AWS 기술 블로그
알리는사람들의 Amazon Data Firehose로 Amazon DynamoDB를 Amazon S3 tables로 실시간 복제하기
개요
알리는사람들은 다양한 메시징 채널을 통합하여 기업의 커뮤니케이션을 자동화하고, 고객에게 정확한 메시지를 빠르게 전달할 수 있도록 돕는 테크 스타트업입니다. 인증, 마케팅, 알림 등 다양한 메시지 유형을 유연하게 다룰 수 있는 인프라를 바탕으로, 수많은 기업이 일상적인 고객 커뮤니케이션을 효율적으로 운영하고 있습니다.
센드온(Sendon)은 알리는사람들이 개발한 클라우드 네이티브 메시징 플랫폼으로, 대용량 메시지 전송에 최적화된 서버리스 아키텍처를 기반으로 운영됩니다. 문자, 알림톡, 친구톡 등 다양한 메시징 채널을 지원하며, 각 채널별 특성에 맞춘 API와 SDK를 통해 빠르고 안정적인 메시지 발송이 가능합니다.
센드온은 앞으로 메시지 자동화와 세분화된 타겟팅 기능을 지속적으로 발전시켜, 메시징 플랫폼 시장에서 새로운 혁신을 만들어 나가고자 합니다. 단순한 발송 도구를 넘어, 고객 행동 기반의 지능형 메시징 플랫폼으로 도약하는 것을 목표로 하고 있습니다.
이를 위해 센드온은 실시간 사용자 데이터를 기반으로 한 분석 환경을 구축하고 있습니다. Amazon DynamoDB 스트림 데이터를 수집하여 Apache Iceberg 기반의 분석 테이블로 변환하는 서버리스 데이터 파이프라인은 이러한 비전을 실현하기 위한 핵심 구성 요소입니다. 이 블로그는 서버리스 환경에서 DynamoDB 트랜잭션 데이터를 스트리밍 방식으로 수집하고, Apache Iceberg 기반 분석 테이블로 변환하는 전체 흐름을 다룹니다. DynamoDB 기반 파이프라인은 단순 저장이 아닌, 스트림 데이터를 구조화된 분석 단위로 변환하는 데 목적이 있습니다.
Amazon S3 Tables 역할
센드온의 메시지 발송 서비스와 같은 핵심 시스템은 사용자 요청을 처리하기 위해 DynamoDB를 주요 저장소로 사용하고 있습니다. 특히 빠른 읽기/쓰기 성능과 유연한 확장성 덕분에 트래픽이 집중되는 실시간 메시징 서비스에 적합한 선택이었습니다. 하지만 이렇게 저장된 트랜잭션 데이터는 서비스 운영에는 적합하더라도, 곧바로 분석에 활용하기에는 여러 한계가 존재합니다.
- 구조적 한계: 분석에 최적화된 저장 구조가 아님
- 쿼리 제약: 복잡한 조건 검색, 조인, 통계 연산 등이 어려움
- 확장성 문제: 전체 데이터를 주기적으로 덤프하는 방식은 비효율적이고 확장성 부족
예를 들어, 특정 기간 동안 발송된 메시지 그룹별 성공률, 사용자별 잔여 포인트 변동 추이, API를 통한 발송 비율 등의 지표를 도출하려 할때, DynamoDB 단독으로는 이를 효율적으로 추출하기 어렵습니다.
기존에는 운영 데이터를 별도로 정제하거나 수작업으로 덤프한 후, RDB 또는 분석용 저장소에 적재하는 방식이 일반적이었습니다. 그러나 이 방식은 실시간성을 갖기 어려웠고, 데이터 파이프라인 자동화 측면에서도 한계가 분명했습니다.
이러한 문제를 해결하기 위해, DynamoDB에서 발생하는 변경 이벤트를 스트리밍 방식으로 외부로 흘려보내고, 이를 Apache Iceberg를 지원하는 S3 Tables에 저장하여 분석 가능한 형태로 전환하는 구조를 선택하게 되었습니다. 이를 통해 실시간에 가까운 데이터 분석, 구조화된 테이블 설계, Amazon Athena 기반의 효율적인 쿼리가 가능해집니다.
아키텍처
이번에 구축한 파이프라인의 목적은 DynamoDB 테이블에서 발생하는 변경 이벤트(INSERT, MODIFY, REMOVE)를 실시간으로 수집하고, 이를 S3 기반의 Iceberg 테이블에 저장해 Athena를 통해 쿼리할 수 있는 구조를 만드는 것입니다.

전체적인 흐름은 데이터를 수집하는 DynamoDB → Kinesis Data Stream → Data Firehose → S3 Tables 단계와 데이터를 분석/시각화하는 Athena/QuickSight 단계로 구성 되어있습니다.
(1) DynamoDB → Amazon Kinesis Data Stream
- DynamoDB 테이블에 항목이 INSERT, MODIFY, REMOVE 될 때마다 DynamoDB Streams를 통해 이벤트가 생성됩니다.
- 이 이벤트는 Kinesis Data Stream으로 전달되어, 이후 실시간 데이터 파이프라인의 첫 입력 지점이 됩니다.
(2) Kinesis Data Stream → Amazon Data Firehose
- Kinesis Data Stream에 수신된 이벤트는 Data Firehose로 전달됩니다.
- Firehose는 이벤트를 수신한 뒤, Transform Lambda 호출 전까지 버퍼링하거나, 그대로 넘기는 역할을 합니다.
(3) Firehose → Transform Lambda
- Firehose는 데이터를 목적지로 전달하기 전에 Lambda 함수를 호출할 수 있습니다.
- 우리는 이 기능을 활용해, Lambda에서 DynamoDB Stream 이벤트(JSON 포맷)를 파싱하고, Iceberg 테이블 구조에 맞게 데이터를 정제합니다. (대소문자 규칙 통일, 숫자/불리언 타입 정제, 파티션 컬럼 보정 등)
- 이 Lambda는 데이터 전처리 및 정형화만 담당하며, 포맷 변환(Parquet)은 Firehose에서 자동 처리됩니다.
(4) Firehose → Resource Link → Iceberg Table
- Lambda로부터 정제된 데이터를 받은 Firehose는 AWS Glue 기본 카탈로그에서 생성된 Resource Link를 통해 Iceberg 테이블에 데이터를 적재합니다.
- Firehose는 직접 s3tablescatalog에 접근할 수 없기 때문에, Resource Link를 프록시로 사용합니다.
- 이 과정에서 Firehose는 내부적으로 JSON 데이터를 Iceberg 포맷에 맞게 자동으로 Parquet으로 변환하여 저장합니다.
(5) Athena / Amazon QuickSight → Iceberg Table 조회
- 데이터 분석가는 Athena를 통해 Iceberg 테이블에 저장된 데이터를 SQL로 조회할 수 있습니다.
- 또는 QuickSight와 Athena를 연동하여 시각화할 수 있습니다.
- 이 모든 쿼리는 Glue Data Catalog를 통해 Iceberg 테이블 메타데이터를 읽으며, AWS Lake Formation 에서 설정한 권한 정책에 따라 접근이 제한됩니다.
파이프라인 구성
아키텍처의 데이터 수집 단계를 구성하는 절차는 다음과 같습니다
단계 1: Kinesis Data Stream 연결
DynamoDB의 변경 스트림 데이터를 실시간으로 수집하려면, Kinesis Data Stream과의 연결이 필요합니다. 이 장에서는 DynamoDB 테이블의 변경 이벤트를 외부 파이프라인으로 전달할 수 있도록 Kinesis와 연결하는 과정을 설명합니다.
DynamoDB는 자체적으로 Streams 기능을 제공합니다. 하지만 이 Streams는 기본적으로 Lambda 트리거나 일부 제한된 서비스에만 연결이 가능하며, 다른 서비스들과 유연하게 연계하기엔 제약이 있습니다. 이를 해결하기 위해 AWS에서는 DynamoDB의 스트림 데이터를 Kinesis Data Stream으로 복제할 수 있는 기능을 제공합니다. 이 기능을 사용하면 실시간 변경 이벤트를 Kinesis 기반의 파이프라인에 직접 연결할 수 있어, 다양한 AWS 서비스 혹은 커스텀 처리로 확장할 수있습니다.
1.1 Kinesis Data Stream 생성하기 (CLI 코드 예시)
aws kinesis create-stream
-- stream-name myS3TableKinesisStream
--shard-count 1
aws kinesis increase-stream-retention-period
—stream-name myS3TableKinesisStream
—retention-period-hours 24- shard-count는 현재 처리량 기준으로 1로 설정했지만, 실제 트래픽에 따라 조정이 필요합니다.
- retention-period-hours는 최대 7일까지 설정 가능하며, 이 예제에서는 24시간 동안 유지되도록 설정했습니다.
- 스트림 모드는 기본적으로 PROVISIONED 모드가 사용됩니다.
1.2 DynamoDB 테이블과 Kinesis 연결하기
DynamoDB 테이블을 Kinesis Data Stream과 연결하기 위해서는 콘솔에서 다음의 작업을 수행해야 합니다
- DynamoDB 콘솔로 이동하여 해당 테이블을 선택합니다.
- “Kinesis Data Stream” 섹션에서 Turn on 버튼을 클릭합니다.
- 앞서 생성한 Kinesis Stream 리소스를 선택한 뒤 저장하면 연결이 완료됩니다.
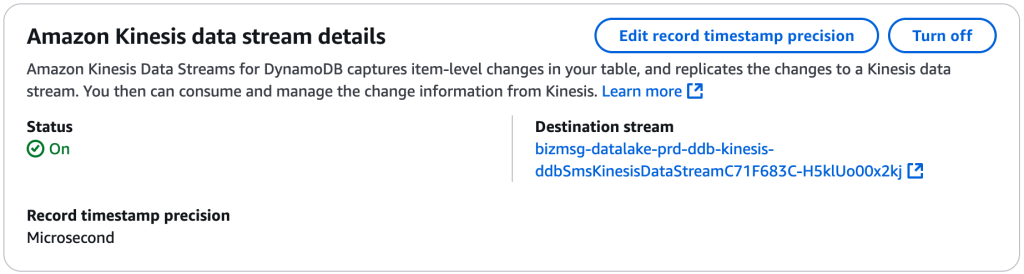
연결이 완료되면, DynamoDB에서 발생하는 모든 변경 이벤트가 지정한 Kinesis Stream으로 복제되어 전송됩니다. 이제 이 스트림을 활용해 Firehose, Lambda 등의 다음 단계를 구성할 수 있습니다.
단계 2: S3 Table Bucket 생성
Apache Iceberg 기반 분석을 위해서는 데이터를 저장할 전용 S3 Table Bucket이 필요합니다. 이 버킷은 일반적인 S3 버킷과 달리 Iceberg 포맷 데이터를 저장하고, Glue Data Catalog, Athena 등과 직접 연동되는 테이블 중심의저장소 역할을 합니다. 현재 Amazon S3 Table Bucket은 서울 리전을 포함한 일부 리전에서만 사용할 수 있으며, 생성 방식도 콘솔 또는 AWS CLI를 통해서만가능합니다.
이 장에서는 다음 세 가지 단계를 중심으로 구성합니다.
- S3 Table Bucket 생성
- Iceberg Namespace(Database) 구성
- Glue Data Catalog 및 Athena 연동
각 단계를 거치면서, 실시간 수집된 데이터를 테이블 단위로 저장하고 분석 가능한 구조로 전환하는 기반을 마련할 수 있습니다.
2.1 S3 Table Bucket 생성하기
센드온 데이터 파이프라인에서는 다양한 원천 데이터를 분석 가능한 구조로 전환하기 위해 Apache Iceberg를 도입하고 있습니다. Iceberg는 S3에 저장된 데이터를 테이블 구조로 관리할 수 있게 해주는 테이블 포맷으로, 대용량 데이터 분석에 적합하며 Athena, Amazon EMR, Glue 등의 서비스와의 연동도 수월합니다.
Iceberg 기반 분석을 구성하기 위해서는 일반 S3 버킷이 아닌 S3 Table Bucket을 먼저 생성해야 합니다. S3 Table Bucket은 단순한 객체 저장소가 아닌, Iceberg 포맷을 저장하고 분석 도구들과 테이블 단위로 연동되는 전용 버킷입니다.
Iceberg 기반 S3 Table을 구성하는 데 필요한 주요 요소는 다음과 같습니다.
- S3 Table Bucket: Iceberg 데이터를 저장하는 전용 버킷
- Glue Data Catalog: 테이블 메타데이터를 관리
- Lake Formation 권한 설정: Athena, Lambda, Firehose 등의 접근 권한 제어
- Iceberg 쿼리 엔진: Athena, Apache Spark, Dremio 등
버킷은 CLI 와 콘솔을 이용하여 생성 할 수 있습니다.
CLI를 이용한 버킷 생성
aws s3tables create-table-bucket
--region ap-northeast-2
--name {bucketName}콘솔을 이용한 버킷 생성
아래는 S3 콘솔에서 S3 Table Bucket을 생성하는 화면입니다.
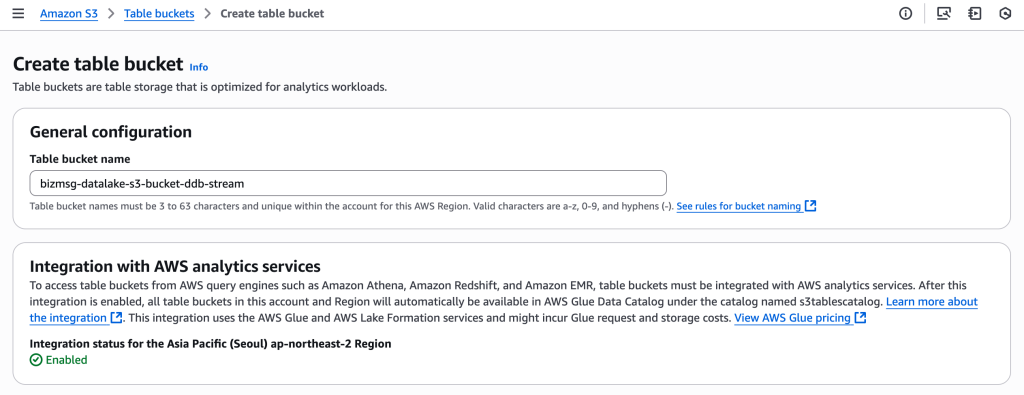
버킷 이름을 지정하고, Glue 기반 분석 서비스와의 연동이 활성화되어 있는지 확인 후, Create table bucket 버튼을 클릭하면 됩니다.
2.2 S3 Table Bucket Namespace 생성하기
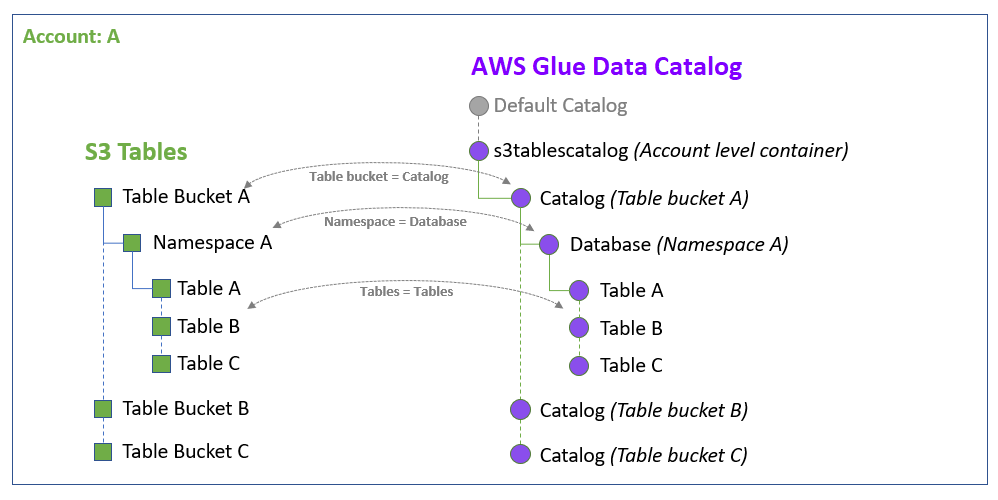
S3 Table Bucket을 생성했다면, 다음 단계는 Iceberg 테이블이 속할 Namespace를 생성하는 것입니다. Namespace는 S3 Table Bucket 내의 논리적인 데이터베이스 단위로, 하나 이상의 테이블이 속하게 되는 공간이며, AWS Glue Data Catalog 상에서는 Database로 표현됩니다.
즉, S3 Table Bucket → Catalog, Namespace → Database, 개별 테이블 → Table로 매핑되는 구조입니다.
아래 다이어그램은AWS Glue Data Catalog에서 S3 Table Bucket이 어떻게 구조화되는지를 보여줍니다.
- 이름은 1자 이상 255자 이하, 소문자/숫자/언더스코어(_)만 사용 가능합니다.
- 콘솔뿐만 아니라 Athena DDL 문을 통해서도 생성할 수 있습니다.
Namespace는 하나의 분석 도메인을 구성하는 기준 단위가 되므로, 도메인별로 분리해서 구성하는 것이 이후 쿼리 관리 측면에서 유리합니다.
CLI를 이용한 네임스페이스 생성
aws s3tables create-namespace
--table-bucket-arn arn:aws:s3tables:ap-northeast-2:{accountId}:bucket/{bucketName}
--namespace {namespaceName}Athena 콘솔을 이용한 네임스페이스 생성
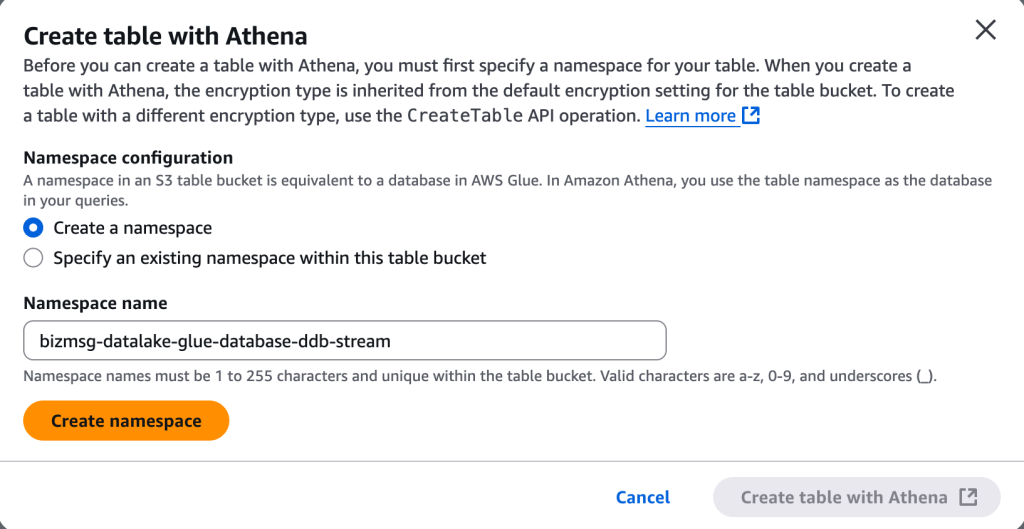
2.3 S3 Iceberg Table 생성하기
S3 Table Bucket과 Namespace를 구성했다면, 이제 Iceberg 테이블을 생성할 차례입니다. Iceberg는 객체 스토리지 기반 데이터 레이크를 마치 RDB의 테이블처럼 관리할 수 있는 포맷으로, Athena, Spark, Flink 등에서 SQL 기반 쿼리를 실행할 수 있게 도와줍니다. 이번 단계에서는 Athena를 이용해 Iceberg 테이블을 직접 생성합니다. Athena에서는 CREATE TABLE 문을 통해 Iceberg 테이블을정의할 수 있으며, S3 Table Bucket 아래 지정된 Namespace(Database)에 테이블이 생성됩니다.
예시 쿼리
CREATE TABLE bizmsg_datalake_glue_database_ddb_stream.messaging_sms_group_detail (
pk string,
sk string,
messages_count int,
message_type string,
total_point double,
...
...
...
ttl string,
updated_at timestamp,
user_id int,
__en string
)
PARTITIONED BY (group_id)
TBLPROPERTIES ('table_type' = 'iceberg')- 테이블은 Database.Table 형태로 생성되며, Glue Data Catalog에 자동 등록됩니다.
- TBLPROPERTIES 항목에서 반드시 table_type = ‘iceberg’로 지정해야 합니다.
컬럼 명명 규칙 주의할 점
Athena Iceberg 테이블을 생성할 때는 컬럼 이름의 대소문자 및 표기 방식에 주의해야 합니다. Iceberg는 컬럼명을 엄격하게 일치시키기 때문에, PARTITIONED BY에 사용된 컬럼이 정의된 컬럼명과 다르면 아래와 같은 오류가 발생할 수 있습니다.
Cannot find source column: groupId
이런 오류는 대부분 camelCase 와 snake_case가 섞여 사용되었을 때 발생하므로, 테이블 생성 시에는 모든 컬럼명을 snake_case로통일하는 것이 안정적입니다.
생성 결과 확인
테이블 생성이 정상적으로 완료되면, Athena 콘솔 좌측 메뉴에서 생성된 테이블을 확인할 수 있습니다.
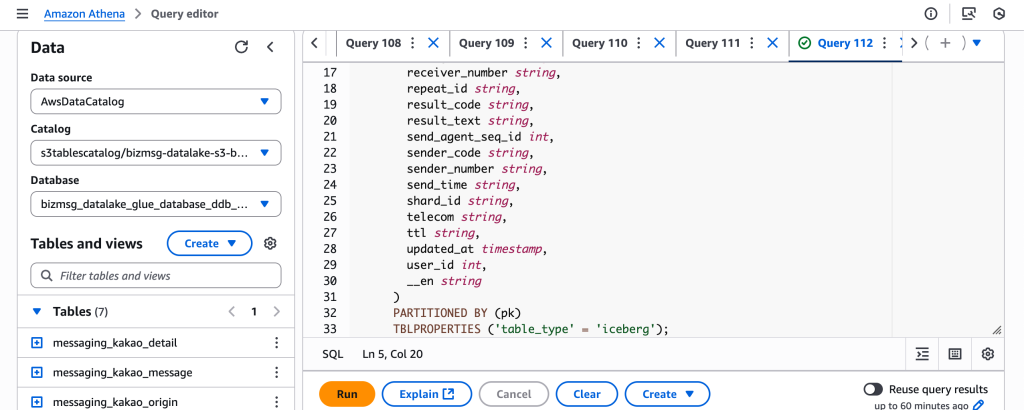
또한 S3 Table Bucket 에서도 아래와 같이 테이블이 추가된 것을 확인할 수 있습니다.
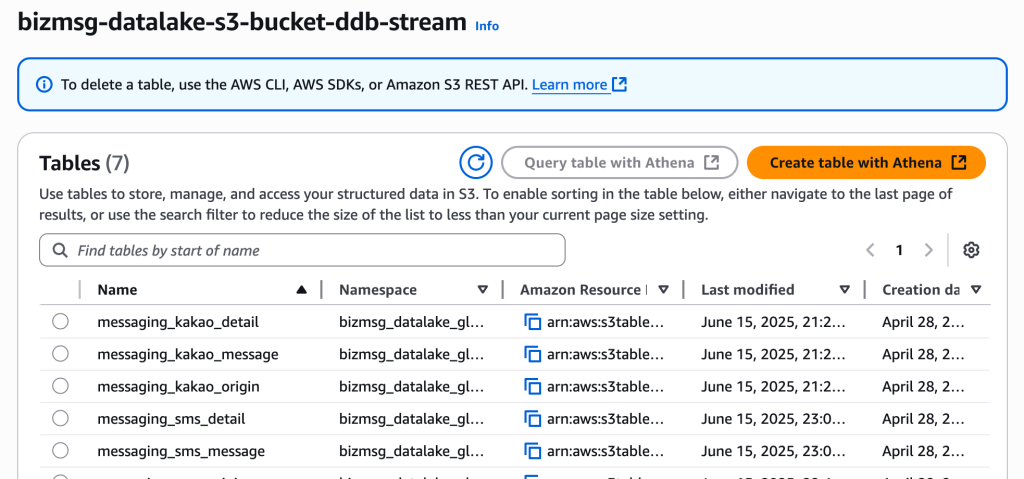
2.4 S3 Iceberg Table 접근 권한 부여하기
S3 Table Bucket과 Iceberg 테이블을 생성한 이후에는, 해당 테이블에 접근할 수 있도록 필요한 서비스에 권한을 부여해야 합니다. Iceberg 기반 S3 Tables는 AWS Glue Data Catalog의 s3tablescatalog 아래에 등록되며, 기본적으로 Lake Formation을 통해 접근제어가 적용됩니다. 따라서 Athena, Firehose, Lambda 등이 해당 테이블에 접근하려면 Lake Formation 권한 설정이 필수입니다.
Lake Formation이란?
Lake Formation은 AWS에서 제공하는 중앙 집중형 데이터 거버넌스 서비스로, Glue Data Catalog에 등록된 리소스에 대해 정교한 권한 관리를 제공합니다. IAM만으로는 어렵던 열(column) 단위, 행(row) 단위 권한 설정이나 위임 기반 제어가 가능하며, Athena, Redshift, EMR, Glue 등 분석 서비스에서 데이터 접근을 통합적으로 관리할 수 있습니다.
권한 부여 위치
Lake Formation 콘솔 > Data permissions > Grant 메뉴에서 권한을 부여할 수 있습니다.
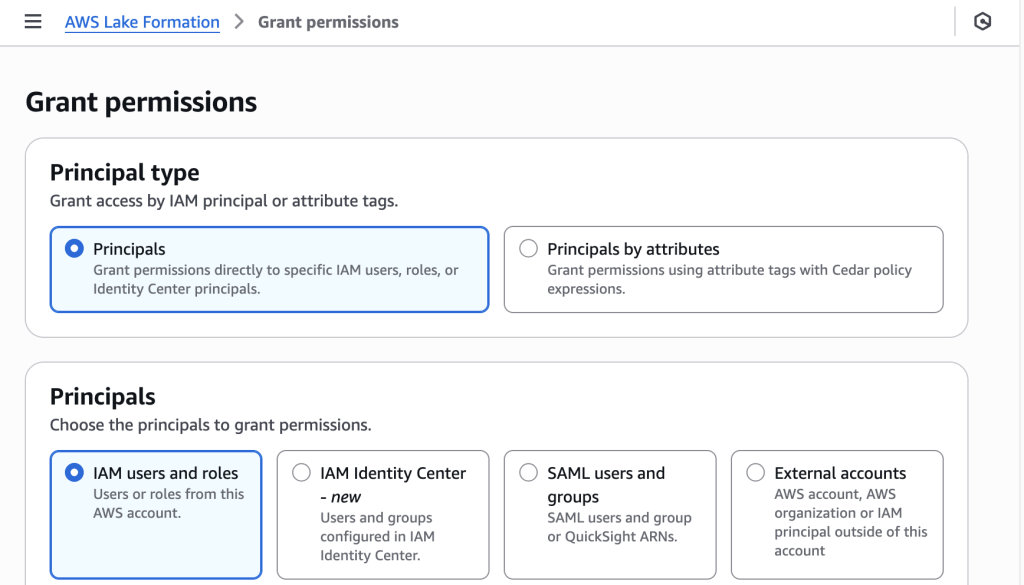
권한 부여 예시
- Principals: IAM users and roles > Firehose용 Role 또는 Athena에서 쿼리할 IAM 사용자 선택
- LF-Tags or catalog resources: Named Data Catalog resources 선택
- Catalogs: “{accountId}:s3tablescatalog/{s3TableBucketName}”
- Databases: “{databaseName}”
- Tables: All tables 또는 특정 테이블 선택
- Table permissions: SELECT, INSERT, DELETE, DESCRIBE, ALTER 등 필요한 항목 체크 (테스트 목적이라면 처음에는 모두 선택해도 무방)
권한 구성 예시
- Firehose: INSERT, DESCRIBE, ALTER
- Athena: SELECT, DESCRIBE
- Lambda: (선택적으로) INSERT 또는 SELECT 등
단계 3: Amazon Data Firehose 연결
이 장에서는 Firehose가 Iceberg 기반 S3 Table과 연동되기까지의 구성 요소들과 설정 과정을 설명합니다.
Amazon Kinesis Data Firehose란?
Amazon Kinesis Data Firehose는 Kinesis Data Stream에서 수신한 데이터를 변환(Lambda 활용)한 후, 지정된 Iceberg 테이블로자동 적재하는 스트리밍 서비스입니다.
3.1 IAM Role 생성하기
Firehose는 Kinesis, Lambda, S3 Tables, Glue, Lake Formation등 여러 리소스에 접근해야 하므로, 적절한 IAM Role을 설정해야합니다.
필요한 권한 범위:
- Kinesis: 스트림 데이터 읽기
- Lambda: 변환 함수 호출
- S3: Iceberg 테이블 및 오류 버킷 접근
- Glue: 테이블 조회, 메타데이터 갱신
- Lake Formation: 데이터 접근 권한
보다 자세한 권한 정책은 AWS 공식 문서 에서 확인하실 수 있습니다.
3.2 Resource Link 생성하기
Firehose는 Glue의 기본 Data Catalog(AwsDataCatalog)만 인식할 수 있기 때문에, Iceberg 테이블이 등록된 s3tablescatalog 를 직접 참조할 수 없습니다. 이를 해결하기 위해 Glue에서 Resource Link 를 생성해야 하며 이는 기본 카탈로그에서 Iceberg 테이블로 연결되는 “프록시” 역할을 합니다.
CLI를 이용한 Resource Link 생성
aws glue create-database --region ap-northeast-2
--catalog-id "{accountId}"
--database-input
'{ "Name": "{database_link_name}",
"TargetDatabase": {
"CatalogId": "{accountId}:s3tablescatalog/{s3TableBucketName}",
"DatabaseName": "{databaseName}"
},
"CreateTableDefaultPermissions": []
}'3.3 Resource Link 에 접근 권한 설정하기
Resource Link를 생성한 후, Lake Formation을 통해 Firehose가 해당 테이블에 접근할 수 있도록 권한을 부여해야 합니다. 가장 먼저 웹 콘솔에서 아래와 같은 순서에 따라 권한 설정이 필요합니다. 이 작업은 현재 CLI 로 지원이 되지 않기 때문에 콘솔에서 직접 진행이 필요하며, Firehose 를 생성하기 위해서 반드시 진행이 필요합니다. 만약 아래 설정이 진행이 되지 않을 경우 Firehose 생성 시 아래와 유사한 문제를 마주하게 됩니다.
API response
Role arn:aws:iam::{accountId}:role/{firehoseRoleName} is not authorized to perform: glue:GetTable for the given table or the table does not exist.
권한 부여 위치
Lake Formation 콘솔 > Databases > {Resource Link} > Actions > Grant on Target 메뉴에서 권한을 부여할 수 있습니다.
권한 부여
- Principals: IAM users and roles > Firehose용 Role 선택
- LF-Tags or catalog resources: Named Data Catalog resources 선택
- Catalogs: “{accountId}:s3tablescatalog/{s3TableBucketName}”
- Databases: “{databaseName}” // !중요: Resource Link 가 아닌 Database 이름이 들어가야 한다.
- Tables: All tables
- Table permissions: Super
Resource Link Database 권한 부여
aws lakeformation grant-permissions
--region ap-northeast-2 \\
--principal DataLakePrincipalIdentifier=arn:aws:iam::{accountId}:role/myFirehoseRole
--permissions ALL
--resource '{
"Database": {
"CatalogId": "{accountId}",
"Name": "{DatabaseName}"
}
}'Resource Link Table 전체에 대한 권한 부여
aws lakeformation grant-permissions
--region ap-northeast-2
--principal DataLakePrincipalIdentifier=arn:aws:iam::{accountId}:role/myFirehoseRole
--permissions ALL
--resource '{
"Table": {
"CatalogId": "{accountId}",
"DatabaseName": "{DatabaseName}",
"TableWildcard": {}
}
}'만약 특정 사용자의 Resource Link 에 대한 권한을 설정하고 싶다면 같은 방식으로 계정에 권한을 부여할 수도 있습니다.
aws lakeformation grant-permissions
--region ap-northeast-2
--principal DataLakePrincipalIdentifier=arn:aws:iam::{accountId}:user/jwkim
--permissions ALL
--resource '{
"Database": {
"CatalogId": "{accountId}",
"Name": "{DatabaseResourceLinkName}"
}
}'3.4 Firehose Transform Lambda 생성하기
Firehose는 데이터를 목적지로 전송하기 전에 Lambda 함수를 통해 레코드를 실시간으로 변환할 수 있습니다. DynamoDB → Iceberg 파이프라인에서는 DynamoDB Streams 이벤트의 구조가 Iceberg 테이블 스키마와 다르기 때문에, 이 변환 단계가 필수적입니다.
DynamoDB Stream 소스 예제
{'awsRegion': 'ap-northeast-2',
'eventID': 'd4148913-9d10-4691-9905-ed9eaba6f43f',
'eventName': 'INSERT',
'userIdentity': None,
'recordFormat': 'application/json',
'tableName': 'gameplay',
'dynamodb': {
'ApproximateCreationDateTime': 1743120918417567,
'Keys': {
'user_id': {'S': '1'},
'game_id': {'S': '1'}},
'NewImage': {
'user_id': {'S': '1'},
'game_id': {'S': '1'},
'score': {'S': '100'}
},
'SizeBytes': 32,
'ApproximateCreationDateTimePrecision': 'MICROSECOND'
},
'eventSource': 'aws:dynamodb'
}Iceberg 목적지 예제
{'records': [
{'data': b'eyJ1c2VyX2lkIjogIjEiLCAiZ2FtZV9pZCI6ICIxIn0=',
'recordId': 'shardId-00000000000300000000000000000000000000000000000000000000000000000000000000000000000049661709324447514016663698551304525667259007084875743282000000000000',
'result': 'Ok',
'metadata': {
'otfMetadata': {
'destinationDatabaseName': 'game_link',
'destinationTableName': 'gameplay',
'operation': 'insert'
}
}
]
}사용 목적
Transform Lambda는 다음과 같은 작업을 수행합니다.
- DynamoDB Streams 이벤트에서 필요한 필드(NewImage 또는 OldImage)만 추출
- DynamoDB JSON 포맷을 일반 JSON으로 변환
- Iceberg 테이블에 맞는 데이터 구조로 정제
- Firehose가 요구하는 Base64 인코딩 포맷으로 변환
- destinationDatabaseName, destinationTableName, operation 등의 메타데이터 삽입
주요 처리 흐름
다음은 핵심 처리 로직을 단계별로 설명한 예제입니다.
def convert_operation(op):
return {
'INSERT': 'insert',
'MODIFY': 'update',
'REMOVE': 'delete'
}.get(op, op)DynamoDB의 이벤트 유형을 Iceberg 쿼리용 표현으로 매핑합니다.
def remove_json_datatype(dynamodb_json):
return {k: list(v.values())[0] for k, v in dynamodb_json.items()}전체 람다 코드 예시
def handler(event, context):
output = { "records": [] }
for record in event["records"]:
try:
raw_payload = base64.b64decode(record["data"]).decode("utf-8")
parsed = json.loads(raw_payload)
event_name = parsed.get("eventName")
operation = convert_operation(event_name)
if operation not in ("insert", "update", "delete"):
continue
image = (
parsed['dynamodb'].get('NewImage')
if operation in ('insert', 'update')
else parsed['dynamodb'].get('OldImage')
)
if not image:
Logger.w(f"[WARN] Missing image for operation={operation}, skipping recordId={record['recordId']}")
continue주의할 점
- destinationDatabaseName은 반드시 Resource Link로 생성된 DB 이름을 사용해야 합니다.
- JSON 구조에서 “NewImage” 또는 “OldImage”가 없을 수 있으므로 예외 처리 중요합니다.
- 결과가 누락되면 Firehose가 전체 배치를 실패로 간주할 수 있으므로 fallback도 고려해야 합니다.
3.5 Firehose 생성하기
앞에서 구성한 Kinesis Data Stream, 변환 Lambda, Glue 테이블, S3 Table Bucket, 그리고 IAM Role이 준비되었다면, 이제 Amazon Data Firehose를 생성해 실시간으로 Iceberg 테이블에 데이터를 적재할 수 있습니다. 이번 단계에서는 콘솔을 통해 Firehose를 생성하는 절차를 정리합니다.
콘솔 접속
- Amazon Data Firehose 콘솔로 이동
- Create Firehose stream 클릭
Source & Destination 설정
- Source: Amazon Kinesis Data Streams
- Stream name: ddb-sms-stream (사전에 만든 Kinesis 스트림)
- Destination: Apache Iceberg tables
- Region: ap-northeast-2
Transform records 설정
- Transform with Lambda function 체크
- Lambda: ddbSmsFirehoseTransformFunction (변환용 Lambda 선택)
- Buffer interval: 5 seconds (필요에 따라 조정 가능)
Unique key configuration 설정
[
{
"DestinationDatabaseName": "{ResourceLinkName}",
"DestinationTableName": "{TableName}",
"UniqueKeys": ["UniqueKey"],
}
]- DestinationDatabaseName: S3TablesCatalog에 대한 리소스 링크 DB 이름이어야 합니다. 원본 Glue Database 이름을 넣을 경우 Firehose는 해당 테이블을 찾지 못하고 glue:GetTable 에러가 발생합니다.
Permissions
- IAM Role: myFirehoseRole
- 오류 버킷을 따로 지정하고 싶다면 S3 error bucket 추가
생성
- 모든 설정이 완료되면 Create delivery stream 클릭
단계 4: 데이터 파이프라인 검증하기
모든 구성 요소를 연결했다면, 이제 실시간으로 생성된 데이터가 Iceberg 기반 S3 Tables에 정확히 적재되고 있는지를 검증해야 합니다. 이 검증 단계는 단순한 데이터 적재 여부 확인을 넘어, 정합성, 스키마 일치 여부, 파티셔닝, 그리고 운영 중 에러 대응까지 포함됩니다.
이 장에서는 아래 4단계에 걸쳐 전체 파이프라인을 검증합니다.
- 테스트 데이터 입력
- 데이터 적재 및 변환 확인
- 컬럼 스키마 및 파티셔닝 확인
- 예외 및 실패 대응 시나리오 점검
4.1 테스트 데이터 입력
가장 먼저, DynamoDB 테이블에 샘플 데이터를 삽입하거나 수정/삭제 작업을 수행합니다. DynamoDB Streams가 활성화되어 있고 Kinesis Data Stream과 연결되어 있다면, 해당 이벤트는 자동으로 스트림을 통해 전파됩니다.
AWS CLI 사용 예시
aws dynamodb put-item
--table-name messaging_sms_group_detail
--item file://sample_item.jsonJSON 예시
{
"pk": {"S": "group#20240421"},
"sk": {"S": "meta"},
"messages_count": {"N": "12"},
"total_point": {"N": "104.5"},
"user_id": {"N": "1234"},
"updated_at": {"S": "2025-04-21T09:00:00Z"},
"__en": {"S": "group_detail"}
}4.2 데이터 적재 및 변환 확인
데이터가 입력되면 Lambda에서 해당 이벤트를 처리하고, 변환 결과가 CloudWatch 로그에 출력됩니다. 이 로그를 통해 변환 성공 여부와 데이터 포맷을 확인할 수 있습니다.
람다 응답 값 예시
{
"recordId": "...",
"result": "Ok",
"data": "base64Encoded",
"metadata": {
"otfMetadata": {
"destinationDatabaseName": "sample_db_link",
"destinationTableName": "sample_table",
"operation": "insert"
}
}
}또한 Athena 쿼리를 통해 테이블에 데이터가 정상적으로 적재되었는지도 확인합니다.
Athena Query 예시
SELECT * FROM sample_db_link.sample_table
LIMIT 10;4.3 컬럼 스키마 및 파티셔닝 확인
데이터가 조회되었다면, 다음 항목들도 반드시 함께 확인해보는 것이 좋습니다.
- 컬럼 매핑: DynamoDB → Iceberg로 컬럼명이 일관성 있게 매핑되었는가?
- 예: updatedAt → updated_at, totalPoint → total_point
- 데이터 타입: 숫자형, 실수형, boolean 등의 타입이 올바르게 변환되었는가?
4.4 예외 및 실패 대응 시나리오 점검
실제 운영 환경에서는 모든 이벤트가 항상 성공적으로 처리되지는 않습니다. 따라서 테스트 데이터 외에도 다음과 같은 실패 시나리오에 대해서도 사전 점검을 해두는 것이 중요합니다.
- Lambda 내 JSON 파싱 실패 (예: NewImage가 없음, schema mismatch)
- Firehose가 Iceberg 테이블을 찾지 못하는 경우 (glue:GetTable 오류)
- Iceberg 테이블에 없는 컬럼이 들어오는 경우 → Athena 쿼리 실패 가능성
- TTL이나 날짜 타입이 잘못 들어와 파티션 쿼리 누락되는 문제
- 중복 데이터 적재 → UniqueKey 설정이 잘 작동하는지 확인
이러한 상황에서는 CloudWatch Logs와 Athena 오류 메시지를 함께 분석하여 원인을 파악해야 하며, 필요시 Transform Lambda에서예외 처리 로직을 추가하는 것이 좋습니다.
마무리
알리는 사람들의 데이터 분석 파이프라인 구축 프로젝트에서는 2024 AWS re:Invent에서 소개된 Amazon S3 Tables 기능을 활용해, DynamoDB의 실시간 스트림 데이터를Apache Iceberg 기반의 S3 테이블로 적재하고, 이를 Athena에서 직접 분석 가능한 구조로 전환하는 파이프라인을 구축했습니다. 이 파이프라인은 전통적인 ETL 기반의 처리 흐름을 벗어나, 이벤트 기반의 실시간 데이터가 곧바로 분석 가능한 테이블 형태로 전환되는 구조를 구현했다는 점에서 의미가 있습니다. 센드온은 이를 기반으로, 운영 데이터와 분석 환경 사이의 간극을 줄이고, 지속적으로 갱신되는 분석 데이터 레이크로 확장해 나가고자 합니다.
향후에는 다음과 같은 방향으로 파이프라인을 확장하고자 합니다.
멀티 테이블 대응
- 다양한 DynamoDB 테이블을 동일한 스트리밍 구조로 연동하여, 분석 범위 확장
지표 분석 자동화
- Athena 쿼리 결과를 기반으로 주요 지표를 산출하고, 이벤트 기반 알림 또는 리포팅 자동화
대시보드 연동
- QuickSight와 같은 시각화 도구를 통해, 실시간 KPI 모니터링 및 대시보드 구성
이로써, 실시간 운영 데이터를 Iceberg 기반으로 통합·분석하는 데이터 레이크의 기반을 마련하게 되었습니다. 이 구조는 센드온의 데이터 기반 의사결정을 가속화하고, 더 나은 메시징 서비스를 제공하는 기반이 될 것입니다.
참고 자료
- https://aws.amazon.com/ko/blogs/storage/build-a-data-lake-for-streaming-data-with-amazon-s3-tables-and-amazon-data-firehose/
- https://aws.amazon.com/ko/blogs/tech/data-firehose-iceberg/
- https://aws.amazon.com/ko/blogs/korea/replicate-changes-from-databases-to-apache-iceberg-tables-using-amazon-data-firehose/
- https://docs.aws.amazon.com/AmazonS3/latest/userguide/s3-tables-integrating-aws.html
- https://docs.aws.amazon.com/AmazonS3/latest/userguide/s3-tables-integrating-firehose.html