AWS 기술 블로그
“보이는 데이터”를 “쓸 수 있는 데이터 “로: 코오롱몰의 LLM 기반 상품 속성 추출 여정
들어가며
코오롱몰은 코오롱FnC가 운영하는 프리미엄 패션 이커머스 플랫폼으로서, 자체 브랜드의 헤리티지와 기술 혁신을 결합하여 고객에게 더 나은 쇼핑 경험을 선사하고 있습니다. 특히 AI를 기반으로 기술 중심의 이커머스 플랫폼으로 진화하며, AI 기반 추천, 상품 정보 자동화, 탐색 최적화 등 혁신적인 시도를 통해 고객에게 온라인에서의 새로운 쇼핑 경험을 제공하고 있습니다.
이 글에서는 코오롱몰이 어떻게 LLM 을 활용하여 ‘보이는 데이터’를 ‘쓸 수 있는 데이터’로 전환하여 고객에게 더 정확하고 빠른 상품 탐색 가능하게 했는지 소개하고자 합니다.
배경
? 발견: 보이지만 쓸 수 없는 데이터
어느 날, 상품에 대한 고객 문의 분석 중 흥미로운 패턴을 발견했습니다.
“이 재킷 75cm 넘나요?”
“루즈핏 셔츠만 보고 싶어요”
“린넨 소재 팬츠 필터 없나요?”
고객들이 원하는 정보는 분명 상품 페이지에 있었습니다. 사이즈표, 소재 정보, 핏 설명등 모두 이미지로 깔끔하게 정리되어 있었죠. 그런데 왜 고객들은 일일이 클릭하고 스크롤하며 찾아야 했을까요?
답은 간단했습니다. 그 정보들이 ‘이미지’ 안에만 존재했기 때문입니다.
? 문제의 본질: 메타데이터의 부재
패션 커머스에서 상품의 메타데이터(사이즈, 소재, 핏, 디테일)는 구매 결정의 핵심입니다. 하지만 대부분의 이 정보들은
- 상품 상세 이미지 안에 디자인 요소로 포함
- 데이터베이스에는 상품명과 가격 정도만 존재
- 검색이나 필터로는 활용 불가능
실제로 코오롱몰 전체 상품을 분석한 결과, 대다수의 상품이 사이즈를 비롯한 주요 속성 정보를 이미지로만 제공하고 있었습니다. 이는 단순히 우리만의 문제가 아닌, 패션 이커머스 업계 전반의 고질적인 문제였습니다.
? 도전 과제: 이미지를 데이터로, 그리고 서비스로
우리가 해결해야 할 핵심 과제는 명확했습니다.
“어떻게 하면 이미지 속 메타 정보를 추출해서 실제 서비스에 활용할 수 있을까?”
이를 위해서는 다음과 같은 과제들을 해결해야 했습니다.
- 수십만 개의 상품 이미지에서 정보 추출
- 브랜드마다 다른 표기법 처리 (총장 vs 기장 vs 총길이)
- 추출된 정보의 정확성 보장
- 실시간 서비스 반영을 위한 자동화
사람이 하나하나 입력한다면 520일이 걸릴 작업이었습니다. 모델을 만든다고 해도 이전에는 모든 상품에 직접 라벨을 달아 학습시켜 분류모델을 생성해야 했고 그 작업은 결코 간단한 과정이 아니었습니다.
그러나 이제는 이미 잘 학습된 다양한 파운데이션 모델을 활용하기만 해도 쉽고 빠르게 원하는 결과를 얻을 수 있습니다. 그래서 우리는 AI를 활용해 이 문제를 해결하기로 했고, 그 여정에서 Amazon Bedrock을 만나게 되었습니다.
메타 추출을 위한 Amazon Bedrock 선택
이번 프로젝트의 핵심 과제는 이미지 OCR → 의미 있는 구조화 → 상품 DB 반영까지의 전 과정을 자동화하는 것이었습니다. 이를 위해서는 다음과 같은 기술적 요구사항을 만족해야 했습니다.
- OCR로 추출된 불완전한 텍스트의 의미를 이해하고 요약할 수 있는 LLM
- 사이즈표나 속성표처럼 표 구조 인식 후 추출된 정보를 검색/추천에 맞는 형식으로 재구성
- 비용과 성능 측면에서 생산 환경에 투입 가능한 API 기반 추론 플랫폼
이러한 기준을 종합해 Amazon Bedrock을 통해 Claude Sonnet 3.5 v2를 호출하는 방식을 채택했습니다. 이 모델은 안정적인 응답 품질과 API 연결성, Prompt 튜닝 유연성 측면에서 실제 운영에 적합했습니다.
또한 Amazon Bedrock의 큰 장점은 단일 모델에 종속되지 않고 다양한 파운데이션 모델을 선택할 수 있다는 점입니다. 그래서 다양한 모델들을 테스트해보고 가장 적합한 모델을 적용하기 편리했습니다. 또한 향후 더 나은 모델이 출시되거나 특정 작업에 특화된 모델이 필요한 경우, 간단한 API 변경만으로 새로운 모델을 테스트하고 적용할 수 있어 지속적인 개선이 가능합니다.
솔루션 아키텍처와 흐름도
이번 프로젝트는 다음 이미지와 같은 흐름으로 진행됐습니다.
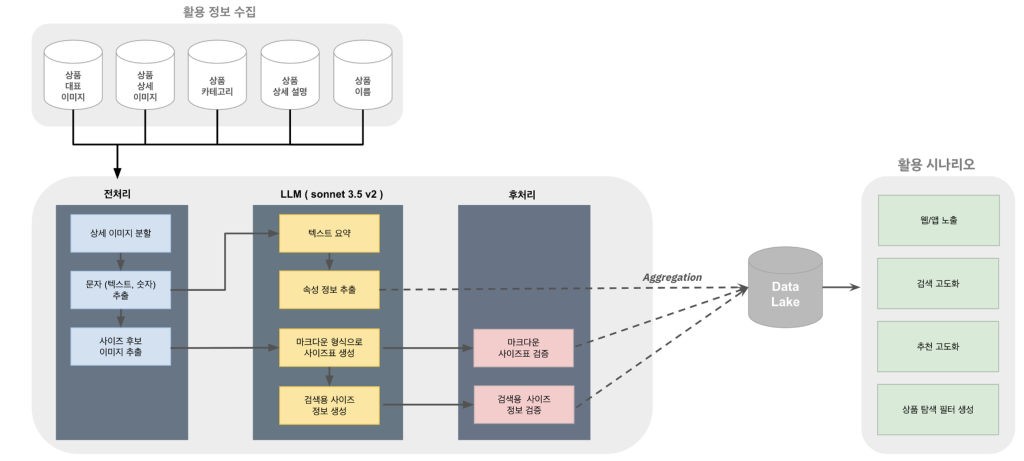
우선 상품 이미지 수집후 전처리가 수행됩니다. 전처리로 추출된 이미지와 OCR 결과를 통해 LLM이 속성과 사이즈표를 만들고 해당 정보를 후처리하여 DataLake에 집계해 실제 서비스에 활용하였습니다. 각 단계별 상세한 정보는 아래와 같습니다.
Step 1: 이미지 수집 – HTML에서 이미지 URL 추출
해당 프로젝트를 진행하기 위해 선행되어야할 과제는 제품 상세 이미지를 LLM에 활용 가능하도록 저장소에 적재하는 것이었습니다. 현재 자사 데이터 베이스에는 제품 상세페이지 이미지를 적재하지 않고 있었으나, 상품별로 상세페이지의 HTML을 OracleDB에 따로 적재한 데이터가 있었습니다. 그 안에서 png, jpg와 같이 이미지 주소 형식으로 되어있는 텍스트를 추출해 다운로드 받아 LLM에서 바로 사용 가능한 Amazon S3 bucket에 저장했습니다.
Step 2: 이미지 청킹 및 전처리
처음에는 상품 상세페이지에 삽입된 이미지를 그대로 인풋으로 넣자 할루시네이션이 빈번히 발생했습니다. 원인을 찾던 중, 인풋 이미지의 크기가 클수록 할루시네이션 발생 빈도가 높아진다는 사실을 발견했습니다. 세로로 긴 제품 상세 이미지 특성상 그대로 모델에 넣으면 사진 내 텍스트를 제대로 인식하지 못하는 문제가 발생하는 것이었습니다. 그래서 이미지의 높이가 특정 수치 이상인 경우 이미지를 크롭해서 모델에 넣었고, 그 결과 문자 오인식 사례가 현저히 감소했습니다.
또한, 전체 이미지 셋을 처리한다면 의미없는 데이터를 처리하기 위한 추가적인 리소스가 소모되었습니다. 따라서 EasyOCR을 활용해 실제 의미 있는 데이터가 포함된 이미지로 필터링하여 전체 파이프라인의 소요되는 리소스를 절감하였습니다.

Step 3: Bedrock LLM을 활용한 사이즈 정보 추출
사이즈 추출을 위해서는 상품 상세 이미지를, 속성 정보를 추출하기 위해서는 상품명, 상품 상세 설명 텍스트, 상품 대표이미지, 이미지 내 텍스트를 모델의 인풋으로 넣었습니다. 그리고 원하는 데이터 형과 추출 예시 항목들을 모델에 입력했습니다. 그 외에 잘 인식하지 못하는 사이즈 표 형식이 있는 경우는 프롬프트 하단에 직접 예시를 입력하고 기대되는 답변 형식을 전달해줬습니다.
프롬프트 예시
Human: Product Description에서 사이즈 정보를 찾고, 마크다운 형식으로 출력해주세요.
### ? Input Information:
- Product Description: `{product_description}`
### ? Instructions:
- 출력은 마크다운(Markdown) 형식으로 작성해주세요.
- 활용 가능한 사이즈 정보가 없다면 "fail”
- 최대한 텍스트 있는 그대로 변형 없이 추출해주세요.
#### Example1:
- Input:
SIZE(CM) 34: 총길이:119.5 가슴단면:46 어깨너비:37 팔길이:11
- Expected output:
| SIZE(CM) | 34 |
|------|------|
| 총길이 | 61 |
| 가슴단면 | 27 |
| 어깨너비 | 37 |
| 팔길이 | 11 |
Step 4: 데이터 정제 및 검증
4-1) 사이즈 정보 마크다운 형태로 생성 후 프론트 노출 가능한 구조로 정제
코오롱몰에서 사이즈표에 노출하는 사이즈 정보 표준과 입점 브랜드 상품들의 사이즈 표준 체계에는 꽤나 많은 차이가 존재했습니다. 예를 들어 코오롱몰에서는 총장이라고 표현하는 측정 부위를 입점 브랜드에서는 총길이, 기장과 같이 다양한 방식으로 표시하고 있었습니다. 그래서 생각한 방식은 ‘최대한 원래 정보를 있는 그대로 보여주자’ 였습니다. 그래서 최대한 원본 형태를 유지하며 용어도 그대로 사용할 수 있도록 마크다운 형태로 추출했고 이를 프론트에 노출시켰습니다.

4-2) 추출 로직 보정 및 재적용
LLM모델이 추출한 사이즈 표에는 실제 사이즈가 아닌 정보들도 종종 있었습니다. 예를 들어 모델의 키와 몸무게 같은 스펙 정보, 혹은 국가명과 같은 불필요한 정보들이 있을 때는 불용어로 처리를 해서 fail로 처리하도록 방어 로직을 생성했습니다. 그 결과 처음 추출했을 때 82.9%였던 모델 정확도가 마지막에는 99.6%까지 상승했습니다.
try:
for stop_word in self.stop_words_list:
if re.search(stop_word, text.lower()): # 정규 표현식 검색 적용
logger.info(
f"Table validation failed: Stop word '{stop_word}' found in text."
)
return "fail", "stop word”
Step 5: 자동화 파이프라인 구축
신규 상품 데이터는 6시간 간격으로 자동 업데이트되도록 스케줄화 해두었고, 추출 로직은 Docker로 컨테이너화되어 Amazon ECR에 배포된 뒤, Amazon SageMaker에서 주기적으로 호출됩니다. 이를 통해 코드 수정 이후에도 별도의 수작업 없이 최신 이미지가 자동 반영되어, 전체 파이프라인의 배포와 실행이 완전히 자동으로 운영되도록 구조화했습니다.
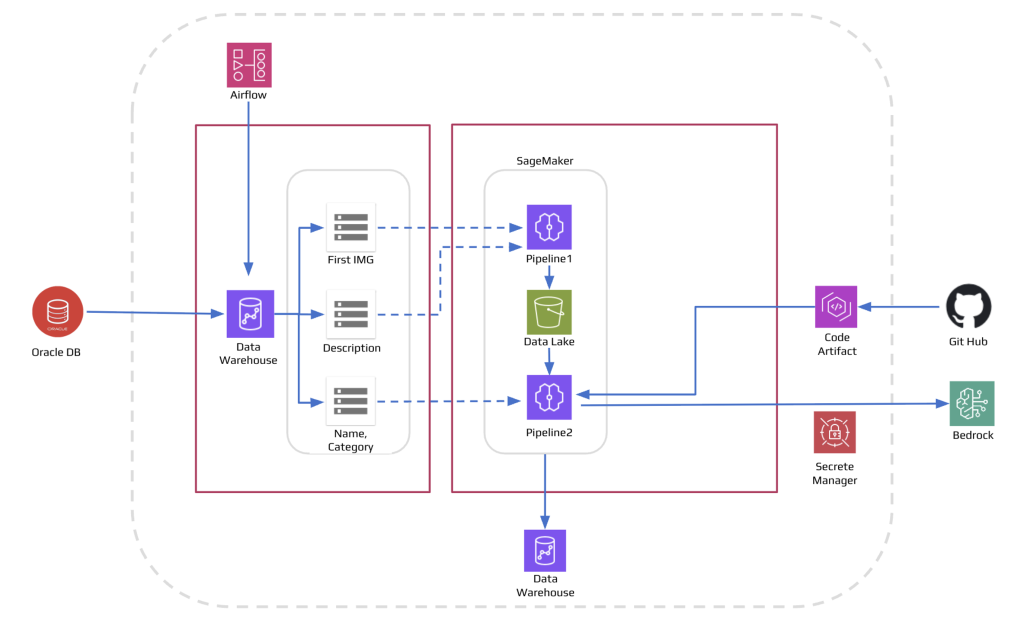
구현 결과와 성과
1. 추출 및 정규화 결과 요약
| 항목 | 기존 | 개선 후 |
|---|---|---|
| 클릭 대비 구매 전환율 | 3.77% | 5.03% (약 33% ↑) |
| 사이즈탭 노출률 | 22% | 42%(+6.3만 개 추가 노출) |
| 전체 속성 수 | 149개 | 23만 개 이상 속성 추출 |
2. 기술 성과
- 상품 정보 추출 자동화로 추출 시간 96% 이상 절감, 추출 비용 90% 절감
- 카테고리별 추출 항목과 용어를 프롬프트에 반영 및 후처리 로직으로 모델 정확도 99.6% 달성
- 패키지 기반 구조 설계로 프롬프트 재작성, 단일 모듈 수정만으로 모델 교체 및 개선 가능
3. 사용자 경험 변화
- 사이즈 정보를 직접 찾을 필요 없이 클릭 한 번으로 쉽고 빠르게 사이즈 정보 확인 가능
- 고객은 필터를 통해 ‘루즈핏 린넨 셔츠’, ‘총장70cm 이상’ 과 같은 조건으로 상품 탐색 가능
- 추천 시스템은 사이즈 유사도 + 소재 기반 유사도를 고려해 정교한 제안 가능
기존 사이즈 정보 탐색 여정 : 상품 클릭 > 상세정보 스크롤 > 사이즈 정보 찾기
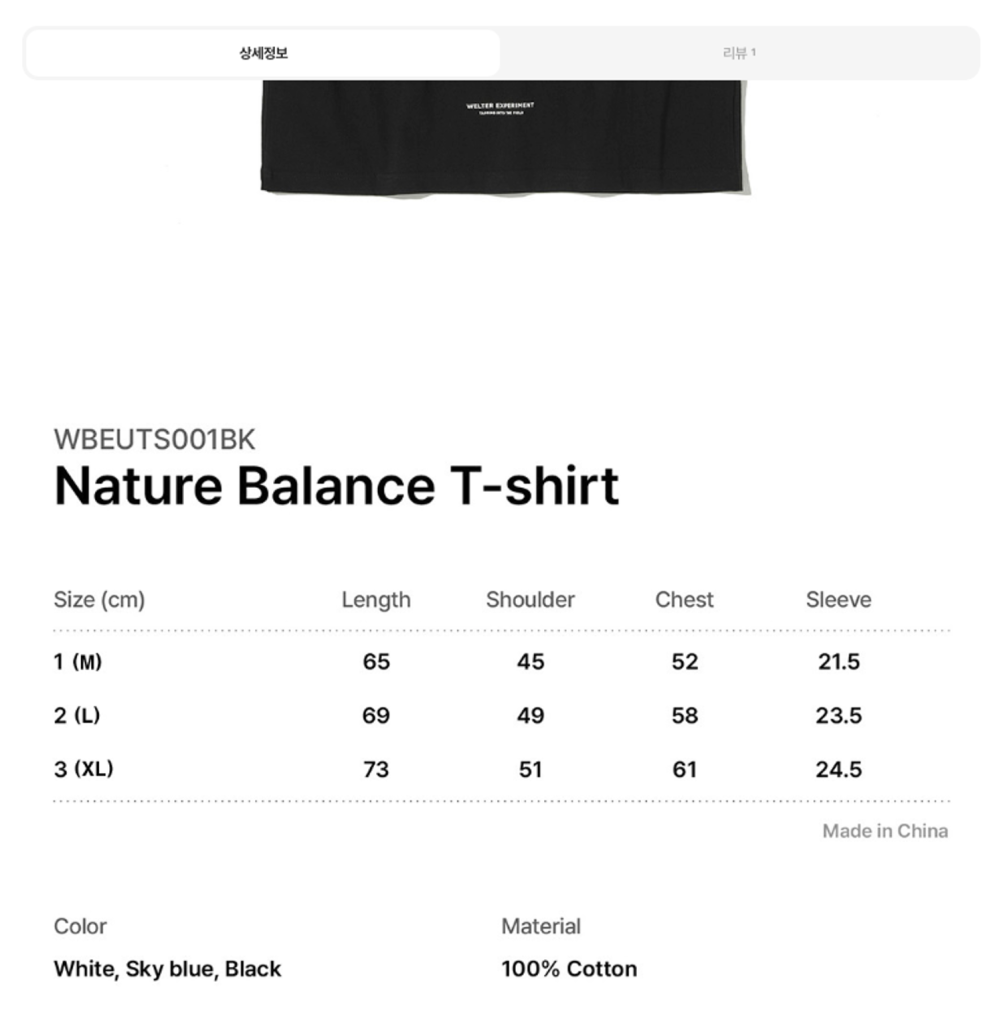
개선된 사이즈 정보 탐색: 상품 클릭 > 사이즈탭 클릭

마무리
“작은 정보 하나가 고객 구매 결정 여부를 바꿀 수 있다.”
이번 프로젝트를 통해, 사람이 직접 수행했다면 520일 이상 소요될 수 있는 작업을 LLM 기반 자동화를 통해 단 14일 만에 완료하며 96% 이상의 시간 절감을 달성했습니다. 전체 추출 비용 역시 약 90% 절감되었고, 사이즈탭이 노출된 상품군은 클릭 대비 구매 전환율 약 33% 이상 상승했습니다.
이러한 결과를 통해 AI 기술이 제공하는 업무 효율성과 비용 절감의 가능성이 매우 크다는 것을 입증했을 뿐 아니라 사이즈 정보와 같은 단순해 보이는 데이터도 고객의 구매 의사결정에 실질적으로 영향을 미치는 핵심 요소임을 확인했습니다. 사이즈표 노출이라는 작지만 의미 있는 도전에서 시작된 코오롱몰의 상품 속성 추출 여정은 이제 검색 결과 개선과 추천 고도화로 이어지며 고객 상품 탐색 경험의 질적 향상을 이끌고 있습니다. 또한 모듈화된 파이프라인 설계로 확장성 있는 운영과 빠른 수정 및 보완이 가능합니다. 이를 기반으로 텍스트 프롬프트나 전처리 모듈만 교체함으로써 다양한 결과물을 출력해 고객 쇼핑 경험 향상에 적극 활용하고 있습니다.
코오롱몰은 앞으로도 데이터와 발빠른 AI 기술 적용을 중심으로 커머스 혁신을 통해, 고객의 더 나은 선택과 기업의 지속 가능한 성장을 함께 실현해 나가고자 합니다.