AWS 기술 블로그
Amazon S3 Vectors와 Amazon OpenSearch Service로 벡터 검색 최적화하기
본 게시글은 AWS Big Data Blog에 게시된 ‘Optimizing vector search using Amazon S3 Vectors and Amazon OpenSearch Service by Sohaib Katariwala, Bobby Mohammed, Sorabh Hamirwasia, Mark Twomey, and Pallavi Priyadarshini’을 한국어 번역 및 편집하였습니다.
참고: 본 블로그 내용은 7월 15일 기준으로, Amazon S3 Vectors와 Amazon OpenSearch Service의 통합 기능은 프리뷰 버전으로, 변경될 수 있습니다.
벡터 임베딩(Vector Embeddings)과 유사성 검색(Similarity Search) 기술의 발전으로 데이터를 저장하고 검색하는 방식은 빠르게 진화하고 있습니다. 벡터 검색은 생성형 AI, 에이전트 AI 같은 최신 애플리케이션의 필수 요소가 되었지만, 방대한 양의 벡터 데이터를 관리하는 것은 여전히 큰 과제입니다. 수백만, 수십억 개의 벡터 임베딩을 저장하고 검색할 때 지연 시간, 비용, 정확도 사이의 균형을 맞추는 데 어려움을 겪는 조직이 많습니다. 기존 솔루션은 상당한 인프라 관리가 필요하거나, 데이터 양이 늘어날수록 비용 부담이 커지는 단점이 있었습니다.
이러한 문제를 해결하기 위해, 이제 Amazon Simple Storage Service(Amazon S3) Vectors와 Amazon OpenSearch Service의 두 서비스의 통합 기능이 public preview로 제공됩니다. 이 기능들은 벡터 임베딩을 저장하고 검색하는 방식에 더 큰 유연성을 제공합니다.
- 비용 최적화된 벡터 스토리지: OpenSearch Service 관리형 클러스터에서 관리형 서비스 S3 Vectors를 사용해 벡터 스토리지를 비용 효율적으로 운영할 수 있습니다. 이 통합 기능은 지연 시간이 다소 길어지더라도 비용을 극도로 낮추고, 하이브리드 검색, 고급 필터링, 지리(Geo) 필터링 등 OpenSearch의 고급 기능들을 사용하고자 하는 워크로드에 적합합니다.
- S3 Vectors에서 원클릭으로 내보내기: S3 Vector Index에서 OpenSearch 서버리스 컬렉션으로 원클릭으로 데이터를 내보내 고성능 벡터 검색을 구현할 수 있습니다. S3 Vectors를 기반으로 애플리케이션을 구축한 고객은 OpenSearch를 활용하여 더 빠른 쿼리 성능을 얻을 수 있습니다.
이러한 통합 기능을 활용해서 자주 쿼리되지 않는 벡터는 S3 Vectors에 보관하고, 하이브리드 검색 및 집계(Aggregations)와 같이 고급 검색 기능이 필요한 시간 민감형 작업에는 OpenSearch를 사용하여 벡터 워크로드를 지능적으로 분산함으로써 비용, 지연 시간, 정확도를 최적화할 수 있습니다. 또한, 양자화(Quantization), k-최근접 이웃(k-nearest neighbor, knn) 알고리즘, 메서드별 파라미터 등 OpenSearch의 성능 튜닝 기능을 통해 비용이나 정확도의 손실을 최소화하면서 성능을 개선할 수 있습니다.
본 블로그에서는 이러한 원활한 통합 기능들을 자세히 살펴보고, 유연한 벡터 검색 구현 방안을 제시합니다. 비용 최적화를 위한 OpenSearch Service 관리형 클러스터의 새로운 S3 엔진 유형 사용법과, 지연 시간 10ms 수준의 지속적인 쿼리가 필요한 고성능 시나리오를 위한 S3 Vectors에서 OpenSearch 서버리스 컬렉션으로 원클릭 내보내기 기능을 사용하는 방법을 배울 수 있습니다. 이 게시물을 통해 성능, 비용, 확장성 등 특정 요구 사항에 따라 가장 적합한 통합 패턴을 선택하고 구현하는 방법을 이해하게 될 것입니다.
서비스 개요
Amazon S3 Vectors는 1초 미만(Sub-second)의 검색 기능을 지원하는 최초의 클라우드 객체 저장소로, 인프라 관리가 필요 없습니다. Amazon S3의 단순성, 내구성, 가용성, 비용 효율성과 기본 벡터 검색 기능을 결합하여, S3에서 벡터 임베딩을 직접 저장하고 쿼리할 수 있게 해줍니다.
Amazon OpenSearch Service는 벡터 워크로드를 위한 두 가지 보완적인 배포 옵션인 관리형 클러스터(Managed Clusters)와 서버리스 컬렉션(Serverless Collections)을 제공합니다. 둘 다 OpenSearch의 강력한 벡터 검색 및 검색 기능을 활용하지만, 각각 다른 시나리오에 특화되어 있습니다. OpenSearch 사용자에게 S3 Vectors와 OpenSearch Service의 통합은 벡터 검색 아키텍처를 최적화하는 데 전례 없는 유연성을 제공합니다. 실시간 애플리케이션을 위한 초고속 쿼리 성능이 필요하든, 대규모 벡터 데이터셋을 위한 비용 효율적인 스토리지가 필요하든, 이 통합 기능은 특정 사용 사례에 가장 적합한 접근 방식을 선택할 수 있게 해줍니다.
벡터 스토리지 옵션 이해하기
OpenSearch Service는 벡터 임베딩을 저장하고 검색하기 위한 여러 옵션을 제공하며, 각각 다른 사용 사례에 최적화되어 있습니다. OpenSearch의 기본 검색 라이브러리인 Lucene 엔진은 HNSW(Hierarchical Navigable Small World) 메서드를 구현하여 효율적인 필터링 기능과 OpenSearch 핵심 기능과의 강력한 통합을 제공합니다. 추가적인 최적화 옵션이 필요한 워크로드를 위해 Faiss 엔진(Facebook AI Similarity Search)은 HNSW와 IVF(Inverted File Index) 메서드 구현 외에 벡터 압축 기능도 제공합니다. HNSW는 벡터 간의 계층적 그래프 구조를 생성하여 검색 시 효율적인 탐색을 가능하게 하며, IVF는 벡터를 클러스터로 구성하여 쿼리 시 관련 하위 집합만 검색합니다. 이번에 S3 엔진 유형이 도입되면서, Amazon S3의 내구성과 확장성을 활용하면서도 1초 미만의 쿼리 성능을 유지하는 비용 효율적인 옵션이 추가되었습니다. 이처럼 다양한 옵션을 통해 성능, 비용, 정확도에 대한 특정 요구 사항에 따라 가장 적합한 접근 방식을 선택할 수 있습니다. 예를 들어, 애플리케이션이 효율적인 필터링과 함께 50ms 미만의 쿼리 응답을 요구한다면 Faiss의 HNSW 구현이 최적의 선택입니다. 반대로, 합리적인 성능을 유지하면서 스토리지 비용을 최적화해야 한다면, 새로운 S3 엔진 유형이 더 적합할 것입니다.
솔루션 개요
이 게시물에서는 두 가지 주요 통합 패턴을 살펴봅니다.
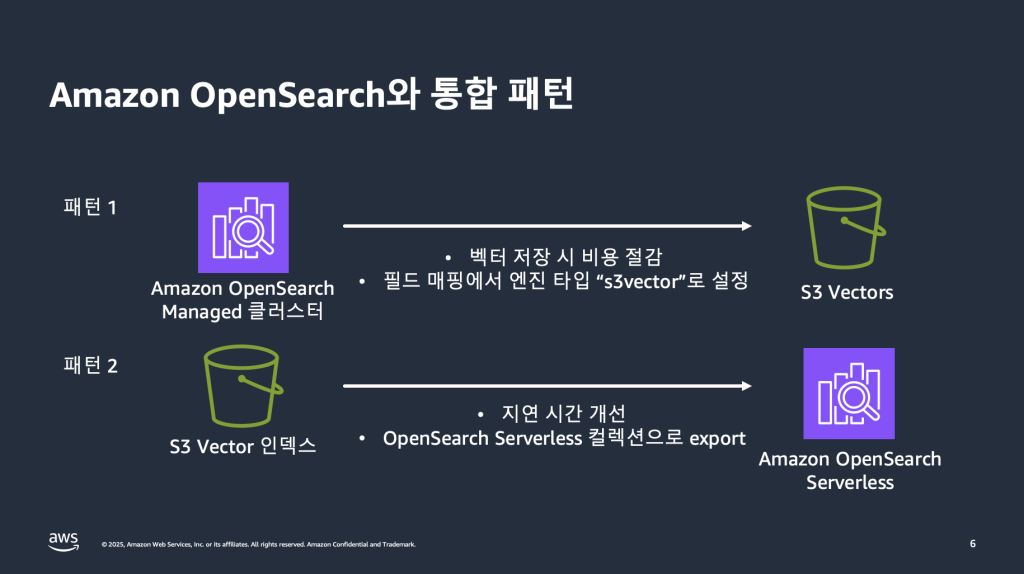
1. 비용 최적화된 벡터 스토리지를 위한 관리형 서비스인 S3 Vectors를 사용하는 OpenSearch Service 관리형 클러스터
이미 OpenSearch Service 도메인을 사용 중이며, 1초 미만의 쿼리 성능을 유지하면서 비용을 최적화하고 싶은 고객에게는 새로운 Amazon S3 엔진 유형이 매력적인 솔루션을 제공합니다. OpenSearch Service가 Amazon S3의 벡터 스토리지, 데이터 검색, 캐시 최적화를 자동으로 관리해주므로 운영 부담이 없습니다.
2. 고성능 벡터 검색을 위해 S3 Vector Index를 OpenSearch 서버리스 컬렉션으로 원클릭 내보내기
더 빠른 쿼리 성능이 필요한 사용 사례의 경우, S3 Vector Index에서 OpenSearch 서버리스 컬렉션으로 벡터 데이터를 마이그레이션할 수 있습니다. 이 접근 방식은 실시간 응답 시간이 필요한 애플리케이션에 이상적이며, 고급 쿼리 및 필터 기능, 자동 확장성, 높은 가용성 등 Amazon OpenSearch Serverless가 제공하는 이점을 누릴 수 있습니다. 내보내기 프로세스가 스키마 매핑, 벡터 데이터 전송, 인덱스 최적화 및 연결 구성을 자동으로 처리합니다.
다음 그림은 Amazon OpenSearch Service와 S3 Vectors 간의 두 가지 통합 패턴을 보여줍니다.
선행 사항 (Prerequisites)
시작하기 전에 다음 사항을 준비해야 합니다:
- AWS 계정
- Amazon S3 및 Amazon OpenSearch Service에 대한 접근 권한
- 통합 패턴 1: OpenSearch Service 도메인
- 통합 패턴 2: S3 Vectors에 저장된 벡터 데이터
통합 패턴 1: S3 Vectors를 사용하는 OpenSearch Service 관리형 클러스터
이 패턴을 구현하려면 다음 단계를 따르세요:
- OpenSearch 버전 2.19의 OR1 인스턴스를 사용하여 OpenSearch Service 도메인을 생성합니다.
- OpenSearch Service 도메인을 생성하는 동안 Advanced features 섹션에서 S3 Vectors as an engine 활성화 옵션을 선택합니다.
- OpenSearch Dashboards에 로그인하여 Dev tools를 엽니다. 그런 다음 knn(k-nearest neighbor) 인덱스를 생성하고 engine으로 s3vector를 지정합니다.
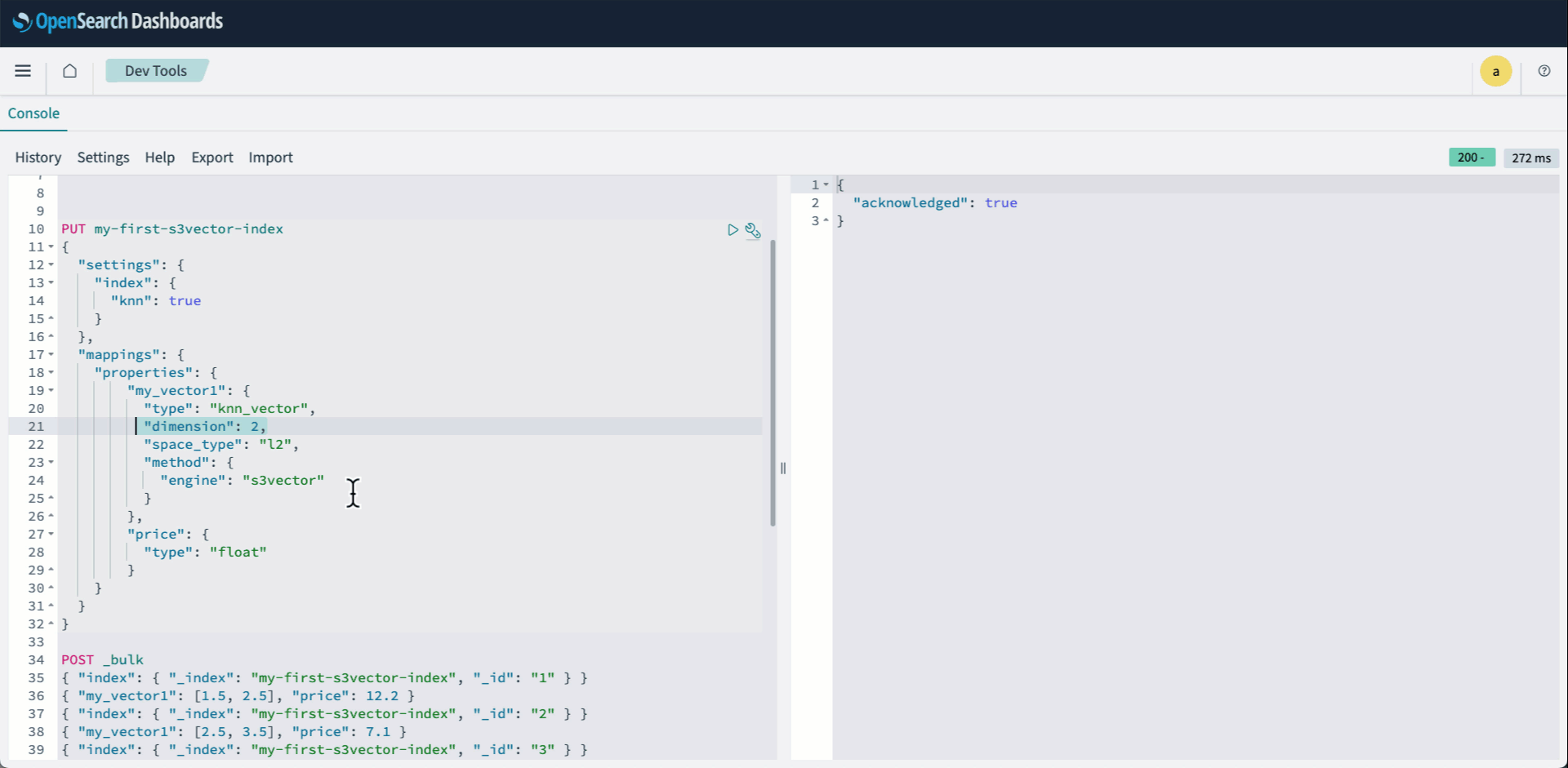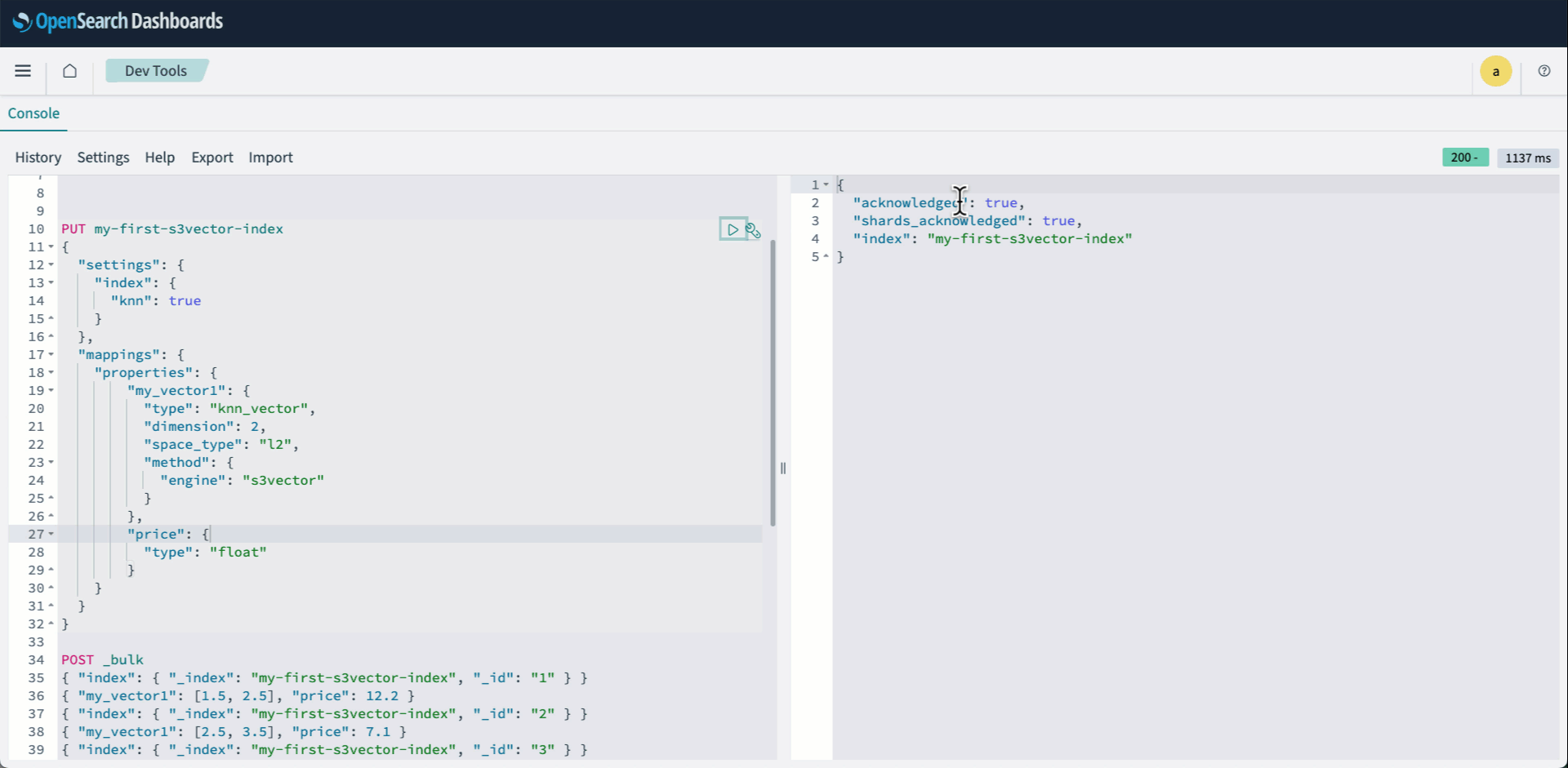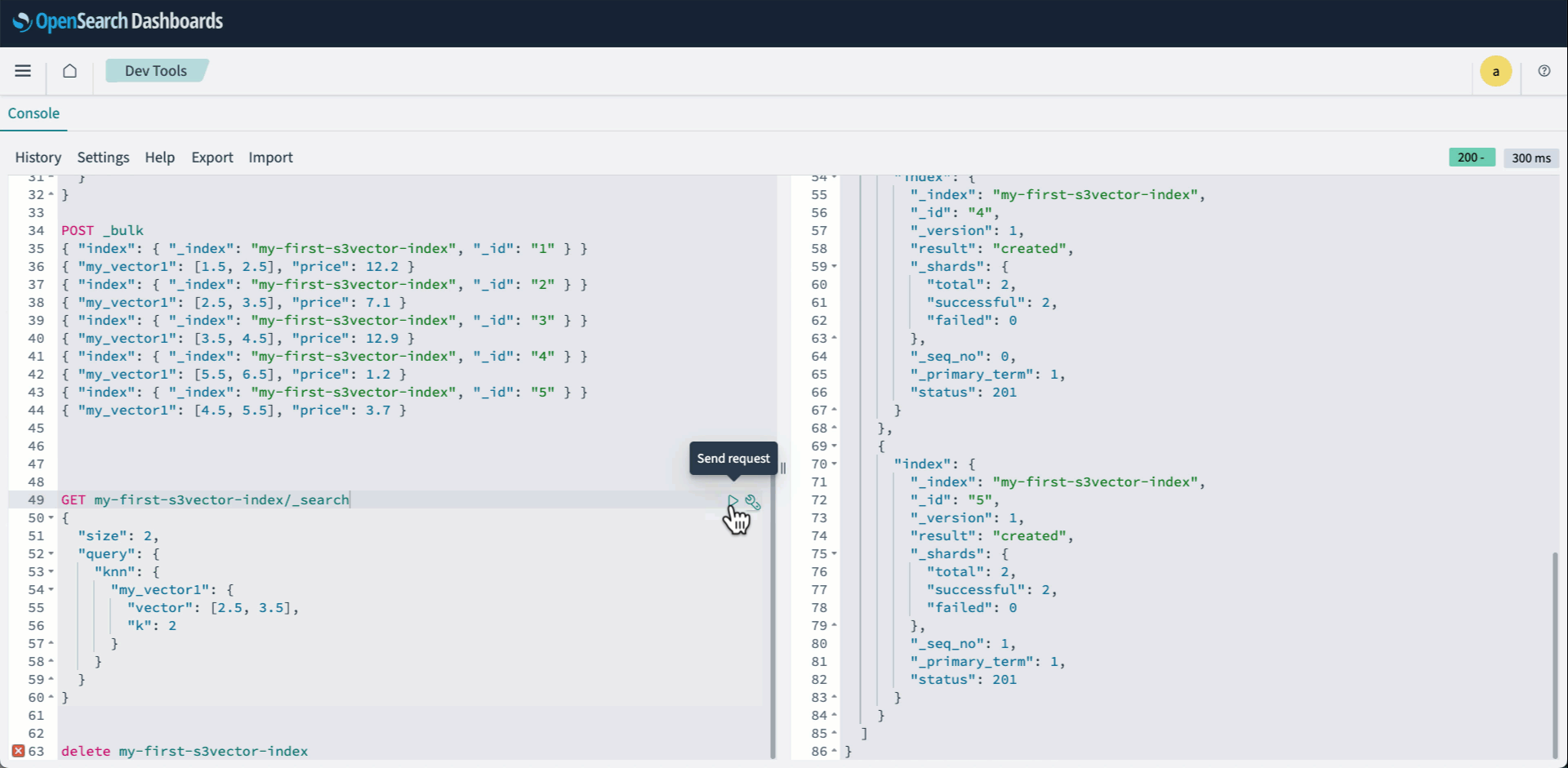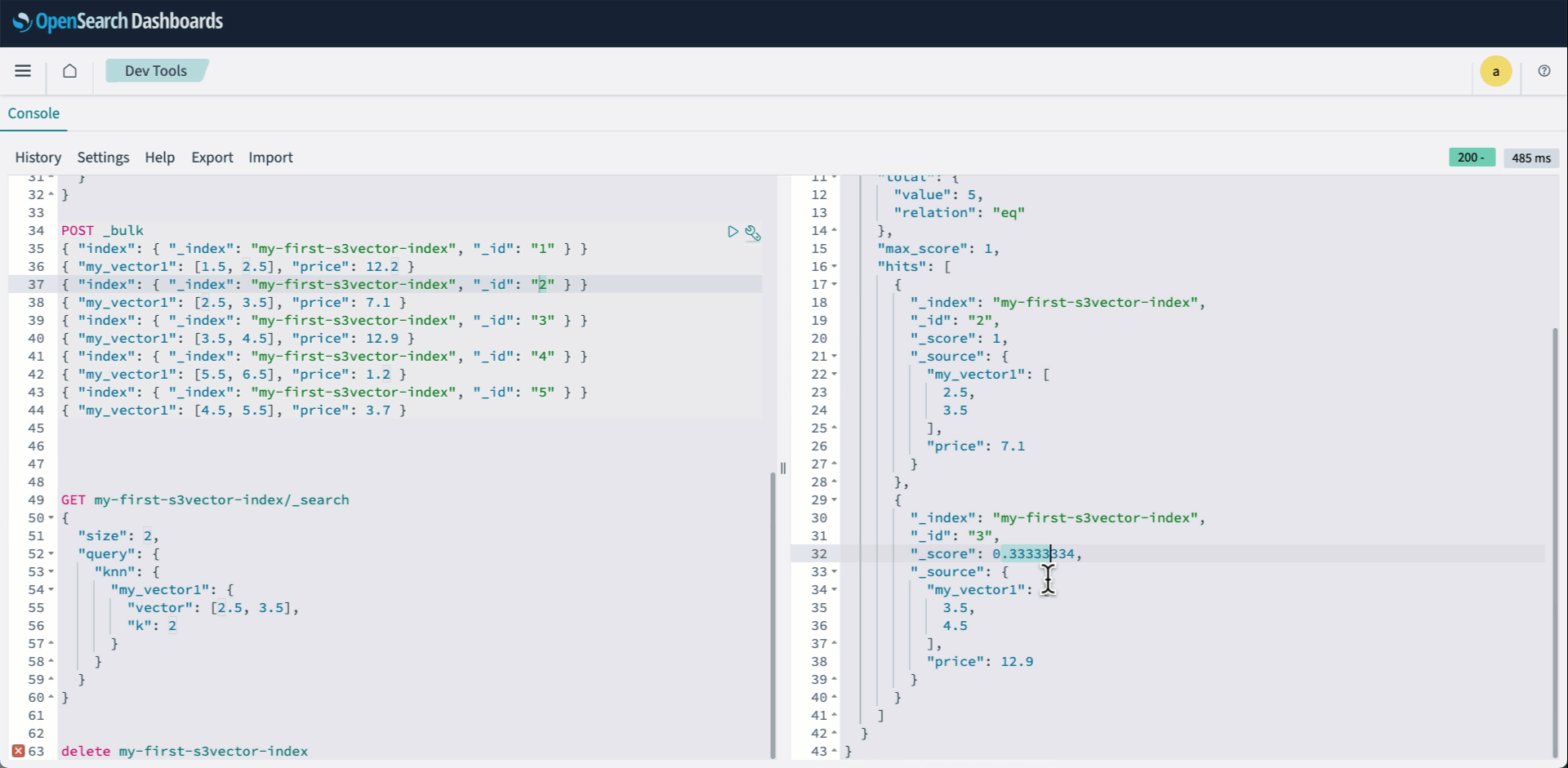
PUT my-first-s3vector-index { "settings": { "index": { "knn": true } }, "mappings": { "properties": { "my_vector1": { "type": "knn_vector", "dimension": 2, "space_type": "l2", "method": { "engine": "s3vector" } }, "price": { "type": "float" } } } } - Bulk API를 사용하여 벡터를 인덱싱합니다.
POST _bulk { "index": { "_index": "my-first-s3vector-index", "_id": "1" } } { "my_vector1": [2.5, 3.5], "price": 7.1 } { "index": { "_index": "my-first-s3vector-index", "_id": "3" } } { "my_vector1": [3.5, 4.5], "price": 12.9 } { "index": { "_index": "my-first-s3vector-index", "_id": "4" } } { "my_vector1": [5.5, 6.5], "price": 1.2 } { "index": { "_index": "my-first-s3vector-index", "_id": "5" } } { "my_vector1": [4.5, 5.5], "price": 3.7 } { "index": { "_index": "my-first-s3vector-index", "_id": "6" } } { "my_vector1": [1.5, 2.5], "price": 12.2 } - 평소처럼 knn 쿼리를 실행 합니다.
GET my-first-s3vector-index/_search { "size": 2, "query": { "knn": { "my_vector1": { "vector": [2.5, 3.5], "k": 2 } } } }
다음 애니메이션은 위의 2-4단계를 보여줍니다.
통합 패턴 2: S3 vector 인덱스를 OpenSearch Serverless로 내보내기
이 패턴을 구현하려면 다음 단계를 따르세요:
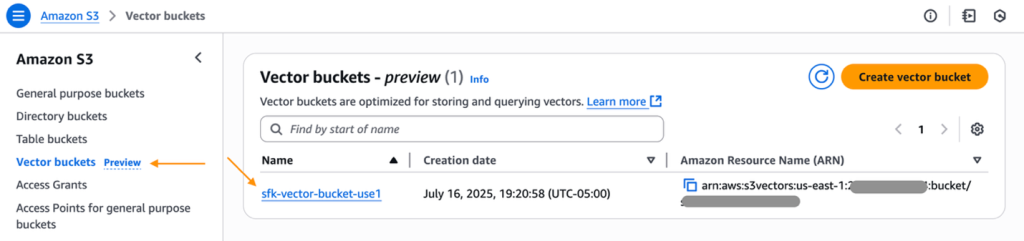
- AWS management 콘솔에서 Amazon S3로 이동한 다음 생성한 S3 vector bucket을 선택합니다.
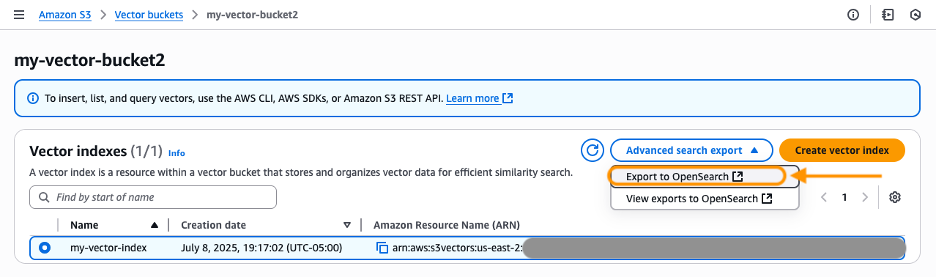
- 내보내기 하고 싶은 Vector Index를 선택합니다. Advanced search export 메뉴 아래에서, Export to OpenSearch를 선택합니다.
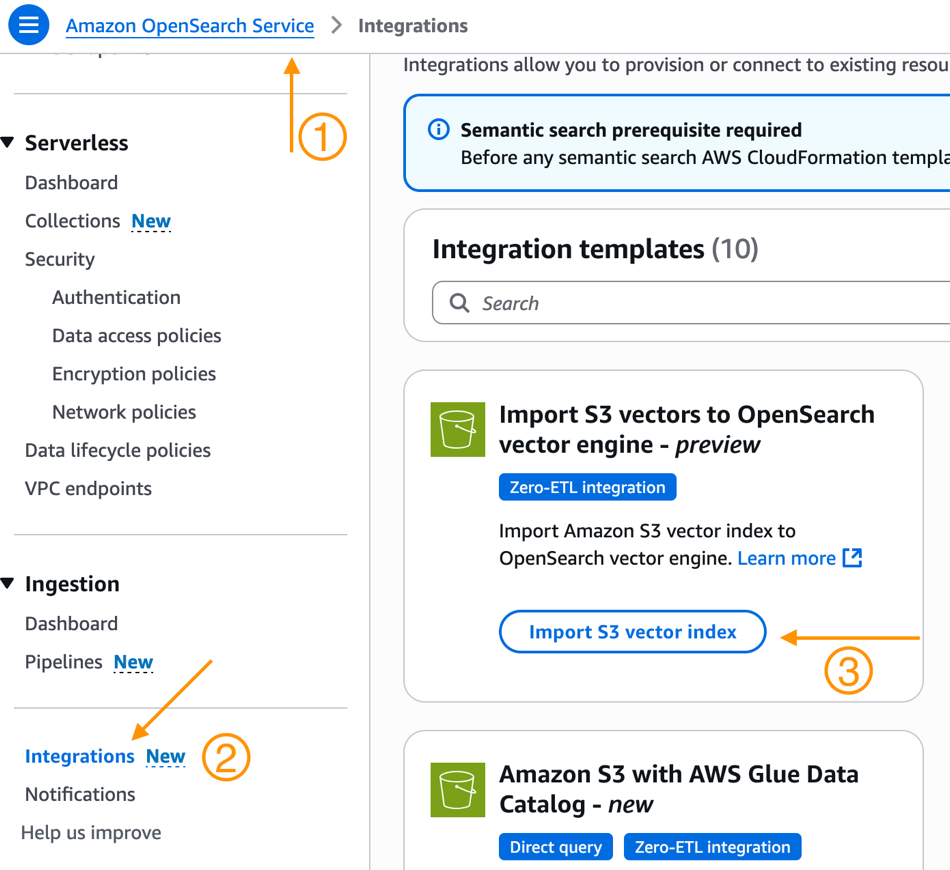
또는, 다음과 같은 방법을 사용할 수 있습니다- OpenSearch Service 콘솔로 이동합니다.
- 네비게이션 메뉴에서 Integrations 를 선택합니다.
- 새로운 Integration template인 Import S3 vectors to OpenSearch vector engine – preview를 보실 수 있습니다. 그런 다음, Import S3vector index를 선택합니다.
- 이제 Amazon OpenSearch Service 통합 콘솔로 이동하게 됩니다. 여기서 Export S3 vector index to OpenSearch vector engine 템플릿이 미리 선택되어 있고, S3 Vector Index의 Amazon Resource Name(ARN)이 자동으로 입력되어 있을 것입니다. 필요한 권한을 가진 기존 역할을 선택하거나 새로운 서비스 역할을 생성하세요.
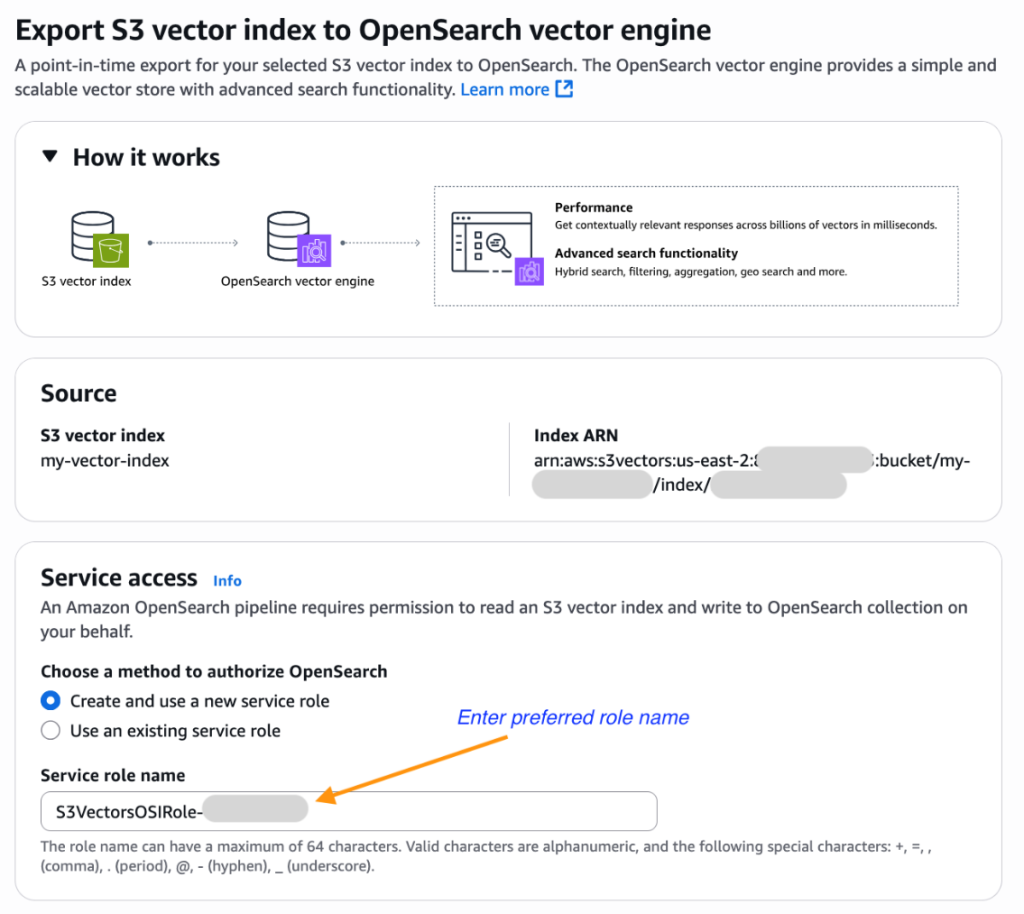
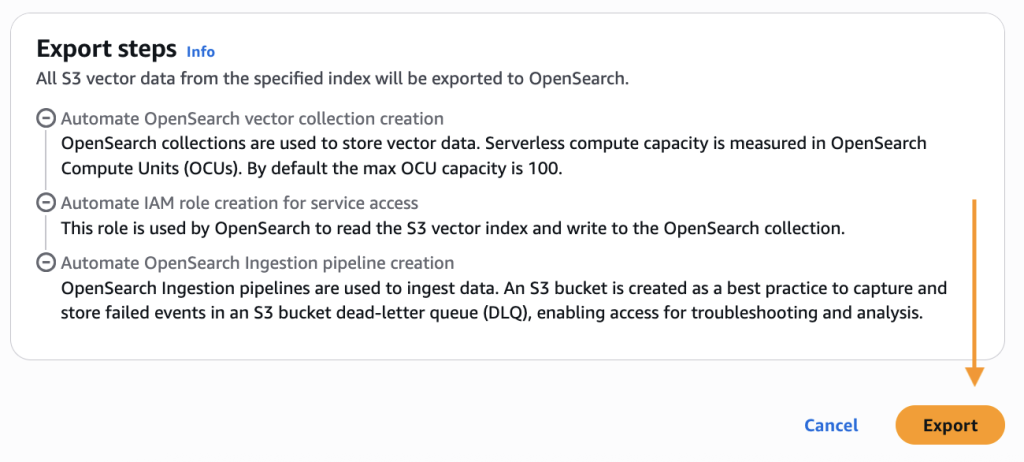
- 아래로 스크롤하여 Export를 선택하면 새로운 OpenSearch Serverless 컬렉션을 생성하고 S3 vector 인덱스의 데이터를 OpenSearch knn 인덱스로 복사하는 단계가 시작됩니다.
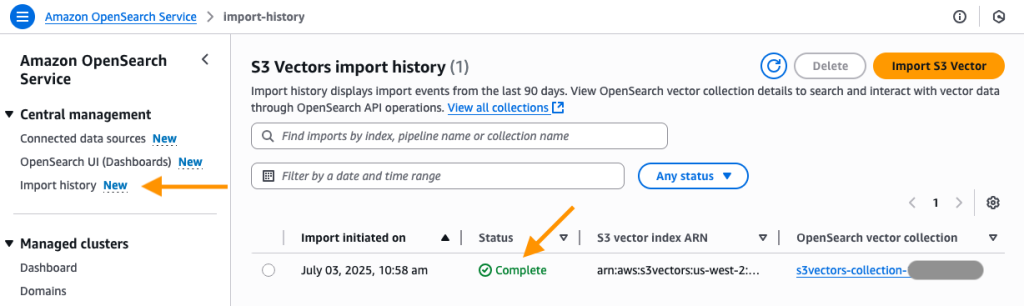
- 이제 OpenSearch Service 콘솔의 Import history 페이지로 이동하게 됩니다. 여기서 S3 Vector Index를 OpenSearch Serverless knn 인덱스로 마이그레이션하기 위해 생성된 새 작업을 볼 수 있습니다. 상태가 In Progress(진행중)에서 Complete(완료)로 변경되면, 새로운 OpenSearch Serverless 컬렉션에 연결하여 새 OpenSearch knn 인덱스를 쿼리할 수 있습니다.
- 다음 애니메이션은 Dev tools를 사용하여 새 OpenSearch serverless 컬렉션에 연결하고 새 OpenSearch knn 인덱스를 쿼리하는 방법을 보여줍니다.
정리
지속적인 비용 발생을 방지하려면 다음 단계를 따르세요:
- 패턴 1의 경우:
- S3 vectors를 사용하는 OpenSearch index를 삭제하세요.
- 더 이상 필요하지 않다면 OpenSearch Service 관리형 클러스터를 삭제합니다.
- 패턴 2의 경우:
- OpenSearch Service 콘솔의 Import history 섹션에서 가져오기 작업을 삭제합니다. 이 작업을 삭제하면 가져오기 작업으로 자동 생성된 OpenSearch 벡터 컬렉션과 OpenSearch Ingestion 파이프라인이 모두 제거됩니다.
결론
Amazon S3 Vectors와 Amazon OpenSearch Service 간의 혁신적인 통합은 벡터 검색 기술에 있어 획기적인 이정표를 세우며, 기업에 전례 없는 유연성과 비용 효율성을 제공합니다. 이 강력한 조합은 두 가지 장점을 모두 제공합니다: Amazon S3의 유명한 내구성과 비용 효율성이 OpenSearch의 고급 AI 검색 기능과 완벽하게 통합됩니다. 이제 조직은 지연 시간, 비용, 정확도를 제어하면서 벡터 검색 솔루션을 수십억 개의 벡터로 확장할 수 있습니다. OpenSearch Service를 통한 10ms의 낮은 지연 시간으로 초고속 쿼리 성능을 우선시하든, S3 Vectors를 사용하여 인상적인 1초 미만의 성능으로 비용 최적화된 스토리지를 구현하든, OpenSearch에서 고급 검색 기능을 구현하든, 이 통합은 특정 요구 사항에 완벽한 솔루션을 제공합니다. OpenSearch 관리형 클러스터에서 S3 Vectors 엔진을 사용해보고 S3 Vector Index에서 OpenSearch Serverless로의 원클릭 내보내기를 테스트하여 오늘 바로 시작해보시기 바랍니다.
더 많은 정보는 다음 링크를 참고해주세요: