AWS 기술 블로그

Amazon EKS 환경에서 다양한 Spark 애플리케이션 제출 방법 비교하기
Amazon EKS 환경에서는 다양한 방법으로 Spark 애플리케이션을 제출할 수 있습니다. 현재 Amazon EKS 환경에서 지원하는 Spark 애플리케이션 제출 방법에는 spark-submit CLI를 활용하는 방법, Spark Operator를 활용하는 방법, AWS CLI 활용하는 방법, EMR Container Controller를 활용하는 방법, 총 4가지 방법이 존재합니다. 본 게시글에서는 Amazon EKS 환경에서 Spark 애플리케이션을 제출할 수 있는 4가지 방법에 대해서 소개하여, 고객분들이 […]

Amazon CloudWatch Agent와 collectd 시작하기
이 글은 AWS Cloud Operations & Migrations Blog에 게시된 Getting Started with CloudWatch agent and collectd by Helen Ashton and Kevin Lewin을 한국어 번역 및 편집하였습니다. 관찰 가능성(Observability)은 워크로드의 상태, 사용량, 성능 및 고객 경험을 이해하는 데 도움이 됩니다. 관찰 가능성은 사고 감지 및 사고 해결 지원부터 새로운 기능이 사용자 및 워크플로에 미치는 영향을 이해하는 […]

Amazon VPC 트래픽 미러링을 통해 상용 환경 트래픽을 테스트 환경으로 미러링하기
이 글은 AWS Networking and Content Delivery Blog에 게시된 Mirror production traffic to test environment with VPC Traffic Mirroring by Simone Pomata를 한국어 번역 및 편집하였습니다. 많은 기업에서 최종 사용자의 서비스 사용 경험에 영향을 주지 않으면서 상용 환경 트래픽을 테스트 환경으로 복제하기를 원합니다. 이를 트래픽 미러링(Traffic mirroring) 또는 트래픽 섀도잉(Traffic shadowing)이라고 합니다. 상용 환경 트래픽으로 새 […]

클라우드 데이터베이스 엔지니어의 역할 강화
이 글은 AWS Database Blog에 게시된 Empowering the role of the cloud database engineer by Wendy Neu and Rajib Sadhu을 한국어 번역 및 편집하였습니다. 자동화는 전통적인 데이터베이스 관리자(DBA)에게 보상이자 선물이었습니다. DBA의 대부분의 기존 역할에는 프로비저닝, 접근 관리, 유지 관리, 모니터링, 고가용성 및 백업/복원이 포함됩니다. 시리즈의 1부에서 우리는 그 역할이 플랫폼보다는 애플리케이션에 더 집중하도록 어떻게 진화했는지에 […]

Amazon CloudWatch를 이용한 Amazon Aurora I/O Optimized 기능에 대한 비용 절감 예상하기
이 글은 AWS Database Blog에 게시된 Estimate cost savings for the Amazon Aurora I/O-Optimized feature using Amazon CloudWatch Sarabjeet Singh을 한국어 번역 및 편집하였습니다. Amazon Aurora는 고급 상용 데이터베이스의 속도와 가용성을 오픈 소스 데이터베이스의 간편함과 비용 효율성을 결합한 관계형 데이터베이스 서비스입니다. Aurora는 MySQL과 PostgreSQL 오픈 소스 데이터베이스 엔진을 지원합니다. Aurora 스토리지는 공유 클러스터 스토리지 아키텍처로 […]
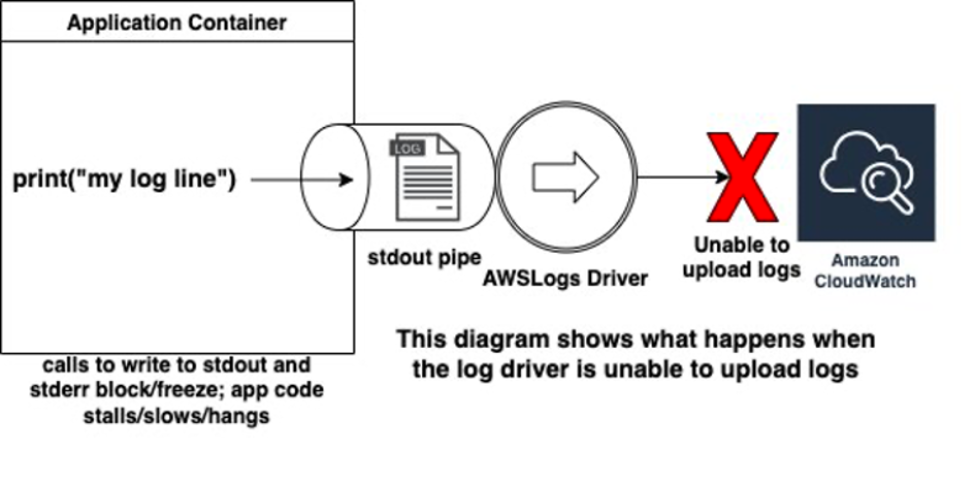
AWSLogs 컨테이너 로그 드라이버의 non-blocking 모드로 로그 손실 방지
본 게시물은 AWS Container Blog에 게시된 “Preventing log loss with non-blocking mode in the AWSLogs container log driver” by Wesley Pettit을 한국어로 번역한 글입니다. 소개 향상된 관찰 가능성과 문제 해결을 위해 컨테이너 로그를 컴퓨팅 플랫폼에서 중앙 로깅 서버에서 실행되는 컨테이너로 전달하는 것이 좋습니다. 실제로는 로깅 서버에 연결할 수 없거나 때때로 로그를 전송할 수 없는 경우가 […]

AWS Glue와 Amazon Athena를 활용한 MongoDB 데이터 분석 방법 비교하기
IoT 디바이스 또는 웹/앱 애플리케이션에서 발생되는 데이터는 JSON 다큐먼트 형태로 주로 저장되고 있으며, 이 데이터에 대한 분석 요구가 증대됨에 따라 MongoDB와 같은 다큐먼트 지향 데이터베이스 사용도 늘어나고 있습니다. AWS에서 제공되는 분석 서비스는 완전관리형 또는 서버리스 형태로 제공되어 사용자의 분석패턴에 따라 다양한 서비스를 활용할 수 있습니다. 이번 게시글에서는 여러 분석 서비스 중 Amazon Athena를 활용하여 ad-hoc […]

Amazon Aurora를 어플리케이션 개발자가 사용하기 위한 10가지 팁 – 2부
이 글은 AWS Database Delivery Blog에 게시된 10 Amazon Aurora tips for application developers – Part 2 by Rajeev Sakhuja을 한국어 번역 및 편집하였습니다. 이 글은 Amazon Aurora를 어플리케이션 개발자가 사용하기 위한 10가지 팁 (10 Amazon Aurora tips for application developers) 게시물의 2부작 시리즈의 두번째 게시물 입니다. 1부에서는 10가지 팁중 처음 5가지 팁을 공유 했습니다. […]

롯데ON 사례로 본 개인화 추천 시스템 구축하기, 2부 : Amazon SageMaker를 활용한 MLOps 구성 및 추천 모델 실시간 서비스
롯데ON은 단순 상품판매 뿐만 아닌 상품에 대한 경험을 함께 제공할 수 있는 플랫폼을 목표로 서비스하고 있습니다. 패션, 뷰티, 럭셔리, 키즈 등 다양한 전문관을 운영하며 고객들이 선호하는 라이프 스타일 전반에 걸쳐 쇼핑에 관한 좋은 경험을 제공해 드릴 수 있도록 노력하고 있습니다. 롯데ON의 고객 쇼핑 경험을 높이기 위해, 추천플랫폼개발팀에서는 고객이 찾고 있는 상품이나 흥미를 느낄 만한 상품을 […]

롯데ON 사례로 본 개인화 추천 시스템 구축하기, 1부 : Dynamic A/B Testing 아키텍처 구축
롯데ON은 풍부한 오프라인 쇼핑 인프라, 온라인 쇼핑 노하우로 세상에 없던 새로운 쇼핑 경험을 제공하는 온라인 쇼핑 플랫폼으로 발전하고 있습니다. 단순히 상품을 판매하는 플랫폼이 아닌 상품에 대한 경험을 제공할 수 있는 플랫폼을 목표로 고객이 원하고 만족하는 서비스를 만들기 위해 노력하고 있습니다. 롯데ON은 메인페이지, 상품상세, 검색, 장바구니, 주문완료 페이지에 이르는 롯데ON 고객의 여정 전반에 걸쳐 다양한 형태의 […]