data Provisioning) 데이터 소스를 구성합니다. 이 블로그에서는 SAP가 제공하는 Demo 테이블 중에 하나인 SFLIGHT 테이블에 대한 OData 서비스를 구성해서 진행합니다.
2. SAP 데이터를 저장할 S3 버킷을 생성합니다.
3. AWS Glue Data Catalog에서 sapgluedatabase라는 데이터베이스를 생성하세요.
4. AWS Glue의 추출, 변환 및 로드(ETL) 작업이 사용할 AWS Identity and Access Management(IAM) 역할을 생성하세요. 이 역할은 Amazon S3 및 AWS Secrets Manager를 포함하여 작업이 사용하는 모든 리소스에 대한 액세스 권한을 부여해야 합니다. 이 게시물의 솔루션에서는 역할 이름을 GlueServiceRoleforSAP로 지정하세요. 다음 정책을 사용하세요:
- AWS 관리형 정책:
- 인라인 정책
2. Glue에서 ETL 작업을 생성할 때, Source나 Target 설정을 위해서는 Data Source와의 Data Connection이 필요합니다. AWS Glue 콘솔에 Data connections 메뉴로 가서 Create connection을 클릭해서 Data Connection을 생성합니다. SAP OData 데이터 소스를 선택하여 SAP 시스템에 대한 AWS Glue 커넥션 GlueSAPOdata를 생성합니다.
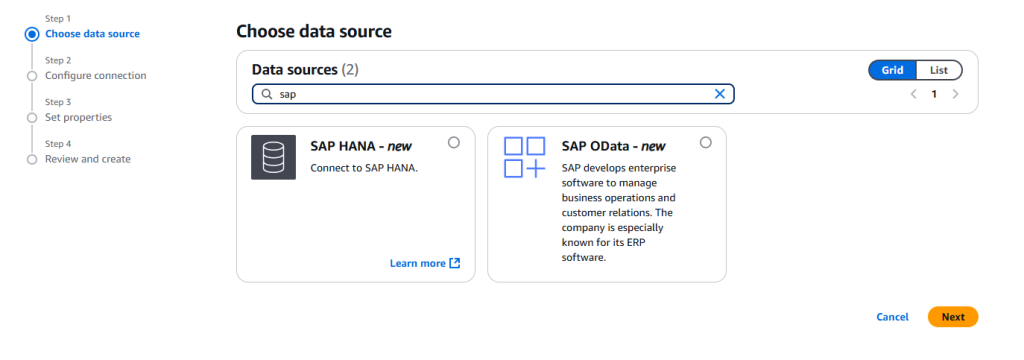
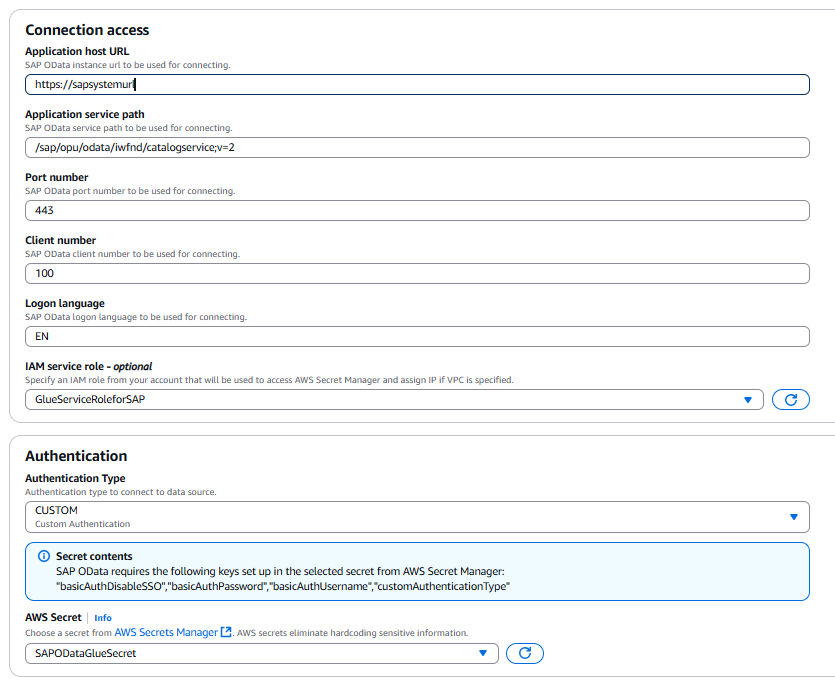
3. 사용자의 SAP 소스에 해당하는 적합한 값을 입력하여 커넥션을 구성합니다.
- Application host URL: 호스트는 SAP 호스트 이름의 인증 및 유효성 검사를 위한 SSL 인증서를 가지고 있어야 합니다.
- Application service path:
/sap/opu/odata/iwfnd/catalogservice;v=2; - Port number: SAP 소스 시스템의 포트 번호
- Client number: SAP 소스 시스템의 클라이언트 번호
- Logon language: SAP 소스 시스템에서 사용하는 로그온 언어
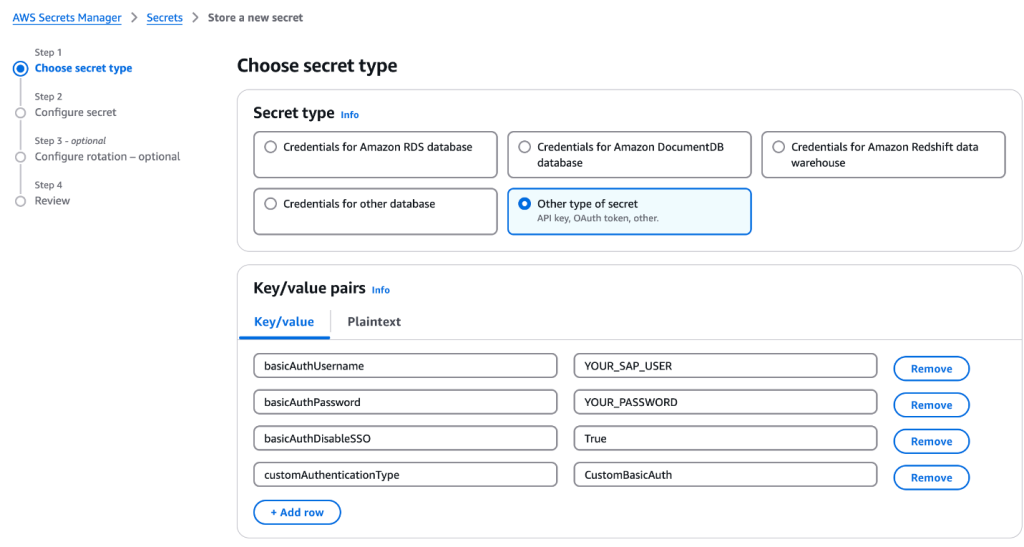
4, 인증 섹션에서 인증 유형(Authentication Type)으로 사용자 지정(CUSTOM)을 선택합니다.
5. 전 단계에서 생성한 AWS Secret인 SAPODataGlueSecret을 선택합니다.
6. 네트워크 옵션으로는 사용자의 SAP 시스템 연결에 사용된 VPC, 서브넷 그리고 보안 그룹을 선택합니다. SAP 시스템 연결에 대한 자세한 설명은 Configure a VPC for your ETL job 링크를 확인하세요.
SAP 데이터 수집을 위한 ETL 작업 생성
Source Node 설정
AWS Glue 콘솔에서 새 Visual Editor AWS Glue 작업을 생성합니다.
1. AWS Glue 콘솔로 이동합니다.
2. ETL Jobs 아래의 탐색 창에서 Visual ETL을 선택합니다.
3. 화면에서 Visual ETL을 선택하여 시각적 편집기에서 작업을 생성합니다.
4. 이 게시물에서는 기본 이름값을 Material Master Job으로 편집하고 저장을 클릭합니다.
5. Visual 탭에서 ‘+’ 기호를 선택하여 노드 추가 메뉴를 엽니다. SAP를 검색하고 SAP OData Source를 추가합니다.
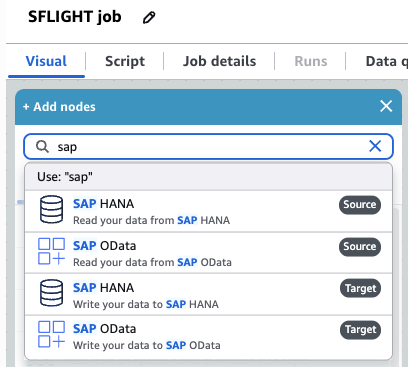
6. 방금 추가한 노드를 선택하고 이름을 입력합니다. 여기서는 SFLIGHT를 사용하겠습니다.
- SAP OData Connection의 경우
GlueSAPOData연결을 선택합니다. - Service Name에서, SAP SFLIGHT 테이블에 대해서 생성한 OData 서비스 이름을 선택합니다. OData 서비스 이름이 선택되면 Entity Set을 선택할 수 있습니다.
- 필드는 따로 선택하지 않고 기본값을 사용합니다.
- 필터 섹션에
limit 100을 입력하여 데이터를 제한합니다. - Full transfer를 선택합니다.
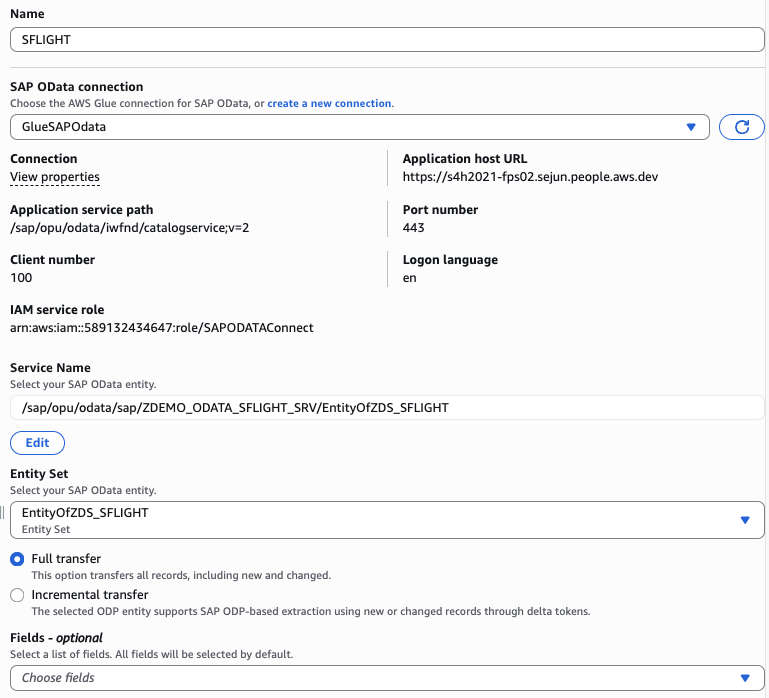
Table Transformation
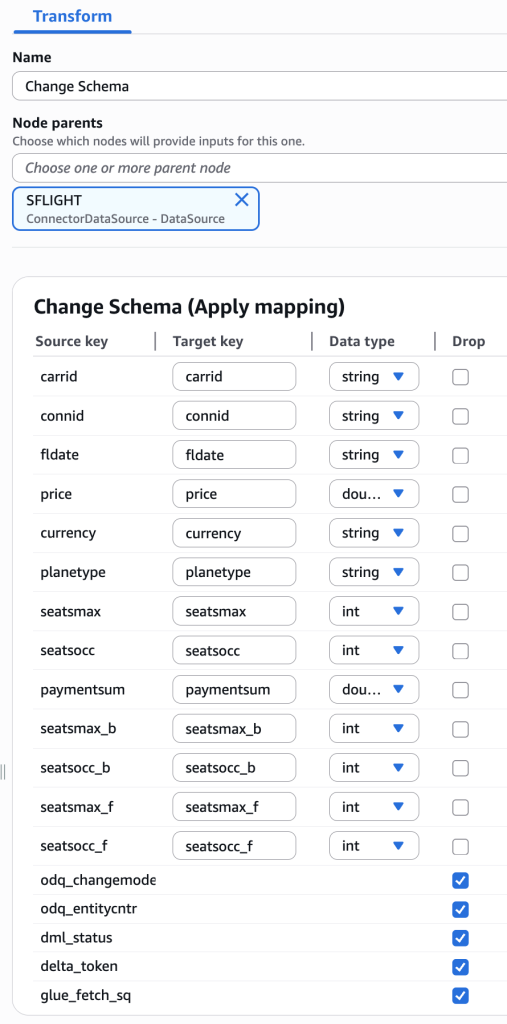
1. 테이블에 대한 변형이 필요할 경우, Glue의 Transform 기능을 활용할 수 있습니다. ‘+’기호를 선택하여, Transforms에서 Change Schema를 추가합니다.
2. Node의 이름은 Change Schema로 설정하고, Node parents로 SFLIGHT를 선택합니다.
3. SAP Table의 Field는 종종 그 자체로는 가독성이 떨어지는 경우가 있어서, 필드의 이름을 이해가 쉬운 이름으로 바꾸거나, 필요에 따라 적절한 Data Type을 설정할 수 있습니다.
4. 본 블로그에서 Delta Update는 다루지 않기 때문에, Drop 체크 박스에 odq_changemode, odq_entitycntr, dml_status, delta_token, glue_fetch_sq를 선택합니다.
Target Node 설정
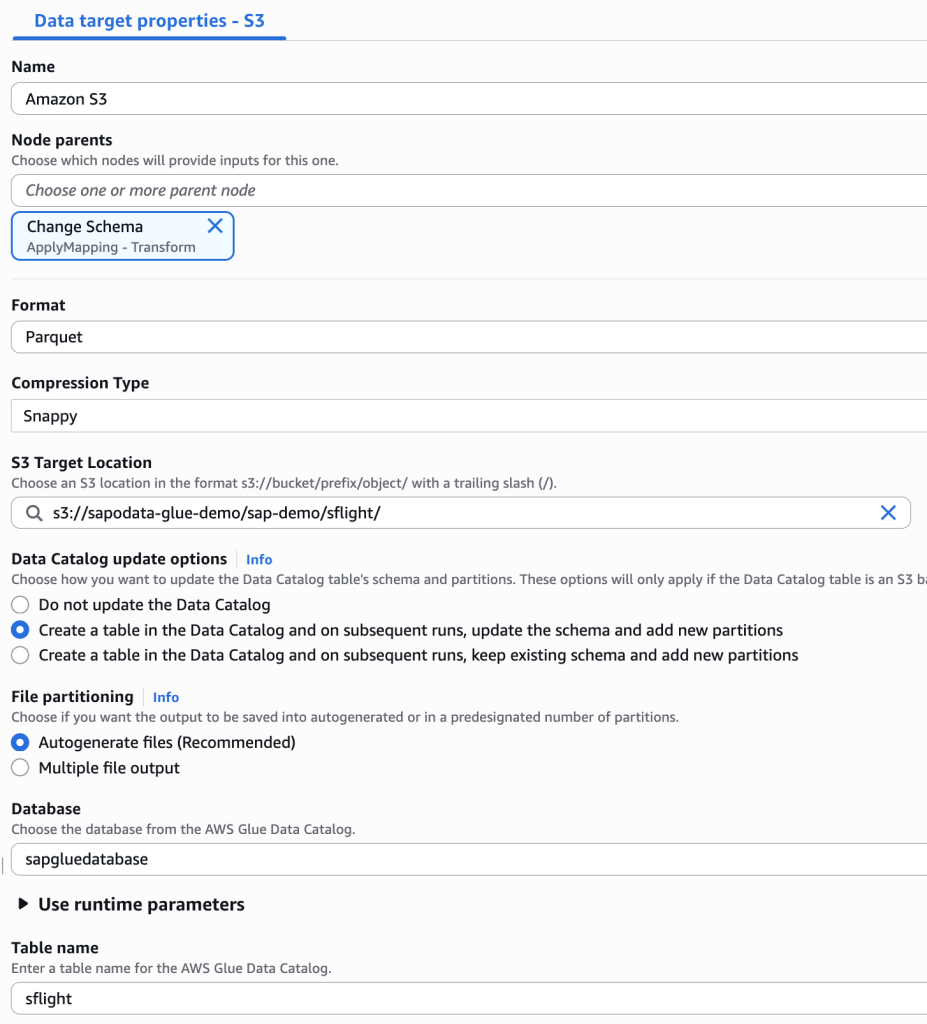
S3 bucket을 Target으로 하는 노드를 생성하고, 옵션은 다음과 같이 설정합니다.
- Node parents:
Change Schema - Format:
Parquet - Compression Type:
Snappy - S3 Target Location:
사전에 생성한 S3 bucket을 입력하고, 적절한 경로를 설정합니다. - Data Catalog update options는 Create a table in the Data Catalog and on subsequent runs, update the schema and add new partitions를 선택합니다.
- Database는 앞서 생성한 AWS Glue database인
sapgluedatabase를 선택합니다. - Table name은
sflight를 입력합니다.
최종 생성한 작업은 아래와 같습니다.
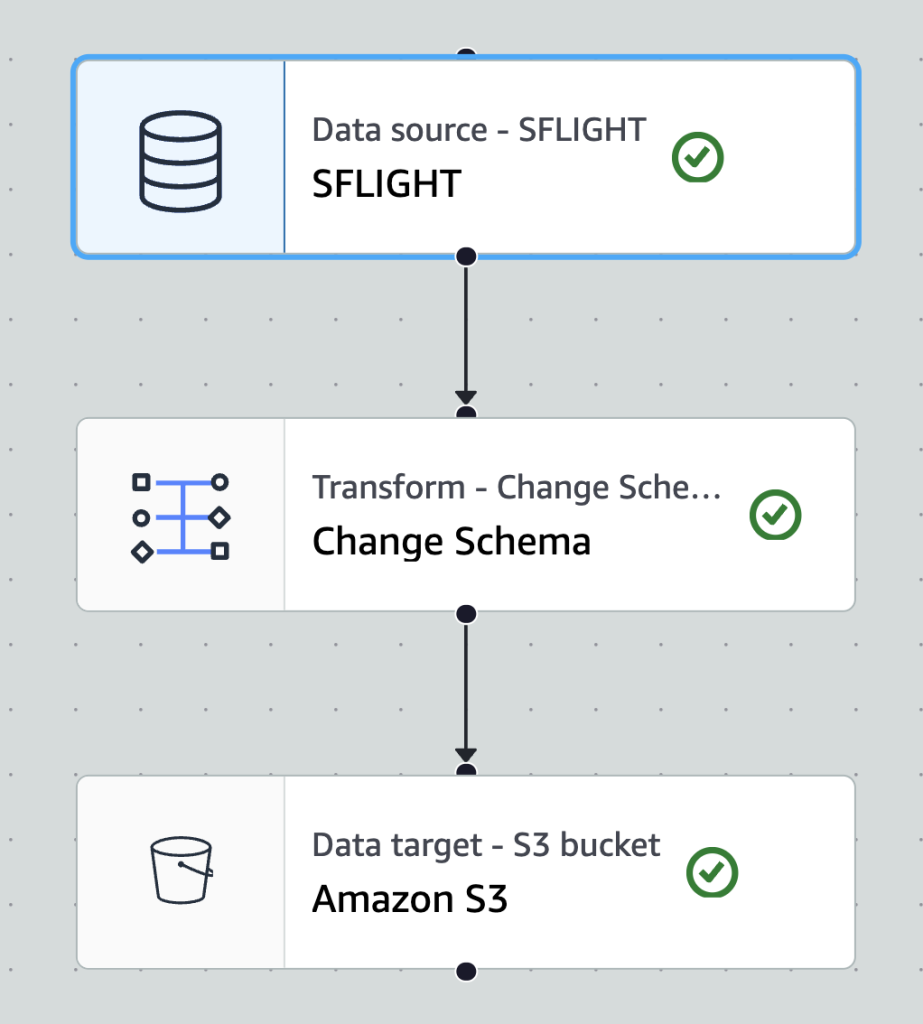
S3 Tables 테이블 생성하기
테이블 버킷(Table Bucket) 생성
1. Amazon S3 콘솔 메뉴에서 Table buckets을 선택합니다. AWS analytics 서비스들이 테이블 버킷을 억세스 할 수 있도록 설정이 되어 있지 않다면, Enable integration 버튼을 눌러서 활성화를 시켜줍니다.

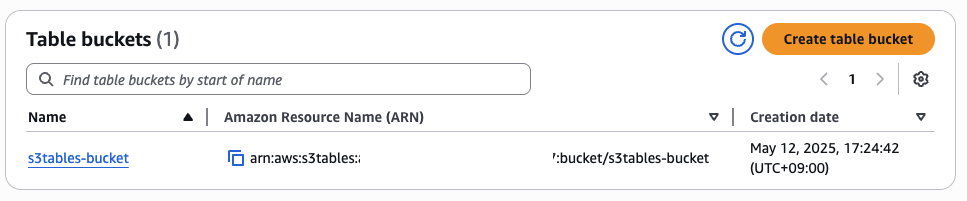
2. Create table bucket을 클릭하고, 테이블 버킷 이름을 입력해서 버킷을 생성합니다.
3. 생성된 테이블 버킷의 ARN을 확인합니다. 이것은 뒷부분에서 S3 Tables 테이블에 데이터를 기록할 때 사용하게 됩니다.
네임스페이스(Namespace) 및 테이블(Table) 생성
Amazon S3 Tables에서 테이블은 Amazon S3 REST API, AWS SDK, AWS CLI 또는 통합 쿼리 엔진을 사용하여 테이블을 생성할 수 있습니다. 여기서는 Athena를 통해 간단히 생성하는 것을 소개합니다. 다른 방법은 사용 설명서 링크를 확인하여 주세요.
1. 이전 단계에서 생성한 S3 Table bucket을 선택하여 이동합니다.
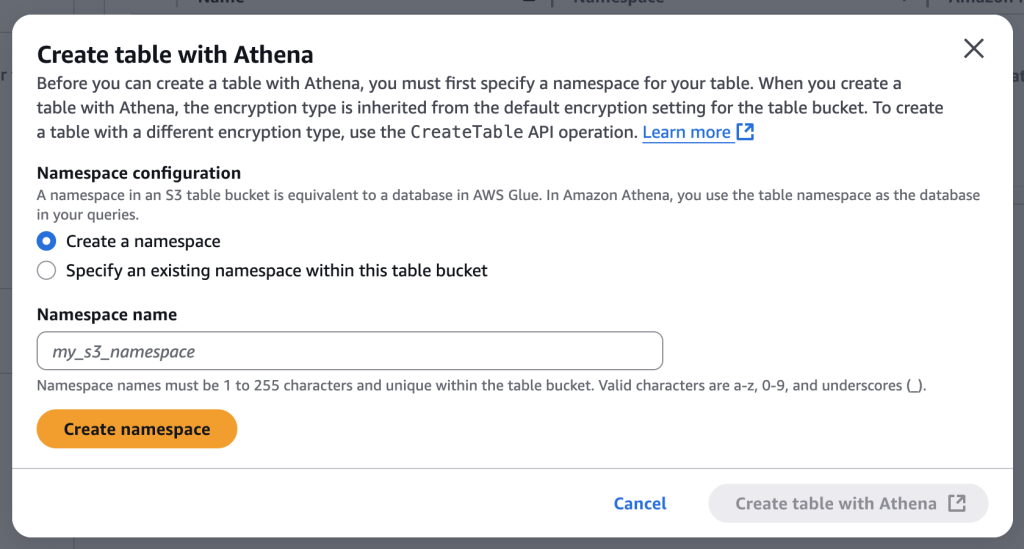
2. Create table with Athena를 선택하여 Athena에서 테이블을 만들 수 있도록 합니다.

3. Create table with Athena를 누르면, 테이블이 사용할 Namespace 생성을 위한 창이 나타납니다. Namespace name을 입력하고, Create namespace를 눌러서 Namespace를 생성합니다. Namespace가 생성된 후, 자동으로 Athena로 이동하여 테이블 생성 작업을 시작합니다.
4. Athena를 처음 사용한다면, Athena 쿼리 수행 결과 저장을 위한 S3 Bucket 설정이 필요합니다. Settings 탭에서 Manage를 눌러서 설정을 합니다.

5. 결과를 저장할 S3 Bucket을 선택합니다.

6. Athena 쿼리 편집기는 Table 생성을 위한 기본 SQL 문을 제공합니다. 이 내용을 참고해서 sflight 테이블을 생성합니다.
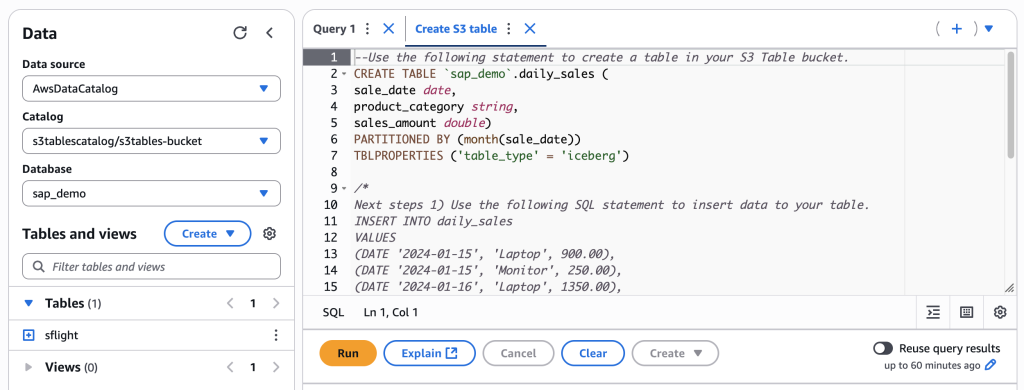
S3 Tables 테이블에 데이터 적재
AWS Glue 콘솔에서 새 AWS Glue Job을 생성합니다.
1. AWS Glue 콘솔로 이동합니다.
2. ETL Jobs 아래의 탐색 창에서 Script Editor를 선택합니다.
3. Engine은 Spark를 선택하고, Options는 Start fresh를 선택합니다. 다른 편집기가 편하시다면, 따로 작성하신 다음 업로드하셔도 됩니다. Create Script를 눌러서 편집기를 시작합니다.
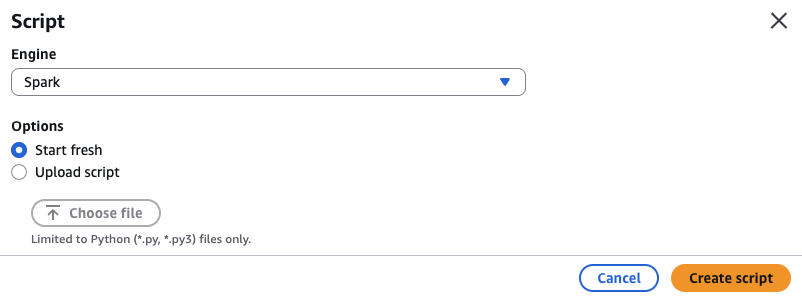
4. 아래의 내용을 참고하여 Job 스크립트를 생성합니다. 스크립트에 추가로 입력해야 할 내용들은 다음과 같습니다.
- S3 Table Bucket ARN: 앞 단계에서 생성한
테이블 버킷의 ARN입력 - Glue Data Catalog Database: 앞에서 생성한
sapgluedatabase입력 - Glue Data Catalog Table: 앞에서 생성한
sflight입력 - S3 Tables table full name:
<S3 Tables bucket>.<Namespace>.<Table>형식으로 입력. 여기서는s3tables-bucket.sap_demo.sflight를 사용
5. Amazon S3 Tables Catalog for Apache Iceberg Runtime Jar 파일 아래의 링크에서 다운 받아서 S3 Bucket에 저장합니다. https://mvnrepository.com/artifact/software.amazon.s3tables/s3-tables-catalog-for-iceberg-runtime
6. 생성한 ETL 작업의 Advanced Properties에서 앞에서 다운 받은 jar 파일의 경로를 설정하고, ETL job을 실행합니다.

SageMaker Unified Studio와 통합
SageMaker Unified Studio에서도 S3 Tables 테이블을 직접 억세스 할 수 있습니다. 시작하려면 SageMaker Unified Studio의 도메인과 프로젝트가 필요합니다. 상세한 내용은 AWS 설명서에서 Amazon SageMaker Unified Studio 도메인 생성을 참조하십시오.
SageMaker Unified Studio에서 S3 Table의 테이블을 억세스하기 위해서는 AWS Lake Formation에서 Data permission 설정이 필요합니다.
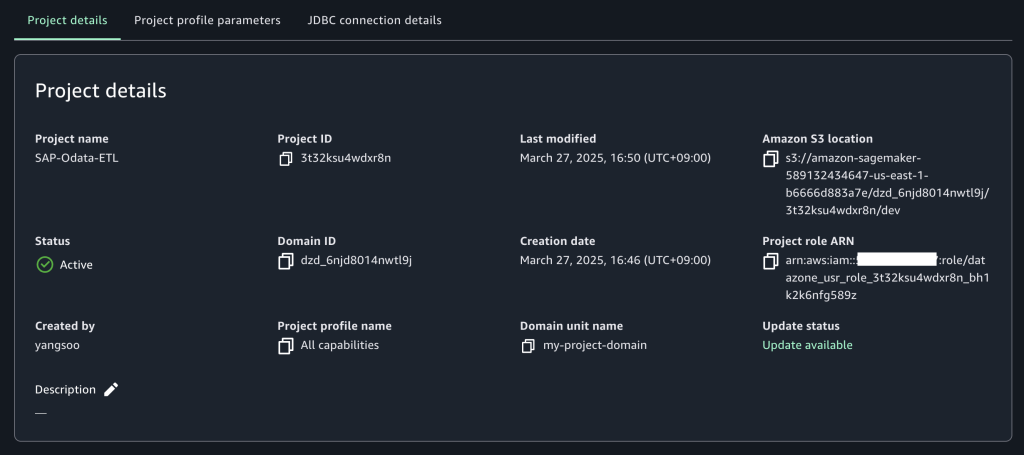
1. 프로젝트를 생성한 후 프로젝트 개요로 이동하고 프로젝트 세부 정보로 스크롤하여 Project role ARN(Amazon Resource Name)을 기록해 둡니다.
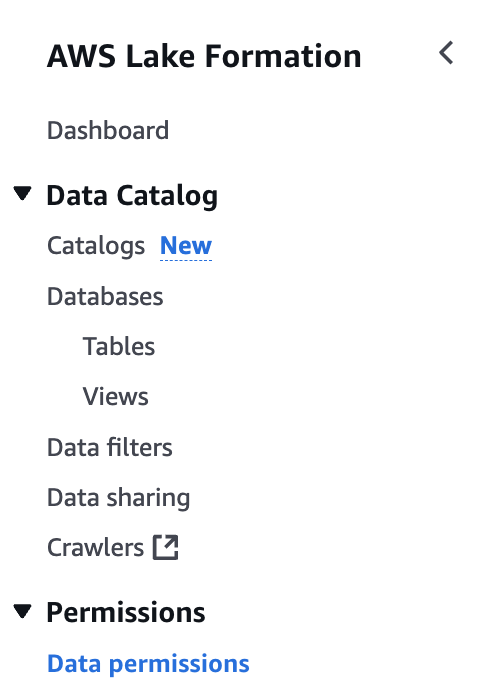
2. Lake Formation 콘솔로 이동하여, 좌측 메뉴에서 Data permissions를 선택합니다.
3. 우상단의 Grant 버튼을 눌러 권한 설정을 합니다.
- IAM users and roles: 앞에서 기록한
SageMaker Unified Studio Project Role ARN을 선택 - Named Data Catalog resources 선택
- Catalogs:
S3 Tables bucket선택 - Databases:
S3 Tables의 Namespace선택 - Tables: 이 경로에 생성되는 모든 table에 대한 억세스가 가능하도록
All tables선택 - Table permissions: SageMaker Unified Studio에 부여하고 싶은 적절한 권한 설정
![]()
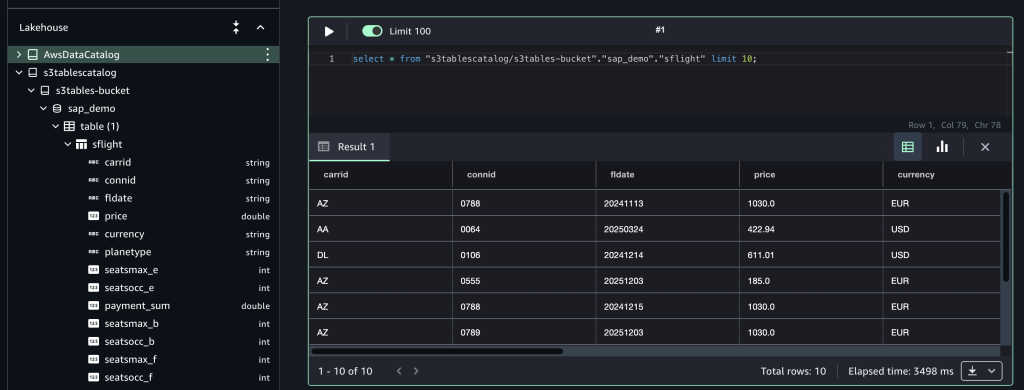
4. SageMaker Unified Studio로 돌아오면 프로젝트 페이지의 왼쪽 탐색 패널에 있는 Data 메뉴의 Lakehouse에서 s3tablescatalog와 그 아래의 bucket, 데이터베이스, 테이블을 볼 수 있습니다. 우측의 Action을 선택하면 Amazon Athena, Amazon Redshift 또는 JupyterLab 노트북에서 S3 Tables 테이블에 대한 쿼리 방법을 선택할 수 있습니다.
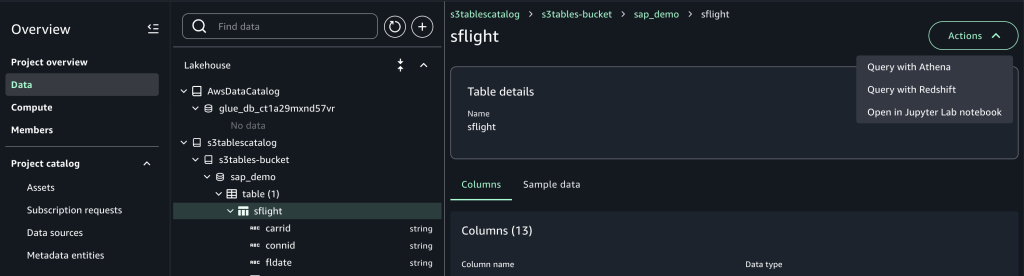
다음 Athena를 통해서, 쿼리를 실행한 결과입니다.
정리하기
비용이 계속해서 발생하는 것을 방지하기 위해 AWS 계정에서 사용한 AWS Glue 작업, SAP OData 커넥션, Glue 데이터 카탈로그, Secrets Manager secret, IAM 역할, S3 bucket에 저장된 콘텐츠, 그리고 S3 버킷, S3 Tables 버킷과 테이블 및 SageMaker Unified Studio 리소스를 정리합니다.
결론
이 게시물에서 SAP 테이블에서 Glue를 통해서 내려받은 데이터를, Apache Iceberg 기반의 고성능 스토리지 서비스인 S3 Tables에 적재하고, 이를 SageMaker Unified Studio로 통합해서 사용하는 방법에 대해서 알아보았습니다. S3 Tables과 SageMaker Unified Studio는 대용량의 SAP 데이터에 대한 빠르고 효율적인 분석과 이용을 가능하게 해줍니다.
이를 통해 간편하고 안전하게 SAP 데이터와 Non-SAP 데이터를 통합한 데이터 레이크 환경을 구축하여 조직의 데이터 기반 경영 활동에 활용할 수 있습니다.