LG전자의 AI 기반 소셜미디어 인사이트 혁신
LG전자는 시장 대응력 향상과 고객 만족도 증대를 위해 YouTube 및 블로그 등 소셜미디어 플랫폼에서 자사 제품과 경쟁사 제품에 대한 인사이트를 추적하는 생성형 AI 기반 소셜미디어 모니터링 시스템을 구축했습니다. AWS Generative AI Innovation Center와 협력하여 개발한 이 시스템은 Amazon Bedrock의 Claude Sonnet과 Nova Pro 모델을 활용해 대규모 비디오 자막과 사용자 댓글을 자동으로 처리하고 분석하여 데이터 기반 의사결정을 위한 정량적 비즈니스 인사이트를 추출합니다. 일차적으로 5개 제품군을 대상으로 YouTube동영상을 대상으로 테스트를 진행하여 시스템 평가를 구축했으며, 향후에는 더 많은 제품군으로 확대하는 동시에 인스타그램과 같은 다른 소셜미디어 플랫폼까지 모니터링 범위를 확장할 계획입니다. 이번 글에서는 이 프로젝트의 핵심인 데이터 처리 파이프라인 설계, 프롬프트 엔지니어링과 평가 방법론을 중심으로 실무 경험을 공유하며, 특히 LLM 기반 시스템의 성능을 정량적으로 평가하고 검증하는 실무적인 방법론에 대해 상세히 다루겠습니다.
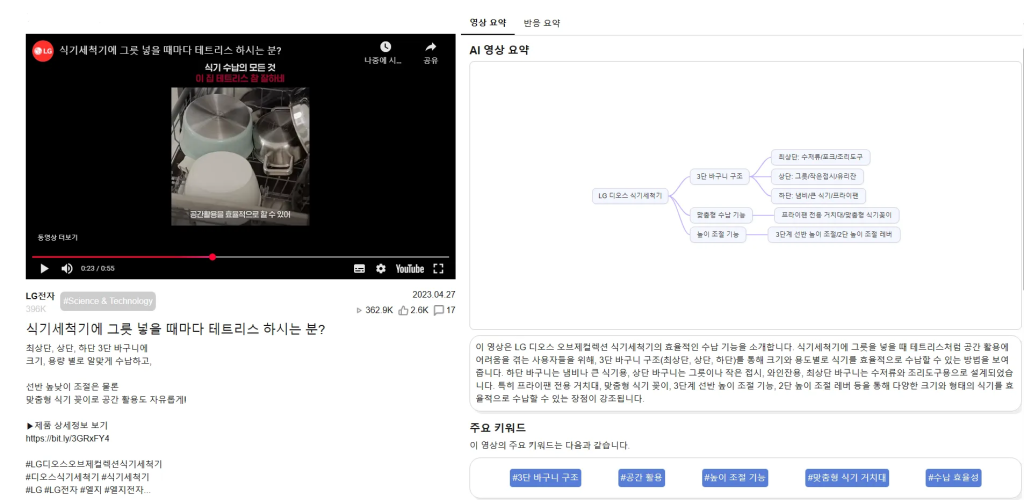
플랫폼 주요 기능
- 비디오 콘텐츠 분석: 동영상을 제품 카테고리와 콘텐츠 유형별로 자동 분류하며, 주요 관심 기능과 감성 분석, 핵심 키워드 추출을 수행합니다. 또한 요약 내용을 단순한 텍스트가 아닌 Tree 형태로 제공하여 동영상 내용의 가시성을 높입니다.
- 사용자 댓글 분석: 동영상의 댓글을 분석하여 사용자 반응을 파악하고 통계적으로 유의미한 수치를 도출합니다. 제품 관련 댓글만을 대상으로 하는 사전 필터링을 적용하고, 병렬 처리를 통해 대량의 댓글 데이터를 효율적으로 처리합니다. 또한 주요 맥락이 누락될 수 있는 댓글의 특성을 고려하여 상위 댓글과의 맥락을 통합함으로써 분석 정확도를 향상시킵니다.
- 실시간 Q&A 시스템: 영상 요약이나 사용자 댓글 분석 페이지에서 답변을 찾기 어려운 경우, 사용자가 특정 동영상을 선택하여 추가 정보를 얻을 수 있는 실시간 Q&A 기능을 제공합니다. 대화형 AI 모델에 동영상의 전체 transcript와 타임스탬프 정보를 제공하여, 사용자 질문에 대한 답변과 함께 해당 내용이 포함된 동영상 구간의 타임스탬프를 함께 제공함으로써 사용자가 원본 영상의 관련 부분을 쉽게 확인할 수 있도록 합니다.
솔루션 아키텍처
LG전자는 한국 고객의 모든 데이터를 통합한 CDP(Customer Data Platform)을 구축하고 그 위에 기술적 배경이 없는 사용자도 쉽고 빠르게 소셜미디어 인사이트를 활용할 수 있는 CDP Explorer Social Insight Hub를 개발했습니다. 이 시스템은 사용자의 요청에 따라서 유튜브 영상 크롤링 도구를 통해 해당 동영상 메타데이터와 자막정보를 실시간 또는 배치로 수집하고 AWS Bedrock을 이용하여 비디오 콘텐츠 및 사용자 댓글을 분석을 수행합니다. AWS Redshift에서 전처리 및 마트를 생성하고 최종 정리된 데이터는 RDS 저장하여 사용자에게 분석된 결과를 제공하고 있습니다. 앞서 소개한 3가지 핵심 기능들이 실제로 어떻게 CDP Explorer Social Insight Hub 에서 유기적으로 연결되어 동작하는지 상세히 살펴보겠습니다.
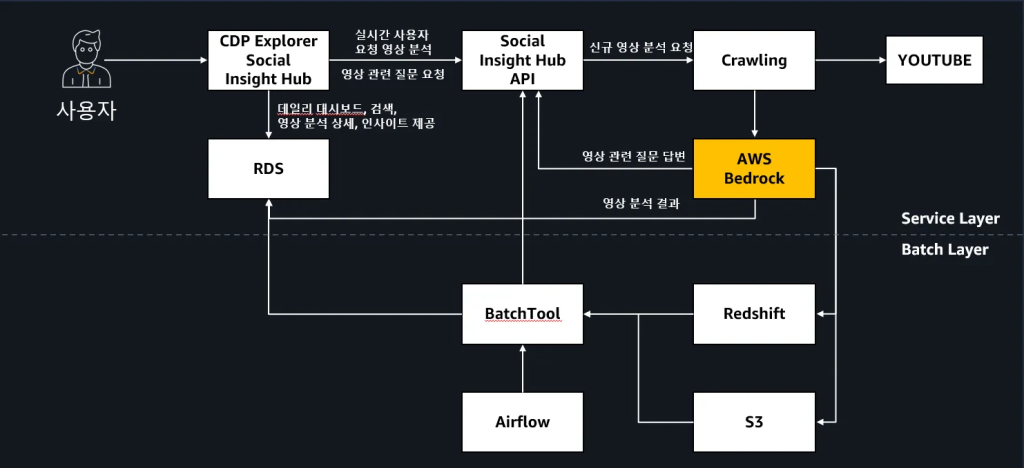
배치 처리 기반의 데이터 분석 파이프라인
이 시스템의 분석 작업은 사전에 계획된 배치 작업으로 수행되며, 각 단계의 결과가 다음 단계의 입력 데이터로 활용되는 체계적인 구조입니다. 먼저 크롤링 모듈을 통해 YouTube에서 수집된 동영상 자막 데이터와 메타정보가 S3에 저장됩니다. 이후 Airflow가 스케줄링하는 배치 작업이 시작되면, Amazon Bedrock을 활용한 첫 번째 분석 단계가 진행됩니다. 이 분석에서는 주로 Anthropic Claude Sonnet 3.7 모델을 활용하며, 일부 감성 분석 작업에는 Amazon Nova Pro를 사용하였습니다.
여기서 추출된 분석 결과들은 데이터의 성격에 따라 차별화된 저장 전략을 사용합니다. 대용량 통계 데이터와 집계 결과는 Aamzon Redshift에 전처리되어 분석용 데이터 웨어하우스에 적재되고, 실시간 서비스에서 빠른 조회가 필요한 구조화된 메타데이터와 분석 결과는 Amazon RDS의 관계형 데이터베이스에 저장됩니다. 이러한 이중 저장 구조를 통해 후속 분석 단계에서는 분석용 데이터를, 사용자 서비스에서는 최적화된 서빙 데이터를 각각 활용할 수 있도록 체계적으로 관리됩니다.
1단계: 비디오 콘텐츠 분석 처리
비디오 콘텐츠 분석은 단순히 한 번에 모든 것을 분석하는 것이 아니라, 정확도를 높이기 위해 단계적 추출 작업이 진행됩니다. 추출된 키워드들은 단순한 단어 나열이 아니라, 제품의 특성과 사용자 관심사를 반영한 구조화된 키워드 맵으로 구성됩니다. 이 키워드를 기반으로 두 번째 분석 단계가 진행되는데, 이때 제품 카테고리 분류, 주요 관심 기능 식별, 감성 분석이 수행됩니다. 마지막으로 세 번째 단계에서는 댓글의 분석 요약을 이전 단계에서 추출한 내용과 종합하여 Tree 형태의 구조화된 요약을 생성합니다.
2단계: 컨텍스트 기반 댓글 분석
동영상 분석이 완료되면, 그 결과가 댓글 분석의 중요한 컨텍스트 정보로 활용됩니다. BatchTool이 동영상별 댓글 데이터를 Amazon Redshift에서 불러와 배치 처리를 시작할 때, 이미 완료된 동영상 분석 결과(키워드, 주요 기능, 카테고리 정보)가 함께 제공됩니다. 댓글 분석 과정에서는 병렬 처리를 통한 효율성과 맥락 통합을 통한 정확성이 핵심입니다. 대량의 댓글 데이터를 여러 워커가 동시에 처리하되, 상위 댓글과 하위 댓글 간의 맥락적 연관성정보를 제공하여 분석을수행합니다. 이때 동영상 분석에서 추출된 키워드와 요약 내용들이 활용되어, 제품과 관련된 댓글만을 선별적으로 분석하게 됩니다.
실시간 Q&A: 사전 처리된 데이터의 활용
실시간 Q&A 시스템은 사용자가 특정 동영상에 대해 질문을 할 때, 배치 처리를 통해 미리 구축된 컨텍스트 데이터를 즉시 활용하여 답변을 제공합니다. 이 컨텍스트 데이터에는 동영상의 전체 자막 데이터와 타임스탬프 정보가 포함되어 있습니다. Amazon Bedrock을 통해 서빙되는 LLM 모델을 활용하여 사전 처리된 데이터를 기반으로 사용자의 질문을 정확하게 해석합니다. 단순한 텍스트 검색을 넘어서 해당 내용이 언급된 정확한 타임스탬프를 함께 제공하여, 사용자가 동영상의 핵심 구간을 직접 확인하며 더 정확한 맥락을 파악할 수 있도록 지원합니다. 이 태스크를 위해서는 빠른 응답 속도 제공을 위해 Nova Pro의 고성능 처리 능력을 활용하였습니다.
앞서 설명한 다단계 분석 파이프라인에서 일관되고 정확한 결과를 얻기 위해서는 체계적인 프롬프트 엔지니어링과 평가 방법론이 필수적입니다. 특히 다양한 언어와 복잡한 분석 작업들을 효과적으로 처리하기 위한 프롬프트 설계 전략이 중요한 역할을 합니다.
프롬프트 엔지니어링 및 평가 방법론
프롬프트 설계 원칙
- 다국어 단일 프롬프트 적용
다국어 콘텐츠 처리에서는 언어별로 별도의 프롬프트를 개발하는 대신, 단일 프롬프트를 활용하는 전략을 채택했습니다. 이를 통해 프롬프트 관리의 복잡성을 줄이면서도 일관된 분석 품질을 유지할 수 있도록 설계했습니다.
- 작업 복잡도에 따른 분리 설계
작업의 복잡도와 정확도 요구사항에 따라 프롬프트를 전략적으로 분리했습니다. 제품 코드 추출, 비디오 타입 분류, 제품군 분류 등 비교적 단순하지만 정확도가 매우 중요한 분류 작업들은 별도의 프롬프트로 분리하여 처리했습니다. 이러한 단순 분류 작업에서는 모델이 일관된 판단을 내릴 수 있도록 temperature를 0으로 설정하여 최대한 동일한 결과가 나오도록 하였습니다.
반면 복합적인 분석이 필요한 감정 분석이나 종합 요약 작업은 보다 복잡한 프롬프트 구조를 사용했습니다. 이때 출력 형식은 후처리의 용이성을 위해 구조화된 HTML 형식을 적용했습니다.
- 평가 기반 반복 개선
모든 프롬프트 개선 작업은 체계적인 평가 방법론을 기반으로 수행했습니다. 프롬프트를 수정할 때마다 정량적 평가 프레임워크를 적용하여 성능 변화를 측정하고, 개선 효과를 검증한 후 적용했습니다. 이러한 데이터 기반 접근을 통해 주관적 판단보다는 객관적 성능 지표에 근거한 프롬프트 최적화가 가능했습니다.
평가 프레임워크 설계
이번 프로젝트에서는 주로 동영상 콘텐츠와 사용자 댓글에 대한 요약, 주요 관심사항, 장단점 등의 정보를 추출하는 작업을 수행했습니다. 하지만 정답이 없는 생성형 작업의 특성상 LLM이 생성한 결과를 객관적으로 평가하기가 매우 어려웠습니다. 이러한 문제를 해결하기 위해 LLM as Judge 방식을 채택하여 체계적인 평가 방법론을 구축했습니다.
주요 평가 대상은 콘텐츠 요약 태스크와 키워드 추출 태스크로 구분되며, 각각의 특성에 맞는 차별화된 평가 방식을 적용했습니다. 요약 태스크에서는 DeepEval을 활용하여 정렬성(Alignment)과 포괄성(Coverage) 등의 품질 지표를 중심으로 평가했으며, 키워드 추출 태스크에서는 일관성(Consistency)과 품질 평가를 위해 별도의 커스텀 평가 메트릭 평가 방식을 개발하여 사용했습니다.
요약 평가
동영상 콘텐츠 분석 파이프라인에서 생성된 요약의 품질을 체계적으로 평가하기 위해 다층적 평가 프레임워크를 설계했습니다. 이 프레임워크는 DeepEval의 기본 제공 Summarization Metric과 사용자 정의 메트릭을 결합하여 요약 성능을 다각도로 측정합니다.
- 정렬성(Alignment): 생성된 요약이 원본 콘텐츠와 사실적으로 일치하는지 평가합니다. 이 지표는 요약 과정에서 발생할 수 있는 환각(hallucination) 현상을 탐지하여, 원본에 존재하지 않는 정보의 추가나 사실 왜곡을 방지합니다.
- 포괄성(Coverage): 원본 콘텐츠의 핵심 정보가 요약에 얼마나 충실히 반영되었는지 측정합니다. 중요한 내용의 누락 없이 원본의 주요 논점과 세부사항이 적절한 비율로 포함되었는지를 평가합니다.
- 반복성(Repetitiveness): 요약 내 중복 콘텐츠를 식별하는 사용자 정의 메트릭입니다. 동일한 정보의 불필요한 반복을 탐지하여 요약의 정보 밀도와 효율성을 평가합니다.
- 모호성(Vagueness): 요약의 구체성과 정보 가치를 판단하는 사용자 정의 메트릭입니다. 일반적이고 추상적인 표현보다는 구체적이고 실용적인 정보 제공 여부를 측정합니다.
실제 평가 결과에서 모호성과 반복성 지표는 대부분의 모델에서 높은 점수를 기록하여 모델 간 차별화에 제한적이었습니다. 따라서 본 분석에서는 정렬성과 포괄성을 중심으로 모델 성능을 비교 분석했습니다. 그럼에도 불구하고 DeepEval에서 사용자 정의 메트릭을 구현하는 방법론을 소개하기 위해 모든 지표를 포함하여 설명하겠습니다.
환경 설정 및 라이브러리 설치
DeepEval 프레임워크를 사용하기 위해서는 먼저 필요한 라이브러리들을 설치합니다.
# DeepEval 프레임워크 설치
pip install deepeval
# AWS Bedrock과의 연동을 위한 LangChain AWS 라이브러리 설치
pip install langchain_aws
사용자 정의 LLM 클래스 구현
AWS Bedrock 모델을 DeepEval에서 사용하기 위해서는 DeepEvalBaseLLM 클래스를 상속받는 커스텀 클래스를 구현해야 합니다. 이 클래스는 DeepEval이 Bedrock 모델과 통신할 수 있도록 하는 역할을 합니다.
import boto3
from deepeval import evaluate
from langchain_aws import ChatBedrock
from deepeval.models.base_model import DeepEvalBaseLLM
from deepeval.metrics import SummarizationMetric
from deepeval.test_case import LLMTestCase
class BedrockLLM(DeepEvalBaseLLM):
"""
AWS Bedrock 모델을 DeepEval에서 사용하기 위한 래퍼 클래스
DeepEvalBaseLLM을 상속받아 필수 메서드들을 구현
"""
def __init__(self, model):
"""
Args:
model: LangChain ChatBedrock 인스턴스
"""
self.model = model
def load_model(self):
"""모델 인스턴스를 반환"""
return self.model
def generate(self, prompt: str) -> str:
"""
동기적으로 텍스트를 생성하는 메서드
Args:
prompt: 입력 프롬프트
Returns:
생성된 텍스트
"""
chat_model = self.load_model()
response = chat_model.invoke(prompt)
if hasattr(response, 'content'):
return response.content
# Fallback if it's already a string
return str(response)
async def a_generate(self, prompt: str) -> str:
"""
비동기적으로 텍스트를 생성하는 메서드
Args:
prompt: 입력 프롬프트
Returns:
생성된 텍스트
"""
chat_model = self.load_model()
response = await chat_model.ainvoke(prompt)
# Extract the content from the response object
if hasattr(response, 'content'):
return response.content
# Fallback if it's already a string
return str(response)
def get_model_name(self):
"""평가 결과에 표시될 모델명을 반환"""
return "Custom AWS Bedrock Model"
Bedrock 클라이언트 설정 및 모델 초기화
이제 실제 AWS Bedrock 클라이언트를 설정하고 Anthropic Claude Sonnet 모델로 초기화해보겠습니다. 이 단계에서는 모델의 파라미터들도 함께 설정할 수 있습니다.
# AWS Bedrock 런타임 클라이언트 생성
# 서울 리전 사용
bedrock_client = boto3.client(
'bedrock-runtime',
region_name="ap-northeast-2",
)
# ChatBedrock 모델 인스턴스 생성
custom_model = ChatBedrock(
# Claude 3.7 Sonnet 모델 ID 지정
model_id="apac.anthropic.claude-3-7-sonnet-20250219-v1:0",
client=bedrock_client,
model_kwargs={
"temperature": 0.0, # 일관된 결과를 위해 Temperature 설정
"max_tokens": 4096 # 최대 토큰 수 제한
}
)
# DeepEval용 래퍼 클래스로 감싸기
bedrock_llm = BedrockLLM(model=custom_model)
# 모델 연결 테스트
print(bedrock_llm.generate("모델 연결 테스트"))
평가 시 Throttling 에러 해결방안
AWS Bedrock을 사용할 때 많은 요청으로 인해 throttling 에러가 발생할 수 있습니다. 이런 경우 LiteLLM을 활용하면 효과적으로 해결할 수 있습니다.
LiteLLM은 다양한 LLM 제공업체들의 API를 통합하여 관리할 수 있는 라이브러리입니다. 주요 특징은 다음과 같습니다:
- 통합 인터페이스: OpenAI, Anthropic, AWS Bedrock, Azure OpenAI 등 다양한 모델을 동일한 API로 호출
- 자동 로드밸런싱: 여러 모델 엔드포인트 간 요청 분산
- 에러 핸들링: Rate limiting, throttling 등의 에러에 대한 자동 재시도 및 fallback
- 다중 리전 지원: 여러 AWS 리전에 분산된 모델을 동시 활용하여 처리량 증대
이를 위해 다음과같은 추가 라이브러를 설치합니다.
pip install langchain litellm
먼저 각 모델별로 사용 가능한 AWS 리전과 해당 모델 ID를 매핑하는 딕셔너리를 정의합니다. 그리고 LiteLLM의 Router 기능을 활용하여 다중 리전 Bedrock 모델을 관리하는 래퍼(Wrapper) 클래스를 구현합니다.
import boto3
import json
import asyncio
from typing import Optional, Any, List, Dict
from langchain.llms.base import LLM
from litellm import Router
import litellm
# Claude 3.7 Sonnet 모델의 리전별 매핑
claude37_region_model_dict = {
"ap-northeast-2": "bedrock/converse/apac.anthropic.claude-3-7-sonnet-20250219-v1:0", # 서울 리전
"us-east-1": "bedrock/converse/us.anthropic.claude-3-7-sonnet-20250219-v1:0", # 버지니아 북부
"us-west-2": "bedrock/converse/us.anthropic.claude-3-7-sonnet-20250219-v1:0", # 오레곤
"eu-central-1": "bedrock/converse/eu.anthropic.claude-3-7-sonnet-20250219-v1:0", # 프랑크푸르트
}
# Claude 4.0 모델의 리전별 매핑
claude40_region_model_dict = {
"ap-northeast-2": "bedrock/converse/apac.anthropic.claude-sonnet-4-20250514-v1:0", # 서울 리전
"us-west-2": "bedrock/converse/us.anthropic.claude-sonnet-4-20250514-v1:0", # 오레곤
"eu-central-1": "bedrock/converse/eu.anthropic.claude-3-7-sonnet-20250219-v1:0", # 프랑크푸르트 (3.7로 fallback)
}
class BedrockLiteLLM(LLM):
"""
LiteLLM Router를 활용한 다중 리전 Bedrock 모델 래퍼 클래스
LangChain의 LLM 기본 클래스를 상속받아 호환성 보장
"""
model_name: str # 사용할 모델명 (예: "anthropic.claude-3-7-sonnet-20250219-v1:0")
def _call(self, prompt, stop=None):
"""
동기적 텍스트 생성을 위한 핵심 메서드
모델명에 따라 적절한 리전별 모델 리스트를 구성하고 Router를 통해 호출
"""
# Claude 3.7 Sonnet 모델인 경우
if self.model_name == "anthropic.claude-3-7-sonnet-20250219-v1:0":
model_list = []
# 각 리전별로 모델 설정을 생성
for region, model_path in claude37_region_model_dict.items():
template = {
"model_name": "anthropic.claude-3-7-sonnet-20250219-v1:0", # 논리적 모델명
"tpm": 1000000, # TPM(Tokens Per Minute) 제한 설정
}
# LiteLLM 파라미터 설정 (실제 Bedrock 모델 경로와 리전 정보)
template["litellm_params"] = {
"model": model_path, # 실제 Bedrock 모델 경로
"aws_region_name": region # AWS 리전명
}
model_list.append(template)
# Claude 4.0 모델인 경우
elif self.model_name == "anthropic.claude-sonnet-4-20250514-v1:0":
model_list = []
# Claude 4.0용 리전별 모델 설정 생성
for region, model_path in claude40_region_model_dict.items():
template = {
"model_name": "anthropic.claude-sonnet-4-20250514-v1:0",
"tpm": 1000000,
}
template["litellm_params"] = {
"model": model_path,
"aws_region_name": region
}
model_list.append(template)
else:
# 지원하지 않는 모델명인 경우 예외 발생
raise ValueError(f"지원하지 않는 모델명: {self.model_name}")
# LiteLLM Router 인스턴스 생성
# Router는 자동으로 로드밸런싱과 fallback을 처리
router = Router(model_list=model_list)
# 실제 모델 호출 수행
response = router.completion(
model=self.model_name, # 논리적 모델명 사용
messages=[{"role": "user", "content": prompt}],
max_tokens=8192, # 최대 토큰 수 설정
temperature=0.0, # 일관성을 위해 temperature 0으로 설정
)
# 응답에서 생성된 텍스트 추출하여 반환
return response.choices[0].message.content
@property
def _identifying_params(self):
"""LangChain에서 모델을 식별하기 위한 파라미터 반환"""
return {"model_name": self.model_name}
@property
def _llm_type(self):
"""LangChain에서 사용하는 LLM 타입 식별자"""
return "litellm"
async def _acall(self, prompt: str, stop: Optional[List[str]] = None, **kwargs) -> str:
"""
비동기 텍스트 생성을 위한 메서드
LangChain의 비동기 작업과의 호환성을 위해 구현
실제로는 동기 메서드를 executor를 통해 비동기적으로 실행
이는 LiteLLM Router의 비동기 지원이 제한적이기 때문
"""
loop = asyncio.get_event_loop()
# 동기 메서드를 별도 스레드에서 실행하여 비동기 호환성 확보
return await loop.run_in_executor(
None,
lambda: self._call(prompt, stop=stop, **kwargs)
)
이제 구현한 LiteLLM 래퍼 클래스를 사용하여 실제 모델을 초기화하고 연결을 테스트합니다.
# LiteLLM 기반 Bedrock 모델 인스턴스 생성
lite_llm = BedrockLiteLLM(model_name="anthropic.claude-3-7-sonnet-20250219-v1:0")
# DeepEval과의 호환성을 위해 이전에 정의한 BedrockLLM 래퍼로 한번 더 감싸기
# 이렇게 하면 DeepEval의 평가 시스템에서 LiteLLM을 사용할 수 있음
bedrock_llm = BedrockLLM(model=lite_llm)
# 모델 연결 및 동작 테스트
print(bedrock_llm.generate("모델 연결테스트"))
요약 성능 평가 실행
모델 설정이 완료되었으니 실제 요약 성능을 평가해보겠습니다. DeepEval의 내장된 SummarizationMetric을 사용하여 Coverage와 Alignment 평가를 수행할 수 있습니다.
# 평가용 테스트 케이스 생성
# 실제 사용 시에는 원본 텍스트와 LLM이 생성한 요약을 입력
test_case = LLMTestCase(
input="{원본 텍스트}", # 요약할 원본 텍스트
actual_output="{LLM이 생성한 요약}", # 모델이 생성한 요약문
retrieval_context=["참조 문서"] # 참조 문서 (선택사항)
)
# 요약 메트릭 인스턴스 생성
summarization_metric = SummarizationMetric(
threshold=0.7, #
verbose_mode=True, # 상세한 평가 과정 출력
n=20, # Coverage 평가에 사용할 질문의 개수
model=bedrock_llm, # 평가에 사용할 모델 (우리가 만든 Bedrock LLM)
truths_extraction_limit=20 # Alignment 평가에 사용할 질문 추출 개수
)
# 평가 실행
eval_result = evaluate([test_case], [summarization_metric])
# 결과 확인
print("평가 결과:", eval_result)
1. 정렬성(Alignement) 평가
정렬성 평가의 목표는 생성된 요약이 환각(hallucination) 현상 없이 원본 콘텐츠로부터 정확한 정보만을 추출했는지를 검증하는 것입니다.
평가 과정은 두 단계로 진행됩니다. 먼저 LLM이 생성된 요약 텍스트를 분석하여 각 문장을 독립적으로 검증 가능한 개별 진술(claim)들로 분해합니다. 이는 복합적인 정보가 담긴 긴 문장을 보다 세밀하게 검증하기 위함입니다. 다음으로, 분해된 각각의 진술에 대해 LLM이 원본 소스 자료와의 일치성을 비교 검증합니다. 이 과정에서 각 진술이 원본에 실제로 존재하는 정보인지, 아니면 모델이 임의로 생성한 잘못된 정보인지를 판단합니다.
다음 예시들은 실제 요약에서 생성된 문장들이 어떻게 개별 진술로 분해되고, 각각에 대해 어떤 판정 결과가 나오는지를 보여줍니다.
생성된 요약
이 영상은 LG 스탠바이미 제품의 기본 사용 방법을 안내하는 내용입니다. 스탠바이미는 무빙 휠로 자유롭게 이동할 수 있고, 화면 높이와 방향, 각도를 자유롭게 조절할 수 있는 특징이 있습니다. 제품 뒷면에는 전원과 볼륨 조절 버튼, NFC 태그, HDMI 및 USB 포트가 있으며, 내장 배터리로 무선 사용이 가능하고 어댑터로 충전할 수 있습니다. 리모컨 사용법, 모바일 거치대 활용법, 네트워크 및 블루투스 연결 방법 등 기본적인 사용 방법을 상세히 설명하고 있습니다. 특히 안드로이드폰을 거치하여 미러링하거나 블루투스 스피커처럼 음악을 재생할 수 있는 기능도 소개하고 있습니다.
LLM 평가 진술
Claims:
[
"이 영상은 LG 스탠바이미 제품의 기본 사용 방법을 안내하는 내용이다.",
"스탠바이미는 무빙 휠로 자유롭게 이동할 수 있다.",
"스탠바이미는 화면 높이와 방향, 각도를 자유롭게 조절할 수 있다.",
"제품 뒷면에는 전원과 볼륨 조절 버튼이 있다.",
"제품 뒷면에는 NFC 태그가 있다.",
"제품 뒷면에는 HDMI 및 USB 포트가 있다.",
"스탠바이미는 내장 배터리로 무선 사용이 가능하다.",
"스탠바이미는 어댑터로 충전할 수 있다.",
"영상에서는 리모컨 사용법을 설명하고 있다.",
"영상에서는 모바일 거치대 활용법을 설명하고 있다.",
"영상에서는 네트워크 및 블루투스 연결 방법을 설명하고 있다.",
"스탠바이미는 안드로이드폰을 거치하여 미러링할 수 있다.",
"스탠바이미는 블루투스 스피커처럼 음악을 재생할 수 있다."
]
정렬성(Alignment) 판정
Alignment Verdicts:
[
{
"verdict": "yes",
"reason": null
},
...
{
"verdict": "idk",
"reason": "The original text does not specifically mention a mobile stand or its usage instructions."
},
...
{
"verdict": "yes",
"reason": null
}
]
2. 포괄성(Coverage) 평가
포괄성 평가의 목표는 생성된 요약이 원본 콘텐츠의 핵심 정보들을 얼마나 빠짐없이 포괄적으로 다루고 있는지를 측정하는 것입니다.
평가 과정에서는 가상의 질문들을 생성하여 이를 통해 포괄성을 검증합니다. 구체적으로는 원본 텍스트를 기반으로 다양한 유형의 질문들을 만들어낸 후, 이 질문들에 대한 답변이 원본 텍스트와 생성된 요약 모두에서 찾을 수 있는지를 비교 분석합니다. 만약 원본에서는 답변을 찾을 수 있지만 요약에서는 찾을 수 없다면, 해당 정보가 요약 과정에서 누락되었다고 판단할 수 있습니다.
아래는 실제 평가에서 생성된 질문들과 이에 대한 답변 가능성 판정 예시입니다:
단순 포괄성 질문 예시:
Assessment Questions:
[
"Is the video about LG StandbyMe?",
"Does LG StandbyMe have a moving wheel for mobility?",
"Can you adjust the screen height and angle of LG StandbyMe?",
"Does LG StandbyMe have power and volume buttons on the bottom left of the back?",
"Does LG StandbyMe support NFC tagging with Android phones?",
"Can you connect devices like set-top boxes and game consoles to LG StandbyMe via HDMI?",
"Does LG StandbyMe have a built-in battery for wireless use?",
"Does the battery LED turn red when LG StandbyMe is charging?",
"Does the LG StandbyMe remote control use AA batteries?",
"Is there a home button on the LG StandbyMe remote control?",
"Can you mirror your Android phone screen on LG StandbyMe?",
"Can you control LG StandbyMe through touch?",
"Are there four attachment points on the back of LG StandbyMe?",
"Can LG StandbyMe connect to the internet via WiFi?",
"Can you use LG StandbyMe as a Bluetooth speaker for your Android phone?",
"Does LG StandbyMe have a USB port?",
"Can you adjust the screen orientation between landscape and portrait modes?",
"Does pressing the home button for a long time launch the most recently used app?",
"Can you store your Android phone on the back of LG StandbyMe when not in use?",
"Does LG StandbyMe automatically run MyView when connected to an Android phone via Bluetooth?"
]
Coverage 평가 결과 예시:
"Coverage Verdicts:
[
{
"summary_verdict": "yes",
"original_verdict": "yes",
"question": "Is the video about LG StandbyMe?"
},
....
{
"summary_verdict": "no",
"original_verdict": "yes",
"question": "Does LG StandbyMe have power and volume buttons on the bottom left of the back?"
},
{
"summary_verdict": "yes",
"original_verdict": "yes",
"question": "Does LG StandbyMe support NFC tagging with Android phones?"
},
{
"summary_verdict": "no",
"original_verdict": "yes",
"question": "Can you connect devices like set-top boxes and game consoles to LG StandbyMe via HDMI?"
},
...
{
"summary_verdict": "no",
"original_verdict": "yes",
"question": "Does LG StandbyMe automatically run MyView when connected to an Android phone via Bluetooth?"
}
]
3. 반복성(Repetitiveness)
다음은 사용자 정의 Metric을 생성하는 방법 중 DeepEval의 G-Eval 프레임워크를 기반으로 한 사용자 정의 메트릭 생성 기능 방식에 대한 예시를 보여줍니다. G-Eval은 LLM-as-a-judge 방식과 체인 오브 씽크(Chain-of-Thoughts, CoT) 접근법을 결합하여 사용자가 정의한 모든 평가 기준에 따라 LLM 출력을 평가할 수 있는 프레임워크입니다. G-Eval의 핵심은 자동화된 Chain-of-Thought 접근법을 통해 복잡한 평가 기준을 단계별로 분해하고, 3단계 프로세스를 통해 체계적으로 평가를 수행한다는 점입니다:
- 기준 분해(Criteria Decomposition): 평가 기준을 구체적이고 측정 가능한 하위 요소들로 세분화
- 단계적 분석(Step-by-step Analysis): CoT를 활용하여 각 평가 요소를 순차적으로 검토
- 종합적 판정(Final Scoring): 개별 분석 결과를 종합하여 최종 점수 산출
G-Eval에 대한 더 자세한 내용은 DeepEval 공식 가이드 에서 확인하실 수 있습니다.
다음은 반복성 평가를 위해 사용된 프롬프트와 G-Eval를 활용한 평가 예시 코드 입니다.
# 반복성 평가를 위한 프롬프트 정의
repet_eval_prompt="""
You are tasked with evaluating the information efficiency of a summary by identifying unnecessary repetitive content.
**Task**: Determine if the summary contains redundant information that diminishes its clarity and conciseness.
**Scoring Guidelines**:
- Score **1**: The summary is information-efficient with no unnecessary repetition
- Score **0**: The summary contains redundant content that could be consolidated
**Output Format**:
Score: [1 or 0]
Reasoning: [Provide specific examples of any identified repetition and explain why it is or isn't necessary for the summary's effectiveness. If scoring 1, explain what makes the summary efficiently structured.
"""
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCaseParams
# GEval 메트릭 인스턴스 생성
repetitiveness_metric = GEval(
name="Repetitiveness", # 메트릭 이름
criteria=repet_eval_prompt, # 평가 기준 프롬프트
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT], # 평가할 파라미터 (생성된 요약)
model=bedrock_llm, # 평가용 LLM 모델
verbose_mode=True # 세부 평가 과정 출력
)
# 평가 실행
eval_result = evaluate([test_case], [repetitiveness_metric]) #summarization_metric
이처럼 G-Eval은 사용자가 제공한 기본적인 평가 기준을 바탕으로 자동으로 세부 평가 방법론을 수립하고, 체계적인 분석을 통해 점수와 함께 평가 근거를 제공합니다.
Evaluation Steps:
[
"Step 1: Identify any instances where the same information is presented multiple times in different words or
phrases throughout the summary.",
"Step 2: Determine if repeated elements serve a necessary purpose (such as reinforcing a key point) or are
simply redundant and could be consolidated.",
"Step 3: Assess whether removing repetitive content would improve the summary's clarity and conciseness without
losing important information.",
"Step 4: Compare summaries to determine which contains less unnecessary repetition while maintaining complete
information coverage."
]
Rubric:
None
Score: 0.9
Reason: The summary shows minimal unnecessary repetition. It efficiently presents the LG StanbyME product features
without duplicating information. Each sentence covers distinct aspects: mobility features, rear panel components,
battery capabilities, remote control usage, mobile device stand functionality, and connectivity options. The only
minor repetition is in describing movement capabilities ('자유롭게 이동' and '자유롭게 조절') which uses similar
phrasing but refers to different features. Overall, the summary maintains excellent information density without
redundancy, presenting a comprehensive overview of the product's functionality in a concise manner.
4. 모호성(Vagueness)
이번에는 DeepEval에서 제공하는 BaseModel과 BaseMetric을 확장하여 커스텀 메트릭을 생성하는 부분에 대해 설명하겠습니다. 모호성(Vagueness)는 요약의 구체성과 정보 가치를 판단하는 사용자 정의 메트릭입니다. 일반적이고 추상적인 표현보다는 구체적이고 실용적인 정보 제공 여부를 측정합니다.
모호성 평가를 위해서는 문장 단위 판별이 필요하여 먼저 문장 단위로 분리한 후 각각의 문장을 평가하는 방식으로 진행하게 됩니다. DeepEval의 BaseMetric을 상속받아 구현하는 이 방식은 기존 G-Eval 프레임워크 보다 더 세밀한 제어와 복잡한 로직 구현이 가능합니다.
prompt = ChatPromptTemplate.from_template(
"""
## Task
You are given a list of sentences from a summary of a text.
For each sentence, your job is to evaluate if the sentence is vague, and hence does not help in summarizing the key points of the text.
Vague sentences are those that do not directly mention a main point.
Such a sentence does not mention the specific reasons, and is vague and uninformative.
### Examples of vague sentences:
- "이 영상은 LG 스탠바이미 제품의 기본 사용 방법을 안내하는 내용입니다." (This sentence only states what the video is about but provides no specific information about the product's features or usage methods)
- "기본적인 사용 방법을 상세히 설명하고 있습니다." (This sentence is meta-commentary about the content rather than providing actual usage information)
- "특히 ... 기능도 소개하고 있습니다." (This sentence talks about what is being introduced rather than directly stating the features)
### Examples of specific, non-vague sentences:
- "스탠바이미는 무빙 휠로 자유롭게 이동할 수 있고, 화면 높이와 방향, 각도를 자유롭게 조절할 수 있는 특징이 있습니다." (This sentence directly describes specific product features)
- "제품 뒷면에는 전원과 볼륨 조절 버튼, NFC 태그, HDMI 및 USB 포트가 있으며, 내장 배터리로 무선 사용이 가능하고 어댑터로 충전할 수 있습니다." (This sentence provides concrete details about the product's components and capabilities)
For each sentence, return a JSON object with the fields:
- `sentence_id`: the `sentence_id` of the sentence
- `is_vague`: a boolean indicating if the sentence is vague
- `reason`: if `is_vague` is true, a concise 1 sentence explanation for why the sentence is vague. If false, give a NIL reply.
Hence return a list of JSON objects.
SENTENCES:
{sentences}
OUTPUT:"""
)
class SentenceVagueness(BaseModel):
sentence_id: int
is_vague: bool
reason: str
class SentencesVagueness(BaseModel):
sentences: List[SentenceVagueness]
class VaguenessMetric(BaseMetric):
def __init__(
self,
threshold: float = 0.5,
verbose_mode: bool = True,
model: Optional[Union[ChatBedrock, DeepEvalBaseLLM]] = None,
# 하위 호환성을 위한 기본 파라미터들 (deprecated)
region: str = 'us-west-2',
model_id: str = "us.anthropic.claude-3-7-sonnet-20250219-v1:0"
):
"""
VaguenessMetric 초기화
Args:
threshold: 성공 임계값
verbose_mode: 상세 로그 모드
model: 외부에서 주입받은 모델 (ChatBedrock 또는 BedrockLLM 인스턴스)
region: 기본 리전 (model이 None일 때만 사용)
model_id: 기본 모델 ID (model이 None일 때만 사용)
"""
self.threshold = threshold
self.verbose_mode = verbose_mode
self.external_model = model
# 하위 호환성을 위한 기본 설정 (external_model이 없을 경우에만 사용)
if model is None:
print("Warning: 모델이 지정되지 않아 기본 설정을 사용합니다. 외부 모델 주입을 권장합니다.")
self.bedrock_client = boto3.client('bedrock-runtime', region_name=region)
self.default_model_id = model_id
def _get_llm_model(self) -> ChatBedrock:
"""
LLM 모델을 반환하는 메서드
외부 모델이 있으면 그것을 사용하고, 없으면 기본 모델을 생성
"""
if self.external_model:
# BedrockLLM 래퍼 클래스인 경우
if isinstance(self.external_model, DeepEvalBaseLLM):
return self.external_model.load_model()
# 직접 ChatBedrock 인스턴스인 경우
elif isinstance(self.external_model, ChatBedrock):
return self.external_model
else:
raise ValueError("지원되지 않는 모델 타입입니다. ChatBedrock 또는 BedrockLLM을 사용해주세요.")
else:
# 기본 모델 생성 (하위 호환성)
return ChatBedrock(
model_id=self.default_model_id,
client=self.bedrock_client,
model_kwargs={
"temperature": 0.0,
"max_tokens": 4096
}
)
def compute_sentences_vagueness(self, sentences: List[dict]):
"""문장들의 모호함을 계산하는 메서드"""
# 외부에서 주입된 모델 또는 기본 모델 사용
llm = self._get_llm_model()
chain = prompt | llm.with_structured_output(SentencesVagueness)
sentences = [
{'sentence_id': i, 'sentence': sentence} for i, sentence in enumerate(sentences)
]
vagueness_result = chain.invoke({'sentences': sentences})
vagueness_out = [e.dict() for e in vagueness_result.sentences]
sentences_df = pd.DataFrame(sentences)
df = pd.DataFrame(vagueness_out)
df = df.merge(sentences_df, on='sentence_id')
return df
def measure(self, test_case: LLMTestCase):
# Break the text up into sentences
sentences = split_sentences(test_case.actual_output)
df = self.compute_sentences_vagueness(sentences)
# Score is 1 - % of vague sentences
self.score = 1 - df['is_vague'].mean()
self.success = self.score >= self.threshold
self.verbose_logs = json.dumps(df.to_dict(orient='records'))
return self.score
async def a_measure(self, test_case: LLMTestCase):
return self.measure(test_case)
def is_successful(self):
return self.success
@property
def __name__(self):
return "Vagueness Score"
vagueness_metric = VaguenessMetric(threshold = 0.5, verbose_mode=True, model=bedrock_llm)
eval_result = evaluate([test_case], [vagueness_metric])
모델 성능 비교
프로젝트 진행 시점에 Claude Sonnet 3.7이 새롭게 출시되어, 기존에 사용하던 Claude Sonnet 3.5 v2와의 성능 비교 테스트를 진행하였습니다. 신규 모델의 성능 개선 효과를 직접 검증해보기 위해 동일한 평가 메트릭을 적용하여 두 모델 간의 요약 품질을 비교 분석하였습니다.
| Metric |
Claude Sonnet3.5 v2 |
Claude Sonnet3.7 |
| Coverage |
0.322 |
0.587 |
| Alignment |
0.987 |
9.991 |
| Vagueness |
0.767 |
0.693 |
| Repetiveness |
1 |
0.974 |
<표1. 요약 평가 메트릭에 대한 모델 성능 점수 비교>
새로 출시된 Claude Sonnet 3.7은 포괄성(Coverage) 과 정렬성(Alignment) 측면에서 기존 Claude Sonnet 3.5 v2 대비 현저한 성능 향상을 보여주었습니다. 특히 Coverage 점수에서 0.587로 Claude Sonnet 3.5 v2의 0.322 대비 약 82% 향상된 결과는 신규 모델의 텍스트 이해 및 핵심 내용 추출 능력이 크게 개선되었음을 의미합니다.
반면 Claude Sonnet 3.5 v2는 모호성(Vagueness) 과 반복성(Repetitiveness) 항목에서 다소 나은 성능을 보였으나, 이는 상대적으로 짧은 요약을 생성하는 경향과 관련이 있는 것으로 분석됩니다. 새로운 Claude Sonnet 3.7 모델이 더 포괄적이고 상세한 요약을 생성하면서 특히 시작 문장이나 마지막 문장의 요약 내용이 모호한 표현 증가에 영향을 끼친 것으로 보입니다.
이러한 비교 평가 결과를 바탕으로, 콘텐츠의 완전성과 정확성이 핵심 요구사항인 콘텐츠 분석 및 사용자 댓글 분석에 새로 출시된 Claude Sonnet 3.7이 최종적으로 선택되었습니다. 이후 프롬프트 개선 과정에서도 포괄성(Coverage)와 정렬성(Alignment)를 주요 기준으로 삼아 성능 향상 여부를 지속적으로 모니터링하며 최적화를 진행하였습니다.
키워드 추출 평가
키워드 추출에 대한 평가에서는 일관성과 품질 측면에서 포괄적인 개체 추출 평가가 수행되었습니다. 일관성 평가의 경우, 여러 모델 실행에 걸친 개체 추출의 신뢰성과 안정성을 평가했습니다. 테스트에서는 각 평가를 5회 실행했습니다. 평가는 프로덕션 환경에서 일관된 성능을 보장하기 위해 단순 분류 작업과 복잡한 개체 추출 시나리오를 모두 검토했습니다. 복잡한 평가의 경우, LLM-as-Judge 방식으로 품질 평가를 수행하였습니다.
1. 단순 다중 레이블 분류 사례
단순한 분류 작업의 경우(예: 비디오 유형, 제품군 분류 등) 동일한 키워드가 일관되게 분류되는지 확인하는 것이 비교적 직관적이었습니다. 이경우 다음과 같은 평가 방법이 적용 되었습니다.
점수 시스템:
- 각 분류 작업이 5회 독립적으로 실행됨
- 점수 1: 5회 실행 모두 동일한 결과 생성 (완벽한 일관성)
- 점수 0: 5회 실행에서 변동 발생 (일관성 없는 결과)
평가는 단순한 이진/다중 분류 접근법을 사용하여 네 가지 기본 분류 범주를 다루었습니다:
다음 표는 일관성 점수와 오류 사례의 예시를 보여줍니다. 평가 결과 영어 데이터셋이 여러 범주에서 한국어 데이터셋에 비해 우수한 일관성 성능을 보여주는 것으로 나타났습니다:

| Category |
Korean Data Set (35 EA)
Consistency Score
|
English Data Set (13 EA)
Consistency Score
|
| Content Type |
0.9714 |
1 |
| Product Category |
1 |
1 |
| Sentiment |
0.914 |
1 |
<표2 . 단순 데이터 클래스에 대한 일관성 점수>
2. 복잡한 개체(Entity) 추출 사례
복잡한 개체 추출 사례의 경우, 일관성 평가와 품질 평가 두 가지 별개의 평가 접근법이 구현되었습니다. 이러한 작업의 복잡성을 고려할 때, 단순한 이진 비교로는 불충분하여 두 평가 차원 모두에 대해 LLM-as-a-Judge 방법론의 사용이 필요했습니다.
일관성 평가 접근법
복잡한 개체 추출 출력은 단순 분류와 달리 직접적인 문자열 비교가 어려웠습니다. 동일한 개체가 다른 표현으로 추출되거나, 부분적으로 겹치는 개체들이 나타나는 경우가 빈번했기 때문입니다. 따라서 1-5점 척도 점수 시스템을 사용하여 5회 실행에 걸친 결과의 의미적 유사성을 평가하기 위해 LLM-as-a-Judge 접근법이 적용되었습니다.
추출된 관심 기능 예시:
Extraction 1:
- – 휴대성: 배터리로 작동하여 3시간 무선 사용 가능, 이동 가능한 스탠드 디자인
- – 터치스크린: 엣지 제스처 모드와 멀티터치 모드를 지원하는 터치 인터페이스
- – 디스플레이 모드: 시계, 날씨 예보, 개인 사진 등을 표시할 수 있는 장식용 모드
- – 스마트폰 연결: 블루투스를 통한 스마트폰 연결 및 스마트폰 클램프 기능
- – 회전 및 조절: 높이 조절 및 회전 가능한 디스플레이
Extraction 2:
- – 배터리 작동: 3시간 무선 작동 가능한 배터리 기능에 관심
- – 터치스크린: 엣지 제스처 모드와 멀티터치 모드를 지원하는 터치 기능
- – 이동성: 스탠드에 장착된 이동 가능한 디스플레이 개념
- – 스마트폰 연결: 블루투스를 통한 스마트폰 연결 기능
- – 스크린 모드: 시계, 날씨 예보, 개인 사진 등을 표시할 수 있는 다양한 디스플레이 모드
Extraction 3:
- – 배터리 작동: 3시간의 무선 작동 시간과 교체 가능한 배터리에 관심
- – 터치스크린: 엣지 제스처 모드와 멀티터치 모드를 포함한 터치 제어 기능
- – 이동성: 스탠드에 장착된 이동 가능한 디스플레이 컨셉
- – 스마트폰 연결: 블루투스를 통한 스마트폰 연결 및 스마트폰 클램프 기능
- – 디스플레이 모드: 시계, 날씨 예보, 개인 사진 등을 표시할 수 있는 다양한 모드
Extraction 4:
- – 배터리 작동: 무선으로 3시간 사용 가능한 배터리 기능에 관심
- – 터치스크린: Edge 제스처 모드와 멀티터치 모드를 포함한 터치 제어 기능
- – 이동성: 스탠드에 장착된 이동식 디스플레이로 다양한 장소에서 사용 가능
- – 디스플레이 모드: 시계, 날씨 예보, 개인 사진 등을 표시할 수 있는 다양한 모드
- – 블루투스 연결: 스마트폰과 블루투스로 연결하여 콘텐츠 재생 가능
Extraction 5:
- – 터치스크린: 엣지 제스처 모드와 멀티터치 모드를 지원하는 터치스크린 기능
- – 배터리 수명: 3시간의 무선 사용 시간 제공
- – 회전/조절 기능: 높이 조절 및 회전이 가능한 스탠드
- – 스마트폰 클램프: TV에 스마트폰을 부착할 수 있는 자석식 클램프 기능
- – 디스플레이 모드: 시계, 날씨 예보, 개인 사진 등을 표시할 수 있는 다양한 디스플레이 모드
일관성 평가 프롬프트:
You are an expert in named entity recognition. Evaluate the extracted entities below based on the given text.
Below is a list of extracted entities from multiple runs of the same input.
Evaluate the consistency of the outputs. On a scale from 1 to 5:- A higher score (closer to 5) means all extracted entity outputs are identical.- A lower score (closer to 1) means there are significant differences in extracted keys or values.- The result should be within in a single number which is the score.- Return the score within <output></output>
Extracted Entity Outputs:
{formatted_entities}
Provide a single consistency score (1-5).
품질 평가 접근법
일관성과 별도로, 추출된 개체의 정확성과 완전성을 평가하기 위한 품질 평가도 수행되었습니다. 이는 모델이 일관되게 결과를 생성하더라도 그 결과가 실제로 의미 있고 정확한 개체를 포함하는지 확인하기 위함입니다. LLM 판정자는 추출된 개체가 원본 텍스트의 맥락에서 얼마나 적절하고 유용한지를 종합적으로 평가했습니다.
품질 평가 프롬프트:
You are an expert in named entity recognition. Evaluate the extracted entities below based on the given text.
**Important Note**: The extracted entities are provided in Korean as per our system requirements, even when the original text may be in English or other languages. When evaluating contextual plausibility, consider the semantic meaning and context rather than direct language matching.
Given the text and the extracted entities, evaluate the entities with the text.
Rate the extraction on:
1. Contextual plausibility (1-5): Do these entities fit the passage’s meaning? Can the extracted entity be inferred with high confidence? Higher score for more fit to context. Note that Korean translations of entities should be considered equivalent to their original language counterparts.
2. Hallucination check (1-5): Did the extraction introduce entities not present? Higher score for lesser hallucination. Consider semantic equivalence across languages.
3. Redundancy check (1-5): If there are duplicate or excessive extractions then the score will be lower.
4. Structure: If the structure of the extracted entities is correct as in JSON or YAML, only check structure.
Provide the aggregated score from 1-5 to 1 decimal place.
– Return the score within
Text:
{context}
Extracted Entities for {entity_type}:
{extracted_entities}
평가 결과
복잡한 개체 추출에 대한 일관성과 품질 평가 결과는 다음과 같습니다. 품질 평가에서는 추출된 개체가 원본 텍스트의 맥락에 얼마나 적절하게 부합하는지, 실제 존재하지 않는 정보를 생성하는 환각 현상은 없는지, 그리고 중복되거나 과도한 추출이 발생하지 않았는지를 종합적으로 평가했습니다. 특히 입력 텍스트가 영어나 다른 언어로 되어 있더라도 시스템 요구사항에 따라 한국어로 개체를 추출하도록 설정되어 있어, 평가 시 언어적 차이보다는 의미적 동등성을 기준으로 판단했습니다. 평가 결과, 모든 추출 항목에서 품질 점수가 일관성 점수보다 현저히 높게 나타났습니다. 이는 모델이 정확하고 맥락에 적합한 개체를 추출하는 능력은 우수하지만, 매번 동일한 방식으로 추출하는 일관성 측면에서는 개선의 여지가 있음을 시사합니다.
| 추출 항목 |
Korean DataSet (35 EA)
일관성 점수
|
Korean DataSet (35 EA)
품질 점수
|
English DataSet (13 EA)
일관성 점수
|
English DataSet (13 EA)
품질 점수
|
| Keyword |
3.17 |
4.82 |
3.15 |
4.92 |
| Negative Details |
3.78 |
4.80 |
4.18 |
4.89 |
| Positive Details |
3.62 |
4.89 |
3.69 |
4.86 |
| Feature of Interest |
3.34 |
4.83 |
3.23 |
4.89 |
<표3. 복잡한 범주 개체 일관성 및 품질 평가 점수>
실시간 Q&A 평가
실시간 Q&A 시스템은 사용자가 특정 동영상에 대해 질문할 때 관련된 시간 구간(timestamp)을 찾아 정확한 답변을 제공하는 기능입니다.
실시간 Q&A 성능을 평가하기 위해 체계적인 접근 방식을 구현했습니다. 먼저 주어진 시간 구간 (timestamp) 와 자막(transcript) 데이터를 활용하여 LLM이 질문을 자동으로 생성하도록 했습니다.
# LG전자 동영상 QA 검증 AI Agent
당신은 LG전자 제품 관련 소셜 동영상의 질문-답변 정확성을 검증하는 AI Agent입니다.
## 역할 및 목적
주어진 동영상 정보를 바탕으로 사용자 질문에 대한 답변이 정확한지, 그리고 제공된 시간대 정보가 올바른지 검증합니다.
## 입력 정보 구조
### 동영상 정보
- **`<title>`**: 동영상 제목
- **`<description>`**: 동영상 설명 및 채널 정보
- **`<transcript>`**: 타임스탬프가 포함된 동영상 전체 대본
### 검증 대상
- **`<query>`**: 사용자가 제기한 질문
- **`<answer>`**: 해당 질문에 대한 답변 및 관련 시간대 정보
## 검증 기준
다음 조건을 **모두** 만족할 경우에만 "예"로 판정:
1. **내용 정확성**: 답변이 동영상 내용(transcript)에 근거하여 사실적으로 정확함
2. **시간대 정확성**: 제공된 타임스탬프가 해당 내용이 실제로 언급되는 시점과 일치함
3. **관련성**: 답변이 질문과 직접적으로 연관되어 있음
위 조건 중 하나라도 만족하지 않을 경우 "아니오"로 판정합니다.
## 출력 형식
```
<output>
[예/아니오]
</output>
<reasoning>
[상세한 판단 근거]
- 내용 정확성: [transcript 기반 검증 결과]
- 시간대 정확성: [타임스탬프 검증 결과]
- 기타 고려사항: [추가 검토 내용]
</reasoning>
```
## 주의사항
- 추측이나 가정에 기반한 판단을 하지 마세요
- transcript에서 명확히 확인할 수 있는 내용만을 근거로 사용하세요
- 시간대 정보는 정확한 일치를 요구하며, 근사치는 허용하지 않습니다
- 애매한 경우에는 "아니오"로 보수적으로 판정하세요
품질 평가
실시간 Q&A 시스템의 성능을 검증하기 위해 Nova Pro와 Claude Sonnet 3.7 모델을 대상으로 비교 평가를 수행했습니다. 평가는 시간 범위 반환 정확도와 응답 답변 정확도 두 가지 기준으로 진행되었습니다.
평가 기준:
- 시간 범위 반환 정확도: 사용자가 특정 동영상 세그먼트에 대해 질문할 때 타임스탬프 참조의 정확성
- 응답 답변 정확도: 사용자 쿼리에 대한 사실적 응답의 정확성과 완전성
모델별 품질 결과
105개의 테스트 쿼리를 대상으로 한 평가에서 Nova Pro는 89.5%의 성공률을 기록했습니다. 실패 사례는 주로 잘못되거나 누락된 타임스탬프 정보로 인한 10건과 불완전한 응답으로 인한 1건이었습니다.
Sonnet 3.7은 94.3%의 성공률로 약간 더 우수한 결과를 보였습니다. 실패 사례는 타임스탬프 부정확성 관련 4건, 불완전한 정보 제공 1건, 응답 구조 문제 1건으로 분석되었습니다.
두 모델 간 품질 차이는 5% 미만으로 실용적 관점에서 허용 가능한 수준이었습니다. 주목할 점은 Nova Pro의 실패 사례가 주로 타임스탬프 정밀도와 관련된 경미한 문제인 반면, Claude Sonnet 3.7은 콘텐츠 정확성과 응답 구조의 보다 근본적인 문제를 포함했다는 것입니다.
| 모델 |
정확도 |
주요 오류 내용 |
| Nova Pro |
89.50% |
- 시간 참조 문제: 잘못되거나 누락된 타임스탬프 정보로 인한 10개 실패
- 콘텐츠 누락: 불완전한 응답 범위로 인한 1개 실패
|
| Sonnet 3.7 |
94.3% |
- 시간 참조 오류: 타임스탬프 부정확성과 관련된 4개 실패
- 콘텐츠 품질 문제: 불완전한 LG 스타일러 정보와 관련된 1개 실패
- 형식 문제: 응답 구조 문제로 인한 1개 실패
|
<표4. NovaPro 와 Claude Sonnet 동영상 Q&A Test 결과 비교>
성능 및 비용 효율성
응답 속도 측면에서 Nova Pro는 Claude Sonnet 3.7 대비 압도적인 성능 우위를 보였습니다. Nova Pro의 응답 시간은 1.15-10.06초 범위로, Claude Sonnet 3.7의 4.97-40.18초 대비 최대 75% 단축된 결과를 나타냈습니다. 특히 대용량 입력 토큰 처리 시 이러한 성능 격차가 더욱 두드러지게 나타났습니다.
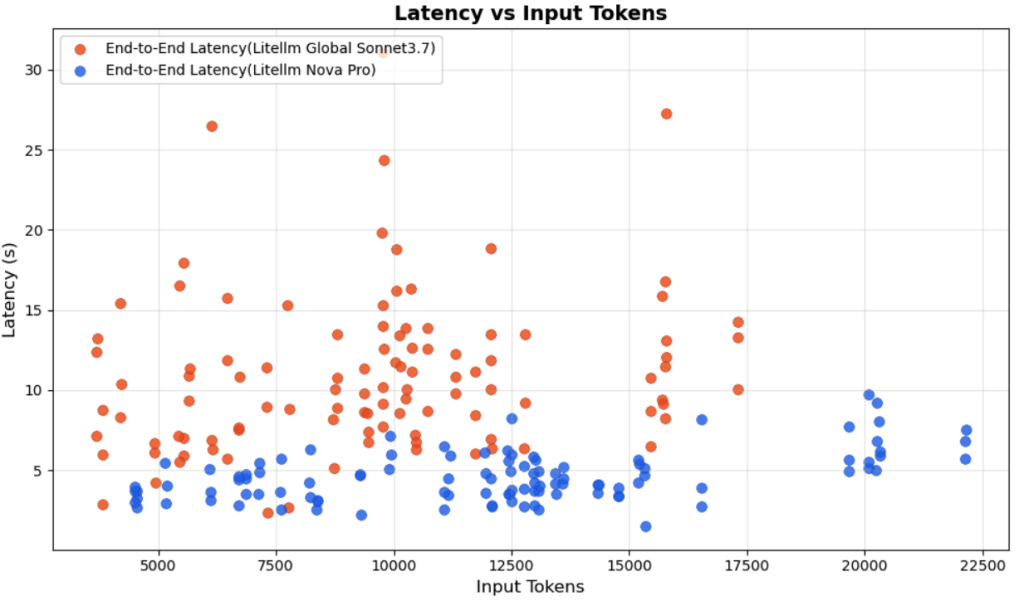
<그림1. 입력 토큰 크기별 Claude Sonnet 3.7과 Nova Pro 지연 시간 (Latency) 비교>
비용 효율성 면에서도 Nova Pro가 현저한 우위를 보였습니다. 전체 테스트 기간 동안 Nova Pro는 Claude Sonnet 3.7 대비 63% 비용 절약을 달성했습니다.
| Model |
Input tokens |
Output tokens |
Input token cost |
Output token cost |
Total Cost |
| Sonnet 3.7 |
1,005,789 |
40,178 |
3.02 |
0.60 |
3.62 |
| NovaPro |
1,289,726 |
26,404 |
1.23 |
0.10 |
1.33 |
| Ratio (Nova Pro / Sonnet 3.7) |
1.28 |
0.66 |
0.41 |
0.17 |
0.37 |
<표 5. Claude Sonnet 3.7과 Nova Pro 총 비용 비교>
이러한 종합적인 분석 결과, 실시간 애플리케이션의 핵심 요구사항인 빠른 응답 시간과 비용 효율성을 모두 만족하는 Nova Pro를 최종 모델로 선택했습니다. 특히 사용자 경험 향상을 위해 응답 속도가 중요한 요소로 작용하는 환경에서 Nova Pro의 성능 우위는 결정적인 선택 기준이 되었습니다.
결론
이번 프로젝트를 통해 기존에 사람이 수동으로 수행하던 소셜미디어 모니터링 작업을 생성형 AI로 자동화함으로써 상당한 업무 효율성을 달성할 수 있었습니다. 수작업으로 진행되던 비디오 분석과 댓글 분석이 자동화되면서 분석 시간이 대폭 단축되었고, 사람의 주관적 판단에 의존했던 감정 분석과 트렌드 파악이 객관적이고 일관된 기준으로 수행될 수 있게 되었습니다.
본 블로그에서는 다음과 같은 주요 경험과 인사이트를 공유했습니다:
- 단계적 데이터 처리 파이프라인 설계: AWS 서비스를 활용한 자동화된 분석 워크플로우 구축과 단계별 결과 연계 방법론
- 효과적인 프롬프트 설계 전략: 복잡한 작업을 단계별로 분리하는 접근법과 다국어 환경에서의 단일 프롬프트 활용 방법
- 체계적인 LLM 평가 방법론: DeepEval 프레임워크를 활용한 정량적 성능 측정과 커스텀 메트릭 개발
- 모델 선택 기준: Claude Sonnet 3.7과 Nova Pro 간의 성능 및 비용 효율성 비교 분석
- 실무적 구현 고려사항: 대용량 데이터 처리를 위한 병렬 처리와 맥락 통합 기법
생성형 AI 기술은 전통적인 텍스트 분석의 한계를 뛰어넘어, 기업이 고객의 목소리를 더 깊이 이해하고 데이터 기반 의사결정을 내릴 수 있는 유용한 도구임을 확인했습니다.
현재 LG전자는 이 시스템의 성공을 바탕으로 더 많은 제품군으로 모니터링 범위를 확대하는 동시에 인스타그램과 같은 다른 소셜미디어 플랫폼까지 분석 영역을 넓혀가고 있습니다. 이러한 지속적인 확장을 통해 더욱 포괄적이고 정교한 소셜미디어 인사이트를 확보해 나갈 예정입니다.