AWS 기술 블로그
Amazon Bedrock에서 프롬프트 캐싱 효과적으로 사용하기
이 글은 Effectively use prompt caching on Amazon Bedrock by Sharon Li, Kosta Belz, Satveer Khurpa, Sean Eichenberger, and Shreyas Subramanian 을 한국어 번역 및 편집하였습니다.
프롬프트 캐싱은 현재 Amazon Bedrock에서 Anthropic의 Claude 3.5 Haiku와 Claude 3.7 Sonnet, Claude 4 Sonnet과 Opus, 그리고 Nova Micro, Nova Lite, Nova Pro 모델 등과 함께 사용 가능하며, 자주 사용되는 프롬프트를 여러 API 호출에 걸쳐 캐싱함으로써 응답 지연 시간을 최대 85%까지 줄이고 비용을 최대 90%까지 절감할 수 있습니다. 지원 가능한 모델 정보는 이곳에서 확인하실 수 있습니다.
프롬프트 캐싱을 사용하면 캐싱할 프롬프트의 특정 연속 부분(프롬프트 접두사)을 표시할 수 있습니다. 지정된 프롬프트 접두사로 요청이 이루어지면, 모델은 입력을 처리하고 접두사와 관련된 내부 상태를 캐시합니다. 일치하는 프롬프트 접두사로 후속 요청이 이루어지면, 모델은 캐시에서 읽고 입력 토큰을 처리하는 데 필요한 계산 단계를 건너뜁니다. 이는 첫 번째 토큰까지의 시간(Time To First Token)을 줄이고 하드웨어를 더 효율적으로 사용하여 비용 절감을 공유할 수 있게 합니다.
이 글에서는 Amazon Bedrock의 프롬프트 캐싱 기능에 대한 자세한 개요를 제공하고 지연 시간 개선과 비용 절감을 달성하기 위해 이 기능을 효과적으로 사용하는 방법에 대한 지침을 제공합니다.
프롬프트 캐싱 동작 방식
대규모 언어 모델(LLM)의 처리는 입력 토큰 처리와 출력 토큰 생성의 두 가지 주요 단계로 구성됩니다. 이 중 Amazon Bedrock의 프롬프트 캐싱 기능은 입력 토큰 처리 단계를 최적화합니다.
캐시 체크포인트를 통해 프롬프트의 캐싱 위치를 표시하는 것부터 시작할 수 있습니다. 이를 통해 체크포인트 앞까지의 프롬프트 전체 섹션이 캐시된 프롬프트 접두사가 됩니다. 캐시 체크포인트로 표시된 동일한 프롬프트 접두사로 더 많은 요청을 보내면, LLM은 프롬프트 접두사가 이미 캐시에 저장되어 있는지 확인합니다. 일치하는 접두사가 발견되면, LLM은 캐시에서 저장된 내용을 읽게 되고, 입력 토큰 처리는 캐시 시점 이후부터 재개될 수 있습니다. 이 과정은 프롬프트에 대한 입력 토큰 처리를 처음부터 다시 계산하는 데 소요되는 시간과 비용을 절약시켜 줍니다.
프롬프트 캐싱 기능은 모델별로 다르다는 점에 유의하세요. 지원되는 모델과 캐시 체크포인트당 최소 토큰 수 및 요청당 최대 캐시 체크포인트 수에 대한 세부 정보를 검토해야 합니다.
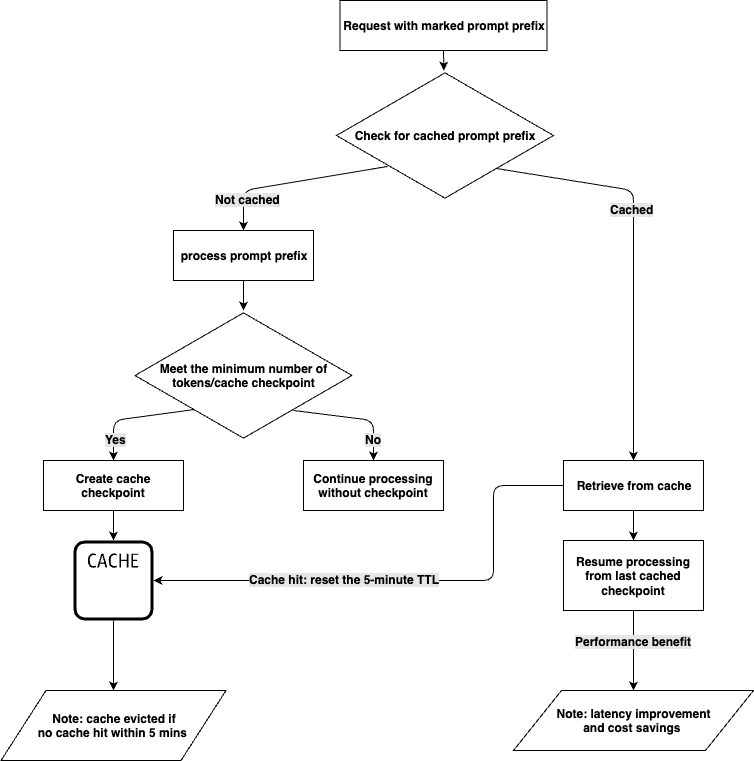
캐시 히트는 정확한 접두사가 일치할 때만 발생합니다. 프롬프트 캐싱의 이점을 최대한 활용하려면, 지시사항 및 예시와 같은 정적 콘텐츠를 프롬프트의 시작 부분에 배치하는 것이 좋습니다. 사용자별 정보를 포함한 동적 콘텐츠는 프롬프트의 끝 부분에 배치해야 합니다. 이 원칙은 캐싱을 가능하게 하기 위해 요청 간에 동일하게 유지되어야 하는 이미지 및 Tool에도 적용됩니다.
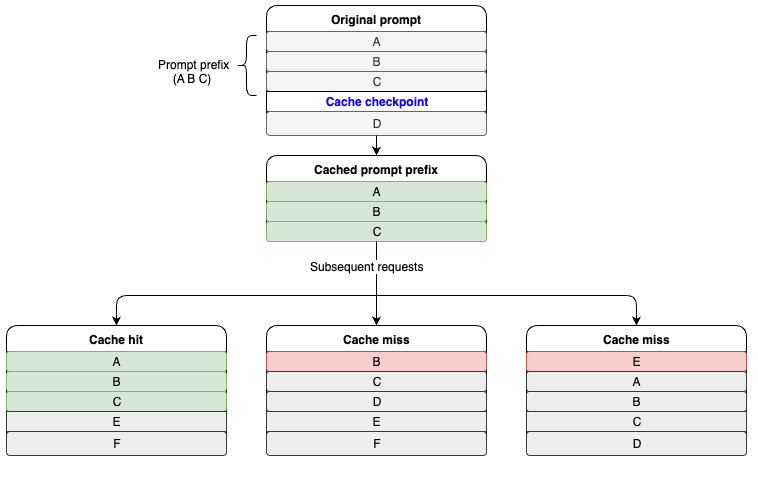
다음 다이어그램은 캐시 히트가 어떻게 작동하는지 보여줍니다. A, B, C, D는 프롬프트의 서로 다른 부분을 나타냅니다. A, B, C는 프롬프트 접두사로 표시됩니다. 후속 요청에 동일한 A, B, C 프롬프트 접두사가 포함되어 있을 때 캐시 히트가 발생합니다.
프롬프트 캐싱을 사용해야 하는 경우
Amazon Bedrock의 프롬프트 캐싱은 여러 API 호출에 걸쳐 자주 재사용되는 긴 컨텍스트 프롬프트를 포함하는 워크로드에 권장됩니다. 이 기능은 응답 지연 시간을 최대 85%까지 개선하고 추론 비용을 최대 90%까지 줄일 수 있어, 반복적이고 긴 입력 컨텍스트를 사용하는 애플리케이션에 적합합니다. 프롬프트 캐싱이 사용 사례에 유익한지 판단하려면, 캐싱할 토큰 수, 재사용 빈도, 요청 간의 시간을 추정해야 합니다.
다음 사용 사례는 프롬프트 캐싱에 적합합니다:
- 문서 기반 챗봇 – 첫 번째 요청에서 문서를 입력 컨텍스트로 캐싱함으로써, 각 사용자 쿼리가 더 효율적으로 처리되어 벡터 데이터베이스와 같은 무거운 솔루션을 사용하지 않는 간단한 아키텍처로 구성할 수 있습니다.
- 코딩 어시스턴트 – 프롬프트에서 긴 코드 파일을 재사용하면 코드 파일을 다시 처리하는 데 소요되는 시간의 대부분을 제거하여 거의 실시간 인라인 추론이 가능합니다.
- 에이전트 워크플로우 – 더 긴 시스템 프롬프트를 사용하여도 최종 사용자 경험을 저하시키지 않고 에이전트 동작을 개선할 수 있습니다. 시스템 프롬프트와 복잡한 도구 정의를 캐싱함으로써, 에이전트 흐름의 각 단계를 처리하는 시간을 줄일 수 있습니다.
- Few-shot 학습 – 고객 서비스나 기술적 문제 해결과 같은 수많은 고품질 예시와 복잡한 지시사항을 포함하는 경우 프롬프트 캐싱의 혜택을 받을 수 있습니다.
프롬프트 캐싱 사용 방법
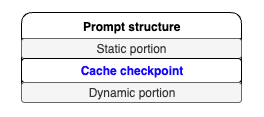
프롬프트 캐싱을 효율적으로 사용하기 위해서는, 주어진 프롬프트의 구성요소를 정적, 혹은 반복되는 영역과 동적 영역으로 분류하는 것이 중요합니다. 즉, 다음과 같은 구조를 따르는 것이 좋습니다.
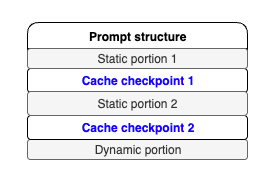
모델 별 제한에 따라 요청 내에 여러 캐시 체크포인트를 생성할 수 있습니다. 이 경우에도 앞서와 동일하게 정적 영역, 캐시 체크포인트, 동적 영역 구조를 따라야 합니다.
사용 사례 예시
문서기반 챗봇은 프롬프트에 문서가 포함되어 있어 프롬프트 캐싱에 적합합니다. 예시의 프롬프트는 정적 부분으로 응답 형식에 대한 지시사항과 문서 본문으로 구성됩니다. 동적 부분은 각 요청마다 변경되는 사용자의 쿼리입니다.
이 시나리오에서는 프롬프트 캐싱을 활성화하기 위해 프롬프트의 정적 부분을 프롬프트 접두사로 표시해야 합니다. 소개해드릴 코드 스니펫은 Invoke Model API를 사용하여 이 접근 방식을 구현하는 방법을 보여줍니다. 여기서는 다음 그림과 같이 지시사항과 문서 내용에 대해 요청에 두 개의 캐시 체크포인트를 생성합니다.
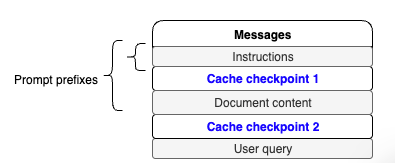
다음과 같이 프롬프트를 구성하고 질문합니다.
def chat_with_document(document, user_query):
instructions = (
"I will provide you with a document, followed by a question about its content. "
"Your task is to analyze the document, extract relevant information, and provide "
"a comprehensive answer to the question. Please follow these detailed instructions:"
"\n\n1. Identifying Relevant Quotes:"
"\n - Carefully read through the entire document."
"\n - Identify sections of the text that are directly relevant to answering the question."
"\n - Select quotes that provide key information, context, or support for the answer."
"\n - Quotes should be concise and to the point, typically no more than 2-3 sentences each."
"\n - Choose a diverse range of quotes if multiple aspects of the question need to be addressed."
"\n - Aim to select between 2 to 5 quotes, depending on the complexity of the question."
"\n\n2. Presenting the Quotes:"
"\n - List the selected quotes under the heading 'Relevant quotes:'"
"\n - Number each quote sequentially, starting from [1]."
"\n - Present each quote exactly as it appears in the original text, enclosed in quotation marks."
"\n - If no relevant quotes can be found, write 'No relevant quotes' instead."
"\n - Example format:"
"\n Relevant quotes:"
"\n [1] \"This is the first relevant quote from the document.\""
"\n [2] \"This is the second relevant quote from the document.\""
"\n\n3. Formulating the Answer:"
"\n - Begin your answer with the heading 'Answer:' on a new line after the quotes."
"\n - Provide a clear, concise, and accurate answer to the question based on the information in the document."
"\n - Ensure your answer is comprehensive and addresses all aspects of the question."
"\n - Use information from the quotes to support your answer, but do not repeat them verbatim."
"\n - Maintain a logical flow and structure in your response."
"\n - Use clear and simple language, avoiding jargon unless it's necessary and explained."
"\n\n4. Referencing Quotes in the Answer:"
"\n - Do not explicitly mention or introduce quotes in your answer (e.g., avoid phrases like 'According to quote [1]')."
"\n - Instead, add the bracketed number of the relevant quote at the end of each sentence or point that uses information from that quote."
"\n - If a sentence or point is supported by multiple quotes, include all relevant quote numbers."
"\n - Example: 'The company's revenue grew by 15% last year. [1] This growth was primarily driven by increased sales in the Asian market. [2][3]'"
"\n\n5. Handling Uncertainty or Lack of Information:"
"\n - If the document does not contain enough information to fully answer the question, clearly state this in your answer."
"\n - Provide any partial information that is available, and explain what additional information would be needed to give a complete answer."
"\n - If there are multiple possible interpretations of the question or the document's content, explain this and provide answers for each interpretation if possible."
"\n\n6. Maintaining Objectivity:"
"\n - Stick to the facts presented in the document. Do not include personal opinions or external information not found in the text."
"\n - If the document presents biased or controversial information, note this objectively in your answer without endorsing or refuting the claims."
"\n\n7. Formatting and Style:"
"\n - Use clear paragraph breaks to separate different points or aspects of your answer."
"\n - Employ bullet points or numbered lists if it helps to organize information more clearly."
"\n - Ensure proper grammar, punctuation, and spelling throughout your response."
"\n - Maintain a professional and neutral tone throughout your answer."
"\n\n8. Length and Depth:"
"\n - Provide an answer that is sufficiently detailed to address the question comprehensively."
"\n - However, avoid unnecessary verbosity. Aim for clarity and conciseness."
"\n - The length of your answer should be proportional to the complexity of the question and the amount of relevant information in the document."
"\n\n9. Dealing with Complex or Multi-part Questions:"
"\n - For questions with multiple parts, address each part separately and clearly."
"\n - Use subheadings or numbered points to break down your answer if necessary."
"\n - Ensure that you've addressed all aspects of the question in your response."
"\n\n10. Concluding the Answer:"
"\n - If appropriate, provide a brief conclusion that summarizes the key points of your answer."
"\n - If the question asks for recommendations or future implications, include these based strictly on the information provided in the document."
"\n\nRemember, your goal is to provide a clear, accurate, and well-supported answer based solely on the content of the given document. "
"Adhere to these instructions carefully to ensure a high-quality response that effectively addresses the user's query."
)
document_content = f"Here is the document: <document> {document} </document>"
messages_API_body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 4096,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": instructions,
"cache_control": {
"type": "ephemeral"
}
},
{
"type": "text",
"text": document_content,
"cache_control": {
"type": "ephemeral"
}
},
{
"type": "text",
"text": user_query
},
]
}
]
}
response = bedrock_runtime.invoke_model(
body=json.dumps(messages_API_body),
modelId="us.anthropic.claude-3-7-sonnet-20250219-v1:0",
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response.get("body").read())
print(json.dumps(response_body, indent=2))
response = requests.get("https://aws.amazon.com/blogs/aws/reduce-costs-and-latency-with-amazon-bedrock-intelligent-prompt-routing-and-prompt-caching-preview/")
blog = response.text
chat_with_document(blog, "What is the blog writing about?")이 요청의 응답에서, usage 부분을 통해 캐시 읽기와 쓰기의 지표를 제공받을 수 있습니다. 다음은 첫 번째 응답의 예시입니다.
{
"id": "msg_bdrk_01BwzJX6DBVVjUDeRqo3Z6GL",
"type": "message",
"role": "assistant",
"model": "claude-3-7-sonnet-20250219”,
"content": [
{
"type": "text",
"text": "Relevant quotes:\n[1] \"Today, Amazon Bedrock has introduced in preview two capabilities that help reduce costs and latency for generative AI applications\"\n\n[2] \"Amazon Bedrock Intelligent Prompt Routing \u2013 When invoking a model, you can now use a combination of foundation models (FMs) from the same model family to help optimize for quality and cost... Intelligent Prompt Routing can reduce costs by up to 30 percent without compromising on accuracy.\"\n\n[3] \"Amazon Bedrock now supports prompt caching \u2013 You can now cache frequently used context in prompts across multiple model invocations... Prompt caching in Amazon Bedrock can reduce costs by up to 90% and latency by up to 85% for supported models.\"\n\nAnswer:\nThe article announces two new preview features for Amazon Bedrock that aim to improve cost efficiency and reduce latency in generative AI applications [1]:\n\n1. Intelligent Prompt Routing: This feature automatically routes requests between different models within the same model family based on the complexity of the prompt, choosing more cost-effective models for simpler queries while maintaining quality. This can reduce costs by up to 30% [2].\n\n2. Prompt Caching: This capability allows frequent reuse of cached context across multiple model invocations, which is particularly useful for applications that repeatedly use the same context (like document Q&A systems). This feature can reduce costs by up to 90% and improve latency by up to 85% [3].\n\nThese features are designed to help developers build more efficient and cost-effective generative AI applications while maintaining performance and quality standards."
}
],
"stop_reason": "end_turn",
"stop_sequence": null,
"usage": {
"input_tokens": 9,
"cache_creation_input_tokens": 37209,
"cache_read_input_tokens": 0,
"output_tokens": 357
}
}최초 호출 시점이므로, 지시사항과 문서에 대해 모두 캐시 쓰기가 발생하여 총 37,209개의 캐시 쓰기 토큰이 사용되었음을 cache_creation_input_tokens 값을 통해 알 수 있습니다. 이를 그림으로 표현하면 다음과 같습니다.
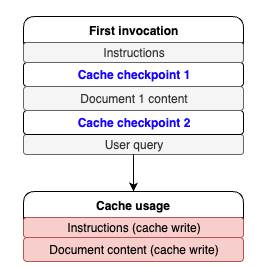
이어서 동일한 문서를 대상으로 다른 내용을 질문해 보겠습니다.
chat_with_document(blog, "what are the use cases?")추가 질문에서는 프롬프트의 동적 영역이 변경되었지만 정적 영역과 프롬프트 접두사는 그대로 유지되어, 캐시 히트를 기대할 수 있습니다. 호출 결과는 다음과 같습니다.
ude-3-7-sonnet-20250219",
"content": [
{
"type": "text",
"text": "Relevant quotes:\n[1] \"This is particularly useful for applications such as customer service assistants, where uncomplicated queries can be handled by smaller, faster, and more cost-effective models, and complex queries are routed to more capable models.\"\n\n[2] \"This is especially valuable for applications that repeatedly use the same context, such as document Q&A systems where users ask multiple questions about the same document or coding assistants that need to maintain context about code files.\"\n\n[3] \"During the preview, you can use the default prompt routers for Anthropic's Claude and Meta Llama model families.\"\n\nAnswer:\nThe document describes two main features with different use cases:\n\n1. Intelligent Prompt Routing:\n- Customer service applications where query complexity varies\n- Applications needing to balance between cost and performance\n- Systems that can benefit from using different models from the same family (Claude or Llama) based on query complexity [1][3]\n\n2. Prompt Caching:\n- Document Q&A systems where users ask multiple questions about the same document\n- Coding assistants that need to maintain context about code files\n- Applications that frequently reuse the same context in prompts [2]\n\nBoth features are designed to optimize costs and reduce latency while maintaining response quality. Prompt routing can reduce costs by up to 30% without compromising accuracy, while prompt caching can reduce costs by up to 90% and latency by up to 85% for supported models."
}
],
"stop_reason": "end_turn",
"stop_sequence": null,
"usage": {
"input_tokens": 10,
"cache_creation_input_tokens": 0,
"cache_read_input_tokens": 37209,
"output_tokens": 324
}
}캐시 영역에 저장된 37,209개의 토큰을 읽어 지시사항과 문서에 대한 입력 토큰 처리를 캐시에서 가져와 수행하였고, 새로운 질문을 위해 10개의 입력 토큰만이 처리되었습니다. 이를 그림으로 표현하면 다음과 같습니다.
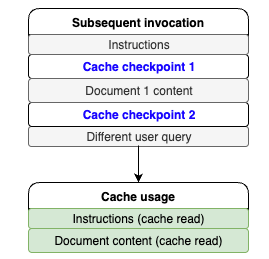
이번엔 문서를 다른 블로그 게시물로 변경해보겠습니다. 이 경우에도 지시사항은 동일하게 유지됩니다. 지시사항에 대한 캐시 체크포인트가 별도로 지정되어 있어 새로운 요청에 대해서도 캐시 히트가 발생할 것으로 예상할 수 있습니다. 다음과 같이 코드를 작성하고 실행하였습니다.
response = requests.get(https://aws.amazon.com/blogs/machine-learning/enhance-conversational-ai-with-advanced-routing-techniques-with-amazon-bedrock/)
blog = response.text
chat_with_document(blog, "What is the blog writing about?")응답 결과입니다.
{
"id": "msg_bdrk_011S8zqMXzoGHABHnXX9qSjq",
"type": "message",
"role": "assistant",
"model": "claude-3-7-sonnet-20250219",
"content": [
{
"type": "text",
"text": "Let me analyze this document and provide a comprehensive answer about its main topic and purpose.\n\nRelevant quotes:\n[1] \"When you're designing a security strategy for your organization, firewalls provide the first line of defense against threats. Amazon Web Services (AWS) offers AWS Network Firewall, a stateful, managed network firewall that includes intrusion detection and prevention (IDP) for your Amazon Virtual Private Cloud (VPC).\"\n\n[2] \"This blog post walks you through logging configuration best practices, discusses three common architectural patterns for Network Firewall logging, and provides guidelines for optimizing the cost of your logging solution.\"\n\n[3] \"Determining the optimal logging approach for your organization should be approached on a case-by-case basis. It involves striking a balance between your security and compliance requirements and the costs associated with implementing solutions to meet those requirements.\"\n\nAnswer:\nThis document is a technical blog post that focuses on cost considerations and logging options for AWS Network Firewall. The article aims to help organizations make informed decisions about implementing and managing their firewall logging solutions on AWS. Specifically, it:\n\n1. Explains different logging configuration practices for AWS Network Firewall [1]\n2. Discusses three main architectural patterns for handling firewall logs:\n - Amazon S3-based solution\n - Amazon CloudWatch-based solution\n - Amazon Kinesis Data Firehose with OpenSearch solution\n3. Provides detailed cost analysis and comparisons of different logging approaches [3]\n4. Offers guidance on balancing security requirements with cost considerations\n\nThe primary purpose is to help AWS users understand and optimize their firewall logging strategies while managing associated costs effectively. The article serves as a practical guide for organizations looking to implement or improve their network security logging while maintaining cost efficiency [2]."
}
],
"stop_reason": "end_turn",
"stop_sequence": null,
"usage": {
"input_tokens": 9,
"cache_creation_input_tokens": 37888,
"cache_read_input_tokens": 1038,
"output_tokens": 385
}
}응답 결과를 통해, 지시사항 처리를 위해 1,038개의 토큰이 캐시로부터 읽어왔다는 것과 37,888개의 토큰이 새로운 문서 컨텐츠를 위해 캐시에 쓰여졌다는 것을 알 수 있습니다. 이를 그림으로 표현하면 아래와 같습니다.
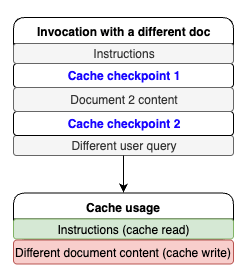
비용 절감
캐시 히트가 발생하면 Amazon Bedrock은 캐시된 컨텍스트에 대해 토큰 당 할인을 제공하여 컴퓨팅 절감 효과를 제공합니다. 비용 절감액을 계산하려면 먼저 Amazon Bedrock 응답의 캐시 쓰기/읽기 메트릭을 통해 프롬프트 캐싱 사용 패턴을 이해해야 합니다. 그런 다음 1,000개 입력 토큰당 가격(캐시 쓰기) 및 1,000개 입력 토큰당 가격(캐시 읽기)을 통해 잠재적인 비용 절감을 계산할 수 있습니다. 자세한 가격 정보는 Amazon Bedrock 가격을 참조하세요.
지연 시간 벤치마크
프롬프트 캐싱은 반복적인 프롬프트에 대한 TTFT(Time to First Token, 첫 번째 토큰까지의 시간) 성능을 개선하도록 최적화되어 있습니다. 프롬프트 캐싱은 채팅 플레이그라운드와 유사한 멀티 턴 채팅을 포함하는 대화형 애플리케이션에 적합합니다. 또한 큰 문서를 반복적으로 참조해야 하는 사용 사례에도 도움이 될 수 있습니다.
그러나 2,000개의 토큰으로 구성된 긴 시스템 프롬프트와 그 이후에 동적으로 변경되는 긴 텍스트를 포함하는 워크로드의 경우, 프롬프트 캐싱은 효과적이지 않을 수 있습니다.
프롬프트 캐싱 사용 방법과 벤치마크 방법에 대한 노트북을 GitHub repo에 게시했습니다. 벤치마크 결과는 입력 토큰 수, 캐시된 토큰 수 또는 출력 토큰 수 등 사용 사례에 따라 달라질 수 있습니다.
Amazon Bedrock의 교차리전 추론
프롬프트 캐싱은 교차 리전 추론(CRIS)과 함께 사용할 수 있습니다. 교차 리전 추론은 사용 가능한 리소스와 모델 가용성을 최대화하기 위해 지리적 위치 내에서 추론 요청을 처리할 최적의 AWS 리전을 자동으로 선택합니다. 수요가 많은 시간에는 이러한 최적화로 인해 캐시 쓰기가 증가할 수 있습니다.
지표와 관찰 가능성 (Observability)
프롬프트 캐싱 관찰 가능성은 Amazon Bedrock을 사용하는 애플리케이션의 비용 절감 및 지연 시간 개선을 최적화하는 데 필수적입니다. 주요 성능 지표들을 모니터링함으로써 개발자는 긴 프롬프트의 TTFT를 최대 85%까지 줄이고 비용을 최대 90%까지 절감하는 등 애플리케이션의 효율성을 향상시킬 수 있습니다. 이러한 지표들은 개발자가 캐시 성능을 정확하게 평가하고 캐시 관리에 관한 전략적 결정을 내릴 수 있게 해줍니다.
Amazon Bedrock을 통해 모니터링 하기
Amazon Bedrock은 API 응답의 usage 영역을 통해 캐시 성능 데이터를 노출하여, 개발자가 캐시 히트율, 토큰 소비(읽기 및 쓰기 모두), 지연 시간 개선과 같은 필수 메트릭을 추적할 수 있게 합니다. 이러한 인사이트를 활용함으로써 여러분들은 애플리케이션 응답성을 향상시키고 운영 비용을 줄이기 위해 캐싱 전략을 효과적으로 관리할 수 있습니다.
Amazon CloudWatch를 통해 모니터링 하기
Amazon CloudWatch는 AWS 서비스의 상태와 성능을 모니터링하기 위한 강력한 플랫폼을 제공하며, 특히 Amazon Bedrock 모델을 위해 맞춤화된 새로운 자동 대시보드를 제공합니다. 이 대시보드를 통해 주요 지표들에 빠르게 접근할 수 있어, 모델 성능에 대한 더 깊은 인사이트를 얻을 수 있습니다.
다음은 사용자 지정 관찰 가능성 대시보드를 만드는 과정입니다.
- CloudWatch 콘솔에서 새 대시보드를 생성합니다. 전체 예시는 Amazon CloudWatch를 사용하여 Amazon Bedrock 사용량 및 성능에 대한 가시성 향상을 참조하세요.
- 데이터 소스로 CloudWatch를 선택하고 초기 위젯 유형으로 Pie를 선택합니다 (이후 변경 가능합니다).
- 모니터링 요구 사항에 맞게 메트릭의 시간 범위를 업데이트합니다 (예: 1시간, 3시간 또는 1일).
- AWS namespaces에서 Bedrock을 선택합니다.
- “cache”를 검색하여 캐시 관련 메트릭을 필터링합니다.
- 조회 할 Model ID(
anthropic.claude-3-7-sonnet-20250219-v1:0)를 찾아CacheWriteInputTokenCount와CacheReadInputTokenCount를 모두 선택합니다.
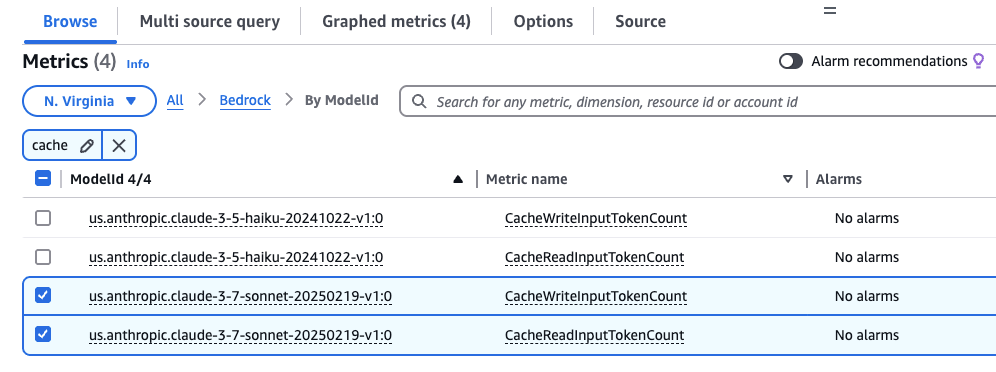
- 위젯 생성을 선택한 다음 저장 버튼을 눌러 대시보드를 저장합니다.
다음은 이 위젯을 생성하기 위한 샘플 JSON 설정입니다.
{
"view": "pie",
"metrics": [
[ "AWS/Bedrock", "CacheReadInputTokenCount" ],
[ ".", "CacheWriteInputTokenCount" ]
],
"region": "us-west-2",
"setPeriodToTimeRange": true
}캐시 히트율(cache hit rates) 이해하기
캐시 히트율 분석에는 CacheReadInputTokens와 CacheWriteInputTokens 모두를 관찰하는 것이 포함됩니다. 정의된 기간 동안 이러한 메트릭을 합산함으로써 개발자는 캐싱 전략의 효율성에 대한 인사이트를 얻을 수 있습니다. Amazon Bedrock 가격 페이지에 게시된 모델별 1,000개 입력 토큰당 가격(캐시 쓰기) 및 1,000개 입력 토큰당 가격(캐시 읽기)을 통해 특정 사용 사례에 대한 잠재적인 비용 절감을 추정할 수 있습니다.
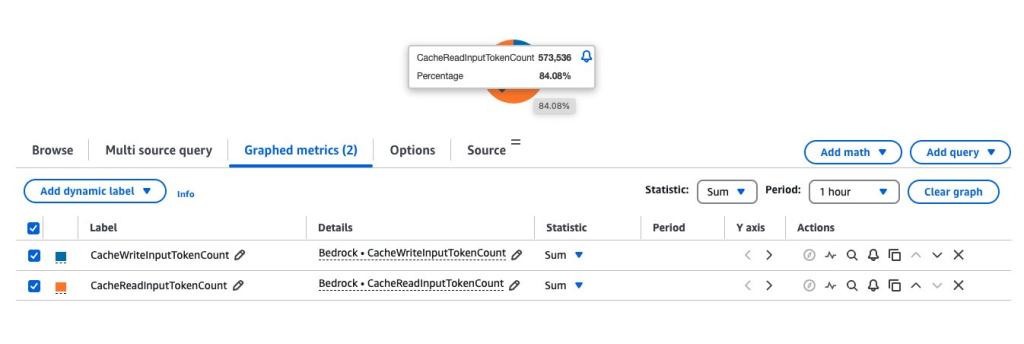
결론
이 글에서는 Amazon Bedrock의 프롬프트 캐싱 기능을 탐색하여 작동 방식, 사용 시기 및 효과적인 사용 방법을 보여주었습니다. 이 기능이 여러분들의 애플리케이션에 도움이 될지 신중하게 평가하는 것이 중요합니다. 이를 위해 프롬프트의 구조화, 정적 콘텐츠와 동적 콘텐츠의 구분, 특정 요구 사항에 적합한 캐싱 전략 선택에 대한 이해가 중요합니다. 또한 CloudWatch 메트릭을 사용하여 캐시 성능을 모니터링하고 이 글에 설명된 구현 패턴을 따름으로써, 높은 성능을 유지하면서 더 효율적이고 비용 효과적인 AI 애플리케이션을 구축할 수 있습니다.
Amazon Bedrock에서 프롬프트 캐싱 작업에 대한 자세한 내용은 더 빠른 모델 추론을 위한 프롬프트 캐싱을 참조하세요.