AWS 기술 블로그
AWS Glue ETL을 활용한 CRM 데이터의 효율적인 병렬처리 전략
노티플라이는 CRM 마케팅 솔루션으로서, 100여 개 이상의 다양한 고객사들의 마케팅 캠페인을 집행하고 결과를 분석하는 기능을 제공하고 있습니다. 마케팅 성과를 보다 정확하고 빠르게 분석하기 위해 캠페인과 관련된 사용자 이벤트 데이터를 수집하고 집계하여 실시간에 가깝게 통계 데이터를 제공해야 합니다.
노티플라이는 다음과 같은 요구사항을 해결하기 위해 AWS 서비스들로 구성된 효율적인 ETL 파이프라인을 구축했습니다.
- 고객사별 캠페인 성과 데이터의 정기적인 집계 및 분석
- 각 고객사의 캠페인 성과 데이터에 대한 빠른 처리와 정확한 결과 제공
- 확장성과 비용 효율성을 고려한 자동화된 데이터 처리 시스템 구현
기존 방식의 한계와 문제점
ETL 파이프라인 구축 전에는 필요할 때마다 애플리케이션에서 직접 Amazon Aurora PostgreSQL(OLTP)과 Amazon Athena(OLAP)에 쿼리를 실행하는 방식으로 캠페인 성과를 분석해 왔습니다. 그러나 이러한 방식은 다음과 같은 한계를 가지고 있었습니다.
즉각적으로 확인할 수 없는 데이터
복잡한 계산 쿼리로 인해 Amazon Aurora PostgreSQL과 Amazon Athena에서의 실행 시간이 길어져 마케팅 캠페인의 성과를 즉각적으로 확인하기 어려웠습니다. 또한 긴 실행 시간 때문에 일부 대형 고객사들의 경우 타임아웃까지 발생했습니다. 결과적으로 고객들이 데이터를 기반으로 한 신속한 의사결정을 할 수 없었습니다.
비효율적인 비용 구조
동일한 쿼리를 반복 실행하면서 Amazon Athena 사용 비용이 증가했습니다. 또한 불필요한 중복 계산으로 OLAP 데이터베이스의 리소스 낭비 및 비용 효율성 저하가 발생했습니다.
일관적이지 못한 데이터
여러 사용자가 각기 다른 시점에 직접 쿼리를 실행하면서 동일한 캠페인에 대한 성과 지표가 서로 다르게 나타나는 문제가 발생했습니다.
예를 들어, 어떤 사용자는 이벤트 적재가 완료되기 전에 쿼리를 실행해 누락된 데이터를 보게 되고, 다른 사용자는 적재 완료 후에 쿼리를 실행해 더 많은 데이터를 보게 되었습니다. 이렇게 시점에 따라 결과가 달라지면, 하나의 캠페인 성과에 대한 해석이 사용자마다 달라지고 내부 보고나 의사결정에도 혼선을 초래하게 됩니다.
복잡도 낮고 효율적인 아키텍처를 위한 고민
기존 방식에서는 쿼리 성능 저하, 비용 비효율, 그리고 데이터 일관성 문제로 인해 많은 어려움이 있었습니다. 이러한 문제를 해결하기 위해서는 단순히 계산 속도를 개선하는 것 이상의 접근이 필요했습니다. 지속 가능한 방식으로 데이터를 일관되게 처리하고, 비용 효율을 확보하면서도 운영 부담이 적은 구조를 갖춰야 했습니다.
초기 설계 단계에서 가장 중요하게 고려한 요소는 아키텍처의 복잡도를 낮추면서도 데이터 파이프라인의 확장성과 안정성을 확보하는 것이었습니다. 시장에는 다양한 데이터 처리 및 워크플로 관리 솔루션들이 존재하지만, 각각은 고유의 운영 복잡도와 러닝 커브를 동반합니다. 예를 들어, Apache Airflow는 강력한 워크플로 제어 기능을 제공하지만, 자체 클러스터 구성 및 운영, 사용자 정의 Operator 개발 등에서 높은 유지관리 비용이 수반됩니다. Spark 기반의 데이터 처리 또한 장점이 아주 많지만, 별도 클러스터 설정 및 스케줄링 도구 연동이 필요해 초기 진입장벽이 존재합니다.
이와 비교하여 AWS Glue는 서버리스로 제공되어 인프라 운영 부담을 최소화할 수 있고, 다른 AWS 서비스와 유기적으로 통합되어 있어 복잡한 구성 없이 데이터 파이프라인을 설계할 수 있다는 장점이 있습니다. 특히 Glue ETL의 경우, Spark 환경 기반의 ETL 작업을 복잡한 초기 셋업 없이 코드 몇 줄로 정의할 수 있는 것이 큰 장점입니다. 게다가 기존에 적극 활용하고 있는 AWS Lambda, Amazon Kinesis, Amazon Data Firehose, Amazon Athena를 함께 활용하면 데이터 등록부터 분석까지의 흐름을 AWS 내에서 자연스럽게 이어갈 수 있다고 판단했습니다.
마찬가지로 AWS Step Functions와 Amazon EventBridge 또한, 간단하게 워크플로를 관리하고 트리거할 수 있는 솔루션이라고 판단하고, Glue ETL과도 유기적으로 통합할 수 있기에 채택하게 되었습니다.
결과적으로, 이러한 비교 끝에 AWS 기반의 완전 관리형 서버리스 컴포넌트들을 조합하는 방식이 기존의 문제들을 해결하면서도 최소한의 관리 오버헤드로 최대한의 유연성과 확장성을 확보할 수 있는 현실적인 선택이라 판단했습니다.
효율적인 새 아키텍처 미리보기
노티플라이는 CRM SaaS로서, 각 고객사의 데이터를 독립적으로 처리해야 하는 요구사항을 해결해야 합니다. 이 요구사항을 만족시키면서도 효율성을 극대화하는 Step Functions + Glue ETL + EventBridge 기반 아키텍처를 소개합니다.
- 사용자의 행동에 의해 발행되는 클라이언트 측 이벤트와 캠페인 발송 등으로 발행되는 서버 측 이벤트를 Amazon Kinesis Data Streams와 Amazon Data Firehose 통합으로 수집하고, 이 대규모 데이터를 S3에 저장합니다. 이때, Amazon Data Firehose의 동적 파티셔닝을 이용해 효율적인 쿼리를 위한 파티션을 구성합니다.
- Amazon EventBridge에 설정한 주기마다 Step Functions의 워크플로를 트리거합니다.
- 워크플로의 상태 머신이 스케줄링 Lambda 함수를 먼저 실행하여 이번 주기에서 계산할 캠페인들을 선정합니다.
- 각 프로젝트 별로 AWS Glue의 카탈로그를 통해 S3에 저장된 데이터를 Glue ETL 작업으로 읽어오고 가공된 결과 통계 데이터를 PostgreSQL에 적재합니다.
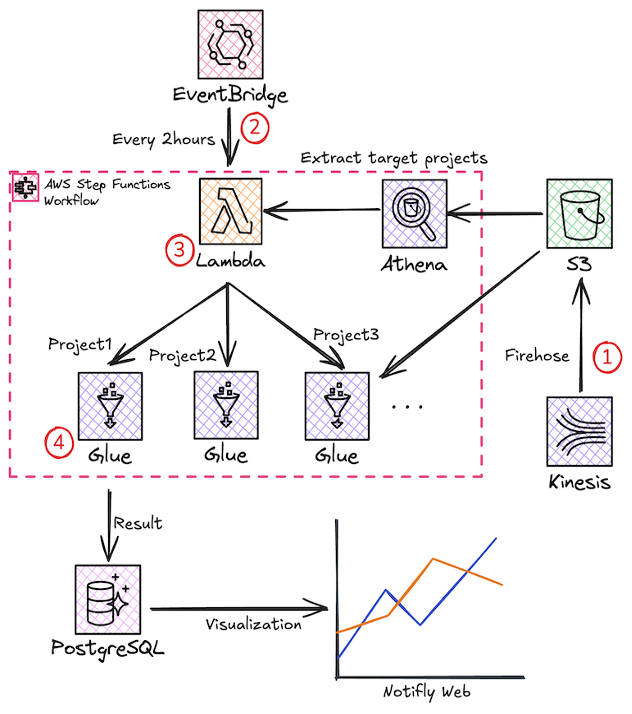
노티플라이 캠페인 성과 집계 워크플로 아키텍처
실용적인 동적 Glue ETL 작업 스케줄링
좀 더 자세히 아키텍처 안으로 들어가 보겠습니다. 노티플라이의 고객사는 약 100여 개에 달하고, 각 고객사는 수십~수백 개의 캠페인을 보유하고 있습니다. 그렇기 때문에 매 주기마다 모든 고객사들의 모든 캠페인들에 대해 ETL 작업을 실행하게 되는 것은 매우 비효율적입니다. 이를 해결하기 위해 Step Functions와 Lambda, Athena, Glue ETL를 연계하여 데이터 변경이 발생한 고객사에 한해서만 Glue ETL 작업을 실행하는 동적 일정 관리 구조를 구성하였습니다.
앞서 언급한 대로, 고객의 이벤트 데이터는 Amazon Kinesis 및 Firehose를 통해 수집되어 Amazon S3에 저장됩니다. 이때, 각 고객사(Project)의 데이터는 project_id, dt(날짜), h(시간) 단위로 파티셔닝되어 저장되며, 캠페인 관련 이벤트는 AWS Glue 카탈로그 내에 두 개의 테이블로 관리 됩니다.
- 메시지 발송 관련 이벤트 → 노티플라이 서버 측에서 발생 (서버 사이드 이벤트)
- 전환 이벤트 → 메시지 클릭, 구매 등 고객 행동 데이터 (클라이언트 사이드 이벤트)
새로운 아키텍처에서는 Step Functions가 트리거된 시점을 기준으로 이번 주기 동안 캠페인 관련 이벤트가 발생한 고객사만 추려서 Glue ETL 작업을 실행합니다. 즉, 전체 고객사에 대해 무조건 ETL 작업을 실행하는 것이 아니라, 아래와 같은 방식으로 집계 데이터가 변경된 고객사만 선별하여 Glue ETL 작업을 수행함으로써 비용과 리소스를 최적화 했습니다.
-
EventBridge를 활용하여 자동으로 Step Functions 스케줄링
EventBridge를 활용하여 2시간마다 Step Functions의 워크플로를 실행하도록 예약합니다. 사용이 거의 없는 새벽 시간(KST 기준)에는 워크플로가 실행되지 않도록 하여 비용을 절감합니다.
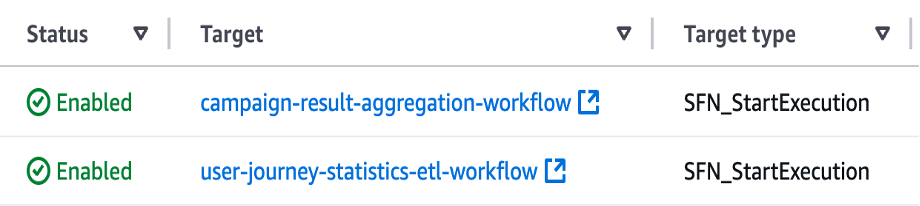
Step Functions의 워크플로를 실행하는 EventBridge
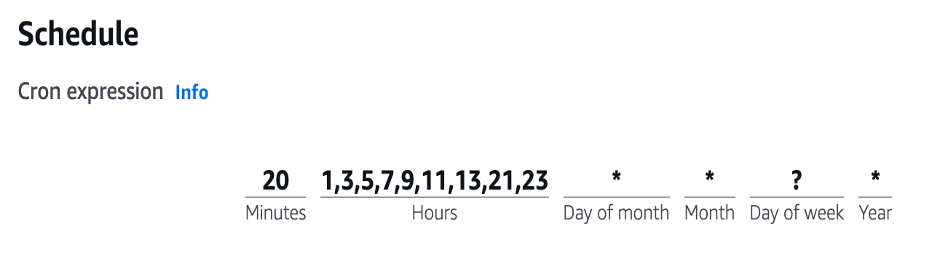
cron expression 으로 주기 설정
-
AWS Lambda 함수가 Athena를 사용해서 집계가 필요한
project_id목록을 추출Lambda 함수는 Athena를 사용하여 다음과 같은 쿼리를 실행하여, 최근 2시간(단, 아침 첫 스케줄은 8시간) 동안 이벤트가 발생한 프로젝트 목록만 추려냅니다.
SELECT DISTINCT project_id, campaign_id FROM notifly_events WHERE concat(dt, '-', h) BETWEEN '2025-01-01-00' AND '2025-01-01-02';- ‘
notifly_events’ 테이블에서 ‘project_id’와 ‘campaign_id’를 조회 - ‘
dt’(날짜)와 ‘h’(시간)를 결합하여 최근 2시간 동안 이벤트가 발생한 데이터만 필터링 - ‘
DISTINCT’를 사용하여 중복을 제거하고, Glue ETL 작업을 실행해야 할 프로젝트 목록을 추출
이렇게 선별된 프로젝트 리스트는 Step Functions 상태 머신의 컨텍스트에 저장되며, 이후 단계에서 Glue ETL 작업 실행을 위한 입력으로 활용됩니다.
- ‘
-
Step Functions가 선별된 고객사 별로 Glue 작업 실행
- 각
project_id별 Glue ETL 작업을 병렬 실행 - 고객사 별로 작업이 격리되어 작업 실패 시 타 고객사 데이터에 영향 없음
이 모든 단계가 Step Functions 워크플로를 구성하여 실행됩니다.
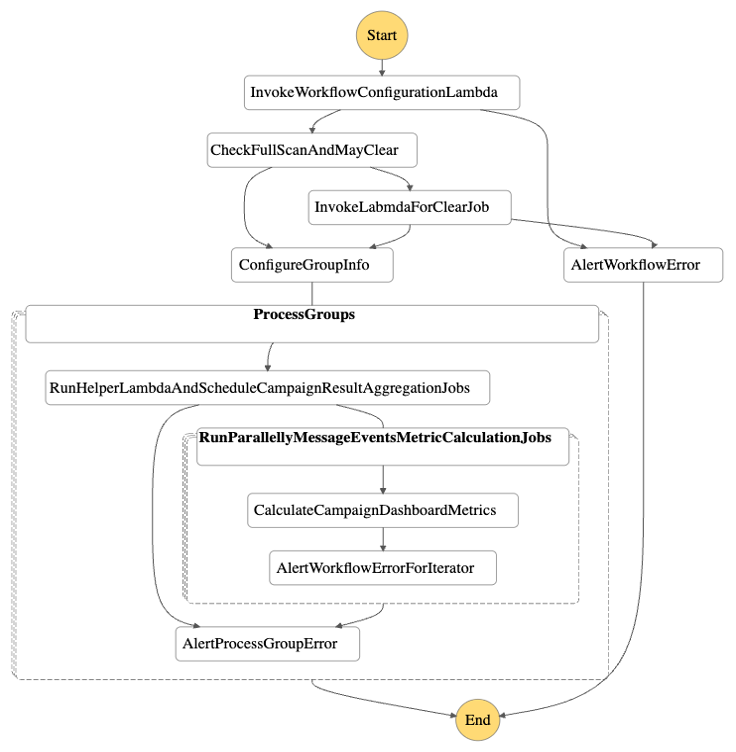
Step Functions 로 구성한 워크플로
이러한 구조는 과거 데이터의 재처리(Backfill) 또한 유연하게 수행할 수 있습니다.
- 고객사별 Glue ETL 작업이 독립적으로 실행되므로, 특정 고객사의 특정 시간 내 데이터를 선택적으로 재처리 가능
- 전체 고객사를 대상으로 특정 기간의 데이터만 재처리하는 것도 가능
- 각
Python으로 구현한 실전 Glue ETL: 설계부터 최적화까지
ETL 파이프라인을 구현하는 데 있어 언어나 프레임워크의 선택은 작업의 생산성과 운영 안정성에 큰 영향을 미칩니다. 노티플라이는 AWS Glue의 Spark 기반 런타임을 선택하고 개발 언어로는 Python을 사용했습니다. AWS Glue가 지원하는 Scala와 Python 중에서 Python을 선택한 가장 큰 이유는 개발 속도와 유지보수의 용이성, 그리고 데이터 엔지니어링 생태계에서의 친숙함이었습니다. Python은 pandas, PySpark, boto3 등 데이터 처리 및 AWS 연동에 적합한 도구들이 풍부하며, 팀 내 엔지니어들에게 이미 익숙한 언어이기도 했습니다.
Spark 런타임 선택의 배경에는 단순히 대용량 처리 능력만이 고려된 것은 아니었습니다. 노티플라이는 AWS Glue가 제공하는 Apache Spark 환경을 기반으로 빠르게 시작하면서도, 필요 시 Amazon EMR이나 자체 Spark 클러스터로 이전, 또는 병행 운용할 수 있는 확장성까지 고려했습니다. 즉, AWS Glue를 통해 초기에는 인프라 부담 없이 안정적인 ETL 작업을 운영하고, 추후 데이터 규모가 더 커지거나 맞춤형 튜닝이 필요한 경우에는 같은 코드 기반을 바탕으로 보다 유연한 Spark 환경으로 전환이 가능하도록 기술적 연속성을 확보한 것입니다.
PySpark를 통해 구현한 ETL 작업의 코드 구성은 다음과 같습니다.
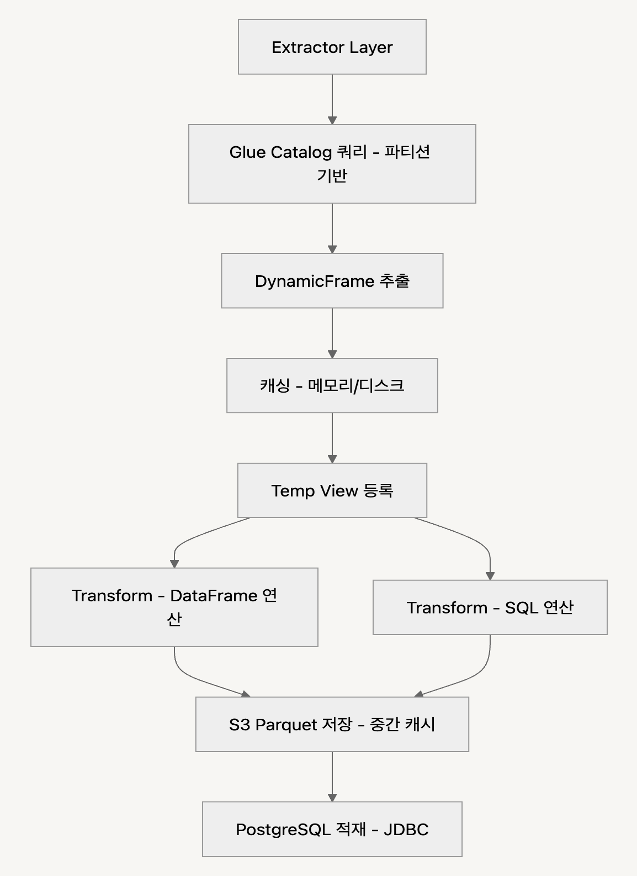
ETL 작업 코드 구조에서 가장 중점을 둔 부분은 Extract, Transform, Load 각 단계를 명확히 분리하여 구조화하는 것이었습니다. 이 계층적 구조는 코드 재사용성과 유지보수성을 높이는 데 큰 도움이 되었으며, 각 단계별로 책임이 분리되어 확장성도 자연스럽게 확보되었습니다.
Extract 단계에서는 AWS Glue 데이터 카탈로그에 등록된 이벤트 데이터 테이블에서 카탈로그 파티션 키 기반 쿼리를 수행하여 데이터를 읽어옵니다. 이 과정에서 데이터를 DynamicFrame으로 로드했는데, DynamicFrame은 스키마 추론, 오류 복구, 중첩 구조 처리 등의 면에서 PySpark DataFrame보다 유연하게 동작하므로, 반정형/불완전 데이터를 다루는 데 있어 매우 유리했습니다. 또한, push_down_predicate_conditions와 catalog_partition_predicates를 함께 활용하여 쿼리 단계에서부터 불필요한 데이터를 읽지 않도록 최적화했습니다. push_down_predicate_conditions 파라미터는 필터 조건을 데이터 소스 레벨에서 최대한 먼저 적용하도록 유도해주며, catalog_partition_predicates 파라미터는 AWS Glue가 데이터 카탈로그에 등록된 파티션 키를 기준으로 필요한 데이터만 추출할 수 있게 해줍니다. 이 두 옵션을 병행하면 전체 데이터셋을 로드한 후에 필터링하는 것이 아니라, 필요한 조건의 데이터만 읽어 오는 형태로 실행 플랜이 구성되기 때문에, I/O 비용은 물론 작업 시간도 크게 단축됩니다.
push_down_predicate_conditions=[
f"project_id = '{project_id}'",
QueryBuilder.build_time_condition_clause(start, end),
f"""campaign_id IN ('{"','".join(campaign_ids)}')""",
],
catalog_partition_predicates=[
f"project_id = '{project_id}'",
QueryBuilder.build_time_condition_for_catalog_partition_predicates(
start, end
),
],
데이터를 추출한 이후에는 메모리와 디스크에 캐시하고, Spark SQL 처리를 위해 Temp View로 등록합니다. 이렇게 하면 복잡한 변환을 SQL로 작성할 수 있어 가독성과 유지보수성이 높아지고, 여러 단계에서 동일 데이터를 반복해서 사용할 수 있습니다. 또한, 필요 없는 시점에는 .unpersist()를 통해 적절히 캐시를 해제하여 메모리 자원을 효율적으로 관리함으로써 작업 안정성과 성능을 모두 확보했습니다.
self.frame.persist(StorageLevel.DISK_ONLY)
if self.temp_view_name is not None:
self.frame.createOrReplaceTempView(self.temp_view_name)
self.clear_cache(frames)
def clear_cache(self, frames):
for frame in frames:
if frame is not None:
frame.unpersist()Transform 단계에서는 연산의 복잡도에 따라 처리 방식이 달라집니다. 단순한 정제나 필터링, 컬럼명 변경 등은 PySpark의 DataFrame API로 처리하고, 복잡한 집계, 조인, 윈도우 연산 등은 SQL 쿼리를 Temp View에 실행하는 방식으로 나누어 설계했습니다.
- 간단한 연산은 DataFrame의 메서드로 단순하게 수행
filtered_df = message_event_df.filter( (F.col("user_journey_id") == user_journey_id) & (F.col("user_journey_node_id") == user_journey_node_id) ).withColumns( { "pre_conversion_type": F.lit(None).cast("string"), "pre_conversion_event_id": F.lit(None).cast("string"), "collected_from": F.concat(F.col("dt"), F.lit("_"), F.col("h")).cast("string"), } ) - 복잡한 연산은 Temp View를 만들어 SQL로 수행
WITH ranked_device AS ( SELECT notifly_device_id__from_device, notifly_user_id__from_device, ROW_NUMBER() OVER (PARTITION BY notifly_user_id__from_device ORDER BY updated_at__from_device DESC) AS rn FROM {_DEVICE_VIEW_NAME} ) ,user_device_map AS ( SELECT notifly_device_id__from_device, notifly_user_id__from_device, FROM ranked_device WHERE rn = 1 ) ,conversion_events_with_device_id AS ( SELECT C.*, UMD.notifly_device_id__from_device FROM {CONVERSION_EVENT_VIEW_NAME} C LEFT JOIN user_device_map UDM ON C.notifly_user_id = UDM.notifly_user_id__from_device ) SELECT T.*, P.session_id, P.pre_conversion_type, P.id AS preconversion_event_id FROM conversion_events_with_device_id T INNER JOIN {PRE_CONVERSION_EVENT_VIEW_NAME} P ON T.user_journey_id = P.user_journey_id AND T.user_journey_node_id = P.user_journey_node_id AND T.notifly_user_id = P.notifly_user_id AND T.time_ms between P.time_ms AND P.time_ms + CAST( T.conversion_window_days AS INT ) * {notifly_constants.ONE_DAY_IN_MILLI_SECONDS}
각각의 중간 단계에서 생성된 결과는 필요시 S3에 Apache Parquet 형식으로 저장합니다. 이는 중복 제거를 위해 쓰이거나, 중간 캐시 혹은 외부에서 재사용 가능한 분석 데이터 저장소로 활용됩니다. Parquet는 열 지향 포맷이기 때문에 Amazon Athena나 AWS Glue와 함께 사용할 때 성능이 우수하고, 파일 크기도 작아 비용 효율도 높아 이점이 많습니다.
결론
노티플라이에서는 Step Functions 기반의 서버리스 Glue ETL 아키텍처를 도입하여 운영 효율성과 비용 절감을 극대화하면서도, 보다 안정적이고 유연한 데이터 파이프라인을 구축하였습니다.
이를 통해 다음과 같은 성과를 달성했습니다.
- 별도 인프라 없이 서버리스 환경에서 운영 및 유지보수 부담 감소
- DAG(Directed Acyclic Graph) 관리를 자동화하여 운영 리소스 절감
- 필요한 데이터만 선별하여 실행하는 최적화된 ETL 구조로 비용 절감
- 고객사별 데이터 처리 격리를 통해 안정성과 보안성 확보
- AWS 서비스 간 원활한 연동으로 확장성과 운영 효율성 향상
이를 바탕으로 월 20억 건 이상의 데이터를 효율적으로 집계/분석하는 준실시간 마케팅 성과 분석 환경을 구축했습니다. 노티플라이는 앞으로도 AWS와 함께 A/B 테스트 결과 집계, 사용자 행동 기반 세그먼트 추출 등 데이터 분석을 고도화하고, CRM 마케팅 캠페인의 자동화·최적화를 지속 확장할 계획입니다. 🚀