AWS 기술 블로그
당근의 AWS 기반 피처 플랫폼 구축 여정, Part 2: 피처 수집
해당 포스트는 당근의 김현호님, 서진형님, 권민재님과 함께 작성했으며, 이전에 AWS 글로벌 블로그에 포스팅한 영문 블로그와 동일한 내용입니다.
이 시리즈의 1부에서는 당근이 개발한 새로운 피처 플랫폼에 대해 다루었습니다. 이 플랫폼은 피처 서빙, 스트림 수집 파이프라인, 배치 수집 파이프라인의 세 가지 주요 구성 요소로 이루어져 있습니다. 또한 요구사항, 솔루션 아키텍처, 다단계 캐시를 활용한 피처 서빙에 대해 설명했습니다. 이번 글에서는 스트림 및 배치 수집 파이프라인과, 다양한 이벤트 소스로부터 데이터를 온라인 스토어로 수집하는 방법을 공유합니다.
솔루션 개요
다음 다이어그램은 1부에서 소개한 솔루션 아키텍처를 보여줍니다. 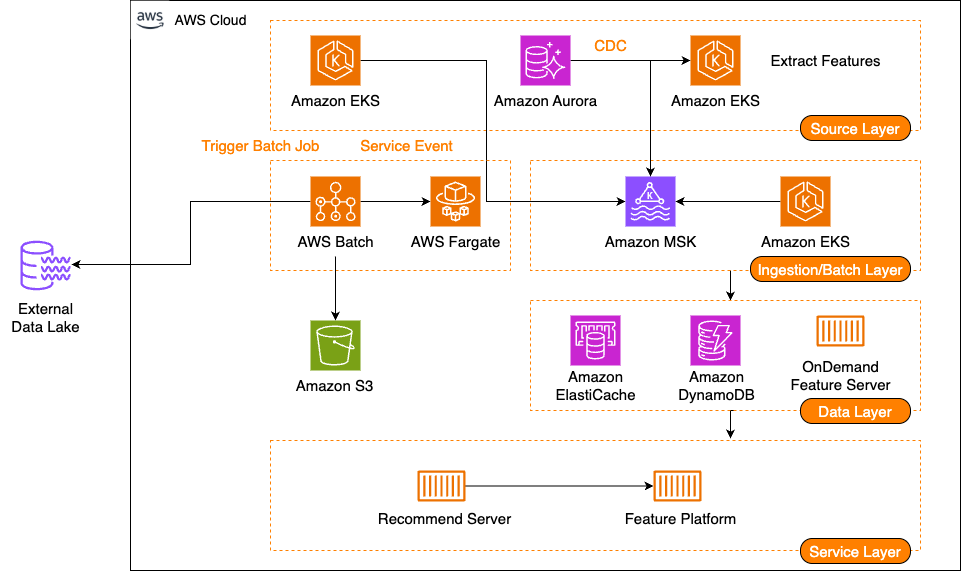
스트림 수집
스트림 수집 (Stream Ingestion)은 다양한 이벤트 소스로부터 실시간으로 데이터를 수집하여 피처로 가공하고 저장하는 과정입니다. 크게 Message Broker, Consumer 로 구성됩니다:
- Message broker – Amazon Managed Streaming for Apache Kafka (Amazon MSK) 를 사용 중이며, 당근의 다양한 서비스에서 발행한 이벤트 및 Amazon Aurora 의 change data capture (CDC) 이벤트를 적재합니다.
- Consumer – Amazon Elastic Kubernetes Service (Amazon EKS) 상에 위치한 Pod 들이며, 피처 플랫폼에 명시된 피처 그룹 명세에 따라 이벤트를 가공 후 Database 및 Remote Cache 에 적재합니다.
Consumer 는 앞서 언급한 소스 이벤트 뿐만 아니라 재발행된 이벤트 또한 다룹니다. 피처를 적재할 때도 다양한 전략을 고려하여 수행하고 있는데, 카디널리티, 데이터 사이즈 및 액세스 패턴을 고려해 Write-through / Write-around 등 세분화하여 적재합니다.
대부분의 피처는 주로 두 가지 유형의 이벤트를 기반으로 생성됩니다: 사용자의 실시간 행동으로 발생하는 이벤트와 사용자/게시글 데이터의 상태 변화로 발생하는 비동기 이벤트입니다. 이러한 이벤트와 피처는 M:N 관계를 가집니다. 즉, 하나의 이벤트가 여러 피처의 소스가 될 수 있고, 하나의 피처가 여러 이벤트를 기반으로 생성될 수 있습니다.
다음 다이어그램은 스트림 수집 파이프라인의 아키텍처를 보여줍니다.

M:N 관계를 효율적으로 처리하기 위해, 이벤트를 수신하여 여러 피처 가공 로직으로 전달하는 구조가 필요했습니다. 이를 위해 두 개의 핵심 컴포넌트를 설계했습니다:
- Dispatcher – 여러 Consumer Group으로부터 이벤트를 받아 관련된 피처 가공 로직으로 전파
- Aggregator – Dispatcher로부터 전달받은 이벤트를 실제 피처로 가공
이렇게 구성된 스트림 처리 파이프라인을 통해 실시간으로 피처를 생성하고 저장합니다.
메시지 브로커 최적화: fast at-least-once 보장
피처 플랫폼은 사용자 행동 로그 이벤트를 포함한 대량의 이벤트를 고속으로 처리하고 있습니다. 하지만 워커 트래픽 급증 시 순간적인 이벤트 처리 실패나 인프라 장애로 이벤트 유실이 간혹 발생했습니다. 이를 해결하기 위해 기존의 auto-commit 모드를 manual-commit으로 변경했습니다. 이를 통해 이벤트가 확실히 처리된 경우에만 커밋하고, 실패한 이벤트는 별도의 retry 토픽으로 보내 전용 워커를 통해 후처리하도록 구성했습니다.
하지만 대량의 이벤트를 manual-commit으로 동기 처리하다보니 처리 속도가 약 10배 가량 감소하고 지연이 발생하는 문제가 생겼습니다. Consumer Group의 자원은 여유가 있었지만, 팀별로 파티셔닝 권한이 분리되어 있어 단순히 파티션을 늘리는 것은 해결책이 될 수 없었습니다. 이에 당근은 단일 파티션 내에서의 병렬 처리를 구상했고, retry 기능과 함께 이를 지원하는 자체 consumer를 구현했습니다.
구현의 핵심은 파티션에서 메시지를 한 번에 fetch size만큼 읽어와 각 메시지별로 워커 스레드를 병렬로 생성(spawn)하여 처리하는 것입니다. 처리가 완료되면 성공한 메시지들의 offset을 정렬해 가장 큰 offset에 대해 manual commit을 수행하고, 실패한 메시지는 retry 토픽으로 재발행합니다. 이를 통해 단일 파티션에서도 병렬 처리가 가능해졌고, 병렬 처리 수준(concurrency)도 자체적으로 제어할 수 있게 되었습니다. 결과적으로 이벤트 처리 속도는 기존 auto-commit 방식보다 더 빨라졌으며, 늘어나는 이벤트 양에도 지연 없이 안정적으로 처리하고 있습니다.
스트림 처리
위에서 언급한 스트림 수집은 간단한 extract, transform, and load (ETL) 로직과 Validation만 수행합니다. 그렇다면 피처플랫폼에 복잡한 스트림 처리에 대한 요구사항은 없었을까요? 당근에는 이미 많은 요구사항이 있었고, 이를 수용하여 만든 별도의 서비스가 존재합니다. 다만 이런 요구사항을 피처플랫폼이 해결하지 않았는데, 그 이유는 다음과 같습니다:
- 피처플랫폼의 스트림 수집 목적은 실시간으로 피처를 수집하고 저장하는 것인 반면, 스트림 처리는 데이터의 가공이 주 목적입니다.
- 모든 피처들이 복잡한 가공을 필요로 하지는 않습니다. 일부 피처를 위해 전체 스트림 수집 과정을 복잡하게 만드는 것은 적절하지 않다고 판단했습니다.
- 스트림 처리의 결과 데이터는 피처플랫폼이 아닌 다른 곳에서도 사용할 수 있고, 이를 고려해달라는 요구사항들이 존재했습니다. 그렇기 때문에 별도로 만드는 것이 당근의 상황에 더 적합했습니다.
- 또한, 원본 데이터가 AWS가 아닌 다른 클라우드에 존재하는 케이스가 있어, 피처플랫폼에서 모든 것을 다루면 추가 비용이 상당히 발생할 수 있었습니다.
피처플랫폼과는 별개의 서비스라 자세히 다루지 않지만, 피처플랫폼이 스트림 처리를 통해 어떤 데이터를 어떻게 사용하는지 간략하게 소개하겠습니다:
- 다양한 컨텐츠 임베딩 사례 – 모델을 활용한 스트림 처리를 하고 있고, 다양한 컨텐츠 (게시글, 이미지 등)를 미리 학습된 모델에 입력 값으로 사용하여 임베딩을 만들고 있습니다. 임베딩은 피처플랫폼에 적재하고, 추천 시에 피처로 사용하여 더 좋은 추천을 하는데 사용하고 있습니다.
- 풍부한 피처 생성 사례 – 당근에서 가공되는 데이터들 중 일부를 LLM을 사용해 추가로 가공하여 피처로 사용하고 있습니다. 특정 중고거래 제품이 어떤 카테고리에 속하는지를 예측하고, 이 예측 값을 피처로 사용하고 있는 것이 그 중 하나입니다.
배치 수집
배치 수집은 대규모의 데이터를 일괄적으로 피처로 가공하여 저장하는 역할을 담당합니다. 이는 주기적으로 실행되는 크론잡 (Cron Job)과 대규모의 데이터를 일회성으로 적재하는 적재 (backfill) 작업으로 구분됩니다.
이를 위한 컴퓨팅 리소스로 AWS Fargate 기반의 AWS Batch 를 사용하고 있습니다. AWS Fargate로 실행되는 AWS Batch Job 은 서비스 운영 환경과 독립적으로 프로비저닝되어 안전한 대규모 작업 처리가 가능합니다. 예를 들어, 대규모 데이터 Backfill을 위해 위해 서버 1,000대 이상 혹은 vCPU 를 10,000개 이상을 사용하더라도 서비스 운영 환경과 분리되어 운영되며 사용량 기반 과금 방식으로 효율적인 운영이 가능합니다.
새로운 피처 추가 시 과거 데이터의 일괄 적재나 대규모 데이터의 주기적 적재는 피처 플랫폼의 핵심 기능 중 하나입니다. 설계 고려한 주요 요구사항은 아래와 같습니다:
- 대규모 데이터에 대해서 처리할 수 있어야 합니다.
- 사용자가 원하는 시간에 시작되어 적절한 시간 내에 작업을 마무리할 수 있어야합니다.
- 운영 비용이 적어야합니다. 가급적 Managed Service 여야하고, 운영을 위한 부가적인 작업이나 특정 도메인 지식이 적으면 더 좋습니다. 또한, 기존 서비스 코드를 최대한 재사용하는 방식이어야합니다.
- 피처를 위한 복잡한 연산이나 Directed Acyclic Graph (DAG)의 구성이 반드시 필요하지는 않습니다.
Apache Airflow 등 여러가지 선택지가 있었으나, 현재 요구사항에 맞춰 운영 비용을 고려하여 오버 엔지니어링을 피하고자 AWS Batch를 선택했습니다. 배치 수집 환경은 Scheduler 와 Job 이 실행되는 AWS Batch 의 작업 큐 및 컴퓨팅 환경으로 구성됩니다.
다음 다이어그램은 배치 수집 파이프라인의 아키텍처를 보여줍니다.

주요 구성 요소는 다음과 같습니다:
- Scheduler – 피처 플랫폼에 사용자가 작성한 명세 (FeatureGroupSpec, IngestionSpec)에 따라 Batch 작업을 수행해야 할 대상을 추출하고, 해당 작업 명세를 AWS Batch Job 에 등록 (Submit Job) 합니다.
- AWS Batch – Scheduler 가 Submit 한 Job 들을 사전에 구성한 작업 큐 및 컴퓨팅 환경으로 수행합니다. AWS Batch 의 경우 프로덕션 서비스가 운영 중인 환경과 별도로 Fargate 환경을 구성하여, 대규모의 리소스를 프로비저닝하여 작업을 수행하더라도 프로덕션 서비스에 영향 없이 안정적으로 작업을 수행할 수 있습니다.
배치 수집을 위한 향후 개선 사항
현재 구성은 안정적으로 잘 동작하지만, 몇 가지 개선할 사항들이 존재합니다:
- DAG 미지원 – 초기 피처 플랫폼은 배치 데이터 소스를 파싱하고 피처 스키마에 맞게 변환 후 저장하는 비교적 단순한 작업들을 수행했습니다. 하지만 플랫폼이 고도화됨에 따라 더욱 복잡한 연산이 필요하게 되었고, 이에 따라 의존성 있는 다양한 Job들을 순차적으로 수행하여 피처를 가공할 수 있는 DAG 구성 지원이 필요해졌습니다.
- 병렬 처리 시 Manual 하게 구성: 현재는 대규모 데이터 병렬 처리 시 작업자가 수동으로 병렬 처리할 Job의 수를 추정하여 명세에 제공해야 하며, Scheduler는 이를 기반으로 단순히 병렬적으로 Submit Job을 수행하고 있습니다. 이는 순전히 경험에 기반한 방식으로, 시스템이 고도화되기 위해서는 적절한 병렬 처리의 수준을 시스템이 자동으로 추상화하여 최적화할 수 있어야 합니다.
- 제한된 AWS Batch 모니터링 사용성: AWS Batch Job이 Runnable에서 Running으로 전환되지 않는 상황이 발생하거나, 이러한 경우에 대한 적절한 알림 시스템이 부재한 점이 아쉬움으로 남습니다. 또한 Job이 실패하여 알림을 받을 때, 해당 Job을 URL 파라미터로 제공하여 브라우저에서 바로 확인할 수 없는 점 등 운영 편의성 측면에서 개선이 필요해보였습니다.
결과
피처 플랫폼 개발 초기에 제시했던 주요 문제들에 대한 성과를 살펴보겠습니다(2025년 2월 기준):
- 추천 로직의 중고거래 서버 의존성 탈피 – 당근의 추천 시스템은 10개 이상의 다양한 추천 지면 및 서비스에서 피처 플랫폼을 활용하고 있습니다.
- 추천 로직에 사용되는 피처의 확장성 확보 – 중고거래, 광고, 알바, 부동산 등 다양한 서비스에서 확보한 1,000개 이상의 고품질의 풍부한 피처를 통해 추천 로직의 고도화에 기여하고 있고, 사내 누구나 쉽게 피처를 탐색하고 추가할 수 있도록 하였습니다.
- 피처 데이터 소스의 신뢰도 확보 – 피처 플랫폼을 통해 일관된 스키마와 수집 파이프라인을 사용하여 신뢰도 있는 데이터를 제공하고 있습니다.
당근 엔지니어들은 피처 플랫폼을 통해 고품질의 피처를 통해 추천을 고도화함으로써 사용자 경험을 지속적으로 향상시키고 있습니다. 이를 통해 사용자가 관심을 가질만한 게시글을 추천함으로써 기존 대비 클릭률 30%, 전환율 70%를 증가시키는 데 기여했습니다.
이렇게 할 수 있었던 것은 피처플랫폼에서 사용하고 있는 AWS 서비스들이 든든히 받쳐주고 있던 덕분에 가능했습니다. Amazon DynamoDB는 읽기,쓰기,스토리지 모든 측면에서 놀라울만큼의 확장성을 갖고 있어서 다이나믹하게 변하는 워크로드를 별도의 운영 비용을 들이지 않고도 해낼 수 있었습니다. Amazon ElastiCache는 매우 신뢰도 높은 운영을 보여주어서 믿고 쓸 수 있었습니다. 또한 스케일 업, 스케일 인-아웃등도 간편하고, 안정적으로 할 수 있어 운영 부담을 줄일 수 있었습니다. 또한 ElastiCache Redis OSS의 생태계와 매끄럽게 연동되어 Redis Exporter와 같은 오픈소스 생태계를 사용할 수 있어서 좋았습니다. Amazon MSK 또한 신뢰도 높은 운영, Kafka 생태계와의 매끄러운 연동 등을 지원하고 있어서 피처플랫폼의 개발과 운영을 손쉽게 해주었습니다.
또한, AWS와 함께라면 AWS의 다양한 지원과 노하우를 바탕으로 비용효율적인 운영을 할 수 있습니다.최근 ElastiCache Redis OSS 클러스터의 오버프로비저닝 문제가 있었고, Solution Architect분들을 비롯하여 다양한 전문가분들의 조언을 바탕으로 최적의 ElastiCache Redis 클러스터를 구성하였습니다. 이를 통해 40%에 가까운 ElastiCache Redis 비용을 줄일 수 있었습니다.
AWS의 이러한 인적 지원은 AWS의 제품들을 사용하여 피쳐플랫폼을 운영하는데 큰 도움이 되었습니다.
Conclusion
이 시리즈에서는 당근이 AWS에서 피처 플랫폼을 어떻게 구축했는지 살펴보았습니다. AWS 서비스들과 저희 경험을 더해 각 회사의 요구사항에 맞게 변형하여 개발하고 운영하면 피처스토어를 손쉽게 개발하고 운영할 수 있을 것이라 생각합니다.