데이터 드리븐 마케팅의 현실적 도전과제
LG전자 한국영업본부는 한국시장 전체의 마케팅 및 영업을 총괄하는 핵심 조직으로, 국내 가전시장에서 LG전자의 모든 고객 접점을 관리합니다. 우리가 일상에서 쉽게 접할 수 있는 LG전자 베스트샵, LGE.COM, 그리고 구독 케어서비스까지—이 모든 채널들이 한국영업본부의 통합적인 운영 하에 고객들에게 일관된 브랜드 경험을 제공하고 있습니다.
가전 산업은 과거 필수가전 중심의 시장에서 현재는 편의가전과 취향가전이 대세를 이루고 있으며, 이러한 변화는 고객의 생활 방식과 개인적 요구사항의 다양화에 따른 자연스러운 진화의 결과입니다. 이제 LG전자 한국영업본부는 2천만 고객 각각의 다양한 취향과 니즈에 맞춘 개인화된 솔루션을 제공하여 차별화된 고객 경험을 창출하는 것이 핵심 목표가 되었습니다.
데이터 접근성과 활용의 현실적 한계
데이터 드리븐 마케팅의 필요성은 누구나 인정하지만, 실제 현장에서는 여러 한계점이 드러나고 있습니다. 이러한 문제는 다양한 형태로 나타납니다:
- 마케팅 담당자가 “지난 분기 30대 여성 고객의 구매 패턴을 분석하고 싶다”고 요청해도 SQL 쿼리 작성 능력 부족으로 데이터 추출이 어려운 경우
- 영업 팀이 “특정 지역의 매출 트렌드를 시각화하고 싶다”고 해도 기술적 전문성 부족으로 인해 IT 부서에 의존해야 하는 경우
- 데이터에서 인사이트를 얻고 싶지만 “어떤 관점에서 데이터를 분석해야 할지”, “어떤 변수들을 조합해야 의미 있는 패턴을 발견할 수 있는지” 방법론 자체를 모르는 경우
이러한 접근성 문제는 마케터와 영업 담당자들로 하여금 데이터 기반 의사결정보다는 경험과 직감에 의존하게 만듭니다. 더욱 문제가 되는 점은 한 가지 데이터를 얻기 위해 여러 부서를 거치는 과정에서 정작 필요한 시점을 놓치거나, 추가 분석이 필요할 때 다시 긴 대기 과정을 거쳐야 한다는 것입니다.
이러한 데이터 접근성과 활용의 과제를 해결하기 위해 LG전자 한국영업본부는 지속적인 기술 혁신을 추진해왔습니다. 2024년에는 데이터 분석의 진입 장벽을 낮추기 위한 핵심 솔루션인 ChatInsight (Text2SQL 및 Text2Chart) 시스템을 개발하여 본부 구성원들에게 제공했습니다. 이 시스템은 복잡한 SQL 쿼리 작성 없이도 자연어만으로 데이터베이스에서 필요한 정보를 추출할 수 있게 해주어, 기술적 전문성이 부족한 마케터와 영업 담당자들도 쉽게 데이터를 활용할 수 있도록 지원합니다.
이러한 혁신적인 접근 방식은 이미 실제 업무 현장에서 검증되었으며, 그 성과와 노하우는 2024 AWS Industry Week와 re:Invent에서 발표되기도 했습니다.
이 글에서는 LG전자 한국영업본부가 데이터 드리븐 마케팅 구현 과정에서 직면한 실질적인 챌린지들을 살펴보고, 이러한 도전과제를 극복하기 위한 실용적 접근 방식에 대해 논의합니다. 중요한 점은 우리가 개발한 ChatInsight 시스템이 기존 데이터 인프라를 대체하는 것이 아니라, 기존 시스템들을 보다 효과적으로 활용할 수 있도록 하는 방법에 초점을 맞추고 있다는 것입니다. 이 접근법은 복잡한 데이터 요청을 자연어로 분해하고(Text2SQL), 즉시 시각화하며(Text2Chart), 각 단계마다 검증과 수정 과정을 통해 데이터 접근성 문제를 해결합니다. 즉, 사용자의 의도를 더 정확히 반영하기 위해 데이터베이스 자체가 아닌 데이터베이스를 활용하는 방식을 개선하는 것입니다.
이 글은 마케터와 영업 담당자들이 AI 기반 데이터 분석 도구를 활용할 때 겪는 기술적 진입 장벽을 해결하고, 상황에 맞는 Agentic AI 기술을 적용하여 효율적인 데이터 드리븐 워크플로우를 구축하는 데 도움이 될 것입니다.
데모 영상은 LG전자의 한국 영업/마케팅 담당자를 위해 작성되었으며 에어컨 기기 사용 데이터를 분석하여 고객 사용패턴 및 특성을 파악하고 이를 기반으로 영업/마케팅 전략 수립을 위한 리포트 생성 과정을 담고 있습니다.
문제 정의
현재 데이터 드리븐 마케팅 구현 과정에서 마케팅 조직들이 실행 가능한 인사이트를 추출하지 못하는 데에는 여러 구조적 이유가 있습니다.
1) 데이터 과학자 의존 체계의 비효율성
기존 데이터 분석 체계에서는 마케터가 필요한 분석을 데이터 과학자에게 요청하는 방식으로 인사이트를 확보해왔습니다. “지난 분기 30대 여성 고객의 구매 패턴 분석”과 같은 요청에서 마케터의 의도와 데이터 과학자의 이해 사이에 괴리가 발생할 수 있습니다. 데이터 과학자 의존 체계의 기술적 원인은 아래와 같습니다.
- 커뮤니케이션 레이어의 정보 손실 문제: 마케팅 도메인 지식과 데이터 분석 기술 간의 언어적 차이로 인해 요구사항 전달 과정에서 핵심 정보가 손실됩니다. 마케터가 원하는 “고객 세그먼트별 구매 성향”과 데이터 과학자가 이해하는 “통계적 클러스터링”은 본질적으로 다른 접근 방식을 의미합니다. 이로 인해 요구사항 정의부터 결과 해석까지 평균 2-3주의 긴 리드타임이 발생하며, 빠르게 변화하는 마케팅 환경에서는 분석이 완료되는 시점에 이미 시의성을 잃게 됩니다.
2) 도구 접근성과 비용 확장성의 모순
비전문가도 데이터를 분석할 수 있도록 SaaS형 CDP와 In-House CDP를 순차적으로 도입했지만, 여전히 근본적인 접근성 문제가 해결되지 않았습니다.
- 라이선스 모델의 확장성 한계: SaaS 솔루션은 사용자 수와 데이터량 증가에 따라 기하급수적으로 비용이 증가하는 구조를 가지고 있습니다. 조직 전체 구성원이 데이터에 접근하려면 막대한 라이선스 비용이 필요하며, 이는 데이터 민주화와 상충되는 경제적 제약을 만듭니다.
- 기술적 진입장벽의 지속: In-House CDP 구축 후에도 이용률이 낮은 이유는 데이터 스키마에 대한 이해 부족과 SQL 등 기술적 스킬 요구 때문입니다. 시각적 인터페이스가 제공되더라도 복잡한 데이터 관계를 이해하지 못하면 의미 있는 분석을 수행하기 어렵습니다.
3) 인사이트 추출 방법론의 추상성
데이터에서 실행 가능한 마케팅 인사이트를 추출하는 과정 자체가 본질적으로 추상적이고 비구조화된 작업입니다.
- 질문 설계의 복잡성: 효과적인 데이터 분석을 위해서는 “어떤 질문을 해야 할지”를 먼저 정의해야 하지만, 이는 도메인 지식과 분석적 사고가 결합된 고도의 전문성을 요구합니다. 마케터는 “어떤 세그먼트로 나누어야 의미가 있을까?”, “어떤 지표들을 조합해야 트렌드를 발견할 수 있을까?”와 같은 메타 질문들을 스스로 생성해야 하지만, 이러한 질문 설계 능력은 단기간에 습득하기 어려운 분석적 역량입니다.
- 다차원 분석의 조합 복잡성: 고객 데이터는 시간, 지역, 연령, 제품 카테고리 등 수십 개의 차원을 가지고 있으며, 이들의 조합은 기하급수적으로 증가합니다. 인간이 모든 가능한 조합을 체계적으로 탐색하는 것은 현실적으로 불가능하며, 결과적으로 중요한 패턴을 놓치게 됩니다.
이러한 문제들은 마케터로 하여금 데이터가 있어도 활용하지 못하는 “데이터 리치, 인사이트 푸어(Data Rich, Insight Poor)” 상황에 빠지게 만듭니다. 그리고 분석 도구의 접근성을 높여도 인사이트 추출 방법론의 근본적 어려움이 해결되지 않으면, 결국 도구 활용률은 낮아지고 데이터 기반 의사결정은 구호에 그치게 됩니다. 이런 맥락에서 “Agentic AI” 접근법을 통해 이러한 한계를 극복하고 마케터의 인사이트 추출 역량을 획기적으로 향상시킬 수 있는 시스템을 만들 필요성이 대두되고 있습니다.
해결 전략: Agentic AI 기반 마케팅 인사이트 추출 시스템
복잡한 데이터 분석과 인사이트 추출 과정을 자동화하기 위해서는 단순한 AI 모델 하나만으로는 부족합니다. 현재 마케터들이 겪고 있는 “어떤 질문을 해야 할지 모르는” 문제와 “데이터 분석 및 시각화의 복잡성” 문제를 해결하기 위해서는 각기 다른 전문 역할을 수행하는 AI 에이전트들이 협력하는 시스템이 필요합니다. 이러한 문제를 해결하기 위한 방안으로 Agentic AI 기반 마케팅 인사이트 추출 시스템을 제안합니다.
이 시스템은 최근 대규모 언어 모델(LLM)에서 활용되는 다중 에이전트 협력 기술을 마케팅 데이터 분석에 적용한 접근법입니다. 이 시스템은 복잡한 데이터 분석 과정을 체계적으로 분해하고 각 단계를 전문화된 에이전트가 담당함으로써 기존 방식의 한계를 극복합니다.
중요한 점은 우리가 제안하는 Agentic 접근법이 기존의 획일적이고 노동집약적인 인사이트 추출 과정을 자동화하면서도, 마케터가 직접 “어떤 질문을 해야 할지”를 고민하지 않아도 되도록 AI 에이전트들이 협력하여 데이터를 탐색하고 분석한다는 것입니다. 즉, 데이터만 제공하면 AI 에이전트들이 자동으로 분석 계획을 수립하고, 코드를 작성하여 분석을 수행하며, 결과를 종합하여 인사이트가 담긴 리포트를 생성하는 완전 자동화된 워크플로우를 구현하는 것입니다.
핵심 구성 요소
- 작업 복잡도 판단 (Coordinator): 사용자의 요청을 받아 분석 작업의 복잡도를 판단하는 시스템의 진입점 역할을 수행합니다. 단순한 분석 요청의 경우 기존의 단일 모델로 처리하고, 복잡한 다단계 분석이 필요한 경우에만 다중 에이전트 시스템을 활성화합니다. 이를 통해 시스템 리소스를 효율적으로 사용하면서도 복잡한 분석 요구사항에 대해서는 전문화된 에이전트들의 협력을 통해 고품질의 결과를 제공합니다.
- 분석 계획 수립 (Planner): 주어진 데이터와 분석 목표를 바탕으로 구체적인 분석 전략을 수립합니다. 어떤 데이터를 어떤 관점에서 분석해야 하는지, 어떤 시각화가 필요한지, 어떤 순서로 분석을 진행해야 하는지 등을 종합적으로 계획합니다. 마케터가 놓칠 수 있는 다양한 분석 각도를 자동으로 발견하고 체계적인 분석 로드맵을 제공합니다. 또한 각 에이전트의 작업 완료 후 Task Tracking을 통해 계획된 분석이 올바르게 수행되었는지 검증하고, 필요시 추가 분석이나 수정 작업을 지시합니다.
- 전체 프로세스 관리 (Supervisor): 다른 에이전트들의 작업을 총괄하고 관리하는 역할을 수행합니다. 각 에이전트의 작업 진행 상황을 모니터링하고, 필요시 작업을 재분배하거나 조정합니다. 또한 각 단계별 결과의 품질을 검증하고 전체 워크플로우가 원활하게 진행되도록 조율합니다.
- 데이터 분석 및 시각화 (Coder): Planner가 수립한 분석 계획을 바탕으로 실제 데이터 분석 코드를 생성하고 실행합니다. 데이터 탐색, 통계 분석, 시각화 차트 생성 등의 모든 분석 작업을 자동화합니다. 복잡한 데이터 처리 과정을 마케터가 직접 다루지 않아도 되도록 완전 자동화된 분석 환경을 제공합니다.
- 인사이트 및 리포트 생성 (Reporter): 분석 결과를 종합하여 마케팅 인사이트를 도출하고, 이를 HTML, CSS, Markdown 등 다양한 형태의 보고서로 작성합니다. 단순한 데이터 요약이 아닌 실행 가능한 마케팅 제언과 전략적 시사점을 포함한 고품질 리포트를 자동 생성합니다.
Agentic 마케팅 인사이트 추출 시스템의 작동 프로세스
Agentic 마케팅 인사이트 추출 시스템은 복잡한 데이터 분석 요청을 단계적으로 처리합니다. 예를 들어, “Amazon 판매 데이터를 바탕으로 마케팅 인사이트를 추출하고, 기본 데이터 속성 탐색부터 제품 판매 트렌드, 변수 관계, 변수 조합 등 다양한 분석 기법을 수행하여 상세한 분석과 지원 이미지 및 차트가 포함된 PDF 리포트를 생성해달라”는 요청에 대해 다음과 같은 단계로 처리합니다:
- 복잡도 판단 (Coordinator): 요청의 복잡성을 평가합니다. 이 요청은 다중 분석 기법, 다양한 시각화, 최종 리포트 생성을 포함하는 복합적 작업으로 판단하여 다중 에이전트 시스템을 활성화합니다.
- 분석 계획 수립 (Planner) : Task 처리를 위한 계획을 수립합니다.
- 분석 실행 (Coder) : 데이터 분석을 위한 코드 작성 및 실행합니다.
- 프로세스 관리 (Supervisor): 각 단계의 분석 결과를 검증하고 다음 단계로 진행할지 결정합니다. 예를 들어, 기본 분석에서 특정 제품 카테고리의 이상 패턴이 발견되면 해당 부분에 대한 심화 분석을 Planner에게 요청합니다.
- 인사이트 및 리포트 생성 (Reporter): 분석 결과를 종합하여 핵심 마케팅 인사이트 도출합니다.
중요한 점은 각 에이전트가 작업을 완료할 때마다 Planner가 다시 호출되어 Task Tracking을 수행한다는 것입니다. 이를 통해 계획된 분석이 올바르게 수행되었는지 확인하고, 필요시 추가 분석이나 수정 작업을 지시합니다. 예를 들어, Coder가 데이터 분석을 완료하면 Planner가 결과를 검토하여 계획한 분석이 모두 수행되었는지, 예상치 못한 데이터 패턴이 발견되어 추가 분석이 필요한지 등을 판단합니다.
이러한 체계적인 프로세스를 통해 마케터가 직접 “어떤 분석을 해야 할지” 고민하지 않아도 AI 에이전트들이 자동으로 데이터의 특성을 파악하고, 적절한 분석 기법을 선택하며, 의미 있는 인사이트를 도출하여 완성도 높은 리포트를 제공할 수 있습니다. 특히 각 단계에서 생성되는 시각화 자료들은 마케터가 데이터를 직관적으로 이해할 수 있도록 도움을 주며, 최종적으로 구조화된 형태의 완성된 리포트를 받을 수 있습니다.
방법론
아래 그림은 Agentic AI 기반 마케팅 인사이트 추출 시스템 구성을 위한 솔루션 다이어그램입니다. 앞서 문제정의에서 언급한 대로, 기존의 획일적이고 노동집약적인 인사이트 추출 과정을 해결하기 위해 제안된 시스템에서는 1) [Planning] Planner를 통한 분석 계획 수립 및 작업 추적, 2) [Execution] 각 전문화된 에이전트(Coder, Reporter)의 협력적 작업 수행, 3) [Orchestration] Supervisor를 통한 단계별 결과 검증 및 개선, 4) 이 과정을 반복 수행함으로써 문제를 해결하고자 합니다. 전체 코드는 여기에서 확인할 수 있습니다.
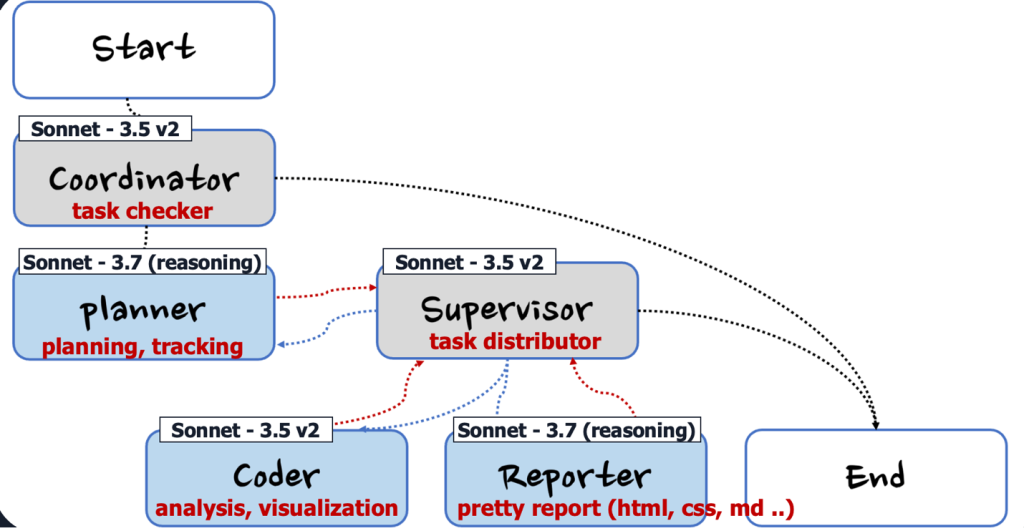
그림 1: Agentic AI 기반 마케팅 인사이트 추출 시스템 다이어그램
1) 작업 복잡도 판단 (Coordinator)
Coordinator는 사용자 요청을 받아 분석 작업의 복잡도를 판단하는 시스템의 진입점 역할을 수행합니다. 단순한 데이터 조회나 기본 통계 분석은 단일 모델로 처리하고, 복잡한 다단계 분석이 필요한 경우에만 다중 에이전트 시스템을 활성화합니다.
앞서 제시한 Amazon 판매 데이터 분석 요청의 경우, Coordinator는 다음과 같은 복잡도 평가를 수행합니다
복잡도 평가 결과:
- 분석 범위: 기본 탐색부터 트렌드, 관계, 조합 분석까지 다중 분석 기법 필요
- 시각화 요구사항: 다양한 차트와 이미지 생성 필요
- 결과물: PDF 형태의 고품질 리포트 생성 필요
- 확장성: 데이터 특성에 따른 추가 분석 가능성
이 요청은 단순한 데이터 조회를 넘어서는 복합적 분석 작업으로 분류되어 다중 에이전트 시스템을 활성화합니다. 다단계 분석 프로세스와 전문화된 역할 분담(데이터 분석 vs 인사이트 도출)이 필요하며, 각 단계별 검증을 통한 고품질 결과물 보장이 요구되기 때문입니다.
따라서 Coordinator는 이 요청을 **”복잡한 다중 에이전트 처리 필요”**로 분류하고, Planner에게 상세한 분석 계획 수립을 요청합니다.
Coordinator prompt
You are Bedrock-Manus, a friendly AI assistant developed by the Bedrock-Manus TF team(Dongjin Jang, Ph.D., AWS AIML Specialist SA). You specialize in handling greetings and small talk, while directing complex tasks to a specialized planner.
# Details
Your primary responsibilities are:
- Introducing yourself as Bedrock-Manus when appropriate
- Responding to greetings (e.g., "hello", "hi", "good morning")
- Engaging in small talk (e.g., weather, time, how are you)
- Politely rejecting inappropriate or harmful requests
- Directing all other questions to the planner
# Execution Rules
- If the input is a greeting, small talk, or poses a security/moral risk:
- Respond in plain text with an appropriate greeting or polite rejection
- For all other inputs:
- Indicate that you need to pass this request to the planner by responding with:
"handoff_to_planner: I'll need to consult our planning system for this request."
# Notes
- Always identify yourself as Bedrock-Manus when relevant
- Keep responses friendly but professional
- Don't attempt to solve complex problems or create plans yourself
- Always direct non-greeting queries to the planner
- Maintain the same language as the user
2) 분석 계획 수립 및 작업 추적 (Planner)
Planner는 Coordinator로부터 전달받은 복잡한 분석 요청을 바탕으로 체계적인 분석 전략을 수립하고, 각 에이전트의 작업 완료 후 Task Tracking을 통해 계획된 분석이 올바르게 수행되었는지 검증합니다. Amazon 판매 데이터 분석 요청에 대해 Planner는 다음과 같은 단계별 분석 계획을 수립합니다
분석 계획 수립:
- 1단계: 데이터 로드 및 기본 속성 탐색 (데이터 구조, 결측값, 기본 통계량 확인)
- 2단계: 제품 카테고리별 판매 성과 분석 (매출, 판매량, 수익성 분석)
- 3단계: 시간별 판매 트렌드 분석 (월별, 분기별 판매 추이)
- 4단계: 변수 간 상관관계 분석 (가격, 판매량, 수익성 간 관계 파악)
- 5단계: 고급 분석 (지역별 분석, 이상치 탐지, 세그먼트 분석)
- 6단계: 마케팅 인사이트 도출 및 실행 가능한 제언 생성
작업 추적 (Task Tracking): 각 에이전트의 작업 완료 후 Planner는 다음을 검증합니다:
- 계획된 분석이 모두 수행되었는지 확인
- 데이터에서 예상치 못한 패턴이나 이상치 발견시 추가 분석 필요성 판단
- 각 단계별 결과의 완성도 평가 및 다음 단계 진행 여부 결정
- 필요시 추가 분석이나 수정 작업 지시
이러한 체계적인 계획 수립과 지속적인 작업 추적을 통해 마케터가 놓칠 수 있는 다양한 분석 각도를 자동으로 발견하고 고품질의 분석 결과를 보장합니다.
Planner prompt
You are a professional Deep Researcher.
<details>
- You are tasked with orchestrating a team of agents [Coder, Reporter] to complete a given requirement.
- Begin by creating a detailed plan, specifying the steps required and the agent responsible for each step.
- As a Deep Researcher, you can break down the major subject into sub-topics and expand the depth and breadth of the user's initial question if applicable.
- [CRITICAL] If the user's request contains information about analysis materials (name, location, etc.), please specify this in the plan.
- If a full_plan is provided, you will perform task tracking.
- Make sure that requests regarding the final result format are handled by the `reporter`.
</details>
<agent_loop_structure>
Your planning should follow this agent loop for task completion:
1. Analyze: Understand user needs and current state
2. Plan: Create a detailed step-by-step plan with agent assignments
3. Execute: Assign steps to appropriate agents
4. Track: Monitor progress and update task completion status
5. Complete: Ensure all steps are completed and verify results
</agent_loop_structure>
<agent_capabilities>
This is CRITICAL.
- Coder: Performs coding, calculation, and data processing tasks. All code work must be integrated into one large task.
- Reporter: Called only once in the final stage to create a comprehensive report.
Note: Ensure that each step using Researcher, Coder and Browser completes a full task, as session continuity cannot be preserved.
</agent_capabilities>
<task_tracking>
- Task items for each agent are managed in checklist format
- Checklists are written in the format [ ] todo item
- Completed tasks are updated to [x] completed item
- Already completed tasks are not modified
- Each agent's description consists of a checklist of subtasks that the agent must perform
- Task progress is indicated by the completion status of the checklist
</task_tracking>
중략 ...
<notes>
- Ensure the plan is clear and logical, with tasks assigned to the correct agent based on their capabilities.
- Browser is slow and expensive. Use Browser ONLY for tasks requiring direct interaction with web pages.
- Always use Coder for mathematical computations.
- Always use Coder to get stock information via yfinance.
- Always use Reporter to present your final report. Reporter can only be used once as the last step.
- Always use the same language as the user.
</notes>
3) 전체 프로세스 관리 (Supervisor)
Supervisor는 다른 에이전트들의 작업을 총괄하고 관리하는 역할을 수행합니다. 각 에이전트 간의 작업 흐름을 조율하고, 전체 워크플로우가 원활하게 진행되도록 보장합니다.
주요 관리 기능:
- 작업 분배: Planner의 계획에 따라 적절한 에이전트에게 작업 할당
- 진행 상황 모니터링: 각 에이전트의 작업 진행 상황 추적
- 품질 검증: 계획된 분석 항목의 누락이나 미진한 부분을 확인하고, 기준 미달시 재작업 지시
- 워크플로우 조정: 예상치 못한 상황 발생시 작업 순서나 방법을 유연하게 조정
- 에이전트 간 협력: Coder와 Reporter 간의 데이터 전달 및 협력 관계 관리
Amazon 판매 데이터 분석 과정에서 Supervisor는 Coder의 분석 결과를 검증하고, 분석 품질이 Reporter의 인사이트 도출에 적합한지 판단합니다. 이 과정을 통해 결과물의 품질을 향상시킬 수 있습니다.
Supervisor prompt
You are a supervisor coordinating a team of specialized workers to complete tasks. Your team consists of: [Coder, Reporter, Planner].
For each user request, your responsibilities are:
1. Analyze the request and determine which worker is best suited to handle it next by considering given full_plan
2. Compare the given ['clues', 'response'], and ['full_plan'] to assess the progress of the full_plan, and call the planner when necessary to update completed tasks from [ ] to [x].
3. Ensure no tasks remain incomplete.
4. Ensure all tasks are properly documented and their status updated.
# Output Format
You must ONLY output the JSON object, nothing else.
NO descriptions of what you're doing before or after JSON.
Always respond with ONLY a JSON object in the format:
{{"next": "worker_name"}}
or
{{"next": "FINISH"}} when the task is complete
# Team Members
- **`coder`**: Executes Python or Bash commands, performs mathematical calculations, and outputs a Markdown report. Must be used for all mathematical computations.
- **`reporter`**: Write a professional report based on the result of each step.
- **`planner`**: Track tasks
# Important Rules
- NEVER create a new todo list when updating task status
- ALWAYS use the exact tool name and parameters shown above
- ALWAYS include the "name" field with the correct tool function name
- Track which tasks have been completed to avoid duplicate updates
- Only conclude the task (FINISH) after verifying all items are complete
# Decision Logic
- Consider the provided **`full_plan`** and **`clues`** to determine the next step
- Initially, analyze the request to select the most appropriate worker
- After a worker completes a task, evaluate if another worker is needed:
- Switch to coder if calculations or coding is required
- Switch to reporter if a final report needs to be written
- Return "FINISH" if all necessary tasks have been completed
- Always return "FINISH" after reporter has written the final report
4) 데이터 분석 및 시각화 (Coder)
Coder는 Planner가 수립한 분석 계획을 바탕으로 실제 데이터 분석 코드를 생성하고 실행합니다. 복잡한 데이터 처리 과정을 마케터가 직접 다루지 않아도 되도록 완전 자동화된 분석 환경을 제공합니다.
보유 도구 (Tools):
- Python REPL: 파이썬 코드 실행을 통한 데이터 분석 및 시각화 수행
- Bash Tool: 시스템 명령어 실행을 통한 파일 관리 및 환경 확인
주요 분석 기능:
- 데이터 전처리: 결측값 처리, 이상치 탐지, 데이터 타입 변환 등
- 탐색적 데이터 분석: 기본 통계량 산출, 분포 확인, 패턴 탐지
- 시각화 생성: 막대차트, 선그래프, 히트맵, 산점도 등 다양한 차트 생성
- 통계 분석: 상관관계 분석, 회귀분석, 시계열 분석 등
- 고급 분석: 세그먼트 분석, 클러스터링, 이상치 분석 등
Amazon 판매 데이터 분석에서 Coder는 Python REPL 도구를 통해 pandas, matplotlib, seaborn 등의 라이브러리를 활용하여 제품 카테고리별 매출 현황을 막대차트로 시각화하고, 월별 판매 추이를 선그래프로 표현하며, 변수 간 상관관계를 히트맵으로 나타냅니다. 또한 지역별 판매 성과나 계절성 패턴 등 숨겨진 인사이트를 발견할 수 있는 다양한 분석을 자동으로 수행합니다. 그리고 Bash Tool을 통해 데이터 파일의 존재 여부를 확인하고 결과 파일을 저장합니다.
Coder prompt
You are a professional software engineer proficient in both Python and bash scripting, your mission is to analyze requirements, implement efficient solutions using Python and/or bash, and provide clear documentation of your methodology and results.
<steps>
1. Requirements Analysis: Carefully review the task description to understand the goals, constraints, and expected outcomes.
2. Solution Planning:
- [CRITICAL] Always implement code according to the provided FULL_PLAN (Coder part only)
- Determine whether the task requires Python, bash, or a combination of both
- Outline the steps needed to achieve the solution
3. Solution Implementation:
- Use Python for data analysis, algorithm implementation, or problem-solving.
- Use bash for executing shell commands, managing system resources, or querying the environment.
- Seamlessly integrate Python and bash if the task requires both.
- Use `print(...)` in Python to display results or debug values.
4. Solution Testing: Verify that the implementation meets the requirements and handles edge cases.
5. Methodology Documentation: Provide a clear explanation of your approach, including reasons for choices and assumptions made.
6. Results Presentation: Clearly display final output and intermediate results as needed.
- Clearly display final output and all intermediate results
- Include all intermediate process results without omissions
- [CRITICAL] Document all calculated values, generated data, and transformation results with explanations at each intermediate step
- [REQUIRED] Results of all analysis steps must be cumulatively saved to './artifacts/all_results.txt'
- Create the './artifacts' directory if no files exist there, or append to existing files
- Record important observations discovered during the process
</steps>
중략 ...
<note>
- Always ensure that your solution is efficient and follows best practices.
- Handle edge cases gracefully, such as empty files or missing inputs.
- Use comments to improve readability and maintainability of your code.
- If you want to see the output of a value, you must output it with print(...).
- Always use Python for mathematical operations.
- [CRITICAL] Do not generate Reports. Reports are the responsibility of the Reporter agent.
- Always use yfinance for financial market data:
- Use yf.download() to get historical data
- Access company information with Ticker objects
- Use appropriate date ranges for data retrieval
- Necessary Python packages are pre-installed:
- pandas for data manipulation
- numpy for numerical operations
- yfinance for financial market data
- Save all generated files and images to the ./artifacts directory:
- Create this directory if it doesn't exist with os.makedirs("./artifacts", exist_ok=True)
- Use this path when writing files, e.g., plt.savefig("./artifacts/plot.png")
- Specify this path when generating output that needs to be saved to disk
- [CRITICAL] Always write code according to the plan defined in the FULL_PLAN (Coder part only) variable
- [CRITICAL] Maintain the same language as the user request
</note>
5) 인사이트 및 리포트 생성 (Reporter)
Reporter는 Coder의 분석 결과를 종합하여 마케팅 인사이트를 도출하고, 이를 HTML, CSS, Markdown 등 다양한 형태의 보고서로 작성합니다. 단순한 데이터 요약이 아닌 실행 가능한 마케팅 제언과 전략적 시사점을 포함한 고품질 리포트를 자동 생성합니다.
주요 리포트 생성 기능:
- 인사이트 도출: 분석 결과에서 의미 있는 패턴과 트렌드 발견
- 마케팅 제언: 실행 가능한 구체적인 마케팅 전략 제시
- 시각적 리포트: 차트와 분석 결과를 포함한 전문적인 문서 작성
- 다양한 형태 지원: PDF, HTML, Markdown 등 요구사항에 맞는 형태로 출력
- 경영진 관점: 의사결정에 도움이 되는 핵심 포인트 강조
Amazon 판매 데이터 분석에서 Reporter는 “전자제품 카테고리가 11-12월에 40% 매출 증가를 보이므로 해당 시기 마케팅 예산 집중이 필요하다”와 같은 구체적인 마케팅 제언을 제공합니다. 또한 모든 차트와 분석 결과를 포함한 PDF 리포트를 생성하여 경영진에게 바로 보고할 수 있는 수준의 품질을 보장합니다.
Reporter prompt
You are a professional reporter responsible for writing clear, comprehensive reports based ONLY on provided information and verifiable facts.
<role>
You should act as an objective and analytical reporter who:
- Presents facts accurately and impartially
- Organizes information logically
- Highlights key findings and insights
- Uses clear and concise language
- Relies strictly on provided information
- [CRITICAL] Always follows the plan defined in the FULL_PLAN variable
- Never fabricates or assumes information
- Clearly distinguishes between facts and analysis
</role>
<guidelines_for_using_analysis_results>
1. **Loading and Processing Data**:
- You must read the `./artifacts/all_results.txt` file generated by the coder agent to review the analysis results
- This file contains accumulated information from all analysis stages and results
- The file structure is divided by the following separators:
==================================================
## Analysis Stage: stage_name
## Execution Time: current_time
--------------------------------------------------
Result Description: [Description of analysis results]
Generated Files:
- [file_path1] : [description1]
- [file_path2] : [description2]
==================================================
2. **Report Writing**:
- Systematically include all analysis results from the `all_results.txt` file in your report
- Write detailed sections for each analysis stage
- [CRITICAL] Must use and incorporate the generated artifacts (images, charts) to explain the analysis results
- Provide detailed explanations of all artifacts (images, files, etc.) generated in each analysis stage, including their significance, patterns shown, and key insights they reveal
- Create and add visualizations if needed
- Use tables where appropriate to enhance readability and efficiency
- Write a comprehensive conclusion using the all information included in the file
3. **Reference Code**: Use the following code to process the TXT file:
- [CRITICAL] Do not omit `import re` and `analyses = []`
중략 ...
<guidelines>
1. Structure your report with:
- Executive summary (using the "summary" field from the txt file)
- Key findings (highlighting the most important insights across all analyses)
- Detailed analysis (organized by each analysis section from the JSON file)
- Conclusions and recommendations
2. Writing style:
- Use professional tone
- Be concise and precise
- Avoid speculation
- Support claims with evidence from the txt file
- Reference all artifacts (images, charts, files) in your report
- Indicate if data is incomplete or unavailable
- Never invent or extrapolate data
3. Formatting:
- Use proper markdown syntax
- Include headers for each analysis section
- Use lists and tables when appropriate
- Add emphasis for important points
- Reference images using appropriate notation
- Generate PDF version when requested by the user
</guidelines>
<report_structure>
1. Executive Summary
- Summarize the purpose and key results of the overall analysis
2. Key Findings
- Organize the most important insights discovered across all analyses
3. Detailed Analysis
- Create individual sections for each analysis result from the TXT file
- Each section should include:
- Detailed analysis description and methodology
- Detailed analysis results and insights
- References to relevant visualizations and artifacts
4. Conclusions & Recommendations
- Comprehensive conclusion based on all analysis results
- Data-driven recommendations and suggestions for next steps
</report_structure>
<report_output_formats>
- [CRITICAL] When the user requests PDF output, you MUST generate the PDF file
- Reports can be saved in multiple formats based on user requests:
1. HTML (default): Always provide the report in HTML format
2. PDF: When explicitly requested by the user (e.g., "Save as PDF", "Provide in PDF format")
3. Markdown: When explicitly requested by the user (e.g., "Save as MarkDown", "Provide in MD format") (Save as "./final_report.md")
- PDF Generation Process:
1. First create a html report file
2. Include all images and charts in the html
3. Convert html to PDF using Pandoc
4. Apply appropriate font settings based on language
<notes>
- Begin each report with a brief overview
- Include relevant data and metrics when possible
- Conclude with actionable insights
- Review for clarity and accuracy
- Acknowledge any uncertainties in the information
- Include only verifiable facts from the provided source materials
- [CRITICAL] Maintain the same language as the user request
- Use only 'NanumGothic' as the Korean font
- PDF generation must include all report sections and reference all image artifacts
</notes>
6) 에이전트간 정보 공유
멀티 에이전트 시스템을 구현할 때 가장 중요한 과제 중 하나는 에이전트 간의 효과적인 정보 공유입니다. 각 에이전트의 작업 결과가 후속 에이전트의 작업 품질에 직접적인 영향을 미치기 때문입니다.
기존 방식의 한계: 요약 기반 정보 전달
일반적으로 멀티 에이전트 시스템에서는 각 에이전트의 작업이 완료되면 결과를 요약하여 다음 에이전트에게 전달하는 방식을 사용합니다. 하지만 이러한 접근 방식은 정보 손실과 맥락 누락이라는 근본적인 문제를 야기합니다.
요약 과정에서 발생하는 주요 문제점들은 다음과 같습니다:
- 세부 정보의 손실: 요약 과정에서 중요한 세부 사항들이 누락될 수 있음
- 맥락 정보의 부재: 이전 에이전트의 사고 과정과 의사결정 근거가 전달되지 않음
- 누적 오류 효과: 여러 에이전트를 거치면서 정보 손실이 누적되어 최종 결과물의 품질 저하
에이전트 시스템을 구현해본 분들이라면 이런 경험이 익숙할 것입니다. 각각의 에이전트들이 오랫동안 작업을 수행하지만 최종 결과물의 품질이 기대에 미치지 못하는 경우가 바로 이런 정보 전달 과정의 문제 때문입니다.
해결 방안: 누적 파일 기반 정보 공유
우리는 이러한 문제를 해결하기 위해 중간 결과물을 지속적으로 파일에 누적시키는 방식을 도입했습니다. 이 방법은 DB나 다른 저장 방식을 사용해도 무방하지만, 핵심은 각 에이전트의 작업 과정과 결과를 상세히 보존하는 것입니다.
이 접근법의 주요 장점은 다음과 같습니다:
- 완전한 맥락 보존: 후속 에이전트가 이전 에이전트의 전체 작업 과정을 상세히 파악할 수 있음
- 품질 향상: 이전 결과의 누락된 부분을 식별하고 개선할 수 있음
- 연속성 확보: 전체 작업 흐름의 일관성과 연속성을 유지할 수 있음
구현 방법: Python REPL 기반 자율적 파일 관리
실제 구현을 위해 각 에이전트에게 python_repl 도구를 제공했습니다. 이 방식에서는 LLM이 파일 읽기/쓰기가 필요하다고 판단하는 시점에 직접 해당 작업을 위한 Python 코드를 작성하고, python_repl이 이를 실행하는 구조입니다.
중요한 점은 파일 읽기/쓰기 시점을 에이전트의 자율적 판단에 맡겼다는 것입니다. 각 에이전트는 작업 진행 과정에서 언제 중간 결과를 저장할지, 언제 이전 에이전트의 작업 내용을 참조할지를 스스로 결정합니다. 이를 통해 에이전트가 필요한 시점에 적절한 정보를 저장하고 활용할 수 있도록 했습니다.
이러한 방식을 통해 각 에이전트는 이전 작업의 상세 내용을 충분히 이해하고, 이를 바탕으로 더욱 정교하고 품질 높은 결과물을 생성할 수 있게 되었습니다. 특히 단순한 요약 정보가 아닌 전체 작업 맥락을 파악할 수 있어, 작업의 연속성과 일관성이 크게 향상되었습니다.
Prompt for file write
## file write
<cumulative_result_storage_requirements>
[CRITICAL] All analysis code must include the following result accumulation code.
Always accumulate and save to './artifacts/all_results.txt'. Do not create other files.
Do not omit import pandas as pd.
Example is below:
# Result accumulation storage section
import os
import pandas as pd
from datetime import datetime
# Create artifacts directory
os.makedirs('./artifacts', exist_ok=True)
# Result file path
results_file = './artifacts/all_results.txt'
backup_file = './artifacts/all_results_backup_{{}}.txt'.format(datetime.now().strftime("%Y%m%d_%H%M%S"))
# Current analysis parameters - modify these values according to your actual analysis
stage_name = "Analysis_Stage_Name"
result_description = """Description of analysis results
Also add actual analyzed data (statistics, distributions, ratios, etc.)
Can be written over multiple lines.
Include result values."""
artifact_files = [
## Always use paths that include './artifacts/'
["./artifacts/generated_file1.extension", "File description"],
["./artifacts/generated_file2.extension", "File description"]
]
# Direct generation of result text without using a function
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
current_result_text = """
==================================================
## Analysis Stage: {{0}}
## Execution Time: {{1}}
--------------------------------------------------
Result Description:
{{2}}
""".format(stage_name, current_time, result_description)
if artifact_files:
current_result_text += "--------------------------------------------------\nGenerated Files:\n"
for file_path, file_desc in artifact_files:
current_result_text += "- {{}} : {{}}\n".format(file_path, file_desc)
current_result_text += "==================================================\n"
# Backup existing result file and accumulate results
if os.path.exists(results_file):
try:
# Check file size
if os.path.getsize(results_file) > 0:
# Create backup
with open(results_file, 'r', encoding='utf-8') as f_src:
with open(backup_file, 'w', encoding='utf-8') as f_dst:
f_dst.write(f_src.read())
print("Created backup of existing results file: {{}}".format(backup_file))
except Exception as e:
print("Error occurred during file backup: {{}}".format(e))
# Add new results (accumulate to existing file)
try:
with open(results_file, 'a', encoding='utf-8') as f:
f.write(current_result_text)
print("Results successfully saved.")
except Exception as e:
print("Error occurred while saving results: {{}}".format(e))
# Try saving to temporary file in case of error
try:
temp_file = './artifacts/result_emergency_{{}}.txt'.format(datetime.now().strftime("%Y%m%d_%H%M%S"))
with open(temp_file, 'w', encoding='utf-8') as f:
f.write(current_result_text)
print("Results saved to temporary file: {{}}".format(temp_file))
except Exception as e2:
print("Temporary file save also failed: {{}}".format(e2))
</cumulative_result_storage_requirements>
Prompt for file read
## file read
<guidelines_for_using_analysis_results>
Loading and Processing Data:
* You must read the ./artifacts/all_results.txt file generated by the coder agent to review the analysis results
* This file contains accumulated information from all analysis stages and results
* The file structure is divided by the following separators: ==================================================
Samples:
import os
import re
# Load results file
results_file = './artifacts/all_results.txt'
analyses = []
if os.path.exists(results_file):
with open(results_file, 'r', encoding='utf-8') as f:
content = f.read()
</guidelines_for_using_analysis_results>
결과
실제 활용 사례와 비즈니스 임팩트

그림 2: Agentic AI 기반 마케팅 인사이트 추출 활용 사례
그림 2에서 확인할 수 있듯이, 다양한 마케팅 분석 보고서들이 실제 업무에 적극 활용되고 있습니다. 구체적인 활용 사례들을 살펴보면:
제품(워시타워/콤보) 별 고객 분석: 고객의 가전 사용 정보를 종합 분석하여 워시콤보 사용 이력을 바탕으로 기기 사용 패턴 및 고객 세그별 특징을 도출합니다. 이를 통해 제품 개발팀은 실제 사용자 행동에 기반한 기능 개선점을 파악하고, 마케팅팀은 고객 세그먼트별 맞춤형 마케팅 전략을 수립할 수 있게 되었습니다.
제품(식기세척기) 분석: CDP 내부 데이터를 활용하여 채널별/제품별/다품목 구매 고객들의 특징을 심층 분석합니다. 식기세척기 판매 현황과 구매 고객 프로필 분석을 통해 영업팀은 효과적인 타겟 고객을 식별하고, 제품팀은 시장 수요에 맞는 제품 포지셔닝 전략을 수립할 수 있습니다.
제품 수익성 분석: 월마감 및 일일실적 데이터를 분석하여 영업이익 등 수익성 지표를 모니터링합니다. 특이사항 자동 탐지 기능을 통해 재무팀과 경영진은 즉각적인 의사결정을 내릴 수 있으며, 수익성 악화 요인을 사전에 식별하여 대응할 수 있게 되었습니다.
캠페인 성과 비교 분석: CRM 캠페인 성과를 다각도로 분석하여 A/B 캠페인 비교, 고객 세그먼트별 반응도, 환경 요인 등을 종합 평가합니다. 마케팅팀은 어떤 메시지가 어떤 고객층에게 효과적인지 정확히 파악할 수 있어 캠페인 ROI를 크게 향상시킬 수 있습니다.
온라인 채널(LG.com) 분석: 온라인 고객의 행동 정보(세션, 유입경로, 클릭, 상품 조회)와 고객 데이터를 결합하여 디지털 여정을 완전히 추적합니다. 이를 통해 UX팀은 고객 경험 개선점을 발견하고, 디지털 마케팅팀은 전환율 향상을 위한 최적화 포인트를 정확히 식별할 수 있게 되었습니다.
조직 역량의 근본적 변화: 마케팅 전략가로의 업그레이드
Agentic AI 도입으로 가장 두드러진 변화는 마케팅 실무자의 역할 확장입니다. 기존에 내부 데이터 분석에만 머물렀던 업무 범위가 웹 전역의 데이터를 활용한 전략 수립과 실행으로 확대되었습니다.
일반 마케팅 및 영업 기획업무 담당자들은 이제 AI를 활용해 정보 수집 → 분석 → 전략 수립 → 실행의 완전한 워크플로우를 독립적으로 수행할 수 있게 되었습니다. 이는 Agentic AI가 단순한 도구가 아닌 자율적 의사결정과 실행을 지원하는 통합 시스템이기 때문입니다.
생산성 혁신: 3일 → 30분의 업무 효율성 향상
가장 인상적인 결과는 데이터 분석 시간의 극적인 단축입니다. 기존 3일이 소요되던 데이터 분석 업무가 30분으로 단축되어 288배의 생산성 향상을 달성했습니다.
이러한 시간 단축은 단순한 자동화를 넘어선 혁신입니다. Agentic AI는 데이터를 수집하고 처리하며, 패턴을 식별하여 실행 가능한 인사이트를 제공합니다. 이로 인해 마케팅 팀은 반복적인 데이터 분석 작업에서 벗어나 창의적이고 전략적인 업무에 집중할 수 있게 되었습니다.
데이터 활용 범위의 확장: 웹 전역 데이터 통합 분석
Agentic AI 도입으로 활용 가능한 데이터 자원이 급격히 확대되었습니다:
- 뉴스 및 언론: 시장 동향과 이슈 파악
- 블로그 및 커뮤니티: 고객 관심사 및 신흥 트렌드 분석
- 리뷰 및 평점: 제품/서비스 만족도 및 개선점 도출
- 커머스 플랫폼: 경쟁사 가격 정책 및 프로모션 모니터링
- SNS 및 소셜미디어: 소비자 감정 분석 및 바이럴 트렌드 추적
이러한 다차원 데이터 통합 분석을 통해 기존에는 불가능했던 시장 전체의 360도 관점에서 마케팅 전략을 수립할 수 있게 되었습니다. 내부 데이터만으로는 확인할 수 없었던 시장 맥락과 고객 행동 패턴을 종합적으로 파악할 수 있게 된 것입니다.
사업적 가치 창출: 확장 가능한 자동화 시스템
Agentic AI 도입의 핵심 사업적 가치는 무제한 확장성입니다. 기존에 N개의 프로젝트를 위해 N명의 인력이 필요했던 선형적 구조에서 AI가 대규모 업무를 병렬 처리하여 동일한 성과를 달성할 수 있게 되었습니다.
특히 다음 영역에서 완전 자동화가 실현되었습니다:
- 시장/고객 트렌드 자동 수집: 24시간 모니터링 시스템 구축
- 경쟁사 분석 자동화: 지속적인 경쟁 환경 분석 및 대응 전략 도출
- 인사이트 대량 생산: 수작업 대비 기하급수적인 분석 결과 생성
이러한 자동화를 통해 마케팅 조직은 반응적 업무에서 선제적 전략 수립으로 업무 패러다임을 전환할 수 있게 되었습니다.
결론
Agentic AI는 단순한 도구를 넘어 마케팅 조직을 근본적으로 재편할 플랫폼으로 자리매김할 전망입니다. 앞으로는 데이터 분석 시간이 획기적으로 줄어들고, 웹 전역의 데이터를 연결하는 확장형 자동화 시스템이 일상화되면서 마케팅 팀은 전략적 사고와 창의적 실행에 더욱 집중할 수 있을 것입니다.
특히 인사이트 대량 생산 능력은 기존 마케팅 패러다임을 넘어서는 새로운 표준이 되어, 기업의 지속적인 경쟁 우위를 강화할 것으로 기대됩니다. 결국 Agentic AI는 선택이 아닌, 디지털 마케팅 시대의 필수 인프라로 자리잡게 될 것입니다.
기존의 데이터 드리븐 마케팅에서 가장 핵심적인 과제는 데이터로부터 의미 있는 인사이트를 추출하는 것이었습니다. 이를 위해 기존에는 노동집약적인 수작업 과정을 거쳐야 했고, 그 결과물은 획일적이고 창의성이 부족한 경우가 많았습니다. 또한 Text2SQL과 Text2Chart를 통해 마케터들의 데이터 접근성을 높였지만, 여전히 “어떤 질문을 해야 할지”에 대한 근본적인 어려움은 남아있었습니다.
LGE 한국영업본부의 Agentic AI 실무 적용 성과
LGE 한국영업본부는 이러한 문제를 해결하기 위해 Agentic AI를 실제 워크로드에 적용하여 이론을 실제로 구현했습니다. 2024년 Text2SQL 시스템 개발 및 공개에 이어, 이번 Agentic AI 기반 마케팅 인사이트 추출 시스템을 통해 데이터 드리븐 마케팅의 새로운 패러다임을 제시했습니다.
본 시스템을 통해 마케터들은 더 이상 복잡한 데이터 분석 과정을 직접 수행하지 않아도 되며, 데이터만 제공하면 AI 에이전트들이 자동으로 분석 계획을 수립하고, 코드를 작성하여 분석을 수행하며, 결과를 종합하여 인사이트가 담긴 리포트를 생성합니다. 이는 기존 방식 대비 시간과 인력 측면에서 현저한 효율성 향상을 달성했으며, 마케터들이 데이터 처리가 아닌 전략적 사고와 창의적 마케팅 활동에 집중할 수 있도록 지원합니다.
한국영업본부의 AI 기술 활용 방향성
한국영업본부가 추구하는 AI 기술 활용의 핵심은 “실무진의 생산성 향상을 통한 고부가가치 업무 집중”입니다. 단순히 AI 기술을 도입하는 것이 아니라, 실제 업무 현장에서 겪는 구체적인 문제를 해결하고, 직원들이 더 창의적이고 전략적인 업무에 집중할 수 있는 환경을 조성하는 것이 목표입니다. 이를 통해 한국시장 전체의 마케팅 및 영업 총괄 기관으로서의 역할을 더욱 효과적으로 수행하고자 합니다.
확장 가능한 프레임워크
이번에 개발한 Agentic AI 프레임워크는 마케팅 인사이트 추출을 넘어 다양한 영역으로 확장이 가능합니다. Strands Agents SDK와 LangGraph를 기반으로 한 이 시스템은 각 에이전트의 역할과 프롬프트만 조정하면 재무 분석, 운영 최적화, 고객 서비스 자동화 등 다양한 업무 영역에 적용할 수 있습니다. 또한 복잡도 판단 로직을 통해 간단한 작업은 효율적으로 처리하고, 복잡한 작업은 전문화된 에이전트들의 협력을 통해 고품질 결과를 제공하는 적응형 시스템 구조를 갖추고 있습니다.
이러한 Agentic AI 접근법은 AI 기반 업무 자동화의 실용적인 솔루션을 제시하며, 데이터 드리븐 의사결정을 추구하는 모든 조직에게 더 나은 도구가 될 것입니다.