AWS 기술 블로그
당근의 AWS 기반 피처 플랫폼 구축 여정, Part 1: 구축 배경과 피처 서빙
해당 포스트는 당근의 김현호님, 서진형님, 권민재님과 함께 작성했으며, AWS 글로벌 블로그에 포스팅한 영문 블로그와 동일한 내용입니다.

당근은 대한민국을 대표하는 지역생활 커뮤니티로서, 동네에서 가능한 모든 연결에 중심을 둔 서비스입니다. 단순한 중고 거래를 넘어 이웃, 지역 가게, 공공 기관 간의 연결을 강화하고, 따뜻하고 활발한 동네를 만드는 것을 핵심 가치로 삼고 있습니다.
당근은 추천 시스템을 활용해 사용자에게 관심사와 동네에 맞는 연결을 제공하며 개인화된 경험을 선사합니다. 특히, 당근 앱의 홈 화면에서는 사용자 맞춤형 컨텐츠들을 확인할 수 있습니다. 특별한 관심 카테고리를 설정하지 않아도 사용자의 활동 패턴을 분석하여 개인화된 컨텐츠가 지속적으로 업데이트됩니다. 피드의 핵심은 새롭고 관심있는 컨텐츠를 제공하는 것이며, 당근은 이를 위해 사용자 만족도 향상에 끊임없이 노력을 기울이고 있습니다. 개인화된 추천 컨텐츠 제공을 위해 당근은 추천 시스템을 적극 활용하고 있습니다. 이 시스템에서 머신러닝 (Machine Learning, ML) 추천 모델과 함께 핵심적인 역할을 담당하는 것이 바로 피처 스토어 (Feature Store) 또는 피처 플랫폼 (Feature Platform) 입니다. 피처 플랫폼은 사용자의 행동 이력, 게시글 정보 등 ML 추천 모델에 필요한 데이터를 저장하고 서빙하는 데이터 스토어의 역할을 수행합니다.
이 블로그는 2 부작으로 구성되며, 1부에서는 당근의 피처플랫폼의 세 가지 주요 구성요소 (피처 서빙, 스트림 수집 파이프라인, 배치 수집 파이프라인)와 요구사항, 솔루션 아키텍처, 다단계 캐시를 활용한 피처 서빙에 대해 설명합니다. 2 부에서는 실시간 피처 수집 및 온라인 스토어에 대한 배치 수집 프로세스와 안정적 운영을 위한 기술적 접근법을 다룹니다.
피처 플랫폼 개발 배경
당근이 피처 플랫폼의 필요성을 느낀 것은 2021년 초반, 앱에 추천 시스템을 도입하고 약 2년 정도 지난 시점이었습니다. 당시 당근은 추천 시스템을 적극적으로 활용하면서 여러 지표에서 큰 성장을 이루고 있었습니다. 최신순 피드를 넘어 각 사용자에게 맞춤화된 피드를 보여주게 되면서 기존 대비 클릭률이 30% 이상 증가하고, 사용자 만족도 또한 높아지는 것을 볼 수 있었습니다. 이렇게 추천 시스템이 만들어내는 임팩트가 점점 커지게 되며 ML팀 내부에서는 자연스럽게 추천 시스템 고도화라는 과제를 마주하게 되었습니다.
ML 기반 시스템에서 다양한 고품질의 입력 데이터(클릭, 전환 액션 등)는 중요한 요소로 꼽힙니다. 이런 입력 데이터를 보통 “피처 (Feature)”라고 부르는데, 당근에서는 사용자의 행동 로그, 액션 로그, 상태 값을 포함한 데이터를 통칭하여 사용자 피처라고 하며, 게시글과 관련된 로그들은 게시글 피처라고 부릅니다.
사용자 맞춤형 추천의 정확도를 높이기 위해서는 다양한 종류의 피처가 필요합니다. 이러한 피처들을 효율적으로 관리하고, ML 추천 모델에 빠르게 전달할 수 있는 시스템이 필수적입니다. 여기서 ‘서빙’이란, 추천 시스템이 사용자에게 맞춤형 컨텐츠를 제안할 때 필요한 데이터를 실시간으로 제공하는 과정을 의미합니다. 그러나 당시 운영 중이던 추천 시스템의 피처 관리 방식에는 여러 한계점이 존재했으며, 주요 문제점은 다음과 같았습니다:
- 추천 로직의 중고거래 서버 의존성: 초기 추천 시스템은 중고거래 서버 내부 라이브러리 형태로 존재했기 때문에, 추천 로직을 수정하거나 피처를 추가할 때마다 웹앱의 소스 코드를 변경해야 했습니다. 이로 인해 배포의 유연성이 떨어지고 리소스 최적화가 어려웠습니다.
- 추천 로직과 피처의 확장성 부족: 초기 추천 시스템은 중고거래 DB에 직접 의존하며 중고거래 게시글만을 고려하고 있었습니다. 이로 인해 서로 다른 데이터 소스로 관리되고 있는 동네생활, 동네알바, 광고와 같은 새로운 게시글 타입으로의 확장이 불가능했습니다. 또한, 피처 정의 및 피처 가공과 같은 피처 관련 코드들이 하드코딩되어 있어 피처의 탐색, 추가, 변경 작업이 어려웠습니다.
- 피처 데이터 소스의 신뢰성 부족: Amazon Simple Storage Service (Amazon S3), Amazon ElastiCache, Amazon Aurora등 다양한 저장소에서 피처를 조회했지만, 일관된 스키마와 수집 파이프라인이 없어 데이터 품질의 신뢰성이 낮았습니다. 이는 피처의 최신성, 정합성 확보에 큰 제약이 되었습니다.
다음 다이어그램은 초기 추천 시스템 백엔드 구조를 보여줍니다.

위의 문제들을 해결하기 위해, 피처의 추가와 관리, 실시간 수집 및 서빙을 중앙에서 효율적으로 지원할 수 있는 새로운 시스템이 필요하다고 판단했고, 따라서 피처 플랫폼 프로젝트를 시작하게 되었습니다.
피처 플랫폼 요구 사항
피처 플랫폼을 독립 서비스로 분리하며 정리한 기능적 요구사항은 다음과 같습니다:
- 사용자가 최근 수행한 상위 N개의 액션을 기록하고 빠르게 서빙할 수 있어야 한다. 단, 상위 N 값과 조회 기간을 파라미터로 지정할 수 있어야 한다.
- 액션 피처 뿐만 아니라 유저가 등록한 알림 키워드와 같은 사용자 특성 피처도 지원해야한다.
- 중고거래 게시글 뿐만 아니라 다양한 게시글 타입의 피처도 처리할 수 있어야한다.
- 모든 피처는 primitive type, list, set, map 등 임의의 데이터 타입을 가질 수 있어야 한다.
- 액션 피처와 사용자 특성 피처는 모두 실시간으로 업데이트 되어야 한다.
- 피처의 목록, 개수, 조회 기간은 요청마다 달라질 수 있어야 한다.
정리한 기능적 요구사항을 반영하기 위해 새로운 플랫폼이 필요했습니다. 이 플랫폼은 세 가지 핵심 기능을 갖추어야 했습니다: 다양한 타입의 피처를 실시간으로 수집하고, 이를 일관된 스키마로 저장하며, 다양한 형태의 쿼리 요청에 빠르게 응답하는 것입니다. 이러한 요구사항은 처음에는 추상적으로 느껴졌지만, 일반화된 구조로 설계함으로써 데이터 수집 파이프라인, 저장 방식, 서빙 스키마를 효율적으로 구성할 수 있었고, 이는 오히려 더 명확한 개발 목표 설정으로 이어졌습니다.
기능적 요구사항 외에도 다음과 같은 기술적 요구사항이 있었습니다:
- 서빙 트래픽: 1,500 이상 RPS (Requests per second)
- 수집 트래픽: 400 이상 WPS (Writes per second)
- top N 값: 30-50
- 단일 피처의 값 크기: 최대 8KB
- 총 피처 개수: 30억 이상
당시에는 사용 중인 피처의 종류와 개수가 적었고, 추천 모델도 단순했기 때문에 기술적 요구 수준이 높지 않았습니다. 하지만 당근의 빠른 성장 속도를 고려했을 때, 향후 시스템 요구 수준이 큰 폭으로 상승할 것이 예상되었습니다. 이러한 예측을 바탕으로 초기 요구사항보다 더 높은 수준의 목표를 설정했습니다.
그 결과, 2025년 2월을 기준으로 서빙과 수집 트래픽은 초기 요구사항 대비 약 90배, 총 피처 개수는 수백 배 이상 증가했습니다. 이러한 급격한 성장에 대응할 수 있었던 것은 앞으로 소개할 피처 플랫폼의 확장성 높은 아키텍처 덕분이었습니다.
솔루션 개요
다음 다이어그램은 피처 플랫폼의 아키텍처를 보여줍니다.
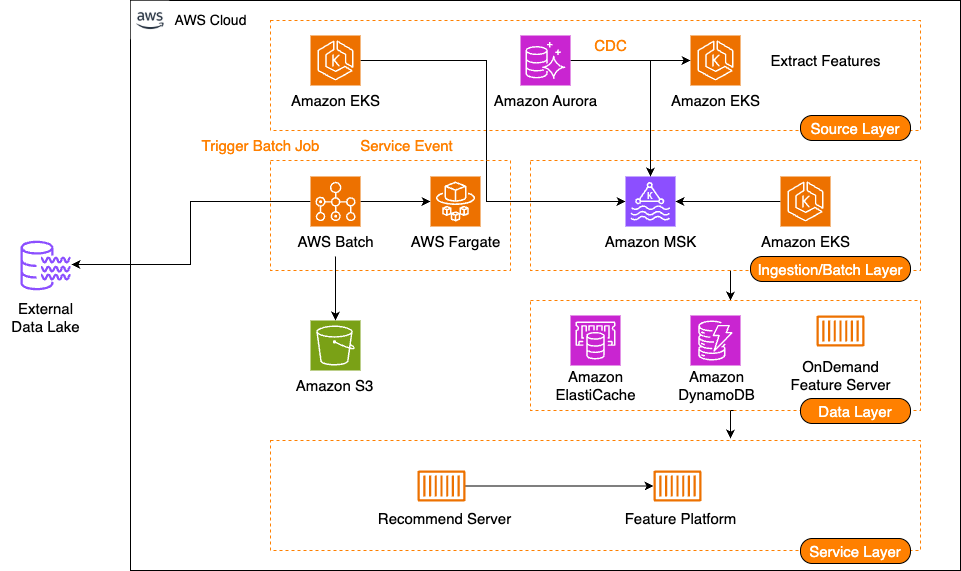
피처 플랫폼은 피처 서빙, 스트림 수집 파이프라인, 배치 수집 파이프라인 이라는 세 가지 큰 축으로 구성됩니다.
이 시리즈의 1부에서는 피처 서빙을 다룰 예정입니다. 피처 서빙은 클라이언트의 요청을 받아 필요한 피처들을 제공하는 핵심 기능을 담당하는데 당근은 이 시스템을 Server, Remote Cache, Database, On-demand Feature Server의 네 가지 주요 구성요소로 설계했습니다:
- Server: 피처 서빙 요청을 받아 처리하는 서버이며, Amazon Elastic Kubernetes Service (Amazon EKS) 상에 위치한 Pod입니다.
- Remote Cache: Server 들이 공유하는 Remote Cache Layer이며, Amazon ElastiCache 를 사용합니다.
- Database: 피처를 저장하는 Persistence Layer 이며, Amazon DynamoDB를 사용합니다.
- On-demand Feature Server: Compliance 이슈 등으로 Remote Cache 및 Database 에 저장할 수 없거나, 매번 실시간으로 계산이 필요한 Feature 를 서빙하는 서버입니다.
데이터스토어 관점에서 피처 서빙은 높은 카디널리티 (Cardinality) 의 피처를 모든 스케일에서 낮은 레이턴시로 서빙해야 합니다. 당근은 Multi-level cache 를 도입하였고, 피처의 특성에 따라 서빙 전략을 세분화했습니다:
- Local cache (tier 1 cache) – Server 내에 위치한 in-memory store 이며, 데이터 크기가 작으면서 자주 조회되거나 빠른 응답 시간이 요구되는 경우에 적합합니다.
- Remote cache (tier 2 cache) – 데이터 크기가 중간 정도이며 자주 조회되는 경우에 적합합니다.
- Database (tier 3 cache) – 데이터 크기가 크고 자주 조회되지 않거나 응답 시간에 덜 민감한 경우에 적합합니다.
스키마 디자인
피처 플랫폼은 컬럼 패밀리 (Column Family)에 대응하는 피처그룹이라는 개념으로 여러 피처들을 묶어서 같이 저장하고 있습니다. 모든 피처그룹은 피처그룹 스펙이라는 피처그룹의 스키마를 통해서 정의되고, 각 피처그룹 스펙은 피처그룹의 이름, 필요한 피처 등을 정의하고 있습니다.
이런 컨셉을 바탕으로 키 디자인을 다음과 같이 정의하고 있습니다.:
- Partition key:
<피처그룹이름>#<피처그룹의 id> - Sort key:
<피처그룹의 타임스탬프>또는 null을 의미하는 string
사용자가 최근 클릭한 중고거래 게시글’이라는 피처그룹의 예시를 통해 실제로 어떻게 사용하고 있는지 보여 드리겠습니다. 이해를 쉽게하기 위해 다음과 같은 상황을 가정하겠습니다.:
- 피처그룹의 이름:
recent_user_clicked_fleaMarketArticles - 유저 아이디:
1234 - 클릭 시점 타임스탬프:
987654321 - 피처그룹에 존재하는 피처:
- 클릭한 게시글 아이디:
a - 유저 세션 아이디:
1111
- 클릭한 게시글 아이디:
위 예제 상황에서 키와 피처그룹은 아래와 같이 생성됩니다:
- Partition key:
recent_user_clicked_fleaMarketArticles#1234 - Sort Key:
987654321 - Value:
{"0": "a", "1": "1111"}
피처그룹 스펙에 정의된 피처들은 고정된 순서를 가지고 있어 순서를 enum처럼 사용하여 피처그룹 저장 시 활용하고 있습니다.
피처 서빙 읽기/쓰기 흐름
다음 다이어그램과 같이 피처 플랫폼은 피처 제공을 위해 다단계 캐시와 데이터베이스를 사용합니다.

피처 플랫폼은 Multi-Level Cache와 데이터베이스 사용하여 피처를 서빙하고 있습니다. 이해를 돕기 위해 중고거래 게시글 피처그룹들 중 id가 1,2,3인 피처 그룹을 조회하는 경우를 예시로 서빙의 흐름을 설명하겠습니다.
읽기 요청의 흐름은 위 그림에서 실선에 해당합니다. 이 과정은 Multi-Level Cache 전략을 사용하여 데이터 접근 속도를 최적화하는 방식을 보여줍니다:
- 조회 요청이 들어오면 먼저 로컬 캐시를 확인합니다.
- 로컬 캐시에 없는 데이터는 ElastiCache에서 찾습니다.
- ElastiCache에도 없는 데이터는 최종적으로 DynamoDB에서 조회합니다.
- 각 단계에서 찾은 피처그룹들을 모아 최종 응답으로 반환합니다.
쓰기 요청의 흐름(위 다이어그램의 실선)은 다단계 캐시 전략을 활용한 데이터 접근 최적화를 보여줍니다:
- 캐시 미스가 발생한 피처그룹들을 각 캐시 레벨에 저장합니다.
- 로컬 캐시에서 찾지 못하고 리모트 캐시나 데이터베이스에서 찾은 데이터는 상위 캐시에 저장됩니다.
- ElastiCache에서 찾은 데이터는 로컬 캐시에 저장
- DynamoDB에서 찾은 데이터는 ElastiCache와 로컬 캐시 모두에 저장
- 모든 캐시 쓰기 작업은 백그라운드에서 비동기적으로 수행됩니다.
이 방식은 Multi-Level Cache 구조에서 데이터의 일관성을 유지하고 향후 접근 속도를 개선하는 전략을 보여줍니다.
이상적인 상황에선 위의 흐름만으로도 아무런 문제없이 서빙이 잘 동작합니다. 하지만 현실은 그렇지 않았습니다. 대표적으로 겪었던 문제는 캐시 미스, 정합성, 관통 문제였습니다:
- 캐시 미스 문제 – 빈번한 캐시 미스는 응답 속도를 느리게 하고, 다음 레벨의 캐시나 데이터베이스에 부담을 줍니다. 당근은 이 문제를 PEE(Probabilistic Early Expirations) 기법을 통해 미래에 다시 조회될 확률이 높은 데이터를 사전에 리프레시하여 낮은 레이턴시 유지 및 캐시 쇄도 (Cache Stampede)를 완화하고 있습니다. 또한, 락 (Lock)을 함께 사용해 DynamoDB의 핫 파티션 현상을 방지하고 있습니다.
- 캐시 정합성 문제 – 캐시의 TTL (Time-To-Live)을 잘못 설정하면 추천 품질에 영향을 미치거나 시스템 효율성이 저하될 수 있습니다. 당근은 Soft TTL과 Hard TTL을 분리해 설정하고, 때로는 Write Through 정책을 함께 사용해 캐시와 데이터베이스 동기화를 통해 정합성 문제 완화하기 위해 노력하고 있습니다. 또한, 비슷한 시점에 쓴 피처그룹들의 리프레시 스톰 현상(cache stampede)을 완화하기 위해 지터 (Jitter)를 추가해 TTL 삭제 시점을 분산시키고 있습니다.
- 캐시 관통 문제 – 생성되지 않은 피처그룹에 대한 지속적인 조회 요청으로 인해 DynamoDB까지 쿼리가 전달되고, 비용 및 응답 속도 증가가 발생 할 수 있습니다. 당근은 생성되지 않은 피처그룹 정보를 캐시에 저장하는 Negative Caching을 통해 불필요한 데이터베이스 조회를 줄여 캐시 관통 문제를 해결하고 있습니다. 또한, DynamoDB에 값이 없는 피처그룹의 비율 추적, Negative Cache 히트율 및 정합성 문제 발생 여부를 모니터링하고 있습니다.
피처 서빙의 향후 개선점
당근은 피처 서빙 솔루션에 대한 다음과 같은 향후 개선 사항을 고려 중입니다:
- 대용량 데이터 캐싱 – 최근엔 큰 데이터 크기의 피처 저장의 요구가 늘어나고 있습니다. 당근이 성장하면서 피처들도 더 늘어나고 있기 때문입니다. 또한 LLM의 급격한 성장과 함께 임베딩에 대한 요구가 늘어나면서 저장해야하는 데이터의 사이즈가 커졌습니다. 이에 따라 Embedded Database를 활용하여 보다 효율적인 서빙을 검토하고 있습니다.
- 효율적인 캐시 메모리 사용 – 초기에 효율적인 TTL값을 설정해도, 유저의 사용패턴이 변하고 모델이 변경되면 효율성이 떨어지기 마련입니다. 또한, 더 많은 피처그룹이 정의될수록 모니터링하는 것도 어려워집니다. 데이터를 기반으로 캐시의 TTL 최적값을 쉽게 찾을 수 있어야 합니다. 캐시 hit rate 및 피처그룹 유실 방지를 통해 추천의 품질은 높게 유지하면서 메모리를 효율적으로 사용할 수 있는 방법에 대해 고민하고 있습니다.
한 번만 조회할 피처그룹은 캐싱해야할까요? 두 번 조회할 피처그룹은 어떤가요? 현재 피처 플랫폼은 한번만 캐시 미스가 발생해도 캐싱을 시도합니다. 캐시 미스가 발생한 모든 피처그룹은 캐싱할 가치가 있다고 보는 것 입니다. 이는 자연스레 캐싱의 비효율을 높입니다. 다양한 데이터를 기반으로 캐싱할 가치가 있는 피처그룹들을 판별하여 캐싱하는 고도화된 정책이 필요합니다. 이를 통해 캐시 사용의 효율성을 높이려고 합니다. - Multi-level cache 최적화 – 현재도 피처플랫폼은 Multi-level cache 구조이고, 향후 Embedded Database를 추가하면 복잡도는 증가할 것 입니다. 따라서 서로 다른 레벨의 캐시들을 고려해 최적 설정 값을 찾고 세팅해야 합니다. 앞으로는 서로 다른 레벨들의 캐시 설정을 고려하여 효율을 극대화하는 것을 시도해보려고 합니다.
마무리
1부에서는 피처 서빙을 중심으로 하여 피처플랫폼을 어떻게 만들었는지 살펴보았습니다. 2025년 2월 기준, 100K RPS 이상의 대규모 요청을 P99 기준 30ms 이하로 안정적으로 처리하며, 트래픽 증가 시에도 손쉽게 확장 가능한 구조를 통해 안정적인 추천 서비스를 제공하고 있습니다.
2부에서는 피처플랫폼을 통해 일관된 피처들의 스키마와 수집 파이프라인을 사용하여 어떻게 피처들을 생성하는지 살펴보겠습니다.