AWS 기술 블로그
삼성계정 서비스, 대규모 트래픽 속 Amazon MSK 를 이용한 무 중단 Database 스키마 전환
이 글은 삼성전자의 기술블로그(Samsung Tech Blog)에 기재된 원문을 인용하여 작성 하였습니다. 대 규모 서비스에서 민감한 정보의 암호화 및 스키마 전환을 서비스 영향 없이 이뤄낸 AWS 사용사례를 AWS 한국 기술 블로그를 통해 게시되도록 지원해 주신 삼성전자 김종구 프로님에게 감사의 말씀을 드립니다.
시작하며,
약 18억 명의 사용자를 기반으로 운영되는 글로벌 계정 서비스인 삼성 계정에서는 24/7 대규모 트래픽을 안정적으로 처리하고 있으며, 삼성 계정에 관련된 모든 작업은 무중단으로 진행하고 있습니다. 이러한 제약사항 속에서 사용자 Database 내 개인식별정보들을 Kafka 를 이용해 서비스 영향 없이 스키마 전환 및 데이터의 컬럼 단위 암호화를 진행했던 경험에 대해 공유하고자 합니다.
삼성 계정은?
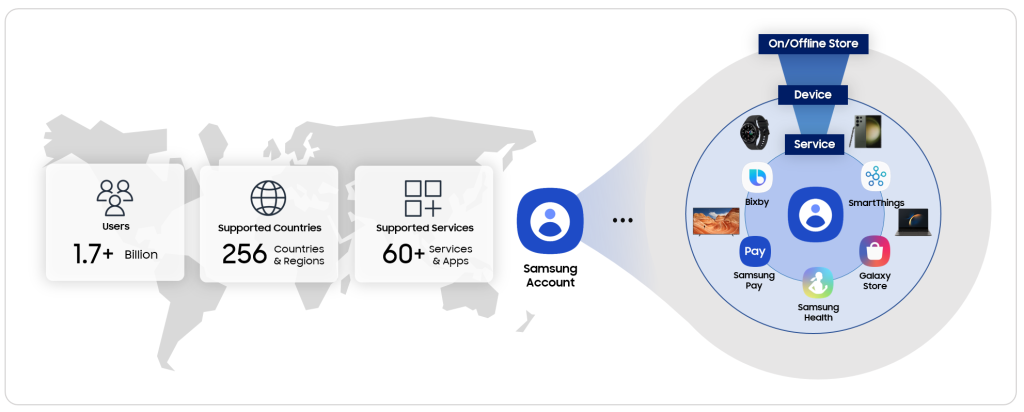
<그림 1>
삼성 계정은 전 세계 18억 사용자 계정을 기반으로 256개국에서 60개 이상의 서비스와 앱을 하나로 이어주는 계정 서비스 입니다. Samsung Pay, SmartThings, Samsung Health 등 여러 분이 잘 알고 계시는 삼성의 서비스뿐 아니라 Mobile, Wearable, TV, PC 등 다양한 기기에서도 활용되고 있습니다.
<그림 2>
삼성 계정은 수 많은 사용자 개인 정보들을 안전하게 보호하기 위해 많은 노력들을 하고 있습니다. 저희는 더 나아가 클라우드 벤더의 해킹이나 물리적 데이터베이스의 탈취 등 최악의 상황에서도 개인정보를 안전하게 지킬 수 있는 방법을 고민을 하였고, D-KMS 라는 삼성전자 표준 암·복호화 솔루션을 사용하여 Database 내 모든 사용자 개인정보 데이터들을 Column 단위 암호화 하기로 결정했습니다. 지금부터는 운영중인 서비스의 암호화 작업을 어떻게 진행 했는지 설명 드리겠습니다.
암호화 설계 시 제약사항 1
서비스 무중단 암호화 및 마이그레이션
삼성 계정 시스템은 70여개의 연관 서비스와 앱들이 전 세계에서 24/7 서비스되는 환경이기 때문에 장애 혹은 서비스 성능 저하가 생긴다면 영향이 매우 커 작업이 굉장히 조심스럽습니다. 또한, 운영되고 있는 Database 와 서비스에 직접 작업을 하는 것은 I/O 부하를 발생시키고, 문제 발생 시 복구가 굉장히 어렵기 때문에 아래와 같은 아키텍쳐를 고안하였습니다.
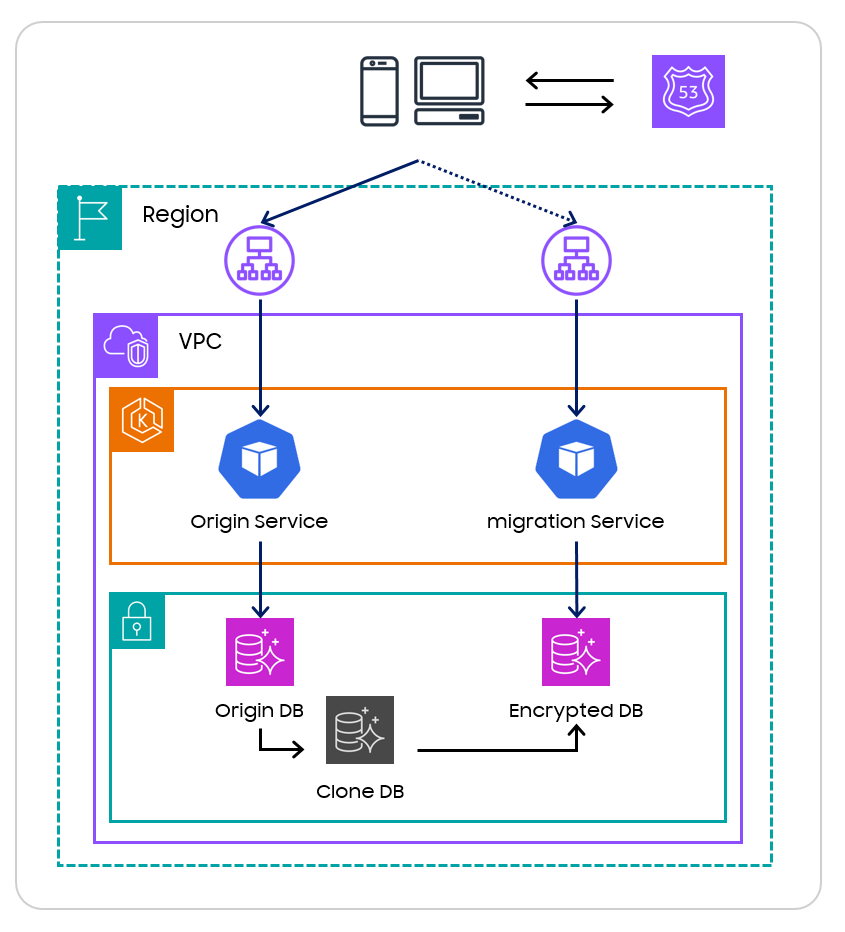
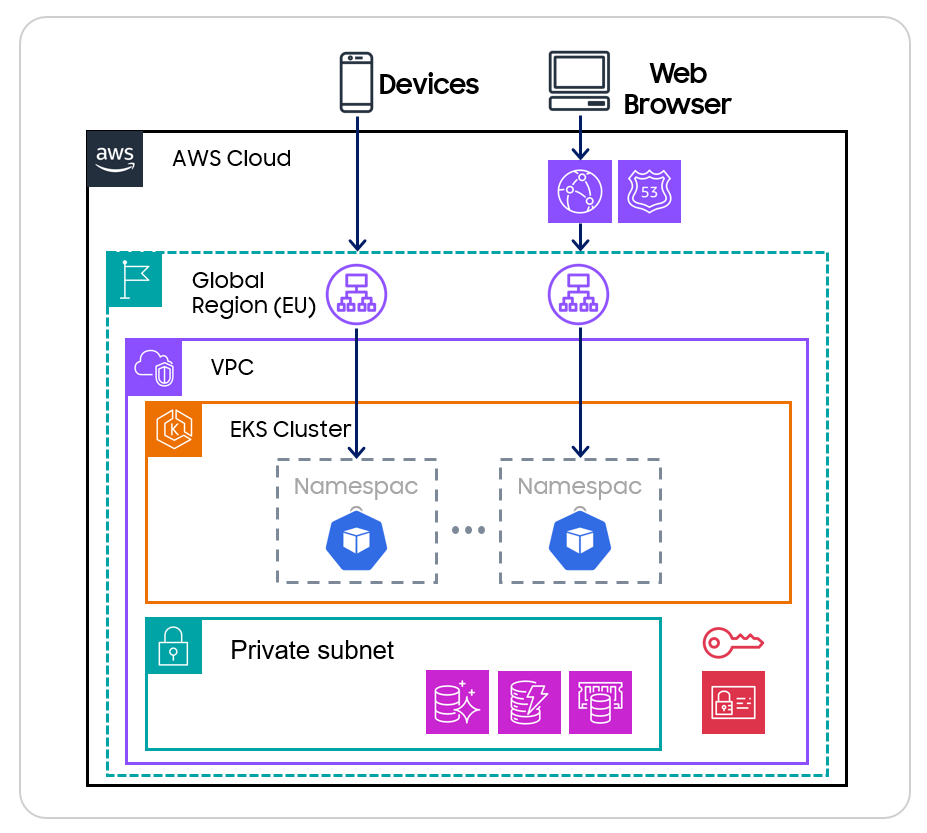
<그림 3>
기존 운영 중인 서비스에 영향을 최소화 하기 위해 운영 DB 를 복제하여 오프라인 상태의 복제 DB 를 생성하였습니다. 그리고 복제 DB 의 모든 데이터들을 암호화하면서 암호화 DB 로 마이그레이션하도록 설계하였습니다. 그 후, 해당 암호화 DB 를 바라보는, 암·복호화 로직이 포함된 서비스들을 미리 배포해두고, 트래픽을 전환 하는 방식을 설계하였습니다.
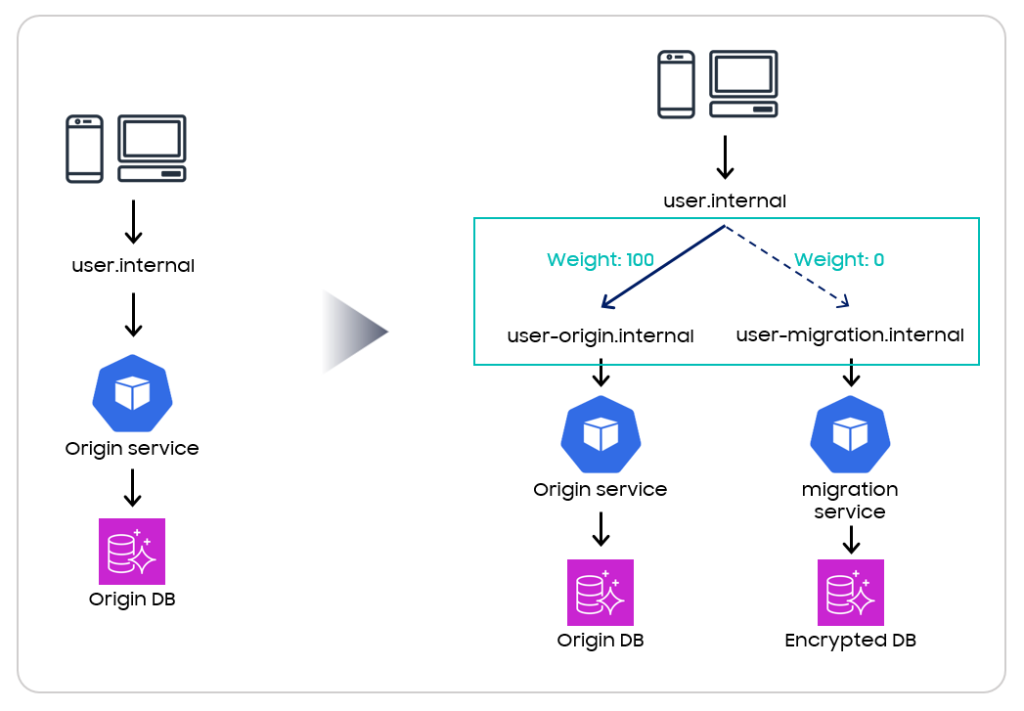
<그림 4>
트래픽 전환 방법은 기존 서비스인 Origin service 와 암·복호화 로직이 포함된 migration service 를 바라보는 internal DNS 를 생성하여 DNS 의 Layer 를 한 겹 추가하고, 이후 전환 시점에서 상위 DNS 의 타겟에 대한 weight 를 조절하는 방식으로 아주 간단하게 대규모 서비스의 트래픽을 전환할 수 있었습니다.
이와 같은 설계를 통해 기존 운영 서비스에 영향 없이 암호화를 진행할 수 있었습니다.
암호화 설계 시 제약사항 2
빠른 성능의 대용량 데이터 마이그레이션 및 암호화
삼성 계정에는 총 4개 권역에 이미 500억 개 이상의 데이터가 저장되어 있고, 추가적으로 전 세계에서 24시간 내내 사용자의 생성/수정/삭제 정보들이 들어오고 있습니다. 그렇기 때문에 빠른 속도로 대용량 데이터를 암호화 및 마이그레이션하고 사용자 트래픽을 실시간으로 암호화할 수 있어야 합니다. 이 상황에서 일반적인 Background 에서의 Batch 를 이용한 암호화 방법은, 마이그레이션만 권역 당 한달 이상이 예상되어 고려할 수 없었습니다.
결론적으로는, 위 제약사항을 해결하기 위해 분산 이벤트 스트리밍 플랫폼인 Kafka 를 이용한 파이프라인을 구축하기로 결정 하였습니다. Kafka 를 이용한 암호화 및 마이그레이션 파이프라인 구축을 위해 저희는 Kafka cluster 로 AWS managed 서비스인 MSK 를 사용하였고, 메시지 처리를 위해 오픈소스인 Kafka connect 및 connector 를 주로 사용하였습니다.
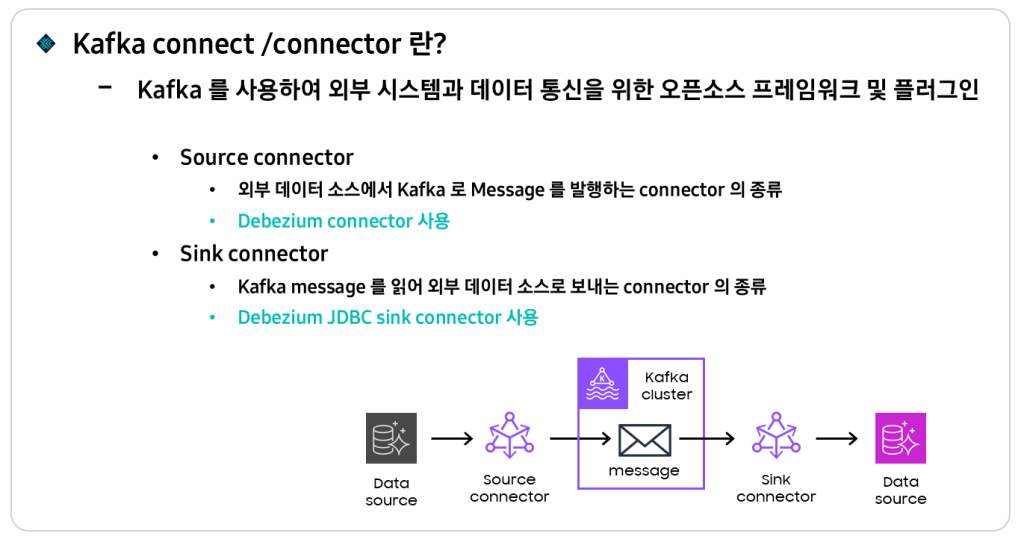
<그림 5>
Kafka connect 와 connector 에 대해 간단하게 설명 드리면, Connect 는 Kafka 를 이용하여 외부와 데이터를 주고 받기 위한 오픈소스 프레임워크를 말하고, Connector 는 그 안에서 동작하는 플러그인 입니다. Connector 는 크게 2가지 형태로 분류됩니다. 외부의 데이터 소스를 Kafka message 로 발행하는 Source connector 와 Kafka message 를 읽어 외부로 보내는 Sink connector 가 있습니다. 저희는 각각 Debezium connector 와 Debezium JDBC sink connector 를 사용하였습니다.

<그림 6>
Debezium connector 는 CDC 와 Snapshot 기능을 지원합니다. Database 의 변경 점을 캡쳐해서 Kafka message 로 발행해주거나, Database 의 특정 시점의 모든 데이터를 Kafka message 로 스트리밍하는 동작을 제공합니다. Debezium JDBC sink connector 는 Kafka message 를 읽어 Database 에 업데이트 하는 기능을 제공합니다. Debezium connector 를 사용한 최종 구현 모습은 다음과 같습니다.
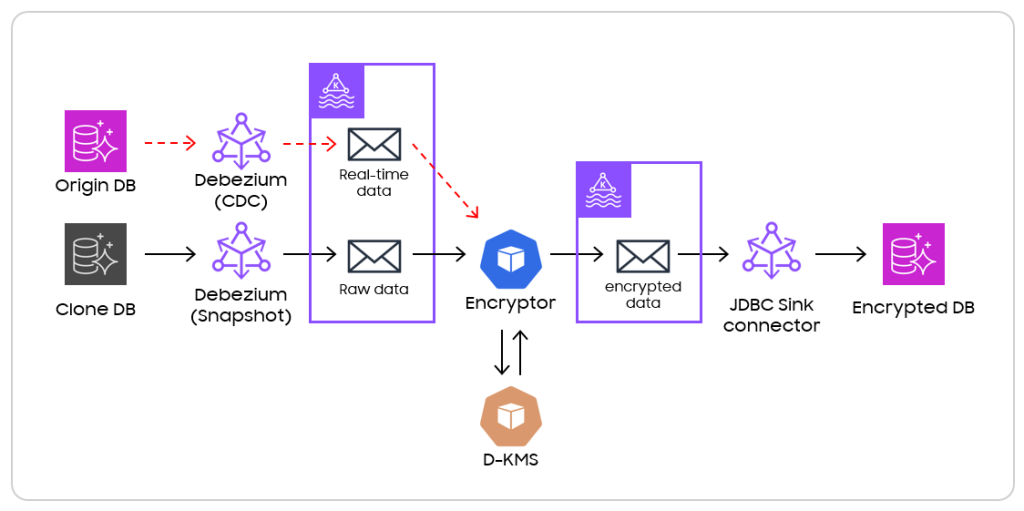
<그림 7>
일단, 복제 DB 를 생성하고 Debezium connector 붙여 Snapshot 을 진행 했습니다. Raw 데이터들이 message 로 발행되면 암호화를 진행하도록 파이프라인을 구축했습니다. 여기서 문제가 하나 있는데요, 복제 DB 는 기존 DB의 복제를 뜬 시점의 데이터만 가지고 있기 때문에 복제 시점 이후에 들어온 실시간 트래픽들과 Gap 이 생깁니다. 그래서 DB 복제를 진행하기 전에 운영 DB 에 또 다른 Debezium 을 붙여서 CDC 로 실시간 트래픽들을 Message 로 쌓아놓고, 복제 DB 생성과 암호화 마이그레이션을 진행하였습니다.
그 이후 마이그레이션이 완료되면, 쌓아 놓았던 Message 를 소모하면서 실시간 데이터까지 따라 잡도록 파이프라인을 구축했습니다.
암호화 설계 시 제약사항 3
데이터베이스 스키마 변경이 포함 된 마이그레이션
암호화 및 마이그레이션을 진행할 때, 암호화와 함께 Database 의 스키마 변경이 동시에 진행되어야 했습니다. 그 이유는, Plain text 를 암호화하면 Key rotation, 난수 삽입 등으로 인해 암호화 결과 값이 매번 달라지게 됩니다. 이 때, 암호화 대상인 데이터가 DB Index 의 key 로 활용되고 있을 경우 문제가 발생합니다.
실제로는 같은 값이지만 저장된 데이터는 다르기 때문에 Index 가 올바르게 동작하지 못합니다. 결국 Index 동작을 위한 고정된 암호화 값을 위해 Hashing 이라는 추가적인 암호화가 필요했고 1개의 개인정보 데이터를 2개의 컬럼에 나누어 저장해야 했습니다.

<그림 8>
결과적으로는, 원본 DB 와 암호화 DB 의 스키마가 달라지기 때문에, 암호화와 동시에 데이터 안의 DB 스키마를 수정하도록 하였습니다.

<그림 9>
구현은 Debezium connector 가 발행하는 Json 형태의 Message 를 이용하였습니다. 가장 위에 DB 스키마가 들어가고, 그 아래 메타 데이터와 변경 전, 후의 데이터가 들어갑니다. 굉장히 직관적이기 때문에 자유롭게 데이터를 가공하고, 빠르게 전달할 수 있습니다. 위 Message 형태의 특성을 이용해 아래와 같이 파이프라인을 구현하였습니다.
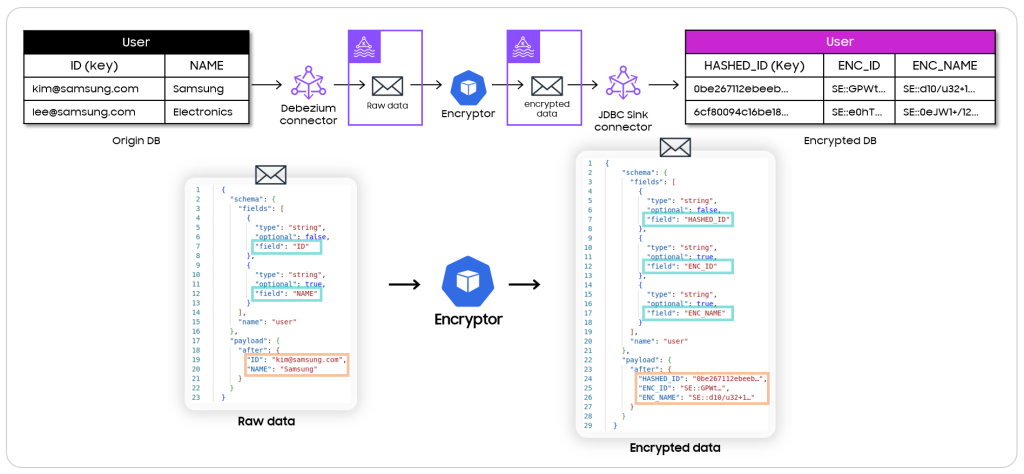
<그림 10>
원본 DB 의 변경점을 Debezium connector 가 메시지로 발행하면, 이를 암호화 서비스가 읽어와 Hashing 및 암호화를 진행하고 암호화 DB 의 스키마에 맞게 가공한 뒤 Kafka message 로 재발행하여, 최종적으로는 암호화 DB 에 문제없이 업데이트 되도록 하였습니다.
암호화 설계 시 제약사항 4
문제 발생 시 빠르게 복구 할 수 있는 롤백 플랜
작업을 할 때 가장 중요한 것은 빠르고 문제없이 복구 할 수 있는 롤백 플랜이 있어야 한다는 것입니다. 운영에서 작업하기에 앞서 개발, 검증 환경에서 여러 번 테스트를 하더라도, 운영 계에서의 돌발 상황은 100% 예측할 수는 없기 때문에, 우리는 항상 롤백 플랜을 준비하여야 합니다.
롤백 플랜을 준비할 때 가장 중요한 부분은 데이터 정합성입니다. 신규 서비스로 트래픽을 전환하게 되면 새로운 서비스와 Database 로 사용자 생성/수정/삭제에 관련된 모든 트래픽들이 들어가게 됩니다. 이 때, 문제 발생 시 롤백을 위해 단순히 트래픽을 기존 서비스로 전환하게 되면, 잠깐 동안 신규 서비스로 들어왔던 데이터들은 유실이 됩니다.
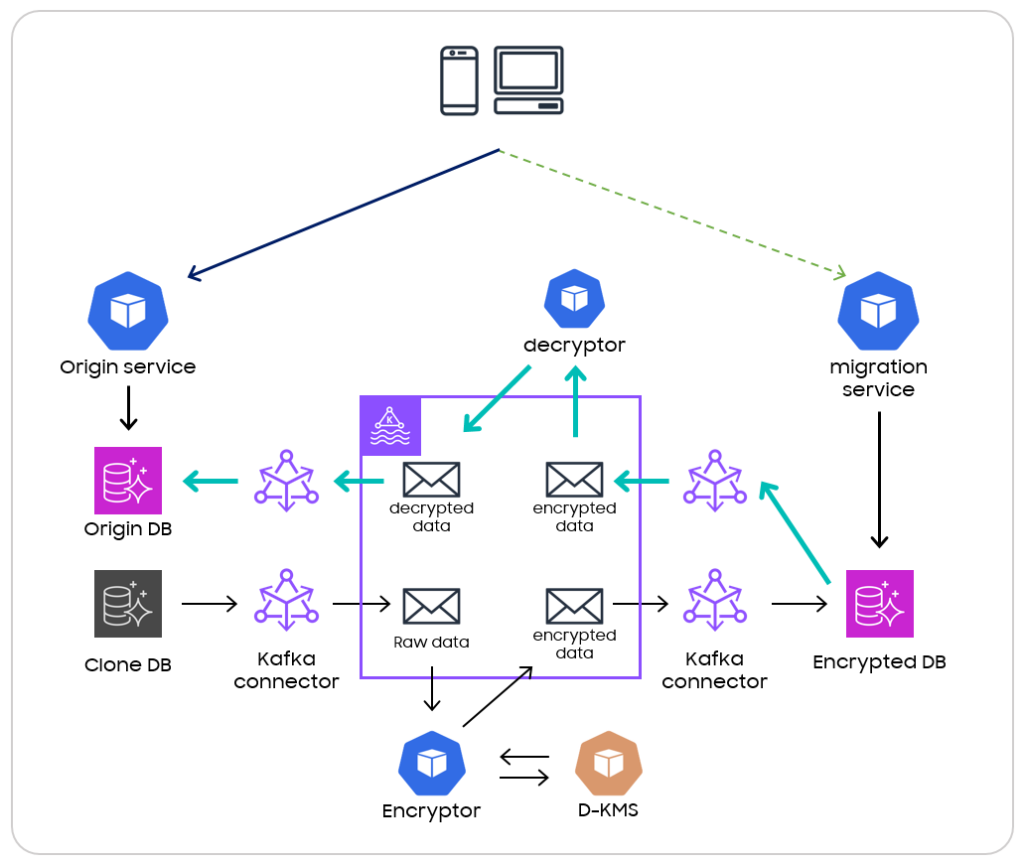
<그림 11>
해당 데이터의 유실을 막기위해서는, 양 쪽 데이터베이스를 실시간으로 동기화 해주어야 합니다. 양방향 동기화를 위해 암호화 파이프라인에 정 반대의 동작을 하는 역방향 복호화 파이프라인을 구축하여, 암호화 DB 로 들어오는 트래픽을 기존 DB 에 실시간으로 동기화할 수 있도록 진행했습니다. 결과적으로, 데이터 정합성을 신경 쓰지 않고 빠른 트래픽 전환이 가능했습니다.
최종적으로, 모든 아키텍쳐 드라이버들을 기반으로 설계하고 구현한 모습은 아래와 같습니다.
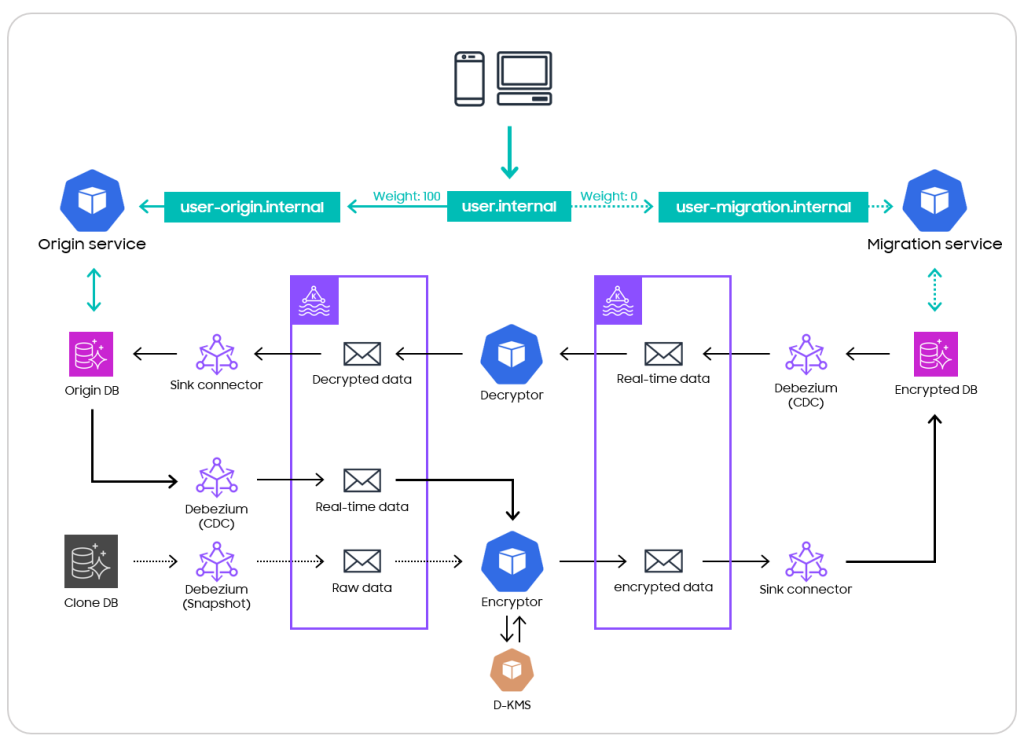
<그림 12>
DNS 의 Weight 조절을 이용해 트래픽을 전환하고, 복제 Database 로 부터 암호화 DB 를 생성 한 뒤에, 원본 Database 와 암호화 Database 가 실시간으로 서로를 동기화 하도록 구현한 모습 입니다.
실제 작업 과정과 결과
마지막으로, 준비 과정과 결과에 대해 간략히 정리해 보겠습니다.

<그림 13>
마무리하며,
이번 프로젝트를 준비하며, 대용량 데이터와 트래픽을 운영 서비스에 영향을 주지 않고 암호화해야 한다는 점이 가장 걱정이었습니다. 하지만 Kafka의 뛰어난 확장성과 안정성을 다시금 체감하며, 우려를 기회로 바꿀 수 있었습니다. 함께 고민하고 도와준 동료들 덕분에 더 수월하게 마칠 수 있었던 것 같고, 앞으로도 이런 경험들이 하나씩 쌓여 더 나은 결과로 이어지길 기대해 봅니다.
이상으로 Samsung Account 팀의 김종구 였습니다. 감사합니다.