AWS 기술 블로그
Nota AI가 제안하는 AWS Inferentia에서 다양한 LLM 모델 양자화 최적화기법 사용하기
Nota AI는 인공지능(AI, Artificial Intelligence) 모델의 경량화 및 최적화 기술을 전문적으로 연구·개발하는 기업입니다. 인공지능 모델을 분석해 특정 하드웨어의 호환성을 지원하고 하드웨어의 특성에 맞게 모델을 변경하여 추론 성능 및 메모리 효율성을 극대화하는 자사 플랫폼인 NetsPresso를 기반으로 모바일, 자동차, 로보틱스, 스마트시티 등 자원이 제한된 다양한 산업군에 고성능 AI 솔루션을 제공합니다. 이번 포스팅에서는, AWS Inferentia와Trainium에 호환되는 LLM 모델에 대해 양자화 기법들을 사용하여 throughput은 최대화 하면서, 정확도 손실을 최소화하는 방안들을 소개하고자 합니다.
AWS Inferentia/Trainium
Nota AI는 GPU를 대체할 수 있는 고성능 NPU 환경에서 LLM을 최적화하고 안정적으로 배포하는 기술을 개발하고 있습니다. GPU 대체를 위해 AWS에서 개발한 Inferentia와 Trainium이라는 전용 AI 칩을 주목하고 있습니다. Inferentia와 trainium은 고성능 처리와 빠른 응답 시간을 제공하도록 특별히 설계되었습니다. 이러한 하드웨어를 쉽게 활용할 수 있도록, AWS는 PyTorch 기반의 오픈소스 추론 라이브러리인 NeuronX Distributed(NxD) Inference를 제공합니다. 이 라이브러리는 최소한의 코드 수정만으로 PyTorch 모델을 쉽게 배포할 수 있게 해주며, HuggingFace 모델들과의 손쉬운 통합은 물론 vLLM 같은 서빙 엔진과도 원활하게 연동됩니다.
NxD Inference의 양자화 옵션
NxD Inference는 컴파일시에 양자화 옵션을 제공합니다. 양자화는 weight 텐서에 대해 int8, fp8을 지원하며 KVcache의 경우 fp8 형태를 지원하고 있습니다. fp8의 경우 fp8e4m3, fp8e5m2 두 가지 형태가 있는데 정밀도와 범위 사이에서 trade-off를 줄 수 있습니다. Weight 텐서에 대해 per_tensor_symmetric, per_channel_symmetric 옵션이 있는데, 양자화에 사용되는 scale 스칼라를 텐서당 1개를 사용할지, 채널 (row or column)마다 1개를 사용할 지가 달라집니다.
아래의 예제 코드는 Mistral-12B 모델의 weight 텐서를 int8형태의 per_channel_symmetric으로, KV cache를 fp8로 양자화( kv_cache_quant=True)하여 컴파일하는 예제를 보여줍니다.
원본 모델의 크기는 24.1GB인데, 양자화 후에 13.2GB까지 줄어들었습니다.
Low-sensitive mixed-precision weight quantization
LLM의 weight 텐서를 낮은 정밀도의 데이터 타입으로 양자화할 때, 양자화하는 weight 텐서의 비율이 높을수록 모델 크기는 줄어들고 추론에 사용하는 메모리가 줄어서 서빙 시 최대 throughput은 늘어나게 됩니다. 하지만, 양자화된 weight 텐서의 비율이 높을수록 원본 모델과의 출력 차이는 커지게 됩니다. 특히 transformer 계열의 언어 모델에서 LayerNorm, Embedding, LM head weight 텐서의 경우 양자화에 민감하다고 알려져 있습니다.
Nota AI의 NetsPresso에서는 Transformer와 같은 모델에 대하여 모듈별로 양자화에 얼마나 민감한지를 계산할 수 있습니다. 아래 결과에서 Mistral-12B 모델에 대하여 self-attention 및 input layernorm weight 텐서의 per-channel 양자화를 수행했을 때의 민감도를 확인할 수 있습니다. 민감도 (outlier magnitude)의 경우 weight 텐서의 channel별로 variance를 구한 후 이를 평균한 값을 사용했습니다.
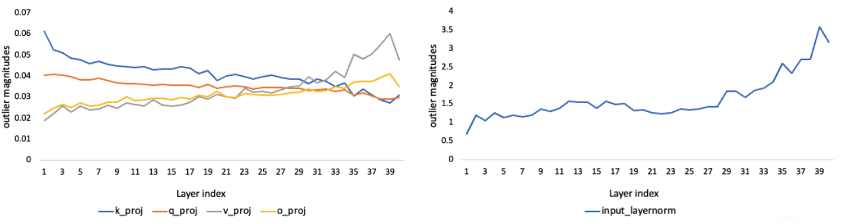
위 결과는 layernorm weight 텐서가 양자화에 대해 민감도가 절대적으로 높다는 기존의 사전지식과 부합하며, self-attention 모듈에 대하여 중간 레이어보다는 첫 부분과 마지막 부분에 가까울수록 민감도가 크다는 경향성을 보여줍니다.
NxD inference에서는 특정한 모듈을 양자화에서 제외시킬 때 `modules_to_not_convert` 옵션을 제공하고 있어 쉽게 선택적 양자화가 가능합니다. 위의 모듈별 양자화 민감도 분석 결과를 바탕으로, 민감도가 특정 임계치 이상인 모듈을 제외하고 양자화를 아래 코드와 같이 수행하였습니다.
새로 양자화된 모델의 정확도, 메모리에 대한 평가 결과는 아래와 같습니다.
| Accuracy (%) | Memory (GB) | ||
| GSM8k | Model weight | Inference peak | |
| Unquantized | 24 | 24.1 | 28.7 |
| All int8 quantized | 19.0 (-20.8%) | 13.2 (-45.2%) | 18.5 (-35.5%) |
| Selective quantized | 22.0 (-8.3%) | 14.7 (-39.0%) | 19.7 (-31.4%) |
모든 weight 텐서를 int8로 양자화 했을 때 GSM8k benchmark의 점수가 -20% 가량이 하락했는데, 양자화에 민감한 모듈만 제외함으로써 점수 하락을 8.3%까지 낮출 수 있었습니다. 이에 반해 model weight 텐서 크기 및 추론시의 peak memory는 각각 6.2%, 4.1%로 소폭 증가하였습니다. 이와 같이 NetsPresso의 민감도 분석과 NxD의 mixed precision 기능을 활용하여 LLM 모델의 memory 사용량과precision 사이의 trade-off를 최적화 할 수 있습니다. NxD inference의 사용자가 mixed precision 기능을 사용할 때, 모듈별 민감도 기반의 선택이 한 가지 예시 기준이 될 수 있습니다.
Trainable weight fake quantization
최근에 LLM weight텐서의 양자화 기법을 다룬 논문들과 이들의 구현체가 오픈소스로 공유되고 있습니다. NxD inference의 사용자들도 LLM을 서빙할 때 고도화된 양자화 기법에 대한 수요가 많을 것으로 예상됩니다. 이에 따라 최신의 LLM weight 텐서 양자화 구현체의Inferentia/Trainium 적용이 가능한지 검토하였습니다.
AWQ, Autoround, SpinQuant 등 많은 weight 텐서 양자화 방법들이 scale, offset등을 찾는 과정이 NVIDIA GPU에서 수행되도록 구현되어 있고, 양자화의 결과물 또한 NVIDIA GPU 및 관련 커널이 있어야 추론 가능한 모델을 제공하는 경우가 많습니다. 이러한 모델의 경우 NxD inference에서 사용 가능하도록 컴파일이 되지 않습니다. Nota AI는 NxD inference에서 쉽게 컴파일되는 LLM 모델의 형태로서 fake-quantization된 형태로의 변환을 고려하였습니다.
Fake-quantization은 실제로 양자화된 데이터 타입 (int8, float8)을 사용하는 대신, 이와 같은 출력을 내는 float32 기반의 연산을 하는방식을 의미한다. 연구 커뮤니티에서 제공하는 weight 텐서 양자화 방법으로 weight/channel마다 scale을 찾았을 때 이를 이용하여 lower-bit로 양자화 후 (wq ), float32으로 복원(wr )하는 절차를 거치면 됩니다.
- quantization: wq =round(w/s)
- dequantization: wr =swq
(w: original float32 weight, s=max(|w|)/Qmax : scale)
아래 그림은 16개의 float32 형태의 weight 값에 대한 int8로의 양자화 및 복원 과정의 예시를 보여줍니다.
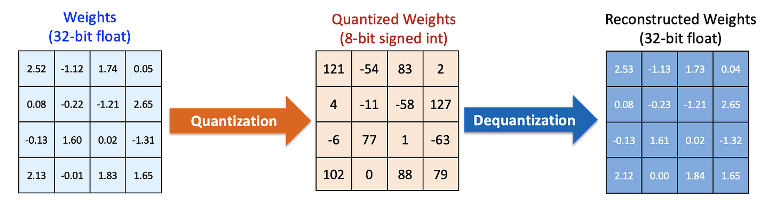
이를 통해 float32 가중치를 가진 모델이 int8과 같은 출력을 내도록 만들 수 있습니다. Fake-quantization은 대부분의 weight 텐서 양자화 기법에 대해 적용 가능한 방법입니다.
Nota AI에서는 LLM weight 텐서 양자화 방법 중 하나로 가중치마다 양자화 레벨을 학습하는 알고리즘을 적용해 보았습니다. Layer-wise로 출력을 비교하여 layer마다 weight 텐서의 양자화 레벨을 정하는 방법 (e.g., Adaround)과, 모델의 최종 출력을 비교하고 전체weight 텐서의 양자화 레벨을 정하는 (e.g., Autoround) 방법등이 있으며, 이 중에서도 Autoround를 사용하였습니다.
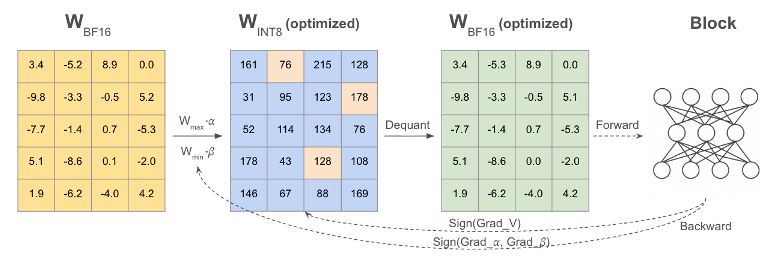
Mistral-12B 모델에 대하여 Autoround 적용 후 fake-quantization 형태로 변환하였습니다. Fake quantization은 NVIDIA GPU상에서 수행되었고, bf16형태의 weight 텐서가 huggingface .safetensors 형태로 저장되었습니다. 해당 모델의 NxD Inference에서 컴파일시에는 weight이 int8 precision을 가지도록 neuron_config을 설정하였습니다.
컴파일된 모델의 벤치마크에 대한 정확도 측정 시 Autoround 방법을 썼을 때 GSM8k 벤치마크 상에서의 정확도 손실이 덜 발생하며, 앞서 소개했던 selective quantization과 함께 사용하면 정확도 손실을 4.2%까지 줄일 수 있습니다.
| GSM8k accuracy (%) | |
| Unquantized | 24 |
| All int8 quantization | 19.0 (-20.8%) |
| Autoround quantization | 21.0 (-12.5%) |
| Selective quantization | 22.0 (-8.3%) |
| Autoround+Selective | 23.0 (-4.2%) |
결론
이번 글에서는 AWS Inferentia/Trainium 환경에서 LLM 모델의 효율적인 양자화 전략에 대해 다루었습니다.
Nota AI는NeuronX Distributed Inference(NxD Inference) 환경에서 다양한 양자화 옵션(int8, fp8, selective quantization 등)을 실험하여 모델 크기와 메모리 사용량을 줄이면서도 정확도 손실을 최소화할 수 있는 방법을 제안하였습니다.
첫째, 기본 양자화 옵션 실험을 통해 모델 크기를 약 45% 감소시키고 추론 시 메모리 사용량을 35% 절감할 수 있었습니다.
둘째, NetsPresso 기반 민감도 분석을 통해 LayerNorm, Embedding, Self-Attention 등의 민감한 모듈을 양자화에서 제외함으로써 정확도 손실을 -8.3% 수준으로 완화할 수 있었습니다.
셋째, Autoround 기반 Fake Quantization을 적용하여 NxD 환경과의 호환성을 유지하면서 정확도 손실을 -4.2%까지 줄이는 효과를 확인하였습니다.
결과적으로, 민감도 기반 선택적 양자화와 Fake Quantization의 조합은 LLM 모델의 처리 효율과 정밀도 간의 균형을 극대화할 수있는 효과적인 접근 방식임을 확인하였습니다.
이는 AWS Inferentia와 Trainium 환경에서 대규모 LLM을 효율적으로 서빙하기 위한 실질적인 방향성을 제시한다고 할 수 있습니다.
마무리
앞으로는 다음과 같은 방향으로 연구와 최적화를 지속할 예정 입니다.
- Activation Quantization 및 Mixed Precision 연구
현재는 weight 중심의 양자화를 수행하였으나, 향후 Activation에 대한 동적 양자화(dynamic quantization)와 per-token 정밀도 조절 방식을 적용하여 추가적인 메모리 절감 효과를 검토할 예정입니다. - KV Cache 효율 최적화 및 Long-context Inference 확장
KV Cache를 fp8로 양자화 한 실험 결과를 기반으로, 긴 시퀀스 입력(Long-context inference) 상황에서의 성능 및 지연(latency) 간의 균형을 분석할 계획입니다. - Cross-backend 호환성 강화 (GPU ↔ Inferentia)
GPU 환경에서 학습된 Autoround/FakeQuant 모델을 Inferentia 환경에서도 원활히 컴파일하고 추론할 수 있도록, cross-backend 변환 파이프라인을 고도화 할 예정입니다. - 다양한 벤치마크 기반 평가 확장
GSM8k뿐만 아니라 MMLU, ARC, HellaSwag 등 다양한 벤치마크를 활용하여, 모델 크기·정확도·응답 속도 간의 최적점을 찾기 위한 실험을 확대할 예정입니다.

김건민
Nota AI의 AI Engineer이며 NPU향 AI 모델 최적화 및 관련 어플리케이션을 개발하고 있습니다.

박한철
Nota AI에서 AI Research Engineer로 재직 중이며, 신뢰성과 안정성이 보장되는 AI 모델 개발 및 모델 최적화/경량화 기술을 개발하고있습니다. 최적화 분야에서는 주로 효율적인 딥러닝 모듈 설계, 양자화 및 커널 최적화에 집중하고 있습니다.

신원진
Nota AI에서 AI Software Engineer로 재직 중이며, AI 모델이 임베디드 디바이스에서 높은 성능을 발휘할 수 있도록 최적화하는 업무를 수행하고 있습니다. 커널 수준의 최적화에 관심을 가지고 있으며, 하드웨어 환경에서 AI 모델이 효율적으로 동작할 수 있도록 개선합니다. AI가 실제 제품에 적용될 수 있도록 문제를 분석하고 해결하는 데 열정을 가지고 있습니다.