AWS 기술 블로그
엔터프라이즈 Multi-EKS 마스터하기: GitOps 기반 Blue-Green 무중단 운영 전략
1. 왜 Multi EKS인가?
엔터프라이즈 환경의 도전과제
현대 엔터프라이즈 기업들은 클라우드 네이티브 애플리케이션의 확산과 마이크로서비스 아키텍처 도입으로 컨테이너 오케스트레이션이 필수가 되었습니다. Amazon EKS는 Kubernetes의 복잡한 관리 부담을 AWS가 대신 처리해주어 기업들이 애플리케이션 개발에 집중할 수 있게 합니다. 이로 인해 많은 엔터프라이즈 기업들이 Amazon EKS을 활용하여 다양한 서비스를 운영하고 있습니다. 고객들은 단일 EKS 클러스터가 아닌 여러 개의 클러스터를 운영하는 것이 일반적이며 이는 아래와 같은 현실적인 요구사항이 존재하기 때문입니다.
조직적 요구사항에 따른 여러 EKS 클러스터 운영
- 서비스를 운영하는 팀별, 부서별 독립적인 리소스와 관리로 인해 여러개의 EKS 클러스터를 운영합니다.
- 안정적인 서비스 운영을 위해 개발/스테이징/프로덕션 환경따라 EKS 클러스터를 운영합니다.
- 규정 준수 및 감사 요구사항을 충족하기 위해 EKS 클러스터를 분리합니다.
기술적 요구사항에 따른 여러 EKS 클러스터 운영
- 서비스별 격리를 통한 장애 영향 범위를 최소화하고자 여러 EKS 클러스터를 운영합니다.
- 각기 다른 보안 정책 및 네트워크 요구사항을 반영하기 위해 여러 EKS 클러스터를 운영합니다.
- 워크로드 특성에 맞는 클러스터 최적화를 위하여 여러 EKS 클러스터를 운영합니다.
복잡성의 현실
하지만 멀티 클러스터 운영은 상당한 복잡성을 가져옵니다. 하나의 예를 들어보도록 하겠습니다. 한 엔터프라이즈 회사는 총 10개의 서비스를 운영하고 있으며 개발/스테이징/운영의 환경을 고려하면 총 30개의 클러스터가 필요합니다. 또한 Amazon EKS 클러스터 특성 상 연 4회의 업데이트 즉 120회의 EKS 클러스터 업그레이드 작업이 필요합니다.
- Dev/Stage/Prod 환경 × 10개 서비스 = 30개 클러스터
- 분기별 4회 업그레이드 × 30개 클러스터 = 연간 120회 업그레이드 작업
- 각 클러스터별 모니터링, 로깅, 보안 설정 관리
단일 vs 멀티 클러스터 비교
| 구분 | 단일 클러스터 | 멀티 클러스터 |
|---|---|---|
| 관리 복잡성 | 낮음 | 높음 |
| 장애 격리 | 낮음 (전체 영향) | 높음 (부분 영향) |
| 보안 격리 | 네임스페이스 수준 | 클러스터 수준 |
| 리소스 효율성 | 높음 | 중간 |
| 업그레이드 리스크 | 높음 | 낮음 |
| 조직별 관리 | 어려움 | 용이함 |
해결해야 할 핵심 문제들
- 운영 부담 증가: 클러스터 수에 비례한 관리 오버헤드
- 일관성 부족: 각 클러스터별 설정 차이로 인한 예측 불가능성
- 업그레이드 복잡성: 다수 클러스터의 순차적 업그레이드 관리
- 모니터링 분산: 통합된 관찰성(Observability) 부족
- 배포 복잡성: 여러 환경에 대한 일관된 배포 파이프라인 필요
이 글에서 제안하는 해결책
이러한 문제들을 해결하기 위해 Multi-level Hub-and-Spoke 아키텍처와 GitOps 기반 자동화를 통한 효율적인 멀티 EKS 운영 방법을 소개합니다.
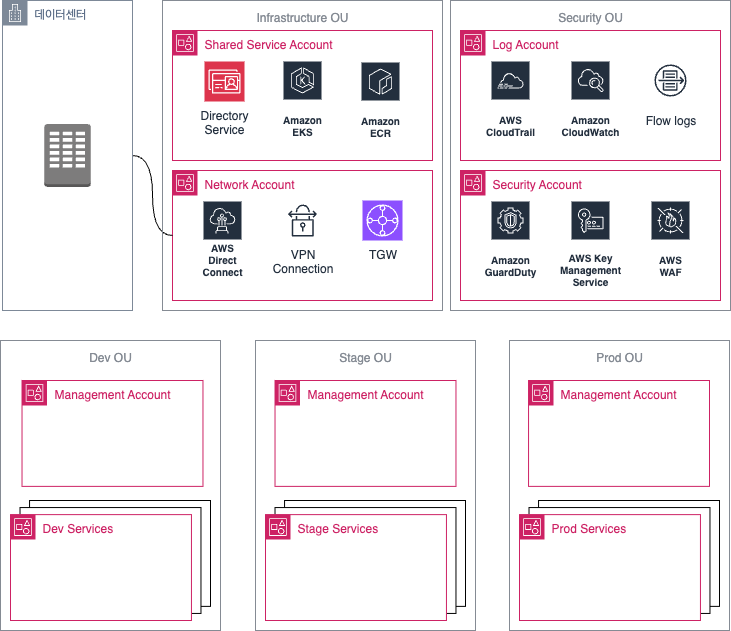
운영환경은 엔터프라이즈에 맞추어 이미 AWS Landing Zone을 통해 구성된 상태를 기본으로 하고 있습니다. Landing Zone을 구축하지 않더라도 별도의 Shared Service Account가 있으면 아래의 운영 방법을 구축하실 수 있습니다.
2. 해결 방안: Hub-and-Spoke 아키텍처
아키텍처 개요
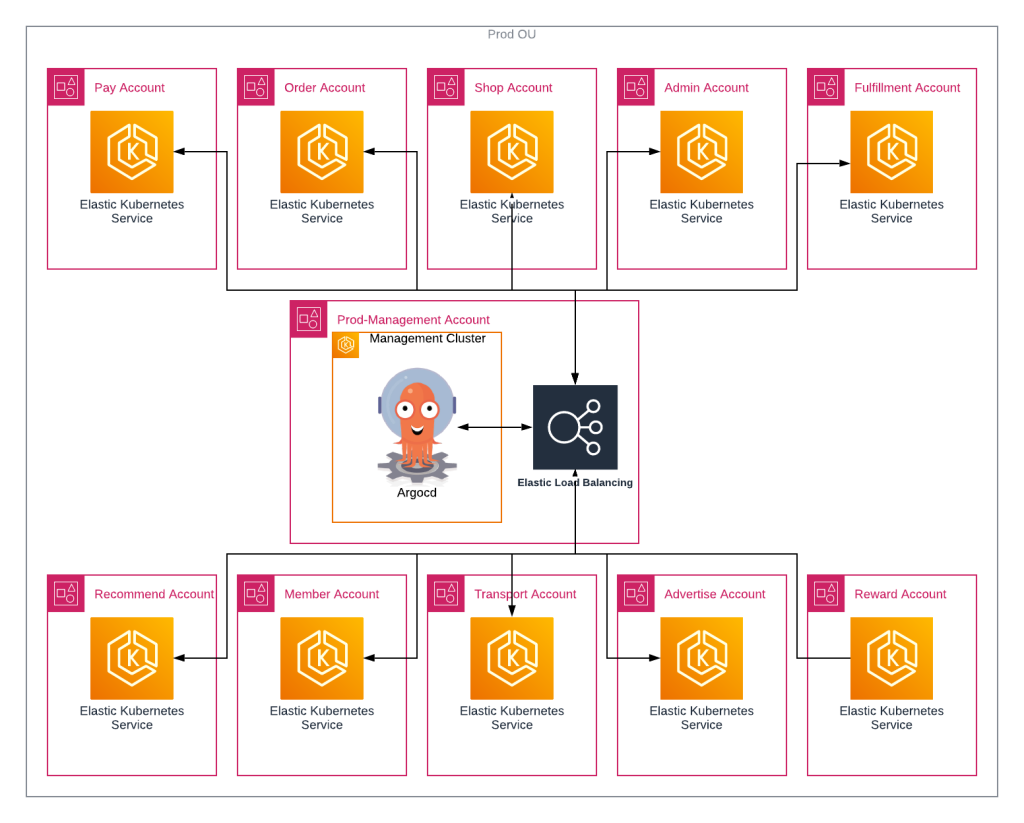
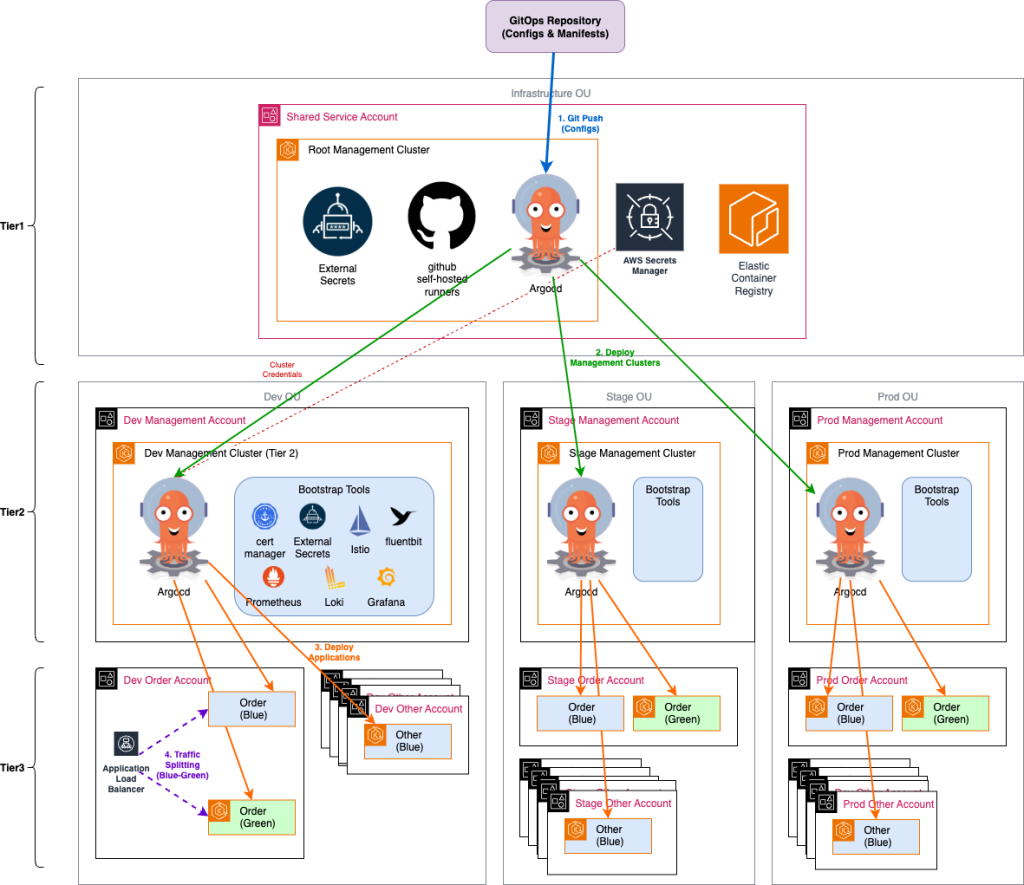
아래 그림은 Multi-level Hub and Spoke 구조로 관리되는 EKS Cluster를 보여주고 있습니다. 이 아키텍처는 3계층 구조로 구성됩니다. Shared Service에 구축되어있는 Root Management Cluster는 각 환경별 Management Cluster를 관리합니다. 또한 Management Cluster는 Service Cluster를 관리하게 됩니다.
Tier 1: Root Cluster (최상위 관리 클러스터)
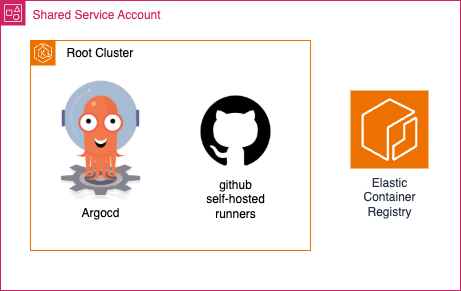
Infrastructure OU 안의 Shared Service Account에 위치하며 전체 멀티 클러스터 환경의 중앙 제어 역할을 하는 클러스터 입니다. 해당 클러스터는 GitOps Repository와 연결되어 모든 변경사항을 추적하며 Self-hosted runner나 ArgoCD등 CI/CD를 관리하는 공통된 개발도구가 여기에서 관리됩니다. 또한 ArgoCD를 통해서 각 환경의 Management Cluster를 관리할 수 있습니다.
이렇게 설치된 Root Cluster에는 개발에 필요한 CI/CD를 위한 공통된 모듈이 있으므로 공통으로 사용될 Shared Service Account에 있는 ECR로 배포할 수 있습니다.
Tier 2: Management Clusters (환경별 관리 클러스터)
각 환경(DEV/STG/PRD)별로 하나씩 존재하는 Management Cluster는 해당 환경의 모든 서비스 클러스터를 관리하고 있습니다. 이를 통해서 환경 별 정책 및 설정을 적용할 수 있습니다. 특히 각 서비스의 배포를 위한 ArgoCD가 여기에 위치합니다. 서비스 클러스터에 대한 배포는 모두 여기서 이루어 지며 모니터링, 로깅도 여기서 관리하게 됩니다.
Tier 3: Service Clusters (실제 워크로드 클러스터)
실제 애플리케이션이 실행되는 클러스터로 서비스별 혹은 팀별로 분리된 독립적인 환경을 제공하게 됩니다.
아키텍처 핵심 특징:
계층별로 클러스터의 역할 분리(Root → Management → Service)하여 운영에 유연성을 가져가게 합니다. 특히 GitOps 기반 자동화를 통해 모든 변경사항이 Git을 통해 추적 및 배포할 수 있도록 하며 Service 클러스터의 경우 Blue/Green 을 통해 무중단으로 업그레이드가 가능함과 동시에 여러 버전(ex: 1.29 -> 1.32)을 한번에 올릴 수 있도록 합니다. 또한 조직운영 환경에 맞게 Root에서 전체 환경을 통합하여 모니터링 할 수도 있고 때로는 환경별로 분리하여 운영할 수 있습니다
배포 흐름 및 체이닝 구조
1단계: Root → Management
Root Cluster ArgoCD → Management Cluster 배포
├── ArgoCD 설치 및 설정
├── 기본 인프라 구성 요소 배포
└── 환경별 정책 적용
2단계: Management → Service
Management Cluster ArgoCD → Service Cluster 배포
├── 애플리케이션 배포
├── 서비스별 설정 적용
└── 모니터링 에이전트 설치
Blue/Green 업그레이드 전략
ArgoCD ApplicationSet을 활용한 무중단 클러스터 업그레이드를 수행할 수 있습니다. ApplicationSet은 여러 대상으로 동일한 어플리케이션을 여러 cluster나 namespace에 배포할 수 있게 됩니다. 또한 Generators를 활용하면 환경별로 혹은 대상에 따라 다른 값(버전, 설정 등)을 적용할 수 있습니다. 이것들을 통해 모든 대상에 동일한 기본 설정을 적용가능하게하고 버전에 따른 변경점이 필요할 때, 원하는 값을 반영할 수 있습니다.
업그레이드 시나리오는 아래와 같습니다.
- 처음으로 기존 Blue 클러스터를 운영중이라면 새 버전의 Green 클러스터를 생성합니다
- 그리고 나서
ApplicationSet을 통해 애플리케이션을 두 클러스터에 배포합니다 새로 배포된 Green클러스터에서 모든 기능을 테스트 및 검증합니다. - 다음으로 점진적으로 Blue → Green으로 트래픽을 점진적으로 전환합니다
- 마지막으로 안정성 안정성 확인 후 기존 Blue 클러스터를 제거합니다
3. 단계별 구현 가이드
3.1 사전 준비사항
필수 요구사항:
- AWS Landing Zone 또는 별도의 Shared Service Account
- 각 환경별 VPC 및 네트워킹 구성
- GitOps Repository (GitHub, GitLab, CodeCommit 등)
- Terraform 또는 다른 IaC 도구
권장 네트워크 구성:
- Management VPC: 모든 환경에 접근 가능한 중앙 VPC
- 환경별 VPC: DEV/STG/PRD 각각의 독립적인 VPC
- VPC Peering 또는 Transit Gateway를 통한 연결
3.2 클러스터 구축
3.2.1 Root Cluster
Root Cluster는 전체 멀티 클러스터 환경의 중앙 제어 역할을 담당합니다. AWS Organization의 Infrastructure OU 내 Shared Service Account에 배치하여 모든 환경에 대한 접근성을 확보합니다. 이 클러스터는 고가용성을 위해 Multi-AZ 구성으로 설계되며, 전체 인프라의 관리 중심점 역할을 합니다.
주요 구성 요소로는 전체 클러스터 배포를 관리하는 ArgoCD, 다중 클러스터 배포를 자동화하는 ApplicationSets, 모든 설정의 버전 관리를 위한 GitOps Repository 연결, 그리고 애플리케이션 빌드 및 테스트를 위한 Github Self-hosted Runner가 포함됩니다. 이 클러스터를 업그레이드 할 경우에는 Management 클러스터에 영향을 주지 않도록 타겟 ArgoCD ServiceAccount secrets을 제거하는 것만으로도 다른 클러스터에 접근이 불가하게 되어 다른 클러스터는 영향을 주지 않은 채로 In-Place 업그레이드를 할 수 있습니다.
3.2.2 Management Cluster
Management Cluster는 각 환경(DEV/STG/PRD)별로 하나씩 존재하며, 해당 환경 내의 모든 서비스 클러스터를 관리합니다. 이를 통해 환경별 정책과 설정을 일관되게 적용할 수 있으며, 환경 간 격리를 유지하면서도 중앙에서 제어가 가능합니다.
이 클러스터에는 서비스 클러스터 관리를 위한 ArgoCD, 서비스 메시 및 트래픽 관리를 위한 Istio, SSL/TLS 인증서 자동 관리를 위한 cert-manager, ALB/ NLB 통합 관리를 위한 AWS Load Balancer Controller, 그리고 AWS Secrets Manager 연동을 위한 External Secrets Operator 등 다양한 인프라 구성 요소 가 포함됩니다. 또한 통합 모니터링을 위한 Prometheus/VictoriaMetrics, Loki, Grafana, AlertManager 등의 관찰성 도구도 구성됩니다.
3.2.3 Service Cluster (Blue-Green 방식)
Service Cluster는 실제 애플리케이션이 실행되는 클러스터로, 서비스별 또는 팀별로 분리된 독립적인 환경을 제공합니다. 무중단 업그레이드를 위해 Blue-Green 방식으로 구성하는 것이 핵심입니다.
Blue-Green 구성에서는 기존 클러스터(Blue)와 동일한 구성으로 새 클러스터(Green)를 생성하고, 두 클러스터에 동일한 애플리케이션을 배포합니다. 새 클러스터에서 모든 기능을 검증한 후, 트래픽을 점진적으로 Blue에서 Green으로 전환합니다. 이 과정에서 문제가 발생하면 즉시 Blue로 롤백할 수 있어 안전한 업그레이드가 가능합니다.
주요 고려사항으로는 두 클러스터 간의 상태 동기화, 데이터 일관성 유지, 네트워크 구성의 일관성, 그리고 리소스 효율성이 있습니다. 특히 Stateful 워크로드의 경우 데이터 동기화 전략이 중요하며, 트래픽 전환 시 세션 관리와 캐시 전략도 신중하게 계획해야 합니다.
3.3 EKS Pod Identity 구성
멀티 클러스터 환경에서는 IRSA보다 EKS Pod Identity를 권장합니다. OIDC Provider 관리의 복잡성을 줄이고 더 간단한 설정이 가능합니다. 이를 통해 클러스터를 Blue Green으로 업그레이드 할 경우에도 IAM Role을 그대로 가져갈 수 있도록 준비합니다.
EKS Pod Identity를 사용하게 되면 OIDC Provider 생성 및 관리 불필요하게 되어 설정이 조금 더 간단합니다. 또한 클러스터 전환 시 IAM 설정을 그대로 재사용 가능하며 IaC의 도움을 받으면 Pod Identity를 그대로 활성화가 가능하기 때문에 보다 쉽고 안전하게 동일한 설정이 가능합니다. 특히나 Blue-Green 전환시 이점이 있는데 동일한 IAM 역할을 Blue/Green 클러스터에서 공유할 수 있고, 권한 검증할 때도 전환전에 Green 클러스터에서 권한 검증을 할 수 있다는 장점이 있습니다.
구성 단계:
- IAM 역할 생성: 필요한 권한을 가진 IAM 역할 생성
- EKS Pod Identity 연결: 서비스 계정과 IAM 역할 연결
- 권한 검증: 적절한 권한이 부여되었는지 확인
다음 단계: Pod Identity 설정이 완료되면, 다음으로 ArgoCD를 통해 클러스터 간 연결을 설정하여 GitOps 기반 배포를 준비합니다.
3.4 ArgoCD 클러스터 간 연결 설정
새로운 클러스터를 생성하면 Management Cluster의 ArgoCD에서 배포할 수 있도록 연결 설정이 필요합니다. 이 과정은 보안을 고려하여 단계별로 진행됩니다.
- 대상 클러스터에 ArgoCD용 Service Account 생성
- 클러스터 정보 수집 및 Secrets Manager 저장
- External Secrets을 통한 ArgoCD Secret 생성
- SecretStore 설정
- ArgoCD ApplicationSet을 통한 다중 클러스터 배포
이제 ArgoCD에서 ApplicationSet을 사용하여 여러 클러스터에 동시 배포가 가능합니다. 아래는 샘플 예제 입니다.
# multi-cluster-applicationset.yaml
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: multi-cluster-app
namespace: argocd
spec:
generators:
# 클러스터 Generator: 등록된 모든 클러스터에 배포
- clusters:
selector:
matchLabels:
environment: production
# Git Generator: 환경별 다른 값 적용
- git:
repoURL: https://github.com/your-org/k8s-configs
revision: HEAD
directories:
- path: environments/*
template:
metadata:
name: '{{name}}-{{path.basename}}'
spec:
project: default
source:
# AWS ECR OCI 형식의 Helm 차트 사용
repoURL: 'oci://123456789012.dkr.ecr.ap-northeast-2.amazonaws.com/helm-charts'
targetRevision: 1.0.0
chart: app-chart
helm:
valueFiles:
- values-{{name}}.yaml # 클러스터별 values 파일
destination:
server: '{{server}}'
namespace: default
syncPolicy:
automated:
prune: true
selfHeal: true
syncOptions:
- CreateNamespace=true
3.5 애플리케이션 배포 및 테스트
배포 검증 체크리스트
새로운 클러스터에 애플리케이션을 배포한 후 다음 항목들을 단계별로 검증합니다:
1. 인프라 레벨 테스트 > 2. 애플리케이션 레벨 테스트 > 3. 통합 테스트 자동화 > 4. 모니터링 및 로깅 확인
4. 운영 및 관리
테스트가 완료되었다면 실제 트래픽을 신규 클러스터에 점진적으로 전환하는 과정이 필요합니다.
4.1 트래픽 제어 및 Blue-Green 전환
클러스터 업그레이드 시 무중단 서비스를 위해 트래픽을 점진적으로 전환하는 것이 중요합니다. 두 가지 주요 방법을 제공합니다.
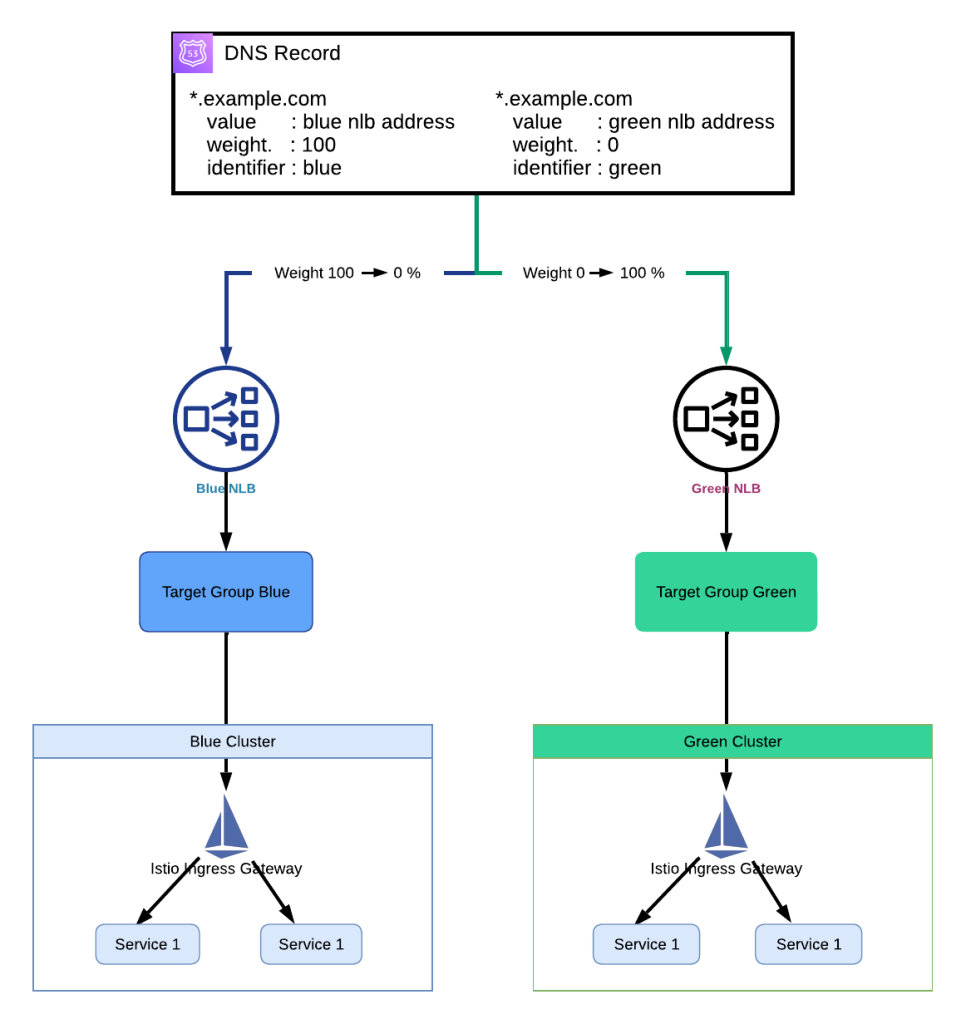
방법 1: DNS 기반 트래픽 제어 (Amazon Route53 Weighted Routing)
Amazon Route53의 Weighted Routing을 사용하여 DNS 레벨에서 트래픽을 제어합니다.
장점:
- 구현이 간단함
- 다양한 로드밸런서 타입 지원 (ALB, NLB, CLB)
단점:
- DNS 캐시 TTL로 인한 전환 지연
- 클라이언트별 캐시 정책에 따른 예측 불가능성
초기에는 Blue 클러스터가 weight 100 (모든 트래픽), Green 클러스터가 weight 0으로 설정됩니다. 점진적으로 Blue의 weight를 줄이고 Green의 weight를 늘려가며 트래픽을 전환합니다.
방법 2: ALB Target Group 기반 제어 (권장)
ALB의 Target Group 가중치를 조정하여 트래픽을 제어합니다.
장점:
- DNS 캐시 TTL 영향 없음
- 즉시 트래픽 전환 가능
- 세밀한 트래픽 제어 가능
단점:
- ALB에서만 사용 가능
- 설정이 상대적으로 복잡
아래 다이어그램은 ALB를 사용한 Blue-Green 배포 아키텍처를 보여줍니다. 하나의 ALB가 가중치 기반 라우팅을 통해 Blue 클러스터와 Green 클러스터로 트래픽을 분산시킵니다. 각 클러스터는 자체 Target Group을 가지며, ALB의 리스너 규칙에서 가중치를 조정하여 점진적으로 트래픽을 Blue에서 Green으로 전환할 수 있습니다.
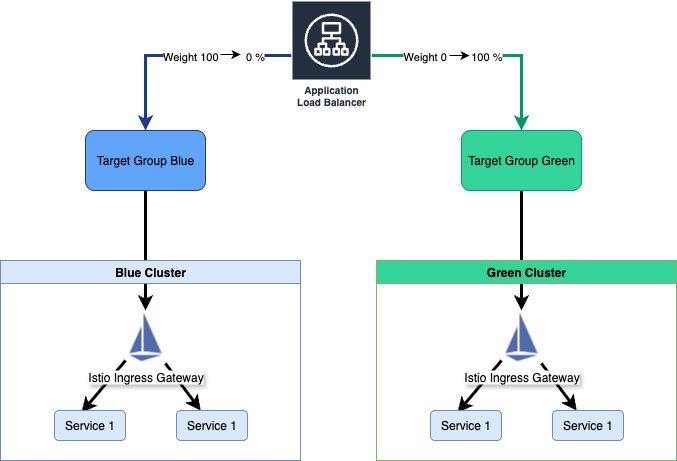
ALB 기반 전환의 핵심 장점:
- 즉시 전환: DNS 캐시 TTL 영향 없이 실시간 트래픽 제어
- 정밀 제어: 1% 단위까지 세밀한 가중치 조정 가능
- 헬스체크 연동: Target Group 헬스체크를 통한 자동 장애 감지
- 롤백 용이성: 문제 발생 시 즉시 이전 상태로 복원 가능
4.2 모니터링 및 관찰성
통합 모니터링 아키텍처
멀티 클러스터 환경에서는 중앙화된 모니터링이 필수입니다. 아래의 예시된 구성요소를 이용하여 통합 모니터링을 구축하면 복잡한 클러스터를 분석하는데 용이합니다.
구성 요소:
- Prometheus/VictoriaMetrics: 메트릭 수집 및 저장
- Grafana: 통합 대시보드
- Loki: 중앙화된 로그 수집
- AlertManager: 통합 알림 시스템
- Jaeger/Tempo: 분산 트레이싱
5. 재해 복구 및 고가용성
Multi-AZ Active-Active 구성
각 AZ에 독립적인 클러스터를 구성하여 AZ 장애 시에도 서비스 연속성을 보장합니다. 특히 ALB가 50:50 가중치로 트래픽을 분산하며, 한쪽 AZ(Available Zone) 에 장애 발생 시 손쉽게 정상 AZ로 트래픽을 전환할 수 있습니다.
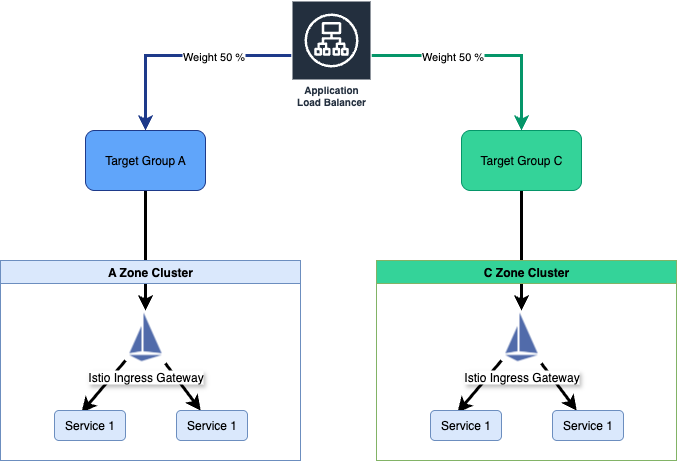
Active-Active 구성시에 얻을 수 있는 장점으로는 하나의 AZ 전체 장애 시에도 weight 변경만으로 서비스 지속할 수 있습니다. 또한 평상시에는 두 AZ에 부하 분산기능으로 성능을 향상시킬 수 있으나 업그레이드시에는 AZ 별로 순차 업그레이드가 가능합니다. 가장 큰 장점으로는 동일 리전내 데이터 전송 비용을 크게 절약할 수 있어 비용 효율성을 크게 높일 수 있습니다
6. 결론 및 요약
핵심 요약
Multi-EKS 클러스터 운영의 복잡성을 해결하기 위한 체계적인 접근 방법을 제시했습니다.
1. 아키텍처 설계
- Multi-level Hub-and-Spoke: 3계층 구조로 관리 복잡성 해결
- GitOps 기반 자동화: 일관성 있는 배포 및 설정 관리
- Blue-Green 전략: 무중단 업그레이드 및 롤백 지원
2. 운영 효율성
- 중앙화된 관리: Root Cluster를 통한 통합 제어
- 자동화된 배포: ApplicationSet을 통한 다중 클러스터 배포
- 통합 모니터링: 전체 인프라에 대한 단일 관찰성
3. 안정성 및 확장성
- 점진적 트래픽 전환: DNS 또는 ALB 기반 무중단 전환
- Multi-AZ 고가용성: AZ 장애에 대한 자동 대응
- 성능 최적화: 클러스터 크기 및 네트워킹 최적화
성공을 위한 핵심 요소
조직 및 서비스의 복잡해짐에 따라 성공적으로 수많은 클러스터를 안정적이고 효율적으로 운영하기 위해서는 많은 준비가 필요합니다.
-
조직적으로 준비하는 과정이 필요합니다. 전담 플랫폼 팀 구성이 필요하며, 개발팀과 협업 프로세스가 정립하고 변경 관리 및 승인 프로세스를 수립하는 과정도 필요합니다.
-
기술적 준비 IaC(Infrastructure as Code) 역량 강화를 통해 인프라를 자동화 하고 배포전에 리뷰를 할 수 있도록 하며 GitOps 및 CI/CD 파이프라인 및 다양한 배포전략을 통해 안정적인 서비스를 구축해야합니다. 필수적으로 통합 모니터링 및 해당 도구 숙련도의 향상도 중요합니다
-
운영에 대한 준비 조직은 장애에 대응 절차 및 런북 작성하여 항상 준비되어 있어야 합니다. 정기적인 DR(Disaster Recovery) 테스트가 좋은 훈련이 될 수 있습니다. 또한 성능 및 비용과의 밸런스를 위하여 계획을 항상 수립해야 합니다,
마무리
Multi-EKS 클러스터 운영은 초기 투자 비용과 복잡성이 높지만, 적절한 아키텍처와 자동화를 통해 운영 안정성, 조직의 효율성, 확장성 및 비용 최적화를 달성 할 수 있습니다. 성공적인 Multi-EKS 운영을 위해서는 단계적 접근과 지속적인 개선이 필요하며, 조직의 성숙도와 요구사항에 맞는 맞춤형 구현이 중요합니다.