AWS 기술 블로그
Amazon RDS for PostgreSQL, Amazon Aurora PostgreSQL, Babelfish for Aurora PostgreSQL에서의 동적 데이터 마스킹
이 글은 AWS Database Blog에 게시된 Dynamic data masking in Amazon RDS for PostgreSQL, Amazon Aurora PostgreSQL, and Babelfish for Aurora PostgreSQL by Ezat Karimi 을 한국어 번역 및 편집하였습니다.
데이터 난독화 또는 데이터 익명화란, 필요한 작업을 위한 합법적인 액세스는 허용하지만 데이터 침해 위험은 최소화하기 위해 민감 데이터를 마스킹하거나 변경하는 데에 사용하는 일련의 기술을 의미합니다. 이 과정은 일반적으로 민감 정보에 대한 기밀 유지가 필요하여 업계 규정 및 표준을 준수해야 하는 금융, 의료 및 정부 산업과 같은 업계에서 사용됩니다.
데이터 난독화 기법은 필요한 개인 정보 보호 수준에 따라 다를 수 있으며, 다음과 같은 기법들이 포함됩니다.
- 암호화 — 이 기술은 특정 키로만 해독할 수 있는 수학적 알고리즘을 사용하여 데이터를 암호문으로 변환하는 기술입니다.
- 해싱 — 이 기술은 고유한 솔트(SALT) 값을 단방향 해시 함수에 입력하여 데이터를 고정된 길이의 해시값으로 변환하는 기술로, 단방향이기 때문에 해시값으로부터 원본 데이터를 역으로 추적하는 리버스 엔지니어링이 불가능합니다.
- 토큰화 — 이 기술은 민감한 데이터를 의미나 가치가 없는 대체값(토큰)으로 대체하는 기술입니다. 여기에서 토큰은 토큰화 시스템을 통해서만 원본 민감 데이터와 매핑될 수 있는 참조값을 의미합니다.
- 데이터 마스킹 — 이 기술은 원본 데이터를 가상의 데이터 또는 가려진 형태로 대체하여 데이터를 부분적으로 또는 완전히 숨기는 기술입니다.
데이터베이스에서 데이터 마스킹을 지원하는 다양한 기법이 있지만, 각각 장단점이 있습니다. 이 게시물에서는 원본 데이터를 수정하지 않지만 쿼리 결과로는 익명화된 데이터를 반환하는 기술인 ‘동적 데이터 마스킹’에 대해 살펴보겠습니다.
Oracle 및 Microsoft SQL Server와 같은 많은 상용 데이터베이스 시스템들은 동적 데이터 마스킹을 제공하고 있으며, 이러한 데이터베이스 시스템에서 PostgreSQL로 마이그레이션하는 고객들은 PostgreSQL에서도 비슷한 기능을 필요로 할 수 있습니다. 이 게시물에서는 동적 마스킹 뷰를 기반으로 하는 동적 데이터 마스킹 기술에 대해 설명합니다. 이러한 뷰는 권한이 없는 사용자들에 대해 개인 식별 정보 (PII) 컬럼을 마스킹합니다. 이 게시물에서는 Babelfish for Aurora PostgreSQL를 포함한 Amazon Relational Database Service (Amazon RDS) for PostgreSQL 및 Amazon Aurora PostgreSQL-Compatible Edition에서 이 기술을 구현하는 방법을 다루며, 마지막 섹션에서는 동적 데이터 마스킹 기술의 한계에 대해 살펴보겠습니다.
마스킹 뷰를 사용한 동적 데이터 마스킹
이 게시물에서는 동적 데이터 마스킹(PGDDM) 패키지에 대해 설명합니다. 이 패키지는 소스 테이블을 입력으로 받아 뷰를 생성하는데, 이 뷰는 접근하는 사용자의 역할(페르소나)에 따라 지정된 마스킹 패턴을 사용하여 소스 테이블의 PII 컬럼을 마스킹합니다. 마스킹 뷰는 권한이 없는 사용자들에게는 PII 컬럼을 마스킹해 보여주고, 권한이 있는 사용자들은 해당 컬럼의 마스킹되지 않은 데이터를 볼 수 있게 합니다. PGDDM의 코드는 함께 제공되는 GitHub repo에서 찾을 수 있습니다.
Babelfish의 경우, PGDDM 패키지를 전역적으로 사용하게 하려면 Babelfish의 PostgreSQL 엔드포인트의 Babelfish_db에 있는 sys 스키마에 패키지를 위치시켜야 합니다. PGDDM 아티팩트들을 로드하려면, Babelfish의 PostgreSQL 엔드포인트로 로그인하여 PGDDM.SQL 스크립트를 로드하세요. 이 스크립트는 모든 아티팩트를 해당 데이터베이스의 sys 스키마에 로드합니다. sys 스키마는 Babelfish에서 전역적이므로 Babelfish 인스턴스의 모든 데이터베이스에서 이러한 아티팩트들이 보이게 됩니다.
Aurora PostgreSQL-Compatible과 Amazon RDS for PostgreSQL의 경우, 지정된 데이터베이스의 sys 스키마에 PGDDM 패키지를 위치시키면 됩니다. 콘텐츠를 로드하려면 PGDDM.SQL 스크립트를 사용하세요. PostgreSQL의 데이터베이스는 독립적이므로, PGDDM 패키지를 모든 데이터베이스에 공통으로 사용하려면 PostgreSQL 템플릿 데이터베이스를 사용해 패키지를 새로운 데이터베이스에도 자동으로 설치할 수 있습니다. 단, 템플릿 콘텐츠는 기존 데이터베이스로는 전파되지 않습니다.
솔루션 개요
PGDDM은 다음 5가지 주요 구성요소를 가지고 있습니다.
- Source tables — PII 컬럼을 포함하는 테이블
- PII_masked_columns table — 소스 테이블의 모든 PII 컬럼들을 나열하고, 특정 PII 컬럼에 적용할 마스킹 패턴을 지정하는 테이블입니다.
- Unmasked_roles table — 소스 테이블의 PII 컬럼을 마스킹되지 않은 상태로 볼 수 있는 권한이 있는 역할들을 지정하는 테이블입니다.
- Masking artifacts – 마스킹 뷰를 생성하고 마스킹 패턴을 적용하는 데 사용되는 함수 및 프로시저 세트입니다.
- Masking views – 선언된 마스킹 패턴을 사용하여 권한 없는 사용자들에게 PII 컬럼을 마스킹하는 뷰입니다.
다음의 다이어그램은 마스킹 뷰를 사용하여 동적 데이터 마스킹을 적용하는 전체 프로세스를 보여줍니다.
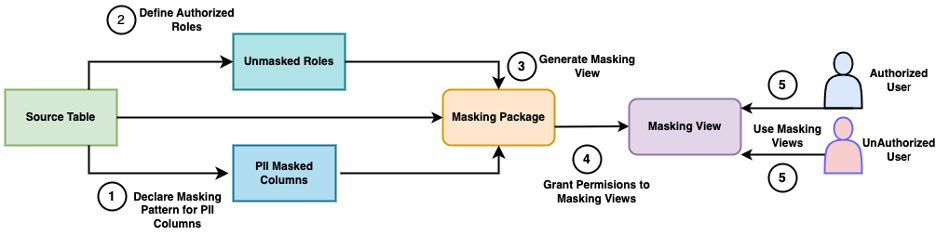
이 워크플로를 구현하려면 다음의 단계를 완료하십시오.
- 각 테이블의 PII 컬럼에 대한 마스킹 패턴을 선언합니다.
- 마스킹되지 않은 역할들을 선언합니다. 이 역할을 가진 사용자들은 원본 테이블에서 마스킹되지 않은 데이터를 볼 수 있습니다.
- 프로시저
GenMaskingView와 함께 제공되는 함수를 실행하여 마스킹 뷰를 생성합니다. - 사용자들에게 마스킹 뷰 사용 권한을 부여합니다. 필요에 따라 원본 테이블에서 권한을 취소합니다.
- 마스킹 뷰를 사용합니다. 이러한 뷰는 사용자 역할을 확인하고, 권한이 없는 경우 동적 데이터 마스킹 패키지에 정의된 마스킹 함수를 사용하여 PII 컬럼에 선언된 마스킹 패턴을 적용합니다.
PGDDM은 원본 테이블과 마스킹 뷰가 별도의 데이터베이스 스키마에 있다고 가정합니다. 이는 마스킹 뷰와 소스 테이블이 동일한 이름을 가지기 때문입니다.
PGDDM의 마스킹 함수
PGDDM 패키지는 다음과 같은 마스킹 패턴들을 제공합니다. 마스킹 패턴은 정규 표현식 패턴을 기반으로 PII 컬럼의 데이터를 마스킹하는 함수입니다. 다음 표에는 사용 가능한 마스킹 패턴이 나와 있습니다.
| 마스킹패턴 | 컬럼 데이터 타입 | 마스킹 패턴 예시 | 입력 예시 | 출력 |
default() |
Text |
MASKED WITH (FUNCTION = default()) |
admin |
X |
default() |
Number |
MASKED WITH (FUNCTION = default()) |
100 |
0 |
partial(n, xxxxx, m) |
Text |
MASKED WITH (FUNCTION = partial(0, xxxxx, 8) |
admin |
xxxxxxxx |
email() |
Text |
MASKED WITH (FUNCTION=email()) |
john@efgh.biz |
joXXXXXXXX.biz |
random(n, 1m) |
Number |
MASKED WITH (FUNCTION = random(1, 100)) |
7102933 |
15 |
pii_masked_columns 테이블은 원본 테이블의 각 PII 컬럼에 대한 마스킹 패턴을 추적합니다. 이 테이블은 다음과 같은 구조를 가집니다.
- Database_name – 원본 테이블이 위치한 데이터베이스의 이름
- schema_name – 원본 테이블이 위치한 스키마의 이름
- Table_name — 원본 테이블의 이름
- Column_name — PII 컬럼의 이름
- Masking — 데이터를 마스킹하기 위한 패턴
다음 표에는 pii_masked_columns 테이블의 예시 항목들이 나와 있습니다.
| 데이터베이스 이름 | 스키마 이름 | 테이블 이름 | 컬럼 이름 | 마스킹 |
users |
source_schema |
user_job |
title |
MASKED WITH (FUNCTION = default()) |
users |
source_schema |
user_job |
job |
MASKED WITH (FUNCTION = default()) |
users |
source_schema |
user_job |
email |
MASKED WITH (FUNCTION = email()) |
users |
source_schema |
user_bank |
bank_name |
MASKED WITH (FUNCTION = partial(0,XXXXXXXX, 5)) |
users |
source_schema |
user_bank |
account_id |
MASKED WITH (FUNCTION = random(1, 100)) |
users |
source_schema |
user_bank |
balance |
MASKED WITH (FUNCTION = random(100,500)) |
마스킹되지 않은 데이터를 볼 수 있는 권한 있는 사용자 설정
권한이 있는 사용자들(PII 데이터를 마스킹되지 않은 상태로 볼 수 있는 사용자들)은 unmasked_roles 테이블을 사용하여 정의됩니다. 이 테이블은 다음과 같은 구조를 가집니다.
- Role – 데이터를 마스킹되지 않은 상태로 볼 수 있는 권한이 있는 사용자의 역할
- Database_name – 원본 테이블이 위치한 데이터베이스의 이름
- Schema_name – 원본 테이블이 위치한 스키마의 이름
- Table_name — 원본 테이블의 이름
다음 표에는 unmasked_roles 테이블의 예시 항목들이 나와 있습니다.
| 역할 | 데이터베이스 이름 | 스키마 이름 | 테이블 이름 |
admin |
users |
source_schema |
user_location |
admin |
users |
source_schema |
job |
staff |
users |
source_schema |
users |
hr |
users |
source_schema |
users |
postgres |
users |
source_schema |
user_location |
hr |
users |
source_schema |
user_job |
hr |
users |
source_schema |
user_bank |
hr |
users |
source_schema |
user_location |
동적 데이터 마스킹 뷰 구축
마스킹 프로시저 GenMaskingView는 특정 테이블에 대한 마스킹 뷰를 생성하는 데 사용됩니다.
다음은 Amazon RDS for PostgreSQL 및 Aurora PostgreSQL-Compatible에서 프로시저를 사용하는 구문입니다.
CALL sys.GenMaskingView (<database>, <source_schema>, <source_table>, <view_schema>);예를 들면 다음과 같습니다.
CALL sys.GenMaskingView ( 'users', 'source_schema', 'users', 'view_schema')이 프로시저를 호출하면 마스킹 뷰를 생성하는 다음과 같은 SQL 문을 생성합니다.
CREATE VIEW view_schema.user_bank AS
WITH t AS(SELECT COUNT(*) as cnt from sys.unmasked_roles
WHERE table_name = 'user_bank'
AND schema_name = 'source_schema'
AND database_name ='users'
AND role = CURRENT_ROLE)
SELECT bank_id, user_id,
CASE WHEN cnt = 1 THEN bank_name ELSE sys.partial(bank_name,0,'xxxxxxxx',5) END AS bank_name,
CASE WHEN cnt = 1 THEN account_id ELSE sys.random_num(1,100) END AS account_id,
CASE WHEN cnt = 1 THEN balance ELSE sys.random_num(100,500) END AS balance
FROM source_schema.user_bank, t이 기법에서 마스킹 뷰는 CURRENT_ROLE (뷰가 실행되는 역할)을 기반으로 권한을 확인합니다. 이는 사용자가 현재 실행하는 컨텍스트에서 가지고 있는 역할에 따라, 다른 권한 패턴을 가질 수 있음을 의미합니다.
Babelfish for Aurora PostgreSQL (TSQL endpoint)에서 프로시저를 사용하는 구문은 다음과 같습니다.
EXEC sys.GenMaskingView @p_database = <database>, @p_source_schema = <source_schema>, @p_source_table = <source_table>, @p_view_schema = <view_schema>예를 들면 다음과 같습니다.
EXEC sys.GenMaskingView @p_database = 'users', @p_source_schema = 'source_schema', @p_source_table= 'users', @p_view_schema = 'view_schema'이 프로시저를 호출하면 마스킹 뷰를 생성하는 다음과 같은 SQL 문을 생성합니다.
CREATE VIEW view_schema.user_bank AS
WITH t AS (SELECT COUNT(*) as cnt from sys.unmasked_roles
WHERE table_name = 'user_bank'
AND schema_name = 'source_schema'
AND database_name ='users'
AND role = ORIGINAL_LOGIN()))
SELECT bank_id, user_id,
CASE WHEN cnt = 1 THEN bank_name ELSE sys.partial(bank_name,0,'xxxxxxxx',5) END AS bank_name,
CASE WHEN cnt = 1 THEN account_id ELSE sys.random_num(1,100) END AS account_id,
CASE WHEN cnt = 1 THEN balance ELSE sys.random_num(100,500) END AS balance
FROM source_schema.user_bank, t기본 소스 테이블의 정의가 변경되면 마스킹 뷰를 재생성해야 합니다. 또한 마스킹 뷰가 생성되기 전에 unmasked_roles 및 pii_masked_columns 테이블에 소스 테이블의 변경 사항이 반영되어야 합니다.
많은 테이블을 처리할 때는 정의가 변경된 테이블을 추적하는 것이 번거로울 수 있습니다. MaskingReconciliation 프로시저를 사용하여 스키마의 모든 테이블에 대한 동적 데이터 마스킹 뷰를 생성할 수 있습니다.
다음은 Amazon RDS for PostgreSQL 및 Aurora PostgreSQL-Compatible용 구문입니다.
CALL sys.MaskingReconciliation (<database>, <source_schema>, <view_schema>);다음은 Babelfish for Aurora PostgreSQL (TSQL endpoint)용 구문입니다.
EXEC sys.MaskingReconciliation @p_database = <database>, @p_source_schema = <source_schema>, @p_view_schema = <view_schema>
동적 마스킹 뷰 쿼리
사용자들에게 동적 데이터 마스킹 뷰에 대한 접근 권한이 부여된 후, 사용자는 이 뷰들을 통해 소스 테이블의 데이터를 볼 수 있습니다. 권한이 없는 사용자는 PII 컬럼이 마스킹된 상태로 보이고, 권한이 있는 사용자는 마스킹되지 않은 상태로 볼 수 있습니다. 예를 들어, 권한이 없는 사용자가 user_bank 뷰에서 조회할 때 다음과 같은 항목들이 표시됩니다.
SELECT * FROM view_schema.user_bank권한이 없는 사용자가 보는 결과
| bank_id | user_id | bank_name | account_id | balance |
| 1 | 1 | xxxxxxxx | 75 | 300 |
| 2 | 1 | bankxxxxxxxxress | 19 | 379 |
| 3 | 2 | xxxxxxxxbank | 56 | 401 |
| 4 | 2 | xxxxxxxx | 20 | 222 |
| 5 | 3 | xxxxxxxxbank | 45 | 283 |
| 6 | 4 | xxxxxxxx | 20 | 295 |
| 7 | 5 | xxxxxxxx | 80 | 195 |
| 8 | 6 | bankxxxxxxxxress | 23 | 361 |
| 9 | 7 | xxxxxxxx | 20 | 284 |
권한이 있는 사용자가 동일한 뷰를 사용할 때는 PII 데이터가 마스킹되지 않은 상태로 보입니다.
권한이 있는 사용자가 보는 결과
| bank_id | user_id | bank_name | account_id | balance |
| 1 | 1 | bank1 | 7,102,933 | 500,000 |
| 2 | 1 | bank_in_congress | 8,100,033 | 100,000 |
| 3 | 2 | southern bank | 1,111,133 | 200,000 |
| 4 | 2 | bank4 | 8,188,833 | 90,000 |
| 5 | 3 | southern bank | 3,333,222 | 700,000 |
| 6 | 4 | bank1 | 9,019,292 | 15,000 |
| 7 | 5 | bank5 | 1,111,111 | 60,000 |
| 8 | 6 | Bank_in_congress | 2,222,222 | 3,000 |
| 9 | 7 | bank1 | 7,887,603 | 650,000 |
동적 데이터 마스킹의 한계
동적 데이터 마스킹은 쉽게 시작할 수 있지만, 알아야 할 몇 가지 제한사항이 있습니다.
- 읽기 전용 특성 — 동적으로 마스킹된 데이터는 데이터베이스에 다시 쓸 수 없으며, 데이터 수정이 필요한 개발 및 테스트 환경에는 적합하지 않습니다.
- 성능 영향 — 실시간 마스킹 프로세스로 인해 추가 처리 오버헤드가 발생하므로, 쿼리 성능에 잠재적 영향을 미칠 수 있습니다.
- 복잡한 구성 — 세분화된 접근 제어나 원격 시스템 연동이 필요한 쿼리에 대한 마스킹 규칙 설정은 복잡하므로, 세심한 관리가 필요할 수 있습니다.
- 우회 가능성 — 고급 SQL 쿼리, 권한 에스컬레이션, 무차별 대입 기법 등 다양한 방법을 통해 동적 마스킹 프로세스가 우회될 가능성이 존재합니다.
- 추론 취약성 — 마스킹으로 인해 민감한 데이터가 숨겨지더라도, 마스킹된 데이터에 접근할 수 있는 사용자는 여전히 패턴 분석을 통해 민감한 정보를 유추할 수 있습니다.
리소스 정리
이 게시물에서 제시한 설정이 더 이상 필요하지 않은 경우, 관련 리소스를 모두 삭제하여 향후 요금이 청구되지 않도록 하세요.
- Amazon RDS 콘솔의 탐색 창에서 Databases를 선택합니다.
- 삭제하려는 DB 인스턴스를 선택하고 Actions 메뉴에서 Delete를 선택합니다.
- 확인하려면
delete me를 입력하고 삭제를 선택합니다.
결론
이 게시물에서는 권한이 없는 사용자들에 대해 PII 데이터를 마스킹하기 위한 마스킹 뷰를 생성하는 방식으로 Aurora PostgreSQL 호환 및 PostgreSQL용 Amazon RDS에서 동적 데이터 마스킹 뷰를 구현하는 방법을 살펴보았습니다. 또한 동적 데이터 마스킹은 주로 제한된 접근 권한을 가진 인증된 사용자를 위한 프로덕션 환경에서 필요에 따라 민감한 데이터를 마스킹하는 데 사용할 수 있지만, 전체 데이터 조작이나 개발 목적으로는 적합하지 않다는 점도 알아야 합니다. 동적 데이터 마스킹 아티팩트의 소스 코드는 GitHub repo에서 확인할 수 있습니다.