AWS 기술 블로그
Amazon Bedrock을 이용한 지능형 쇼핑 어시스턴트 구현하기
배경
생성형 AI가 공개된 이후로 쇼핑 경험 전환에 사용하려는 시도가 다양하게 있었습니다. 이제 단순히 상품을 검색하고 구매하는 경험을 넘어 탐색형 쇼핑으로 나아가는 과도기라고 할 수 있습니다. AI 검색을 지향하는 Perplexity에서 2024년 11월에 쇼핑 어시스턴트 기능을 출시하기도 했으며 Amazon.com에서는 Rufus를 출시했습니다. Amazon Rufus는 생성형 AI 기반 쇼핑 어시스턴트로, 고객이 상품을 검색하고, 비교하고, 추천을 받고, 구매 결정을 내리는 데 도움을 주는 솔루션입니다.
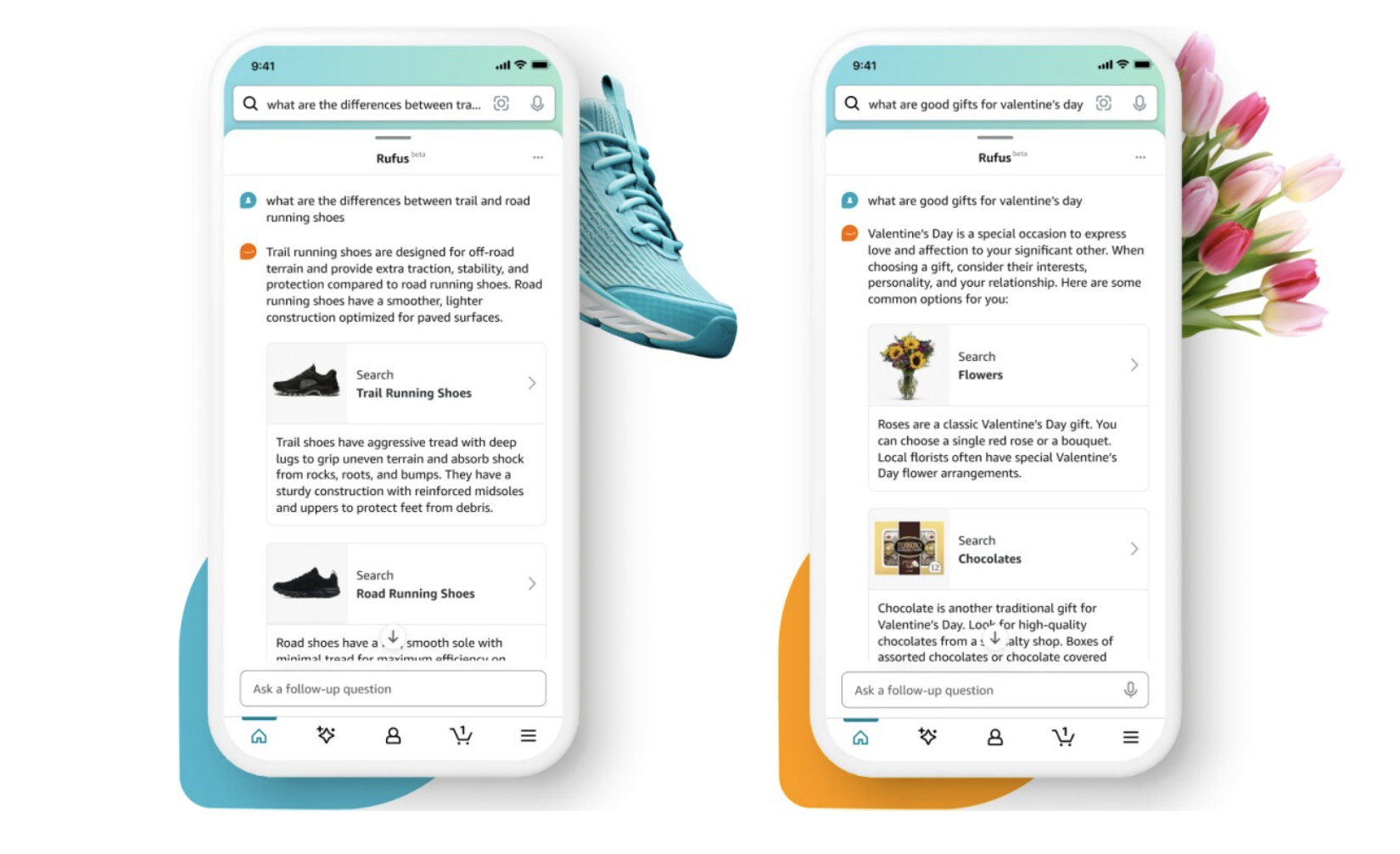
Rufus는 무엇보다 속도에 최적화 되어있습니다. 이를 위해 전용 LLM을 개발하였고, Amazon의 Trainium과 Inferencia2, 그리고 Neuron SDK를 이용해 지연 시간을 최소화하면서 처리량을 극대화했습니다.
Rufus는 질문의 성격에 따라 다양한 형식의 답변을 제공하도록 설계되었습니다. 복잡한 상품 비교나 구매 가이드가 필요한 경우에는 상세한 설명을 제공하고, 간단한 문의에는 명확하고 간결한 답변을 제시하며, 상품 탐색이 필요한 상황에서는 클릭 가능한 링크와 네비게이션 요소를 활용합니다. 특히 고급 스트리밍 아키텍처를 통해 토큰 단위로 실시간 응답을 제공하여, 고객이 긴 답변이 완전히 생성될 때까지 기다릴 필요 없이 첫 번째 부분부터 바로 확인할 수 있습니다. 더 나아가 단순히 텍스트만 표시하는 데에 그치지 않고 실제 클릭할 수 있는 상품 링크와, 다음 검색 추천 등 클릭할 수 있는 박스와 같은 출력들을 제공합니다.
위 내용은 다양한 AWS 블로그에서 실제 확인해볼 수 있는 정보입니다. 그런데 이러한 블로그를 보는 입장에서, Rufus와 같은 것을 만들기 위해서 전용 LLM 개발을 꼭 해야 하는지 그것을 하지 않고는 빠른 응답 시간을 가질 수 없는지에 대한 고민이 생깁니다.
문제 해결 솔루션
이 블로그에서는 Amazon Bedrock을 활용하여 Rufus와 같은 지능형 쇼핑 어시스턴트를 구현하는 포괄적인 솔루션을 제시합니다.
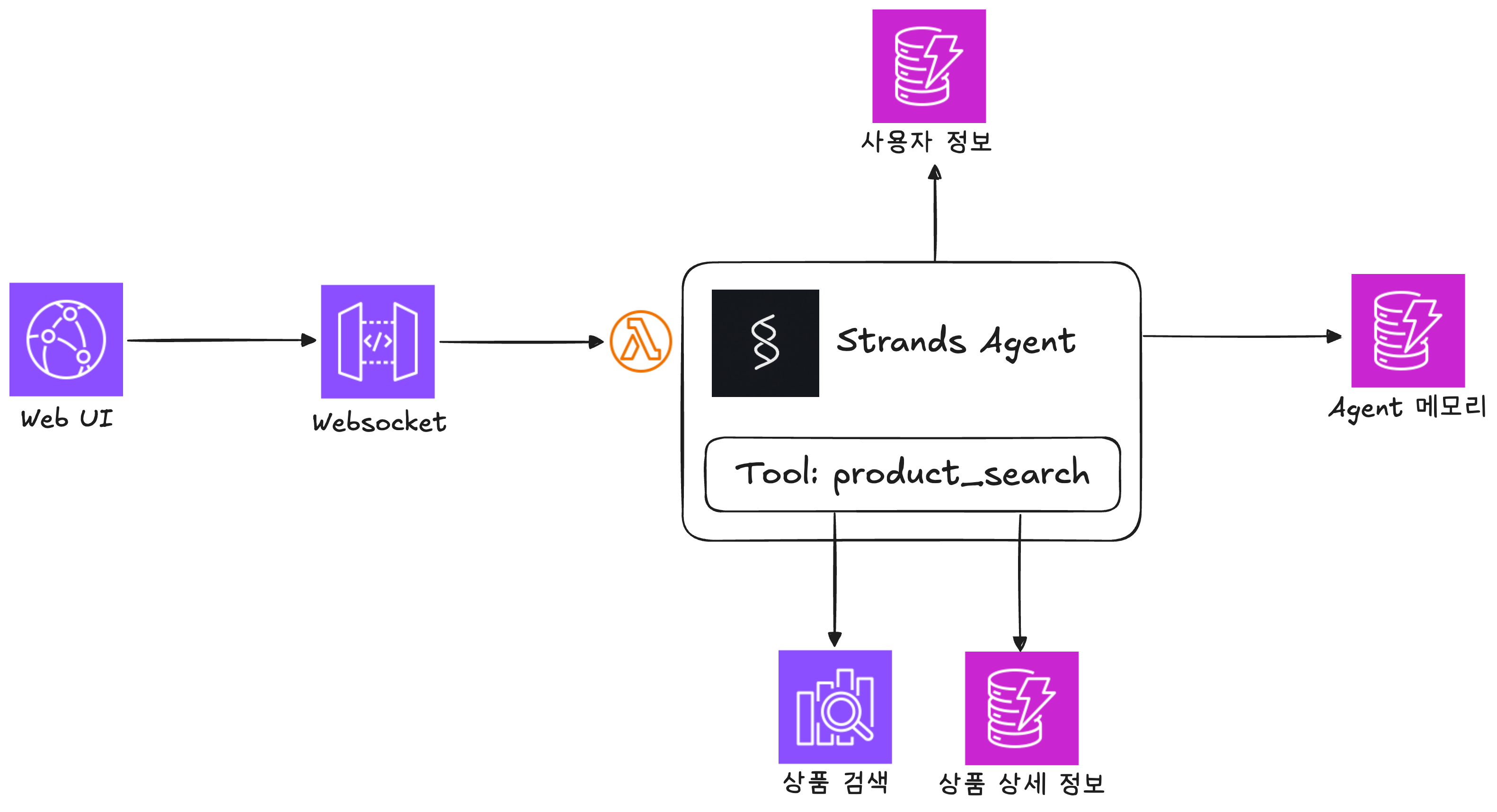
솔루션 구성 요소
이번 데모에서는 다음과 같은 AWS 서비스들을 활용하여 Rufus와 같은 쇼핑 어시스턴트를 구현했습니다:
- Amazon Bedrock
- 생성형 AI의 핵심 엔진으로 필요에 따라 다른 모델을 활용
- 사용자 질문 의도 파악, 상품 검색 쿼리 생성, 자연어 응답 생성을 담당
- 스트리밍 응답을 통해 실시간으로 답변 제공
- Amazon DynamoDB
- 고객의 주문 이력, 상품 리뷰, 사용자 프로필 정보 저장
- 대화 히스토리와 세션 관리
- Amazon OpenSearch Service
- 상품 카탈로그 검색
- Amazon API Gateway
- WebSocket을 통한 실시간 스트리밍 통신 지원
- Strands Agent
- 코드로 에이전트를 구현할 수 있는 오픈소스 SDK
데이터 위치에 따른 유연한 구성
위 구성은 하나의 예시일 뿐이며, 실제 환경에서는 데이터가 위치한 곳에 따라 유연하게 구성할 수 있습니다. 중요한 것은 각 데이터 소스에 API를 통해 접근할 수 있다면 동일한 방식으로 쇼핑 어시스턴트를 구축할 수 있다는 점입니다. 예를 들어보겠습니다.
- 상품 데이터: Elasticsearch, Solr, 또는 기존 상품 관리 시스템의 REST API
- 주문 데이터: 기존 ERP 시스템, MySQL, PostgreSQL 등의 관계형 데이터베이스
- 고객 데이터: CRM 시스템, 고객 데이터 플랫폼(CDP), 또는 온프레미스 데이터베이스
- 리뷰 데이터: 리뷰 관리 시스템, MongoDB, 또는 외부 리뷰 플랫폼 API
핵심은 이러한 다양한 데이터 소스들을 Lambda 함수 내에서 각각의 API를 호출하여 통합하고, Amazon Bedrock을 통해 자연어로 처리하는 것입니다. 이 접근 방식을 통해 기존 시스템을 그대로 활용하면서도 최신 생성형 AI 기술을 적용한 쇼핑 어시스턴트를 구축할 수 있습니다. 데이터의 위치나 저장 방식에 관계없이 API 접근이 가능하다면, 이번 블로그에서 제시한 워크플로우와 최적화 기법들을 그대로 적용할 수 있습니다.
생성형 AI의 응답 속도를 빠르게 하는 방법론
챗봇의 핵심적인 요구사항 중 하나는 빠른 응답시간입니다. 만약 쇼핑 어시스턴트 챗봇을 이용하는데 최근 주문 내역 조회까지 10초가 넘게 걸리고 상품을 검색하고 추천받는데 30초가 넘게 걸린다면 사용자의 만족도가 매우 떨어질 가능성이 높습니다. 이번 단계에서는 챗봇의 응답시간을 빠르게 할 수 있는 다양한 방법론을 소개합니다.
생성형 AI의 응답시간 이해하기
보다 빠른 응답속도를 구현하기 위해서는 생성형 AI의 응답시간을 이해하는 것이 중요합니다. 생성형 AI에서는 크게 두 가지의 응답시간이 있습니다.
- Time To First Token (TTFT): 입력을 전송하고 응답을 첫 토큰이 나오기까지 걸리는 시간
- Tokens Per Second * Tokens generated (TPS): 초당 생성하는 토큰의 수 * 생성한 토큰의 수
챗봇은 일반적으로 스트리밍으로 구현하기 때문에 TTFT가 중요합니다. 첫 토큰이 느리게 나올수록 사용자가 이탈할 가능성이 높아지고 답답함을 느낍니다. 입력 토큰의 수가 많아지면 TTFT가 증가하지만 늘어나는 정도는 크지 않습니다. 모델에 따라 다르지만 일반적으로 1초에서 길면 3초 정도 소요됩니다. TPS도 마찬가지로 모델에 따라 다르고 TTFT와 다르게 토큰 길이에 따라 변동은 없습니다.
챗봇을 구현할 때 응답을 빠르게 주기 위해서는 두 가지를 할 수 있습니다. 첫 번째로 TTFT 자체는 줄이지 못하지만 호출 횟수를 줄임으로써 발생 빈도를 낮출 수 있습니다. 두 번째로는 출력 토큰의 숫자를 줄이는 것인데, 사용자에게 스트리밍되고 있는 토큰을 줄이는 것도 전체 답변의 길이를 고려했을 때 중요하지만 사용자에게 보이지 않는 토큰의 숫자를 줄이는 것이 핵심입니다.
Tool 효율적으로 사용하기
쇼핑 어시스턴트를 구현할 때 상품 검색과 같은 일을 수행하기 위해서 LLM의 tool 사용은 필수적입니다. 일반적으로 tool을 만들 때 코드의 함수를 짜듯이 단위별로 구현하는 것을 생각합니다. 예를 들면 상품 검색 tool, 상품 상세 정보 tool을 각각 만들어 필요할 때 활용하도록 할 수 있습니다.
하지만 tool 사용에 따르는 지연 시간을 생각해보면 이는 응답 속도 측면에서 고려했을 때 비효율적일 수 있습니다. LLM이 tool을 사용할 때에는 응답이 중단되고 tool을 실행한 후 결과를 다시 LLM을 호출합니다. 이는 매번 TTFT 지연을 발생시킵니다.
핵심 원칙: 선택적 Tool 사용
따라서 다음과 같은 전략을 사용하는 것이 좋습니다:
- 정말 필요한 경우에만 tool을 사용
- 코드로 처리 가능한 부분은 코드로 직접 처리
- 컨텍스트 재사용을 통해 중복 호출 방지
실제 예시: 쇼핑 어시스턴트 시나리오
다음과 같은 도구들이 있다고 가정해보겠습니다:
- 상품 검색 도구: 키워드로 상품 카탈로그 검색
- 상품 조회 도구: 상품 ID로 상세 정보 조회
대화 시나리오:
- 첫 번째 턴: 고객이 “의자”를 검색
- 두 번째 턴: 고객이 특정 의자의 리뷰 정보 요청
비효율적인 접근법
첫 번째 턴에서 상품을 검색하고, 이어서 두 번째 턴에서 해당 상품의 리뷰 정보를 요청하는 일반적인 대화 시나리오를 살펴보겠습니다.
효율적인 접근법
비효율적인 접근법에서 발생할 수 있는 여러 번의 LLM 호출과 Tool 사용 지연을 줄이기 위해, 다음과 같이 효율적인 접근법을 적용할 수 있습니다.
핵심은 한번 Tool을 사용할 때 최대한 많은 정보를 대화 맥락에 넣어두는 것 입니다.
검색과 리뷰 조회를 통합했을 때의 또 다른 장점은 첫 답변 생성에서도 이미 사용자에게 리뷰 관련된 내용을 안내할 수 있다는 점입니다. 더 풍부한 답변을 제공함으로 이어질 수 있었던 턴 자체가 필요 없어질 수도 있습니다.
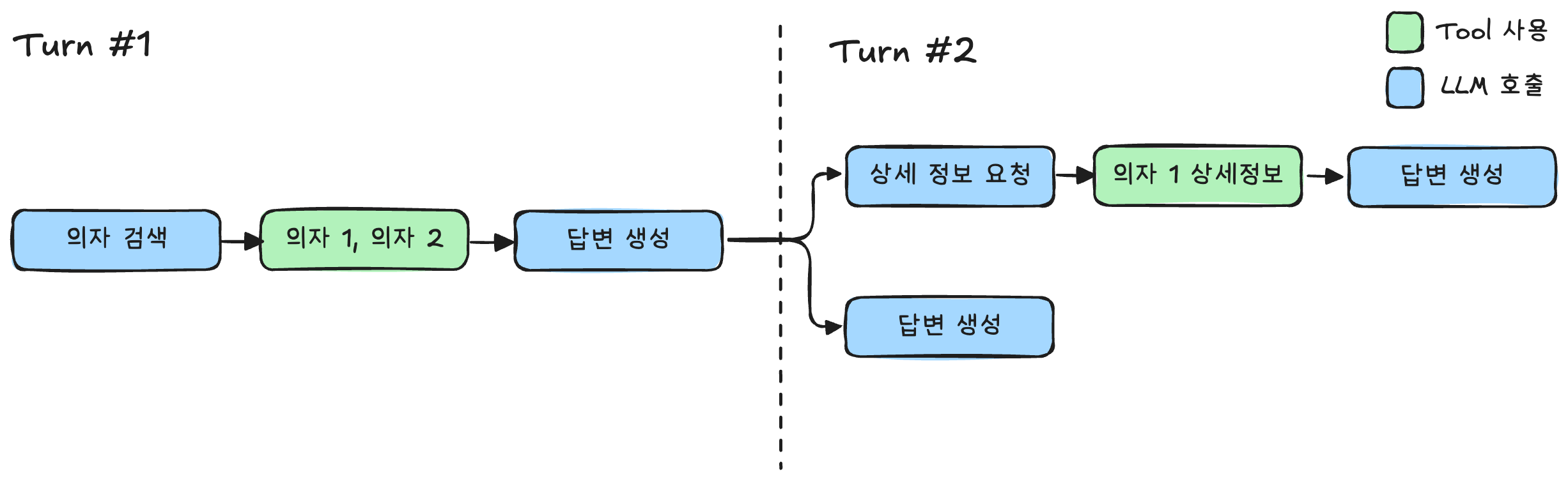
실제로 위 시나리오에서 응답시간이 얼만큼 단축되는지 확인하기 위해 가상의 tool을 만들어서 응답 시간을 측정해보겠습니다.
# 상품 검색 결과를 반환하는 가상 tool
@tool
def keyword_product_search(query_keywords: str) -> list:
"""
Search for products by keywords.
Args:
query_keywords: str
Returns:
List[dict]
"""
return [
{
"_index": "products",
"_type": "_doc",
"_id": "tshirt_001",
"_score": 9.123456,
"_source": {
"id": "tshirt_001",
"image_url": "https://cdn.example.com/images/organic-cotton-basic-tee-white.jpg",
"name": "Patagonia Organic Cotton Basic T-Shirt",
"description": "Sustainably made organic cotton t-shirt in classic fit, perfect for casual wear and everyday comfort",
"price": 35.00,
"gender_affinity": "unisex",
"current_stock": 78
}
},
{
"_index": "products",
"_type": "_doc",
"_id": "tshirt_002",
"_score": 8.789123,
"_source": {
"id": "tshirt_002",
"image_url": "https://cdn.example.com/images/vintage-band-tee-rolling-stones.jpg",
"name": "Vintage Rolling Stones Concert T-Shirt",
"description": "Authentic vintage-style band t-shirt with distressed print and soft cotton blend fabric",
"price": 28.99,
"gender_affinity": "unisex",
"current_stock": 42
}
},
...
# 상품 리뷰를 가져오는 가상 tool
@tool
def get_product_reviews(product_ids: List[str]) -> List[dict]:
"""
Get product reviews by product IDs.
Args:
product_ids: List[str]
Returns:
List[dict]
"""
return [
{
"product_id": "tshirt_001",
"avg_rating": 4.3,
"positive_keywords": ["soft fabric", "sustainable", "good fit", "breathable", "eco-friendly", "comfortable", "classic style", "well-made", "organic cotton"],
"negative_keywords": ["shrinks after washing", "thin material", "fades quickly", "overpriced for basic tee", "wrinkles easily"],
"review_summary": "Customers appreciate the soft, breathable organic cotton fabric and the sustainable manufacturing process. The classic fit works well for most body types and the shirt is comfortable for both casual wear and outdoor activities. However, several reviews mention significant shrinkage after the first wash and some color fading over time. A few customers feel the price is too high for what they consider a basic t-shirt, despite the organic materials."
},
{
"product_id": "tshirt_002",
"avg_rating": 4.1,
"positive_keywords": ["authentic vintage look", "soft cotton", "cool design", "comfortable fit", "nostalgic", "unique style", "good quality print"],
"negative_keywords": ["expensive for vintage style", "print cracks over time", "sizing runs large", "thin fabric", "fades after washing"],
"review_summary": "Music fans love the authentic vintage aesthetic and nostalgic appeal of this Rolling Stones t-shirt. The soft cotton blend feels comfortable and the distressed print looks genuinely vintage. Many appreciate the unique style and conversation-starting design. However, customers report that the print begins to crack and fade after several washes. Some find the sizing runs larger than expected, and a few think the price is steep for what's essentially a reproduction vintage tee."
},
...# 상품 검색 Agent
search_agent_prompt = """You are a product catalog search agent that finds relevant products using keyword-based search.
CORE BEHAVIOR:
- Use keyword_product_search for text-based product searches
- Use get_product_reviews to get product reviews
- Extract the most relevant keywords from user queries for keyword searches
FUNCTION SELECTION:
- Use keyword_product_search for general product searches based on categories or descriptions
- Use get_product_reviews to get product reviews
KEYWORD EXTRACTION:
- Match user queries to available product keywords
- Use specific product types when mentioned (jacket, sneaker, camera, etc.)
- For broad queries, use general categories (apparel, electronics, furniture, etc.)
- Combine related keywords when appropriate
AVAILABLE KEYWORDS:
t-shirt, jacket, sneakers
RESPONSE FORMAT:
- Product Name
- Product Description
- Product Price
Do not include any other text in your response."""
search_agent = Agent(
system_prompt=search_agent_prompt,
tools=[keyword_product_search, get_product_reviews],
model=BedrockModel(
model_id=BedrockModelId.AMAZON_NOVA_PRO.value,
)
)
search_agent("Find me 5 t-shirts with the highest reviews")# 상품을 검색하고 리뷰까지 가져오는 tool
@tool
def search_products_with_reviews(query: str) -> list:
search_results = keyword_product_search(query)
reviews_data = get_product_reviews(search_results)
reviews_lookup = {review["product_id"]: review for review in reviews_data}
# Join data
joined_results = []
for hit in search_results:
# Start with product data
joined_item = hit["_source"].copy()
joined_item["search_score"] = hit["_score"]
# Add review data if available
product_id = hit["_source"]["id"]
if product_id in reviews_lookup:
review = reviews_lookup[product_id]
joined_item.update({
"avg_rating": review["avg_rating"],
"positive_keywords": review["positive_keywords"],
"negative_keywords": review["negative_keywords"],
"review_summary": review["review_summary"]
})
else:
# Handle missing reviews
joined_item.update({
"avg_rating": None,
"positive_keywords": [],
"negative_keywords": [],
"review_summary": None
})
joined_results.append(joined_item)
return joined_results
tool_aware_agent=Agent(
system_prompt=search_agent_prompt,
tools=[search_products_with_reviews],
model=BedrockModel(
model_id=BedrockModelId.AMAZON_NOVA_PRO.value,
)
)
tool_aware_agent("Find me 5 t-shirts with the highest reviews")각 Agent에게 가장 높은 리뷰 점수를 가진 5개의 티셔츠를 찾아달라고 하면 첫번째 에이전트의 경우 2번의 tool 호출을 통해 결과를 생성하고 두 번째 에이전트는 1번의 tool 호출을 통해 결과를 생성합니다. 자세한 실행 결과를 확인해보면 아래와 같습니다.
| 방식 | 총 응답 시간 | 토큰 사용량 | Tool 호출 |
|---|---|---|---|
| 일반적인 Tool | 17.4초 | 9,083 | 2회 |
| 효율적인 Tool | 13.4초 | 5,473 | 1회 |
이처럼 효율적인 tool 설계를 통해 응답시간을 줄일 수 있다는 것을 알아봤습니다.
가용한 context는 미리 준비하기
사용자가 쇼핑몰에 로그인하는 순간, 시스템은 단순히 사용자를 시별하는 것을 넘어 과거 구매 이력, 선호 상품, 개인 설정 등 다양한 정보를 불러옵니다. 이처럼 이미 확보된 사용자 데이터를 활용하여 어시스턴트가 사용자의 잠재적인 문의에 대한 답변을 미리 준비하도록 할 수 있습니다. 예를 들어 사용자가 최근 주문 내역 조회와 같은 문의를 하기 전에 미리 데이터를 불러와 준비해둘 수 있습니다.
이 방법은 다음과 같은 원리로 응답 속도를 최적화할 수 있습니다.
- 사용자가 로그인하면 채팅 시작 전에 주문 내역을 미리 조회
- 이 정보를 system prompt나 messages에 포함
- 사용자가 주문 내역을 요청하면 tool 호출 없이 즉시 응답
트레이드오프:
- 응답 속도 향상
- 입력 토큰 수 증가
- 사용하지 않을 수도 있는 정보 포함
입력 토큰 수가 늘어나고 사용하지 않을 수도 있는 정보를 컨텍스트에 포함하는 것과 같은 단점에도 불구하고 context를 미리 준비하는 것은 응답 속도를 비약적으로 빠르게 할 수 있습니다. 아래에서 에이전트가 tool을 이용해 조회하는 것과 데이터를 미리 준비하는 것의 응답 속도를 비교해보겠습니다.
Tool을 이용하는 경우
# 에이전트 예시 prompt
agent_prompt = """You are a customer service agent that manages user accounts and order data through DynamoDB tables.
CORE BEHAVIOR:
- Always use the appropriate function based on the user's request
Available actions:
- get_orders_with_user_id: get the orders for a user
- get_user_info: get the user's information
ERROR HANDLING:
- If user data not found, explain clearly and offer alternatives
- For failed updates, provide guidance on correct format or requirements
- If orders are empty, inform user appropriately
RESPONSE FORMAT:
For orders:
Order Number: 123
Order Date: 2025-01-01
Order Status: Delivered
For user info:
User ID: 123
User Name: John Doe
User Email: john.doe@example.com
User Address: 123 Main St, Anytown, USA, 12345
Do NOT include any other text or XML tags like <thinking>."""# 사용자 ID를 이용해 구매 내역을 불러오는 tool
@tool
def get_orders_with_user_id(user_id: str) -> dict:
"""
Get the orders for a user.
"""
table_name = "OrdersTable"
dynamodb = boto3.resource('dynamodb', region_name='us-west-2')
table = dynamodb.Table(table_name)
# Query the table for orders with the given user_id
try:
response = table.query(
IndexName='UserStatusIndex',
KeyConditionExpression=Key('user_id').eq(int(user_id))
)
orders = response.get('Items', [])
# Format orders for response
formatted_orders = []
for order in orders:
formatted_order = {
"order_id": order.get('order_id'),
"timestamp": order.get('timestamp'),
"item_id": order.get('item_id'),
"delivery_status": order.get('delivery_status')
}
formatted_orders.append(formatted_order)
return {
"messageVersion": "1.0",
"response": {
"orders": formatted_orders
}
}
except Exception as e:
error_msg = f"Error getting orders: {str(e)}"
return {
"messageVersion": "1.0",
"response": {
"error": error_msg
}
}%%timeit
customer_agent = Agent(
system_prompt=agent_prompt,
tools=[get_orders_with_user_id, get_user_info],
model=BedrockModel(
model_id=BedrockModelId.AMAZON_NOVA_PRO.value,
),
callback_handler=None
)
response = customer_agent("이 사용자의 최근 주문 내역 10개 알려줘 UserID: 15")컨텍스트에 미리 포함하는 경우
frontloaded_agent_prompt = f"""You are a customer service agent that manages user accounts and order data through DynamoDB tables.
ERROR HANDLING:
- If user data not found, explain clearly and offer alternatives
- For failed updates, provide guidance on correct format or requirements
- If orders are empty, inform user appropriately
RESPONSE FORMAT:
For orders:
Order Number: 123
Order Date: 2025-01-01
Order Status: Delivered
For user info:
User ID: 123
User Name: John Doe
User Email: john.doe@example.com
User Address: 123 Main St, Anytown, USA, 12345
Do NOT include any other text.
User Info:
{get_user_info("15")}
User Orders:
{get_orders_with_user_id("15")}"""%%timeit
frontloaded_agent = Agent(
system_prompt=frontloaded_agent_prompt,
model=BedrockModel(
model_id=BedrockModelId.AMAZON_NOVA_PRO.value,
),
callback_handler=None
)
frontloaded_response = frontloaded_agent("이 사용자의 가장 최근 주문 내역 10개 알려줘")| 방식 | 총 응답 시간 | 토큰 사용량 | Tool 호출 |
|---|---|---|---|
| Tool 사용 | 7.9초 | 6,078 | 1회 |
| 사전 로딩 | 3.7초 | 4,863 | 0회 |
Tool을 사용하는 경우는 중간에 agent의 reasoning output이 발생하고 tool 호출로 인해 TTFT가 발생합니다. 그에 반해 context에 미리 포함하는 경우에는 reasoning output도 tool 호출도 발생하지 않습니다. 최종적으로 결과를 비교해보면 총 응답 시간이 2배 가까이 차이나는 것을 확인할 수 있습니다.
Prompt caching 활용하기
지금까지 tool 효율적으로 사용하는 방법과 context를 미리 준비하는 방법은 모두 입력 토큰을 증가시킬 수 있다는 단점을 갖고 있습니다. 그 외에도 쇼핑 어시스턴트는 검색과 상품 조회를 많이 사용할수록 대화 히스토리가 급속히 증가합니다.
토큰 증가 요인들
- 대화 내역: 사용자와 어시스턴트의 모든 대화
- 상품 정보: 검색 결과와 상세 정보들
- 시스템 구성: system prompt, tool configuration
- 프로액티브 데이터: 미리 로드된 사용자 정보
Prompt Caching의 필요성
위에서 소개한 “tool 효율적 사용” 기법을 적용하면 컨텍스트에 더 많은 정보를 미리 포함하게 되어 토큰 수가 증가합니다. 이때 prompt caching을 활용하면 아래와 같은 장점을 얻을 수 있습니다.
- 반복적인 컨텍스트 재사용: system prompt, 상품 정보 등
- 비용 절감: 캐시된 토큰에 대한 재처리 비용 감소
- 응답 속도 향상: 캐시 히트 시 더 빠른 처리
결론적으로 prompt caching을 활용하면 급격하게 증가하는 입력 토큰으로 인해 발생할 수 있는 비용 부담을 줄이고 응답 속도까지 향상시키는 두 마리의 토끼를 잡을 수 있습니다.
구현 전략
- 정적 요소 캐싱: system prompt, tool configurations, 사용자 정보
- 동적 요소 관리: 실시간 대화 내용
긴 대화에서 prompt caching을 사용할 때에는 system prompt, tool configuration에 cachepoint를 사용하고 마지막 2개의 user message에 cachepoint를 사용하면 됩니다.
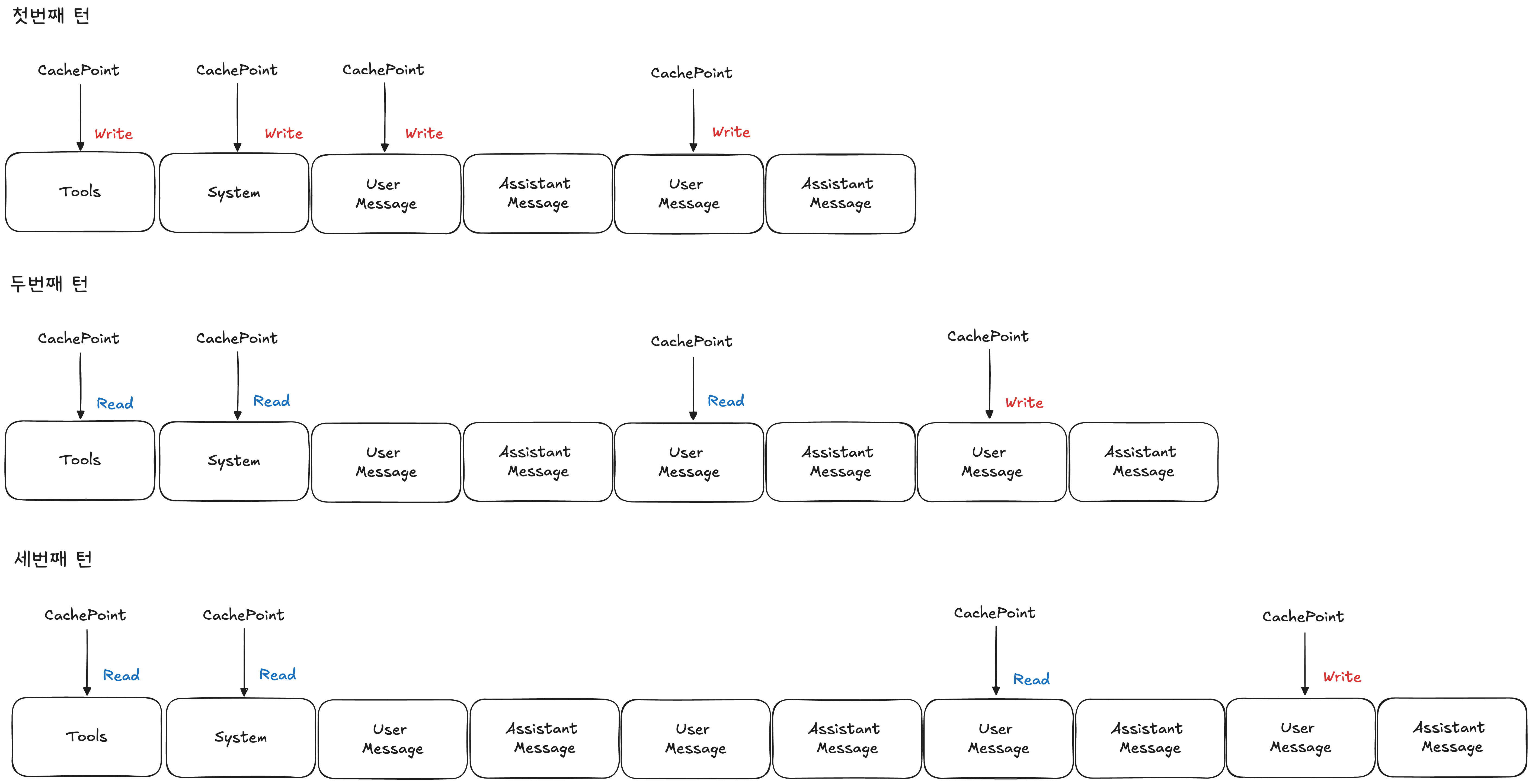
위 그림과 같이 멀티턴 대화에서 prompt caching을 활용할 수 있습니다.
Prompt caching의 효율
실제 테스트를 통해 prompt caching의 효율을 확인해보겠습니다.
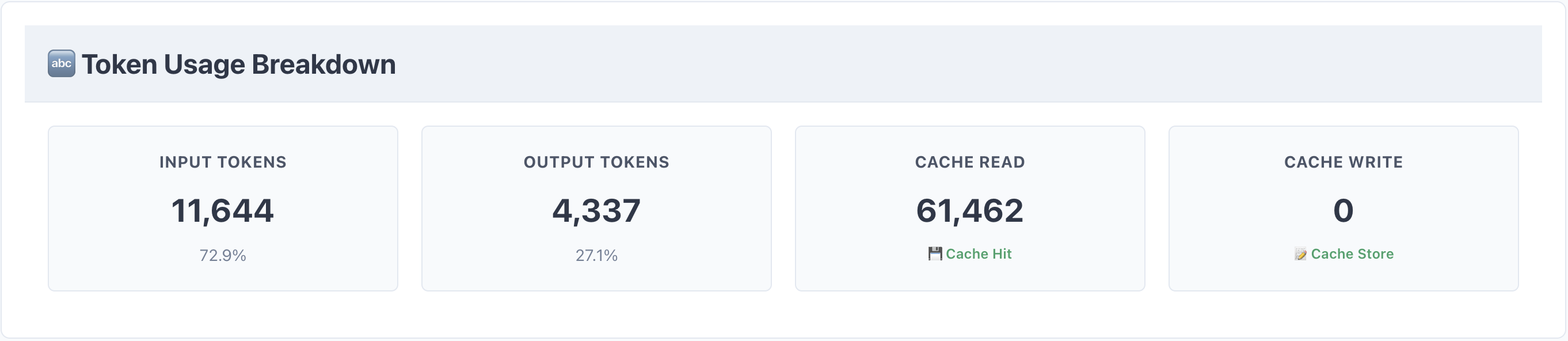
프롬프트 캐싱이 적용된 쇼핑 어시스턴트의 토큰 사용량입니다.
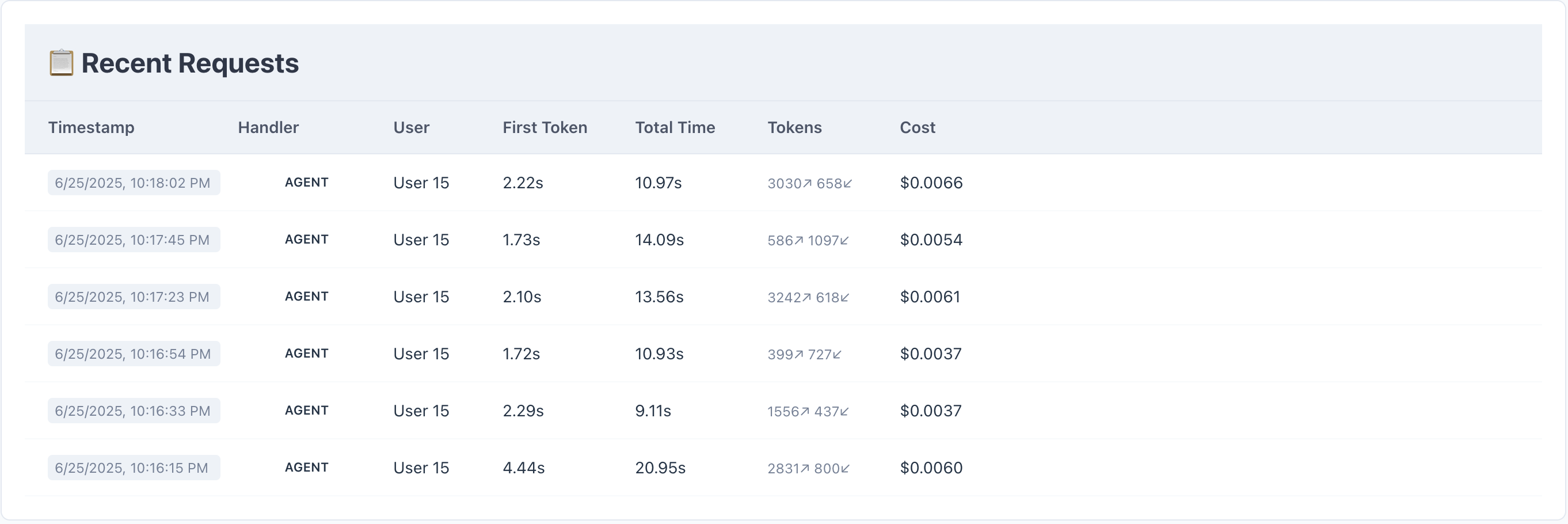
프롬프트 캐싱이 적용되었을때와 되지 않았을 때의 응답속도 차이 또한 볼 수 있습니다. 위 그림에서 가장 아래 메세지가 시스템 프롬프트가 캐싱되지 않았을 때의 데이터로 첫 토큰이 나오기까지 4.44초가 걸린 것을 확인할 수 있습니다. 이후에 cache hit가 되기 시작하면서 첫 토큰이 나오기까지 2초 내외가 걸리는 것을 볼 수 있습니다.
스트리밍 응답 구성
Rufus 처럼 응답 중간에 상품 정보와 같은 정보를 출력하기 위해서는 LLM에서 스트리밍 되는 토큰 구분이 필요합니다. 일반적으로 추론 모델이나 agent framework에서는 <think></think> 와 같은 특수 토큰을 활용하여 추론 토큰과 응답 토큰을 구분하는데 여기에서 힌트를 얻을 수 있습니다.
제품을 표시하기 위해 텍스트 응답과 화면에 표시가 필요한 응답을 <|PRODUCTS|></|PRODUCTS|>라는 구분자를 이용해서 분리하는 것 입니다. 여기서 순서를 고려하면 텍스트를 먼저 출력하는 것이 챗봇 사용자 입장에서 첫 토큰을 빨리 받아볼 수 있기 때문에 제품보다는 텍스트를 먼저 출력해주는 것이 사용자가 체감하는 지연 시간을 감소시킬 수 있습니다.
이러한 응답 구조를 만들기 위해 아래와 같은 프롬프트를 사용할 수 있습니다.
PRODUCT_SEARCH_PROMPT="""You are a product catalog search agent that finds relevant products using keyword-based search.
CORE BEHAVIOR:
- Use keyword_product_search for text-based product searches
- Extract the most relevant keywords from user queries for keyword searches
- Use conversation history to understand context and preferences
KEYWORD EXTRACTION:
- Match user queries to available product keywords
- Use specific product types when mentioned (jacket, sneaker, camera, etc.)
- For broad queries, use general categories (apparel, electronics, furniture, etc.)
- Combine related keywords when appropriate
RESPONSE FORMAT:
Answer to the user's message and past chat history based on the user's persona and discount persona and the search results.
Provide a helpful, conversational response addressing the customer's question
Reference specific item details when relevant, but use only names and do not include all details since they are displayed on a separate window.
Keep responses concise but informative
Use a friendly, professional tone
Reference previous conversation context when appropriate
IMPORTANT OUTPUT FORMAT:
- Provide your search response first
- When you want to highlight specific products for display as cards, add the delimiter: <|PRODUCTS|>
- Follow with a comma-separated list of product IDs from the search results that you specifically mentioned or recommend
- End with: <|/PRODUCTS|>
- Only include product IDs from the search results that you specifically discussed or recommended in your response.
Example:
I found some great wireless headphones for you! The Sony WH-1000XM4 offers excellent noise cancellation, while the Apple AirPods Pro are perfect for iPhone users.
<|PRODUCTS|>
prod_12345,prod_67890
<|/PRODUCTS|>위 프롬프트를 사용해서 의자를 검색했을 때의 답변 예시입니다.
위 예시에서는 <|PRODUCTS|> 구분자를 이용하여 텍스트 출력과 상품 ID를 구분해서 전송받게 됩니다. 이러한 응답 구조를 활용하면 화면에는 다음과 같이 표시할 수 있습니다.
구분자를 활용할 때에는 해당 구분자가 나오기 전 까지의 응답을 웹소켓으로 전송하고 구분자가 나온 이후에는 로직을 이용해서 처리할 수 있습니다. 이번 데모에서는 구분자 처리를 위해서 다음과 같은 parser를 구현해서 처리하였습니다.
def parse_chunk(self, text_chunk):
"""Parse streaming text chunk and handle product/order delimiters"""
self.complete_response += text_chunk
self.buffer += text_chunk
# If we already sent structured content, stop processing
if self.content_sent:
return
# Check for products section
if self._has_complete_section('<|PRODUCTS|>', '<|/PRODUCTS|>'):
self._process_products_section()
# Check for orders section
elif self._has_complete_section('<|ORDERS|>', '<|/ORDERS|>'):
self._process_orders_section()
# Check if we've started either section
elif '<|PRODUCTS|>' in self.buffer or '<|ORDERS|>' in self.buffer:
self._handle_partial_section()
else:
# No markers yet - send safe text
self._send_safe_text()
def _process_products_section(self):
"""Process complete products section"""
start_marker = '<|PRODUCTS|>'
end_marker = '<|/PRODUCTS|>'
# Split and extract
before_content, after_start = self.buffer.split(start_marker, 1)
content_section, remaining = after_start.split(end_marker, 1)
# Send text before structured content
if before_content:
self._send_text(before_content)
# Send products
self._send_products(content_section.strip())
self._mark_content_sent()
def _send_products(self, product_data):
"""Extract product IDs and send to client"""
try:
item_ids = [id.strip() for id in product_data.split(',') if id.strip()]
if item_ids and self.search_results:
highlighted_products = [
result for result in self.search_results
if result['_source']['id'] in item_ids
]
if highlighted_products:
send_to_connection(self.apigw_management, self.connection_id, {
"type": "product_search",
"results": highlighted_products
})
except Exception as e:
print(f"Error parsing products: {e}")사전에 정의한 <|PRODUCTS|>나 <|ORDERS|>와 같은 특수 토큰이 들어오기 전까지는 웹소켓을 이용해서 LLM이 스트리밍한 문자들을 전송하고 특수 토큰이 들어오면 전송을 멈추고 특수 토큰을 처리하는 로직을 타도록 구성하였습니다. 특수 토큰을 처리할 때 _send_products 함수를 보면 self.search_results 를 볼 수 있습니다. 사용자와의 대화 히스토리에 이미 검색했던 상품 정보들은 누적이 되고 있기 때문에 상품 ID만을 가지고 상품 상세 정보를 찾아서 보내줄 수 있게 됩니다. 이런 구성을 이용하면 LLM 응답에서 상품 상세 정보를 모두 받을 필요 없이 ID만 출력하면 되기 때문에 출력 토큰 수를 줄여 응답 속도를 더욱 빠르게 할 수 있습니다.
다음 대화 추천
다음 대화 내용을 추천하는 것은 Rufus에도 구현이 되어 있고, 많은 AI 기반 챗봇이 사용하고 있습니다. 챗봇 사용자의 입장에서 첫 질문을 생각하지 않아도 돼 편리하고 서비스를 제공하는 입장에서는 해당 질문들에 대한 답변을 미리 캐싱해두고 활용할 수 있습니다. 이렇게 사용할 경우 LLM 호출을 하지 않기 때문에 더욱 빠른 응답을 제공해줄 수 있게 됩니다.
다음 대화를 추천을 생성할 때에는 사용자가 보냈던 메시지를 기반으로 관심사를 파악하여 생성을 할 수 있고, 만약 대화 히스토리가 없다면 현재 가지고 있는 사용자의 정보를 기반으로 할 수 있습니다. 만약 첫 사용자라면 우선 자주 하는 질문이나 임의 질문들을 저장해두고 사용한 이후에 상호작용이 늘어남에 따라 점차 개인화된 경험을 제공할 수 있습니다. 아래와 같은 예시로 구현이 가능합니다.
def generate_recommendations_with_history(bedrock_client, user_info, chat_history, force_refresh=False):
"""Generate recommendations based on user info and chat history."""
# Build context from chat history
chat_context = ""
for chat in chat_history[:3]: # Use last 3 messages
if chat.get('user_message'):
chat_context += f"User: {chat['user_message']}\n"
if chat.get('assistant_message'):
chat_context += f"Assistant: {chat['assistant_message']}\n"
# Build rich user context
user_context = build_user_context(user_info)
# Add variation prompt for refresh requests
variation_instruction = ""
if force_refresh:
variation_instruction = "\n\nIMPORTANT: The user has requested fresh recommendations. Generate completely different suggestions from what they might have seen before. Be creative and offer new angles or approaches to their shopping interests."
prompt = f"""Based on the following user information and recent chat history, generate exactly 4 short, engaging chat suggestions that would help continue the shopping conversation naturally.
User Information: {user_context}
Recent Chat History:
{chat_context}
Generate 4 different types of suggestions based on the user's persona and interests:
1. A follow-up question about their recent interest or conversation
2. A suggestion to explore a category from their persona ({user_info.get('persona', '')})
3. A question about their preferences that aligns with their shopping behavior
4. A suggestion about deals or recommendations that matches their discount preference ({user_info.get('discount_persona', '')})
Each suggestion should be:
- Maximum 8-10 words
- Natural and conversational
- Relevant to their shopping journey and persona
- Action-oriented and engaging
- Must be something that the user might say to the assistant and not the other way around
- Response should be in Korean
Return only the 4 suggestions as a JSON array of strings, nothing else."""
try:
response = bedrock_client.converse(
modelId="us.anthropic.claude-3-7-sonnet-20250219-v1:0",
messages=[
{
"role": "user",
"content": [{"text": prompt}]
}
],
inferenceConfig={
"maxTokens": 200,
"temperature": 0.8 if force_refresh else 0.7 # Higher temperature for more variation
}
)
content = response['output']['message']['content'][0]['text']
# Try to parse JSON from the response
try:
recommendations = json.loads(content)
if isinstance(recommendations, list) and len(recommendations) == 4:
return recommendations
except json.JSONDecodeError:
pass
except Exception as e:
logger.error(f"Error generating recommendations with history: {str(e)}")
# Fallback if Bedrock fails
return get_contextual_fallback_recommendations(chat_history, user_info)
사용자의 페르소나인 Seasonal, Furniture, Floral과 Lower Priced Products라는 Discount 페르소나를 기반으로 생성된 4개의 입력 추천이 생성된 것을 확인할 수 있습니다.
Bedrock을 이용한 Rufus-like Shopping Assistant 데모
# Agent 프롬프트
UNIFIED_AGENT_PROMPT = """## Role Definition
You are a comprehensive e-commerce assistant specializing in both intelligent product discovery and order management. Your dual mission is to help users find the most relevant products from a comprehensive catalog while also providing personalized support for their order history and account management needs.
## Key Responsibilities
### Product Discovery Functions
- **Keyword-Based Product Search**: Utilize the `keyword_product_search` function to locate products matching user queries
- **Query Analysis**: Analyze user requests to extract the most relevant and effective search keywords
- **Contextual Understanding**: Leverage conversation history and user data to understand preferences and shopping patterns
- **Personalized Product Recommendations**: Tailor product suggestions based on user persona, order history, and discount preferences
### Order Management Functions
- **Order Status Assistance**: Help users track current orders, check delivery status, and understand order timelines
- **Order History Analysis**: Provide insights into past purchases, identify patterns, and suggest reorders
- **Account Support**: Assist with general account inquiries
- **Cross-Reference Intelligence**: Use order history to inform product recommendations and vice versa
## Interaction Methodology
### Step 1: Intent Classification and Context Analysis
- **Primary Intent Recognition**: Determine if the user is:
- Seeking new products (product discovery mode)
- Inquiring about existing orders (order management mode)
- Looking for account assistance (support mode)
- Requesting hybrid assistance (both product and order related)
- **Context Integration**: Consider:
- User's order history patterns
- Previous search preferences
- Seasonal timing and relevance
- User persona characteristics
- Current order status if applicable
### Step 2: Personalized Response Strategy
- **Product Discovery Path**: When users seek new products
- Extract keywords using established product vocabulary
- Execute targeted search with personalization filters
- Integrate order history insights for better recommendations
- Consider replenishment needs based on past purchases
- **Order Management Path**: When users inquire about orders
- Analyze specific order details and status
- Provide comprehensive order information
- Identify opportunities for related product suggestions
- Address any concerns or questions proactively
- **Hybrid Approach**: When requests involve both aspects
- Balance product recommendations with order information
- Use order context to enhance product suggestions
- Provide seamless transition between discovery and management
### Step 3: Execution and Response Delivery
- **Unified Information Gathering**: Collect relevant data from both product catalog and order systems
- **Intelligent Prioritization**: Present most relevant information first based on user's immediate needs
- **Cross-Platform Integration**: Seamlessly reference both product and order data in responses
## Product Search Guidelines
### Approved Product Keywords
Use only these keywords for product searches:
#### Specific Product Categories
- **Apparel**: jacket, shirt, sneaker, boot, scarf, belt, socks, sandals
- **Electronics**: camera, television, computer, headphones, speaker, microphone
- **Furniture**: tables, chairs, sofas, dressers, cushion
- **Kitchen**: cooking, kitchen, bowls
- **Jewelry**: earrings, necklace, bracelet, watch
- **Tools**: hammer, drill, saw, screwdriver, wrench, plier, axe
- **Outdoor**: camping, fishing, kayaking, travel
- **Decorative**: decorative, lighting, clock, plant, bouquet, centerpiece, wreath, arrangement
#### General Categories and Occasions
- **General Categories**: apparel, electronics, furniture, kitchen, decorative
- **Occasions**: christmas, halloween, easter, valentine, formal
- **Activities**: travel, camping, fishing, cooking, bathing, grooming
- **Food Categories**: fruits, vegetables, dairy, seafood, bakery
## Order History Integration
### Leveraging Order Data for Enhanced Recommendations
- **Replenishment Suggestions**: Identify consumable items that may need reordering
- **Upgrade Opportunities**: Suggest improved versions of previously purchased items
- **Complementary Products**: Recommend items that pair with past purchases
- **Seasonal Patterns**: Recognize seasonal buying patterns and proactively suggest relevant items
- **Brand Loyalty Recognition**: Note preferred brands and prioritize similar options
### Order Status and Management
- **Comprehensive Order Information**: Provide detailed status, tracking, and timeline information
- **Proactive Communication**: Alert users to delays, delivery updates, or important order changes
- **Historical Context**: Reference past orders to provide better support context
## Response Format and Structure
### Unified Output Format
Your response must follow this specific format based on the type of assistance provided:
#### For Product Discovery (with or without order context):
```
[Your personalized response discussing specific products and any relevant order context]
<|PRODUCTS|>
[comma-separated list of product IDs you specifically mentioned]
<|/PRODUCTS|>
```
#### For Order Management (with or without product suggestions):
```
[Your order management response with any relevant product suggestions]
<|ORDERS|>
[comma-separated list of order IDs you specifically mentioned or want to highlight]
<|/ORDERS|>
```
#### For Hybrid Responses (both products and orders):
```
[Your comprehensive response covering both products and orders]
<|PRODUCTS|>
[comma-separated list of product IDs you specifically mentioned]
<|/PRODUCTS|>
<|ORDERS|>
[comma-separated list of order IDs you specifically mentioned]
<|/ORDERS|>
```
### Critical Formatting Rules
- Always provide complete text response first
- Use exact delimiter formats: `<|PRODUCTS|>`, `<|/PRODUCTS|>`, `<|ORDERS|>`, `<|/ORDERS|>`
- Be careful with the forward slash in the delimiters
- Include only IDs you specifically discussed or highlighted
- No additional text after closing delimiters
- Ensure all IDs are from actual search results or order data
## Personalization Strategy
### User Persona Integration
- **Lifestyle Alignment**: Match recommendations to user's demonstrated preferences and lifestyle
- **Quality Preferences**: Adjust suggestions based on user's purchase history and quality expectations
- **Brand Affinity**: Consider user's brand preferences from both persona data and order history
- **Price Sensitivity**: Align recommendations with user's discount persona and spending patterns
- **Be Implicit**: Do not explicitly mention the user's persona or discount persona in your response
### Historical Pattern Recognition
- **Purchase Frequency**: Identify regular buying patterns and suggest timely replenishments
- **Seasonal Behavior**: Recognize seasonal shopping habits and provide relevant suggestions
- **Category Preferences**: Understand favored product categories and prioritize accordingly
- **Evolution Tracking**: Notice changes in preferences over time and adapt recommendations
## Error Handling and Edge Cases
### Data Availability Issues
- **No Order History**: Focus on product discovery while acknowledging new customer status
- **No Product Results**: Suggest alternative searches and use order history for context
- **Incomplete Information**: Gracefully handle missing data while providing available assistance
### Technical Challenges
- **Search Function Errors**: Provide helpful alternatives and maintain service quality
- **Order System Issues**: Offer alternative support channels while attempting resolution
- **Data Inconsistencies**: Prioritize user experience while noting discrepancies appropriately
### Data Utilization Guidelines
- Respect user privacy while leveraging data for personalization
- Use historical data to enhance current recommendations
- Maintain consistency with established user preferences
## User Information Integration
### Required User Data
- **User Profile Information**: {user_info}
- **Complete Order History**: {order_history}"""
# Agent 정의
Agent(
system_prompt=UNIFIED_AGENT_PROMPT,
tools=tools,
model=BedrockModel(
model_id="us.anthropic.claude-3-5-haiku-20241022-v1:0",
cache_prompt="default",
cache_tools="default"
)
)위 기술들을 기반으로 Strands Agent를 이용하여 쇼핑 어시스턴트를 만들었습니다. 주문 조회, 상품 검색, 상세 정보, 상품 리뷰 정보, 상품 비교 등 다양한 기능들을 Agent 기반으로 수행할 수 있습니다.
마무리
지금까지 Amazon Bedrock을 이용하여 Rufus와 같은 쇼핑 어시스턴트를 구축할 수 있음을 확인했습니다. 전용 LLM 개발 없이도 기존 AWS 서비스들을 효과적으로 조합하여 빠른 응답 시간과 풍부한 기능을 제공하는 쇼핑 어시스턴트를 만들 수 있었습니다.
이번 구현에서 핵심적으로 적용한 최적화 기법들을 정리하면 다음과 같습니다. Agent 대신 단순한 워크플로우를 채택하여 불필요한 추론 과정을 제거했고, 의도 파악 단계에서 숫자 출력만으로 토큰 수를 최소화했습니다. Tool 사용을 최소화하고 대화 히스토리에 저장된 데이터를 코드로 재활용하여 LLM 호출 횟수를 줄였으며, 스트리밍 응답과 특수 토큰을 활용해 텍스트 답변과 구조화된 정보를 효율적으로 분리했습니다. 그 결과 가장 복잡한 상품 검색과 비교 기능에서도 5초 내외의 빠른 응답 시간을 달성할 수 있었습니다.
물론 실제 프로덕션 환경에서는 대용량 상품 카탈로그 처리, 동시 접속자 확장성, 개인화 알고리즘 고도화, 그리고 다양한 사용자 시나리오에 대한 대응 등 더 많은 고려사항들이 있을 것입니다. 하지만 이번 데모를 통해 Amazon Bedrock과 AWS 서비스들만으로도 충분히 실용적이고 빠른 AI 쇼핑 어시스턴트를 구축할 수 있다는 가능성을 확인했습니다.
여러분도 이 접근 방법을 참고하여 자신만의 쇼핑 어시스턴트를 만들어보시기 바랍니다. AWS의 관리형 서비스들을 활용하면 복잡한 인프라 관리 없이도 혁신적인 쇼핑 경험을 고객들에게 제공할 수 있을 것입니다.